mysql的性能调优,explain的用法,explain各字段的解释
EXPLAIN一条语句的各字段解析如下
id
首先我们要知道explain的每一条记录都对应着访问单表的方式,即使说一条查询语句可能用了两个表,那也要拆成两条记录,只不过二者id相同,因为一个SELECT对应一个id。并且出现在前面的s1代表mysql选择它作为驱动表,而后面的s2代表mysql选择其作为被驱动表:

假设是一个SELECT的查询结果作为临时表给另一个SELECT,那就是两个id了:

但我们要注意的是,优化器可能会为我们重写MySQL语句,使其更高效,例如下面就由子查询变成连接了:

你可能以为这就结束了,但实际上,UNION是一种比较特殊的情况,他会把两个查询的结果拼起来去重,这期间就产生了一个对两表合一块的临时表的SELECT,id为NULL:

UNION ALL不同,他不需要去重,两个结果集拼起来就结束了,所以还是俩id:

select_type
从这个字段可以看出查询的属性

SIMPLE
没有UNION的都算,JOIN也算:

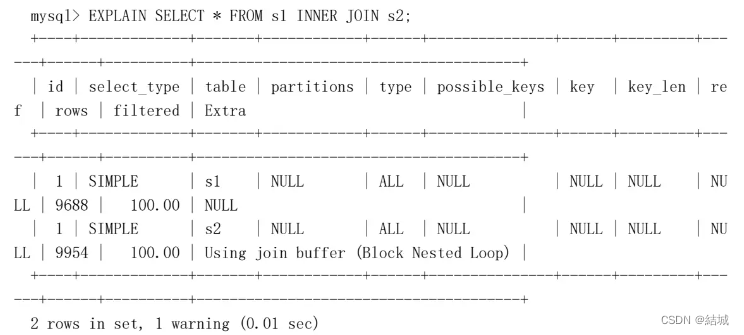
PRIMARY
UNION (ALL)查询中最左边的SELECT
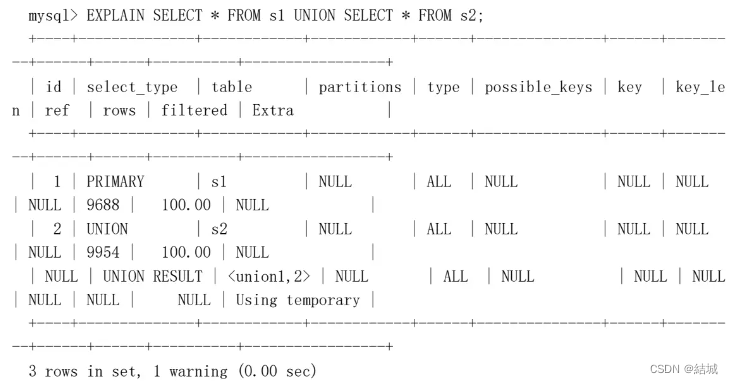
UNION
UNION (ALL)除了最左边的SELECT外都是
UNION RESULT
UNION的临时查询表
SUBQUERY
子查询,假设优化器发现没法JOIN,那就只能正常走子查询了:
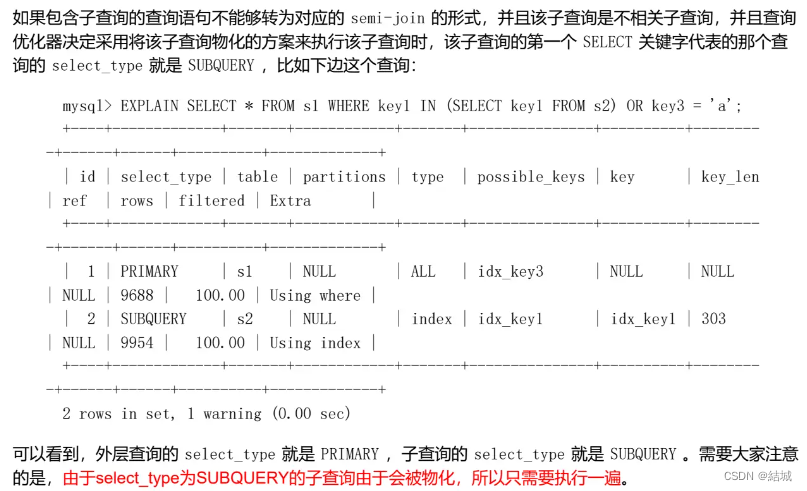
DEPENDENT SUBQUERY # DEPENDENT UNION
# DEPENDENT UNION
子查询里有UNION,那子查询里第一个是DEPENDENT SUBQUERY,其他的都是DEPENDENT UNION
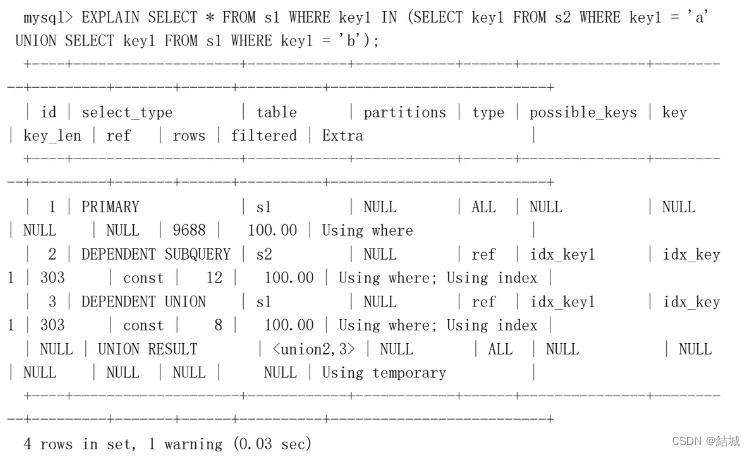
DERIVED

