递归的递归之书:第五章到第九章
五、分而治之算法
原文:Chapter 5 - Divide-and-Conquer Algorithms
译者:飞龙

分而治之算法是将大问题分解为更小的子问题,然后将这些子问题分解为更小的问题,直到变得微不足道。这种方法使递归成为一种理想的技术:递归情况将问题分解为自相似的子问题,基本情况发生在子问题被减少到微不足道的大小时。这种方法的一个好处是这些问题可以并行处理,允许多个中央处理单元(CPU)核心或计算机处理它们。
在本章中,我们将研究一些常见的使用递归进行分而治之的算法,例如二分查找、快速排序和归并排序。我们还将重新审视对整数数组求和,这次采用分而治之的方法。最后,我们将看一下更神秘的 Karatsuba 乘法算法,它是在 1960 年开发的,为计算机硬件的快速整数乘法奠定了基础。
二分查找:在按字母顺序排列的书架上找书
假设你有一个有 100 本书的书架。你记不得你有哪些书,也不知道它们在书架上的确切位置,但你知道它们是按标题字母顺序排列的。要找到你的书Zebras: The Complete Guide,你不会从书架的开头开始,那里有Aaron Burr Biography,而是朝书架的末尾。如果你还有关于 zebras、动物园和合子的书,你的斑马书就不会是书架上的最后一本书,但会很接近。因此,你可以利用书是按字母顺序排列的这一事实,以及Z是字母表的最后一个字母作为启发式,或者近似线索,向书架的末尾而不是开头寻找。
二分查找是一种在排序列表中定位目标项的技术,它通过反复确定项在列表的哪一半来进行。搜索书架的最公正的方法是从中间的一本书开始,然后确定你要找的目标书是在左半部分还是右半部分。
然后,您可以重复这个过程,如图 5-1 所示:查看您选择的一半中间的书,然后确定您的目标书是否在左侧四分之一还是右侧四分之一。您可以一直这样做,直到找到书,或者找到书应该在的地方但却没有找到,并宣布书不存在于书架上。
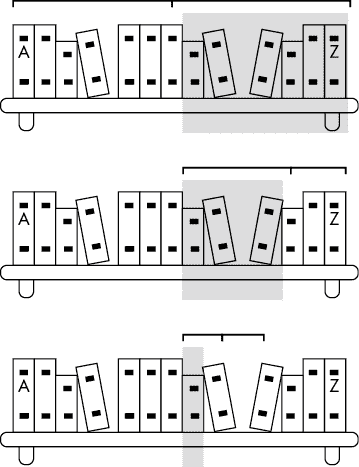
图 5-1:二分搜索反复确定范围的哪一半包含排序数组中的目标项。
这个过程的扩展效率很高;将要搜索的书籍数量加倍只会增加搜索过程的一步。对于有 50 本书的书架进行线性搜索需要 50 步,对于有 100 本书的书架进行线性搜索需要 100 步。但对于有 50 本书的书架进行二分搜索只需要 6 步,而对于有 100 本书的书架只需要 7 步。
让我们对我们的二分搜索实现提出三个递归问题:
-
什么是基本情况?搜索长度为 1 的项目范围。
-
传递给递归函数调用的参数是什么?我们正在搜索的列表范围的左右端的索引。
-
这个参数如何接近基本情况?每次递归调用时,范围的大小减半,因此最终变为一个项目长。
检查我们binarySearch.py程序中的以下binarySearch()函数,它在排序值haystack的排序列表中定位值needle:
Python
def binarySearch(needle, haystack, left=None, right=None):
# By default, `left` and `right` are all of `haystack`:
if left is None:
left = 0 # `left` defaults to the 0 index.
if right is None:
right = len(haystack) - 1 # `right` defaults to the last index.
print('Searching:', haystack[left:right + 1])
if left > right: # BASE CASE
return None # The `needle` is not in `haystack`.
mid = (left + right) // 2
if needle == haystack[mid]: # BASE CASE
return mid # The `needle` has been found in `haystack`
elif needle < haystack[mid]: # RECURSIVE CASE
return binarySearch(needle, haystack, left, mid - 1)
elif needle > haystack[mid]: # RECURSIVE CASE
return binarySearch(needle, haystack, mid + 1, right)
print(binarySearch(13, [1, 4, 8, 11, 13, 16, 19, 19]))
binarySearch.html程序有这个 JavaScript 等价物:
JavaScript
<script type="text/javascript">
function binarySearch(needle, haystack, left, right) {
// By default, `left` and `right` are all of `haystack`:
if (left === undefined) {
left = 0; // `left` defaults to the 0 index.
}
if (right === undefined) {
right = haystack.length - 1; // `right` defaults to the last index.
}
document.write("Searching: [" +
haystack.slice(left, right + 1).join(", ") + "]<br />");
if (left > right) { // BASE CASE
return null; // The `needle` is not in `haystack`.
}
let mid = Math.floor((left + right) / 2);
if (needle == haystack[mid]) { // BASE CASE
return mid; // The `needle` has been found in `haystack`.
} else if (needle < haystack[mid]) { // RECURSIVE CASE
return binarySearch(needle, haystack, left, mid - 1);
} else if (needle > haystack[mid]) { // RECURSIVE CASE
return binarySearch(needle, haystack, mid + 1, right);
}
}
document.write(binarySearch(13, [1, 4, 8, 11, 13, 16, 19, 19]));
</script>
当您运行这些程序时,将搜索列表[1, 4, 8, 11, 13, 16, 19, 19]中的13,输出如下:
Searching: [1, 4, 8, 11, 13, 16, 19, 19]
Searching: [13, 16, 19, 19]
Searching: [13]
4
目标值13确实在列表中的索引4处。
代码计算了由left和right索引定义的范围的中间索引(存储在mid中)。起初,这个范围是整个项目列表的长度。如果mid索引处的值与needle相同,则返回mid。否则,我们需要弄清楚我们的目标值是在范围的左半部分(在这种情况下,要搜索的新范围是left到mid - 1)还是在右半部分(在这种情况下,要搜索的新范围是mid + 1到end)。
我们已经有一个可以搜索这个新范围的函数:binarySearch()本身!对新范围进行递归调用。如果我们最终到达搜索范围的右端在左端之前的点,我们知道我们的搜索范围已经缩小到零,我们的目标值找不到。
请注意,递归调用返回后,代码不执行任何操作;它立即返回递归函数调用的返回值。这个特性意味着我们可以为这个递归算法实现尾递归优化,这是我们在第八章中解释的一种做法。但也意味着二分搜索可以很容易地作为一个不使用递归函数调用的迭代算法来实现。本书的可下载资源位于nostarch.com/recursive-book-recursion,其中包括用于比较递归二分搜索的迭代二分搜索的源代码。
快速排序:将未排序的书堆分成排序的堆
请记住,binarySearch()的速度优势来自于项目中的值是排序的。如果值是无序的,算法将无法工作。输入quicksort,这是由计算机科学家 Tony Hoare 在 1959 年开发的递归排序算法。
快速排序使用一种称为分区的分而治之技术。想象一下分区:想象你有一大堆未按字母顺序排列的书。拿起一本书并把它放在书架上的正确位置意味着当书架变得满时,你将花费大量时间重新排列书架。如果你首先将书堆分成两堆:一个A到M的堆和一个N到Z的堆会有所帮助。(在这个例子中,M将是我们的枢轴。)
你还没有对这堆进行排序,但你已经分区了。分区很容易:书不必放在两堆中的一个正确的位置,它只需放在正确的堆中。然后你可以进一步将这两堆分成四堆:A到G,H到M,N到T,和U到Z。这在图 5-2 中显示。如果你继续分区,最终会得到每堆包含一本书的情况(基本情况),而且这些堆现在是按顺序排列的。这意味着书现在也是按顺序排列的。这种重复的分区是快速排序的工作原理。
对于A到Z的第一次分区,我们选择M作为枢轴值,因为它是在A和Z之间的中间字母。然而,如果我们的书集包括一本关于亚伦·伯尔的书和 99 本关于斑马、和风、动物园、合子和其他Z主题的书,我们的两个分区堆将会严重失衡。我们会在A到M堆中有一本单独的亚伦·伯尔的书,而在M到Z堆中有其他所有的书。当分区均匀平衡时,快速排序算法的工作速度最快,因此在每个分区步骤中选择一个好的枢轴值是很重要的。

图 5-2:快速排序通过反复将项目分成两组来工作。
然而,如果你对你要排序的数据一无所知,那么选择一个理想的枢轴是不可能的。这就是为什么通用的快速排序算法简单地使用范围中的最后一个值作为枢轴值。
在我们的实现中,每次调用quicksort()都会给出一个要排序的项目数组。它还给出了left和right参数,指定了要对该数组中的索引范围进行排序,类似于binarySearch()的 left 和 right 参数。算法选择一个枢轴值与范围中的其他值进行比较,然后将这些值放在范围的左侧(如果它们小于枢轴值)或右侧(如果它们大于枢轴值)。这是分区步骤。接下来,quicksort()函数在这两个更小的范围上递归调用,直到一个范围已经减少到零。随着递归调用的进行,列表变得越来越有序,直到最终整个列表按正确的顺序排列。
请注意,该算法会就地修改数组。有关详细信息,请参见第四章中的“就地修改列表或数组”。因此,quicksort()函数不会返回一个排序好的数组。基本情况只是返回以停止产生更多的递归调用。
让我们对我们的二分搜索实现提出三个递归问题:
-
基本情况是什么?给定一个要排序的范围,其中包含零个或一个项目,并且已经按顺序排列。
-
递归函数调用传递了什么参数?我们正在排序的列表中范围的左右端的索引。
-
这个论点如何接近基本情况?每次递归调用时,范围的大小减半,所以最终变为空。
quicksort.py Python 程序中的以下quicksort()函数将 items 列表中的值按升序排序:
def quicksort(items, left=None, right=None):
# By default, `left` and `right` span the entire range of `items`:
if left is None:
left = 0 # `left` defaults to the 0 index.
if right is None:
right = len(items) - 1 # `right` defaults to the last index.
print('\nquicksort() called on this range:', items[left:right + 1])
print('................The full list is:', items)
if right <= left: # ?
