[学习笔记] ONNX 基础知识
1. ONNX 简介
1.1 什么是 ONNX
开放神经网络交换 ONNX(Open Neural Network Exchange)是一套表示深度神经网络模型的开放格式,由微软和 Facebook 于 2017 推出,然后迅速得到了各大厂商和框架的支持。通过短短几年的发展,已经成为表示深度学习模型的实际标准,并且通过 ONNX-ML,可以支持传统非神经网络机器学习模型,大有一统整个 AI 模型交换标准。
1.2 ONNX 的核心思想
ONNX 定义了一组与环境和平台无关的标准格式,为 AI 模型的互操作性提供了基础,使 AI 模型可以在不同框架和环境下交互使用。硬件和软件厂商可以基于 ONNX 标准优化模型性能,让所有兼容 ONNX 标准的框架受益。目前,ONNX 主要关注在模型预测方面(inferring),使用不同框架训练的模型,转化为 ONNX 格式后,可以很容易的部署在兼容 ONNX 的运行环境中。
1.3 ONNX 的存储方式 —— ProtoBuf
ONNX 使用的是 Protobuf 这个序列化数据结构去存储神经网络的权重信息。
Protobuf 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
1.4 ONNX 组成部分 {##Opset}
ONNX 规范由以下几个部分组成:
- 一个可扩展的计算图模型:定义了通用的计算图中间表示法(Intermediate Representation)。
- opset:
ai.onnx和ai.onnx.ml。ai.onnx是默认的操作符集,主要针对神经网络模型ai.onnx.ml主要适用于传统非神经网络机器学习模型
- 标准数据类型:包括张量(tensors)、序列(sequences)和映射(maps)。
opset:operator set,可以翻译为算子集合。
目前,ONNX 规范有两个官方变体,主要区别在与支持的类型和默认的操作符集(opset)。ONNX 神经网络变体只使用张量作为输入和输出;而作为支持传统机器学习模型的 ONNX-ML,还可以识别序列和映射,ONNX-ML 为支持非神经网络算法扩展了 ONNX 操作符集。
1.5 ONNX 主要协议
- ModelProto(模型协议): 定义整个神经网络模型的结构,包括模型的元数据、图结构以及其他相关信息。
- GraphProto(图协议): 描述神经网络的计算图结构,包括节点(NodeProto)、边(连接节点的边)等信息。
- NodeProto(节点协议): 用于定义计算图中的节点,每个节点表示一个操作或计算步骤,包括该节点的输入、输出、操作类型等信息。
- ValueInfoProto(值信息协议): 用于描述计算图中的值(如张量)的信息,包括名称、数据类型、形状等。
- TensorProto(张量协议): 用于描述神经网络中的张量,包括张量的数据、形状、数据类型等信息。
- AttributeProto(属性协议): 用于表示节点或图的属性,这些属性可能包含操作的参数、超参数等信息。
1.6 ONNX 的粒度与运行速度的关系
主流的模型部署有两种路径,以 TensorRT 为例,一种是 PyTorch->ONNX->TensorRT,另一种是 PyTorch->Caffe->TensorRT,两种转换路径的对比如下:
| 属性 | ONNX | Caffe |
|---|---|---|
| 灵活性 | 高 | 低 |
| op 粒度 | 细粒度 | 粗粒度 |
| 条件分支 | 不支持 | 支持 |
| 动态 shape | 支持 | 不支持 |
上面的表列了 ONNX 和 Caffe 的几点区别,其中最重要的区别就是 op 的粒度。举个例子,如果对 Bert 的 Attention 层做转换,ONNX 会把它变成 MatMul, Scale, SoftMax 的组合,而 Caffe 可能会直接生成一个叫做 Multi-Head Attention 的层,同时告诉 CUDA 工程师:“你去给我写一个大 kernel“(很怀疑发展到最后会不会把 ResNet50 都变成一个层 😂)
因此如果某天一个研究员提了一个新的 SOTA 的 op,很可能它直接就可以被转换成 ONNX(如果这个 op 在 PyTorch 的实现全都是用 Aten 的库拼接的),但是对于 Caffe 的工程师,需要重新写一个 kernel。
ATen 是 PyTorch 内置的 C++ 张量计算库,PyTorch 算子在底层绝大多数计算都是用 ATen 实现的。
细粒度 op 的好处就是非常灵活,坏处就是速度会比较慢。这几年有很多工作都是在做 op fushion(比如把卷积和它后面的 ReLU 合到一起算),也就是把小 op 拼成大 op。
TensorRT 是 NVIDIA 推出的部署框架,自然性能是首要考量的,因此 Layer 的粒度都很粗(粗粒度代表着有大 op,从而速度会快)。在这种情况下把 Caffe 转换过去有天然的优势。
除此之外粗粒度也可以解决分支的问题。TensorRT 眼里的神经网络就是一个单纯的 DAG(有向无环图):给定固定 shape 的输入,执行相同的运算,得到固定 shape 的输出。
在 评估一个自定义的节点 中有相关的实验。通过实验我们可以知道,将多个算子合在一起称之为 fusion,这个 fusion 是可以快加模型速度的。
2. ONNX 示例
2.1 线性回归(Linear Regression){##example1}
线性回归是机器学习中最简单的模型,由以下表达式描述:
Y = X A + B Y = XA + B Y=XA+B
我们可以将其看作是三个变量
Y
=
f
(
X
,
A
,
B
)
Y = f(X, A, B)
Y=f(X,A,B) 分解成 y = Add(MatMul(X, A), B)。这是我们需要用 ONNX 运算符表示的内容。首先是使用 ONNX 运算符实现一个函数。ONNX 是强类型的,必须为函数的输入和输出定义形状和类型。也就是说,我们需要四个函数来构建图,其中包括 make 函数:
make_tensor_value_info:根据其形状和类型声明变量(输入或输出)make_node:创建由操作(op 类型)、其输入和输出定义的节点make_graph:创建一个带有前两个函数创建的对象的 ONNX 图的函数make_model:最后一个函数,将图和附加元数据合并
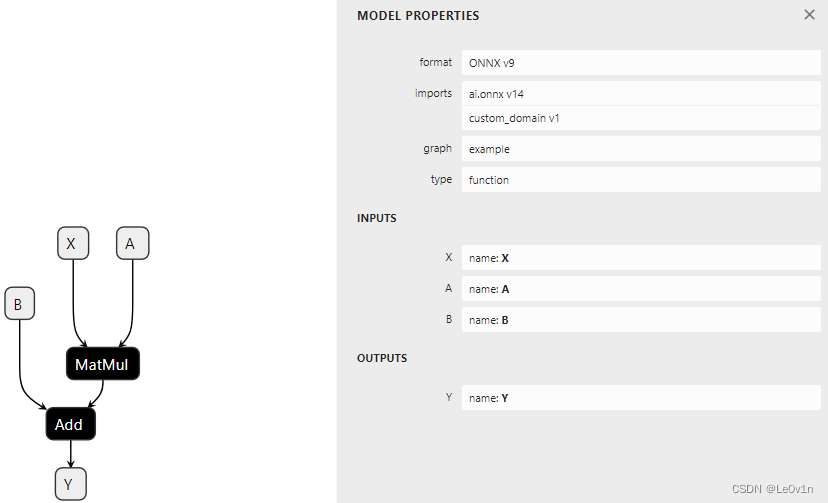
在整个创建过程中,我们需要为图的每个节点的每个输入和输出赋予一个名称。图的输入和输出由 ONNX 对象定义,使用字符串引用中间结果。下面是示例代码。
import onnx
from onnx import TensorProto
from onnx.helper import (make_model, make_node, make_graph,
make_tensor, make_tensor_value_info)
from onnx.checker import check_model
# -------------------------- inputs --------------------------
# 'X'是名称,TensorProto.FLOAT是类型,[None, None]是形状。
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, None])
A = make_tensor_value_info('A', TensorProto.FLOAT, [None, None])
B = make_tensor_value_info('B', TensorProto.FLOAT, [None, None])
# -------------------------- outputs(形状未定义) --------------------------
Y = make_tensor_value_info('Y', TensorProto.FLOAT, [None])
# -------------------------- nodes --------------------------
# 它创建一个由运算符类型MatMul定义的节点,'X'、'A'是节点的输入,'XA'是输出。
node1 = make_node(op_type='MatMul',
inputs=['X', 'A'],
outputs=['XA'])
node2 = make_node(op_type='Add',
inputs=['XA', 'B'],
outputs=['Y'])
# -------------------------- graph --------------------------
# 从节点到图,图是由节点列表、输入列表、输出列表和名称构建的。
graph = make_graph(nodes=[node1, node2], # 节点
name='lr', # 名称
inputs=[X, A, B], # 输入节点
outputs=[Y]) # 输出节点
# -------------------------- model --------------------------
# ONNX图,这种情况下没有元数据。
onnx_model = make_model(graph=graph)
# 让我们检查模型是否一致,这个函数在“Checker and Shape Inference”部分有描述。
check_model(model=onnx_model) # 如果测试失败,将引发异常
print(onnx_model)
# 将这个模型保存到本地
onnx.save_model(onnx_model, 'ONNX/saves/linear_regression.onnx')
模型打印结果:
ir_version: 9
opset_import {
version: 20
}
graph {
node {
input: "X"
input: "A"
output: "XA"
op_type: "MatMul"
}
node {
input: "XA"
input: "B"
output: "Y"
op_type: "Add"
}
name: "lr"
input {
name: "X"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "A"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "B"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
output {
name: "Y"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
}
}
}
}
}
??
