【PyTorch】PyTorch之Module模块
文章目录
- 前言
- MODULE类
- 1. add_module(name, module)
- 2. apply(fn)
- 3. children()
- 4. cpu()和cuda()
- 5. eval()
- 6. forward(*input)
- 7. get_parameter(target)
- 8. get_submodule(target)
- 9. load_state_dict(state_dict, strict=True, assign=False)
- 10. modules()
- 11. named_buffers(prefix='', recurse=True, remove_duplicate=True)
- 12. named_children()
- 13. named_modules(memo=None, prefix='', remove_duplicate=True)
- 14. named_parameters(prefix='', recurse=True, remove_duplicate=True)
- 15. parameters(recurse=True)
- 16. state_dict(*, prefix: str = '', keep_vars: bool = False) → Dict[str, Any]
- 17. to(device: Optional[Union[int, device]] = ..., dtype: Optional[Union[dtype, str]] = ..., non_blocking: bool = ...) → T
- 18. to_empty(*, device, recurse=True)
- 19. train(mode=True)
- 20. type(dst_type)
- 21. zero_grad(set_to_none=True)
前言
本文介绍pytorch中的module模块。
MODULE类
***torch.nn.Module(args, kwargs)
这是所有神经网络模块的基类。模型必须继承这个类。
模块还可以包含其他模块,允许将它们嵌套在树结构中。你可以将子模块分配为常规属性:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
以这种方式分配的子模块将被注册,并且当你调用 to() 等方法时,它们的参数也将被转换。
如上面的示例所示,在子类上进行分配之前,必须首先调用父类的 init()。
类变量:
training(bool):布尔值表示该模块是在训练模式还是评估模式。
1. add_module(name, module)
Parameters:
name (str) –子模块的名称。可以使用给定的名称从该模块访问子模块。
module (Module) – 要添加到模块的子模块。
向当前模块添加一个子模块。
可以使用给定的名称将该模块视为属性访问。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
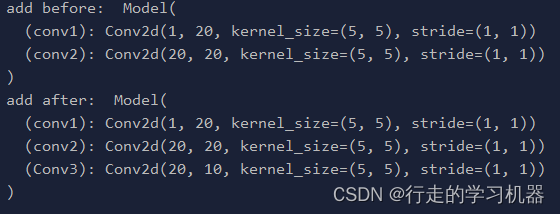
if __name__ == '__main__':
net = Model()
print("add before: ", net)
net.add_module("Conv3", nn.Conv2d(20, 10, 5))
print("add after: ", net)
2. apply(fn)
Parameters:
fn (Module -> None) :要应用于每个子模块的函数。
Returns:
self
Return type:
Module
递归地对每个子模块(由 .children() 返回)以及自身应用 fn 函数。典型的用途包括初始化模型的参数(参见 torch.nn.init)。