# With only zero or one item, `items` is already sorted.
return # BASE CASE
# START OF THE PARTITIONING
i = left # i starts at the left end of the range. ?
pivotValue = items[right] # Select the last value for the pivot.
print('....................The pivot is:', pivotValue)
# Iterate up to, but not including, the pivot:
for j in range(left, right):
# If a value is less than the pivot, swap it so that it's on the
# left side of `items`:
if items[j] <= pivotValue:
# Swap these two values:
items[i], items[j] = items[j], items[i] ?
i += 1
# Put the pivot on the left side of `items`:
items[i], items[right] = items[right], items[i]
# END OF THE PARTITIONING
print('....After swapping, the range is:', items[left:right + 1])
print('Recursively calling quicksort on:', items[left:i], 'and', items[i + 1:right + 1])
# Call quicksort() on the two partitions:
quicksort(items, left, i - 1) # RECURSIVE CASE
quicksort(items, i + 1, right) # RECURSIVE CASE
myList = [0, 7, 6, 3, 1, 2, 5, 4]
quicksort(myList)
print(myList)
quicksort.html程序包含了 JavaScript 等效程序:
<script type="text/javascript">
function quicksort(items, left, right) {
// By default, `left` and `right` span the entire range of `items`:
if (left === undefined) {
left = 0; // `left` defaults to the 0 index.
}
if (right === undefined) {
right = items.length - 1; // `right` defaults to the last index.
}
document.write("<br /><pre>quicksort() called on this range: [" +
items.slice(left, right + 1).join(", ") + "]</pre>");
document.write("<pre>................The full list is: [" + items.join(", ") + "]</pre>");
if (right <= left) { // ?
// With only zero or one item, `items` is already sorted.
return; // BASE CASE
}
// START OF THE PARTITIONING
let i = left; ? // i starts at the left end of the range.
let pivotValue = items[right]; // Select the last value for the pivot.
document.write("<pre>....................The pivot is: " + pivotValue.toString() +
"</pre>");
// Iterate up to, but not including, the pivot:
for (let j = left; j < right; j++) {
// If a value is less than the pivot, swap it so that it's on the
// left side of `items`:
if (items[j] <= pivotValue) {
// Swap these two values:
[items[i], items[j]] = [items[j], items[i]]; ?
i++;
}
}
// Put the pivot on the left side of `items`:
[items[i], items[right]] = [items[right], items[i]];
// END OF THE PARTITIONING
document.write("<pre>....After swapping, the range is: [" + items.slice(left, right + 1).join(", ") + "]</pre>");
document.write("<pre>Recursively calling quicksort on: [" + items.slice(left, i).join(", ") + "] and [" + items.slice(i + 1, right + 1).join(", ") + "]</pre>");
// Call quicksort() on the two partitions:
quicksort(items, left, i - 1); // RECURSIVE CASE
quicksort(items, i + 1, right); // RECURSIVE CASE
}
let myList = [0, 7, 6, 3, 1, 2, 5, 4];
quicksort(myList);
document.write("<pre>[" + myList.join(", ") + "]</pre>");
</script>
这段代码类似于二分搜索算法中的代码。作为默认值,我们将items数组中范围的left和right端设置为整个数组的开始和结束。如果算法达到了right端在left端之前或在left端之前的基本情况(一个或零个项目的范围),则排序完成?。
在每次调用quicksort()时,我们对当前范围内的项目进行分区(由left和right中的索引定义),然后交换它们,使得小于枢纽值的项目最终位于范围的左侧,而大于枢纽值的项目最终位于范围的右侧。例如,如果数组[81, 48, 94, 87, 83, 14, 6, 42]中的枢纽值为42,则分区后的数组将是[14, 6, 42, 81, 48, 94, 87, 83]。请注意,分区后的数组与排序后的数组不同:尽管42左侧的两个项目小于42,42右侧的五个项目大于42,但项目并不按顺序排列。
quicksort()函数的主要部分是分区步骤。要了解分区的工作原理,想象一个索引j,它从范围的左端开始并向右端移动?。我们将索引j处的项目与枢纽值进行比较,然后向右移动以比较下一个项目。枢纽值可以任意选择范围内的任何值,但我们将始终使用范围的右端的值。
想象一下第二个索引i,它也从左端开始。如果索引j处的项目小于或等于枢纽值,则交换索引i和j处的项目?,并将i增加到下一个索引。因此,j在与枢纽值进行比较后总是增加(即向右移动),而i只有在索引j处的项目小于或等于枢纽值时才会增加。
i和j这两个名称通常用于保存数组索引的变量。其他人的quicksort()实现可能会使用j和i,甚至完全不同的变量。重要的是要记住,这两个变量存储索引并且表现如此。
例如,让我们来看看数组[0, 7, 6, 3, 1, 2, 5, 4]的第一次分区,范围由left为0和right为7定义,覆盖数组的整个大小。pivot将是右端的值4。i和j索引从索引0开始,即范围的左端。在每一步中,索引j总是向右移动。只有当索引j处的值小于或等于枢纽值时,索引i才会移动。items数组,i索引和j索引的初始状态如下:
items: [0, 7, 6, 3, 1, 2, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 0 i
j = 0 j
索引j处的值(为0)小于或等于枢纽值(为4),因此交换i和j处的值。这实际上没有产生任何变化,因为i和j是相同的索引。此外,增加i,使其向右移动。j索引在与枢纽值进行比较时每次都会增加。变量的状态现在如下所示:
items: [0, 7, 6, 3, 1, 2, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 1 i
j = 1 j
索引j处的值(为7)不小于或等于枢纽值(为4),因此不交换值。请记住,j始终增加,但只有在执行交换后i才会增加——因此i始终在j处或左侧。变量的状态现在如下所示:
items: [0, 7, 6, 3, 1, 2, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 1 i ^
j = 2 j
索引j处的值(为6)不小于或等于枢纽值(为4),因此不交换值。变量的状态现在如下所示:
items: [0, 7, 6, 3, 1, 2, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 1 i ^
j = 3 j
索引j处的值(为3)小于或等于枢纽值(为4),因此交换i和j处的值。7和3交换位置。此外,增加i,使其向右移动。变量的状态现在如下所示:
items: [0, 3, 6, 7, 1, 2, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 2 i ^
j = 4 j
索引j处的值(为1)小于或等于枢纽值(为4),因此交换i和j处的值。6和1交换位置。此外,增加i,使其向右移动。变量的状态现在如下所示:
items: [0, 3, 1, 7, 6, 2, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 3 i ^
j = 5 j
索引j处的值(为2)小于或等于枢纽值(为4),因此交换i和j处的值。7和2交换位置。此外,增加i,使其向右移动。变量的状态现在如下所示:
items: [0, 3, 1, 2, 6, 7, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 4 i ^
j = 6 j
索引j处的值(为6)不小于或等于枢轴值(为4),因此不交换值。现在变量的状态如下:
items: [0, 3, 1, 2, 6, 7, 5, 4]
indices: 0 1 2 3 4 5 6 7
^
i = 4 i ^
j = 7 j
我们已经到达了分区的末尾。索引j位于枢轴值(始终是范围中最右边的值)处,因此让我们最后一次交换i和j,以确保枢轴不在分区的右半部分。6和4交换位置。现在变量的状态如下:
items: [0, 3, 1, 2, 4, 7, 5, 6]
indices: 0 1 2 3 4 5 6 7
^
i = 4 i ^
j = 7 j
注意i索引的变化:由于交换的结果,该索引始终会接收小于枢轴值的值;然后i索引向右移动以接收未来小于枢轴值的值。因此,i索引左侧的所有值都小于或等于枢轴,而i索引右侧的所有值都大于枢轴。
整个过程会重复进行,我们会在左右分区上递归调用quicksort()。当我们对这两半进行分区(然后对这两半的四半进行分区,再进行更多递归的quicksort()调用,依此类推),整个数组最终会被排序。
当我们运行这些程序时,输出显示了对[0, 7, 6, 3, 1, 2, 5, 4]列表进行排序的过程。点的行用于在编写代码时对齐输出:
quicksort() called on this range: [0, 7, 6, 3, 1, 2, 5, 4]
................The full list is: [0, 7, 6, 3, 1, 2, 5, 4]
....................The pivot is: 4
....After swapping, the range is: [0, 3, 1, 2, 4, 7, 5, 6]
Recursively calling quicksort on: [0, 3, 1, 2] and [7, 5, 6]
quicksort() called on this range: [0, 3, 1, 2]
................The full list is: [0, 3, 1, 2, 4, 7, 5, 6]
....................The pivot is: 2
....After swapping, the range is: [0, 1, 2, 3]
Recursively calling quicksort on: [0, 1] and [3]
quicksort() called on this range: [0, 1]
................The full list is: [0, 1, 2, 3, 4, 7, 5, 6]
....................The pivot is: 1
....After swapping, the range is: [0, 1]
Recursively calling quicksort on: [0] and []
quicksort() called on this range: [0]
................The full list is: [0, 1, 2, 3, 4, 7, 5, 6]
quicksort() called on this range: []
................The full list is: [0, 1, 2, 3, 4, 7, 5, 6]
quicksort() called on this range: [3]
................The full list is: [0, 1, 2, 3, 4, 7, 5, 6]
quicksort() called on this range: [7, 5, 6]
................The full list is: [0, 1, 2, 3, 4, 7, 5, 6]
....................The pivot is: 6
....After swapping, the range is: [5, 6, 7]
Recursively calling quicksort on: [5] and [7]
quicksort() called on this range: [5]
................The full list is: [0, 1, 2, 3, 4, 5, 6, 7]
quicksort() called on this range: [7]
................The full list is: [0, 1, 2, 3, 4, 5, 6, 7]
Sorted: [0, 1, 2, 3, 4, 5, 6, 7]
快速排序是一种常用的排序算法,因为它易于实现,而且速度快。另一种常用的排序算法——归并排序也很快,而且使用了递归。我们接下来会介绍它。
归并排序:将小堆纸牌合并成更大的排序好的堆
计算机科学家约翰·冯·诺伊曼于 1945 年开发了归并排序。它采用了分割-合并的方法:每次对mergeSort()的递归调用都将未排序的列表分成两半,直到它们被分割成长度为零或一的列表。然后,随着递归调用的返回,这些较小的列表被合并成排序好的顺序。当最后一个递归调用返回时,整个列表将被排序。
例如,分割步骤将列表[2, 9, 8, 5, 3, 4, 7, 6]分成两个列表,如[2, 9, 8, 5]和[3, 4, 7, 6],然后传递给两个递归函数调用。在基本情况下,列表已经被分成了零个或一个项目的列表。没有项目或一个项目的列表自然是排序好的。递归调用返回后,代码将这些小的排序好的列表合并成更大的排序好的列表,直到最终整个列表被排序。图 5-3 展示了使用归并排序对纸牌进行排序的示例。
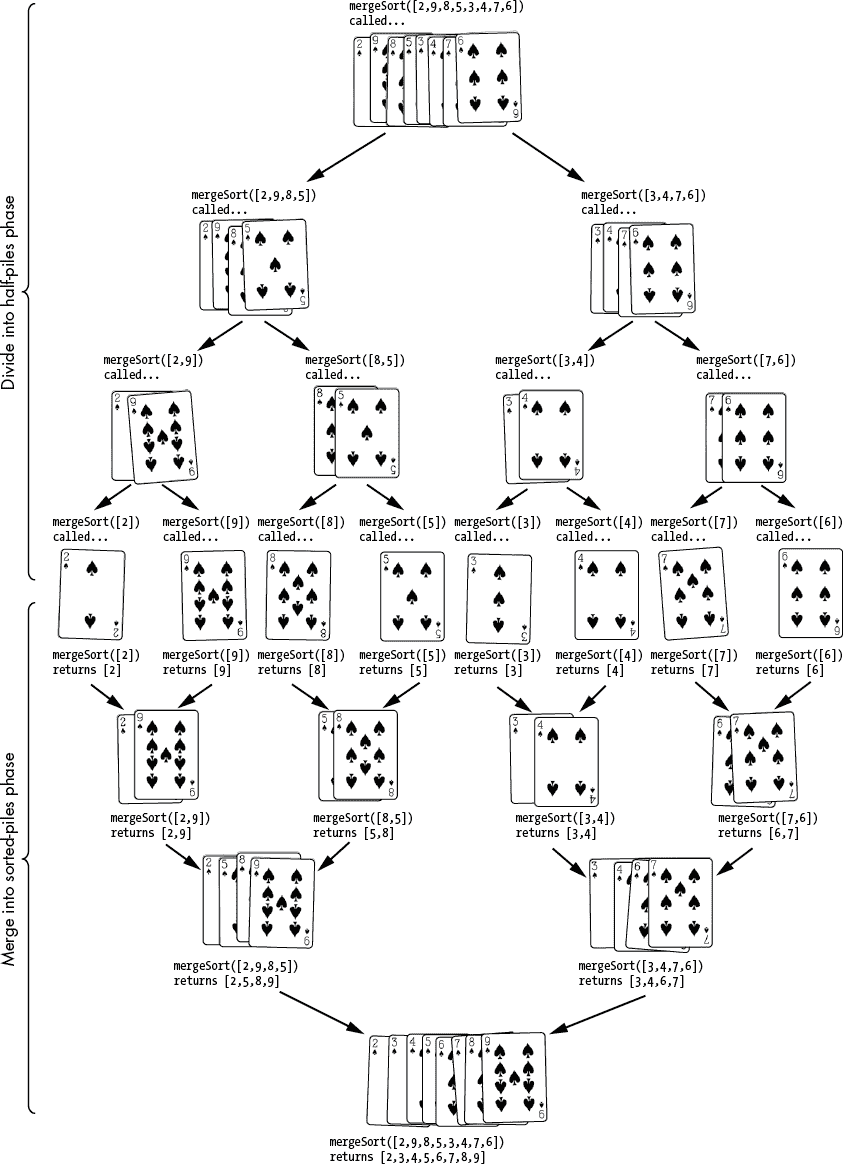
图 5-3:归并排序的分割和合并阶段
例如,在分割阶段结束时,我们有八个单独的数字列表:[2], [9], [8], [5], [3], [4], [7], [6]。只有一个数字的列表自然是按顺序排列的。将两个排序好的列表合并成一个更大的排序好的列表涉及查看两个较小列表的开头,并将较小的值附加到较大的列表上。图 5-4 显示了合并[2, 9]和[5, 8]的示例。在合并阶段中重复执行此操作,直到最终结果是原始的mergeSort()调用以排序顺序返回完整列表。
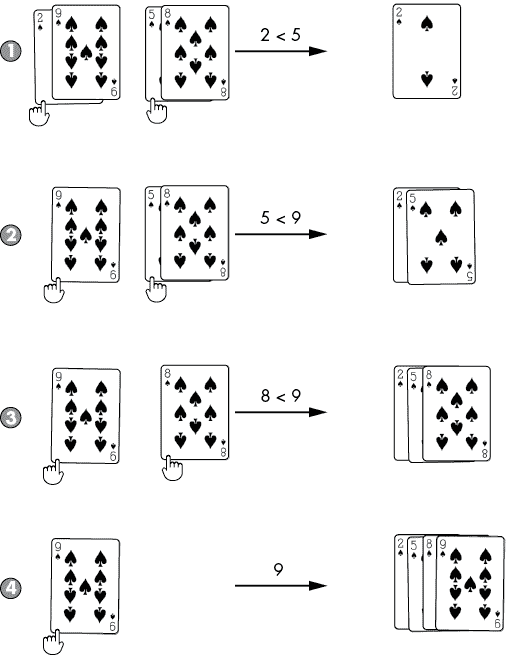
图 5-4:合并步骤比较较小排序列表开头的两个值,并将它们移动到较大的排序列表中。合并四张卡只需要四个步骤。
让我们问一下我们的三个递归算法问题关于归并排序算法:
-
什么是基本情况? 给定一个要排序的列表,其中有零个或一个项目,已经按排序顺序排列。
-
递归函数调用传递了什么参数? 由原始列表的左半部分和右半部分制成的列表。
-
这个参数如何接近基本情况? 传递给递归调用的列表的大小是原始列表的一半,因此最终成为零个或一个项目的列表。
mergeSort.py Python 程序中的以下mergeSort()函数将项目列表中的值按升序排序:
import math
def mergeSort(items):
print('.....mergeSort() called on:', items)
# BASE CASE - Zero or one item is naturally sorted:
if len(items) == 0 or len(items) == 1:
return items # ?
# RECURSIVE CASE - Pass the left and right halves to mergeSort():
# Round down if items doesn't divide in half evenly:
iMiddle = math.floor(len(items) / 2) # ?
print('................Split into:', items[:iMiddle], 'and', items[iMiddle:])
left = mergeSort(items[:iMiddle]) # ?
right = mergeSort(items[iMiddle:])
# BASE CASE - Returned merged, sorted data:
# At this point, left should be sorted and right should be
# sorted. We can merge them into a single sorted list.
sortedResult = []
iLeft = 0
iRight = 0
while (len(sortedResult) < len(items)):
# Append the smaller value to sortedResult.
if left[iLeft] < right[iRight]: # ?
sortedResult.append(left[iLeft])
iLeft += 1
else:
sortedResult.append(right[iRight])
iRight += 1
# If one of the pointers has reached the end of its list,
# put the rest of the other list into sortedResult.
if iLeft == len(left):
sortedResult.extend(right[iRight:])
break
elif iRight == len(right):
sortedResult.extend(left[iLeft:])
break
print('The two halves merged into:', sortedResult)
return sortedResult # Returns a sorted version of items.
myList = [2, 9, 8, 5, 3, 4, 7, 6]
myList = mergeSort(myList)
print(myList)
mergeSort.html程序包含等效的 JavaScript 程序:
<script type="text/javascript">
function mergeSort(items) {
document.write("<pre>" + ".....mergeSort() called on: [" +
items.join(", ") + "]</pre>");
// BASE CASE - Zero or one item is naturally sorted:
if (items.length === 0 || items.length === 1) { // BASE CASE
return items; // ?
}
// RECURSIVE CASE - Pass the left and right halves to mergeSort():
// Round down if items doesn't divide in half evenly:
let iMiddle = Math.floor(items.length / 2); // ?
document.write("<pre>................Split into: [" + items.slice(0, iMiddle).join(", ") +
"] and [" + items.slice(iMiddle).join(", ") + "]</pre>");
let left = mergeSort(items.slice(0, iMiddle)); // ?
let right = mergeSort(items.slice(iMiddle));
// BASE CASE - Returned merged, sorted data:
// At this point, left should be sorted and right should be
// sorted. We can merge them into a single sorted list.
let sortedResult = [];
let iLeft = 0;
let iRight = 0;
while (sortedResult.length < items.length) {
// Append the smaller value to sortedResult.
if (left[iLeft] < right[iRight]) { // ?
sortedResult.push(left[iLeft]);
iLeft++;
} else {
sortedResult.push(right[iRight]);
iRight++;
}
// If one of the pointers has reached the end of its list,
// put the rest of the other list into sortedResult.
if (iLeft == left.length) {
Array.prototype.push.apply(sortedResult, right.slice(iRight));
break;
} else if (iRight == right.length) {
Array.prototype.push.apply(sortedResult, left.slice(iLeft));
break;
}
}
document.write("<pre>The two halves merged into: [" + sortedResult.join(", ") +
"]</pre>");
return sortedResult; // Returns a sorted version of items.
}
let myList = [2, 9, 8, 5, 3, 4, 7, 6];
myList = mergeSort(myList);
document.write("<pre>[" + myList.join(", ") + "]</pre>");
</script>
mergeSort()函数(以及对mergeSort()函数的所有递归调用)接受一个未排序的列表并返回一个排序的列表。该函数的第一步是检查列表是否只包含零个或一个项目?。这个列表已经排序,所以函数原样返回列表。
否则,函数确定列表的中间索引?,以便我们知道在哪里将其分成左半部分和右半部分列表,然后传递给两个递归函数调用?。递归函数调用返回排序的列表,我们将其存储在左侧和右侧变量中。
下一步是将这两个排序好的半列表合并成一个排序好的完整列表,命名为sortedResult。我们将为left和right列表维护两个索引,命名为iLeft和iRight。在循环内,将两个值中较小的一个?附加到sortedResult,并递增其相应的索引变量(iLeft或iRight)。如果iLeft或iRight达到其列表的末尾,则将另一半列表中剩余的项目附加到sortedResult。
让我们跟随一个合并步骤的示例,如果递归调用已经返回了[2, 9]作为left和[5, 8]作为right。由于这些列表是从mergeSort()调用返回的,我们总是可以假设它们是排序好的。我们必须将它们合并成一个单独的排序好的列表,以便当前的mergeSort()调用将其返回给其调用者。
iLeft和iRight索引从0开始。我们比较left[iLeft](为2)和right[iRight](为5)的值,以找到较小的值:
sortedResult = []
left: [2, 9] right: [5, 8]
indices: 0 1 0 1
iLeft = 0 ^
iRight = 0 ^
由于left[iLeft]的值2是较小的值,我们将其附加到sortedResult并将iLeft从0增加到1。 变量的状态现在如下:
sortedResult = [2]
left: [2, 9] right: [5, 8]
indices: 0 1 0 1
iLeft = 1 ^
iRight = 0 ^
再次比较left[iLeft]和right[iRight],我们发现9和5中,right[iRight]的5更小。 代码将5附加到sortedResult并将iRight从0增加到1。 变量的状态现在如下:
sortedResult = [2, 5]
left: [2, 9] right: [5, 8]
indices: 0 1 0 1
iLeft = 1 ^
iRight = 1 ^
再次比较left[iLeft]和right[iRight],我们发现9和8中,right[iRight]的8更小。 代码将8附加到sortedResult并将iRight从0增加到1。 现在变量的状态如下:
sortedResult = [2, 5, 8]
left: [2, 9] right: [5, 8]
indices: 0 1 0 1
iLeft = 1 ^
iRight = 2 ^
因为iRight现在是2,等于right列表的长度,所以从iLeft索引到末尾的left中剩余的项目被附加到sortedResult,因为right中没有更多的项目可以与它们进行比较。这使得sortedResult成为[2, 5, 8, 9],它需要返回的排序列表。这个合并步骤对每次mergeSort()调用都执行,以产生最终排序的列表。
当我们运行mergeSort.py和mergeSort.html程序时,输出显示了对[2, 9, 8, 5, 3, 4, 7, 6]列表进行排序的过程。
.....mergeSort() called on: [2, 9, 8, 5, 3, 4, 7, 6]
................Split into: [2, 9, 8, 5] and [3, 4, 7, 6]
.....mergeSort() called on: [2, 9, 8, 5]
................Split into: [2, 9] and [8, 5]
.....mergeSort() called on: [2, 9]
................Split into: [2] and [9]
.....mergeSort() called on: [2]
.....mergeSort() called on: [9]
The two halves merged into: [2, 9]
.....mergeSort() called on: [8, 5]
................Split into: [8] and [5]
.....mergeSort() called on: [8]
.....mergeSort() called on: [5]
The two halves merged into: [5, 8]
The two halves merged into: [2, 5, 8, 9]
.....mergeSort() called on: [3, 4, 7, 6]
................Split into: [3, 4] and [7, 6]
.....mergeSort() called on: [3, 4]
................Split into: [3] and [4]
.....mergeSort() called on: [3]
.....mergeSort() called on: [4]
The two halves merged into: [3, 4]
.....mergeSort() called on: [7, 6]
................Split into: [7] and [6]
.....mergeSort() called on: [7]
.....mergeSort() called on: [6]
The two halves merged into: [6, 7]
The two halves merged into: [3, 4, 6, 7]
The two halves merged into: [2, 3, 4, 5, 6, 7, 8, 9]
[2, 3, 4, 5, 6, 7, 8, 9]
从输出中可以看出,该函数将[2, 9, 8, 5, 3, 4, 7, 6]列表分成[2, 9, 8, 5]和[3, 4, 7, 6],并将它们传递给递归的mergeSort()调用。第一个列表进一步分成[2, 9]和[8, 5]。[2, 9]列表分成[2]和[9]。这些单值列表不能再分割,所以我们已经达到了基本情况。这些列表合并成排序后的顺序为[2, 9]。函数将[8, 5]列表分成[8]和[5],达到基本情况,然后合并成[5, 8]。
[2, 9]和[5, 8]列表分别按顺序排序。记住,mergeSort()不只是将列表简单地连接成[2, 9, 5, 8],这样不会按顺序排序。相反,该函数将它们合并成排序后的列表[2, 5, 8, 9]。当原始的mergeSort()调用返回时,返回的完整列表已完全排序。
对整数数组求和
我们已经在第三章中使用头尾技术对整数数组求和进行了讨论。在本章中,我们将使用分治策略。由于加法的结合律意味着将 1 + 2 + 3 + 4 相加与将 1 + 2 和 3 + 4 的和相加是相同的,我们可以将要求和的大数组分成两个要求和的小数组。
好处在于,对于更大的数据集,我们可以将子问题分配给不同的计算机,并让它们并行工作。无需等待数组的前半部分被求和,另一台计算机就可以开始对后半部分进行求和。这是分治技术的一个很大的优势,因为 CPU 的速度并没有提高多少,但我们可以让多个 CPU 同时工作。
让我们对求和函数的递归算法提出三个问题:
-
基本情况是什么?要么是包含零个数字的数组(返回
0),要么是包含一个数字的数组(返回该数字)。 -
递归函数调用传递了什么参数?要么是数字数组的左半部分,要么是右半部分。
-
这个参数如何变得更接近基本情况?每次数组的大小减半,最终变成一个包含零个或一个数字的数组。
sumDivConq.py Python 程序实现了sumDivConq()函数中的分治策略,用于对数字进行求和。
Python
def sumDivConq(numbers):
if len(numbers) == 0: # BASE CASE
return 0 # ?
elif len(numbers) == 1: # BASE CASE
return numbers[0] # ?
else: # RECURSIVE CASE
mid = len(numbers) // 2 # ?
leftHalfSum = sumDivConq(numbers[0:mid])
rightHalfSum = sumDivConq(numbers[mid:len(numbers) + 1])
return leftHalfSum + rightHalfSum # ?
nums = [1, 2, 3, 4, 5]
print('The sum of', nums, 'is', sumDivConq(nums))
nums = [5, 2, 4, 8]
print('The sum of', nums, 'is', sumDivConq(nums))
nums = [1, 10, 100, 1000]
print('The sum of', nums, 'is', sumDivConq(nums))
sumDivConq.html程序包含了 JavaScript 的等效内容。
JavaScript
<script type="text/javascript">
function sumDivConq(numbers) {
if (numbers.length === 0) { // BASE CASE
return 0; // ?
} else if (numbers.length === 1) { // BASE CASE
return numbers[0]; // ?
} else { // RECURSIVE CASE
let mid = Math.floor(numbers.length / 2); // ?
let leftHalfSum = sumDivConq(numbers.slice(0, mid));
let rightHalfSum = sumDivConq(numbers.slice(mid, numbers.length + 1));
return leftHalfSum + rightHalfSum; // ?
}
}
let nums = [1, 2, 3, 4, 5];
document.write('The sum of ' + nums + ' is ' + sumDivConq(nums) + "<br />");
nums = [5, 2, 4, 8];
document.write('The sum of ' + nums + ' is ' + sumDivConq(nums) + "<br />");
nums = [1, 10, 100, 1000];
document.write('The sum of ' + nums + ' is ' + sumDivConq(nums) + "<br />");
</script>
该程序的输出是:
The sum of [1, 2, 3, 4, 5] is 15
The sum of [5, 2, 4, 8] is 19
The sum of [1, 10, 100, 1000] is 1111
sumDivConq()函数首先检查numbers数组是否包含零个或一个数字。这些微不足道的基本情况很容易求和,因为它们不需要进行加法:返回0或数组中的单个数字。其他情况是递归的;计算数组的中间索引,以便对数字数组的左半部分和右半部分进行单独的递归调用。这两个返回值的和成为当前sumDivConq()调用的返回值。
由于加法的结合性质,没有理由要求一个数字数组必须由单个计算机按顺序相加。我们的程序在同一台计算机上执行所有操作,但对于大数组或比加法更复杂的计算,我们的程序可以将一半数据发送到其他计算机上进行处理。这个问题可以分解成类似的子问题,这是一个递归方法可以被采用的重要提示。
Karatsuba 乘法
*运算符使得在高级编程语言(如 Python 和 JavaScript)中进行乘法变得容易。但是低级硬件需要一种使用更原始操作进行乘法的方法。我们可以使用循环仅使用加法来相乘两个整数,比如下面的 Python 代码来相乘5678 * 1234:
>>> x = 5678
>>> y = 1234
>>> product = 0
>>> for i in range(x):
... product += y
...
>>> product
7006652
然而,这段代码对大整数的扩展效率并不高。Karatsuba 乘法是一种快速的递归算法,由 Anatoly Karatsuba 于 1960 年发现,可以使用加法、减法和预先计算的所有单个数字乘积的乘法表来相乘整数。这个乘法表,如图 5-5 所示,被称为查找表。
我们的算法不需要相乘单个数字,因为它可以直接在表中查找。通过使用内存存储预先计算的值,我们增加了内存使用量以减少 CPU 运行时间。

图 5-5:查找表,比如这个包含所有单个数字乘积的表,可以使我们的程序避免重复计算,因为计算机将预先计算的值存储在内存中以供以后检索。
我们将在高级语言(如 Python 或 JavaScript)中实现 Karatsuba 乘法,就好像*运算符并不存在一样。我们的karatsuba()函数接受两个整数参数x和y进行相乘。Karatsuba 算法有五个步骤,前三个步骤涉及对从x和y派生的较小的、分解的整数进行递归调用karatsuba()。基本情况发生在x和y参数都是单个数字时,此时可以在预先计算的查找表中找到乘积。
我们还定义了四个变量:a和b分别是x的数字的一半,c和d分别是y的数字的一半,如图 5-6 所示。例如,如果x和y分别是5678和1234,那么a是56,b是78,c是12,d是34。
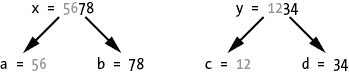
图 5-6:要相乘的整数x和y被分成一半a、b、c和d。
以下是 Karatsuba 算法的五个步骤:
-
将
a和c相乘,可以从乘法查找表中查找,也可以通过对karatsuba()进行递归调用来实现。 -
将
b和d相乘,可以从乘法查找表中查找,也可以通过对karatsuba()进行递归调用来实现。 -
将
a + c和b + d相乘,可以从乘法查找表中查找,也可以通过对karatsuba()进行递归调用来实现。 -
计算第 3 步 - 第 2 步 - 第 1 步。
-
用零填充第 1 步和第 4 步的结果,然后将它们加到第 2 步。
第 5 步的结果是x和y的乘积。如何用零填充第 1 步和第 4 步的结果的具体方法将在本节后面解释。
让我们向karatsuba()函数提出三个递归算法的问题:
-
基本情况是什么?相乘单个数字,可以在预先计算的查找表中找到。
-
递归函数调用传递了什么参数?从
x和y参数派生的a、b、c和d的值。 -
这个参数是如何变得更接近基本情况的呢?因为
a、b、c和d分别是x和y的一半,并且它们自己被用作下一个递归调用的x和y参数,递归调用的参数变得越来越接近基本情况所需的单个数字。
我们的 Python 实现 Karatsuba 乘法在karatsubaMultiplication.py程序中:
import math
# Create a lookup table of all single-digit multiplication products:
MULT_TABLE = {} # ?
for i in range(10):
for j in range(10):
MULT_TABLE[(i, j)] = i * j
def padZeros(numberString, numZeros, insertSide):
"""Return a string padded with zeros on the left or right side."""
if insertSide == 'left':
return '0' * numZeros + numberString
elif insertSide == 'right':
return numberString + '0' * numZeros
def karatsuba(x, y):
"""Multiply two integers with the Karatsuba algorithm. Note that
the * operator isn't used anywhere in this function."""
assert isinstance(x, int), 'x must be an integer'
assert isinstance(y, int), 'y must be an integer'
x = str(x)
y = str(y)
# At single digits, look up the products in the multiplication table:
if len(x) == 1 and len(y) == 1: # BASE CASE
print('Lookup', x, '*', y, '=', MULT_TABLE[(int(x), int(y))])
return MULT_TABLE[(int(x), int(y))]
# RECURSIVE CASE
print('Multiplying', x, '*', y)
# Pad with prepended zeros so that x and y are the same length:
if len(x) < len(y): # ?
# If x is shorter than y, pad x with zeros:
x = padZeros(x, len(y) - len(x), 'left')
elif len(y) < len(x):
# If y is shorter than x, pad y with zeros:
y = padZeros(y, len(x) - len(y), 'left')
# At this point, x and y have the same length.
halfOfDigits = math.floor(len(x) / 2) # ?
# Split x into halves a & b, split y into halves c & d:
a = int(x[:halfOfDigits])
b = int(x[halfOfDigits:])
c = int(y[:halfOfDigits])
d = int(y[halfOfDigits:])
# Make the recursive calls with these halves:
step1Result = karatsuba(a, c) # ? # Step 1: Multiply a & c.
step2Result = karatsuba(b, d) # Step 2: Multiply b & d.
step3Result = karatsuba(a + b, c + d) # Step 3: Multiply a + b & c + d.
# Step 4: Calculate Step 3 - Step 2 - Step 1:
step4Result = step3Result - step2Result - step1Result # ?
# Step 5: Pad these numbers, then add them for the return value:
step1Padding = (len(x) - halfOfDigits) + (len(x) - halfOfDigits)
step1PaddedNum = int(padZeros(str(step1Result), step1Padding, 'right'))
step4Padding = (len(x) - halfOfDigits)
step4PaddedNum = int(padZeros(str(step4Result), step4Padding, 'right'))
print('Solved', x, 'x', y, '=', step1PaddedNum + step2Result + step4PaddedNum)
return step1PaddedNum + step2Result + step4PaddedNum # ?
# Example: 1357 x 2468 = 3349076
print('1357 * 2468 =', karatsuba(1357, 2468))
JavaScript 的等价代码在karatsubaMultiplication.html中。
<script type="text/javascript">
// Create a lookup table of all single-digit multiplication products:
let MULT_TABLE = {}; // ?
for (let i = 0; i < 10; i++) {
for (let j = 0; j < 10; j++) {
MULT_TABLE[[i, j]] = i * j;
}
}
function padZeros(numberString, numZeros, insertSide) {
// Return a string padded with zeros on the left or right side.
if (insertSide === "left") {
return "0".repeat(numZeros) + numberString;
} else if (insertSide === "right") {
return numberString + "0".repeat(numZeros);
}
}
function karatsuba(x, y) {
// Multiply two integers with the Karatsuba algorithm. Note that
// the * operator isn't used anywhere in this function.
console.assert(Number.isInteger(x), "x must be an integer");
console.assert(Number.isInteger(y), "y must be an integer");
x = x.toString();
y = y.toString();
// At single digits, look up the products in the multiplication table:
if ((x.length === 1) && (y.length === 1)) { // BASE CASE
document.write("Lookup " + x.toString() + " * " + y.toString() + " = " +
MULT_TABLE[[parseInt(x), parseInt(y)]] + "<br />");
return MULT_TABLE[[parseInt(x), parseInt(y)]];
}
// RECURSIVE CASE
document.write("Multiplying " + x.toString() + " * " + y.toString() +
"<br />");
// Pad with prepended zeros so that x and y are the same length:
if (x.length < y.length) { // ?
// If x is shorter than y, pad x with zeros:
x = padZeros(x, y.length - x.length, "left");
} else if (y.length < x.length) {
// If y is shorter than x, pad y with zeros:
y = padZeros(y, x.length - y.length, "left");
}
// At this point, x and y have the same length.
let halfOfDigits = Math.floor(x.length / 2); // ?
// Split x into halves a & b, split y into halves c & d:
let a = parseInt(x.substring(0, halfOfDigits));
let b = parseInt(x.substring(halfOfDigits));
let c = parseInt(y.substring(0, halfOfDigits));
let d = parseInt(y.substring(halfOfDigits));
// Make the recursive calls with these halves:
let step1Result = karatsuba(a, c); // ? // Step 1: Multiply a & c.
let step2Result = karatsuba(b, d); // Step 2: Multiply b & d.
let step3Result = karatsuba(a + b, c + d); // Step 3: Multiply a + b & c + d.
// Step 4: Calculate Step 3 - Step 2 - Step 1:
let step4Result = step3Result - step2Result - step1Result; // ?
// Step 5: Pad these numbers, then add them for the return value:
let step1Padding = (x.length - halfOfDigits) + (x.length - halfOfDigits);
let step1PaddedNum = parseInt(padZeros(step1Result.toString(), step1Padding, "right"));
let step4Padding = (x.length - halfOfDigits);
let step4PaddedNum = parseInt(padZeros((step4Result).toString(), step4Padding, "right"));
document.write("Solved " + x + " x " + y + " = " +
(step1PaddedNum + step2Result + step4PaddedNum).toString() + "<br />");
return step1PaddedNum + step2Result + step4PaddedNum; // ?
}
// Example: 1357 x 2468 = 3349076
document.write("1357 * 2468 = " + karatsuba(1357, 2468).toString() + "<br />");
</script>
当你运行这段代码时,输出如下:
Multiplying 1357 * 2468
Multiplying 13 * 24
Lookup 1 * 2 = 2
Lookup 3 * 4 = 12
Lookup 4 * 6 = 24
Solved 13 * 24 = 312
Multiplying 57 * 68
Lookup 5 * 6 = 30
Lookup 7 * 8 = 56
Multiplying 12 * 14
Lookup 1 * 1 = 1
Lookup 2 * 4 = 8
Lookup 3 * 5 = 15
Solved 12 * 14 = 168
Solved 57 * 68 = 3876
Multiplying 70 * 92
Lookup 7 * 9 = 63
Lookup 0 * 2 = 0
Multiplying 7 * 11
Lookup 0 * 1 = 0
Lookup 7 * 1 = 7
Lookup 7 * 2 = 14
Solved 07 * 11 = 77
Solved 70 * 92 = 6440
Solved 1357 * 2468 = 3349076
1357 * 2468 = 3349076
这个程序的第一部分发生在调用karatsuba()之前。我们的程序需要在MULT_TABLE变量中创建乘法查找表。通常,查找表是直接硬编码在源代码中的,从MULT_TABLE[[0, 0]] = 0到MULT_TABLE[[9, 9]] = 81。但为了减少输入量,我们将使用嵌套的for循环来生成每个乘积。访问MULT_TABLE[[m, n]]会给我们整数m和n的乘积。
我们的karatsuba()函数还依赖于一个名为padZeros()的辅助函数,它在字符串的左侧或右侧填充额外的零。这种填充是在 Karatsuba 算法的第五步中完成的。例如,padZeros("42", 3, "left")返回字符串00042,而padZeros("99", 1, "right")返回字符串990。
karatsuba()函数本身首先检查基本情况,即x和y是单个数字。这些可以使用查找表相乘,并且它们的乘积会立即返回。其他情况都是递归情况。
我们需要将x和y整数转换为字符串,并调整它们,使它们包含相同数量的数字。如果其中一个数字比另一个短,就会在左侧填充 0。例如,如果x是13,y是2468,我们的函数调用padZeros(),这样x就可以被替换为0013。这是因为我们随后创建a、b、c和d变量,每个变量包含x和y的一半数字。a和c变量必须具有相同数量的数字,以使 Karatsuba 算法起作用,b和d变量也是如此。
请注意,我们使用除法和向下取整来计算x的数字的一半是多少。这些数学运算和乘法一样复杂,可能在我们为 Karatsuba 算法编程的低级硬件上不可用。在实际实现中,我们可以使用另一个查找表来存储这些值:HALF_TABLE = [0, 0, 1, 1, 2, 2, 3, 3...],以此类推。查找HALF_TABLE[n]将得到n的一半,向下取整。一个仅有 100 个项目的数组就足以满足大多数情况,可以避免我们的程序进行除法和取整。但我们的程序是用来演示的,所以我们将使用/运算符和内置的取整函数。
一旦这些变量被正确设置,我们就可以开始进行递归函数调用。前三个步骤涉及使用参数a和b、c和d,最后是a + b和c + d进行递归调用。第四步是将前三步的结果相互相减。第五步是将第一步和第四步的结果右侧填充 0,然后加上第二步的结果。
Karatsuba 算法背后的代数
这些步骤可能看起来像魔术,所以让我们深入代数,看看为什么它们有效。我们使用 1,357 作为x和 2,468 作为y,作为我们要相乘的整数。我们还考虑一个新变量n,表示x或y的数字位数。由于a是 13,b是 57,我们可以计算原始x为 10(*n*)(/2) × a + b,即 102 × 13 + 57 或 1,300 + 57,即 1,357。同样,y也是 10(*n*)(/2) × c + d。
这意味着x × y的乘积=(10(*n*)(/2) × a + b)×(10(*n*)(/2) × c + d)。通过一些代数运算,我们可以将这个方程重写为x × y = 10n × ac + 10(*n*)(/2) × (ad + bc) + bd。对于我们的示例数字,这意味着 1,357 × 2,468 = 10,000 × (13 × 24) + 100 × (13 × 68 + 57 × 24) + (57 × 68)。这个方程的两边都计算为 3,349,076。
我们将xy的乘法分解为ac、ad、bc和bd的乘法。这构成了我们递归函数的基础:我们通过使用较小数字的乘法(记住,a、b、c和d是x或y的一半的数字)来定义x和y的乘法,这接近了将单个数字相乘的基本情况。我们可以使用查找表而不是乘法来执行单个数字的乘法。
因此,我们需要递归计算ac(Karatsuba 算法的第一步)和bd(第二步)。我们还需要计算(a + b)(c + d)作为第三步,我们可以将其重写为ac + ad + bc + bd。我们已经从前两步得到了ac和bd,所以减去这些值给了我们ad + bc。这意味着我们只需要进行一次乘法(和一次递归调用)来计算(a + b)(c + d),而不是计算ad + bc需要两次。而ad + bc是我们原始方程中 10n^(/2) × (ad + bc)的一部分。
通过填充零位数,可以通过 10n和 10(*n*)(/2)的幂来进行乘法:例如,10,000 × 123 是 1,230,000。因此,对于这些乘法,没有必要进行递归调用。最后,将x × y的乘法分解为三个较小乘积的乘法,需要进行三次递归调用:karatsuba(a, c)、karatsuba(b, d)和karatsuba((a + b), (c + d))。
通过仔细研究本节,您可以理解 Karatsuba 算法背后的代数。我无法理解的是,23 岁的学生 Anatoly Karatsuba 是如何在不到一周的时间里聪明地设计出这个算法的。
总结
将问题分解为更小的、自相似的问题是递归的核心,使得这些分而治之的算法特别适合递归技术。在本章中,我们为数组中数字求和的第三章程序创建了一个分而治之的版本。这个版本的一个好处是,在将问题分解为多个子问题时,可以将子问题分配给其他计算机并行处理。
二分搜索算法通过不断缩小搜索范围的方式在排序数组中搜索。线性搜索从开头开始搜索整个数组,而二分搜索利用数组的排序顺序来定位它正在寻找的项目。性能提升如此之大,以至于值得对未排序的数组进行排序,以便对其项目进行二分搜索。
在本章中,我们介绍了两种流行的排序算法:快速排序和归并排序。快速排序根据一个枢轴值将数组分成两个分区。然后算法递归地对这两个分区进行分割,重复这个过程,直到分区的大小为一个单独的项目。在这一点上,分区和其中的项目都是按排序顺序排列的。归并排序采取相反的方法。算法首先将数组分成较小的数组,然后将这些较小的数组合并成排序顺序。
最后,我们介绍了 Karatsuba 乘法,这是一种递归算法,用于执行整数乘法,当*乘法运算符不可用时。这在低级硬件编程中会出现,因为它没有内置的乘法指令。Karatsuba 算法将两个整数相乘分解为三个较小整数的乘法。为了基本情况下的单个数字相乘,该算法在查找表中存储了从 0 × 0 到 9 × 9 的每个乘积。
本章中的算法是大一计算机科学学生学习的许多数据结构和算法课程的一部分。在下一章中,我们将继续研究计算的核心算法,包括计算排列和组合的算法。
进一步阅读
YouTube 的 Computerphile 频道有关于快速排序的视频,网址为youtu.be/XE4VP_8Y0BU,以及关于归并排序的视频,网址为youtu.be/kgBjXUE_Nwc。如果你想要更全面的教程,免费的“Algorithmic Toolbox”在线课程涵盖了许多大一数据结构和算法课程会涵盖的相同主题,包括二分搜索、快速排序和归并排序。你可以在www.coursera.org/learn/algorithmic-toolbox上报名参加这门 Coursera 课程。
排序算法经常在大 O 算法分析课程中相互比较,你可以在我的书Beyond the Basic Stuff with Python(No Starch Press, 2020)的第十三章中阅读有关此内容。你可以在inventwithpython.com/beyond上在线阅读这一章。Python 开发者 Ned Batchelder 在 2018 年的 PyCon 演讲中描述了大 O 和“随着数据增长,代码的减速”,演讲的名称也是这个名字,网址为youtu.be/duvZ-2UK0fc。
分治算法很有用,因为它们经常可以并行在多台计算机上运行。Guy Steele Jr.在 Google TechTalk 上发表了题为“Four Solutions to a Trivial Problem”的演讲,网址为youtu.be/ftcIcn8AmSY。
Tim Roughgarden 教授为斯坦福大学制作了一段关于 Karatsuba 乘法的视频讲座,网址为youtu.be/JCbZayFr9RE。
为了帮助你理解快速排序和归并排序,获取一副扑克牌或者简单地在索引卡上写上数字,并按照这两种算法的规则手动排序它们。这种离线方法可以帮助你记住快速排序的中轴和分区以及归并排序的分治。
练习问题
通过回答以下问题来测试你的理解:
-
与第三章中的头尾求和算法相比,本章中的分治求和算法有什么好处?
-
如果在书架上搜索 50 本书的二分搜索需要六步,那么搜索两倍的书需要多少步?
-
二分搜索算法能搜索未排序的数组吗?
-
分区和排序是一样的吗?
-
快速排序的分区步骤发生了什么?
-
快速排序中的中轴值是多少?
-
快速排序的基本情况是什么?
-
quicksort()函数有多少递归调用? -
数组
[0, 3, 1, 2, 5, 4, 7, 6]在以4为中轴值时没有正确分区? -
归并排序的基本情况是什么?
-
mergeSort()函数有多少递归调用? -
当归并排序算法对数组
[12, 37, 38, 41, 99]和[2, 4, 14, 42]进行排序时,结果数组是什么? -
查找表是什么?
-
在乘法整数x和y的 Karatsuba 算法中,变量a、b、c和d分别存储什么?
-
回答关于本章中每个递归算法的三个问题:
-
基本情况是什么?
-
递归函数调用传递了什么参数?
-
这个参数如何变得更接近基本情况?
然后,重新创建本章中的递归算法,而不看原始代码。
练习项目
为了练习,为以下每个任务编写一个函数:
-
创建一个具有从 0×0 到 999×999 的乘法查找表的
karatsuba()函数的版本,而不是从 0×0 到 9×9。粗略估计使用这个更大的查找表在循环中计算karatsuba(12345678, 87654321)10,000 次所需的时间,与原始查找表相比。如果这仍然运行得太快以至于无法测量,增加迭代次数到 100,000 或 1,000,000 或更多。(提示:您应该删除或注释掉karatsuba()函数内的print()和document.write()调用,以进行此定时测试。) -
创建一个函数,在一个包含 10,000 个整数的大数组上执行线性搜索 10,000 次。粗略估计这需要多长时间,如果程序执行得太快,增加迭代次数到 100,000 或 1,000,000。将此与第二个函数在执行相同数量的二进制搜索之前对数组进行排序所需的时间进行比较。
六、排列和组合
原文:Chapter 6 - Permutations and Combinations
译者:飞龙
涉及排列和组合的问题特别适合递归。这在集合论中很常见,集合论是处理对象集合的选择、排列和操作的数学逻辑分支。
处理我们短期记忆中的小集合很简单。我们可以轻松地想出一组三个或四个对象的每种可能顺序(即排列)或组合。对更大集合中的项目进行排序和组合需要相同的过程,但很快就变成了我们人类大脑无法完成的任务。在那一点上,引入计算机来处理随着我们向集合中添加更多对象而发生的组合爆炸变得实际。
在其核心,计算大群体的排列和组合涉及计算较小群体的排列和组合。这使得这些计算适合递归。在本章中,我们将看看用于生成字符串中所有可能排列和组合的递归算法。我们将扩展到生成所有可能的平衡括号组合(正确匹配的开括号顺序与闭括号)。最后,我们将计算集合的幂集,即集合的所有可能子集的集合。
本章中的许多递归函数都有一个名为indent的参数。这并不是由实际的递归算法使用的;相反,它是由它们的调试输出使用的,以便您可以看到哪个递归级别产生了输出。每次递归调用时缩进增加一个空格,并在调试输出中呈现为句点,以便轻松计算缩进级别。
集合论术语
本章并没有像数学或计算机科学教科书那样完全涵盖集合论。但它涵盖了足够的内容,以证明从解释该学科的基本术语开始是有道理的,因为这样做将使本章的其余部分更容易理解。集合是一组唯一对象,称为元素或成员。例如,字母A、B和C形成了一个三个字母的集合。在数学(以及 Python 代码语法)中,集合用大括号括起来,对象之间用逗号分隔:{A, B, C}。
集合的顺序并不重要;集合{A,B,C}与集合{C,B,A}是相同的集合。集合具有不同的元素,这意味着没有重复:{A,C,A,B}有重复的A,因此不是一个集合。
如果一个集合只包含另一个集合的成员,则称其为另一个集合的子集。例如,{A,C}和{B,C}都是{A,B,C}的子集,但{A,C,D}不是它的子集。相反,{A,B,C}是{A,C}和{B,C}的超集,因为它包含它们的所有元素。空集{}是一个不包含任何成员的集合。空集被认为是每个可能集合的子集。
一个子集也可以包括另一个集合的所有元素。例如,{A,B,C}是{A,B,C}的一个子集。但是,真子集或严格子集是一个不包含所有集合元素的子集。没有集合是其自身的真子集:因此{A,B,C}是一个子集,但不是{A,B,C}的真子集。所有其他子集都是真子集。图 6-1 显示了集合{A,B,C}及其一些子集的图形表示。

图 6-1:集合{A,B,C}在虚线内以及其一些子集{A,B,C},{A,C}和{ }在实线内的图形表示。圆圈代表集合,字母代表元素。
一个集合的排列是集合中所有元素的特定顺序。例如,集合{A,B,C}有六个排列:ABC,ACB,BAC,BCA,CAB 和 CBA。我们称这些排列为无重复的排列,或者无替换的排列,因为每个元素在排列中不会出现超过一次。*
一个组合*是一个集合的元素选择。更正式地说,k-组合是从一个集合中选择 k 个元素的子集。与排列不同,组合没有顺序。例如,集合{A,B,C}的 2-组合是{A,B},{A,C}和{B,C}。集合{A,B,C}的 3-组合是{A,B,C}。
“n 选 k”一词指的是可以从 n 个元素的集合中选择 k 个元素的可能组合(不重复)。 (一些数学家使用“n 选 r”一词。)这个概念与元素本身无关,只与它们的数量有关。例如,4 选 2 是 6,因为有六种方法可以从四个元素的集合{A,B,C,D}中选择两个元素:{A,B},{A,C},{A,D},{B,C},{B,D}和{C,D}。同时,3 选 3 是 1,因为从三个元素的集合{A,B,C}中只有一种 3 个元素的组合,即{A,B,C}本身。计算 n 选 k 的公式是(n!)/(k!×(n-k)!)。回想一下,n!是阶乘的表示法:5!是 5×4×3×2×1。
术语n multichoose k指的是可以从 n 个元素的集合中选择 k 个元素的可能组合带有重复。因为 k-组合是集合,而集合不包含重复元素,所以 k-组合不会重复。当我们使用带有重复元素的 k-组合时,我们特别称它们为带重复的 k-组合。
