基于数据库和NER构建知识图谱流程记录
文章目录
环境准备
本任务中知识图谱里的内容主要有两个来源,一个是数据库中的字段值,一个是从数据库中的描述字段中通过NER提取出的关键词。
因此,除了在服务器上安装neo4j图数据库环境,在本地安装py2neo包负责与图数据库间交互,还要安装pymysql包负责与数据库间交互,安装paddlenlp完成NER任务。
拓扑设计
从数据库中提取有用的信息,并对应于节点和关系,使用presson绘制出知识图谱的整体拓扑。其中蓝色为节点,黄色为不同节点间的关系(虚线为反向边),绿色同同一类型节点间的关系(基于相似性度量)。
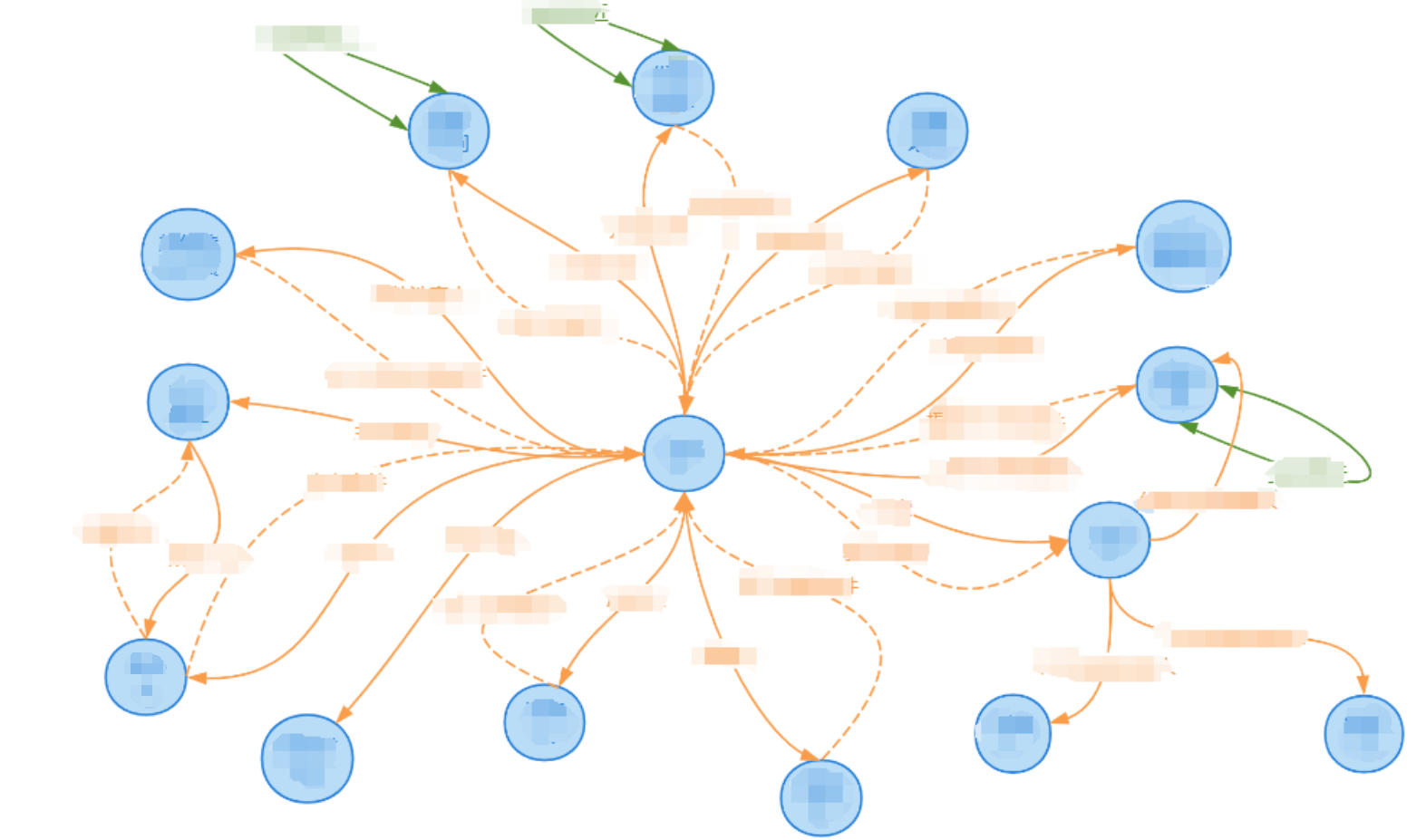
选中节点,点击数据属性,可以为不同节点添加属性,并记录其在数据库中的来源

构建流程设计
其实知识图谱的构建常常是节点和边同时构建的,但由于我们的数据量非常大,同时构建逻辑比较复杂,所以采取了先统一建节点,后统一建边的逻辑。
节点构建时有两个来源:一个是从数据库直接读取,一个是从数据库中的一个描述字段中通过NER提取关键词来构建。
边在构建时除了这两个来源,还有一种来源是同一类型节点间基于相似性计算出连边。
文件流设计
构建节点时,为了让流程更为清晰可控,首先根据预先定义的节点数据库CSV文件和NER解析JSON文件去生成节点数据CSV文件,再根据节点数据CSV文件去生成节点。
节点数据库CSV文件名为节点名称,内容包含数据库名、字段和属性三列,其中字段是数据库中的字段名,属性是节点中的属性名。
注意第一行的第三列必须是name,第二列如果以加号开头说明要确保字段的唯一性,下面是一个常规示例:
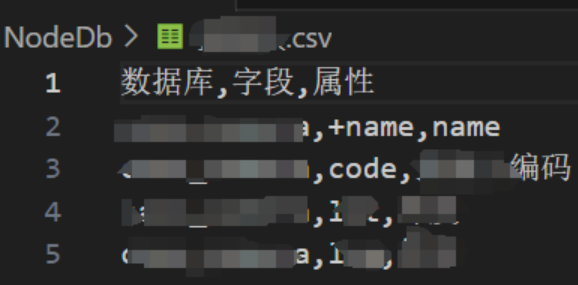
写这个文件时可以做一些骚操作,例如在字段中将SQL语句融入进去,比如说我想构建一个坐标节点,其名字为“坐标X,坐标Y”,这个文件的后两列就可以写成:"+CONCAT_WS(',', zbx, zby)",name。
节点数据CSV文件,第一列是name,后面是其他属性,相当于把上面的节点数据库CSV文件横过来。以坐标节点为例:

构建边时,首先根据预先定义的关系数据库CSV文件和NER解析JSON文件以及相似性计算算法去生成关系数据CSV文件,再根据关系数据CSV文件去生成边。
关系数据库CSV文件名为关系名称,内容只有一行,包含数据库,起点字段,起点label,起点所用属性,终点字段,终点label,终点所用属性这几列。其中label指的是头实体和尾实体的节点类型,属性是查询时用到的属性。
关系数据CSV文件,列数不固定,第一部分是连接时用到的头实体节点属性,形如name1, axx1, bxx1,...;第二部分是连接时用到的尾实体节点属性,形如name2, axx2, bxx2, ...;最后两列固定为label1, label2,对应头实体节点类型和尾实体节点类型,以时间相似的关系为例:

交互解析算法实现
为了将数据库中字段解析为知识图谱的内容,需要完成以下几部分的功能:一是直接与数据库交互,二是通过NER解析文本描述内容,三是计算时间和地点间的相似度。
数据库交互
定义下述数据库交互类,输入SQL查询语句后将返回结果封装为dataframe。
import pymysql
import pandas as pd
class SQLSelector:
def __init__(self):
# 初始化数据库连接
self.db_config = {
'host':'',
'user':'',
'password':'',
'db':'',
'charset':'utf8'
}
self.cursor, self.connection = self.connect_db()
def connect_db(self):
try:
connection = pymysql.connect(**self.db_config)
cursor = connection.cursor()
return cursor, connection
except Exception as e:
print(f"Error connecting to the database: {e}")
raise
def close_db(self):
try:
self.cursor.close()
self.connection.close()
except Exception as e:
print(f"Error closing the database connection: {e}")
def __del__(self):
# 关闭数据库连接
self.close_db()
def execute_db(self, sql_query):
# 返回执行状态和结果
try:
self.cursor.execute(sql_query)
