MySQL索引
索引是对数据库表中一列或多列的值进行排序的一种结构。MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
索引就像图书馆的目录,能快速定位到你想查找的内容
索引分为
- 主键索引(primary key)
- 唯一索引(unique)
- 普通索引(index)
- 全文索引(fulltext)--解决中子文索引问题。
创建主键索引
方式一:
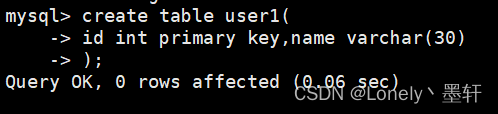
方式二:

方式三:

主键索引的特点:
- 一个表中,最多有一个主键索引,当然可以使符合主键
- 主键索引的效率高(主键不可重复)
- 创建主键索引的列,它的值不能为null,且不能重复
- 主键索引的列基本上是int
创建唯一索引
方式一:

方式二:

方式三:
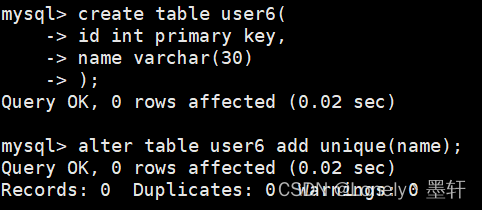
唯一索引的特点:
- 一个表中,可以有多个唯一索引
- 查询效率高
- 如果在某一列建立唯一索引,必须保证这列不能有重复数据
- 如果一个唯一索引上指定not null,等价于主键索引
普通索引的创建
方式一:
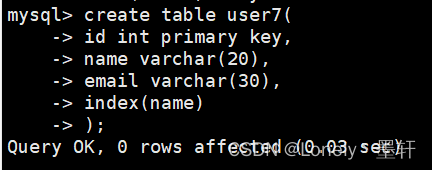
方式二:
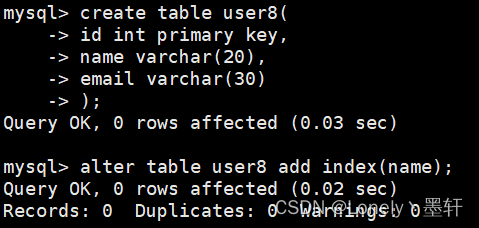
方式三:
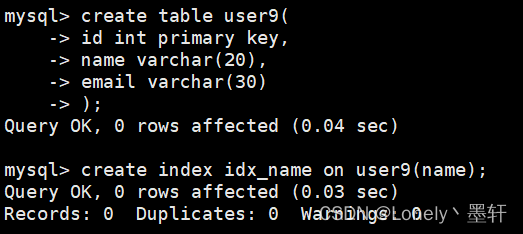
普通索引的特点:
- 一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
- 如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
全文索引的创建
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有 要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文。如果对中文进 行全文检索,可以使用sphinx的中文版(coreseek)。
SELECT * FROM articles
-> WHERE MATCH (查询的字段) AGAINST ('查询的数据');
查询索引
方式一:
show keys from 表名
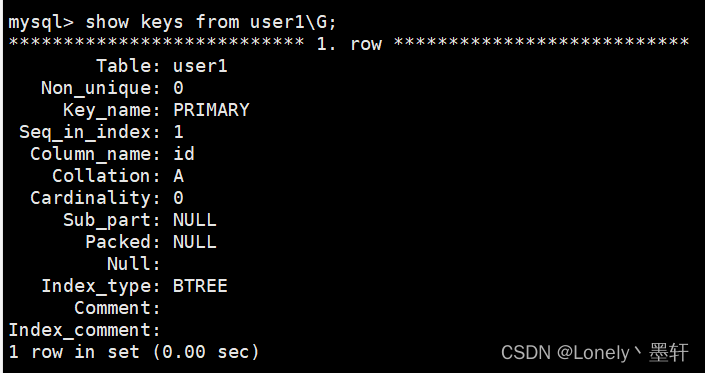
方式二:

方式三:

