【Linux系统编程二十五】:线程概念(Linux中的轻量级进程)
【Linux系统编程二十五】:线程概念(Linux中的轻量级进程)
一.线程的概念
1.地址空间是资源窗口
当我们以一个进程角度,看待所能看到的的资源目前是通过地址空间来看到,所以地址空间就是进程的资源窗口。
你的进程想找到代码,比如初始化数据,想使用全局变量,想申请内存,想加载动态库,临时变量,想要使用命令和参数环境变量,想访问操作系统,你会发现你的进程要访问的话,就必须得通过地址空间加页表的方案在物理内存当中去找到你所对应的代码数据。
换句话说,我们一个进程能看到的资源,我们是通过地址空间来看的。所以在我看来我们的地址空间就是进程的资源窗口。
二.线程初步理解
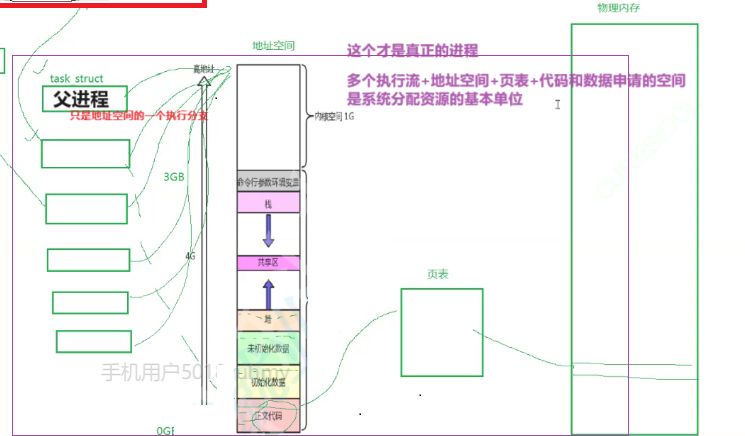
如果我今天在linux当中,我创建一个进程。操作系统会给这个进程分配PCB,地址空间,页表,物理内存等。
然后我再创建一个"子进程",只不过这个"子进程"不再给创建新的地址空间,不再创建新的页表,不再给他在物理内存当中重新开辟一个属于进程的所有的资源。
它只要创建PCB。并且它的PCB指向父进程的地址空间,父进程会把这个正文部分的代码呢分一部分来给对应的这个"子进程",来让这个"子进程"执行。
既然能创建一个"子进程",那么就能创建多个,那么创建的每一个我只创建PCB,这个PCB呢都和我们对应的父进程呢共享地址空间。
共享地址空间之后呢,我们把父进程所对应的地址空间当中,比如正文部分分成若干份,然后给这里每一个每一个我们对应的这个我们的子进程呢。
好,所以呢我们就可以发现其中新创建的这些进程,
他们对这个地质空间的内容呢可以进行一定程度上的分享。
我把对应的这种形式的进程起个名字,我们把它叫做线程!
在操作系统中是这样定义它的:是进程的执行分支(它是进程内的一个执行流),比进程的执行粒度要细。
1.进程执行分支(内部运行)
而且呢我们对应的整个所有的"进程"呢,它是在我们这个所谓的父进程它的地址空间内运行的。
线程是在进程内部运行的。在linux中线程在进程内部运行。在我们linux的视角看来,我们认为线程是在进程的地址空间内运行。
是它为什么要在地址空间内运行呢?
1.因为任何执行流要执行必须得有资源!从软件上讲。没有代码和数据,你这个执行流就跑不起来。往硬件上谈,不持有CPU资源,访问i o资源,这个执行流就跑不起来。所以你要执行,你就得有资源。我们任何执行流它都要有自己对应的资源。
2.而进程地址空间它就是属于进程的资源。你所要的资源就在这里,所以我们对应的每一个执行流要进行运行。
那么他们享有资源的方式,要么就是把别人的资源整体给自己拷一份,就有了我们曾经的子进程。
要么就是大家共享,我们用一人用一部分资源,这就是我们今天的线程。

好,同学们,所以呢任何执行流程执行都得需要资源。
那么进城地址空间是进程的资源窗口,所以线程在进城的地质空间内运行很合理!也必须在进程的地址空间里执行,因为它自己没有地址空间。
如果它自己有了地址空间,那不就是真正的子进程了吗。
所以说线程在进程内部运行的本质是其实是在进程的地址空间内运行。
它呢是我们要执行的这么多代码当中的一部分,所以我们就称之为它是进程内的一个执行分支。
2.执行粒度更细
在linux当中呢线程执行的力度要比进程更细,因为
你此时所拥有的资源是和其他执行流共享的啊,所以当然会细啊。
以前我的主进程执行这一大坨代码,今天你只需要执行一部分代码。其余的都共享给线程执行了。
所以它的执行的粒度比这个进程的粒度呢肯定要更细一些。
3.重构进程概念:系统资源分配的基本实体
最开始的那个我们传说意义上的父进程,但今天看来,这个父进程它也只是我们这个地址空间内部的一个执行分支。你用一个执行分支能代表整个进程吗?