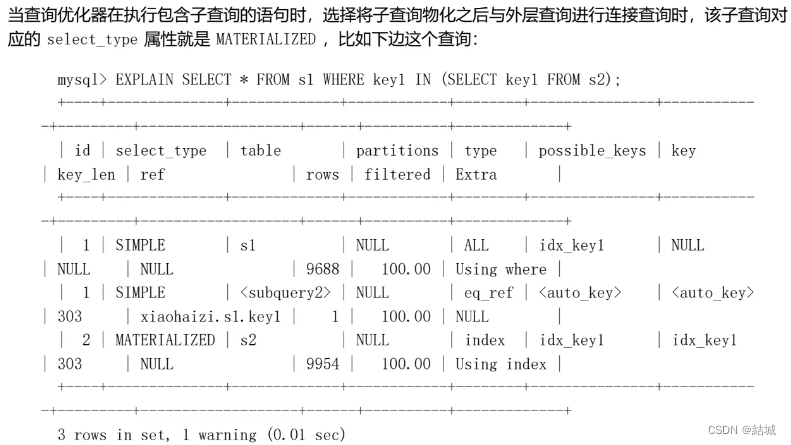
MATERIALIZED
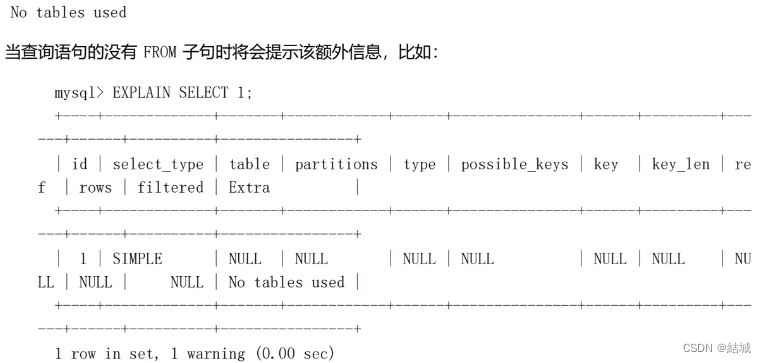
partitions
分区,一般都是NULL
type
代表MySQL对某个表的访问方式
type扫描方式由快到慢:system > const > eq_ref > ref > range > index > ALL
system
该表只有一行(相当于系统表),是const类型的特例
const
用主键或唯一二级索引进行等值查询的时候,就是const

eq_ref

ref
普通的二级索引与常量进行等值匹配,就是相比于eq_ref,可能在某个值上多查几个,假设上表s2.id是普通二级索引
ref_or_null
普通二级索引等值匹配还有可能遇到NULL,这是会就会出现的:

