什么是向量数据库
什么是向量数据库
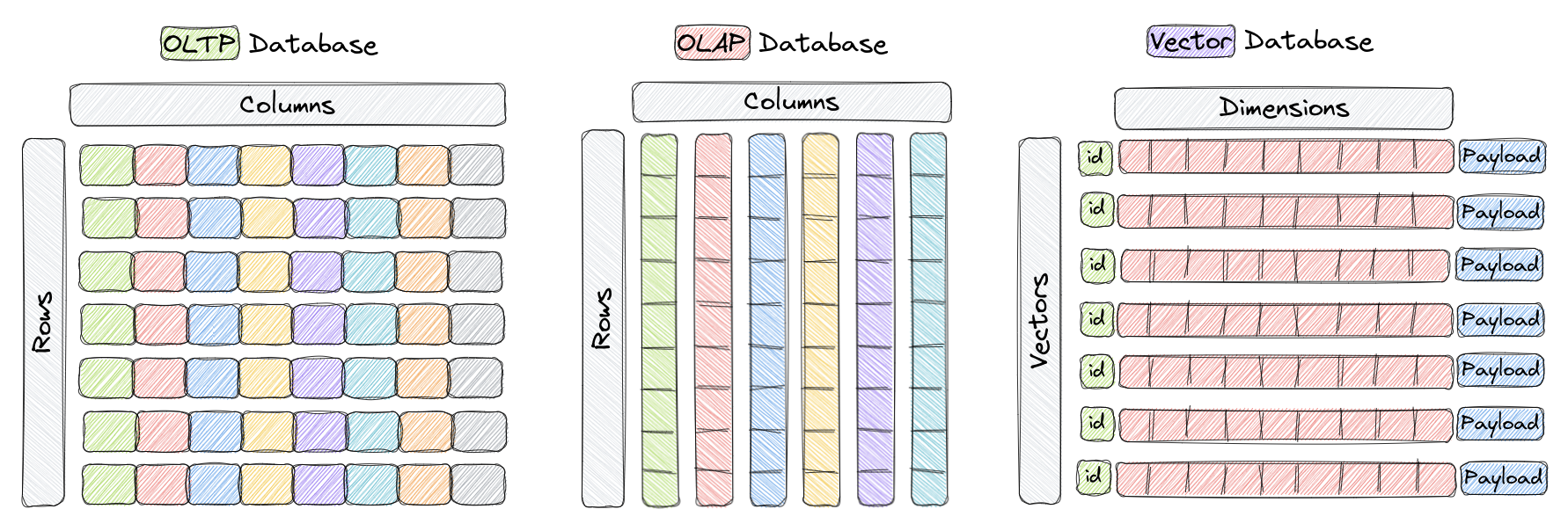
向量数据库是一种应用在高效存储和查询高维向量的数据库。在传统的OLTP和OLAP数据库中(如上图所示),数据按行和列组织(这些称为表),并根据这些列中的值执行查询。然而,在某些应用程序中,包括图像识别、自然语言处理和推荐系统,数据通常表示为高维空间中的向量,这些向量加上 id 和有效负载(Payload),组成我们存储在集合中的元素。
在搞清楚向量数据库之前,先需要知道什么是向量(vector)。
什么是向量
在AI领域中,向量是一个具有大小和方向的数学对象。它可以用来表示现实世界中的各种事物,例如图像、语音、文本等。
在机器学习和深度学习中,向量通常被用作表示数据的形式,其中每个向量的维度代表了不同的特征或属性。例如,在图像分类任务中,一个图像可以被表示为像素值组成的向量;在自然语言处理任务中,一句话可以被表示为单词嵌入(word embeddings)组成的向量。通过对这些向量进行计算和比较,机器可以从数据中提取出有用的信息,如相似性、聚类等。
比如人脸识别技术,计算机从照片或视频中提取出人脸的图像,然后将人脸图像转换为128维或者更高维度的向量。说到向量,就离不开embeddings。下面说下embeddings是什么。
什么是embeddings
embeddings是一个相对低维度的空间,可以将高维向量转换为低维度。embeddings使得机器学习更加高效,例如表示单词的稀疏向量。最理想的情况是,embeddings能够通过将语义上相似的输入放置在embeddings空间中,通过彼此靠近的向量来捕获输入的某些语义。可以在不同的模型中学习和重复使用嵌入。
什么是向量检索
向量搜索是一种使用机器学习模型在索引中检测对象间语义关系的方法,以找到具有相似特征的相关对象。
如果你想在你的网站上添加自然语言文本搜索、创建图像搜索或构建强大的推荐系统,那么你就需要考虑使用向量技术。
为什么需要向量数据库
上面的一些概念解释了之后,其实在 AI 领域中,向量数据库是为了更高效地存储和检索大规模高维度的向量数据而设计的。由于传统的数据库系统并不擅长处理向量数据,因此需要专门的向量数据库来支持各种应用场景,例如语义搜索、图像检索、推荐系统等。
与传统数据库不同,向量数据库可以使用特殊的索引结构和相似度度量方法,在高维度向量空间中快速查找相似的向量。例如,一些流行的向量数据库使用基于倒排索引和最邻近搜索(Approximate Nearest Neighbor Search)的技术,极大地加快了向量数据的查询速度。
向量数据库还提供了方便的 API 接口和工具库,使得用户可以轻松地将其集成到自己的应用程序中,并进行快速的向量搜索。因此,在许多需要处理大规模向量数据的 AI 应用中,向量数据库成为了不可或缺的组件。
接下来我们来看看怎么简单快速的入门向量数据库~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 排序 | 冒泡 插入 希尔 选择 堆 快排 归并 非递归 计数 基数 排序
- 2024第15届电子教育、电子商务、电子管理和电子学习国际会议
- 操作系统——I/O控制器
- 插火把(洛谷)
- 使用 LOAD DATA INFILE 将 CSV 文件导入运行在容器中的 MySQL
- 图还能有数据库?一文带你了解图数据库是个什么东西!
- 01 Redis的特性
- Java面试之并发篇(二)
- vue中的常见使用
- 为什么选择计算机?大数据时代学习计算机的价值探讨