check_model()这个函数的目的是检查模型是否一直,它没有返回值,如果模型有问题,那么这个函数会自动抛出异常。
我们用 Netron 看一下这个模型:


2.2 查看对象的字段 -> 检查 ONNX
空形状(None)表示任意形状,形状定义为 [None, None] 表示此对象是一个具有两个维度且没有进一步精确度的张量。还可以通过查看图中每个对象的字段来检查 ONNX 图,代码如下:
import onnx
from onnx import TensorProto
from onnx.helper import (make_model, make_node, make_graph,
make_tensor, make_tensor_value_info)
from onnx.checker import check_model
def shape2tuple(shape):
return tuple(getattr(d, 'dim_value', 0) for d in shape.dim)
# -------------------------- inputs & outputs --------------------------
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, None])
A = make_tensor_value_info('A', TensorProto.FLOAT, [None, None])
B = make_tensor_value_info('B', TensorProto.FLOAT, [None, None])
Y = make_tensor_value_info('Y', TensorProto.FLOAT, [None])
# -------------------------- nodes & graph --------------------------
node1 = make_node(op_type='MatMul',
inputs=['X', 'A'],
outputs=['XA'])
node2 = make_node(op_type='Add',
inputs=['XA', 'B'],
outputs=['Y'])
graph = make_graph(nodes=[node1, node2], # 节点
name='lr', # 名称
inputs=[X, A, B], # 输入节点
outputs=[Y]) # 输出节点
# -------------------------- model --------------------------
onnx_model = make_model(graph=graph)
check_model(model=onnx_model) # 如果测试失败,将引发异常
# -------------------------- Check: Inputs --------------------------
print(f"-------------------------- inputs --------------------------")
# print(onnx_model.graph.input)
"""
[name: "X"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
, name: "A"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
, name: "B"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
]
"""
for obj in onnx_model.graph.input:
print(f"name={obj.name!r} "
f"dtype={obj.type.tensor_type.elem_type!r} "
f"shape={shape2tuple(obj.type.tensor_type.shape)!r}")
# -------------------------- Check: Outputs --------------------------
print(f"------------------------- outputs -------------------------")
for obj in onnx_model.graph.output:
print(f"name={obj.name!r} "
f"dtype={obj.type.tensor_type.elem_type!r} "
f"shape={shape2tuple(obj.type.tensor_type.shape)!r}")
# -------------------------- Check: Nodes --------------------------
print(f"-------------------------- nodes --------------------------")
for node in onnx_model.graph.node:
print(f"name={node.name!r} "
f"type={node.op_type!r} "
f"input={node.input!r} "
f"output={node.output!r}")
结果如下:
-------------------------- inputs --------------------------
name='X' dtype=1 shape=(0, 0)
name='A' dtype=1 shape=(0, 0)
name='B' dtype=1 shape=(0, 0)
------------------------- outputs -------------------------
name='Y' dtype=1 shape=(0,)
-------------------------- nodes --------------------------
name='' type='MatMul' input=['X', 'A'] output=['XA']
name='' type='Add' input=['XA', 'B'] output=['Y']
和
xml和json类似
2.3 ONNX 数据类型查看和与 Numpy 数据类型的关系
张量类型是一个整数(= 1)。辅助函数 onnx.helper.tensor_dtype_to_np_dtype() 可以用于获取与 numpy 对应的数据类型。
from onnx import TensorProto
from onnx.helper import tensor_dtype_to_np_dtype, \
tensor_dtype_to_string
np_dtype = tensor_dtype_to_np_dtype(TensorProto.FLOAT)
print(f"将 ONNX 的 [{tensor_dtype_to_string(TensorProto.FLOAT)}] 数据类型转换为"
f"Numpy 的 [{np_dtype}] 数据类型")
结果为:
将 ONNX 的 [TensorProto.FLOAT] 数据类型转换为Numpy 的 [float32] 数据类型
2.4 序列化
前面我们说了,ONNX 是建立在 Protobuf 之上的。它添加了描述机器学习模型所需的定义,大多数情况下,ONNX 用于序列化或反序列化模型。接下来实例操作一下对数据(如张量、稀疏张量等)进行序列化和反序列化的过程。
2.4.1 模型序列化(保存)
为了部署,模型需要被保存。ONNX 基于 protobuf,它最小化了在磁盘上保存图所需的空间。ONNX 中的每个对象都可以使用 SerializeToString 方法进行序列化。整个模型也是如此。
?? 在 2.1 线性回归(Linear Regression) 中我们使用
onnx.save()这个函数对我们创建的 ONNX 模型进行了保存,这里我们探寻一下这个保存是如何进行的。
from onnx import TensorProto
from onnx.helper import (make_model, make_node, make_graph,
make_tensor, make_tensor_value_info)
from onnx.checker import check_model
def shape2tuple(shape):
return tuple(getattr(d, 'dim_value', 0) for d in shape.dim)
# -------------------------- inputs & outputs --------------------------
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, None])
A = make_tensor_value_info('A', TensorProto.FLOAT, [None, None])
B = make_tensor_value_info('B', TensorProto.FLOAT, [None, None])
Y = make_tensor_value_info('Y', TensorProto.FLOAT, [None])
# -------------------------- nodes & graph --------------------------
node1 = make_node(op_type='MatMul',
inputs=['X', 'A'],
outputs=['XA'])
node2 = make_node(op_type='Add',
inputs=['XA', 'B'],
outputs=['Y'])
graph = make_graph(nodes=[node1, node2], # 节点
name='lr', # 名称
inputs=[X, A, B], # 输入节点
outputs=[Y]) # 输出节点
# -------------------------- model --------------------------
onnx_model = make_model(graph=graph)
check_model(model=onnx_model) # 如果测试失败,将引发异常
# 序列化保存模型
save_path = 'ONNX/saves/linear_regression-serialized.onnx'
with open(save_path, 'wb') as f:
f.write(onnx_model.SerializeToString())
print(f"Serialized model has saved at {save_path}!")
Serialized model has saved at ONNX/saves/linear_regression-serialized.onnx!
我们使用 Netron 查看一下,并与之前使用 onnx.save() 保存的对比一下:
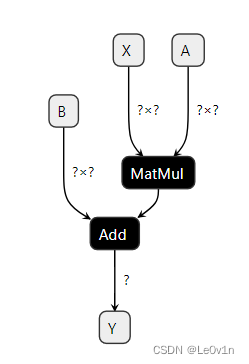
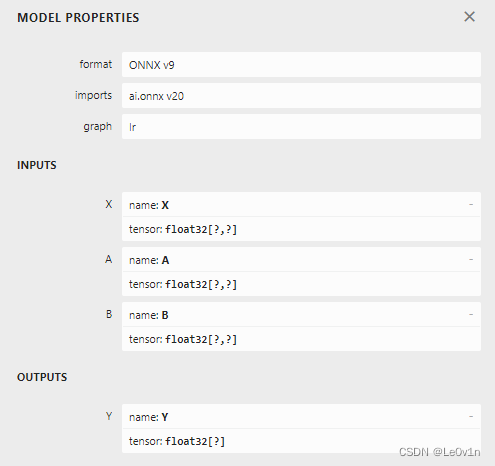
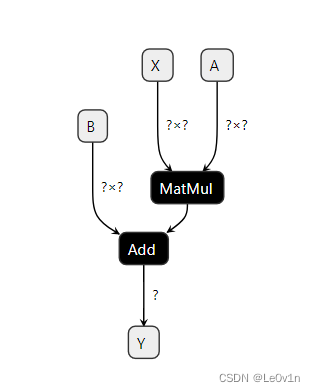
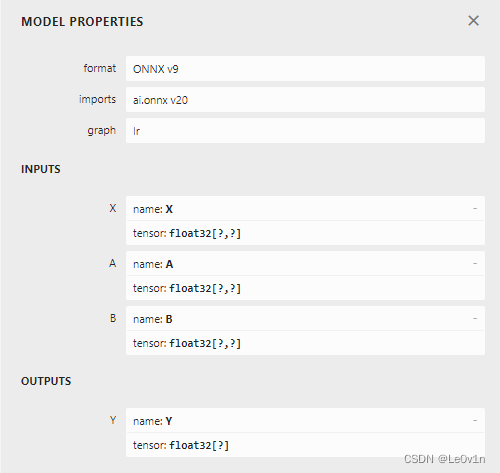
可以看到,两者是一样的,同时我们也问一下 GPT:
GPT:在 ONNX 中,onnx.save() 和模型序列化(serialization)实际上是相同的概念。onnx.save() 函数用于将整个 ONNX 模型保存到磁盘上的文件中,这个过程就是模型的序列化。这个函数的调用类似于对 ONNX 模型对象调用 SerializeToString() 方法。
?? 选择使用
onnx.save()更符合 ONNX 库的约定,同时提供了更方便的接口
2.4.2 模型反序列化(加载)
from onnx import load
weights_path = 'ONNX/saves/linear_regression-serialized.onnx'
with open(weights_path, 'rb') as f:
onnx_model = load(f)
print(onnx_model)
这两种方式看起来确实是一样的。除非模型大小超过 2 GB,任何模型都可以通过这种方式进行序列化。Protobuf 对象的大小受到 2 GB 限制,因此需要采取其他方法来克服这一限制。接下来的章节将展示如何解决这个大小限制的问题。
下面两种读取模型的方法有什么区别吗?
import onnx
# 方法1
weights_path = 'ONNX/saves/linear_regression.onnx'
onnx_model = onnx.load(weights_path)
# 方法2
with open(weights_path, 'rb') as f:
onnx_model = f.read()
是的,这两种读取方式有很大的区别。
-
第一种方式:
weights_path = 'ONNX/saves/linear_regression.onnx' onnx_model = onnx.load(weights_path)这种方式使用
onnx.load函数从文件中直接加载 ONNX 模型。这是一种常见的方式,特别适用于大型的二进制文件,比如 ONNX 模型文件。 -
第二种方式:
weights_path = 'ONNX/saves/linear_regression.onnx' with open(weights_path, 'rb') as f: onnx_model = f.read()这种方式使用 Python 的
open函数以二进制读取模式打开文件,然后使用read方法读取文件内容。这样获得的是文件的二进制数据,而不是 ONNX 模型对象。
区别:
- 第一种方式返回一个经过解析的 ONNX 模型对象,可以直接使用 ONNX 库的函数和方法进行操作,比如查看模型的结构、元数据等。
- 第二种方式返回一个包含整个文件内容的二进制数据,需要额外的步骤将其解析为 ONNX 模型对象,通常需要使用
onnx.load_model_from_string等方法。
通常情况下,如果需要直接处理 ONNX 模型的结构和元数据,建议使用第一种方式,而如果需要将 ONNX 模型文件的内容作为二进制数据进行其他处理,可以选择第二种方式。
import onnx
# 第一种方法
weights_path = 'ONNX/saves/linear_regression.onnx'
onnx_model_1 = onnx.load(weights_path)
print(f"第一种方法: {type(onnx_model_1)}")
# 第二种方法
with open(weights_path, 'rb') as f:
onnx_model_2 = f.read()
print(f"第二种方法: {type(onnx_model_2)}")
# 使用 onnx.load_model_from_string 解析二进制数据为 ONNX 模型对象
onnx_model_2 = onnx.load_model_from_string(onnx_model_2)
print(f"第二种方法(转换后): {type(onnx_model_2)}")
第一种方法: <class 'onnx.onnx_ml_pb2.ModelProto'>
第二种方法: <class 'bytes'>
第二种方法(转换后): <class 'onnx.onnx_ml_pb2.ModelProto'>
2.4.3 数据序列化(保存)
Tensor 的序列化通常会按照以下方式进行:
import numpy as np
from onnx.numpy_helper import from_array
# 创建一个 numpy 的 Tensor
numpy_tensor = np.array([0, 1, 4, 5, 3], dtype=np.float32)
print(type(numpy_tensor))
# 创建一个 onnx 的 Tensor
onnx_tensor = from_array(numpy_tensor)
print(type(onnx_tensor))
# 将 onnx 的 Tensor 序列化
serialized_tensor = onnx_tensor.SerializeToString()
print(type(serialized_tensor))
# 将序列化的 onnx Tensor 保存到本地
save_path = 'ONNX/saves/saved_serialized_tensor.pb' # pb: Protocol Buffers
with open(save_path, 'wb') as f:
f.write(serialized_tensor)
print(f"The serialized onnx tensor has been saved at {save_path}!")