当然不可以了!那么到底什么叫进程呢?
以前我们对进程的理解就是各种内核数据结构+代码和数据。
而真正的进程:整个的这些创建执行流都叫做进程执行流。地址空间叫做进程所占有的资源。页表和进程在物理内存当中所占据的一点点物理内存,我们把这一整套我们称之为这才是进程。

也就是说那么一大堆的执行流,地址空间和页表,还有该进程在物理内存当中保存代码和数据所申请占用的内存空间整体被称为进程。
怎么理解呢?
从内核上看我们的进程是承担系统分配资源的基本实体,也就是在操作系统内我们分配资源的方式是以进程为单位来进行分配的。记住进程才是分配资源的实体,而线程不是。
当你创建一个进程时,我们给你创建对应的执行流,创建地址空间,创建列表。然后物理内存的开辟空间构建映射,给你把所有的资源全部都给你创建好,这就是进程是承担分配系统资源的基本实体。
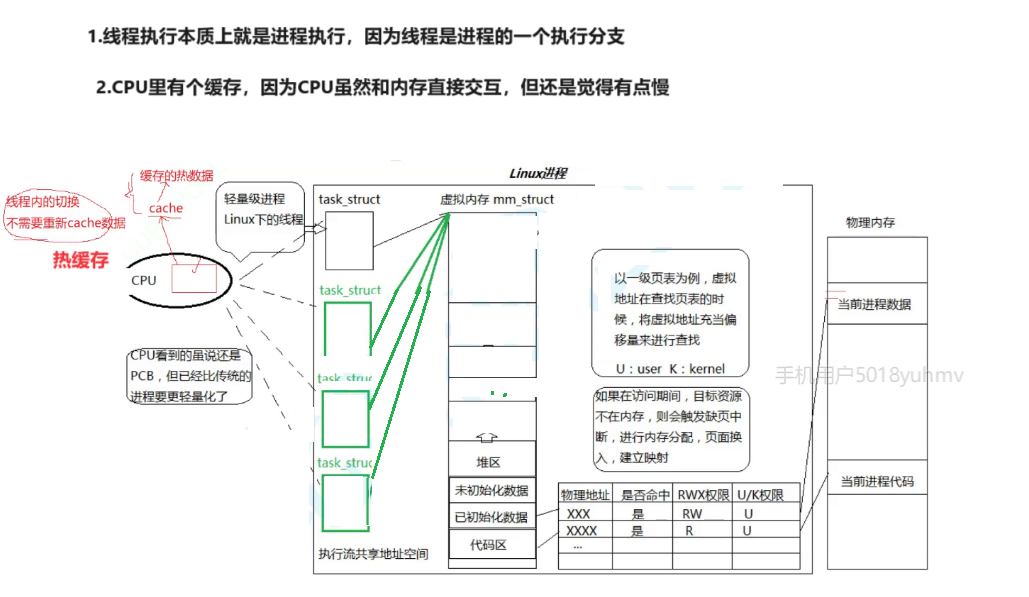
在我看来,那么你未来创建一个我们对应的新的线程,就是在地址空间内创建一个新的task_struct对应的结构体。这个结构的对象也需要资源,只不过是共享进程的资源,那么这个task_struct就是属于进程的内部。
所以我们的进程它是属于承担分配整个系统资源的基本实体。
以前我们创建进程时,创建什么内核数据结构,什么PCB地,地址空间、页表,还有申请资源。
这不就是操作系统以进程为单位在给你分配资源吗?
