多模态图像配准中的跨模态注意
Cross-modal attention for multi-modal image registration
多模态图像配准中的跨模态注意
Medical Image Analysis 82 (2022) 102612
code:https://github.com/DIAL-RPI/Attention-Reg
背景
图像引导的介入手术通常需要配准多模式图像来可视化和分析互补信息。例如,前列腺癌症活检受益于将经直肠超声(TRUS)成像与磁共振成像(MR)融合以优化靶向活检。然而,图像配准是一项具有挑战性的任务,尤其是对于多模态图像。在过去的几年里,卷积神经网络(CNNs)已被证明在提取对医学图像配准至关重要的图像特征方面具有强大的功能。然而,具有挑战性的应用和计算机视觉的最新进展表明,神经网络理解特征之间的空间对应关系的能力有限,而特征之间的对应关系是图像配准的核心。当涉及到多模态图像配准时,这个问题被进一步夸大了,其中输入图像的外观可能显著不同。
大多数基于CNN的深度学习方法不是对图像之间的对应关系进行建模,而是将输入图像的合成特征直接映射到空间变换中以对齐它们。到目前为止,成功主要来自两个方面。一种是通过训练适当设计的网络来自动学习图像表示的能力;另一种是将复杂图案映射到图像变换的能力。目前的方法将这两种成分混合在一起进行图像配准。然而,将图像特征转换为空间关系是极具挑战性的,并且高度依赖于数据,这是进一步提高配准性能的瓶颈。
我们的假设是,明确地建立两幅不同图像的相应图像特征之间的空间对应关系可以显著提高图像配准的性能
贡献
- 提出了一种新的跨模态注意力机制,显式地对空间对应关系进行建模,用于关联从多模态输入图像中提取的特征,并将这种关联映射到图像配准变换。
