【ICCV2023】MMVP:基于运动矩阵的视频预测
?
目录
论文链接:https://openaccess.thecvf.com/content/ICCV2023/html/Zhong_MMVP_Motion-Matrix-Based_Video_Prediction_ICCV_2023_paper.html
代码:https://github.com/Kay1794/MMVP-motion-matrix-based-video-prediction
引用:Zhong Y, Liang L, Zharkov I, et al. MMVP: Motion-Matrix-based Video Prediction[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 4273-4283.

?
导读
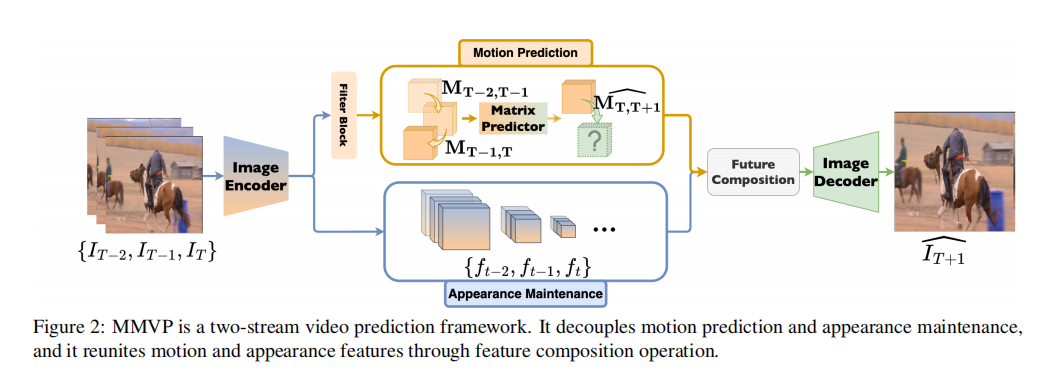
本文讨论了视频预测领域的一个核心挑战,即在图像帧中推测对象的未来运动同时保持它们在各帧之间外观的一致性。为了解决这一问题,作者引入了一种端到端可训练的两流视频预测框架,称为“Motion-Matrix-based Video Prediction”(MMVP)。
与以往的方法不同,以往的方法通常在相同的模块内处理运动预测和外观维护,MMVP通过构建外观无关的运动矩阵来解耦运动和外观信息。这些运动矩阵表示输入帧中每对特征块的时间相似性,它们是MMVP中运动预测模块的唯一输入。这种设计提高了视频预测的准确性和效率,并降低了模型大小。
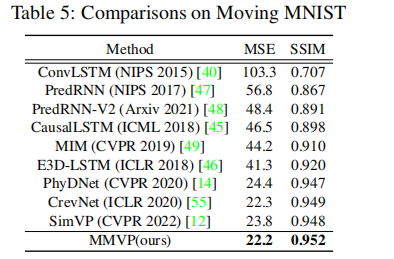
广泛的实验证明,MMVP在公共数据集上的表现优于最先进的方法,性能提升显著(在PSNR上提高了约1 dB,例如 UCF Sports数据集),而模型大小却显著减小(相当于84%或更小的模型尺寸)。
本文方法
?
给定一个视频序列
![]()
,其中 It 表示第t帧,通常是RGB格式。MMVP估计未来的T‘帧,即
![]()
?
与已知的帧集相比,我们将估计的帧集表示为:
![]()
?
该框架的训练仅由均方误差(MSE)损失来监督。MMVP 包括以下三个步骤:
-
空间特征提取
-
运动矩阵的构造和预测
-
未来帧的合成和解码
步骤1:空间特征提取
空间特征提取涉及到MMVP框架的两个组成部分:图像编码器和滤波器块。
MMVP中的图像编码器 Ω 分别对从输入数据序列到相应特征的每个 Ii 进行编码。滤波器块Θ随后处理 fi,滤波器块的任务是滤除 fi 的运动不相关特征,以供后续的运动矩阵构建使用:

?
我们使用一个具有残差的卷积网络(RRDBs)[44]来实现图像编码器,使用一个两层卷积网络来实现滤波器块。
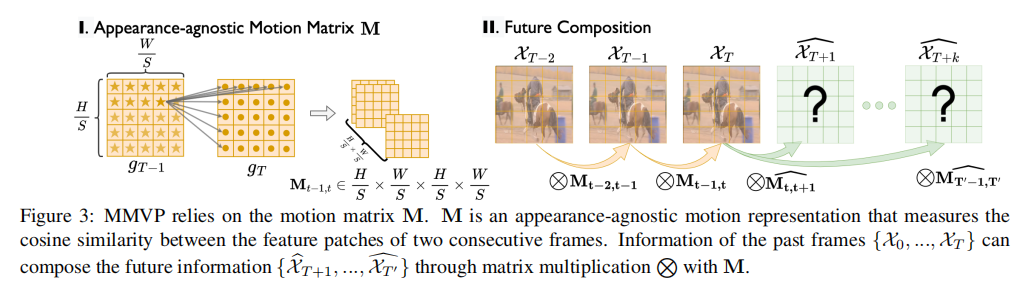
步骤2:运动矩阵的构造和预测
MMVP基于特征对
![]()
为每两个连续帧生成一组运动矩阵
![]()
,这是通过计算每对特征块的余弦相似度来构建的。矩阵
![]()
在位置
![]()
的元素表示为:
![]()
?
给定
![]()
,矩阵预测函数
![]()
预测未来的矩阵
![]()
?
不同于预测连续帧之间的运动矩阵,这里预测了从最后观察到的帧
![]()
到每个未来帧
![]()
, 的运动矩阵,如下所示:
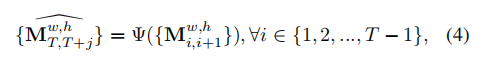
?
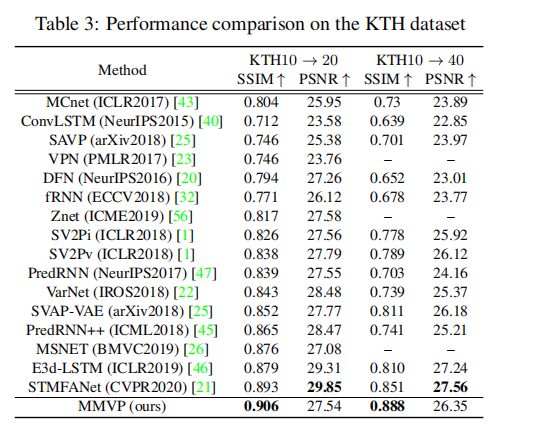
这个设计旨在减少特征合成过程中的累积误差,并通过表格 3 中的长期预测设置得到验证。
?
步骤3:未来帧的合成和解码
这一步骤通过使用观察到的信息和运动矩阵生成未来帧的信息。这一过程可以表示为:
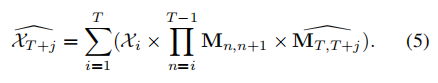
?
与仅使用最后观察到的帧的信息不同,我们使用所有观察到的信息进行未来合成,并通过重复矩阵乘法来减小较早帧的权重。公式中的 X 代表过去帧的观察信息。这些信息可以是图像编码器不同尺度的输出特征
![]()
,也可以是观察到的帧
![]()
?
