数据中台介绍
项目说明
srt-cloud 是采用 Vue3,Ts,Spring Cloud Alibaba、SpringSecurity、Spring Cloud Gateway、SpringBoot、Nacos、Redis、Mybatis-Plus,Tidb,Flink,Hadoop 等最新技术,开发的全新数睿通数据中台,包含数据集成(完成),数据开发(完成),数据治理,数据资产,数据服务,数据集市六大模块,解决数据孤岛问题,实现数据统一口径标准,自定义数据开发任务,帮助企业,政府等解决数据问题!
功能模块
目前全局管理,应用管理,日志管理,系统管理,数据集成,数据开发,数据服务几大模块已基本完毕
- 数据集成
- 数据库管理 — 管理用户添加的数据源,支持 MYSQL/ORACLE/SQLSERVER/POSTGRESQL/GREENPLUM/MARIADB/DB2/DM/OSCAR/KINGBASE8/OSCAR/GBASE8A/HIVE/SQLITE3/SYBASE,支持库表查询,测试连接等
- 文件管理 — 管理用户上传的文件数据
- 数据接入 — 接入外部数据源的数据到中台?ODS?层,也可自定义接入目的端数据源,支持一次性全量同步和周期性增量同步;可自定义表名,字段名的映射规则,支持正则表达式匹配;支持查看执行记录及详细执行结果,可查看同步的数据量,数据大小,成功表数量,失败表数量,成功信息,失败信息,也可查看具体每张表同步的数据量,数据大小,错误信息等,帮助用户全面掌握数据接入的执行情况
- 贴源数据 — 查看接入到ods层的数据表和数据,可查看每张表的同步记录
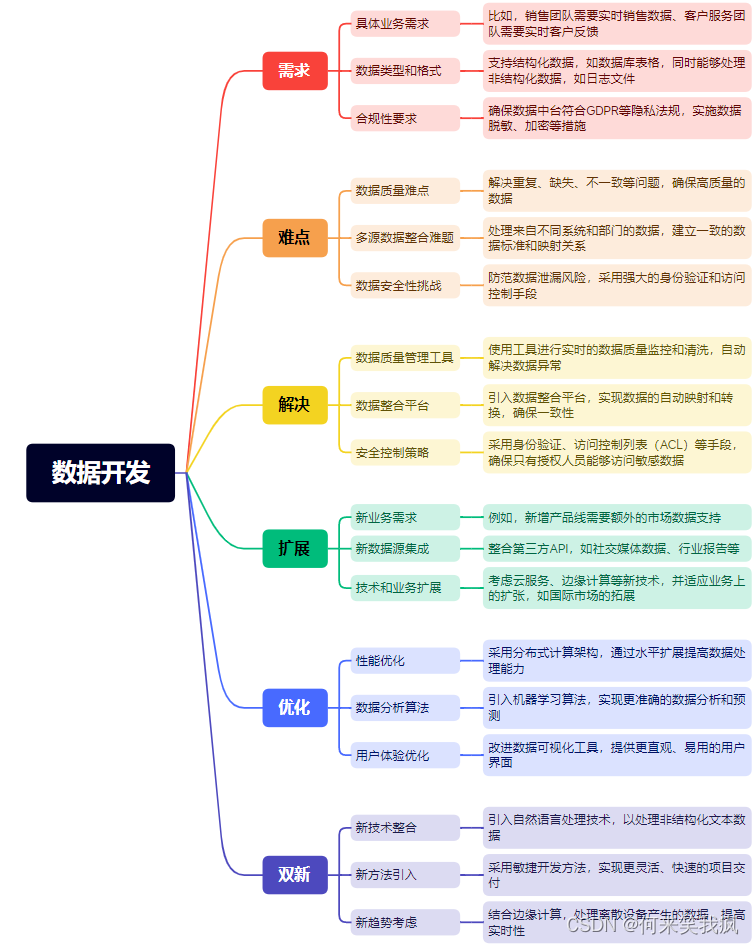
- 数据开发
- 数据生产 — 对数据进行作业代码化编辑,自行 DDL 建模,运行,调试等
- 调度中心
- 调度管理 — 对生产作业进行流程编辑,可视化调度
- 调度记录 — 查看调度结果,日志等
- 运维中心 — 对作业执行运维管理
- 资源中心
- Flink 集群实例 — 管理 FLink 资源
- Hadoop 集群配置 — 管理 Hadoop 资源
- 配置中心 — 管理 FlinkSql 执行配置
- 数据服务
- API 目录 — 用户自定义 API 目录,动态生成 API,对外提供服务
- API 权限 — 对私有 API 进行授权操作
- API 日志 — 查看 API 调用日志

- 数据治理
- 元数据
- 元模型 — 描述元数据的元数据,主要定义了元数据的属性,通常元模型都是系统内置的,如表元模型,字段元模型等
- 元数据采集 — 根据定义的元模型对元数据进行采集,通常是每一种元模型有自己内置的采集逻辑,可以设置采集周期等
- 元数据管理 — 对采集的元数据进行查看和管理
- 数据血缘 — 通过数据接入,数据生产流程之间的关系自动构建数据血缘关系图,追溯数据流向(开发中)
- 数据标准?