- 为了更好地利用新的跨模态注意力块,还提出了一种基于对比学习的预训练策略,该策略有助于从两种成像模态中提取判别特征。
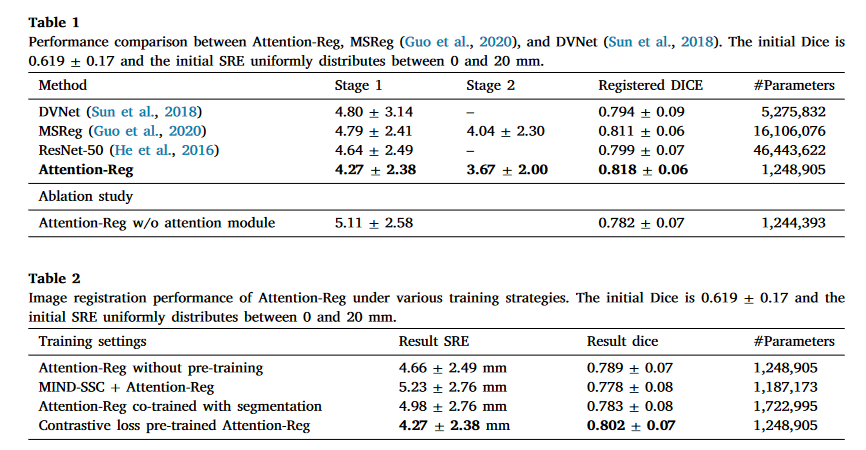
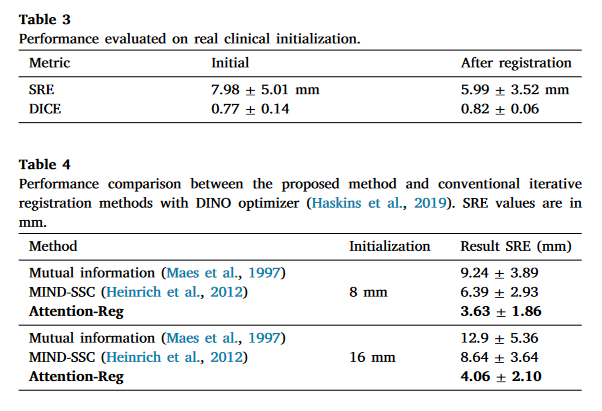
- 验证了所提出的经直肠超声(TRUS)磁共振(MR)配准方法,这是一种有利于前列腺癌症活检的临床重要程序。实验结果表明,对于MRTRUS配准,嵌入跨模态注意力块的深度神经网络的性能是其他先进的基于CNN的网络的十倍。我们还结合了可视化技术来提高网络的可解释性,这有助于深入了解基于深度学习的图像配准方法。
- 我们的工作旨在使Sun等人(2014)需要体力劳动的步骤自动化。此外,尽管Hu等人的可变形配准管道(2018)编码了更高的灵活性,但Venderink等人的临床研究(2018)发现刚性配准方法和可变形配准方法之间的临床效果没有显著差异。
实验
评估指标:SRE(表面配准误差)
SRE描述了地面实况配准前列腺和预测配准前列腺之间的欧几里得点对点距离。
DICE不反映这种点对点距离,它测量两个体积的重叠,而没有考虑方向如何。尽管如此,我们还是将DICE作为一个额外的指标进行了参考。
数据集:使用528例MRI-TRUS体积对进行训练,66例进行验证,68例进行测试。每个病例都包含一个T2加权MRI体积和一个3D超声体积。MRI体积具有512×512×D体素,其中D的范围从26到32。超声体积是从前列腺的电磁跟踪徒2D扫描重建的。为了进行评估,所有超声体积都用整个前列腺的掩膜进行注释。将MR和TRUS体积重新采样到96×96×32作为网络输入
方法
Feature extraction
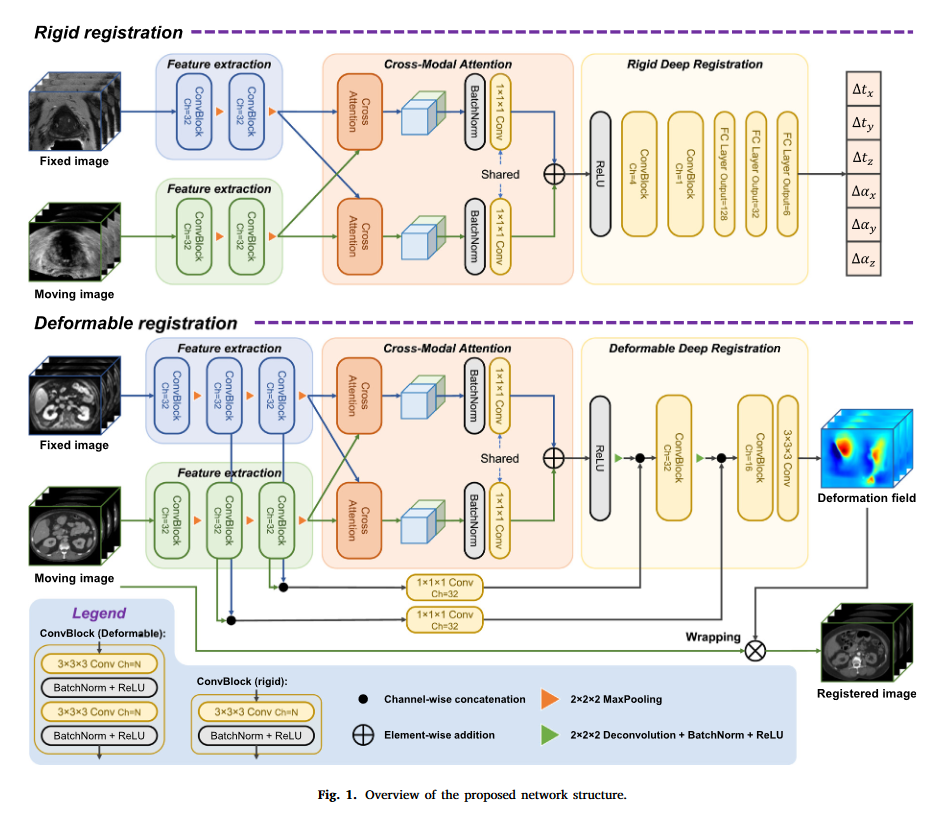
