【杂七杂八】GyP-DataLoader
发布时间:2024年01月16日
前言:
- pytorch :2.0.0+cuda 11.8
- Jupyter Notebook:7.0.6
- 所以 PyG不需要安装依赖包,直接cuda/pip install ; Jupyter Notebook 有扩展管理器,不需要也装不了 很多教程里的扩展管理插件 😁
1 基本数据结构 torch_geometric.data.Data
- data.x : 节点特征矩阵
[num_nodes, num_node_features] - data.edge_index: 将稀疏的邻接矩阵表示为COO格式(Coordinate Format,一种稀疏矩阵存储方式)
[2, num_edges]- 将邻接矩阵中不为零的元素坐标转置成为列向量拼在一起
- 无向图 两个节点之间是隐藏着两个箭头 ———— 无向图的邻接矩阵是对角阵
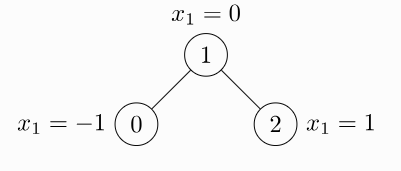
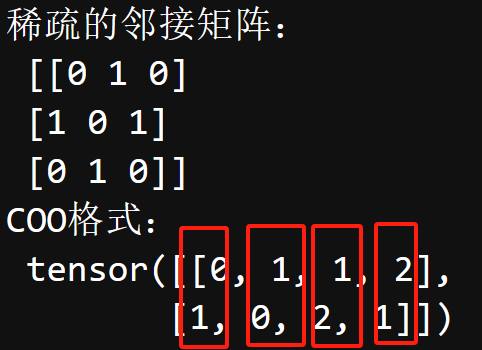
m = np.array([[0,1,0],[1,0,1],[0,1,0]])
print("稀疏的邻接矩阵:\n" , m) # 原始稀疏的邻接矩阵
edge_index = torch.tensor([[0,1,1,2],[1,0,2,1]],dtype = torch.long)
print("COO格式:\n",edge_index) # COO形式的邻接矩阵【无向图】
- data.edge_attr : 边特征矩阵
[num_edges, num_edge_features] - data.y :标签
- node-level :
[num_nodes, *] - graph-level :
[1, *]
- node-level :
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0,1,1,2],[1,0,2,1]],dtype = torch.long)
x = torch.tensor([[-1],[0],[1]],dtype=torch.float)
# 构造出一个图样本
data = Data(x=x,edge_index=edge_index)
2 加载数据集 torch_geometric.datasets
2.1 Graph-level
from torch_geometric.datasets import TUDataset
dataSet = TUDataset(root='/tmp/ENZYMES',name='ENZYMES')
print(len(dataSet)) # 数据集中含有600个图
print(dataSet.num_classes) # 6各类
print(dataSet.num_node_features) # 节点特征为3维
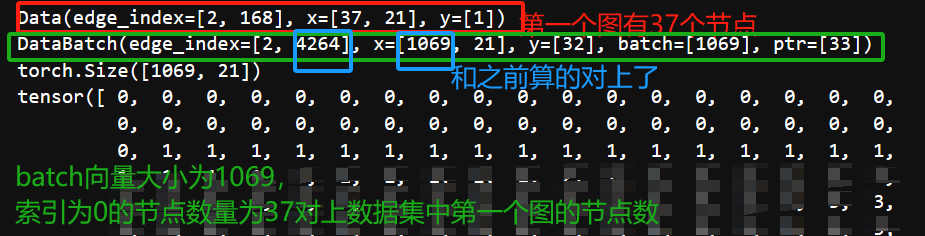
- 该样本(图)具有37个节点,每个节点含有3个特征,具有168/2=84个边,被分配到一个类(graph-level)
data_0 = dataSet[0]
print(data_0)
print(data_0.is_undirected) # True

2.2 Node-level
from torch_geometric.datasets import Planetoid
dataset1 = Planetoid(root='/tmp/Cora', name='Cora') # 最好科学上网下载
print(len(dataset1))# 1 只有一个图
print(dataset1.num_classes) # 7
