卷积层里的多输入与多输出通道(channel)
目录
一、多输入输出通道
1、多输入通道

???????下图是多输入通道、单输出通道的情况:每个通道都有自己的卷积核,每个通道卷积后的输出相加得到结果。
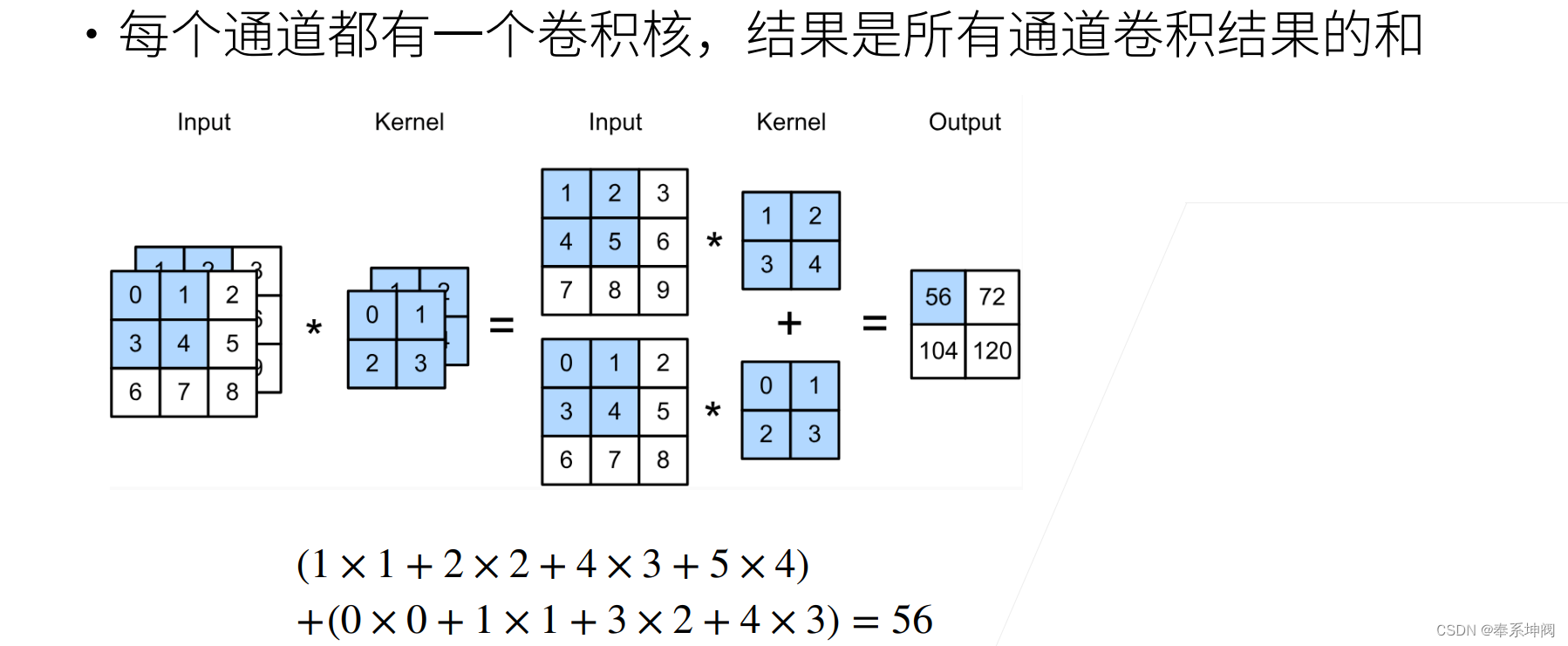
???????多通道输入、单通道输出的情况可以用公式来进行表示:
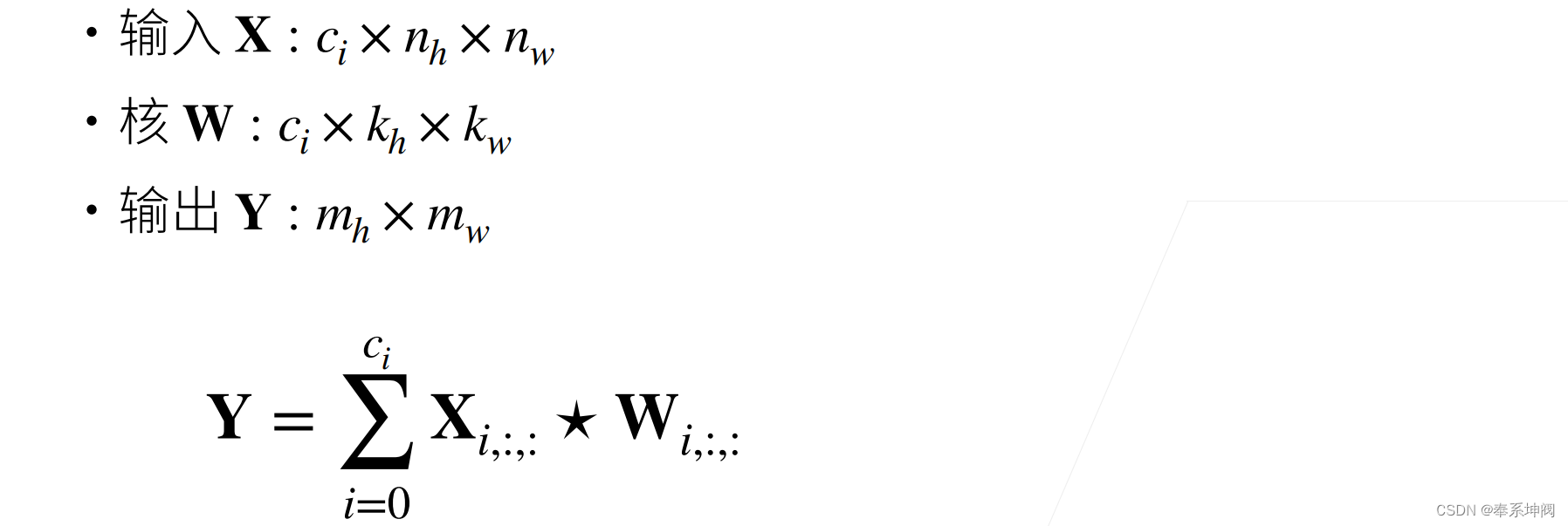
-?:输入通道数
-?:输入的高和宽
-?:卷积核的高和宽
-?:输出的高和宽
这里忘记写偏移bias了,偏移应该也为一个长为?
?的一个向量。
2、多输出通道
???????如果输入是R,G,B三通道时,输出只有单通道有时候不太够用。如果想要输出也有多个通道,我们可以对每个输出的通道都有一个自己的三维卷积核,每个核生成一个输出通道。
???????多通道输入、多通道输出的情况可以用公式来进行表示:

-?:输入通道数
-?:输入的高和宽
-?:卷积核的高和宽
-?:输出的高和宽
-?:输出通道数
???????多个输入输出通道的原理:可以认为每一个输出通道在识别某一个特别的模式(比如说输出纹理、边缘等信息),然后在下一层神经网络对上一层的输出进行加权形成一个组合的模式识别。对于一个深层的神经网络来说,当一张图片传进来的时候,最下层学习到的是一些局部的小纹理等特征,上层则会把一些局部的纹理给组合起来,一层一层逐层递进。
