突破界限:首个国产DeepSeek MoE的高效表现
前言
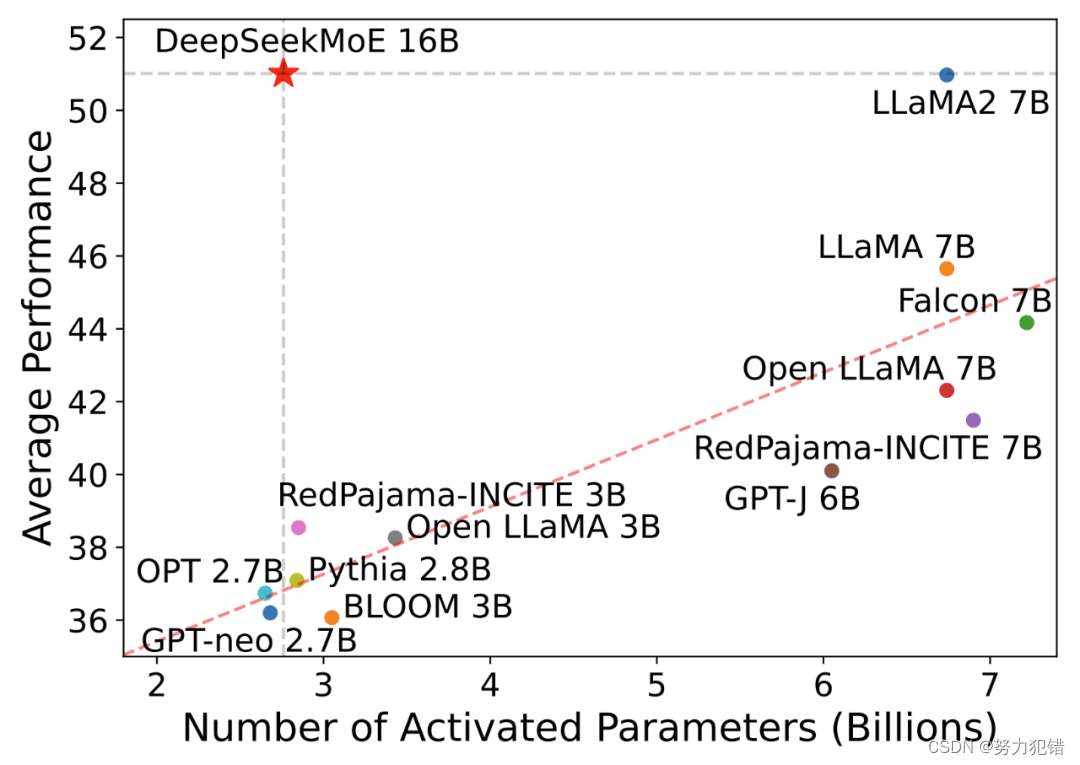
在人工智能技术的快速发展过程中,国产首个开源MoE(Mixture of Experts)大模型——DeepSeek MoE的推出,不仅标志着中国在全球AI领域的重大突破,而且在计算效率和模型性能上展现了显著的优势。这款160亿参数的模型在保持与国际知名Llama 2-7B模型相媲美的性能的同时,实现了显著的计算效率提升,计算量仅为对手的40%。
模型特性与技术创新
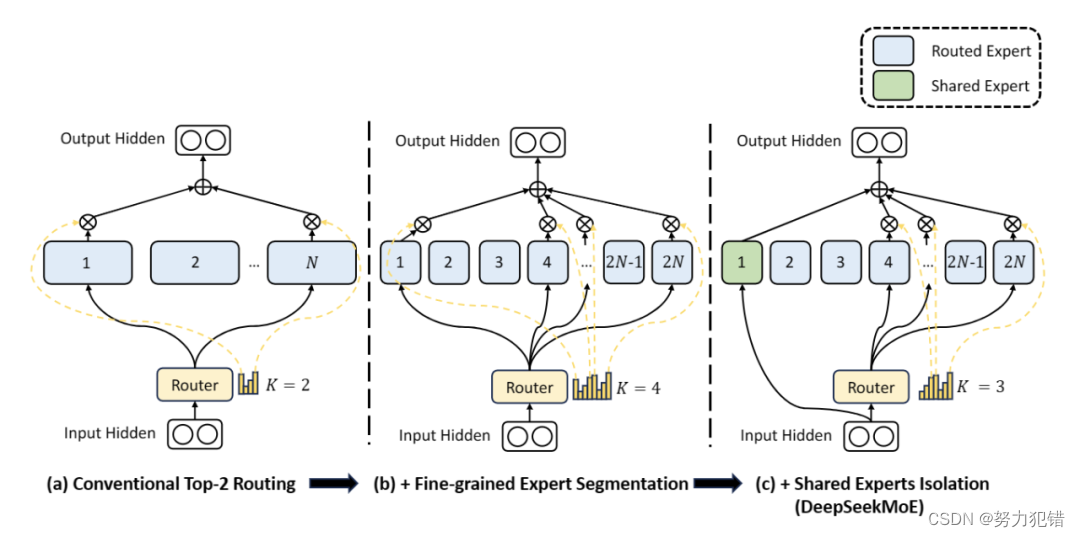
DeepSeek MoE模型的核心优势在于其高效的计算性能和优秀的模型表现。深度求索团队在传统MoE技术基础上进行了创新,提出了更细粒度的专家划分策略和引入共享专家的概念,从而大幅提高了计算效率和模型性能。
-
Huggingface模型下载:https://huggingface.co/deepseek-ai/deepseek-moe-16b-chat
-
AI快站模型免费加速下载:https://aifasthub.com/models/deepseek-ai

细粒度专家划分
与传统MoE模型相比,DeepSeek MoE采用了更细粒度的专家划分策略。在保证激活参数量不变的情况下,从更多的专家中选择激活更多的专家,这种策略提供了更大的灵活性和适应性,从而提高了模型在不同任务上的准确性和知识获取的针对性。
共享专家引入
DeepSeek MoE创新性地引入了“共享专家”概念。这些共享专家对所有输入的token激活,不受路由模块的影响,有助于将共享和通用的知识集中到公共参数中,减少专家之间的参数冗余,提高了模型的参数效率。
性能评测
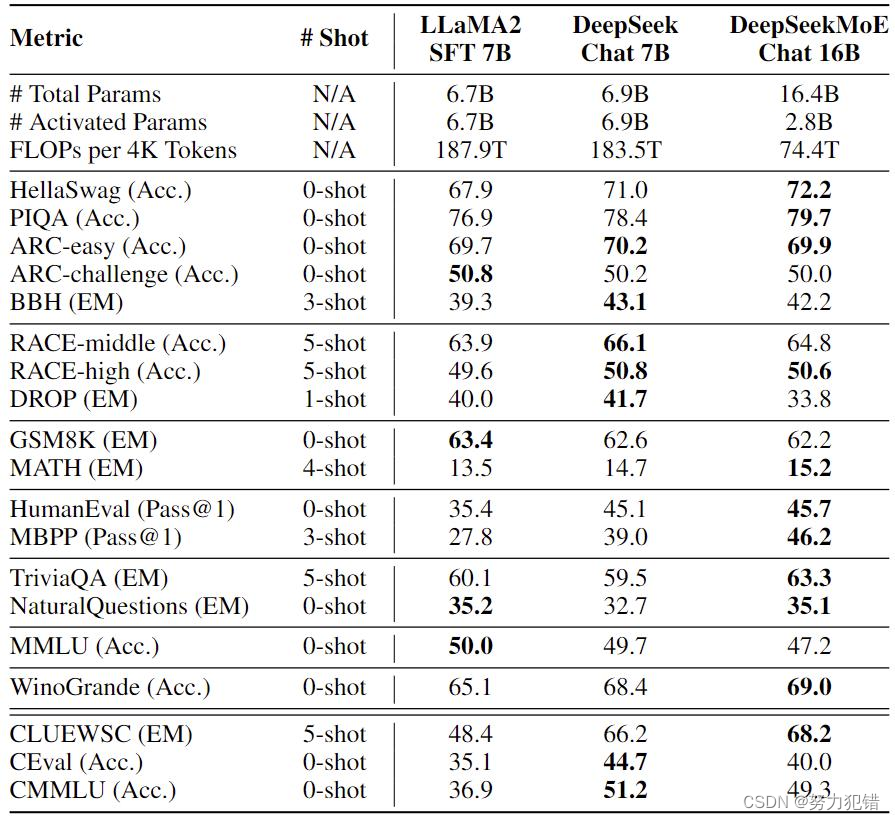
DeepSeek MoE在性能评测方面表现出色。与其他模型相比,其计算量显著降低,同时在多个数据集上的表现与7B级别密集模型相当,甚至在数学和代码等特定任务上展现出明显优势。
计算量对比
DeepSeek MoE的计算量仅为74.4TFLOPs,相比于其他密集模型超过180TFLOPs的计算量,显著降低了60%。这一显著的计算效率提升为AI领域提供了新的可能性,特别是在资源受限的应用场景中。
数据集表现