execute_result = pd.DataFrame(self.cursor.fetchall(), columns=[desc[0] for desc in self.cursor.description])
execute_state = True
except Exception as e:
execute_result = str(e)
execute_state = False
return execute_state, execute_result
NER解析
定义下列文本解析类,由于没有经过训练,直接使用paddlenlp做解析,并把结果保存为json,因此结果不是很准确,后续需要后处理,下面的代码做了脱敏处理。
from paddlenlp import Taskflow
import pandas as pd
import json
from utils import write_json_file, read_json_file, is_id_card, count_elements_in_nested_list
from tqdm import tqdm
tqdm.pandas()
class PaddleNLP:
def __init__(self):
self.ner_file_path = "./Data/NER_data"
def paddle_ner(self, batch_size, input_list):
ner = Taskflow("ner", batch_size=batch_size)
print("start NER")
result_list = ner(input_list)
return result_list
def paddle_ie(self, batch_size, input_list, schema):
ner = Taskflow("knowledge_mining", batch_size=batch_size)
print("start IE")
result_list = ner(input_list)
return result_list
def ner_data_save(self, path):
ner_source_data = pd.read_json(path)
ner_source_data[''] = ner_source_data[''].fillna("此处为空")
input_list = ner_source_data[""].tolist()
ner_result_list = self.paddle_ner(batch_size=50, input_list=input_list)
write_json_file(self.ner_file_path + "./ner_result_no_na.json", ner_result_list)
def ie_data_save(self, path):
ner_source_data = pd.read_json(path)
ner_source_data[''] = ner_source_data[''].fillna("此处为空")
input_list = ner_source_data[""].tolist()[0:100]
schema = []
ner_result_list = self.paddle_ie(batch_size=10, input_list=input_list, schema=schema)
print(ner_result_list)
def combine_ner_data(self, ner_path, source_data_path):
ner_data = read_json_file(ner_path)
print(len(ner_data))
source_df = pd.read_json(source_data_path)
print(len(source_df) - len(ner_data))
source_df["ner_result"] = ner_data
output_file_path = self.ner_file_path + '/ner_data.json'
source_df.to_json(output_file_path, force_ascii=False, orient='records')
def analysis_ner_data(self, data_path):
ner_df = pd.read_json(data_path)
results = ner_df.progress_apply(combined_entity_check, axis=1)
ner_df[''] = results['']
ner_df[''] = results['']
ner_df.drop('ner_result', axis=1, inplace=True)
output_file_path = self.ner_file_path + '/updated_ner_data.json'
