私有部署ELK,搭建自己的日志中心(四)-- kibana展示es的数据
一、说在前面的话
前一篇已把elk的安装连带讲完,本文重在讲述如何在kibana展示es数据。
二、数据的展示
展示es数据库的客户端工具有很多,比如es head插件,但是一说到要查询日志,还是非kibana莫属了。
1、kibana.yml
# 服务端口
server.port: 5601
# 服务IP
server.host: "0.0.0.0"
# ES的内网Ip:192.168.8.29
elasticsearch.hosts: ["http://192.168.8.29:9200"]
# 汉化
i18n.locale: "zh-CN"
2、添加索引
索引模式,新增索引模式。

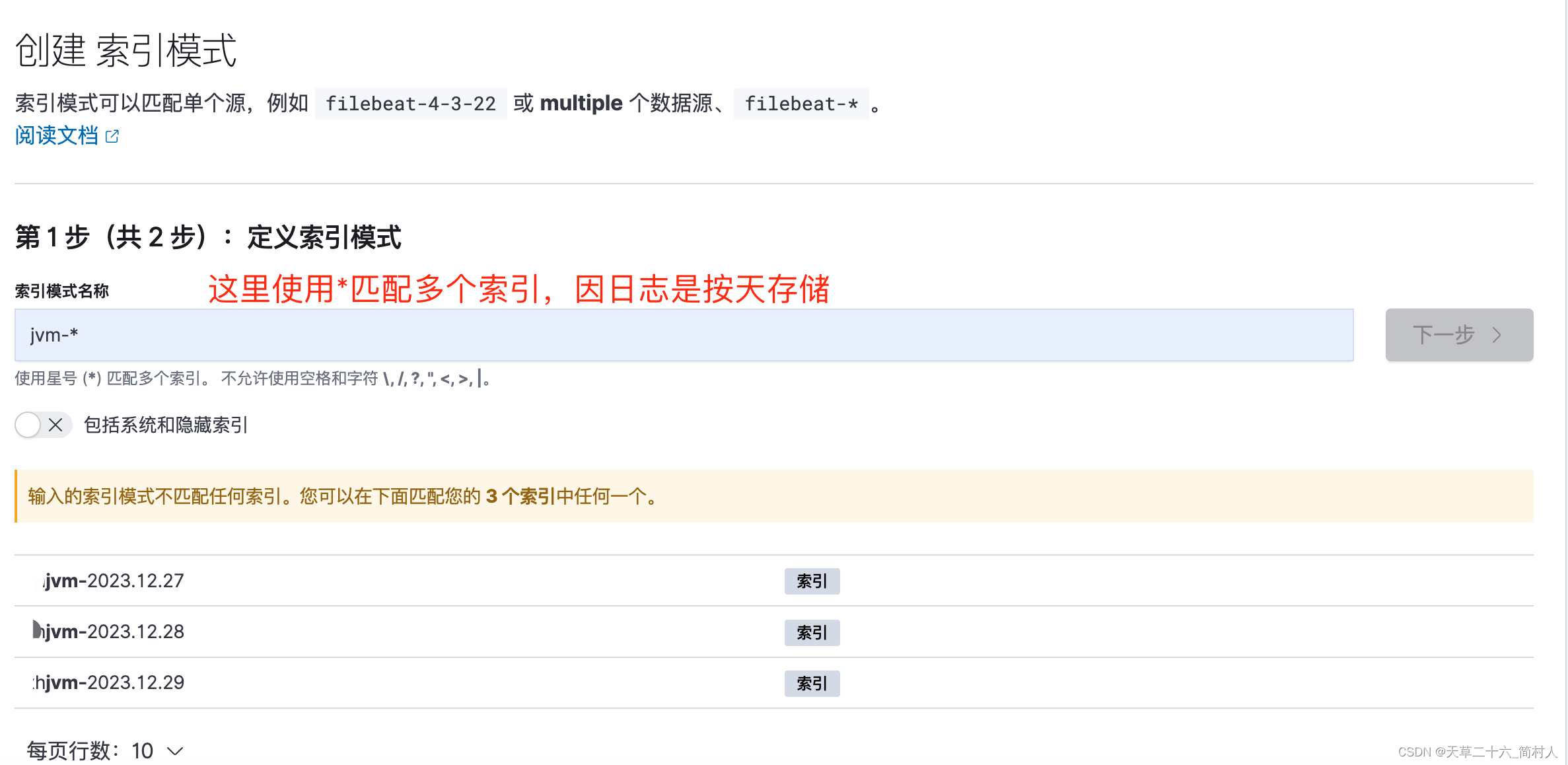
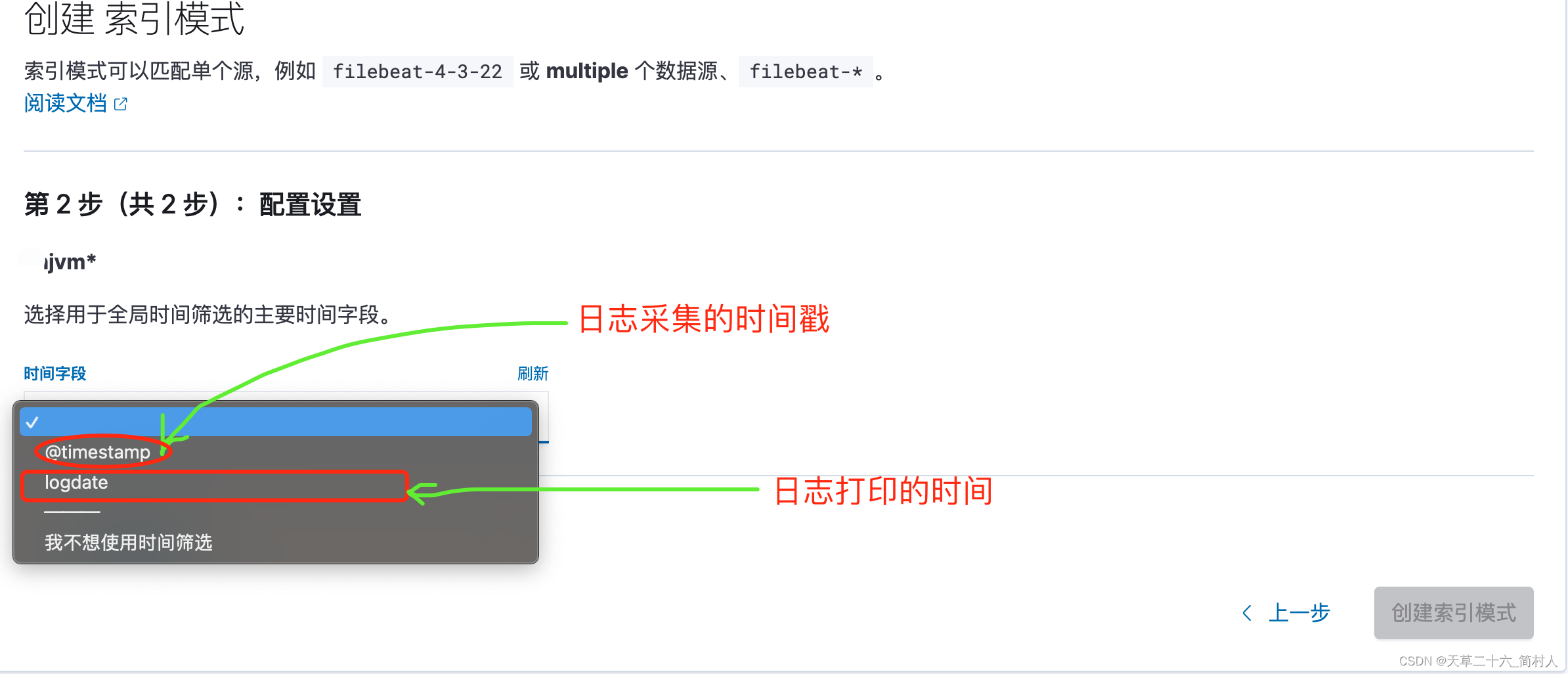
添加索引模式完成,可以看到其时间筛选字段名称是logdate,另外右上角可以将之删除。

时间字段是必选的,建议你使用日志打印的时间,因为采集时间并不和打印时间相等。
但是,如果你没能对日志内容进行解析成功,换句话说,在filebeat或者logstash未能得到logdate,那么你将查询不到任何日志。(因为Kibana查询的时候,时间是必填的查询条件)
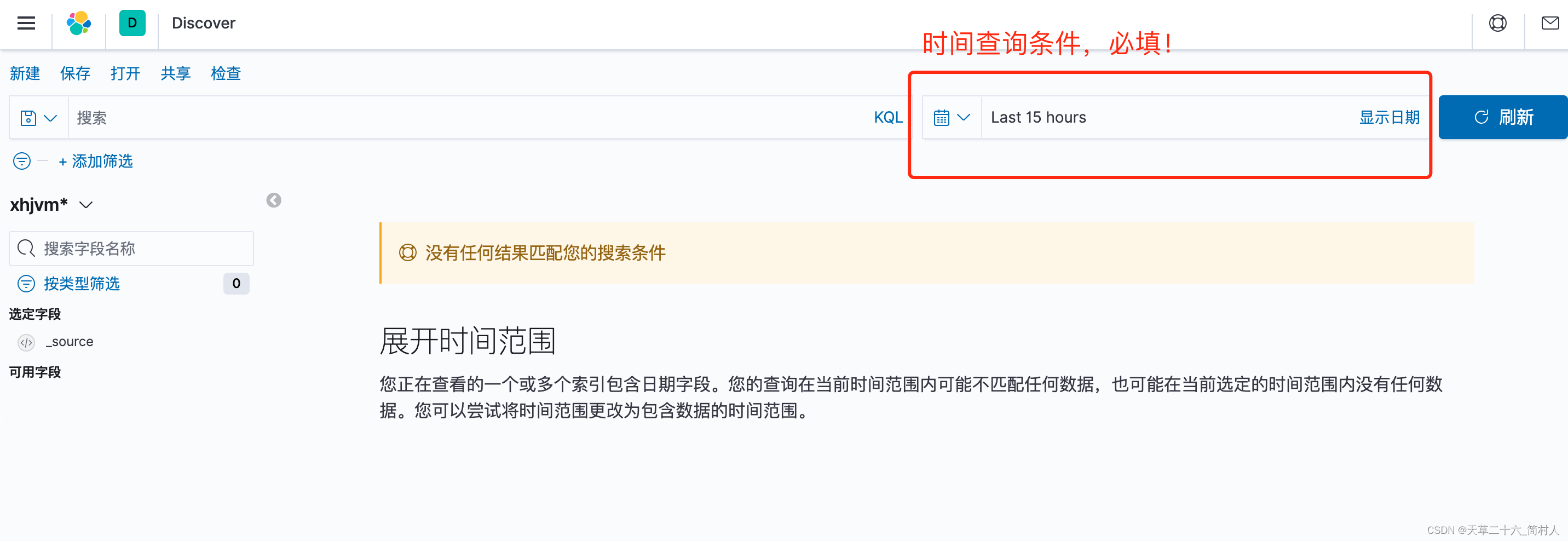
此时,你就得选择采集时间@timestamp作为索引的时间字段。效果见下:
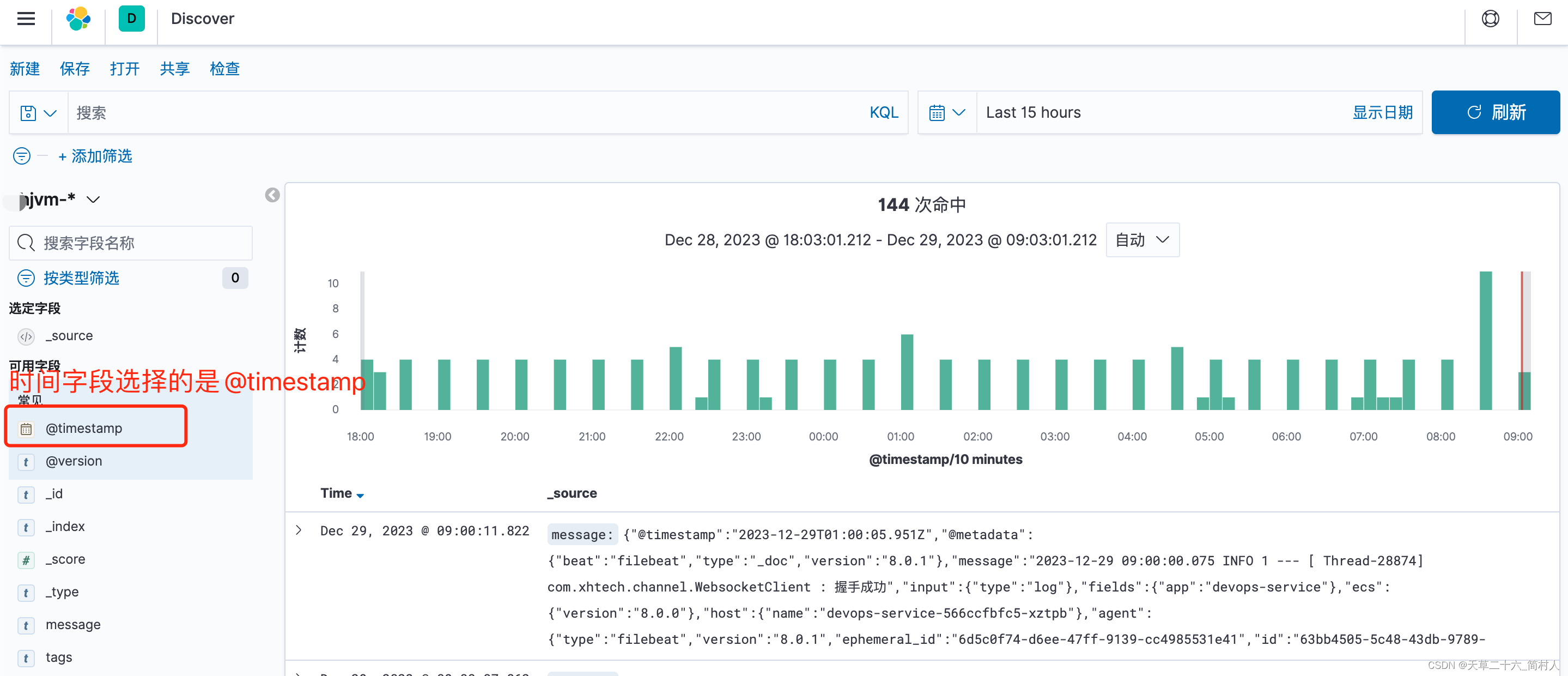
要想在Kibana展示es数据并不难,保证时间字段必须有值。
三、数据存储
1、elasticsearch.yml