只不过你这个对应的所有的资源里只有一个执行流啊,只有一个PCB。
而今天我们学到的进程其实里面包含了很多执行流,跟以前的是没有区别的,只不过是进程的一种特殊情况。
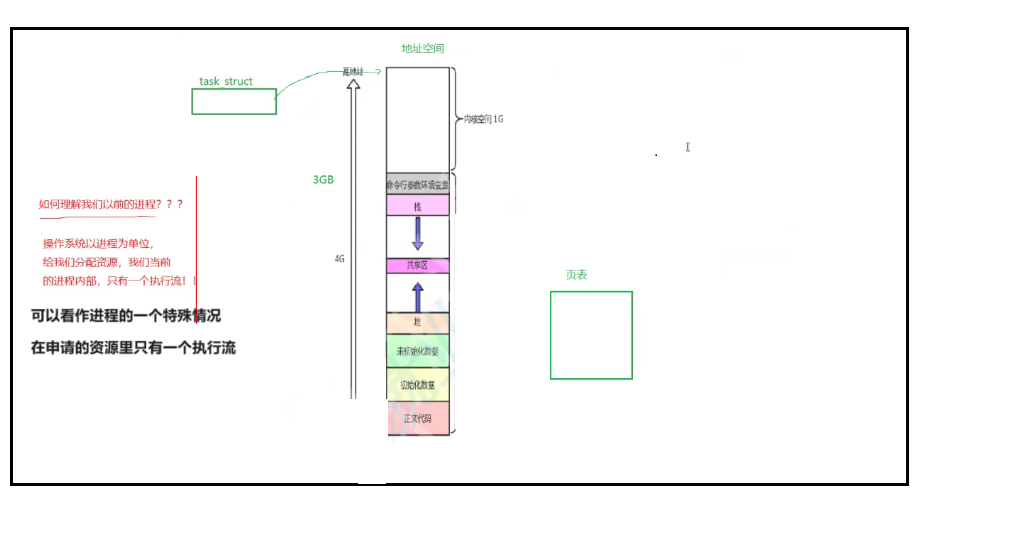
我们以前讲的进程这个概念,其实就相当于是只有一个执行流啊,他自己在所所申请的资源当中有一个执行流啊。
4.重构线程概念:系统调度的基本单位
进程的内核数据结构都是属于操作系统分配的资源,地址、空间列表、代码和数据都是要占据物理内存,都是要占资源的。执行流是资源吗?进程内部的一个一个的PCB啊,这玩意儿它是资源吗?
不要认为一个进程它能够被调度,它就是进程的所有。
它只是进程内部的一个我们对应的执行流资源被c p u执行了。
一个进程还有自己的地址空间,还有页表,还有自己的代码数据在物理内存当中占用的空间,所以我们所对应的进程,其实它呢是承担分配系统资源的基本实体,而线程只是我们进程概念当中的基本调度单元。
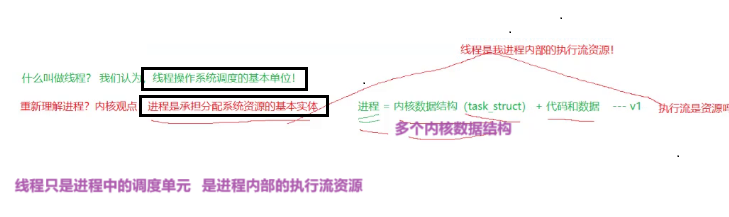
所以进程和线程之间的关系是进程内部是包含线程的,为什么?
因为进程是承担分配系统资源的基本实体,而线程是我进程内部的执行流资源。
正因为我们进程是承担分配系统资源的基本实体。
我们才可以认为线程是我进程内部的执行流资源。
所以创建一个进程,操作系统要给我们当前进程分配很多很多的资源,分配完资源之后,如果你接下来要创建一个线程,会在我进程内部给你创建一个PCB,然后把我进程的资源掰一块,给你这个线程,那么你去调度吧,你去执行吧,这就叫做线程。
5.Linux中线程的实现
一个进程里面应该有多个线程,它对应的比率一定是一比n的。线程可不是一创建就退出,一创建就完成,创建才是开始。操作系统要能够调度这个线程啊,要运行这个线程,切换这个线程。
所以同学们线程又多比进程还多,你还要来对他做调度。
操作系统要不要管理线程?
所以操作系统必须得为线程创建专门描述该线程的数据结构。所以windows操作系统它就它就这么干了。
他就给线程创建对应的TCB,然后再把进程和线程之间还有关联起来。很复杂。
实你的进程和线程啊,其实那么我们已经描述进程用了test start,它也要被调度,有状态,有优先级,要有自己的上下文要被切换。
好,那我为什么还要再为一个叫做线程单独创建数据结构呢?那我已经有了一套这样的策略,只不过你接下来现场你执行的时候力度比较细一些罢了。
你执行的代码少了一点,你访问的资源少一点。所以linux的设计者直接复用。
直接用进程的内核数据结构来模拟线程。
linux设计者呢他此时就直接不再重新设计p c b,而用我们进程的数据结构和调度算法来模拟线程。
直接我们对内核的数据库进行复用,我们就能模拟实现出来你对应的线程了。

5.CPU视角:轻量级进程
在CPU调度的过程,它是不知道这个调度的这个task struct或者PCB是进程,还是线程的。
因为它根本上不需要知道,调度的是进程还是线程。
CPU只有执行流的概念,只有调度执行流的概念。
而它一定是小于等于进程的。执行流是大于等于线程的,小于等于进程的。
c p u不关心进程还是线程。只要有执行流,让执行流去执行就可以了。说白了我要访问代码,你就得给我代码,我要读取你的数据,你就得给我数据。 反正不管怎么,你能够让我找到代码和数据去执行就可以了。
linux当中内部的这个执行流,它的执行流是大于等于线程的,小于等于进程的。极端情况下,就是我们对应的执行流呢,那么有线程等于执行流,有执行流等于进程。
我们对应的一个c p u内部呢,它有很多很多的执行流,我们一般把linux当中的执行流,我们叫做轻量级进程。

它为什么叫轻量级呢?