DeepSeek MoE在多个数据集上的表现证明了其在多方面任务上的能力。尤其在数学和代码等特定领域,DeepSeek MoE展现出了相较于Llama 2-7B的明显优势。此外,与自家的7B密集模型相比,DeepSeek MoE在19个数据集上的表现各有千秋,但整体表现接近,体现了其高效性能。
应用前景
DeepSeek MoE的开源对国内外AI研究和开发具有重大意义。它不仅为AI研究提供了一个高效的大模型架构,而且为自然语言处理、机器学习和计算机视觉等领域的研究提供了新的实验平台。
AI研究和开发
在自然语言处理、机器学习和计算机视觉等领域,DeepSeek MoE作为一个高效且功能强大的模型,提供了新的研究工具。它的高计算效率和出色的性能使得在资源受限的研究环境中也能进行高级的AI研究和应用开发。
产业应用
DeepSeek MoE的高效性能和低计算需求使其在多个应用场景中具有广阔前景。从智能助手、自动编程到数据分析,DeepSeek MoE的应用潜力巨大。对中英文的支持也使其在国内外市场均具有应用潜力。
结论
DeepSeek MoE的推出是国产AI技术发展中的一个重要里程碑,也代表着MoE技术在全球大模型发展中的重要进步。它在保持高性能的同时显著降低了计算需求,展现了国产技术的创新实力和全球竞争力。随着深度求索团队对更大规模模型的持续研发,DeepSeek MoE有望继续在AI领域引领技术潮流,推动整个行业的发展。
模型下载
Huggingface模型下载
https://huggingface.co/deepseek-ai/deepseek-moe-16b-chat
AI快站模型免费加速下载
https://aifasthub.com/models/deepseek-ai
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 企业微信开发:本地运行一个页面应用
- 写点东西《理解 JavaScript 中的异步迭代器》
- php 文件移动、拷贝和删除
- 数字孪生项目中的导航片及寻路实现算法的探索
- 超高质量的 8个免费设计素材网站,设计师必备。
- 【2024系统架构设计】 系统架构设计师第二版-层次式架构设计理论与实践
- 第十四章!
- 开发做前端好还是后端好
- 一文了解:化妆品FDA注册 食品FDA注册 医疗器械FDA注册 药品FDA注册
- 喜讯| 触想智能获2023年度【触控一体机十佳品牌】荣誉