3. children()
Yields:
Module – a child module
Return type:
Iterator[Module]
返回一个迭代器,用于遍历当前模块的直接子模块。
4. cpu()和cuda()
cpu()
Returns
self
Return type
Module
移动所有的模型参数和缓冲区数据到CPU中。
该方法就地修改模型。
cuda(device=None)
Parameters:
device (int, optional) – 如果指定,所有的参数会被移动到指定设备
Returns:
self
Return type:
Module
移动所有的模型参数和缓冲区数据到GPU中
这还使关联的参数和缓冲区成为不同的对象。因此,如果模块将在被优化时存在于 GPU 上,则应在构建优化器之前调用此方法。
该方法就地修改模型。
5. eval()
Returns:
self
Return type:
Module
设置模块为评估模式。
这仅对特定的模块产生影响。查看特定模块的文档以了解其在训练/评估模式下的行为,例如 Dropout、BatchNorm 等。
这等效于 self.train(False)。
有关 .eval() 和一些可能与其混淆的类似机制之间的比较,请参阅链接: Locally disabling gradient computation。
6. forward(*input)
定义每次调用时执行的计算。所有子类都应该重写此方法。
注意:
虽然前向传播的计算步骤需要在这个函数内定义,但应该之后调用模块实例,而不是直接调用这个函数,因为前者会负责运行注册的钩子,而后者会默默地忽略它们。
7. get_parameter(target)
*Parameters:
target (str) – 要查找的参数的完全限定字符串名称。 (有关如何指定完全限定字符串的信息,请参阅 get_submodule。)
Returns:
由目标引用的参数
Return type:
torch.nn.Parameter
Raises:
AttributeError – 如果目标字符串引用无效路径或解析为不是 nn.Parameter 的内容。
如果存在,返回由target指定的参数;否则,抛出错误。
有关此方法功能的更详细解释以及如何正确指定目标的信息,请参阅 get_submodule 的文档字符串。
8. get_submodule(target)
Parameters:
target (str) – 要查找的子模块的完全限定字符串名称。 (请参阅上面的示例以了解如何指定完全限定字符串。)
Returns:
由目标引用的子模块
Return type:
torch.nn.Module
Raises:
AttributeError – If the target string references an invalid path or resolves to something that is not an nn.Module
如果存在,返回由target指定的子模块;否则,抛出错误。
例如,假设有如下的nn.Module A:
A(
(net_b): Module(
(net_c): Module(
(conv): Conv2d(16, 33, kernel_size=(3, 3), stride=(2, 2))
)
(linear): Linear(in_features=100, out_features=200, bias=True)
)
)
(图示一个 nn.Module A。A 具有嵌套的子模块 net_b,net_b 本身具有两个子模块 net_c 和 linear。net_c 然后具有子模块 conv。)
要检查我们是否有 linear 子模块,我们将调用 get_submodule(“net_b.linear”)。要检查我们是否有 conv 子模块,我们将调用 get_submodule(“net_b.net_c.conv”)。
get_submodule 的运行时受目标模块嵌套程度的限制。对 named_modules 的查询可以达到相同的结果,但其复杂度是相对于传递模块数量的 O(N)。因此,对于简单的检查是否存在某个子模块,应始终使用 get_submodule。
9. load_state_dict(state_dict, strict=True, assign=False)
*Parameters:
state_dict (dict) – 包含参数和持久缓冲区的字典。
strict (bool, optional) – 是否严格执行state_dict中的键与此模块的state_dict()函数返回的键完全匹配。默认值:True
assign (bool, optional) – 是否将状态字典中的项目分配给模块中相应的键,而不是将它们就地复制到模块的当前参数和缓冲区中。当为False时,保留当前模块中张量的属性,而当为True时,保留state dict中张量的属性。默认值:False
Returns:
missing_keys是包含缺少键的字符串列表
unexpected_keys是包含意外键的字符串列表
Return type:
具有missing_keys和unexpected_keys字段的命名元组
将参数和缓冲区从state_dict复制到此模块及其子模块中。如果strict为True,则state_dict的键必须与此模块的state_dict()函数返回的键完全匹配。
警告:
如果assign为True,则必须在调用load_state_dict之后创建优化器。
注意:
如果将参数或缓冲区注册为None并且其相应的键存在于state_dict中,load_state_dict()将引发RuntimeError。
10. modules()
生成:
Module – 网络中的一个模块
返回类型:
Iterator[Module]
返回网络中所有模块的迭代器。
注意:
重复的模块只返回一次。在以下示例中,l 只会被返回一次。

11. named_buffers(prefix=‘’, recurse=True, remove_duplicate=True)
Parameters:
prefix (str) – 要添加到所有缓冲区名称前面的前缀。
recurse (bool, optional) – 如果为True,则生成此模块及所有子模块的缓冲区。否则,仅生成此模块的直接成员的缓冲区。默认值为True。
remove_duplicate (bool, optional) – 是否在结果中删除重复的缓冲区。默认值为True。
Yields:
(str, torch.Tensor) – 包含名称和缓冲区的元组
Return type:
Iterator[Tuple[str, Tensor]]
返回模块缓冲区的迭代器,生成缓冲区的名称以及缓冲区本身。
for name, buf in self.named_buffers():
if name in ['running_var']:
print(buf.size())
12. named_children()
Yields:
(str, Module) – 包含模块名称和子模块的元组
Return type:
Iterator[Tuple[str, Module]]
返回对直接子模块的迭代器,生成模块的名称以及模块本身。
13. named_modules(memo=None, prefix=‘’, remove_duplicate=True)
*Parameters:
memo (Optional[Set[Module]]) – 一个备忘录,用于存储已添加到结果中的模块集合。
prefix (str) – 将添加到模块名称前面的前缀。
remove_duplicate (bool) – 是否在结果中删除重复的模块实例。
Yields:
(str, Module) –包含名称和模块的元组
返回网络中所有模块的迭代器,生成模块的名称以及模块本身。
注意:
重复的模块只返回一次。在以下示例中,l 只会被返回一次。

14. named_parameters(prefix=‘’, recurse=True, remove_duplicate=True)
Parameters:
prefix (str) – 要添加到所有参数名称前面的前缀。
recurse (bool) – 如果为True,则返回此模块及其所有子模块的参数。否则,仅返回此模块的直接成员参数。
remove_duplicate (bool, optional) – 是否在结果中删除重复的参数。默认为True。
Yields:
(str, Parameter) – 包含参数名称和参数的元组。
Return type:
Iterator[Tuple[str, Parameter]]
返回一个迭代器,该迭代器遍历模块参数,同时提供参数的名称和参数本身。
for name, param in self.named_parameters():
if name in ['bias']:
print(param.size())
15. parameters(recurse=True)
Parameters:
recurse (bool) – 如果为True,则返回此模块及其所有子模块的参数。否则,仅返回此模块的直接成员参数。
Yields:
Parameter – 模块参数
Return type:
Iterator[Parameter]
返回一个模块参数的迭代器。通常,此迭代器会被传递给优化器使用。