那是因为你的执行流小于等于这个进程,你执行的粒度是小于进程的,所以它叫做轻量级进程。
那么往后我们可以认为linux的系统里。没有进程,没有线程或者不叫进程不叫线程,我们统一都叫做叫做轻量级进程。
三.页表映射实现
我们现在知道了进程是承担分配系统资源的基本实体,而线程是共享进程的资源的,也就是进程会将资源分配给一个一个的执行流。
我该如何理解现阶段基于地址空间的那么多个执行流,如何分配资源的情况?
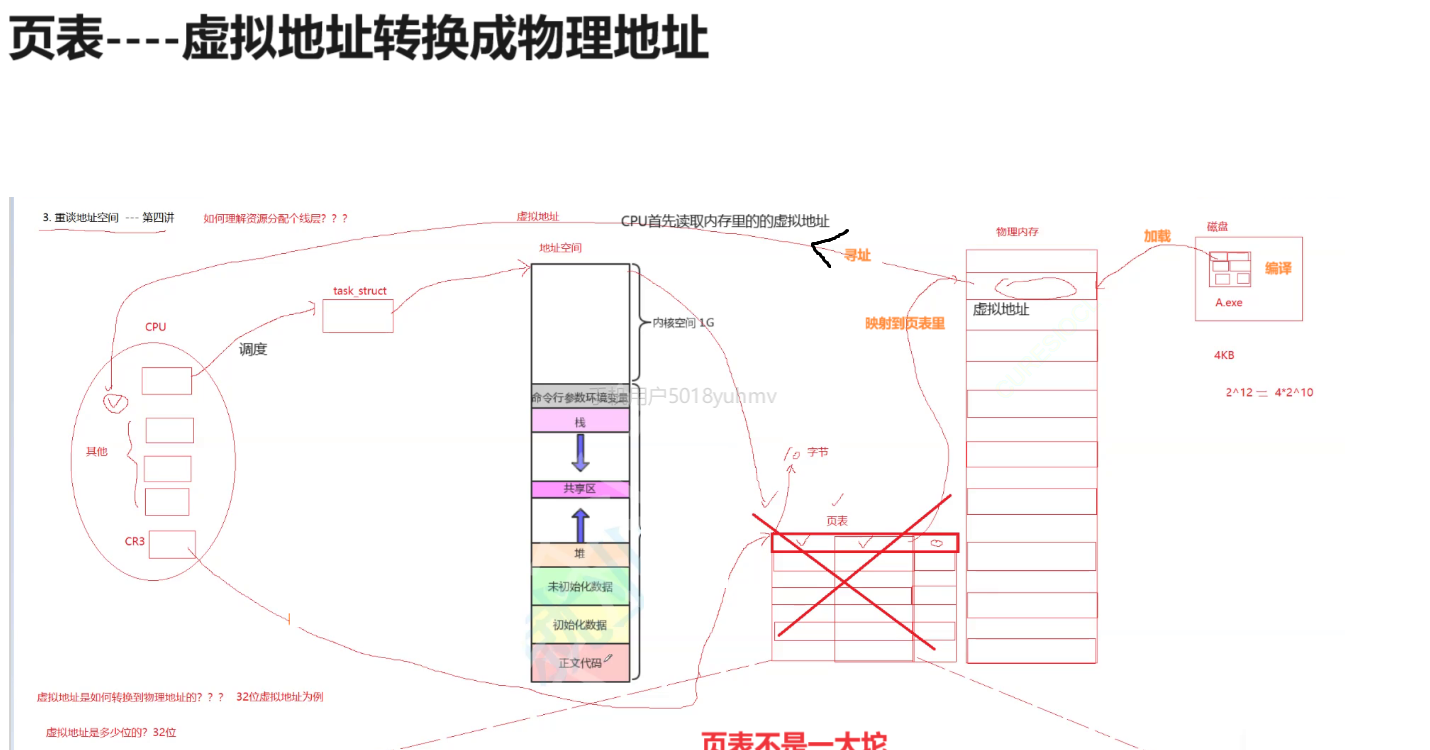
页表什么样子的呢?
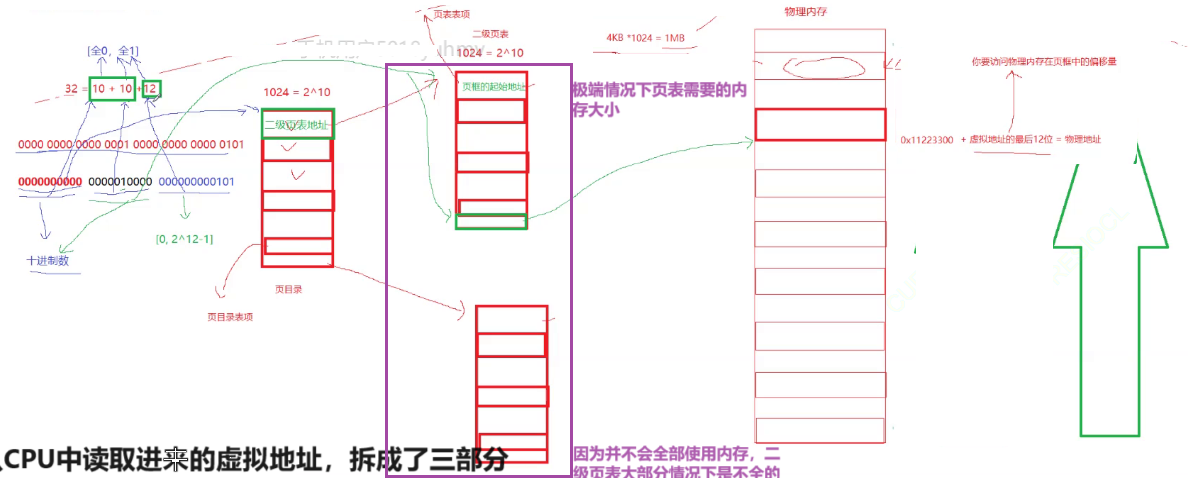
它呢是被拆成我们对应的,我们称之为叫做三十二位,被拆成两级的。
1.一级页表它有1024个位置,每个位置里存放就是二级页表的地址。一级页表其实叫做页目录。
2.二级页表里面也是有1024个位置。二级页表里面存放的是页框的起始地址。
1.页目录
你将来从c p u内读到的某一个寻址里面有个虚拟地址。这个虚拟地址它一共有32位。
将这个32个比特位分成3部分,前10个比特位为第一部分,中间10个比特位为第二部分,最后12个比特位为第三部分。
它的虚拟地址是被拆成这三个部分,所以CPU将来是按照这个的方式去识别这个虚拟地址的。
CPU将来会用虚拟地址的前10个比特位进行查找对应的第一级页表。
因为第一级列表有1024个条目,也就是2^10。是10个二进制位的最大值,所以可以涵盖所有的前10个比特位能构成的数字。第一级列表转化成十进制数就充当了该列表的,我们可以称之为数组的下标。
我们不需要保存虚拟地址,前十位直接转成十进制数。然后就作为一级页表,它对应的下标。一级页表里面呢,它存放的是它二级页表的地址。也就是前10位就能定位到二级页表的地址,找到了这个二级列表,然后呢?