<class 'numpy.ndarray'>
<class 'onnx.onnx_ml_pb2.TensorProto'>
<class 'bytes'>
The serialized onnx tensor has been saved at ONNX/saves/saved_serialized_tensor.pb!
💡 文件扩展名为
.pb的文件通常是 Protocol Buffers(protobuf)格式的文件。Protocol Buffers 是一种用于序列化结构化数据的轻量级机制,通常用于跨网络或持久化存储。
我们使用 Netron 查看一下这个保存的序列化 onnx Tensor:

2.4.4 数据反序列化(加载)
我们看一下反序列化(即将序列化的数据加载到代码中):
from onnx import TensorProto
from onnx.numpy_helper import to_array
# 读取序列化数据
data_path = 'ONNX/saves/saved_serialized_tensor.pb' # pb: Protocol Buffers
with open(data_path, 'rb') as f:
serialized_tensor = f.read()
print(f"--------------------------- serialized_tensor ---------------------------\n"
f"{type(serialized_tensor)}\n" # <class 'bytes'>
f"{serialized_tensor}\n")
"""
我们发现此时 serialized_tensor 的数据类型并不是我们想要的 onnx.onnx_ml_pb2.TensorProto
而是 <class 'bytes'>,所以我们需要将其转换为 onnx.onnx_ml_pb2.TensorProto 格式
"""
# 创建一个空的 onnx tensor
onnx_tensor = TensorProto()
# 从二进制字符串 serialized_tensor 中解析数据,并将解析后的结果存储在 onnx_tensor 对象中
onnx_tensor.ParseFromString(serialized_tensor)
print(f"--------------------------- onnx_tensor ---------------------------\n"
f"{type(onnx_tensor)}\n"
f"{onnx_tensor}\n")
# 将 onnx 的 Tensor 转换为 numpy 的Tensor
numpy_tensor = to_array(onnx_tensor)
print(f"--------------------------- numpy_tensor ---------------------------\n"
f"{type(numpy_tensor)}\n"
f"{numpy_tensor}")
--------------------------- serialized_tensor ---------------------------
<class 'bytes'>
b'\x08\x05\x10\x01J\x14\x00\x00\x00\x00\x00\x00\x80?\x00\x00\x80@\x00\x00\xa0@\x00\x00@@'
--------------------------- onnx_tensor ---------------------------
<class 'onnx.onnx_ml_pb2.TensorProto'>
dims: 5
data_type: 1
raw_data: "\000\000\000\000\000\000\200?\000\000\200@\000\000\240@\000\000@@"
--------------------------- numpy_tensor ---------------------------
<class 'numpy.ndarray'>
[0. 1. 4. 5. 3.]
这段代码可以使用 load_tensor_from_string 函数进行简化:
from onnx import load_tensor_from_string
from onnx.numpy_helper import to_array
# 读取序列化数据
data_path = 'ONNX/saves/saved_serialized_tensor.pb' # pb: Protocol Buffers
with open(data_path, 'rb') as f:
serialized_tensor = f.read()
print(f"--------------------------- serialized_tensor ---------------------------\n"
f"{type(serialized_tensor)}\n" # <class 'bytes'>
f"{serialized_tensor}\n")
# 更加便捷地加载序列化数据
onnx_tensor = load_tensor_from_string(serialized_tensor)
print(f"--------------------------- onnx_tensor ---------------------------\n"
f"{type(onnx_tensor)}\n"
f"{onnx_tensor}\n")
# 将 onnx 的 Tensor 转换为 numpy 的Tensor
numpy_tensor = to_array(onnx_tensor)
print(f"--------------------------- numpy_tensor ---------------------------\n"
f"{type(numpy_tensor)}\n"
f"{numpy_tensor}")
--------------------------- serialized_tensor ---------------------------
<class 'bytes'>
b'\x08\x05\x10\x01J\x14\x00\x00\x00\x00\x00\x00\x80?\x00\x00\x80@\x00\x00\xa0@\x00\x00@@'
--------------------------- onnx_tensor ---------------------------
<class 'onnx.onnx_ml_pb2.TensorProto'>
dims: 5
data_type: 1
raw_data: "\000\000\000\000\000\000\200?\000\000\200@\000\000\240@\000\000@@"
--------------------------- numpy_tensor ---------------------------
<class 'numpy.ndarray'>
[0. 1. 4. 5. 3.]
2.4.5 序列化与反序列可用范围
相同的模式(序列化与反序列)可以用于但不仅限于 TensorProto:
import onnx
import pprint
pprint.pprint([protocol for protocol in dir(onnx)
if protocol.endswith('Proto') and protocol[0] != '_'])
['AttributeProto',
'FunctionProto',
'GraphProto',
'MapProto',
'ModelProto',
'NodeProto',
'OperatorProto',
'OperatorSetIdProto',
'OperatorSetProto',
'OptionalProto',
'SequenceProto',
'SparseTensorProto',
'StringStringEntryProto',
'TensorProto',
'TensorShapeProto',
'TrainingInfoProto',
'TypeProto',
'ValueInfoProto']
Q:序列化就是保存,反序列化就是加载?
GPT:是的,你的理解是正确的。在计算机科学中,序列化是将数据结构或对象转换为可存储或传输的格式的过程,通常以字节流的形式。这个过程允许将数据保存到文件、数据库或通过网络传输。反序列化是将之前序列化的数据恢复为原始数据结构或对象的过程,以便进一步使用或处理。因此,序列化和反序列化是数据的保存和加载的过程。
2.5 Initializer(初始化器),默认值
前面的模型假设线性回归的系数也是模型的输入,但这并不太方便。它们应该作为模型的一部分(作为常数或初始化器),这样就符合 ONNX 的语义了。下面这个例子修改了前一个例子,将输入 A 和 B 改为初始化器。该包实现了两个函数,用于在 numpy 数组和 ONNX 格式之间进行转换。
onnx.numpy_helper.to_array: 从 ONNX 转换为 NumPy 数组onnx.numpy_helper.from_array: 从 NumPy 转换为 ONNX
这两个函数我们上面的例子就已经用过了
import numpy as np
import onnx
from onnx import numpy_helper, TensorProto
from onnx.helper import (make_tensor_value_info,
make_node, make_graph, make_model)
from onnx.checker import check_model
# -------------------------- 创建 initializers --------------------------
value = np.array([0.5, -0.6], dtype=np.float32)
A = numpy_helper.from_array(value, name='A')
value = np.array([0.4], dtype=np.float32)
C = numpy_helper.from_array(value, name='C')
# -------------------------- 创建 输入、输出、节点、图、模型 --------------------------
X = make_tensor_value_info(name='X', elem_type=TensorProto.FLOAT, shape=[None, None])
Y = make_tensor_value_info(name='Y', elem_type=TensorProto.FLOAT, shape=[None])
# 输入是['X', 'A'],输出是['AX'],那么意思就是说,将输入X与参数A相乘,得到输出AX
node1 = make_node(op_type='MatMul', inputs=['X', 'A'], outputs=['AX'])
# 输入是['AX', 'C'],输出是['Y'],那么意思就是说,将输入AX与参数C相加,得到输出Y --> Y <=> AX + C
node2 = make_node(op_type='Add', inputs=['AX', 'C'], outputs=['Y'])
# 创建图的时候输入就是最一开始的输入,输出就是最终的输出
graph = make_graph(nodes=[node1, node2],
name='lr',
inputs=[X],
outputs=[Y],
initializer=[A, C])
# 根据图创建模型
onnx_model = make_model(graph=graph)
check_model(onnx_model) # 检查模型
model_save_path = 'ONNX/saves/onnx_with_initializer.onnx'
onnx.save(onnx_model, model_save_path)
print(f"ONNX model with initializer has been saved to {model_save_path}")
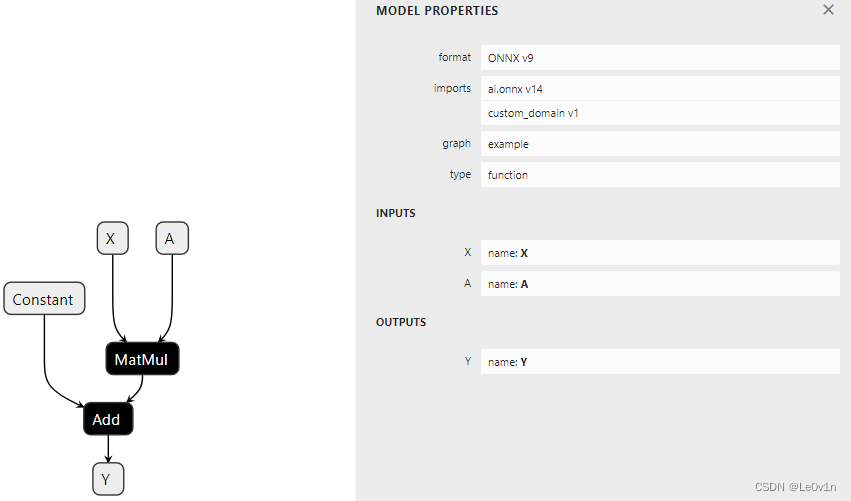
我们使用 Netron 查看一下这个模型(并附上之前的结果):

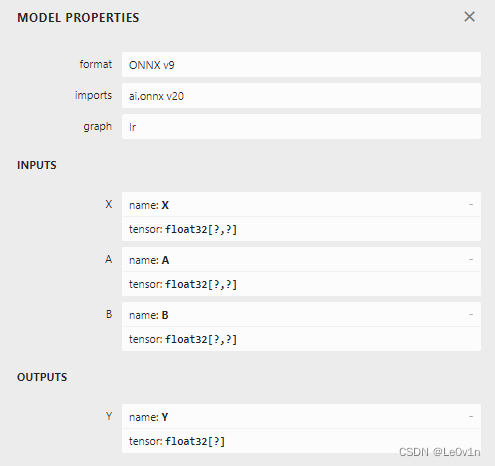
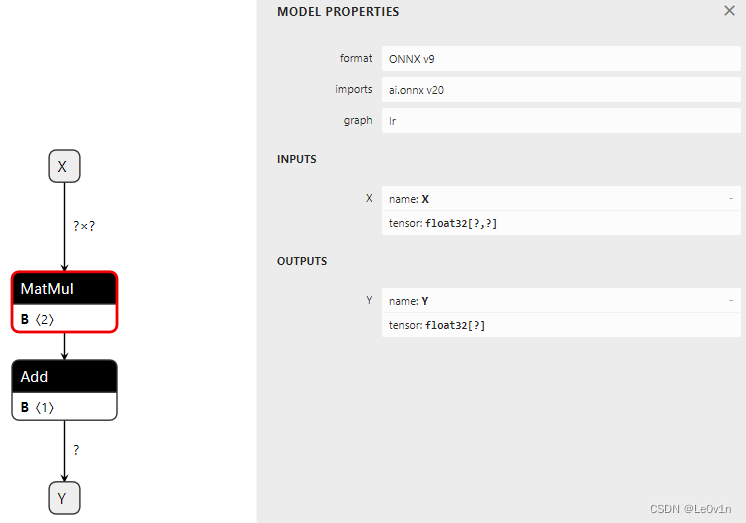
可以看到,之前的模型步骤看起来有点繁琐,而加了 initializer 后的结果就简洁了很多,<2> 和 <1> 表示权重有几个维度。
同样,我们可以遍历 ONNX 结构,查看初始化器的具体内容。
... # 代码同上
# 根据图创建模型
onnx_model = make_model(graph=graph)
check_model(onnx_model) # 检查模型
# -------------------------- 查看初始化器 --------------------------
print(f" -------------------------- 查看初始化器 --------------------------")
for init in onnx_model.graph.initializer:
print(init)
-------------------------- 查看初始化器 --------------------------
dims: 2
data_type: 1
name: "A"
raw_data: "\000\000\000?\232\231\031\277"
dims: 1
data_type: 1
name: "C"
raw_data: "\315\314\314>"
类型也被定义为具有相同含义的整数。在第二个示例中,只剩下一个输入。 输入 A 和 B 已被删除(他们可以被保留)。在这种情况下,它们是可选的:每个与输入共享相同名称的 initializer 都被视为默认值。如果未给出此输入,它将替换输入。
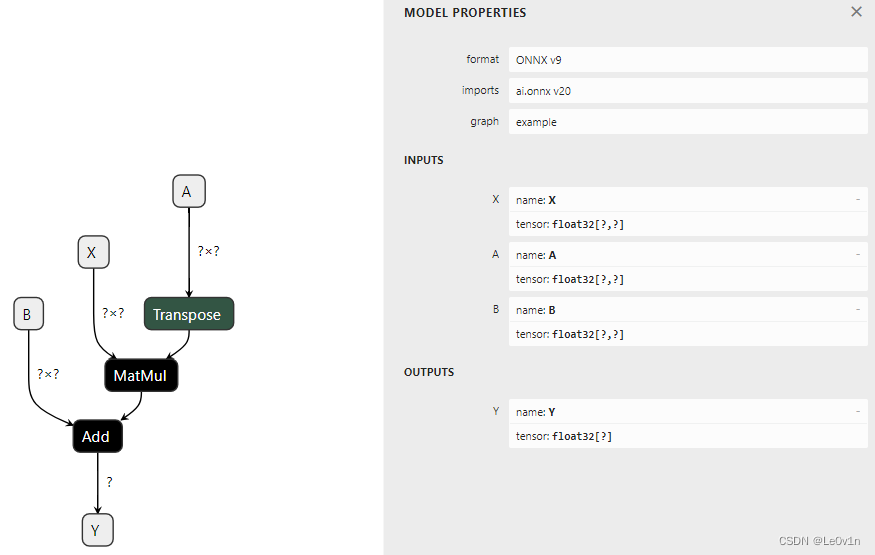
2.6 Attributes,属性
有些运算符需要像转置运算符(transpose)这样的属性。让我们为表达式
y
=
X
A
′
+
B
y = XA' + B
y=XA′+B 或 y = Add(MatMul(X, Transpose(A)) + B) 构建图。转置运算符需要一个定义轴置换的属性:perm=[1, 0]。它被添加为函数 make_node 中的一个具名属性。
import onnx
from onnx import numpy_helper, TensorProto
from onnx.helper import (make_tensor_value_info,
make_node, make_graph, make_model)
from onnx.checker import check_model
# -------------------------- 不变 --------------------------
X = make_tensor_value_info(name='X', elem_type=TensorProto.FLOAT, shape=[None, None])
A = make_tensor_value_info(name='A', elem_type=TensorProto.FLOAT, shape=[None, None])
B = make_tensor_value_info(name='B', elem_type=TensorProto.FLOAT, shape=[None, None])
Y = make_tensor_value_info(name='Y', elem_type=TensorProto.FLOAT, shape=[None])
# -------------------------- 新算子:transpose --------------------------
node_transpose = make_node(op_type='Transpose', inputs=['A'], outputs=['tA'], perm=[1, 0])
# -------------------------- 创建 输入、输出、节点、图、模型 --------------------------
node1 = make_node(op_type='MatMul', inputs=['X', 'tA'], outputs=['XA'])
node2 = make_node(op_type='Add', inputs=['XA', 'B'], outputs=['Y'])
graph = make_graph(nodes=[node_transpose, node1, node2],
name='example',
inputs=[X, A, B],
outputs=[Y])
# 根据图创建模型
onnx_model = make_model(graph=graph)
check_model(onnx_model) # 检查模型
model_save_path = 'ONNX/saves/attributes-transpose.onnx'
onnx.save(onnx_model, model_save_path)
print(f"ONNX model with initializer has been saved to {model_save_path}")
print(onnx_model)
ONNX model with initializer has been saved to ONNX/saves/attributes-transpose.onnx
ir_version: 9
opset_import {
version: 20
}
graph {
node {
input: "A"
output: "tA"
op_type: "Transpose"
attribute {
name: "perm"
type: INTS
ints: 1
ints: 0
}
}
node {
input: "X"
input: "tA"
output: "XA"
op_type: "MatMul"
}
node {
input: "XA"
input: "B"
output: "Y"
op_type: "Add"
}
name: "example"
input {
name: "X"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "A"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "B"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
output {
name: "Y"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
}
}
}
}
}
我们用 Netron 看一下:
以下是一系列 make 函数的完整列表:
import onnx
import pprint
pprint.pprint([k for k in dir(onnx.helper) if k.startswith('make')])
['make_attribute',
'make_attribute_ref',
'make_empty_tensor_value_info',
'make_function',
'make_graph',
'make_map',
'make_map_type_proto',
'make_model',
'make_model_gen_version',
'make_node',
'make_operatorsetid',
'make_opsetid',
'make_optional',
'make_optional_type_proto',
'make_sequence',
'make_sequence_type_proto',
'make_sparse_tensor',
'make_sparse_tensor_type_proto',
'make_sparse_tensor_value_info',
'make_tensor',
'make_tensor_sequence_value_info',
'make_tensor_type_proto',
'make_tensor_value_info',
'make_training_info',
'make_value_info']
2.7 Opset and metadata,算子集与元数据
首先先明白两个概念:
- 什么是 Opset:在 1.4 ONNX 组成部分 中有提到,简而言之,Op 就是算子,Set 是集合,那么 Opset 就是算子集合。
- 什么是 metadata:这个需要好好说一下。
我们首先看一下维基百科的介绍:
元数据(Metadata,又译作诠释资料,元资料),是一群数据,其内容提供了有关于另一群数据的信息。英文前缀词 meta- 的意思是之后,进而有超出界限(transcending)之意思,其语义来自形而上学的外语构词 meta-physics (希腊语:μετ?-φυσικ?) ,具有探求现象或对象背后之本质的意味。因此,元数据也带有相仿的意义,指的就是超出于“特定一群数据”所呈现的内容数据之外,其第二层次的数据。实质上,也就是用于描述这“特定一群数据”的数据,具体来说,如:
- 书籍的书名、作者、主题、目次、页数、语言、出版时间、出版社等
- 新闻的报导日期、主副标题、关键字、记者、报刊名、版次/版名、语言等
- 照片的相机型号、拍摄时间、拍摄地点、照片尺寸、分辨率、照片标题、标签、摄影师等
💡 正由于元数据是在描述关于“特定一群数据”的信息,但并非是这“特定一群数据”其自身的内容数据,所以才命名为 meta-data,即数据背后的数据。
再看一下知乎的解释:

最后看一下 GPT 对 meta 这个词的解释:
“meta”(元)是希腊语的一个前缀,表示在或超越某事物之后的事物,或者表示对该事物的更高级别或抽象的描述。在英语中,“meta” 常被用作前缀,用于构建一些与原始事物相关但更为抽象或高级的概念。
例如:
-
元数据(metadata): “meta” 在这里表示数据的描述,即对数据的更高级别的信息,而不是数据本身。
-
元分析(meta-analysis): “meta” 表示对多个独立研究的综合分析,是对研究的更高级别的分析。
-
元编程(meta-programming): “meta” 表示在程序中对程序进行操作的能力,即在程序中对代码进行处理的过程。
💡 总的来说,“meta” 表示对某一领域的更高级别、更抽象或更全面的理解和描述。
好的,我们现在回到正题。
让我们加载之前创建的 ONNX 文件并检查它具有哪些类型的元数据:
import onnx
# 第一种方法
weights_path = 'ONNX/saves/linear_regression.onnx'
onnx_model = onnx.load(weights_path)
# -------------------------- 获取 metadata --------------------------
for field in ['doc_string', 'domain', 'functions',
'ir_version', 'metadata_props', 'model_version',
'opset_import', 'producer_name', 'producer_version',
'training_info']:
print(field, getattr(onnx_model, field))
doc_string
domain
functions []
ir_version 9
metadata_props []
model_version 0
opset_import [version: 20
]
producer_name
producer_version
training_info []
?? 注意:我们不能使用二进制的方式读取模型,这样读取的模型的数据类型是
<class 'bytes'>而非<class 'onnx.onnx_ml_pb2.ModelProto'>。前者是没有 metadata 这些属性的,需要使用onnx.load_model_from_string()方法进行转换,得到<class 'onnx.onnx_ml_pb2.ModelProto'>这样数据类型的模型才会有 metada。
从上面的结果我们可以看到,这个模型中的 metadata 大多数都是空的,因为在创建 ONNX 图时没有填充它们。这个模型只有两个 metada 有数值:
import onnx
weights_path = 'ONNX/saves/linear_regression.onnx'
onnx_model = onnx.load(weights_path)
print(f"[metadata] ir_version: {onnx_model.ir_version}")
for opset in onnx_model.opset_import:
print(f"[metadata] opset domain={opset.domain!r} version={opset.version!r}")
[metadata] ir_version: 9
[metadata] opset domain='' version=20
IR 定义了 ONNX 语言的版本。Opset 定义了正在使用的运算符的版本。如果没有指定精度,ONNX 将使用来自已安装包的最新版本。当然也可以使用其他版本。
💡 IR 的英文全称是 “Intermediate Representation”,意为中间表示或中间表达式。在计算机科学和编程领域,IR 通常用来表示源代码和目标代码之间的一种中间形式,便于在编译过程中进行分析、优化和转换。在 ONNX 的上下文中,IR 指的是 ONNX 模型的中间表示。
import onnx
weights_path = 'ONNX/saves/linear_regression.onnx'
onnx_model = onnx.load(weights_path)
# 删除掉目前模型的 opset
del onnx_model.opset_import[:]
# 我们自己定义opset
opset = onnx_model.opset_import.add()
opset.domain = ''
opset.version = 14
print(f"[metadata] ir_version: {onnx_model.ir_version}")
for opset in onnx_model.opset_import:
print(f"[metadata] opset domain={opset.domain!r} version={opset.version!r}")
[metadata] ir_version: 9
[metadata] opset domain='' version=14