16. state_dict(*, prefix: str = ‘’, keep_vars: bool = False) → Dict[str, Any]
Parameters:
destination (dict, optional) – 如果提供,将模块的状态更新到字典中,并返回相同的对象。否则,将创建并返回一个 OrderedDict。默认值:None。
prefix (str, optional) – 添加到参数和缓冲区名称以组成 state_dict 键的前缀。默认值:‘’。
keep_vars (bool, optional) – 默认情况下,在 state dict 中返回的 Tensor 与 autograd 分离。如果设置为 True,则不会执行分离。默认值:False。
Returns:
包含模块整个状态的字典。
Return type:
dict
返回一个包含模块整个状态引用的字典。其中包括参数和持久缓冲区(例如运行平均值)。键是相应的参数和缓冲区名称。设置为 None 的参数和缓冲区不包括在内。
注意:
返回的对象是一个浅拷贝。它包含对模块参数和缓冲区的引用。
警告:
目前,state_dict() 还接受用于目标、前缀和保留变量的位置参数。然而,这已经过时,并且将在将来的版本中强制使用关键字参数。请避免使用destination 参数,因为它不是为最终用户设计的。

17. to(device: Optional[Union[int, device]] = …, dtype: Optional[Union[dtype, str]] = …, non_blocking: bool = …) → T
Parameters:
device (torch.device) – 模块中参数和缓冲区的期望设备。
dtype (torch.dtype) – 模块中参数和缓冲区的期望浮点数或复杂数的数据类型。
tensor (torch.Tensor) – 其数据类型和设备是模块中所有参数和缓冲区期望的数据类型和设备的张量。
memory_format (torch.memory_format) – 模块中4D参数和缓冲区的期望内存格式(关键字参数)。
Returns:
self
Return type:
Module
这个方法用于移动和/或转换模块的参数和缓冲区。
可以使用以下方式调用:
- to(device=None, dtype=None, non_blocking=False)
- to(dtype, non_blocking=False)
- to(tensor, non_blocking=False)
- to(memory_format=torch.channels_last)
方法类似于 torch.Tensor.to(),但仅接受浮点数或复杂数的数据类型。此外,该方法仅将浮点数或复杂数的参数和缓冲区转换为给定的 dtype(如果提供)。如果给定了 device,则将整数参数和缓冲区移动到该设备,但 dtype 保持不变。当设置了 non_blocking 时,它会尝试根据可能性在主机上异步转换/移动,例如,将具有固定内存的 CPU 张量移动到 CUDA 设备上。
注意:此方法会原地修改模块。

18. to_empty(*, device, recurse=True)
Parameters:
device (torch.device) – 该模块中参数和缓冲区的期望设备。
recurse (bool) – 是否应递归地将子模块的参数和缓冲区移动到指定设备。
Returns:
self
Return type:
Module
将参数和缓冲区移动到指定设备,而无需复制存储。
19. train(mode=True)
Parameters:
mode (bool) – 是否设置为训练模式(True)或评估模式(False)。默认值:True。
Returns:
self
Return type:
Module
将模块设置为训练模式。这仅对某些模块产生影响。如果受影响,例如 Dropout、BatchNorm 等,请参阅特定模块的文档,了解其在训练/评估模式下的行为详情。
20. type(dst_type)
Parameters:
dst_type (type or string) – 期望的类型
Returns:
self
Return type:
Module
将所有参数和缓冲区强制转换为dst_type。该方法会原地修改模型。
21. zero_grad(set_to_none=True)
*Parameters:
set_to_none (bool) – 是否将梯度设置为 None,而不是设置为零。详细信息请参阅 链接: torch.optim.Optimizer.zero_grad()
重置所有模型参数的梯度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【复现】金和 jc6协同管理平台 任意文件上传漏洞(2)_21
- 生产环境 OpenFeign 的配置最佳实践
- 自学黑客(网络安全)技术——高效学习
- ACL16_S 系列 低成本物联网安全芯片,可应用物联网认证、 SIM、防抄板和设备认证等产品上
- 【51单片机】动态数码管
- php composer安装
- 生成式 AI 如何重塑开发流程和开发工具
- 什么是SLAM中的回环检测,如果没有回环检测会怎样
- ubuntu常用命令
- 手把手教你制作微信图书小程序商城