print(dataset1.num_node_features) # 1433
- 划分了 训练集、验证机、测试集
- 注意 y : 每个节点都有一个标签
data1 = dataset1[0]
print(data1.is_undirected)
print(data1.train_mask.sum().item())
print(data1.val_mask.sum().item())
print(data1.test_mask.sum().item())

3 Mini-batches torch_geometric.loader.DataLoader
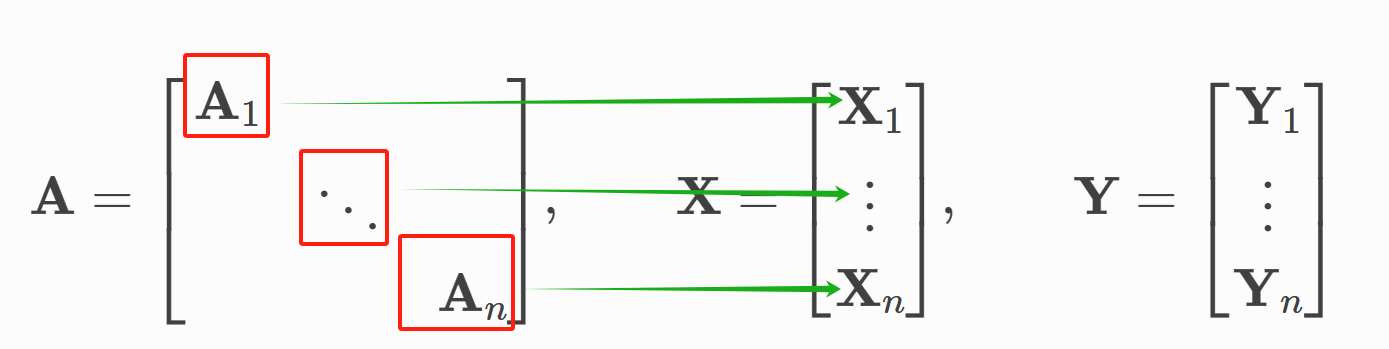
- 主要思想:
- DataLoader 将所有图的邻接矩阵按对角放置拼接成一个大矩阵,每个图的邻接矩阵在这个大矩阵可以视为一个元素
- batch_size 是一次训练选择多少个图
- DataLoader 会保存每一批次的训练样本,使用batch来将训练样本的节点对应哪个图的索引
简单验证:
- 不要打乱数据集,batch_size设置为32
from torch_geometric.loader import DataLoader
dataset2 = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader2 = DataLoader(dataset2,batch_size=32,shuffle=True) # 这里不按官网的教程来洗牌打乱,会更容易理解
- 取出前32个图
num = 0
num_node = 0
num_edge = 0
for data in dataset2[:32]:
m = data.edge_index.size()
n = data.x.size()
num_node += n[0]
num_edge += m[1]
num += 1
print(num) # 32个图
print(num_node) # 总计 1069个节点
print(num_edge) # 总计 4264个边
- 使用DataLoader加载数据集
loader3 = DataLoader(dataset2,batch_size=32,shuffle=False)
torch.set_printoptions(threshold=np.inf)
print(dataset2[0])
num = 0
for data in loader3:
# print(data.x)
print(data)
print(data.x.size())
if num < 1 :
print(data.batch)
print(data.batch.size())
num += 1
print("===============")
文章来源:https://blog.csdn.net/qq_45022770/article/details/135620776
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【ROS2】MOMO的鱼香ROS2(一)ROS2入门篇——从Ubuntu操作系统开启
- 【性能】【算法】for循环,性能提高
- AI数据微调找免费GPU遇阻之路
- 编程实际应用实例:洗车店会员管理系统操作教程
- ElasticSearch分词器介绍
- 【Python常用函数】一文让你彻底掌握Python中的numpy.array函数
- 2024年【熔化焊接与热切割】报名考试及熔化焊接与热切割作业考试题库
- 计算机毕业设计——springboot养老院管理系统 养老院后台管理
- 记录一下事件捕获问题的解决方法。
- 每日一道算法题 1