???????比如说要识别猫:下层先识别猫胡须的纹理、耳朵的纹理等,上层则会把这些纹理组合起来,形成猫头、猫腿等,最上层会组合所有的信息来识别猫。
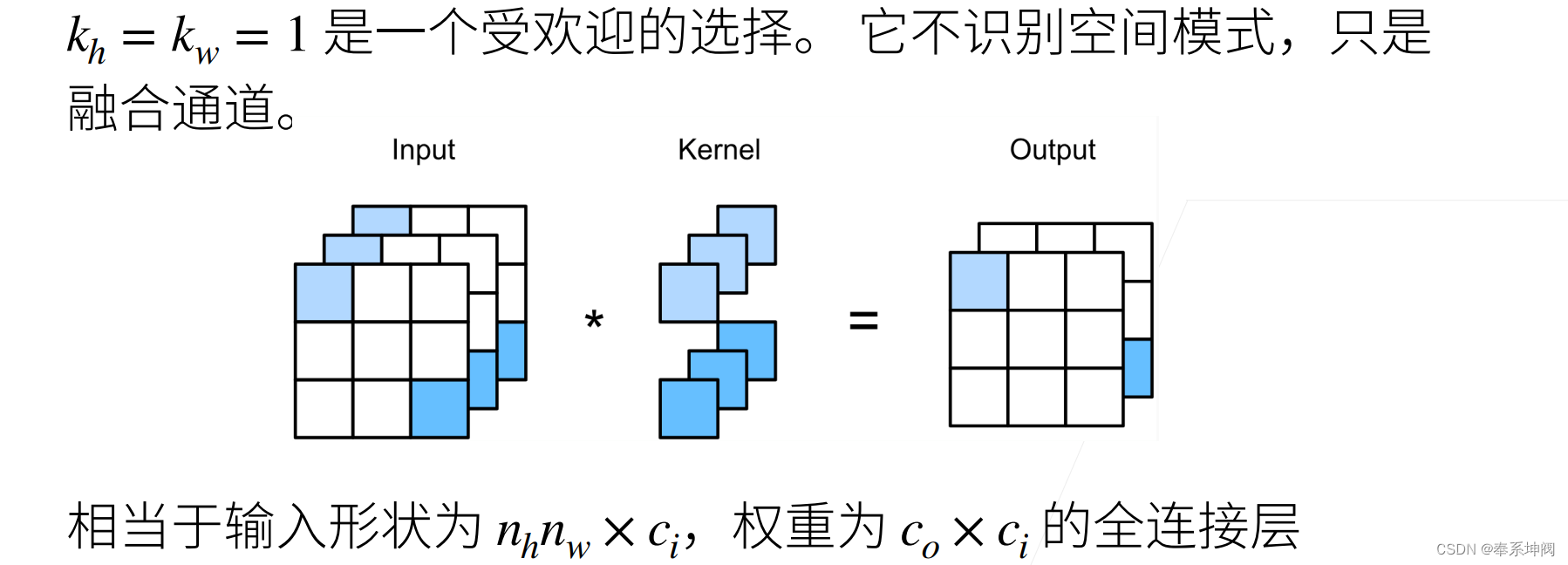
3、1×1卷积层
????????的卷积核的高和宽都等于1,意味着它不会去识别空间信息,因为它每次只看一个像素,它所做的是去融合通道的信息
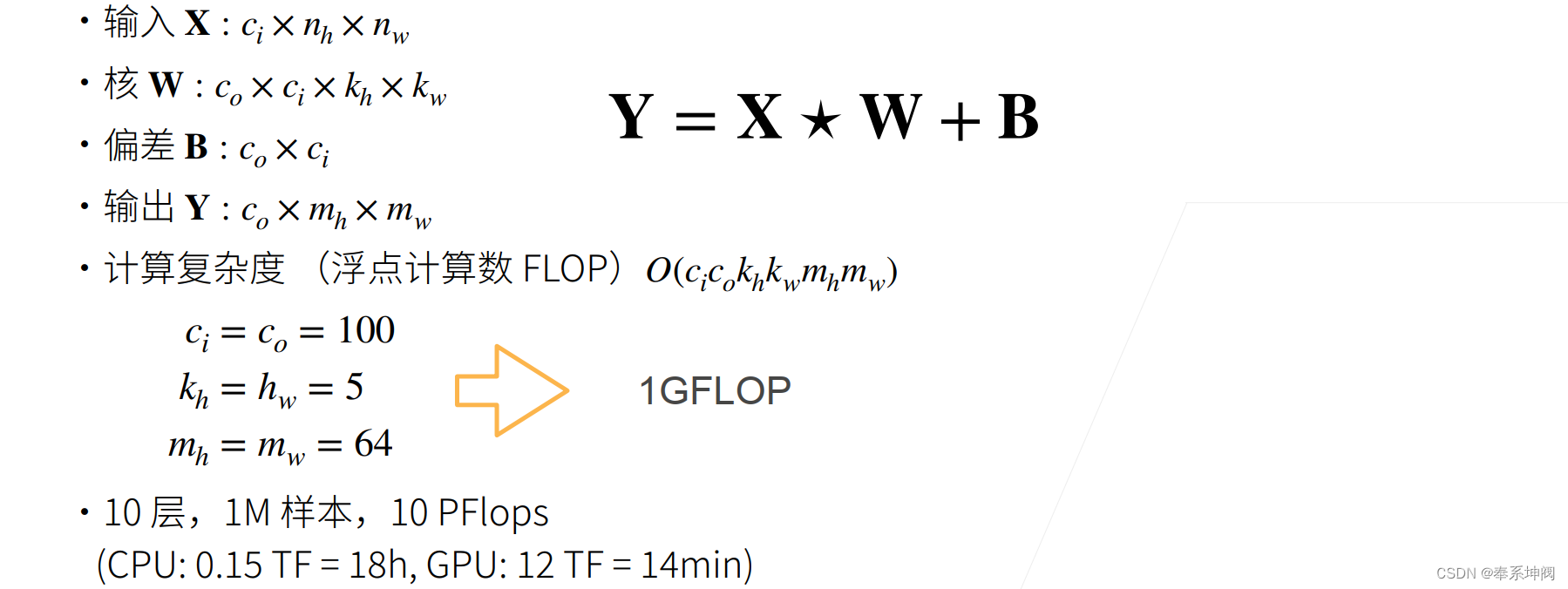
4、二维卷积层的计算复杂度
???????可以简单认为对于每一个输出的像素,都需要进行??次运算,然后输出有?
?层(通道),每个层(通道)有?
?个像素,因此计算复杂度为?
。
5、总结

二、代码实现
1、多输入通道
???????当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为 ,那么卷积核的输入通道数也需要为
。如果卷积核的窗口形状是
,那么当
?时,我们可以把卷积核看作形状为
?的二维张量。
???????然而,当??时,我们卷积核的每个输入通道将包含形状为
?的张量。将这些张量?
?连结在一起可以得到形状为
?的卷积核。由于输入和卷积核都有?
?个通道,我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将
