[Big Bird]论文解读:Big Bird: Transformers for Longer Sequences
论文:Big Bird: Transformers for Longer Sequences
作者:Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed
时间:2021
地址:http://goo.gle/bigbird-transformer
1 介绍
结合attention mechanism的模型毫无疑问是NLP领域最热的模型,但是普通的注意力机制收到了平方次计算量的限制,为了解决这个问题,这里论文推出了BigBird,去结合sparse attention mechanism把平方次计算变为线性计算;
Big Bird保留了完全注意力机制的特性,同时论文还解释了全局token的用处,例如bert中的CLS,在sparse attention mechanism中可以对整体序列进行交互,利用这个模型可以在保持硬件不发生改变的情况下处理比原来高8x的序列长度,像QA任务和summarization任务这些长序列任务可以在Big Bird中得到显著的改善;
self-attention mechanism并不能够记忆sequence的顺序,在这个机制中,组成sequence的各个部分都是无序的,同时该机制是图灵完全的,可以伪装成人类,表现出和人类一致的智力水准;作者提出了两个问题,如何利用能少的计算获取完整的注意力机制的表达能力?sparse attention mechanism 能否保留full attention mechanism的表达力和灵活度;
作者从graph sparsification中找到灵感,当full-attention mechanism放缩到一定程度时,transformer的表达能力会失效;通过合理的放缩,作者提出了Big Bird模型,该模型主要由三个部分组成:
- 部分注意整体序列的全局tokens
- 所有注意邻近序列的局部tokens
- 所有注意任意序列的随机tokens
该论文的主要成果是:
- BigBird拥有transformer模型的所有已知的理论属性,同时证明了全局token可以表达整体 序列的能力;
- BigBird可以处理长序列,并在长序列任务中达到了sota;
- BigBird可以运用在处理基因序列上;
2 模型架构
在allevate the quadratic dependency上,有两种处理方式:
- 第一种是用其他方法去绕过
full-attention - 第二种是想其他办法去优化
full-attention
BigBird很显然是第二种方法,下面是BIGBIRD的注意力机制架构:

从图中很容易就可以看出,这种方法和Longformer是差不多相同,但是作者提到了区别:首先Longformer中没有random attention;第二,Big Bird使用相对位置编码,而Longformer采用的是BERT的位置编码即learned absolute embedding;第三,BigBird对全局token使用的是CPC损失;
下面是注意力机制的一般形式,这个就看一下公式就好,加了一个残差连接:

这里Big Bird通过不去计算白色部分来加快计算;但是感觉有random的话加快不了多少,我感觉反而不如Longformer的膨胀处理方式;
在这里的话,random我个人认为是让模型有一定的获取全局信息的能力,但是能力不如full attention,近似于模糊处理,有这个能力一定是要比没有好的,所以有一定的提升是很正常的,但是这样一处理,感觉模型速度加快受到了部分限制,但总归是提升了吧;

这里全局注意力有两种方式:

第一种便是ITC机制,就是在矩阵中选择一些token作为全局token
第二种便是ETC机制,采取的方式是类似于bert中的cls方式,在序列上设置一些special token
在这里个人认为第二种ETC机制应该常用一些,我一直纳闷怎么显著加快训练,这里给了我答案:

对,就是用了分块矩阵的性质,把大矩阵变成小矩阵来计算,具体如图:
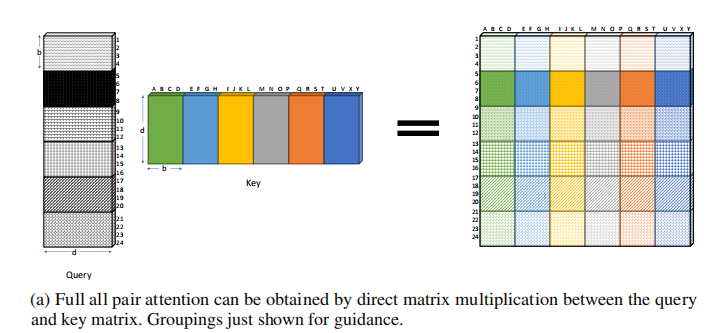
上面是full attention的效果图,可以看到没有空块,但是全部要计算;
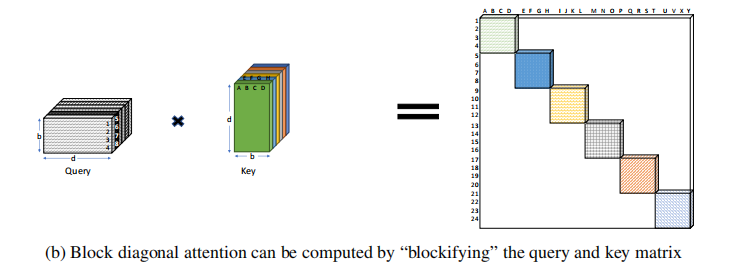
这是计算对角阵的注意力权重,可以发现只需要相应的矩阵相乘就可以得到;
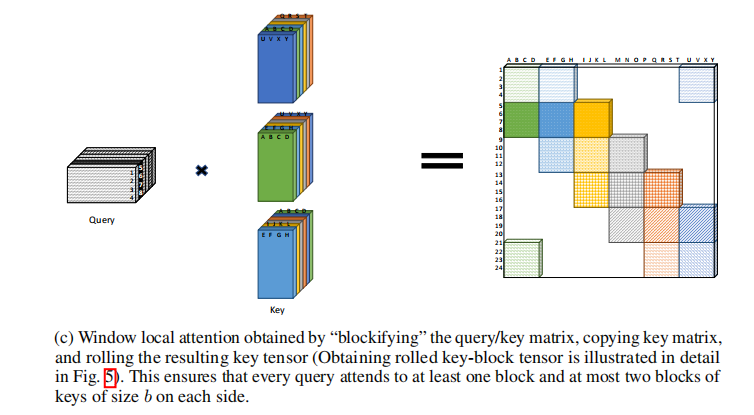
这是其计算的扩展,不需要计算空块,接下来只需要加上一个random模块就完美解决了;
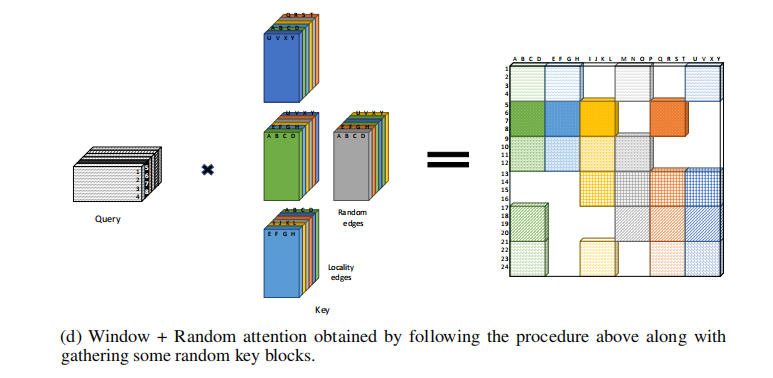
如图,完美解决计算量的问题,我觉得Longformer也可以试一下,不过好像Longformer的优化要比这个要好;
最后得到的整体如下图:

妙!但是这样依赖随机矩阵就受到了一定的限制,不过是可以优化的;
3 结果
其采取的预训练方式为MLM;
模型结果如下:
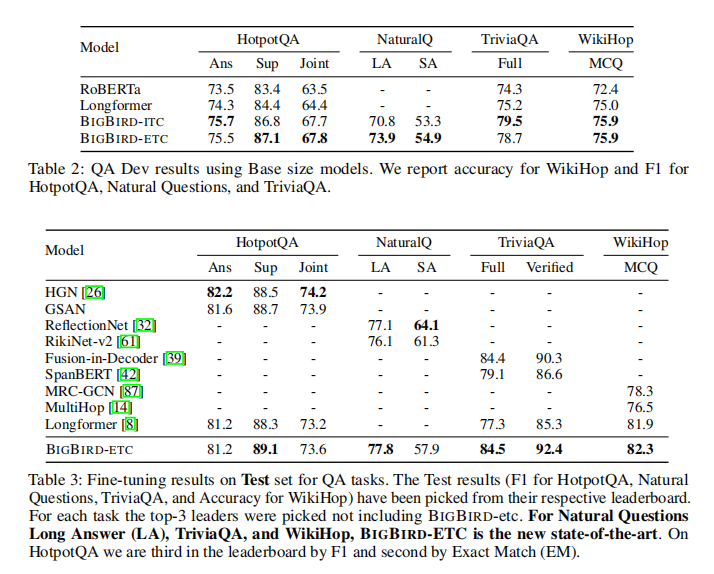

可以发现,效果是可观的,random可以让sequence获得全局信息,在提升模型速度的同时,提升模型的性能;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 5年开酸奶店的经历,告诉小白如何做市场调查
- 免费学习AI知识的渠道,整理了一些公开的GPT综合学习资料
- 方法 ‘NetWork.call()‘ 的签名与类 ‘Model‘ 中基方法的签名不匹配
- 软件测试|深入理解SQL RIGHT JOIN:语法、用法及示例解析
- 中国香港服务器:2024好用服务商有哪几家推荐
- “中国女性婉婉有仪”浅谈
- maven多个module打包
- 手持机定制_手持终端_rfid手持终端设备开发解决方案
- Ceph文档
- Java集合Collection