爬虫之牛刀小试(四):爬取B站番剧的简介
发布时间:2024年01月13日
今天爬取的是b站。
如何爬取b站中的番剧呢?
首先我们来到番剧索引中,随便点开一部动漫,检查代码。
每个作品对应一个链接: https://www.bilibili.com/bangumi/play/ss…(ss后面的数字称为ss号)
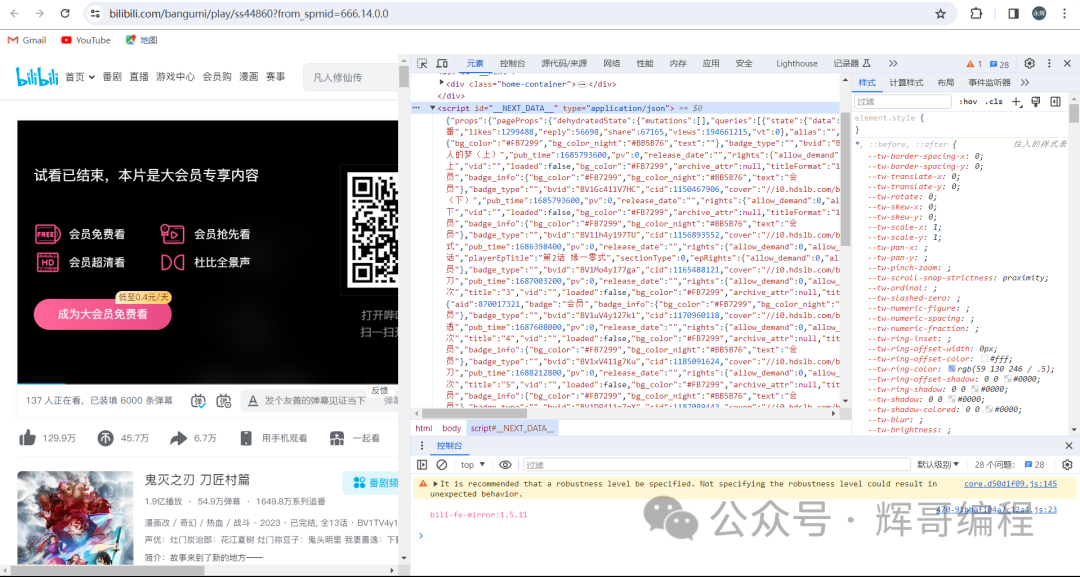
发现关于动漫的信息在这里
‘script’, id=“NEXT_DATA”

关键是如何获取ss号?
随便乱找一下,发现有media_id,于是点进去看一下
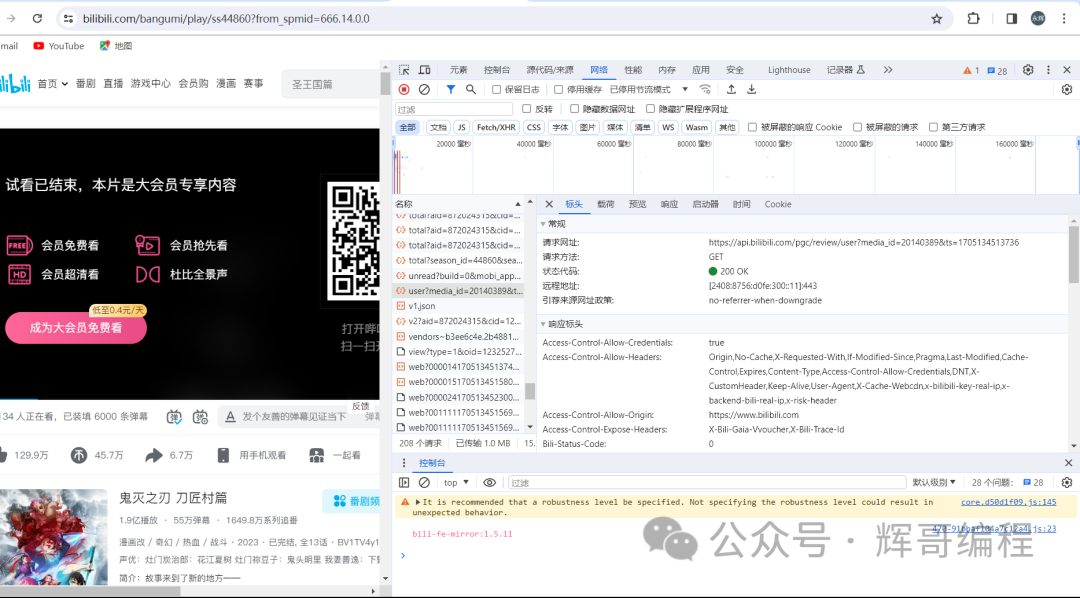
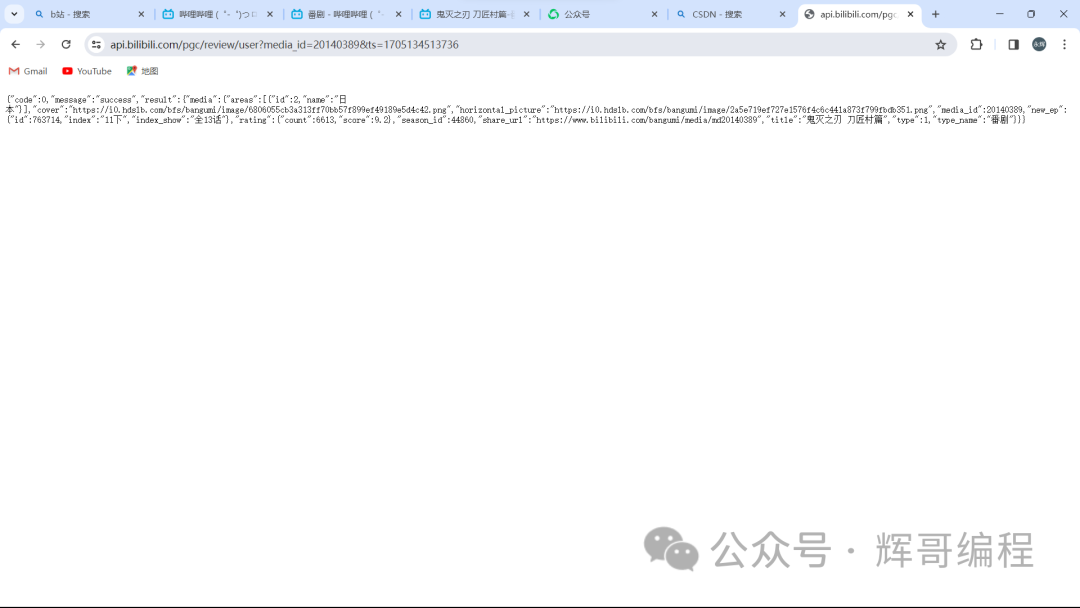
于是肯定了对应的api接口:api.bilibili.com /pgc/review/user?media_id=…&ts=…
这样子就解决了如何爬取每部番剧的网址了。
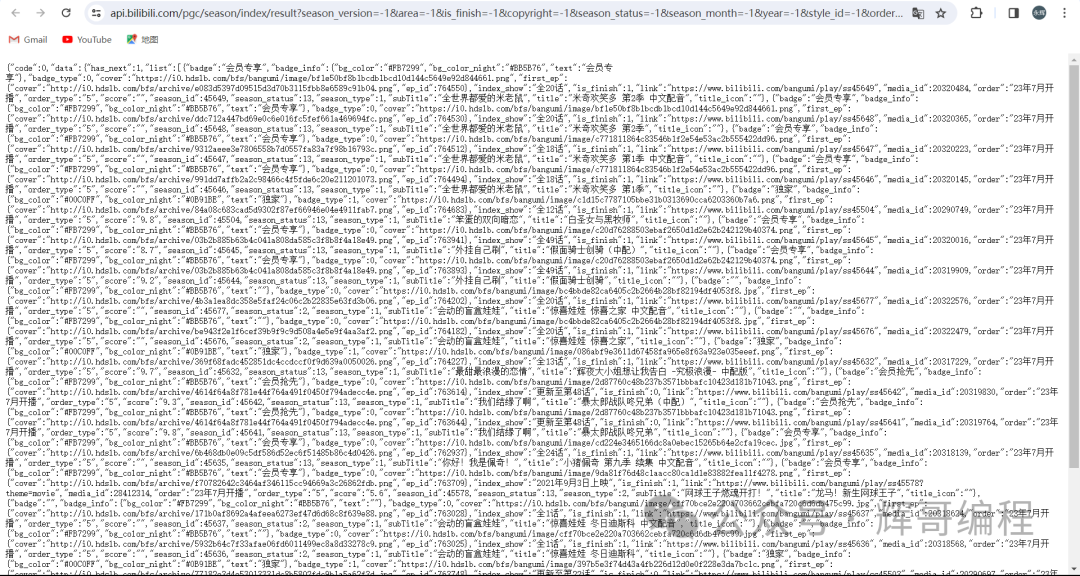
获取每部番剧的title和url就行,接着只要匹配获取简介的内容就行了。
其返回的是一个json字典。
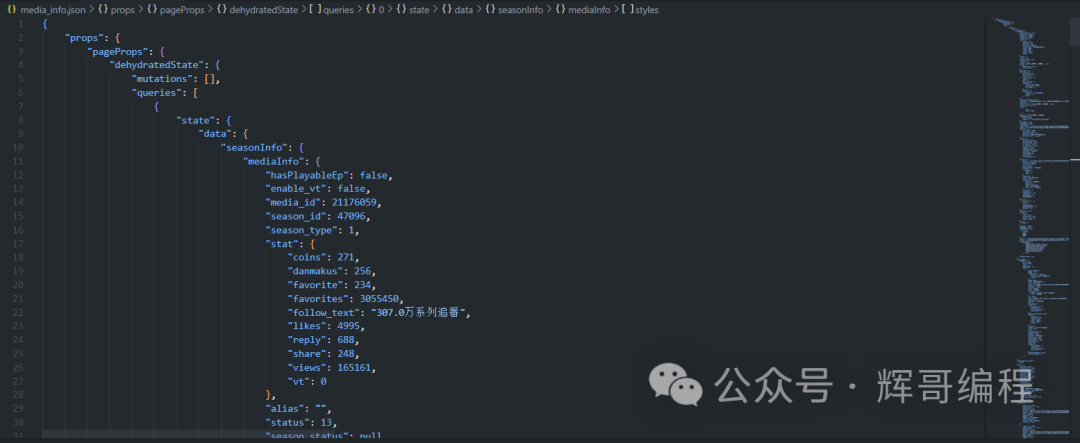
我们只要选出我们感兴趣的内容,比如配音演员,硬币等内容。
最后保存在xlsx文件即可。
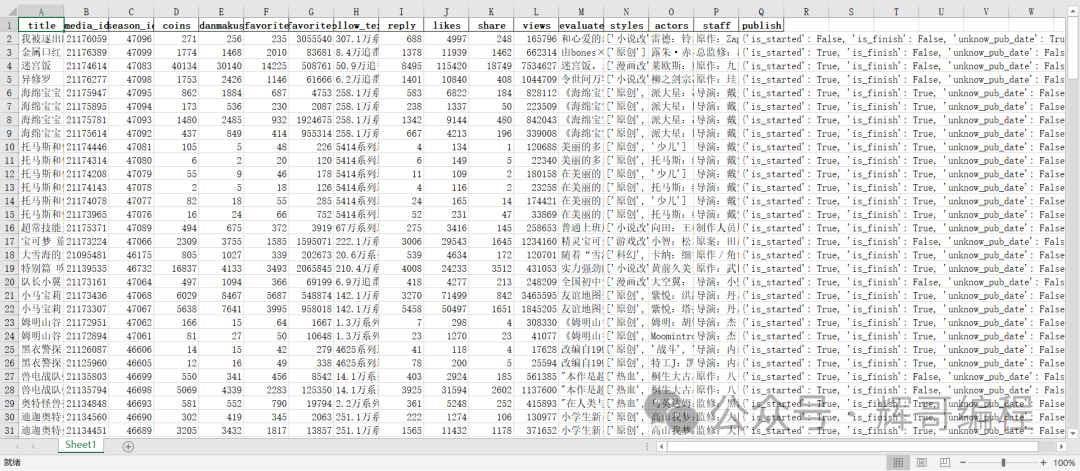
奉上代码如下所示:
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup as bs
import urllib.request as ur
import urllib.parse as up
import urllib.error as ue
import http.cookiejar as hc
import re
import gzip
import json
import time
import os
import socket
os.chdir(r'...')
socket.setdefaulttimeout(30)
cookie=''
### 配置爬虫条件 ###
# 设置请求头
# api请求头
apiheaders={
'Host': 'api.bilibili.com',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'Accept':' application/json, text/plain, */*',
'Sec-Fetch-Dest': 'empty',
'User-Agent': '',
'Origin': 'https://www.bilibili.com',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'document',
'Referer': 'https://www.bilibili.com/anime/index/',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie':cookie
}
# 网页请求头
wwwheaders={
'Host': 'www.bilibili.com',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': '',
'Sec-Fetch-Dest': 'document',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Referer': 'https://www.bilibili.com/anime/index/',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie':cookie
}
# 图片请求头
imageheaders={
'Host': 'i0.hdslb.com',
'Connection': 'keep-alive',
'User-Agent': '',
'Sec-Fetch-Dest': 'image',
'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'no-cors',
'Referer': 'https://www.bilibili.com/bangumi/media/md1178/?from=search&seid=17806546061422186816',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
# 创建cookiejar对象
cj=hc.CookieJar()
# 根据cookiejar创建handler对象
hl=ur.HTTPCookieProcessor(cj)
# 根据handler创建opener对象
opener=ur.build_opener(hl)
### 爬取ss号 ##
# 番剧区索引
def ssdownload():
sslist=list()
pattern=re.compile(r'https://www.bilibili.com/bangumi/play/ss\d+')
pattern2=re.compile(r'"title":"(.*?)"')
for i in range(1,11):
url='https://api.bilibili.com/pgc/season/index/result?season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&order=5&st=1&sort=0&page='+str(i)+'&season_type=1&pagesize=20&type=1'
print('正在获取第'+str(i)+'页番剧信息')
print(url)
try_time=0
while try_time<=5:
try:
r=ur.Request(url=url,headers=apiheaders)
response=opener.open(r)
break
except ue.HTTPError as e:
print('网页不存在...跳过')
break
except Exception as e:
try_time+=1
print('重新尝试',try_time)
else:
raise Exception('下载失败!!')
try:
content=str(gzip.decompress(response.read()),'utf-8')
except Exception as e:
break
response.close()
titles=re.findall(pattern2,content)
ssurl=re.findall(pattern,content)
for i in range(len(ssurl)):
sslist.append({'title':titles[i],'ssurl':ssurl[i]})
return sslist
### 访问ss链接 ###
def mddownload(sslist):
datajson=[]
for each_ssurl in sslist:
print('正在下载第'+str(sslist.index(each_ssurl)+1)+'个番剧')
print('第'+str(sslist.index(each_ssurl)+1)+'个番剧网址为'+each_ssurl['ssurl'])
try_time=0
httperror=False
while try_time<=5:
try:
r=ur.Request(url=each_ssurl['ssurl'],headers=wwwheaders)
response=opener.open(r)
break
except ue.HTTPError as e:
httperror=True
print('网页不存在...跳过')
break
except Exception as e:
try_time+=1
print('重新尝试',try_time)
else:
raise Exception('下载失败!!')
if httperror:
continue
content=str(gzip.decompress(response.read()),'utf-8')
response.close()
soup=bs(content, features="lxml")
script_tag = soup.find('script', id="__NEXT_DATA__")
if script_tag is not None:
json_text = script_tag.string
data = json.loads(json_text)
datajson.append(data)
return datajson
def getdata(datajson):
data=[]
for each_data in datajson:
each_data=each_data['props']['pageProps']["dehydratedState"]["queries"][0]["state"]["data"]["seasonInfo"]['mediaInfo']
data.append({'title':each_data['title'],'media_id':each_data['media_id'],'season_id':each_data['season_id'],
"coins":each_data["stat"]['coins'],"danmakus":each_data["stat"]['danmakus'],"favorite":each_data["stat"]['favorite'],
"favorites":each_data["stat"]['favorites'],"follow_text":each_data["stat"]['follow_text'],"reply":each_data["stat"]['reply'],
"likes":each_data["stat"]['likes'],"share":each_data["stat"]['share'],"views":each_data["stat"]['views'],
'evaluate':each_data['evaluate'],'styles':each_data['styles'],'actors':each_data['actors'],
'staff':each_data['staff'],'publish':each_data['publish'],
})
print('成功写入有关'+each_data['title']+'的数据')
return data
if __name__=='__main__':
sslist=ssdownload()
datajson=mddownload(sslist)
data=getdata(datajson)
df=pd.DataFrame(data)
df.to_excel('bilibili.xlsx',index=False)
print('爬取完成!')
User-Agent和cookie用自己的,具体可以自行搜索如何操作。
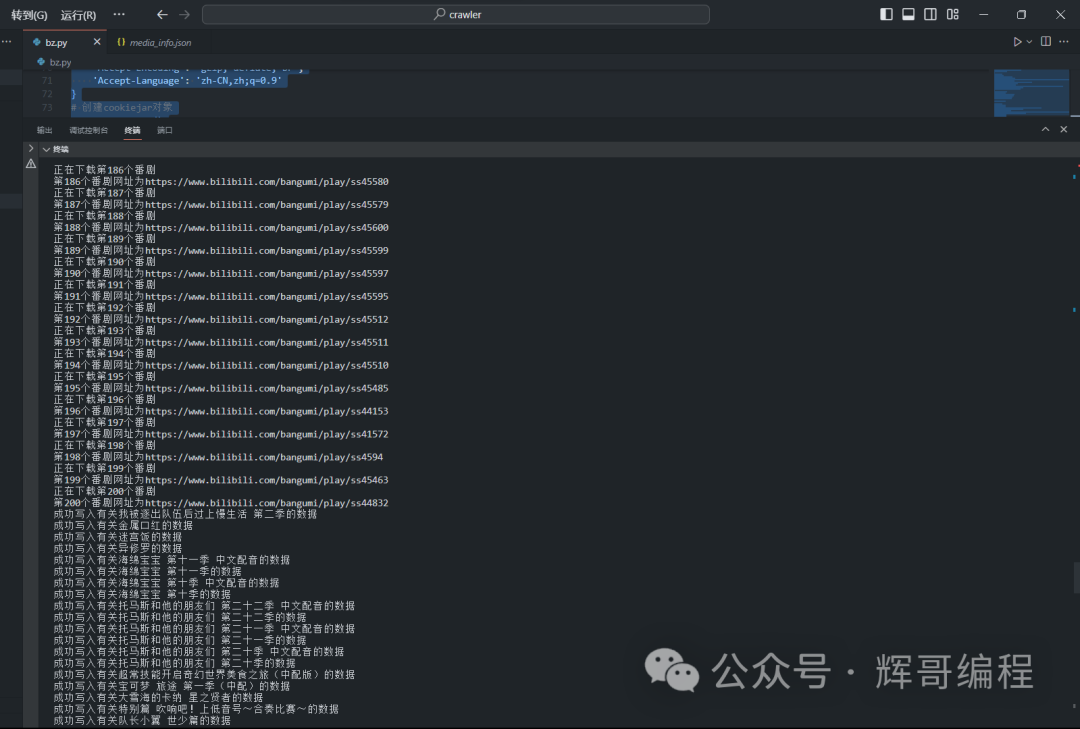
代码运行效果:
最近新开了公众号,请大家关注一下。

文章来源:https://blog.csdn.net/m0_68926749/article/details/135572531
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 聊一聊 JavaScript 中的作用域和闭包
- Qt 网络编程
- 吉时利2601A数字源表Keithley 2601A
- springCloud使用apache的http类和RestTemplate以及Eureka
- Mysql数据库批量更新表编码及排序规则
- SQL Server ,使用递归查询具有层级关系的数据。
- JavaScript之函数、数组作业
- Js WebSocket类,收发Json,带心跳,断线重连
- [Linux] MySQL数据库之事务
- Python爬虫-大麦网演出数据和票价数据