?的结果相加)得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
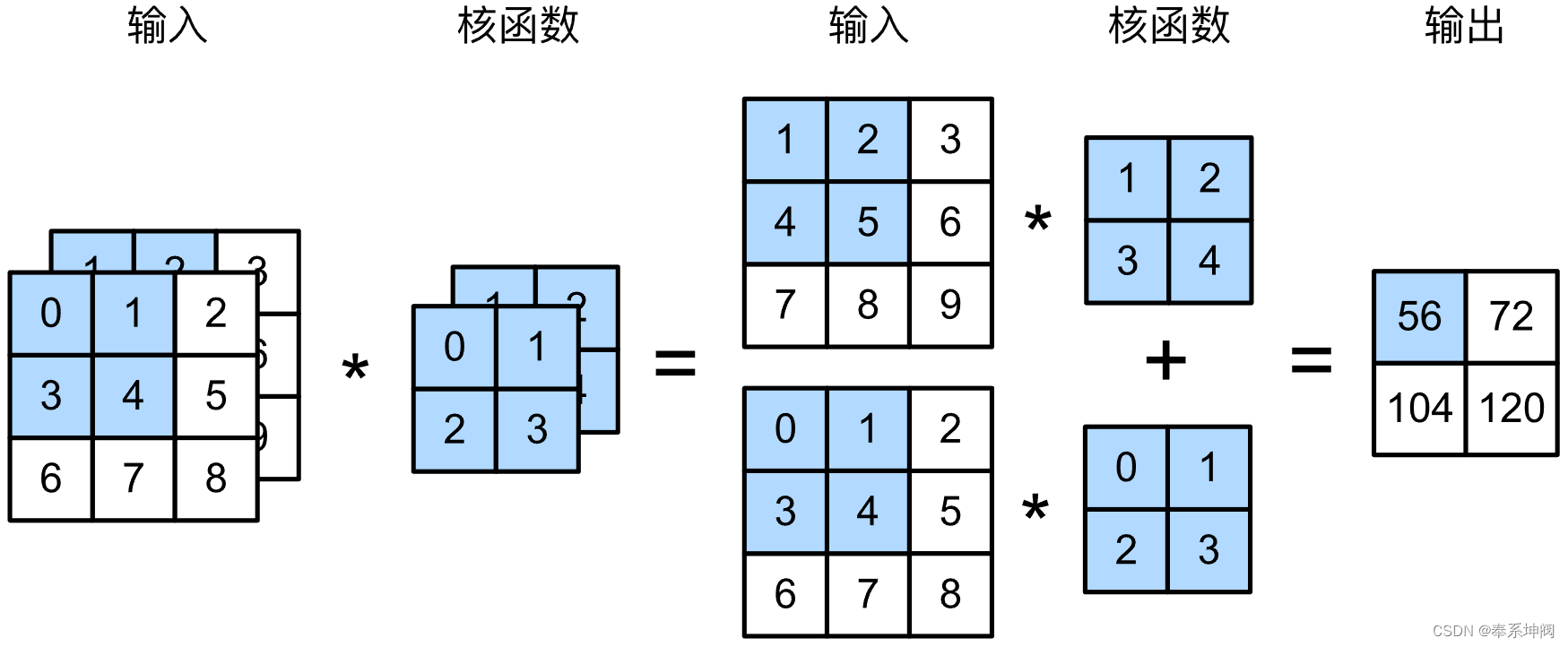
???????下面的代码是对上图互相关运算的实现:
import torch
from d2l import torch as d2ldef corr2d_multi_in(X, K): # X:3D K:3D
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K)) # zip()对最外的通道(输入通道)做遍历????????构造与上图中的值相对应的输入张量`X`和核张量`K`,以验证互相关运算的输出。
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_multi_in(X, K)tensor([[ 56., 72.],
[104., 120.]])2、多输出通道
???????在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
???????如下所示,我们实现一个计算多个通道的输出的互相关函数。
def corr2d_multi_in_out(X, K): # X:3D K:4D
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0) # k:3D corr2d_multi_in(X, k):2D???????通过将核张量`K`与`K+1`(`K`中每个元素加1)和`K+2`连接起来,构造了一个具有3个输出通道的卷积核。
K = torch.stack((K, K + 1, K + 2), 0) # 创建3个输出通道
print(K.shape) # (channel_ouput, channel_input, kernel_height, kernel_width):(3, 2, 2, 2)torch.Size([3, 2, 2, 2])???????下面,我们对输入张量`X`与卷积核张量`K`执行互相关运算。现在的输出包含3个通道,第一个通道的结果与先前输入张量`X`和多输入单输出通道的结果一致。
corr2d_multi_in_out(X, K)tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])3、1×1卷积层
???????因为使用了最小窗口,?卷积失去了卷积层的特有能力——在高度和宽度维度上,识别相邻元素间相互作用的能力。其实?
?卷积的唯一计算发生在通道上。
???????下面,我们使用全连接层实现??卷积。请注意,我们需要对输入和输出的数据形状进行调整。
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))???????当执行??卷积运算时,上述函数相当于先前实现的互相关函数`corr2d_multi_in_out`。让我们用一些样本数据来验证这一点。
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-64、总结
- 多输入多输出通道可以用来扩展卷积层的模型。
- 当以每像素为基础应用时,
?卷积层相当于全连接层。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 泰迪智能科技分享:AI大模型发展趋势分析
- 关于python环境变量相关的配置汇总(venv虚拟环境/conda环境/pip相关)
- LeetCode-232. 用栈实现队列【栈 设计 队列】
- Open CV 图像处理基础:(六)在Java中使用 Open CV进行图片翻转和图片旋转
- 记edusrc一处信息泄露
- ES6之Promise的链式调用
- 计算三叉搜索树的高度 - 华为OD统一考试
- 代码随想录算法训练营第二十七天 | 39. 组合总和、40.组合总和II、131.分割回文串
- 晚会抽奖程序 用Java编程实现一个晚会抽奖程序,要求能随机抽奖,并显示。 (一)具体要求: (1)可初始化设置抽奖轮次数、每次中奖人数、是否允许重复中奖(一般不允许)等信息。 (2)可设定参与人数
- RK3568平台 PWM Backlight控制背光亮度