删除索引
方式一:
删除主键索引: alter table 表名 drop primary key;
方式二:
第二种方法-其他索引的删除: alter table 表名 drop index 索引名;
索引名就是show keys from 表名中的 Key_name 字段
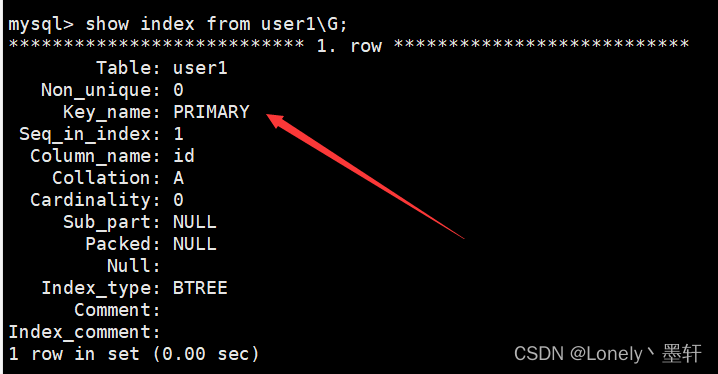
mysql> alter table user10 drop index idx_name;
方式三:
第三种方法方法: drop index 索引名 on 表名
mysql> drop index name on user8;
索引创建原则
- 比较频繁作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合作创建索引
- 不会出现在where子句中的字段不该创建索引
实际上,MySQL数据库的索引就是建立了一棵?B+ 树?(其它存储引擎不一定)
聚簇索引和非聚簇索引的区别
在 MySQL 的 InnoDB 引擎中,每个索引都会对应一颗 B+ 树,而聚簇索引和非聚簇索引最大的区别在于叶子节点存储的数据不同,聚簇索引叶子节点存储的是行数据,因此通过聚簇索引可以直接找到真正的行数据;而非聚簇索引叶子节点存储的是主键信息,所以使用非聚簇索引还需要回表查询,因此我们可以得出聚簇索引和非聚簇索引的区别主要有以下几个:
- 聚簇索引叶子节点存储的是行数据;而非聚簇索引叶子节点存储的是聚簇索引(通常是主键 ID)。
- 聚簇索引查询效率更高,而非聚簇索引需要进行回表查询,因此性能不如聚簇索引。
- 聚簇索引一般为主键索引,而主键一个表中只能有一个,因此聚簇索引一个表中也只能有一个,而非聚簇索引则没有数量上的限制。
InnoDB下 主键是聚簇索引
MyISAM下 主键不是聚簇索引
例
下面我们创建了一个学生表,做三种查询,来说明什么情况下是聚簇索引,什么情况下不是。
create table student (
id bigint,
no varchar(20) ,
name varchar(20) ,
address varchar(20) ,
PRIMARY KEY (`branch_id`) USING BTREE,
UNIQUE KEY `idx_no` (`no`) USING BTREE
)ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;第一种,直接根据主键查询获取所有字段数据,此时主键是聚簇索引,因为主键对应的索引叶子节点存储了id=1的所有字段的值。
select * from student where id = 1第二种,根据编号查询编号和名称,编号本身是一个唯一索引,但查询的列包含了学生编号和学生名称,当命中编号索引时,该索引的节点的数据存储的是主键ID,需要根据主键ID重新查询一次,所以这种查询下no不是聚簇索引
select no,name from student where no = 'test'第三种,我们根据编号查询编号(有人会问知道编号了还要查询?要,你可能需要验证该编号在数据库中是否存在),这种查询命中编号索引时,直接返回编号,因为所需要的数据就是该索引,不需要回表查询,这种场景下no是聚簇索引,是索引覆盖,因为直接找到test就返回数据,而不用根据test去查找其他数据。
select no from student where no = 'test'本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PCF8563转STM32 RTC避坑指南
- 只有一点儿详细的永恒之蓝Enternal_blue漏洞的开始使用
- 跨境电商优选邮箱:提升业务沟通与品牌形象的关键工具
- 从零开始的神经网络
- 如何查看一篇论文是期刊还是会议?
- 华为OD机试真题-堆内存申请-2023年OD统一考试(C卷)
- 鸿蒙应用开发学习:改进小鱼动画实现按键一直按下时控制小鱼移动和限制小鱼移出屏幕
- 详解git pull和git fetch的区别
- Nginx配置备忘
- 组播(多播)原理及代码