redis
redis可以将查询结果缓存,减少与数据库的交互。很多操作都是读操作,很多时候都是反复查询一个东西,就可以将查询结果缓存到内存中,需要的时候从缓存里取,不需要查询数据库。从内存中读取比从数据库查询也要快得多。
redis支持的数据类型:string、list、hash、sort、zsort。
一、缓存机制
缓存的数据在内存中,而内存资源是有限的,不能无节制的缓存下去。
1、设置超时时间。
设置缓存的超时时间,过期的缓存就会被清除掉。每100ms就会做一次清理过期缓存。redis可以缓存大量的数据,不能一次就把所有过期的缓存都清除掉,因为还要留资源去接待新请求。
2、惰性删除
redis随机选择一部分过期的缓存清除,这就会出现一个情况,就是某些过期的缓存会多次都逃逸掉了被清除。于是在定期删除的基础上,又增加了一招,就是一个查询请求过来,发现这个缓存已经过期了,就会立即删除。因为是被动触发的,不查询就不会删除,因此又叫做惰性删除。
3、内存淘汰策略
仍会有个别的缓存,逃掉了定期删除,也逃掉了惰性删除。引入了内存淘汰策略。
八种内存淘汰策略:
noeviction:默认策略,返回错误,不会删除任何键值。
allkeys-lru:使用 LRU 算法删除最近最少使用的键值。
volatile-lru:使用 LRU 算法从设置了过期时间的键值集合中删除最近最少使用的键值。
allkeys-random:从所有key随机删除。
volatile-random:从设置了过期时间的键的集合中随机删除。
volatile-ttl:从设置了过期时间的键中挑选剩余时间最短的键删除。
allkeys-lfu:从设置了过期时间的键中挑选使用频率最少的键删除。
volatile-lfu:从所有键中删除使用频率最少的键。?
二、缓存问题
缓存穿透:
如果查询的数据不存在,那就不会缓存到内存,下次这个查询又来了,因为缓存中没有,仍然会查询数据库,这就是缓存穿透。
缓存击穿:
热点数据到期,从缓存中删除掉了,随后有大量的这个请求过来,因为缓存中没有,因此会去查询数据库。
缓存雪崩:
大量的热点数据几乎同时过期,缓存中已经删除了,大量的请求都到数据库了,这就是缓存雪崩。
解决方案:把缓存过期时间设置的均匀一些,不要几乎同时过期。
三、缓存持久化
如果遇到了某些原因系统崩溃了,那缓存在内存中的数据就都没有了,项目重启之后,大量的请求又都会到数据库。
解决方案:如果可以能把缓存在内存的数据持久化到磁盘就可以解决这个问题了。
持久化方案有RDB、AOF。
1、RDB
RDB(Redis DataBase缩写快照)是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期;记录Redis数据库的所有键值对,在某个时间点将数据写入一个临时文件持久化结束后,用这个临时文件替换上次持久化的文件达到数据恢复;

优点:
fork子进程来完成写操作,让主进程继续处理命令,主进程不会进行?IO 操作,保证了Redis的高性能。
缺点:
1、RDB不适合高频备份,是间隔一段时间进行持久化(根据如何配置),会发生数据丢失。所以这种方式更适合数据要求不严谨的时候。
2、如果这个备份周期都是读操作没有写操作,那么就不需要持久化操作的。
?
2、AOF
redis是命令式的,响应命令的请求。类似mysql的binlog文件记录所有的写sql,将redis所有执行的写命令都记录下来写入aof文件。如果每执行一个命令就写入一次文件会影响性能,因此就有了aof_buf缓冲区,aof_buf会临时保存执行的命令,然后再择机写入文件。
随着时间的推移,aof文件会越来越大。AOF重写就是压缩aof文件给aof文件瘦身,如何压缩呢?