index_merge

unique_subquery
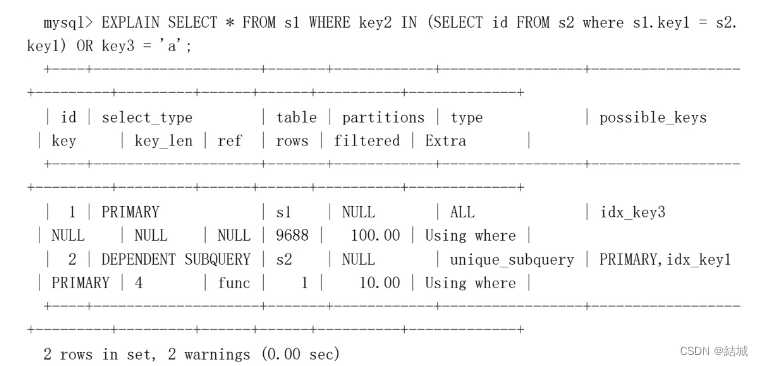
IN子查询被优化成了EXIST子查询,并且子查询使用到了主键进行等值匹配了,那么子查询就是unique_subquery:
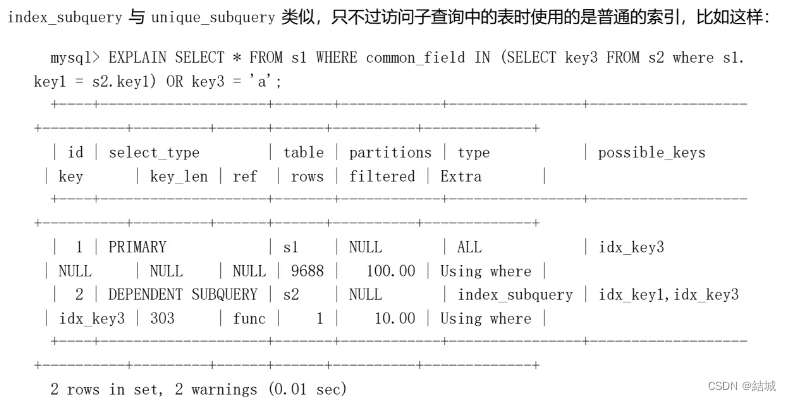
index_subquery
range
范围查询,注意,既可能是IN也可能是<以及>:


index

ALL
全表扫描

possible_keys和key
possible_keys代表查询时候可以用的索引有哪些,key代表实际上优化器选择的什么,不过索引多了也不是好的,一个是维护成本高;另一个是优化器会试探用什么索引好,这么多索引,它试探时间也会变长

假设type为index,也就是使用了索引覆盖,那么possible_keys是NULL,key是实际上的索引

Extra
顾名思义,是给你一些额外信息的。





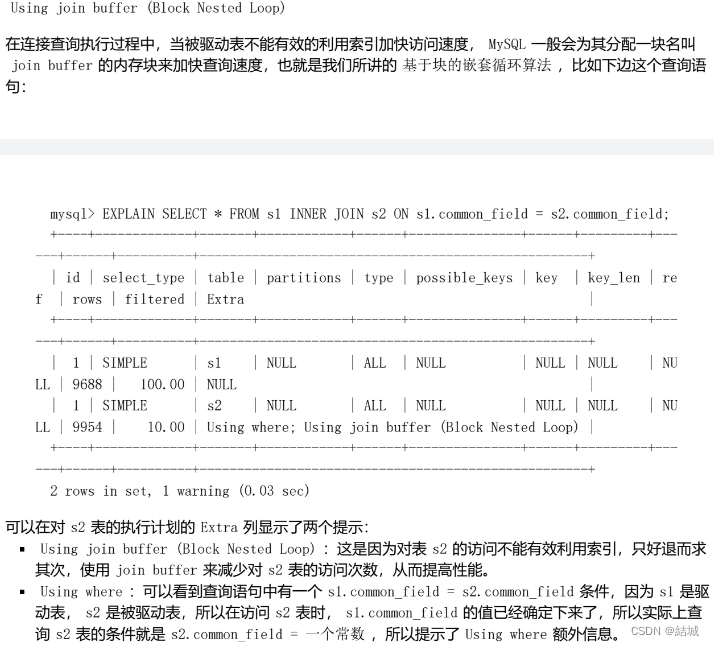
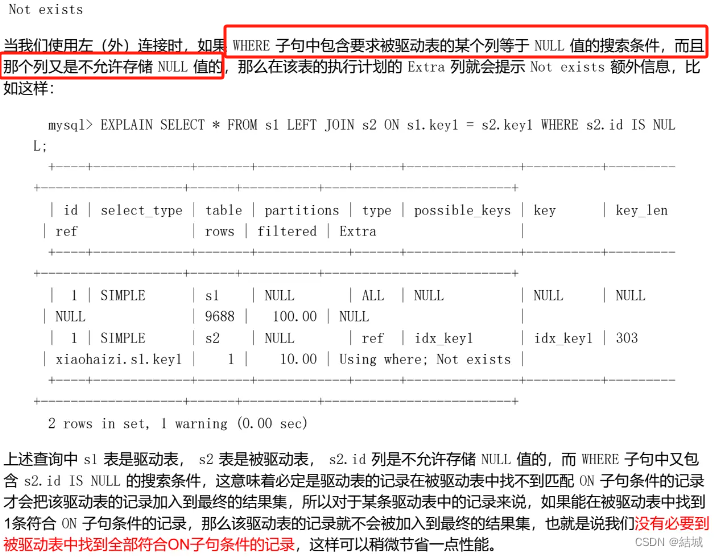



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!