两个特征提取器,分别提取固定影像和移动影像的特征
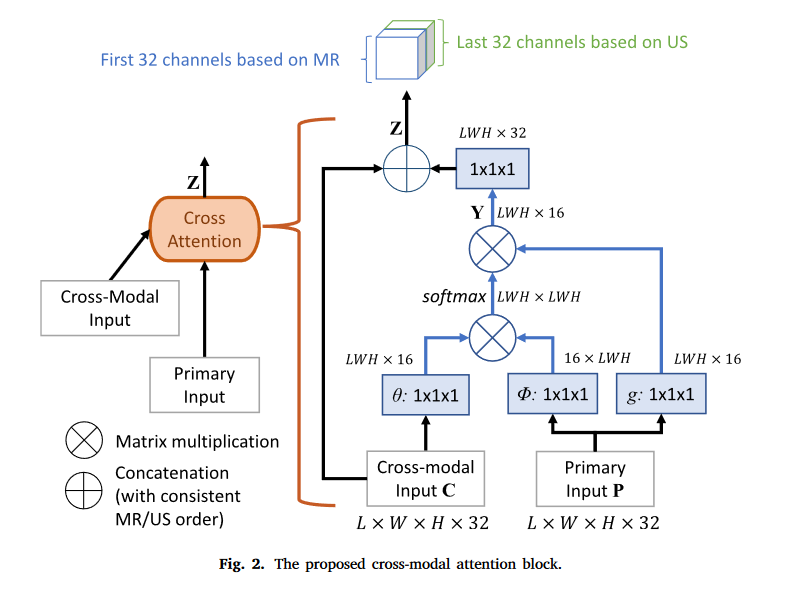
Cross-modal attention
建立不同模态的两幅图像的特征之间的空间对应关系。
交叉注意力机制,使用cross-modal input的Q和Primary input的K和V

Rigid registration
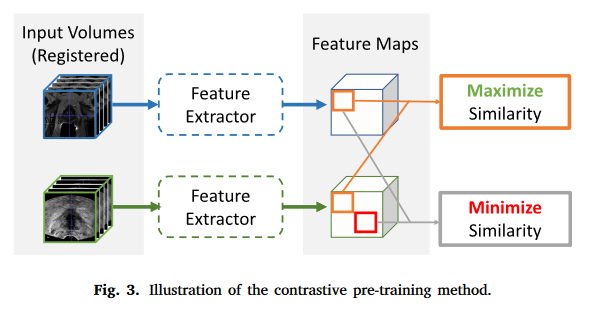
Contrastive pretraining of the feature extraction module
特征提取模块的对比预训练
跨模态注意力模块使用先前特征提取模块提取的特征来计算注意力。在训练的早期阶段,提取的特征可能与图像配准任务无关,因此计算的注意力可能与配准不相关。整体培训可能效率很低。为了解决这个问题,我们开发了一种基于对比学习的预训练策略,该策略强制所提出的网络的特征提取器模块在对整个网络进行端到端训练之前,从两种模态的相应解剖区域学习相似的特征表示。旨在最大化每个特征图中相同位置的特征向量之间的相似性,并最小化不同位置的特征矢量之间的相似度
Rigid registration implementation details
首先预训练网络的特征提取模块,如第2.3.1节所述。然后,我们冻结预先训练的模块,以调整网络的其余部分。在300个时代之后,我们放松整个网络进行微调。
损失函数
Thinking
由于在训练的早期阶段,提取的特征可能与图像配准任务无关。因此先进行自监督学习(对比学习)进行预训练,冻结预训练好的特征提取器,用于图像配准训练,在300轮之后,解冻特征提取器,对整个网络进行微调。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!