只要所有运算符按照 ONNX 规定的方式进行定义,就可以使用任意的 opset。例如,运算符 Reshape 的第 5 个版本将形状定义为一个输入,而不像第 1 个版本那样定义为属性。Opset 指定了描述图时遵循的规范。
其他元数据可以用于存储任何信息,以存储有关模型生成方式的信息,或者用版本号区分一个模型和另一个模型。下面我们举个例子:
import onnx
# -------------------------- 加载模型 --------------------------
weights_path = 'ONNX/saves/linear_regression.onnx'
onnx_model = onnx.load(weights_path)
# -------------------------- 修改metadata --------------------------
onnx_model.model_version = 15
onnx_model.producer_name = 'Le0v1n'
onnx_model.producer_version = 'v1.0'
onnx_model.doc_string = 'documentation about this onnx model by Le0v1n'
# 读取模型现在的metadata属性
prop = onnx_model.metadata_props
print(prop) # []
# 目前 metadata属性中的内容为空,我们可以往里面放一些信息
# ?? metadata_props只接受字典
info1 = {'model说明': '这是一个用于学习的ONNX模型',
'时间': '20240123'}
onnx.helper.set_model_props(onnx_model, info1)
print(onnx_model)
[]
ir_version: 9
opset_import {
version: 20
}
producer_name: "Le0v1n"
producer_version: "v1.0"
model_version: 15
doc_string: "documentation about this onnx model by Le0v1n"
graph {
node {
input: "X"
input: "A"
output: "XA"
op_type: "MatMul"
}
node {
input: "XA"
input: "B"
output: "Y"
op_type: "Add"
}
name: "lr"
input {
name: "X"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "A"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "B"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
output {
name: "Y"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
}
}
}
}
}
metadata_props {
key: "model说明"
value: "这是一个用于学习的ONNX模型"
}
metadata_props {
key: "时间"
value: "20240123"
}
💡 字段 training_info 可以用于存储额外的图形信息。
2.8 Subgraph: test and loops —— IF
它们通常被分组在一个称为控制流的类别中。通常最好避免使用它们,因为它们不像矩阵操作那样高效和优化。
可以使用运算符 If 来实现测试。它根据一个布尔值执行一个子图或另一个子图。这通常不经常使用,因为函数通常需要在批处理中进行许多比较的结果。以下示例根据矩阵中的符号计算所有浮点数的和,并返回 1 或 -1。
import numpy as np
import onnx
from onnx.helper import make_tensor_value_info, make_node, make_graph, make_model
from onnx.numpy_helper import from_array
from onnx.checker import check_model
from onnxruntime import InferenceSession
# -------------------------- 初始化器 --------------------------
# 创建一个包含值为0的浮点数数组,并指定数据类型为np.float32
value = np.array([0], dtype=np.float32)
# 使用onnx.numpy_helper.from_array将numpy数组转换为ONNX的TensorProto形式
zero = from_array(value, name='zero')
# -------------------------- 输入 --------------------------
# 创建输入Tensor信息,名称为'X',数据类型为onnx.TensorProto.FLOAT,形状为[None, None],表示可变维度
X = make_tensor_value_info('X', onnx.TensorProto.FLOAT, shape=[None, None])
# 创建输出Tensor信息,名称为'Y',数据类型为onnx.TensorProto.FLOAT,形状为[None],表示可变维度
Y = make_tensor_value_info('Y', onnx.TensorProto.FLOAT, shape=[None])
# -------------------------- 节点 --------------------------
# 创建 ReduceSum 节点,用于沿着指定轴对输入Tensor进行求和,输入为 'X',输出为 'rsum'
rsum = make_node(op_type='ReduceSum', inputs=['X'], outputs=['rsum'])
# 创建 Greater 节点,用于比较 'rsum' 和 'zero',输出结果保存在 'cond'
cond = make_node(op_type='Greater', inputs=['rsum', 'zero'], outputs=['cond'])
# -------------------------- 图形(带有条件) --------------------------
"""
then <=> True: 表示当条件满足的时候执行的
else <=> False: 表示当条件不满足的时候执行的
"""
# -------------------------- 图形: True -> then --------------------------
# 条件为True时的输出Tensor信息
then_out = make_tensor_value_info(name='then_out',
elem_type=onnx.TensorProto.FLOAT,
shape=None)
# 用于返回的常量Tensor
then_cst = from_array(np.array([1]).astype(np.float32))
# 创建 Constant 节点,将常量Tensor作为输出 'then_out' 的值,构成一个单一节点
then_const_node = make_node(op_type='Constant',
inputs=[],
outputs=['then_out'],
value=then_cst,
name='cst1')
# 创建包裹这些元素的图形,表示当条件为真时执行
then_body = make_graph(nodes=[then_const_node],
name='then_body',
inputs=[],
outputs=[then_out])
# -------------------------- 图形: False -> else --------------------------
# 对于 else 分支,相同的处理过程
else_out = make_tensor_value_info(name='else_out',
elem_type=onnx.TensorProto.FLOAT,
shape=[5])
else_cst = from_array(np.array([-1]).astype(np.float32))
else_const_node = make_node(op_type='Constant',
inputs=[],
outputs=['else_out'],
value=else_cst,
name='cst2')
else_body = make_graph(nodes=[else_const_node], name='else_body', inputs=[], outputs=[else_out])
# 创建 If 节点,接受条件 'cond',并有两个分支,分别为 'then_body' 和 'else_body'。
if_node = make_node(op_type='If', inputs=['cond'], outputs=['Y'],
then_branch=then_body,
else_branch=else_body)
# 创建整体的图形,包括 ReduceSum、Greater 和 If 节点
graph = make_graph(nodes=[rsum, cond, if_node],
name='if',
inputs=[X],
outputs=[Y],
initializer=[zero])
# -------------------------- 模型 --------------------------
# 创建 ONNX 模型,使用之前构建的图形作为参数
onnx_model = make_model(graph=graph)
# 检查模型的有效性,确保模型结构符合 ONNX 规范
check_model(onnx_model)
# 删除原有的 opset
del onnx_model.opset_import[:]
# 添加新的 opset
opset = onnx_model.opset_import.add()
opset.domain = ''
opset.version = 15
# 设置 ONNX 模型的 IR 版本和文档字符串
onnx_model.ir_version = 8
onnx_model.doc_string = '这是一个涉及到 if-else 语句的 ONNX 模型'
# 保存模型
model_save_path = 'ONNX/saves/if-else.onnx'
onnx.save(onnx_model, model_save_path)
print(onnx_model)
# -------------------------- 推理 --------------------------
# 创建推理会话,加载保存的 ONNX 模型
session = InferenceSession(path_or_bytes=model_save_path,
providers=['CPUExecutionProvider'])
# 创建输入张量,全为1,形状为[3, 2],数据类型为np.float32
input_tensor = np.ones(shape=[3, 2], dtype=np.float32)
# 运行推理,获取输出张量
output_tensor = session.run(output_names=None,
input_feed={'X': input_tensor})
# 打印输出张量
print(f"output: {output_tensor}")
ir_version: 8
opset_import {
domain: ""
version: 15
}
doc_string: "这是一个涉及到 if-else 语句的 ONNX 模型"
graph {
node {
input: "X"
output: "rsum"
op_type: "ReduceSum"
}
node {
input: "rsum"
input: "zero"
output: "cond"
op_type: "Greater"
}
node {
input: "cond"
output: "Y"
op_type: "If"
attribute {
name: "else_branch"
type: GRAPH
g {
node {
output: "else_out"
name: "cst2"
op_type: "Constant"
attribute {
name: "value"
type: TENSOR
t {
dims: 1
data_type: 1
raw_data: "\000\000\200\277"
}
}
}
name: "else_body"
output {
name: "else_out"
type {
tensor_type {
elem_type: 1
shape {
dim {
dim_value: 5
}
}
}
}
}
}
}
attribute {
name: "then_branch"
type: GRAPH
g {
node {
output: "then_out"
name: "cst1"
op_type: "Constant"
attribute {
name: "value"
type: TENSOR
t {
dims: 1
data_type: 1
raw_data: "\000\000\200?"
}
}
}
name: "then_body"
output {
name: "then_out"
type {
tensor_type {
elem_type: 1
}
}
}
}
}
}
name: "if"
initializer {
dims: 1
data_type: 1
name: "zero"
raw_data: "\000\000\000\000"
}
input {
name: "X"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
output {
name: "Y"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
}
}
}
}
}
output: [array([1.], dtype=float32)]
💡 参数说明:
- 在 ONNX Runtime 中,
providers参数指定了在推理时使用的执行提供程序(Execution Provider)。Execution Provider 是 ONNX Runtime 提供的不同后端的实现,用于在不同硬件上进行推理。常见的 Execution Providers 包括CPUExecutionProvider、CUDAExecutionProvider(用于 NVIDIA GPU)、DnnlExecutionProvider(用于 Intel CPU 使用 DNNL)、TensorRTExecutionProvider(用于 NVIDIA GPU 使用 TensorRT)等。 output_names是在 ONNX Runtime 推理过程中用于指定输出张量的名称的参数。它允许用户选择性地获取模型中特定输出张量的值。在上述代码中,output_names=None表示获取所有输出张量的值。如果想要仅获取模型中特定输出张量的值,可以将output_names设置为一个包含所需输出张量名称的列表。例如,如果模型有两个输出张量,分别命名为'output1'和'output2',可以使用output_names=['output1']来指定只获取'output1'对应的输出张量的值。input_feed是在 ONNX Runtime 推理过程中用于提供输入数据的参数。它是一个字典,其中键是模型定义中输入张量的名称,而值是对应的输入数据。在上述代码中,input_feed={'X': input_tensor}意味着将输入张量input_tensor提供给模型中名为'X'的输入张量。具体来说,'X'是通过make_tensor_value_info创建的输入张量信息的名称。通过input_feed参数,可以在进行推理时将模型的输入用具体的数据填充,以获取对应的输出。
上面代码的可视化如下:

else 和 then 分支都非常简单。If 节点甚至可以被替换为一个 Where 节点,这样可能更快。当两个分支都更大且跳过其中一个更有效时,情况就变得有趣了。
2.9 Functions
正如前面所提到的,函数可用于缩短构建模型的代码,并且在运行预测时提供更多可能性,如果存在该函数的特定实现,运行时可以更快。如果不是这种情况,运行时仍然可以使用基于现有运算符的默认实现。
make_function 函数用于定义一个函数。它类似于一个图,但类型更少,更像是一个模板。这个 API 可能会发生变化。它也不包括初始化器。
2.9.1 A function with no attribute,没有属性的函数
这是更简单的情况,即函数的每个输入都是在执行时已知的动态对象。
import numpy as np
import onnx
from onnx import numpy_helper, TensorProto
from onnx.helper import (make_tensor_value_info, make_tensor, make_function,
make_node, make_graph, make_model, set_model_props,
make_opsetid)
from onnx.checker import check_model
# -------------------------- 定义一个线性回归的函数 --------------------------
# 新的领域名称
new_domain = 'custom_domain'
# 构建 opset_imports 列表,包含两个 OpsetID,分别为默认领域和自定义领域
opset_imports = [
make_opsetid(domain="", version=14),
make_opsetid(domain=new_domain, version=1)
]
# 创建矩阵相乘节点,输入为 'X' 和 'A',输出为 'XA'
node1 = make_node('MatMul', ['X', 'A'], ['XA'])
# 创建加法节点,输入为 'XA' 和 'B',输出为 'Y'
node2 = make_node('Add', ['XA', 'B'], ['Y'])
linear_regression = make_function(
domain=new_domain, # 作用域名称(指定函数的作用域名称)
fname='LinearRegression', # 函数名称(指定函数的名称)
inputs=['X', 'A', 'B'], # 输入的名称(定义函数的输入张量的名称列表)
outputs=['Y'], # 输出的名称(定义函数的输出张量的名称列表)
nodes=[node1, node2], # 使用到的节点(定义函数使用到的节点列表)
opset_imports=opset_imports, # opset(指定 OpsetID 列表,定义函数使用的运算符版本)
attributes=[], # 属性的名称(定义函数的属性列表)
)
# -------------------------- 定义图 --------------------------
X = make_tensor_value_info(name='X', elem_type=TensorProto.FLOAT, shape=[None, None])
A = make_tensor_value_info(name='A', elem_type=TensorProto.FLOAT, shape=[None, None])
B = make_tensor_value_info(name='B', elem_type=TensorProto.FLOAT, shape=[None, None])
Y = make_tensor_value_info(name='Y', elem_type=TensorProto.FLOAT, shape=[None])
graph = make_graph(
nodes=[make_node(op_type='LinearRegression', inputs=['X', 'A', 'B'], outputs=['Y1'], domain=new_domain),
make_node(op_type='Abs', inputs=['Y1'], outputs=['Y'])],
name='example',
inputs=[X, A, B],
outputs=[Y]
)
# -------------------------- 定义模型 --------------------------
onnx_model = make_model(graph=graph,
opset_imports=opset_imports,
functions=[linear_regression])
check_model(onnx_model)
print(onnx_model)
ir_version: 9
opset_import {
domain: ""
version: 14
}
opset_import {
domain: "custom_domain"
version: 1
}
graph {
node {
input: "X"
input: "A"
input: "B"
output: "Y1"
op_type: "LinearRegression"
domain: "custom_domain"
}
node {
input: "Y1"
output: "Y"
op_type: "Abs"
}
name: "example"
input {
name: "X"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "A"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "B"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
output {
name: "Y"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
}
}
}
}
}
functions {
name: "LinearRegression"
input: "X"
input: "A"
input: "B"
output: "Y"
node {
input: "X"
input: "A"
output: "XA"
op_type: "MatMul"
}
node {
input: "XA"
input: "B"
output: "Y"
op_type: "Add"
}
opset_import {
domain: ""
version: 14
}
opset_import {
domain: "custom_domain"
version: 1
}
domain: "custom_domain"
}
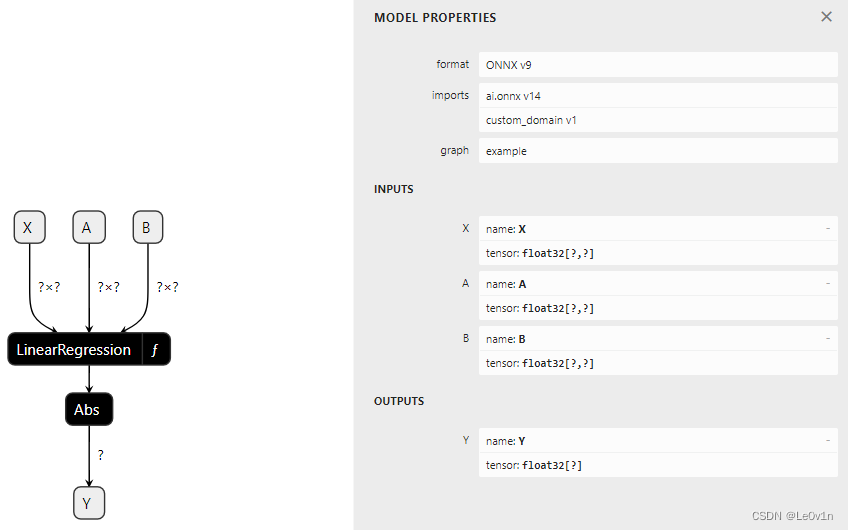
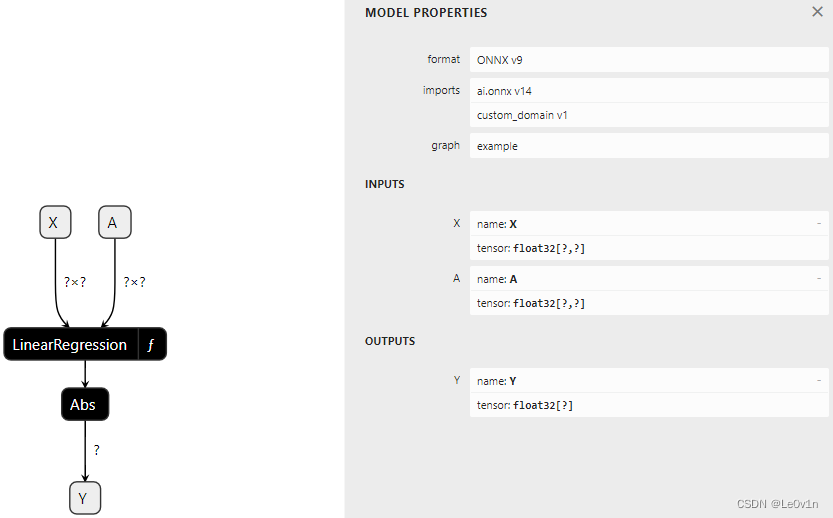
2.9.2 A function with attribute,有属性的函数
下面的函数与前一个函数等效,只是一个输入
B
B
B 被转换为名为
b
i
a
s
bias
bias 的参数。代码几乎相同,只是现在偏置是一个常数。在函数定义内部,创建了一个节点
C
o
n
s
t
a
n
t
Constant
Constant,将参数插入为一个结果。它与参数之间通过属性 ref_attr_name 进行关联。
import numpy as np
import onnx
from onnx import numpy_helper, TensorProto, AttributeProto
from onnx.helper import (make_tensor_value_info, make_tensor, make_function,
make_node, make_graph, make_model, set_model_props,
make_opsetid)
from onnx.checker import check_model
# -------------------------- 定义一个线性回归的函数 --------------------------
# 新的领域名称
new_domain = 'custom_domain'
# 构建 opset_imports 列表,包含两个 OpsetID,分别为默认领域和自定义领域
opset_imports = [
make_opsetid(domain="", version=14),
make_opsetid(domain=new_domain, version=1)
]
# 第一步是创建一个与函数的输入参数相等的常数
cst = make_node(op_type='Constant', inputs=[], outputs=['B'])
att = AttributeProto()
att.name = 'value'
# 这行代码指示该值来自函数所给定的名为 'bias' 的参数
att.ref_attr_name = 'bias'
att.type = AttributeProto.TENSOR
cst.attribute.append(att)
node1 = make_node('MatMul', ['X', 'A'], ['XA'])
node2 = make_node('Add', ['XA', 'B'], ['Y'])
linear_regression = make_function(
domain=new_domain, # 作用域名称(指定函数的作用域名称)
fname='LinearRegression', # 函数名称(指定函数的名称)
inputs=['X', 'A'], # 输入的名称(定义函数的输入张量的名称列表)
outputs=['Y'], # 输出的名称(定义函数的输出张量的名称列表)
nodes=[cst, node1, node2], # 使用到的节点(定义函数使用到的节点列表)
opset_imports=opset_imports, # opset(指定 OpsetID 列表,定义函数使用的运算符版本)
attributes=[], # 属性的名称(定义函数的属性列表)
)
# -------------------------- 定义图 --------------------------
X = make_tensor_value_info(name='X', elem_type=TensorProto.FLOAT, shape=[None, None])
A = make_tensor_value_info(name='A', elem_type=TensorProto.FLOAT, shape=[None, None])
B = make_tensor_value_info(name='B', elem_type=TensorProto.FLOAT, shape=[None, None])
Y = make_tensor_value_info(name='Y', elem_type=TensorProto.FLOAT, shape=[None])
graph = make_graph(
nodes=[make_node(op_type='LinearRegression',
inputs=['X', 'A'], outputs=['Y1'],