2.二级页表
那么拿着第二个部分的十个比特位把它转化成十进制数,然后再去二级列表当中去索引它的下标。
因为二级页表呢也是1024的条目,所以你一共十个数字取值范围就是0到1023,所以转成十进制数。就相当于二级页表的下标了。
二级页表里存放的是页框的起始地址。也就是物理内存的地址,是按照4kb的形式存储的。
最终我们其实只需要通过虚拟地址的前二十位查一级,查二级,我们其实就已经找到了我们对应的页框了。
3.页框偏移量
而最后一部分是由12个比特位构成。最大值就是4kb,也就是一个页框的大小,最小值为0.所以它是用来定位一个页框里的具体的物理地址的。
因为前20位比特位帮我们定位到页框的起始地址了。那么页框的起始地址加上[0,4kb]大小,不就定位到该页框内部具体的物理地址了嘛。
最后的十二位,它本质是什么呢?叫做我们对应的在一个指定页框当中,那么你所要访问的物理内存的在页框里的偏移量。
前10个比特位是索引页目录,中间10个比特位是索引我们的页表二级页表。定位到页框,找到页框之后再加上我们最后12个比特位,在页框内进行偏移量索引到具体的物理地址。
【总结】:
原来虚拟到物理地址之间的转化,它是通过把我们对应CPU内读进来的虚拟地址拆成了10,10,12比特位这样形式。
然后呢我们对应的先拿10比特位查页目录,再拿我们中间10比特位查我们的这里的二级页表。定位找到页框啊,再根据最后12个比特位找到具体一个我们对应的物理内存。

【注意】:
c p u内部呢指向的页表就直接指向的是页目录。
一般任何一个进程,它的二级页表可以残缺,甚至可以没有,但必须得有页目录。
页目录里面的内容可以你可以没有,但是呢这个页目录它必须得存在,就相当于对任何一个进程来讲,它创建出来页目录必须得先有。
然后呢我们后面随着你的运行过程,这个页表呢会被填充缺页中断。那么会被填充的越来越完善。
4.访问变量的本质
可能有人会迷惑,这里只是定位到了物理内存的某一个以字节为单位的某一个地址。我们要访问的变量在内存里不一定就申请一个字节啊,就是我要访问的时候,我不是访问只访一个字节啊。我是访问可能连续的四个、八个字节。
那该如何访问到这个变量所有的内存呢?

就是这个变量开辟开辟了众多字节当中的最小的起始地址。
那么所以其实我们计算机硬件只要能帮我找到你这个变量的起始地址,c p u天然就能够识别出来。
你要识别多少类型啊,你要识别几个都行。
所以我们就能知道找到起始地址,我们就根据类型我们就能找到连续读取多个字节,我们就能把数据读上来了。
所以在我看来任何变量只有一个地址,就是它的起始地址。这就是为什么我们所有的变量它都有类型。
这就是为什么我们叫做访问任何变量都叫做起始地址加类型。
起始地址加类型啊,那么它的本质是什么呢?
就是起始地址加偏移量
四.地址空间与线程的关系
1.资源分配的本质
谈一谈如何理解资源分配。
上面所讲的这个线程,它所对应的所有的资源分配,全部都是通过地址空间来的。你所有的代码和数据都是通过地址空间加页表然后映射过来的。
所以呢我们线程分配资源本质就是把整个地址空间划分一部分。那么你就是你用你的,我用我的。
好,那么比如说我把代码呢分成几部分啊,那么其中呢我们其中有一部分呢就直接给我们对应的线程,有一部分给另一个线程。
好,那么凡是不划分的,比如说堆区栈区啊,或者全局数据区。那么对于所有线程全部都是共享的。

所以对我们来讲,线程的资源分配本质就是地址空间范围的分配。
因为所有的线程也共同属于同一个进程。使用同样的一个页表映射查同样的内存。
换句话说,你把哪一部分资源想给这个线程,其实就是把它对应的代码范围给他就可以。
所以我们如何理解现成的资源分配呢?
