【Pytorch】学习记录分享9——PyTorch新闻数据集文本分类任务实战
发布时间:2023年12月27日
【Pytorch】学习记录分享9——PyTorch新闻数据集文本分类任务
1. 认为主流程code
import time
import torch
import numpy as np
from train_eval import train, init_network
from importlib import import_module
import argparse
from tensorboardX import SummaryWriter
###制定参数 --model TextRNN
parser = argparse.ArgumentParser(description='Chinese Text Classification')
parser.add_argument('--model', type=str, required=True, help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')
parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained')
parser.add_argument('--word', default=False, type=bool, help='True for word, False for char')
args = parser.parse_args()
if __name__ == '__main__':
dataset = 'THUCNews' # 数据集
# 搜狗新闻:embedding_SougouNews.npz, 腾讯:embedding_Tencent.npz, 随机初始化:random
embedding = 'embedding_SougouNews.npz'
if args.embedding == 'random':
embedding = 'random'
model_name = args.model #TextCNN, TextRNN,
if model_name == 'FastText':
from utils_fasttext import build_dataset, build_iterator, get_time_dif
embedding = 'random'
else:
from utils import build_dataset, build_iterator, get_time_dif
x = import_module('models.' + model_name)
config = x.Config(dataset, embedding)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
start_time = time.time()
print("Loading data...")
vocab, train_data, dev_data, test_data = build_dataset(config, args.word)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# train
config.n_vocab = len(vocab)
model = x.Model(config).to(config.device)
writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))
if model_name != 'Transformer':
init_network(model)
print(model.parameters)
train(config, model, train_iter, dev_iter, test_iter,writer)
RNN
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
x, _ = x
out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
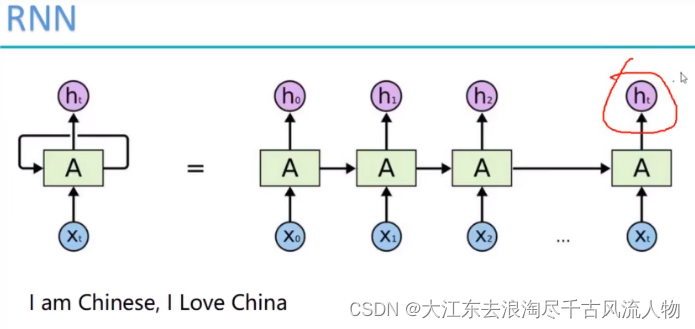
TextRNN h_t 为RNN提取出来的特征
2. NLP 对话和预测基本均属于分类任务详细见
Pytorch学习记录分享9-PyTorch新闻数据集文本分类任务实战
3. Tensorborad
数据可视化操作 code repo
文章来源:https://blog.csdn.net/Darlingqiang/article/details/135001407
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 影响代理IP稳定性的因素有哪些?
- JavaScript基础01
- Linux学习(1)——初识Linux
- 软件接口测试是什么?怎么测?
- 【HUAWEI】trunk和access两种链路模式实例
- 高并发场景下如何实现系统限流?
- 如果一款葡萄酒是“裸”的,这意味着什么?
- 【LeetCode: 155. 最小栈 + 栈 + 数据结构设计】
- MySQL主从复制与读写分离
- 【react项目开发遇到的问题记录】:The above error occurred in the <Route.Provider> component: