Mysql 主从集群同步延迟问题怎么解决
发布时间:2023年12月26日
一个工作了 8 年的粉丝,去京东面试在第一面被问到这个问题。
Mysql 主从集群同步延迟问题怎么解决
我发现这个问题面试命中率还挺高的,如果大家准备去面试的话,我建议可以去评论区
置顶中领取一下之前整理的
30W 字的面试文档
、100份精选简历模板、学习路线图
或者去
公众号:“?
灰灰聊架构?
”, 回复暗号:“?
321?
”即可获取

下面我先来个大家复习一下主从复制的工作原理。
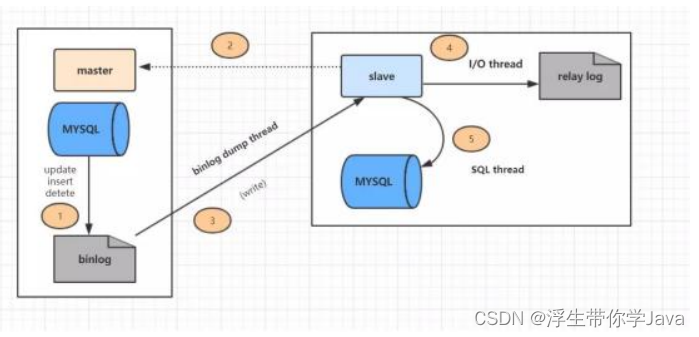
复制过程分为几个步骤:
1. 主库的更新事件(update、insert、delete)被写到 binlog
2. 从库发起连接,连接到主库。
3. 此时主库创建一个 binlog dump thread,把 binlog 的内容发送到从库。
4. 从库启动之后,创建一个 I/O 线程,读取主库传过来的 binlog 内容并写入到relay log
5. 从库还会创建一个 SQL 线程,从 relay log 里面读取内容,从Exec_Master_Log_Pos 位置开始
执行读取到的更新事件,将更新内容写入到slave的 db
主从数据同步涉及到网络数据传输,由于网络通信的延迟以及从库数据处理的效率问题,就会导致主从数据同步延迟的情况。
一般可以通过以下几个方法来解决
?
设计一主多从来分担从库压力,减少主从同步延迟问题
?
如果对数据一致性要求高,在从库存在延迟的情况下,可以强制走主库查询数据
?
可以在从库上执行 show slave status 命令,获取 seconds_behind_master 字段的延迟时间,然后通过 sleep 阻塞等待固定时间后再次查询
?
通过并行复制解决从库复制延迟的问题
实际上,主从复制的场景无法避免同步延迟的问题,如果一定要用强一致方案,那就应该考虑其他能够实现一致性场景的技术方案。
好的,几天的分享就到这里,byebye
?
文章来源:https://blog.csdn.net/sinat_53467514/article/details/135222811
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!