数据定义标准: 这包括定义数据元素、数据域、数据对象和其他数据相关的术语。确保组织中的人员都理解数据的含义,避免误解或混淆。
数据格式标准: 确定数据的存储和传输格式,以确保在不同系统之间的互操作性。这包括日期格式、数字格式、文本格式等。
命名约定标准: 确定数据元素、字段、表等对象的命名规则,以确保命名的一致性和可理解性。良好的命名约定有助于提高数据的可维护性和可理解性。
数据分类标准: 将数据分为不同的类别或类型,以便更好地组织和管理数据。这有助于确保对数据的正确使用和保护。
数据质量标准: 包括确保数据的准确性、完整性、一致性、可靠性和时效性等方面的规范。数据质量标准有助于提高决策的可信度和组织的效率。
元数据标准: 定义关于数据的信息,如数据的来源、含义、格式、拥有者等。元数据标准有助于更好地理解和管理数据资产。
安全和隐私标准: 确保在数据处理过程中符合相关法规和政策,以保护数据的安全性和隐私性。
交换标准: 确定数据在不同系统之间传递和共享的标准,以确保数据的无缝流动
- 数据质量
准确性: 数据准确性指数据的精度和正确性,即数据反映的是实际情况。准确的数据对于做出正确的决策至关重要。
完整性: 完整性关注数据的完整程度,确保数据没有缺失或遗漏。缺失的数据可能导致信息不完整,影响对问题或情境的全面理解。
一致性: 数据一致性指在不同的数据存储和处理环境中,数据的定义和值是一致的。一致性问题可能导致对同一实体或事务的多个视图之间存在差异。
可靠性: 可靠性涉及到数据的稳定性和可信度。可靠的数据能够在不同时间和条件下保持一致,不容易受到干扰或错误的影响。
时效性: 时效性关注数据的更新速度和数据的实效性。确保数据及时更新,以反映当前的业务状况。
可理解性: 数据可理解性指数据的表达方式是否易于理解,对用户而言是否具有可读性和清晰性。
合规性: 数据合规性确保数据的收集、存储和处理符合相关法规和政策,包括隐私保护、数据安全等方面的合规性

- 元数据
- 数据资产
- 资源管理 — 自定义资源目录,在每个目录下自定义资源,挂在数据库,api等
- 资产总览 — 对中台资源做一个总的统计概览

- 数据集市
- 资源目录 — 中台资源目录以及目录下资源的查看,可对资源进行申请操作
- API 目录 — 中台 API 目录以及目录下 API 的查看,可对 API 进行申请
- 我的申请 — 可以查看自己的申请记录,审批结果
- 服务审批 — 管理员对其他角色的申请做出审批,若审批通过,申请人便可以收到审批通过的消息,使用自己申请的服务资源
- 全局管理
- 数据项目管理 — 中台项目的管理,每个项目下可以关联用户,用户只能查看自己关联的项目下的数据,所有的模块数据都会有所属项目
- 数仓分层展示 — 对中台数仓的分成做展示说明
- 应用管理
- 消息管理
- 短信平台 — 集成短信平台,支持阿里,腾讯等常用的短信平台
- 短信日志 — 调用短信所产生的日志
- 消息管理
- 日志管理
- 登录日志 — 系统登录产生的日志
- 系统管理
- 用户管理 — 对系统用户进行管理
- 菜单管理 — 对系统菜单进行管理,用于实现动态菜单
- 定时任务 — 可自定义定时任务,调度执行
- 数据字典 — 系统的字典数据
- 机构管理 — 机构数据,若各模块中的数据有所属机构概念,可用于数据权限管理
- 岗位管理 — 岗位的管理
- 角色管理 — 角色管理,可以为每个角色自定义菜单查看权限以及机构级的数据权限
- 附件管理 — 系统附件管理,可以上传下载
定义
????????数据中台是一套可持续“让企业的数据用起来”的机制,是一种战略选择和组织形式,是依据企业特有的业务模式和组织架构,通过有形的产品和实施方法论支撑,构建的一套持续不断把数据变成资产并服务于业务的机制
????????数据中台是处于业务前台和技术后台的中间层,是对业务提供的数据能力的抽象和共享的过程,数据中台通过将企业的数据变成数据资产,并提供数据能力组件和运行机制,形成聚合数据接入、集成、清洗加工、建模处理、挖掘分析,并以共享服务的方式将数据提供给业务端使用,从而与业务产生联动,而后结合业务系统的数据生产能力,最终构建数据生产>消费>再生的闭环,通过这样持续使用数据、产生智能、反哺业务从而实现数据变现的系统和机制
系统数仓架构