domain=new_domain, bias=make_tensor('former_B', TensorProto.FLOAT,
dims=[1], vals=[0.67])),
make_node(op_type='Abs', inputs=['Y1'], outputs=['Y'])],
name='example',
inputs=[X, A],
outputs=[Y]
)
# -------------------------- 定义模型 --------------------------
onnx_model = make_model(graph=graph,
opset_imports=opset_imports,
functions=[linear_regression])
check_model(onnx_model)
print(onnx_model)
model_save_path = 'ONNX/saves/function-with_attribute.onnx'
onnx.save(onnx_model, model_save_path)
ir_version: 9
opset_import {
domain: ""
version: 14
}
opset_import {
domain: "custom_domain"
version: 1
}
graph {
node {
input: "X"
input: "A"
output: "Y1"
op_type: "LinearRegression"
domain: "custom_domain"
attribute {
name: "bias"
type: TENSOR
t {
dims: 1
data_type: 1
float_data: 0.67
name: "former_B"
}
}
}
node {
input: "Y1"
output: "Y"
op_type: "Abs"
}
name: "example"
input {
name: "X"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
input {
name: "A"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
}
}
}
}
}
output {
name: "Y"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
}
}
}
}
}
functions {
name: "LinearRegression"
input: "X"
input: "A"
output: "Y"
node {
output: "B"
op_type: "Constant"
attribute {
name: "value"
ref_attr_name: "bias"
type: TENSOR
}
}
node {
input: "X"
input: "A"
output: "XA"
op_type: "MatMul"
}
node {
input: "XA"
input: "B"
output: "Y"
op_type: "Add"
}
opset_import {
domain: ""
version: 14
}
opset_import {
domain: "custom_domain"
version: 1
}
domain: "custom_domain"
}
3. Evaluation and Runtime,模型评估和运行时间
ONNX 标准允许框架以 ONNX 格式导出训练好的模型,并且支持使用任何支持 ONNX 格式的后端进行推理。onnxruntime 是一个高效的选择,可在许多平台上使用。它经过优化,以实现快速推理。其覆盖范围可以在 ONNX 后端仪表板上跟踪。onnx 还实现了一个用于帮助理解模型的 Python 运行时。它并不打算用于生产,性能也不是其目标。
💡 只是用于理解模型时性能不是目标,日常使用的话,ONNX 还是挺高效的。
3.1 Evaluation of a linear regression,评估一个线性回归模型
完整的 API 文档可以在 onnx.reference 中找到。它接受一个模型(一个 ModelProto,一个文件名等)。run 方法根据在字典中指定的一组输入返回输出。下面是一个示例:
import numpy
from onnx import numpy_helper, TensorProto
from onnx.helper import (
make_model, make_node, set_model_props, make_tensor,
make_graph, make_tensor_value_info)
from onnx.checker import check_model
from onnx.reference import ReferenceEvaluator
# -------------------------- 不变 --------------------------
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, None])
A = make_tensor_value_info('A', TensorProto.FLOAT, [None, None])
B = make_tensor_value_info('B', TensorProto.FLOAT, [None, None])
Y = make_tensor_value_info('Y', TensorProto.FLOAT, [None])
node1 = make_node('MatMul', ['X', 'A'], ['XA'])
node2 = make_node('Add', ['XA', 'B'], ['Y'])
graph = make_graph([node1, node2], 'lr', [X, A, B], [Y])
onnx_model = make_model(graph)
check_model(onnx_model)
# -------------------------- 模型评估 --------------------------
# 创建 ReferenceEvaluator 对象,用于运行 ONNX 模型
sess = ReferenceEvaluator(onnx_model)
# 生成随机输入数据
x = numpy.random.randn(4, 2).astype(numpy.float32)
a = numpy.random.randn(2, 1).astype(numpy.float32)
b = numpy.random.randn(1, 1).astype(numpy.float32)
# 将输入数据放入字典中
feeds = {'X': x, 'A': a, 'B': b}
# 使用 ReferenceEvaluator 对象运行模型,获取输出结果
result = sess.run(None, feeds)
print(f"The model result is: \n{result}\n"
f"It's type: {type(result)}\n"
f"Specific type: {type(result[0])}")
The model result is:
[array([[0.49450195],
[0.5288675 ],
[0.25783658],
[1.0908649 ]], dtype=float32)]
It's type: <class 'list'>
Specific type: <class 'numpy.ndarray'>
3.2 Evaluation of a node, 评估某一个节点
评估器还可以评估一个简单的节点,以检查运算符在特定输入上的行为。下面是一个示例:
import numpy
from onnx import numpy_helper, TensorProto
from onnx.helper import make_node
from onnx.reference import ReferenceEvaluator
node = make_node('EyeLike', ['X'], ['Y'])
sess = ReferenceEvaluator(node)
x = numpy.random.randn(4, 2).astype(numpy.float32)
feeds = {'X': x}
result = sess.run(None, feeds)
print(f"The node result is: \n{result}\n"
f"It's type: {type(result)}\n"
f"Specific type: {type(result[0])}")
The node result is:
[array([[1., 0.],
[0., 1.],
[0., 0.],
[0., 0.]], dtype=float32)]
It's type: <class 'list'>
Specific type: <class 'numpy.ndarray'>
💡 类似的代码也可以在 GraphProto 或 FunctionProto 上运行。
3.3 Evaluation Step by Step,一步一步的评估
转换库接收一个用机器学习框架(如 pytorch、scikit-learn 等)训练的现有模型,将该模型转换为一个 ONNX 图。通常,复杂的模型在第一次尝试时可能无法正常工作,查看中间结果可能有助于找到不正确转换的部分,使用参数 verbose 用于显示有关中间结果的信息。下面是一个示例代码:
import numpy
from onnx import numpy_helper, TensorProto
from onnx.helper import (
make_model, make_node, set_model_props, make_tensor,
make_graph, make_tensor_value_info)
from onnx.checker import check_model
from onnx.reference import ReferenceEvaluator
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, None])
A = make_tensor_value_info('A', TensorProto.FLOAT, [None, None])
B = make_tensor_value_info('B', TensorProto.FLOAT, [None, None])
Y = make_tensor_value_info('Y', TensorProto.FLOAT, [None])
node1 = make_node('MatMul', ['X', 'A'], ['XA'])
node2 = make_node('Add', ['XA', 'B'], ['Y'])
graph = make_graph([node1, node2], 'lr', [X, A, B], [Y])
onnx_model = make_model(graph)
check_model(onnx_model)
for verbose in [1, 2, 3, 4]:
print()
print(f"------ verbose={verbose}")
print()
sess = ReferenceEvaluator(onnx_model, verbose=verbose)
x = numpy.random.randn(4, 2).astype(numpy.float32)
a = numpy.random.randn(2, 1).astype(numpy.float32)
b = numpy.random.randn(1, 1).astype(numpy.float32)
feeds = {'X': x, 'A': a, 'B': b}
result = sess.run(None, feeds)
print(f"No.{verbose} result is: \n{result}")
------ verbose=1
No.1 result is:
[array([[1.3466744],
[1.4322073],
[1.4926268],
[1.3633491]], dtype=float32)]
------ verbose=2
MatMul(X, A) -> XA
Add(XA, B) -> Y
No.2 result is:
[array([[ 0.6492353 ],
[ 0.22668248],
[-1.3016735 ],
[-0.14969295]], dtype=float32)]
------ verbose=3
+I X: float32:(4, 2) in [-1.3570822477340698, 0.5996934771537781]
+I A: float32:(2, 1) in [-1.163417100906372, -0.8546339869499207]
+I B: float32:(1, 1) in [0.16759172081947327, 0.16759172081947327]
MatMul(X, A) -> XA
+ XA: float32:(4, 1) in [-1.0257296562194824, 1.317176342010498]
Add(XA, B) -> Y
+ Y: float32:(4, 1) in [-0.8581379652023315, 1.484768033027649]
No.3 result is:
[array([[ 1.484768 ],
[ 0.24345586],
[-0.85813797],
[ 1.3841225 ]], dtype=float32)]
------ verbose=4
+I X: float32:(4, 2):-0.06228995695710182,-0.5402382016181946,0.855003833770752,0.023194529116153717,-1.138258934020996...
