大模型中训练出现的ignore_index的作用
发布时间:2023年12月27日
问题:研究stanford_alpaca代码时,不清楚ignore_index=-100有什么用?
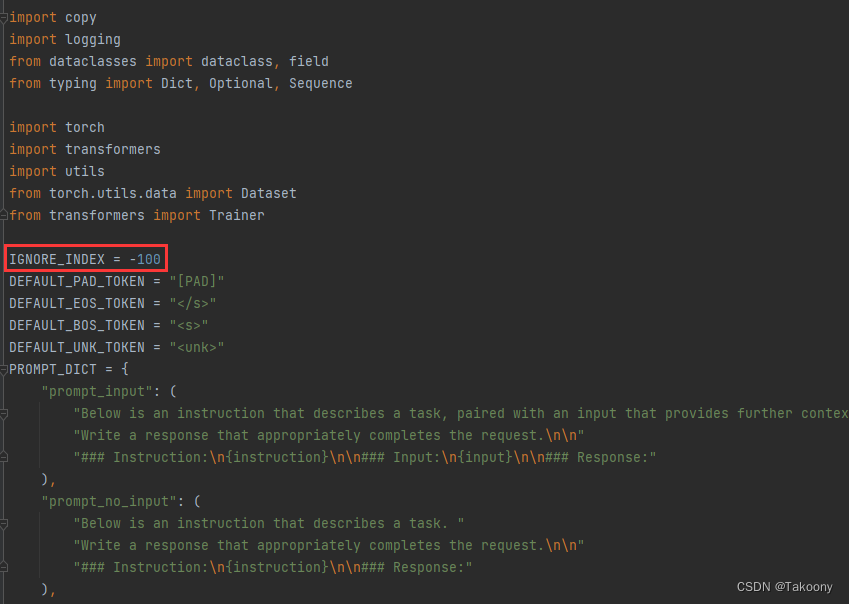
ignore_index作用分析
如图所示,将模型输入的所有token对应标签全部设置成-100
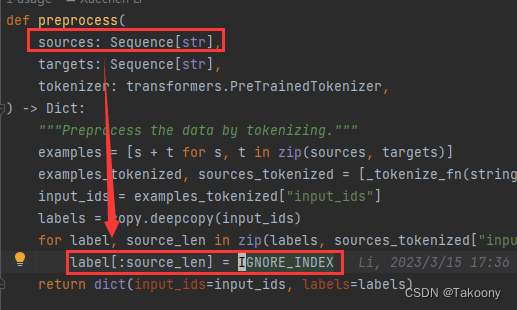
label会送入交叉熵损失函数中进行计算损失值,那么该函数如何起作用呢?
CrossEntropyLoss的作用
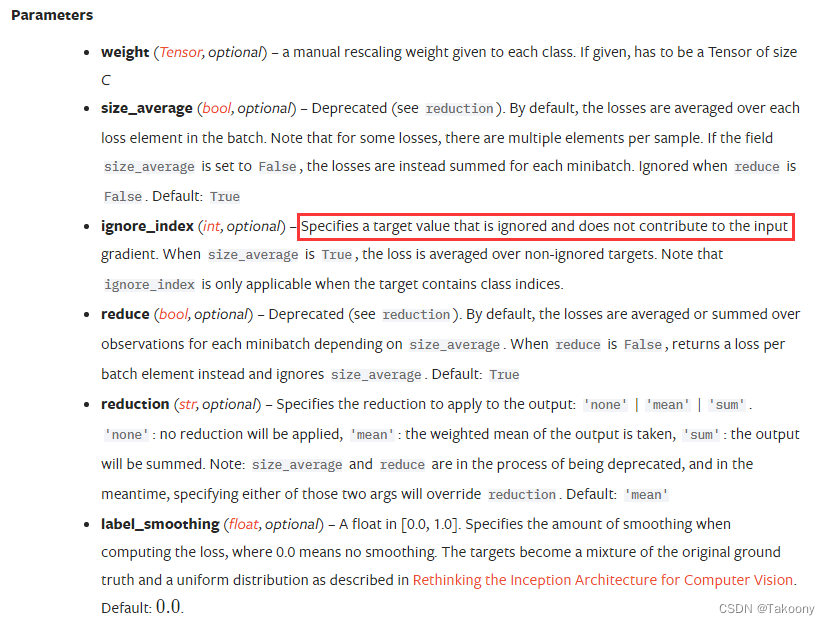
官方定义如下,也存在ignore_index参数,且刚好等于-100,这个值是不参与损失计算的
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean', label_smoothing=0.0)
从数据维度来看,如下所示:

案例
import torch
import torch.nn as nn
# 假设有3个类别,忽略索引为2的类别
criterion = nn.CrossEntropyLoss(ignore_index=2)
# 模拟模型输出和目标标签
outputs = torch.tensor([[0.9, 0.1, 0.0], [0.3, 0.4, 0.3], [0.01, 0.01, 0.98]])
targets = torch.tensor([0, 2, 1]) # 目标标签中包含了要忽略的类别2
# 计算损失
loss = criterion(outputs, targets)
print(loss)
输出:tensor(1.0763)
import torch
import torch.nn as nn
# 假设有3个类别,忽略索引为2的类别
criterion = nn.CrossEntropyLoss()
# 模拟模型输出和目标标签
outputs = torch.tensor([[0.9, 0.1, 0.0], [0.3, 0.4, 0.3], [0.01, 0.01, 0.98]])
targets = torch.tensor([0, 2, 1]) # 目标标签中包含了要忽略的类别2
# 计算损失
loss = criterion(outputs, targets)
print(loss)
输出:tensor(1.0952)
上述代码中的可以从targets = torch.tensor([0, 2, 1])变成targets = torch.tensor([0, 1, -1])吗
在PyTorch中,当使用nn.CrossEntropyLoss作为损失函数时,targets数组应该包含每个样本的类别索引,这些索引必须是非负整数,因为它们代表了类别标签。如果你使用-1作为类别索引,会违反这个要求,因为-1不是有效的类别索引,而且通常在这种情况下,PyTorch会抛出一个错误。
在上述案例代码中,target中的0对应0.9,2对应后面的0.3,1对应0.98
文章来源:https://blog.csdn.net/ningyanggege/article/details/135242758
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [ffmpeg系列 03] 文件、流地址(视频)解码为YUV
- 【高效写作技巧】CSDN的原力等级有什么用?如何增长原力等级?
- varnish的简单使用
- 【极客公园 IF 2024】张宏江 & 卢一峰:大模型皇冠上的明珠,到底是什么?
- imgaug库指南(21):从入门到精通的【图像增强】之旅
- 5118优惠券优惠链接是多少?5118优惠码怎么用?
- linux修改文件名
- Spring MVC学习笔记
- 数据库 MySQL 索引的原理
- C语言例题5