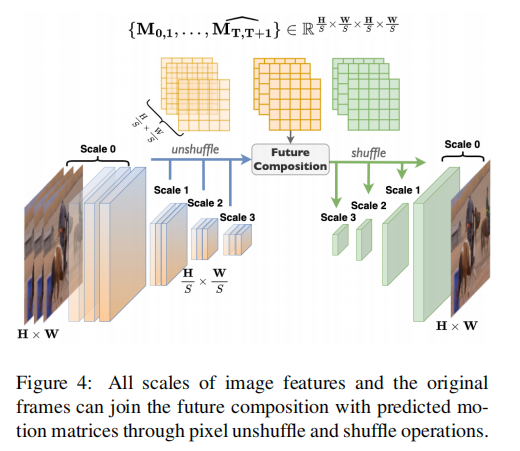
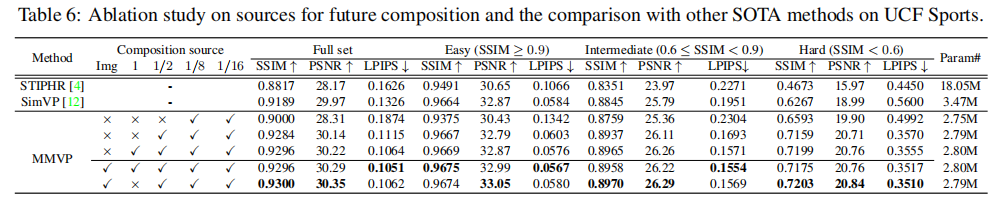
由于运动矩阵是从某个尺度的图像特征构建的,因此矩阵与某些特征之间可能存在不兼容性。为了实现运动矩阵与观察到的特征(任何尺度)或图像之间的矩阵乘法,作者借用了来自[39]的像素解缩。像素解缩操作将特征或图像重新整形成与运动矩阵相同的尺度,以进行矩阵乘法。然后,将矩阵乘法的结果重新整形为特征或图像的原始尺度。如图4,这整个过程涉及很少的信息损失。根据表格 6 的研究,我们可以看出多尺度特征合成设计通常在系统中使用更多尺度的特征时能够获得更好的性能。
解码过程采用了UNet的解码器结构,结合了RRDB块来实现MMVP的图像解码器。这一设计允许来自所有尺度的图像特征以及原始图像的合成特征对最终的输出做出贡献。在框架训练中,使用均方误差(MSE)损失来进行监督。
?
实验
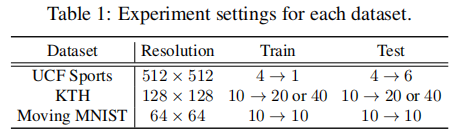
数据集设置:
?
实验结果
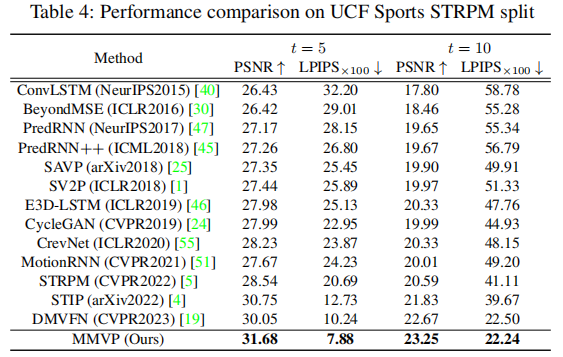
与SOTA的比较
?
?
?
预测的运动矩阵可视化结果:

?
UCF Sports 数据集的定性结果:

?
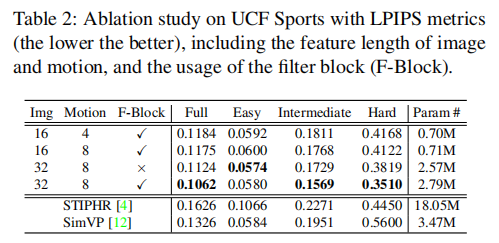
消融实验
?
?
结论
本文提出的基于运动矩阵的视频预测框架(MMVP)是一个端到端可训练的双流管道。MMVP使用运动矩阵来表示与外观无关的运动模式。作为MMVP中运动预测模块的唯一输入,运动矩阵描述了特征块之间的多对多关系,无需训练额外的模块;通过矩阵乘法直观地组合了未来特征与多尺度图像特征,有助于运动预测更加集中,有效地减少了外观上的信息损失。通过广泛的实验证明,MMVP在模型大小和性能方面均优于现有的最先进方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue保姆级教程----深入了解 Vue3路由守卫
- SpringBoot整合Activiti7——终止结束事件(十三)
- 获取当前进程RAM瞬时占用[windows][linux][c++]
- Mac无法访问GitHub
- Python——机器学习分类模型实例:从数据预处理到模型训练全流程
- 【分布式技术专题】「授权认证体系」深度解析OAuth2.0协议的原理和流程框架实现指南(授权流程和模式)
- Vue项目Nginx代理F5刷新出现404问题解决
- java-sec-code中的文件上传
- 鸿蒙不想成为第二个Windows Phone
- 代码随想录算法训练营29期|day27 任务以及具体安排