ner_df.to_json(output_file_path, force_ascii=False, orient='records')
def check_data(self, data_path):
ner_data = pd.read_json(data_path)
qtr_xm = ner_data["qtr_xm"]
print(count_elements_in_nested_list(qtr_xm))
def combined_entity_check(row):
# 提取人物类实体
human_entities = set(item[0] for item in row['ner_result'] if item[1] == '人物类_实体')
xy = row[''].split(',') if row[''] else []
sa = row[''].split(',') if row[''] else []
check_result = []
qtr_xm = []
return pd.Series([check_result, qtr_xm], index=['check_result', 'qtr_xm'])
if __name__ == "__main__":
paddle_nlp = PaddleNLP()
ner_data_path = paddle_nlp.ner_file_path + "/updated_ner_data.json"
source_data_path = paddle_nlp.ner_file_path + "/ner_source.json"
paddle_nlp.check_data(ner_data_path)
相似度计算
基于KD-Tree计算坐标和时间相似度
def filter_coordinate_nodes(nodes, label, threshold_distance=0.02):
print("计算坐标相似度中...")
coordinates = np.array([
(float(node[1]), float(node[2]))
for node in nodes
if node[1] != "NULL" and node[2] != "NULL"
])
# Build KD-tree
kdtree = cKDTree(coordinates)
# Query pairs within the threshold distance
pairs = kdtree.query_pairs(threshold_distance, output_type='ndarray')
unique_pairs = set()
for i, j in pairs:
pair = (min(nodes[i][0], nodes[j][0]), max(nodes[i][0], nodes[j][0]), label, label)
unique_pairs.add(pair)
print("计算坐标相似度完成!")
return list(unique_pairs)
def filter_time_nodes(nodes, label, threshold=21600):
print("Calculating time similarity...")
# Extract timestamps from nodes
timestamps = np.array([
int(datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S').timestamp())
if time_str.strip() and time_str.strip() != "NULL"
else None
for time_str in nodes
])
# Build KD-tree
kdtree = cKDTree(timestamps.reshape(-1, 1))
# Query pairs within the threshold time difference
pairs = kdtree.query_pairs(threshold, output_type='ndarray')
unique_pairs = set()
for i, j in pairs:
pair = (min(nodes[i], nodes[j]), max(nodes[i], nodes[j]), label, label)
unique_pairs.add(pair)
print("Time similarity calculation completed!")
return list(unique_pairs)
经过比较,其运行速度不如下面这种矩阵运算
def filter_coordinate_nodes(nodes, label, threshold_distance=0.001):
print("计算坐标相似度中...")
# 提取坐标信息并转换为NumPy数组
coordinates = []
for node in nodes:
if node[1] != "NULL" and node[2] != "NULL":
x_str = re.sub("[^0-9.]", "", str(node[1]))
y_str = re.sub("[^0-9.]", "", str(node[2]))
if x_str and y_str: # 确保字符串不为空
coordinates.append((float(x_str), float(y_str)))
coordinates = np.array(coordinates)
# 使用广播计算两两之间的绝对值距离
unique_pairs = set()
for i in tqdm(range(len(coordinates)), desc="相似度计算"):
# 计算点i与其他所有点的距离
distances = np.sqrt(np.sum((coordinates - coordinates[i]) ** 2, axis=1))
# 找到距离小于阈值的点
close_points = np.where(distances < threshold_distance)[0]
# 避免将点i与自身比较
close_points = close_points[close_points != i]
for j in close_points:
pair = (min(nodes[i][0], nodes[j][0]), max(nodes[i][0], nodes[j][0]), label, label)
unique_pairs.add(pair)
print("计算坐标相似度完成!")
return list(unique_pairs)
def filter_time_nodes(nodes, label, threshold=10800):
print("计算时间相似度中...")
placeholder = -1
# 将时间字符串转换为时间戳,对于无效值使用占位符
timestamps = np.array([
int(datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S').timestamp())
if time_str.strip() and time_str.strip() != "NULL"
else placeholder # 使用占位符代替 None
for time_str in nodes
])
# 使用广播计算两两之间的距离
unique_pairs = set()
# 使用 tqdm 包裹您的循环来显示进度条
for i in tqdm(range(len(timestamps)), desc="计算进度"):
if timestamps[i] is not None:
# 计算时间点 i 与其他所有时间点的差异
distances = np.abs(timestamps - timestamps[i])
# 找到小于阈值且不是自己的时间点
close_points = np.where((distances < threshold) & (distances != 0))[0]
for j in close_points:
pair = (min(nodes[i], nodes[j]), max(nodes[i], nodes[j]), label, label)
unique_pairs.add(pair)
print("计算时间相似度完成!")
return list(unique_pairs)
基于数据库的文件生成
下面是根据生成节点和关系数据库CSV文件去生成数据CSV文件的部分,基于NER和基于相似度的文件生成逻辑与之类似,在此略过。
从数据库中读取字段
import os
import pandas as pd
class DbInfoReader:
def __init__(self):
# 数据库CSV文件存放路径
self.node_file_path = "./NodeDb"
self.rel_file_path = "./RelDb"
# 必要时只对filter里面的做更新
self.node_filter = []
def generate_node_info(self):
node_files = os.listdir(self.node_file_path)
for node_file in node_files:
node_db_dict = {}
df = pd.read_csv(os.path.join(self.node_file_path, node_file), index_col=False)
# CSV文件名代表节点label,第一列是数据库名,第二列是数据库字段,第三列是对应属性名
# 注意第一行的第三列必须是name
# 第二列如果以加号开头说明要确保该字段的唯一性
assert df.iloc[0,2] == "name"
label = os.path.splitext(os.path.basename(node_file))[0]
if len(self.node_filter) == 0 or label in self.node_filter:
for _, row in df.iterrows():
# 转化为字典
data_dict = row.to_dict()
key_name = data_dict.pop('数据库')
if key_name not in node_db_dict:
node_db_dict[key_name] = {}
node_db_dict[key_name][data_dict['字段']] = data_dict['属性']
yield label, node_db_dict
def generate_rel_info(self):
rel_files = os.listdir(self.rel_file_path)
for rel_file in rel_files:
# CSV格式:库,起点字段,起点label,起点所用属性,终点字段,终点label,终点所用属性
df = pd.read_csv(os.path.join(self.rel_file_path, rel_file), index_col=False)
label = os.path.splitext(os.path.basename(rel_file))[0]
for _, row in df.iterrows():
# 转化为字典
data_dict = row.to_dict()
yield label, data_dict
if __name__ == "__main__":
dbinforeader = DbInfoReader()
dbinforeader.generate_rel_info()
将字段后处理后保存为文件
from SQLSelector import *
from DbInfoReader import *
from utils import generate_sql_dict, read_json, is_name
from tqdm import tqdm
class DbInfoSaver:
def __init__(self):
# 属性CSV文件存放路径
self.node_file_path = "./NodeFile"
self.rel_file_path = "./RelFile"
self.ner_file_path = "./Data/NER_data"
self.split_files = []
self.delete_unknown_files = []
self.dbinforeader = DbInfoReader()
self.sqlselector = SQLSelector()
self.sql_dict = generate_sql_dict()
def save_node_file_in_sql(self):
# 节点来源一:从数据库里直接建节点
for label, node_db_dict in self.dbinforeader.generate_node_info():
data = pd.DataFrame()
for db, pair in node_db_dict.items():
# 添加唯一约束
columns = []
for db_name, node_name in pair.items():
ddb_name = db_name
if db_name[0] == "+":
ddb_name = "DISTINCT " + db_name[1:]
columns.append("{} AS {}".format(ddb_name, node_name))
column_str = ", ".join(columns)
sql_query = "SELECT {} FROM {}".format(column_str, db)
results = self.sqlselector.execute_db(sql_query)[1]
data = pd.concat([data, results], ignore_index=True)
# 使用字典对字段值做映射,异常值映射为未知
if label in self.sql_dict:
for col, dic in self.sql_dict[label].items():
data[col] = data[col].map(lambda x: dic.get(x, '未知'))
# print(col, set(data[col]))
# 对多值情况做分割
if label in self.split_files:
new_df = data['name'].str.split(',', expand=True).reset_index(drop=True).drop_duplicates().stack().reset_index(drop=True).drop_duplicates()
new_df = pd.DataFrame(new_df)
new_df.columns = ["name"]
data = new_df
# 对每一列删除多余空格
for col in data.columns:
data[col] = data[col].apply(lambda x: x.strip() if isinstance(x, str) else x)
data = data.drop_duplicates(subset = data.columns).reset_index(drop=True)
# 删除每行全部未知的节点
if label in self.delete_unknown_files:
cols_to_check = data.columns[1:]
to_drop = data[cols_to_check].eq('未知') | data[cols_to_check].isna() | data[cols_to_check].eq('')
data = data[~to_drop.all(axis=1)]
data.to_csv(os.path.join(self.node_file_path, f"{label}.csv"), index=False)
def save_rel_file_in_sql(self):
# 关系来源一:从数据库里直接建关系
for label, rel_db_dict in tqdm(self.dbinforeader.generate_rel_info()):
# 构建起点和终点的 SELECT 子句
start_column = "{} AS {}".format(rel_db_dict['起点字段'], rel_db_dict['起点所用属性']+'1')
end_column = "{} AS {}".format(rel_db_dict['终点字段'], rel_db_dict['终点所用属性']+'2')
# 构建 SQL 查询语句
sql_query = "SELECT DISTINCT {}, {} FROM {}".format(start_column, end_column, rel_db_dict['库'])
# 执行 SQL 查询
results = self.sqlselector.execute_db(sql_query)[1]
results['label1'] = rel_db_dict['起点label']
results['label2'] = rel_db_dict['终点label']
# 对每一列删除多余空格
for col in results.columns:
results[col] = results[col].apply(lambda x: x.strip() if isinstance(x, str) else x)
results = results.drop_duplicates(subset=results.columns).reset_index(drop=True)
# 保存结果到 CSV 文件
results.to_csv(os.path.join(self.rel_file_path, f"{label}.csv"), index=False)
if __name__ == "__main__":
dbinfosaver = DbInfoSaver()
dbinfosaver.save_node_file_in_sql()
基于文件的知识图谱构建
在生成了节点和关系的数据CSV文件之后,直接读取文件内容并生成知识图谱中的节点和关系,全流程走完。
import pandas as pd
from py2neo import Graph, Node, NodeMatcher, Relationship
import os
from tqdm import tqdm
import logging
# Set up logging configuration
logging.basicConfig(filename='error_log.txt', level=logging.ERROR)
class GraphGenerator:
def __init__(self) -> None:
self.node_file_path = "./NodeFile"
self.rel_file_path = "./RelFile"
self.graph = Graph("http://localhost:7474", auth=("neo4j", "123456"), name='neo4j')
def generate_nodes_list(self, csv_file_path):
"""
将节点CSV文件中的数据导入到图数据库中
:param graph: 图数据库
:param csv_file_path: csv文件的路径
"""
# 读取CSV文件
df = pd.read_csv(csv_file_path, index_col=False)
# df.dropna(subset=['name'], inplace=True)
df.fillna("NULL", inplace=True)
nodes = []
label = os.path.splitext(os.path.basename(csv_file_path))[0]
# 遍历数据,将数据导入到图数据库中
for _, row in tqdm(df.iterrows(), total=len(df), desc="Processing Rows"):
# 转化为字典
data_dict = row.to_dict()
# 创建一个节点并添加到列表中
node = Node(label, **data_dict)
nodes.append(node)
return nodes
def generate_relationship_list(self, graph: Graph, csv_file_path):
"""
将边CSV文件中的数据导入到图数据库中
:param graph: 图数据库
:param csv_file_path: csv文件的路径
"""
# 读取CSV文件
df = pd.read_csv(csv_file_path, index_col=False)
df.fillna("NULL", inplace=True)
relationship_label = os.path.splitext(os.path.basename(csv_file_path))[0]
start_label = df['label1'][0]
end_label = df['label2'][0]
start_keys = [x for x in list(df.columns[0:-2]) if x[-1] == '1']
node_start_keys = [x[:-1] for x in start_keys]
end_keys = [x for x in list(df.columns[0:-2]) if x[-1] == '2']
node_end_keys = [x[:-1] for x in end_keys]
# 预先加载所有需要的节点,实现节点的大小写不敏感快速匹配算法
start_nodes = list(NodeMatcher(graph).match(start_label))
end_nodes = list(NodeMatcher(graph).match(end_label))
start_nodes_map = {tuple(node[key].lower() if isinstance(node[key], str) else node[key] for key in node_start_keys): node for node in start_nodes}
end_nodes_map = {tuple(node[key].lower() if isinstance(node[key], str) else node[key] for key in node_end_keys): node for node in end_nodes}
# 创建一个空的关系列表
relationships = []
# 遍历数据,将数据导入到图数据库中
for _, row in tqdm(df.iterrows(), total=len(df), desc="Processing Rows"):
# 转化为字典
data_dict = row.to_dict()
# 查询节点
start_node = start_nodes_map.get(tuple(data_dict[key].lower() if isinstance(data_dict[key], str) else data_dict[key] for key in start_keys))
end_node = end_nodes_map.get(tuple(data_dict[key].lower() if isinstance(data_dict[key], str) else data_dict[key] for key in end_keys))
# 未找到相关节点
if start_node is None or end_node is None:
error_message = f"Error: Node not found for relation {data_dict}"
print(error_message) # This will print the error message to the console
logging.error(error_message)
continue
# 创建关系并添加到关系列表
relationship = Relationship(start_node, relationship_label, end_node)
relationships.append(relationship)
return relationships
def create_nodes_or_relationships(self, graph: Graph, nodes_or_relations):
batch_size = 10000
for batch in [nodes_or_relations[i:i+batch_size] for i in range(0, len(nodes_or_relations), batch_size)]:
tx = graph.begin()
for data in batch:
tx.create(data)
graph.commit(tx)
def generate_all(self, mode='all'):
"""
根据指定的模式生成节点、关系或两者。
参数:
- mode (str): 指定操作模式。'all' 生成节点和关系,'node' 仅生成节点,'rel' 仅生成关系。
返回:
无
"""
if mode in ['all', 'node']:
# 遍历节点文件夹下的所有节点文件
# 每次先清空图数据库
self.graph.delete_all()
for node_file in tqdm(os.listdir(self.node_file_path), desc="处理节点csv中:"):
if node_file.endswith(".csv"):
csv_path = os.path.join(self.node_file_path, node_file)
nodes = self.generate_nodes_list(csv_path)
self.create_nodes_or_relationships(graph=self.graph, nodes_or_relations=nodes)
if mode in ['all', 'rel']:
# 遍历边文件夹下的所有边文件
# 每次先清空所有边
if mode == 'rel':
rel_types = self.graph.schema.relationship_types
for rel_type in rel_types:
query = f"MATCH (n)-[r:{rel_type}]-(m) DELETE r"
self.graph.run(query)
for edge_file in tqdm(os.listdir(self.rel_file_path), desc="处理边csv中:"):
if edge_file.endswith(".csv"):
csv_path = os.path.join(self.rel_file_path, edge_file)
relationships = self.generate_relationship_list(self.graph, csv_path)
self.create_nodes_or_relationships(graph=self.graph, nodes_or_relations=relationships)
if __name__ == "__main__":
graph_generator = GraphGenerator()
graph_generator.generate_all(mode='node')
print(graph_generator)
进入浏览器后查看,知识图谱建立成功!

bug修改与算法优化
图数据库连接问题
一开始使用Graph("http://localhost:7474", auth=("neo4j", "123456"))连接图数据库,在执行tx = graph.begin()这句会报错
py2neo.errors.ProtocolError: Cannot decode response content as JSON
连接的时候加上name参数就好了。
批量构建知识图谱问题
构建函数的实现一开始为:
def create_nodes_or_relationships(self, graph: Graph, nodes_or_relations):
tx = graph.begin()
for node_or_relation in nodes_or_relations:
tx.create(node_or_relation)
graph.commit(tx)
这样会导致下列两种问题
py2neo.errors.ProtocolError: Cannot decode response content as JSON
[Transaction.TransactionNotFound] Unrecognized transaction id. Transaction may have timed out and been rolled back.
如果改成下面这种一个一个建,就不会报错,所以分析应该是一次建立的节点或关系太多了:
def create_nodes_or_relationships(self, graph: Graph, nodes_or_relations):
for node_or_relation in nodes_or_relations:
tx = graph.begin()
tx.create(node_or_relation)
graph.commit(tx)
为了加速,改成了现在这种一次批量建10000个的方法。
批量删除边问题
由于建边时出了一点问题,试图将所有边删除,删边语句一开始为"MATCH ()-[r]-() DELETE r',会导致下列错误:
py2neo.errors.DatabaseError: [Statement.ExecutionFailed] Java heap space
应该是边的数量太多了,所以我改成现在这种,每次删除一类边。
空值处理问题
图数据库中节点的属性不能为空值,解决方法是将CSV数据文件的空值替换为"NULL",也就是这句:
df.fillna("NULL", inplace=True)
去重时的大小写问题
- 数据库中使用DISTINCT关键词去重,这是大小写不敏感的,无法区分大写和小写字母
- dataframe数据使用drop_duplicates方法去重,这是大小写敏感的
当这两种方法同时用于生成数据文件,就会造成不匹配问题,后来通过在节点匹配时加入lower()方法统一转换为小写解决。
加速构建边优化
在构建边的时候,首先要找到对应的头实体和尾实体,之前的匹配算法是使用了内置的全局匹配
matcher = NodeMatcher(graph)
start_node = matcher.match(data_dict['label1'], **start_property).first()
end_node = matcher.match(data_dict['label2'], **end_property).first()
这样跑是能跑,但是速度会非常慢,因为每次都从所有的节点里面找。我们可以观察到,对某种特定的关系,头实体和尾实体都属于某种特定的节点类型,因此可以先把所有这一类型的节点存到一个字典里,再在这个字典里做匹配,这也是目前实现的算法。
将属性修改为节点
这个任务的需求是之前将一个字段建立为了某类节点的一个属性,现在想把它拿出来,作为单独的一类节点使用。考虑到任务量不多,这里采取了节点和关系同时建立的策略。
def generate_new_kg(self):
# 尝试将属性抽离为节点
new_nodes = list(NodeMatcher(self.graph).match('xx'))
node_dict = {}
edge_list = []
for new_node in tqdm(new_nodes, '根据属性构建新的节点和关系'):
node = new_node['xxx']
if node not in node_dict:
node_dict[node] = Node('案件类型', name=node)
edge_list.append(Relationship(node_dict[node], 'xxxx', new_node))
subgraph = Subgraph(list(node_dict.values()), edge_list)
tx = self.graph.begin()
tx.create(subgraph)
self.graph.commit(tx)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mysql 中的常用命令
- 【Java万花筒】通往高效通信的道路:揭秘Java网络库的奥秘
- 项目管理:风险的来源及管理方法
- Leetcode 53 最大子数组和
- Day01-Vue
- 实现Android设备蓝牙之间的自动配对
- 机器学习算法实战案例:VMD-LSTM实现单变量多步光伏预测
- 接口测试用例设计 - 实战篇
- [精品毕设]基于Uniapp+springboot心灵伴侣管理系统App征婚交友会员
- 三、MySQL之创建和管理表