本质就是分配代码和数据。让每一个线程执行不同的代码。
2.如何实现资源分配
地址空间里面,大部分资源全都是共享的。分配给线程不同的资源,就是分配不同的地址给线程。
因为每一个函数的地址绝对都是不一样的。
那么所以我们只需要把一个函数交给一个线程运行。
它天然就是在代码层面上,它已经天然做好了,在地理空间划分上把它分开了。每个线程执行不同的函数,就是在分配不同的代码。
五.线程PK进程:轻量化
线程要比进程更轻量化。为什么呢?
1.创建释放轻量化
创建和释放更轻量化,
因为你创建线程的时候,只要创建PCB就行了。
创建进程,你需要创建PCB,地址空间,页表、加载内存构建映射关系全部都要做啊,包括你的信号三张表和我们对应的文件描述图表这样的结构你全都要有。
释放呢,线程只要把PCB干掉就行了。什么资源你什么都不用管,只有最后一个PCB被干掉时候,我们的资源才会被释放。
好,所以创建和释放更加轻量化,这个好理解。
2.切换轻量化
线程整个生命周期,它都比进程要轻量化。
,以前你要执行一大批代码,现在你只需要执行一小块代码。
所以呢代码变少了,这是第一第二呢,更重要的是切换啊。
线程在调度的时候,硬件上下文肯定会保存,但是线程在切换的时候,页表用切换吗?答案是不需要。页表的空间都不需要切换,所以它切换的效率就会更高。
那么在CPU当中。除了有寄存器。CPU还会以进程为载体,帮我们缓存大量的高频数据。
线程的执行。本质就是进程在执行。线程是进程的一个执行分支。
c p u这个硬件中是有对应的catch缓存的,它觉得和这个内存在进行数据交互时。数据还是有点太慢了。
所以他会把你当前,比如你在访问第十行代码时,他会把第十行到第五十行第一百行的代码全部给你全部录入到内存里或者数据啊,那么这就叫做catch。
那么catch呢它就是也是根据局部性原理,在我们的c p u和这个c p寄存器和内存之间,在c p u内部集成了一段我们的空间这空间虽然相比较内存不大,但是相比较cpu它很大,所以它有catch啊,那么所以你的进程在调度的时候,它应该越跑越快越跑越快,为什么?
因为它的命中率会越来越高,那么这部分catch我们称之为进程运行时的热数据啊和缓存的热数据。
好,那么热数据什么意思呢?相当于这就是数据高频被访问。
如果你在调度的时候,那么我们就分为线程啊,以一个进程内的多个线程,那么在c p u上去进行调度。
第一,c p u在切换的时候,它来来回回是切换的是一个进程内的多个线程。那么它在切换的时候呢,此时上下文虽然一直在变化,但是缓存里的数据一直不变。
好,但是如果你整个进程啊,那么上面所有的线程的时间片全用完了,假设你整个县城也要被切换推。
可是进程的切换时是c p u寄存器要保存,更重要的是它的这个热的缓存数据要被直接丢弃掉。
好,那么把另一个进程放出来,他要重新再开始这里重新缓存新的数据。
只要重新缓存数据就要由冷变热,所以他又是需要花一段时间,所以线程间切换效率更高,更重要的是我们线程切换啊,在同一个进程内的多个线程切换时,它对应的catch数据不需要重新被呃由冷变热,不需要重新缓存。下个进程再来,那就它又重新必须得重新缓存,所以它的效率当然会拖后腿啊,
所以线程切换的时候,那么它所对应的cache数据要被从冷变热重新缓存,这才是线程。切换为什么效率更高的原因,因为它不需要重新热缓存了。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【揭秘】如何使用LinkedHashMap来实现一个LUR缓存?
- 2024年烟花爆竹经营单位安全管理人员证考试题库及烟花爆竹经营单位安全管理人员试题解析
- 有什么建议或技巧可以分享给 C++ 初学者?
- 论文自己改过后怎么降重 papergpt
- 前端加密后端校验(MD5)
- 【AI视野·今日Robot 机器人论文速览 第七十三期】Tue, 9 Jan 2024
- Nginx会话保持
- 海外网红营销:母婴品牌提升影响力和市场份额的绝佳途径
- Linux软链接的创建,删除,修改
- Armv8-M的TrustZone技术解决的安全需求