该系统主要基于 Flink + TiDB 构建准实时数仓,进行数据同步,流转,计算和分析处理,下面是 Flink 和 TiDB 的相关说明:
Flink 是一个低延迟、高吞吐、流批统一的大数据计算引擎,被普遍用于实时性场景下的计算统计和分析。
在集成了 TiFlash 之后,TiDB 已经成为了真正的 HTAP(在线事务处理 OLTP + 在线分析处理 OLAP)数据库。换句话说,在实时数仓架构中,TiDB 既可以作为数据源的业务数据库,进行业务查询的处理;又可以作为实时 OLAP 引擎,进行分析型场景的计算。
结合了 Flink 与 TiDB 两者的特性,Flink+ TiDB 的方案的优势也体现了出来:首先是速度有保障,两者都可以通过水平扩展节点来增加算力;其次,学习和配置成本相对较低,因为 TiDB 兼容 MySQL 5.7 协议,而最新版本的 Flink 也可以完全通过 Flink SQL 和强大的连接器(connector)来编写提交任务,节省了用户的学习成本。
相比传统数仓(Hadoop + Hive ),除了进行常规的批量计算,还可以满足实时计算的需求。
数仓整体架构图如下:

关于数仓为什么要分层:分层可以有助于数据的管理,同时每次取数只需要获取统计分析过的成品就可以,不需要从源头数据反复计算,避免了计算资源的浪费,通常源头数据量较大,并且中间的处理逻辑较为复杂,所以采用建模分层的方式解决,通常表的前缀都用层级来定义。
系统核心技术栈
前台:
????????vue3
????????vite
????????typeScript
????????element-plus
????????pinia
后台:
????????Spring Cloud Alibaba
????????SpringSecurity
????????Spring Cloud Gateway
????????SpringBoot
????????Nacos
????????Redis
????????Mybatis-Plus
????????mysql8.0
????????tidb
????????flink
????????flink cdc
????????flink sql
更新后
?????????1.支持 MongoDB
????????????????????????新版数睿通的数据接入和数据生产模块添加了 MongoDB 的支持,数据接入可以选择 MongoDB 作为源端或者目的端进行数据同步操作。数据生产可以创建 MongoDB 类型的作业任务。现在的数据生产模块已经可以支持 Flink1.16,Flink1.16 官方已经支持 MongoDB 的连接器,所以在平台可以建立 MongoDB 类型的 FlinkSql 任务,提交到 Flink 集群或者 Yarn 上面执行,但具体效果还需要进一步测试,后续版本平台在建立数据生产任务的时候,将可以动态选择 Flink 版本执行相应的任务
????????2.支持 FlinkJar 任务
????????????????之前版本的数据生产支持 Sql 和 FlinkSql 两种任务类型,通过这两种方式可以完成大部分的实时和离线开发需求,但如果遇到复杂的业务,仅靠这两种方式显得有些力不从心,所以新版支持了 FlinkJar 类型的任务,通过数据开发人员编写任务代码,打成 Jar 包提交到平台,应对复杂的数据开发需求,当前支持提交任务到 Flink 集群或 Yarn 集群
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java内部类介绍和使用
- 计算机基础面试题 |01.精选计算机基础面试题
- 12.25~12.27并查集(查找与合并),全排列,约瑟夫问题(队列,数组)upper/lower_bound,重构二叉树,最优矩阵,线段树(构建),淘汰赛(构建树,队列),医院问题(最短路,弗洛伊德
- vue3 过渡动画
- vscode的debug的目录问题
- 每天一杯羊奶,让身体更健康
- test-02-java 单元测试框架 junit5 入门介绍
- 【后端那些事儿】Redis设计与实现(一) 数据结构,耐心看完你比Redis还懂Redis!
- Mysql配置服务器
- 美易官方:美股IPO有望大幅回暖!逾80家公司排队纳斯达克上市