+I A: float32:(2, 1):[2.67880916595459, 1.616241216659546]
+I B: float32:(1, 1):[-0.08334967494010925]
MatMul(X, A) -> XA
+ XA: float32:(4, 1):[-1.040018081665039, 2.3278801441192627, -3.307098865509033, -1.5567586421966553]
Add(XA, B) -> Y
+ Y: float32:(4, 1):[-1.1233677864074707, 2.244530439376831, -3.390448570251465, -1.640108346939087]
No.4 result is:
[array([[-1.1233678],
[ 2.2445304],
[-3.3904486],
[-1.6401083]], dtype=float32)]
3.4 Evaluate a custom node,评估一个自定义的节点 {##评估一个自定义的节点}
下面的例子仍然实现了一个线性回归,但在 A A A 上添加了单位矩阵:
Y = X ( A + I ) + B Y = X(A + I) + B Y=X(A+I)+B
import numpy
from onnx import numpy_helper, TensorProto
from onnx.helper import (
make_model, make_node, set_model_props, make_tensor,
make_graph, make_tensor_value_info)
from onnx.checker import check_model
from onnx.reference import ReferenceEvaluator
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, None])
A = make_tensor_value_info('A', TensorProto.FLOAT, [None, None])
B = make_tensor_value_info('B', TensorProto.FLOAT, [None, None])
Y = make_tensor_value_info('Y', TensorProto.FLOAT, [None])
node0 = make_node('EyeLike', ['A'], ['Eye'])
node1 = make_node('Add', ['A', 'Eye'], ['A1'])
node2 = make_node('MatMul', ['X', 'A1'], ['XA1'])
node3 = make_node('Add', ['XA1', 'B'], ['Y'])
graph = make_graph([node0, node1, node2, node3], 'lr', [X, A, B], [Y])
onnx_model = make_model(graph)
check_model(onnx_model)
with open("ONNX/saves/linear_regression.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
sess = ReferenceEvaluator(onnx_model, verbose=2)
x = numpy.random.randn(4, 2).astype(numpy.float32)
a = numpy.random.randn(2, 2).astype(numpy.float32) / 10
b = numpy.random.randn(1, 2).astype(numpy.float32)
feeds = {'X': x, 'A': a, 'B': b}
result = sess.run(None, feeds)
print(f"Result is: \n{result}")
EyeLike(A) -> Eye
Add(A, Eye) -> A1
MatMul(X, A1) -> XA1
Add(XA1, B) -> Y
Result is:
[array([[ 0.48974502, 1.777401 ],
[-0.90059066, -0.81312126],
[-1.9505675 , 0.43714556],
[-1.9263479 , -1.0114272 ]], dtype=float32)]
如果我们将运算符
E
y
e
L
i
k
e
EyeLike
EyeLike 和
A
d
d
Add
Add 结合成
A
d
d
E
y
e
L
i
k
e
AddEyeLike
AddEyeLike,那么是否可以是的推理更加高效呢?下一个例子将这两个运算符替换为来自领域 'optimized' 的单个运算符。
import numpy
from onnx import numpy_helper, TensorProto
from onnx.helper import (
make_model, make_node, set_model_props, make_tensor,
make_graph, make_tensor_value_info, make_opsetid)
from onnx.checker import check_model
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, None])
A = make_tensor_value_info('A', TensorProto.FLOAT, [None, None])
B = make_tensor_value_info('B', TensorProto.FLOAT, [None, None])
Y = make_tensor_value_info('Y', TensorProto.FLOAT, [None])
node01 = make_node('AddEyeLike', ['A'], ['A1'], domain='optimized')
node2 = make_node('MatMul', ['X', 'A1'], ['XA1'])
node3 = make_node('Add', ['XA1', 'B'], ['Y'])
graph = make_graph([node01, node2, node3], 'lr', [X, A, B], [Y])
onnx_model = make_model(graph, opset_imports=[
make_opsetid('', 18), make_opsetid('optimized', 1)
])
check_model(onnx_model)
with open("ONNX/saves/linear_regression_improved.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
我们需要评估这个模型是否等价于第一个模型。这需要为这个特定的节点实现一个功能。
import numpy
from onnx.reference import ReferenceEvaluator
from onnx.reference.op_run import OpRun
class AddEyeLike(OpRun):
op_domain = "optimized"
def _run(self, X, alpha=1.):
assert len(X.shape) == 2
assert X.shape[0] == X.shape[1]
X = X.copy()
ind = numpy.diag_indices(X.shape[0])
X[ind] += alpha
return (X,)
sess = ReferenceEvaluator("ONNX/saves/linear_regression_improved.onnx", verbose=2, new_ops=[AddEyeLike])
x = numpy.random.randn(4, 2).astype(numpy.float32)
a = numpy.random.randn(2, 2).astype(numpy.float32) / 10
b = numpy.random.randn(1, 2).astype(numpy.float32)
feeds = {'X': x, 'A': a, 'B': b}
print(sess.run(None, feeds))
# Let's check with the previous model.
sess0 = ReferenceEvaluator("ONNX/saves/linear_regression.onnx",)
sess1 = ReferenceEvaluator("ONNX/saves/linear_regression_improved.onnx", new_ops=[AddEyeLike])
y0 = sess0.run(None, feeds)[0]
y1 = sess1.run(None, feeds)[0]
print(y0)
print(y1)
print(f"difference: {numpy.abs(y0 - y1).max()}")
AddEyeLike(A) -> A1
MatMul(X, A1) -> XA1
Add(XA1, B) -> Y
[array([[-0.42936724, -0.59607476],
[-1.8834507 , -0.9946752 ],
[ 1.0796697 , -0.16089936],
[ 0.3997272 , -1.9825854 ]], dtype=float32)]
[[-0.42936724 -0.59607476]
[-1.8834507 -0.9946752 ]
[ 1.0796697 -0.16089936]
[ 0.3997272 -1.9825854 ]]
[[-0.42936724 -0.59607476]
[-1.8834507 -0.9946752 ]
[ 1.0796697 -0.16089936]
[ 0.3997272 -1.9825854 ]]
difference: 0.0
预测是相同的。让我们比较在一个足够大的矩阵上的性能,以便看到显著的差异。
import timeit
import numpy
from onnx.reference import ReferenceEvaluator
from onnx.reference.op_run import OpRun
class AddEyeLike(OpRun):
op_domain = "optimized"
def _run(self, X, alpha=1.):
assert len(X.shape) == 2
assert X.shape[0] == X.shape[1]
X = X.copy()
ind = numpy.diag_indices(X.shape[0])
X[ind] += alpha
return (X,)
sess = ReferenceEvaluator("ONNX/saves/linear_regression_improved.onnx", verbose=2, new_ops=[AddEyeLike])
x = numpy.random.randn(4, 100).astype(numpy.float32)
a = numpy.random.randn(100, 100).astype(numpy.float32) / 10
b = numpy.random.randn(1, 100).astype(numpy.float32)
feeds = {'X': x, 'A': a, 'B': b}
sess0 = ReferenceEvaluator("ONNX/saves/linear_regression.onnx")
sess1 = ReferenceEvaluator("ONNX/saves/linear_regression_improved.onnx", new_ops=[AddEyeLike])
y0 = sess0.run(None, feeds)[0]
y1 = sess1.run(None, feeds)[0]
print(f"difference: {numpy.abs(y0 - y1).max()}")
print(f"time with EyeLike+Add: {timeit.timeit(lambda: sess0.run(None, feeds), number=1000)}")
print(f"time with AddEyeLike: {timeit.timeit(lambda: sess1.run(None, feeds), number=1000)}")
difference: 0.0
time with EyeLike+Add: 0.09205669999937527
time with AddEyeLike: 0.12604709999868646
在这种情况下似乎值得添加一个优化节点。这种优化通常被称为 fusion。两个连续的运算符被融合成它们的优化版本。生产环境通常依赖于 onnxruntime,但由于这种优化使用基本的矩阵操作,它应该在任何其他运行时上带来相同的性能提升。
4. Implementation details,实现细节
4.1 Python and C++
ONNX 依赖于 Protobuf 来定义其类型。你可能会认为一个 Python 对象只是在内部结构上包装了一个 C 指针。因此,应该可以从接收 ModelProto 类型的 Python 对象的函数中访问内部数据。但事实并非如此。根据 Protobuf 4 的更改,在版本 4 之后不再可能这样做,更安全的做法是假设获取内容的唯一方法是将模型序列化为字节,传递给 C 函数,然后再进行反序列化。像 check_model 或 shape_inference 这样的函数在使用 C 代码检查模型之前,会调用 SerializeToString,然后再调用 ParseFromString。
4.2 Attributes and inputs,属性和输入
这两者之间有明显的区别。输入是动态的,可能在每次执行时都会改变。属性从不改变,优化器可以假设它永远不会改变来优化执行图。因此,?? 将输入转换为属性是不可能的。💡 而常量运算符是唯一将属性转换为输入的运算符。
4.3 Shape or no shape,有形状和没有形状
ONNX 通常期望每个输入或输出都有一个形状,假设已知秩(或维度的数量)。但如果我们需要为每个维度创建一个有效的图呢?这种情况仍然令人困惑。
import numpy
from onnx import numpy_helper, TensorProto, FunctionProto
from onnx.helper import (
make_model, make_node, set_model_props, make_tensor,
make_graph, make_tensor_value_info, make_opsetid,
make_function)
from onnx.checker import check_model
from onnxruntime import InferenceSession
def create_model(shapes):
new_domain = 'custom'
opset_imports = [make_opsetid("", 14), make_opsetid(new_domain, 1)]
node1 = make_node('MatMul', ['X', 'A'], ['XA'])
node2 = make_node('Add', ['XA', 'A'], ['Y'])
X = make_tensor_value_info('X', TensorProto.FLOAT, shapes['X'])
A = make_tensor_value_info('A', TensorProto.FLOAT, shapes['A'])
Y = make_tensor_value_info('Y', TensorProto.FLOAT, shapes['Y'])
graph = make_graph([node1, node2], 'example', [X, A], [Y])
onnx_model = make_model(graph, opset_imports=opset_imports)
# Let models runnable by onnxruntime with a released ir_version
onnx_model.ir_version = 8
return onnx_model
print("----------- case 1: 2D x 2D -> 2D")
onnx_model = create_model({'X': [None, None], 'A': [None, None], 'Y': [None, None]})
check_model(onnx_model)
sess = InferenceSession(onnx_model.SerializeToString(),
providers=["CPUExecutionProvider"])
res = sess.run(None, {
'X': numpy.random.randn(2, 2).astype(numpy.float32),
'A': numpy.random.randn(2, 2).astype(numpy.float32)})
print(res)
print("----------- case 2: 2D x 1D -> 1D")
onnx_model = create_model({'X': [None, None], 'A': [None], 'Y': [None]})
check_model(onnx_model)
sess = InferenceSession(onnx_model.SerializeToString(),
providers=["CPUExecutionProvider"])
res = sess.run(None, {
'X': numpy.random.randn(2, 2).astype(numpy.float32),
'A': numpy.random.randn(2).astype(numpy.float32)})
print(res)
print("----------- case 3: 2D x 0D -> 0D")
onnx_model = create_model({'X': [None, None], 'A': [], 'Y': []})
check_model(onnx_model)
try:
InferenceSession(onnx_model.SerializeToString(),
providers=["CPUExecutionProvider"])
except Exception as e:
print(e)
print("----------- case 4: 2D x None -> None")
onnx_model = create_model({'X': [None, None], 'A': None, 'Y': None})
try:
check_model(onnx_model)
except Exception as e:
print(type(e), e)
sess = InferenceSession(onnx_model.SerializeToString(),
providers=["CPUExecutionProvider"])
res = sess.run(None, {
'X': numpy.random.randn(2, 2).astype(numpy.float32),
'A': numpy.random.randn(2).astype(numpy.float32)})
print(res)
print("----------- end")
----------- case 1: 2D x 2D -> 2D
[array([[-0.17025554, -0.19959664],
[ 2.4781291 , 1.6193585 ]], dtype=float32)]
----------- case 2: 2D x 1D -> 1D
[array([-0.84798825, -0.75835514], dtype=float32)]
----------- case 3: 2D x 0D -> 0D
[ONNXRuntimeError] : 1 : FAIL : Node () Op (MatMul) [ShapeInferenceError] Input tensors of wrong rank (0).
----------- case 4: 2D x None -> None
<class 'onnx.onnx_cpp2py_export.checker.ValidationError'> Field 'shape' of 'type' is required but missing.
[array([ 0.6613703, -1.9580202], dtype=float32)]
----------- end
知识来源
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!