日志中心在内部使用,关闭认证,方便使用。
# 集群名称
cluster.name: elasticsearch-cluster
network.host: 0.0.0.0
# 支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
# 安全认证
xpack.security.enabled: false
2、定期清理数据
kibana的索引管理–》索引生命周期策略:
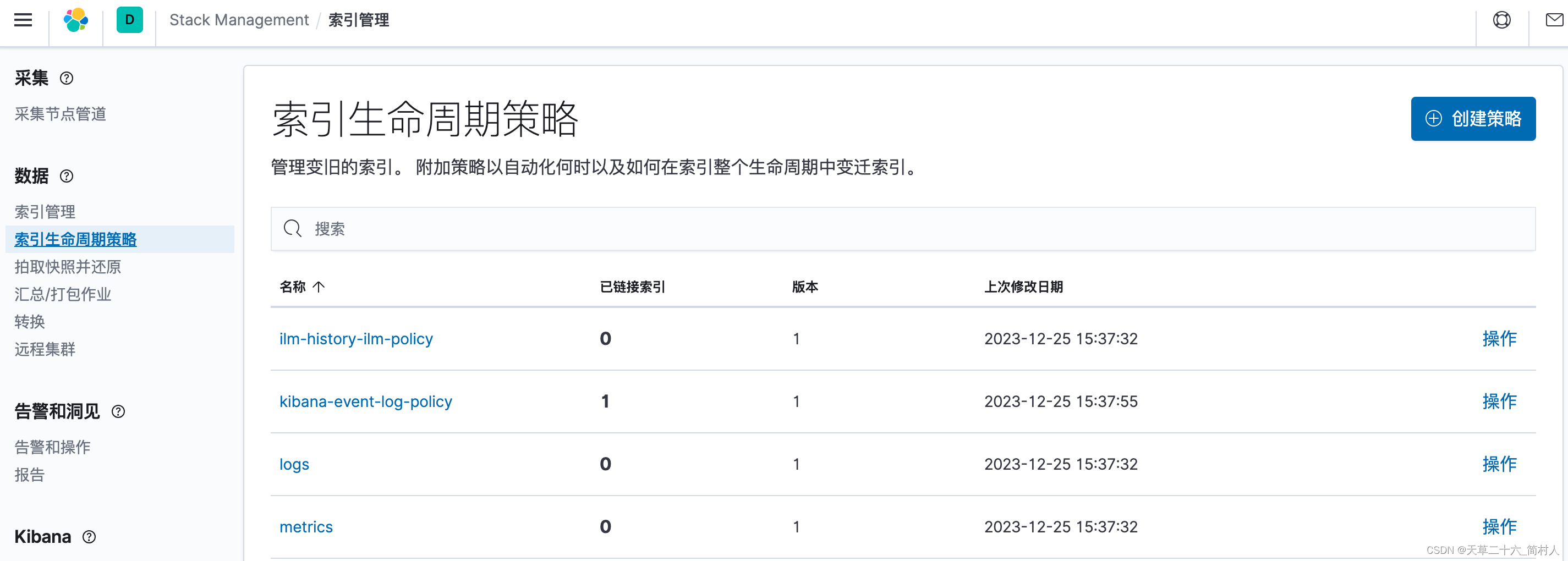
-
创建策略