指令合并:
例如,一个值被改来改去的,那就可以只记录最终的值。
也fork子进程来做这件事。子进程在重写期间,要是修改了数据,就会出现和重写的内容不一致的情况(1、子进程重写前,name=zhangsan。2、子进程重写,name=zhangsan。3、缓存中name修改了,name=lisi)。
为解决aof重写数据不一致的问题,又引入一个aof_rewrite_buf缓冲区,从创建重写子进程的那一刻起,把后来的写入命令也copy一份写到aof_rewrite_buf缓冲区,等到子进程重写文件结束之后,再把aof_rewrite_buf缓冲区的内容写入新的aof文件,最后重命名文件替换原来臃肿的大文件。
四、redis主从同步+哨兵
如果只有一个节点,这个节点又挂掉了,那么就无法提供服务了。为实现高可用,可以使用redis集群,多个节点,如果一个挂掉了,还有其他的节点可以提供服务。
主从模式,主节点负责写数据,从节点负责读数据,做好数据同步,读写分离,提高性能。如果主节点崩溃了,选择一个从节点成为主节点,实现高可用。
如果主节点有新增、修改、删除,也会把这些命令挨个通知到从节点,这就是命令传播。通过这样的方式,主节点与从节点之间数据就能保持同步了。但是,如果一个从节点B掉线了,节点B只同步自己掉线那段时间的数据就可以了,不需要同步全部的数据,而RDB文件里是全部的数据,节点B该如何仅同步自己掉线那段时间的数据呢?
解决方案:主节点内部准备一个缓冲区,后面传播命令的时候,除了同步给从节点,也往缓冲区写入一份,这样如果某个子节点掉线了,子节点只同步缓冲区里最后的同步命令就可以了。
?主节点怎么知道缓存的和子节点缺失的能不能对得上呢?怎么知道该发缓存中的哪些给子节点呢?
解决方案:弄一个游标,叫做赋值偏移量,最开始从0开始,随着数据复制和同步,大家一起更新,后面只需要比较各自的偏移量,就能知道缺失哪些数据了。
虽然有了主从复制,但主节点要是挂了,还是需要程序员来手动选择从节点升级为主节点来提供写入服务,不够智能,如何解决?
解决方案:从redis集群选择一个服务当管理员,不用负责数据的读写,专门统筹协调,如果哪个节点掉线了,就从子节点中选择一个顶上主节点。
这个管理页就被叫做哨兵,但要是管理员挂了呢?也要多找几个管理员。管理员和主节点沟通。
为了及时获得和更新主从节点的信息,哨兵每隔10秒钟就要用info命令去问候一下主节点,主节点会告诉哨兵都有哪些从节点,为了更加及时知道节点是否掉线,哨兵每隔1秒就要用ping命令问候一下各个节点,如果在设置的时间里没有收到回复,那没有回复的节点就可能是挂了,此时是主观下线,为防止误判,还要确认一下其他的哨兵是否也判定为下线,如果多数哨兵都判定节点下线,才认定为客观下线。判定为客观下线,就可以启动故障转移了。
故障转移:
1、选择新的主节点。2、让其他从节点从新的主节点那里同步数据。3、把原来旧的主节点改为从节点。
选择新的主节点的规则:
1、可以给节点设置优先级,硬件配置高的优先级越高,挑选主节点的时候就按照这个优先级来。
2、优先选择跟主节点断开连接最短的节点,这样它的数据会更新一点。
3、还可以参考一下复制偏移量,越大的数据应该越全。
五、redis集群
主从复制+哨兵,解决了高可用,但是不能解决数据量大的问题,因为虽然节点多,但存储的都是全量数据,不能解决数据量大的问题。
解决方案:
将所有节点的内存拼起来,成为一个大的缓存服务器,这就是集群。
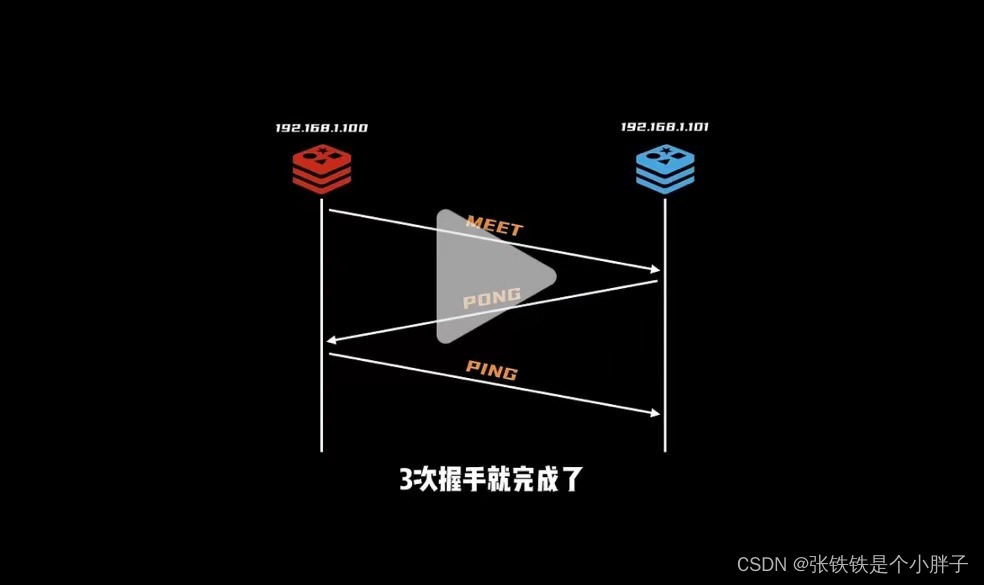
参考TCP的三次握手,想要加入集群,通过集群中的任意一个成员都行,例如经过集群中的A,知道要加入进来的服务D的IP和端口,A和D经过三次握手就行了,A再把这个消息告诉集群中的其他成员,D就正式成为集群中的一份子了。
既然是集群,就要解决数据存储的公平问题,不能旱的旱死涝的涝死,学习hash表的方法,总共划分了16384的哈希桶,这些哈希桶叫做槽位slot,程序员可以根据集群成员的硬件配置给分配槽位,数据读写的时候,对键值做一下hash计算,映射到哪个槽就由对应的服务负责,为了让大家的信息达成一致,启动的时候,每个成员都要把自己负责的槽位信息告诉其他伙伴,一共有1万多个槽要通知其他成员,需要传输的数据量还是挺大的,为了压缩数据空间,每个槽就用一个bit表示,自己负责就是1,否则就是0,这样一共才16384个bit,传输起来轻便快捷。
遇到读写数据的时候,总不能挨个去看谁的那一位是1吧,干脆一步到位,用空间换时间,又准备了一个超大的数组来存储每个槽由哪个节点负责,通过上面的方式拿到信息后就更新到这里来。补图。这样一来遇到数据访问的时候,就能快速知道这个歌数据是由哪个槽来负责的。这16384个槽位都有节点负责,整个集群才是正常工作。

数据读写的时候多了一个步骤,要先检查槽位是不是由自己负责,如果是自己负责那就进行处理,否则的话就要返回一个MOVED错误给请求端,同时把槽号、IP和端口告诉请求端。让请求端知道该找谁处理,这个过程,程序员是不感知的。

如果集群中哪个挂了怎么处理呢?每个节点至少得有一个backup才行,如果节点挂了,backup能快速顶上。
扩容
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【若依】关于对象查询list返回,进行业务处理以后的分页问题
- 【Vue3干货】template setup 和 tsx 的混合开发实践
- 视频号分成计划该怎么做?3000字超详细保姆级教程来了
- 每日算法打卡:机器人跳跃 day 11
- 嵌入式开发之外部中断EXTI
- 1317:【例5.2】组合的输出
- Spring Boot快速搭建一个简易商城项目【一展示商城首页篇】
- 【深基9.例4】求第 k 小的数#洛谷(MLE)
- geyser互通服基岩版进不去
- js 判断路由有没有参数 vue2+vue3