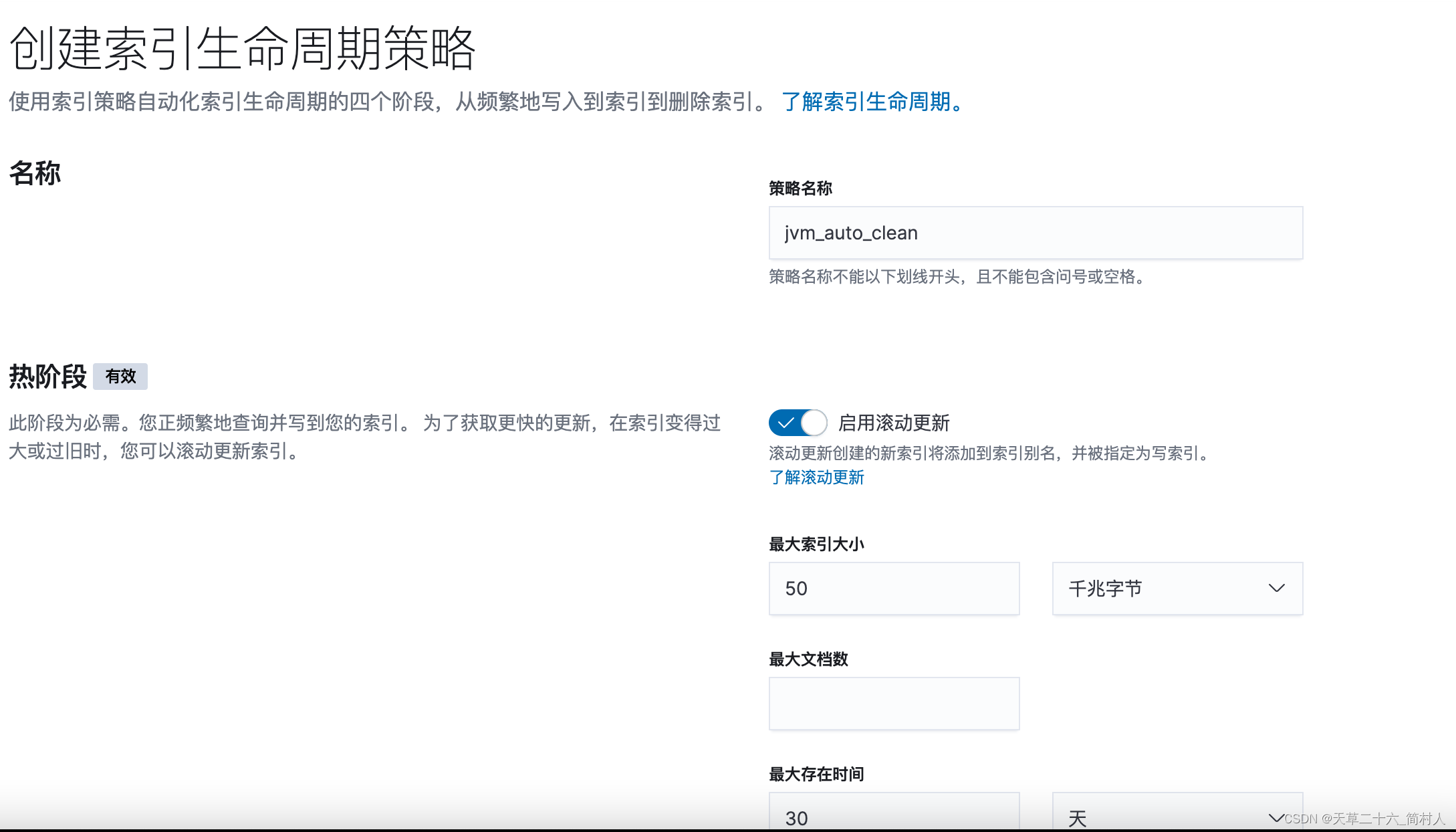
数据治理的策略分为四种: -
热阶段
-
温阶段
-
冷阶段
-
删除阶段
热阶段,此阶段为必需。默认即可。
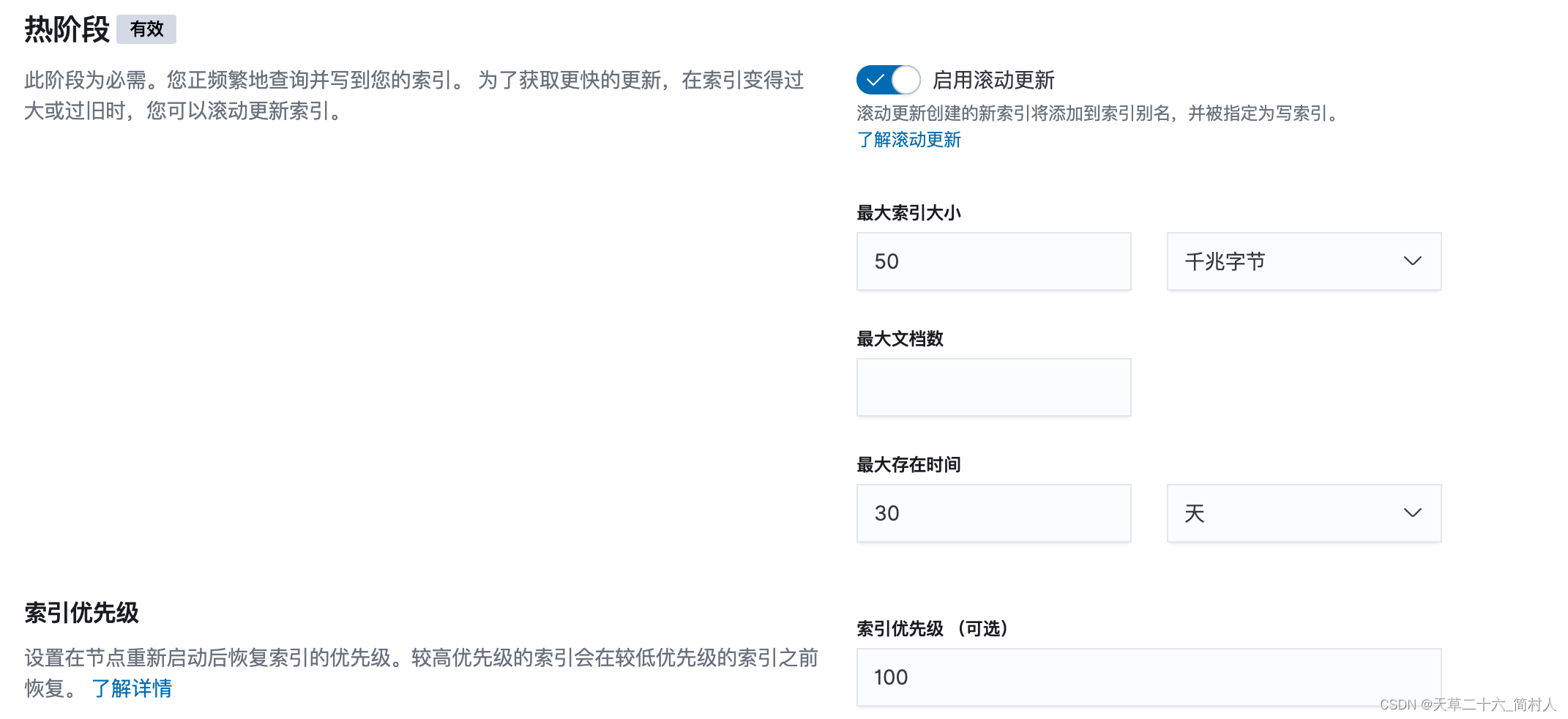
温阶段:您仍在查询自己的索引,但其为只读。您可以将分片分配给效率较低的硬件。为了获取更快的搜索,您可以减少分片数目并强制合并段。
冷阶段:您查询自己索引的频率较低,因此您可以在效率较低的硬件上分配分片。因为您的查询较为缓慢,所以您可以减少副本分片数目。
因为日志中心搭建的es是单节点模式,所以,不开启温和冷阶段。
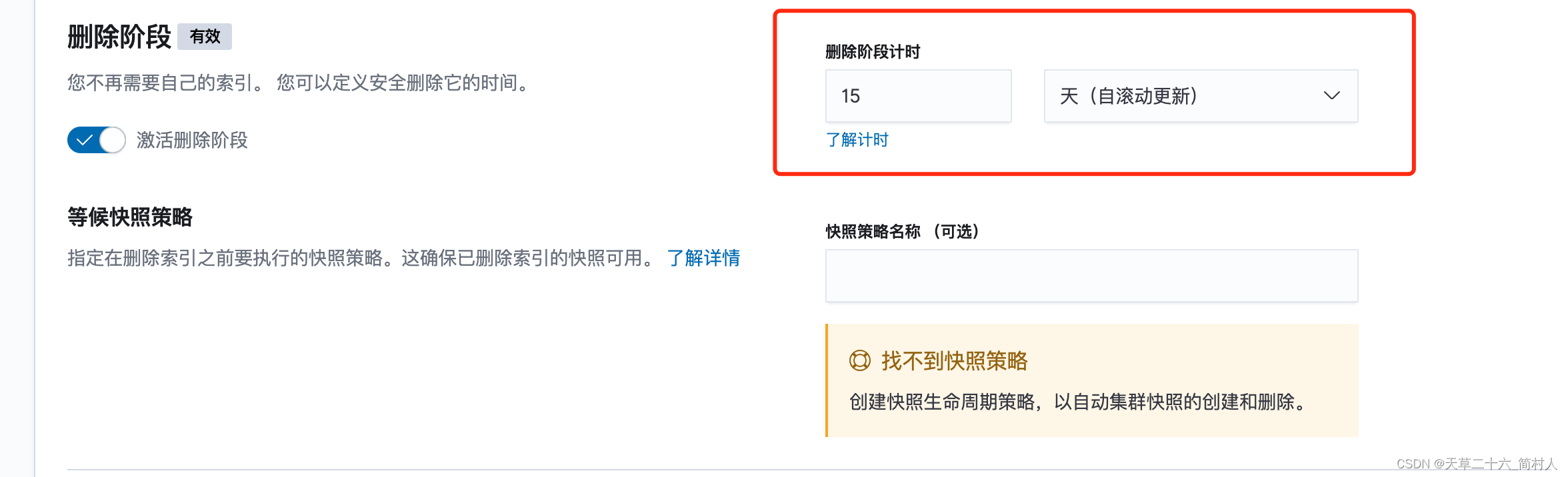
删除阶段
设置需要保存的天数,15天前的索引将被自动删除,从而控制其数据量。
另外,你可以根据需求创建快照,可以恢复删除的数据。(我这里也没有创建,因为研发环境下的日志数据其重要性较低)
3、其他事项
- 单节点
environment:
- "discovery.type=single-node"
- jvm配置
environment:
- "ES_JAVA_OPTS=-Xms1500m -Xmx1500m"
四、kibana之索引管理
你可以在kibana管理es的索引数据。
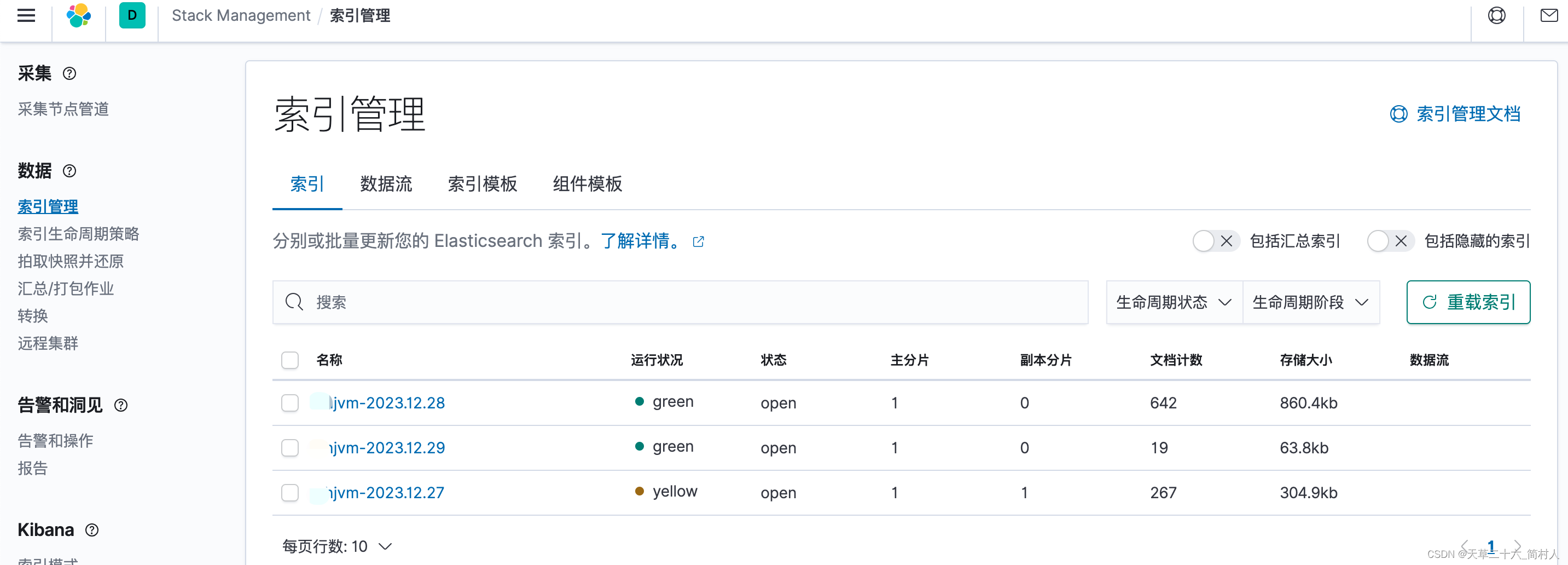
至此,我们的日志中心完成了一半,可以采集ecs虚拟机上的jvm日志。
下文,我们将介绍如何在k8s pod里采集jvm日志,以及大流量日志采集环境下,适当引入Kafka消息中间件。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 现性代数期末复习报告
- 基于辉芒微32位MCU(FT32_库函数开发)的高压包驱动模块(开源)
- Python爬虫使用代理IP的实现动态页面抓取
- Creating a new SqlSession
- 机器学习和深度学习检测网络安全课题资料:XSS、DNS和DGA、恶意URL、webshell
- 企业多云组网怎么办?
- 详解Java乱码问题,深入ASCII、GBK、UTF-8编码和解码(一学就会,通俗易懂版)
- 【redis】Redis中的字典类型:数据结构与使用方法
- 用c语言写一个抖音点赞系统
- Java学校实验室设备管理系统(源码+开题)