请记住,无论有无重复,您都可以将排列视为集合中所有元素的特定排列,而组合是集合中某些元素的无序选择。排列有顺序并使用集合中的所有元素,而组合没有顺序并使用集合中的任意数量的元素。为了更好地了解这些术语,表 6-1 显示了集合{A,B,C}的排列和组合之间的区别,有无重复。
表 6-1:集合{A,B,C}的所有可能排列和组合,有无重复。
| 排列 | 组合 | |
|---|---|---|
| 无重复 | ABC,ACB,BAC,BCA,CAB | (无),A,B,C,AB,AC,BC,ABC |
| 有重复 | AAA,AAB,AAC,ABA,ABB,ABC,ACA,ACB,ACC,BAA,BAB,BAC,BBA,BBB,BBC,BCA,BCB,BCC,CAA,CAB,CAC,CBA,CBB,CBC,CCA,CCB,CCC | (无),A,B,C,AA,AB,AC,BB,BC,CC,AAA,AAB,AAC,ABB,ABC,ACC,BBB,BBC,BCC,CCC |
当我们向集合添加元素时,排列和组合的数量会迅速增长,这种组合爆炸由表 6-2 中的公式捕捉到。例如,一个包含 10 个元素的集合有 10!,或 3,628,800 个可能的排列,但是一个包含两倍元素的集合有 20!,或 2,432,902,008,176,640,000 个排列。
表 6-2:计算n元素集合的可能排列和组合的数量,有重复和无重复
| 排列 | 组合 | |
|---|---|---|
| 无重复 | n! | 2n |
| 有重复 | n^(n) | 2n 选择 n,或 (2n)!/(n!)2 |
请注意,没有重复的排列总是与集合的大小相同。例如,{A,B,C}的排列总是三个字母长:ABC,ACB,BAC 等。然而,有重复的排列可以是任意长度。表 6-1 显示了{A,B,C}的三个字母排列,范围从 AAA 到 CCC,但是你也可以有有重复的五个字母排列,范围从 AAAAA 到 CCCCC。有重复的n元素的排列的长度为k的数量是n^(k)。表 6-2 将其列为n^(n),表示有重复的n元素的排列也是n元素长的排列。
排列的顺序很重要,但组合的顺序不重要。虽然 AAB,ABA 和 BAA 被视为具有重复的相同组合,但它们被视为具有重复的三个不同排列。
寻找没有重复的所有排列:婚礼座位表
想象一下,你必须为一个有着微妙社交要求的婚礼宴会安排座位表。一些客人彼此讨厌,而其他人则要求坐在一个有影响力的客人附近。长方形桌子上的座位形成一排,而不是一个圆圈。对于你的计划来说,看到每个客人的所有可能的排列,也就是每个客人的没有重复的排列,将是有帮助的。没有重复发生,因为每个客人在座位表中只出现一次。
让我们以 Alice,Bob 和 Carol,或{A,B,C}为例。图 6-2 显示了这三位婚礼客人的所有六种可能排列。
我们确定没有重复的排列数量的一种方法是使用头尾递归策略。我们从集合中选择一个元素作为头部。然后我们得到剩余元素的每个排列(构成尾部),对于每个排列,我们将头部放在排列的每个可能位置上。
在我们的 ABC 示例中,我们将从 Alice(A)作为头部开始,Bob 和 Carol(BC)作为尾部。{B,C}的排列是 BC 和 CB。(我们如何得到 BC 和 CB 将在下一段解释,所以现在先把这个问题放在一边。)我们将 A 放在 BC 的每个可能位置上。也就是说,我们将 Alice 放在 Bob 之前(ABC),在 Bob 和 Carol 之间(BAC),和在 Carol 之后(BCA)。这样就创建了 ABC,BAC 和 BCA 的排列。我们还将 A 放在 CB 的每个可能位置上,创建了 ACB,CAB 和 CBA。这样就创建了 Alice,Bob 和 Carol 在宴会桌上的所有六种排列。现在我们可以选择导致最少争吵的安排(或者如果你想要一个难忘的婚礼宴会,也可以选择导致最多争吵的安排)。

图 6-2:桌子上三位婚礼客人的六种可能排列
当然,要得到{B,C}的每个排列,我们需要用 B 作为头部,C 作为尾部递归重复这个过程。单个字符的排列是字符本身;这是我们的基本情况。通过将头部 B 放在 C 的每个可能位置上,我们得到了上一段中使用的 BC 和 CB 排列。请记住,虽然集合的顺序无关紧要(如{B,C}与{C,B}相同),但排列的顺序很重要(BC 不是 CB 的重复)。
我们的递归排列函数接受一个字符字符串作为参数,并返回这些字符的每种可能排列的字符串数组。让我们针对这个函数的递归算法提出三个问题:
-
什么是基本情况?单个字符字符串或空字符串的参数,返回一个只包含该字符串的数组。
-
递归函数调用传递了什么参数?缺少一个字符的字符串参数。为每个缺失的字符进行了单独的递归调用。
-
这个参数如何接近基本情况?字符串的大小缩小,最终变成一个单字符字符串。
递归排列算法在permutations.py中实现:
def getPerms(chars, indent=0):
print('.' * indent + 'Start of getPerms("' + chars + '")')
if len(chars) == 1: # ?
# BASE CASE
print('.' * indent + 'When chars = "' + chars + '" base case returns', chars)
return [chars]
# RECURSIVE CASE
permutations = []
head = chars[0] # ?
tail = chars[1:]
tailPermutations = getPerms(tail, indent + 1)
for tailPerm in tailPermutations: # ?
print('.' * indent + 'When chars =', chars, 'putting head', head, 'in all places in', tailPerm)
for i in range(len(tailPerm) + 1): # ?
newPerm = tailPerm[0:i] + head + tailPerm[i:]
print('.' * indent + 'New permutation:', newPerm)
permutations.append(newPerm)
print('.' * indent + 'When chars =', chars, 'results are', permutations)
return permutations
print('Permutations of "ABCD":')
print('Results:', ','.join(getPerms('ABCD')))
等效的 JavaScript 程序在permutations.html中:
<script type="text/javascript">
function getPerms(chars, indent) {
if (indent === undefined) {
indent = 0;
}
document.write('.'.repeat(indent) + 'Start of getPerms("' + chars + '")<br />');
if (chars.length === 1) { // ?
// BASE CASE
document.write('.'.repeat(indent) + "When chars = \"" + chars +
"\" base case returns " + chars + "<br />");
return [chars];
}
// RECURSIVE CASE
let permutations = [];
let head = chars[0]; // ?
let tail = chars.substring(1);
let tailPermutations = getPerms(tail, indent + 1);
for (tailPerm of tailPermutations) { // ?
document.write('.'.repeat(indent) + "When chars = " + chars +
" putting head " + head + " in all places in " + tailPerm + "<br />");
for (let i = 0; i < tailPerm.length + 1; i++) { // ?
let newPerm = tailPerm.slice(0, i) + head + tailPerm.slice(i);
document.write('.'.repeat(indent) + "New permutation: " + newPerm + "<br />");
permutations.push(newPerm);
}
}
document.write('.'.repeat(indent) + "When chars = " + chars +
" results are " + permutations + "<br />");
return permutations;
}
document.write("<pre>Permutations of \"ABCD\":<br />");
document.write("Results: " + getPerms("ABCD") + "</pre>");
</script>
这些程序的输出如下:
Permutations of "ABCD":
Start of getPerms("ABCD")
.Start of getPerms("BCD")
..Start of getPerms("CD")
...Start of getPerms("D")
...When chars = "D" base case returns D
..When chars = CD putting head C in all places in D
..New permutation: CD
..New permutation: DC
..When chars = CD results are ['CD', 'DC']
.When chars = BCD putting head B in all places in CD
.New permutation: BCD
.New permutation: CBD
.New permutation: CDB
.When chars = BCD putting head B in all places in DC
.New permutation: BDC
.New permutation: DBC
.New permutation: DCB
.When chars = BCD results are ['BCD', 'CBD', 'CDB', 'BDC', 'DBC', 'DCB']
# --snip--
When chars = ABCD putting head A in all places in DCB
New permutation: ADCB
New permutation: DACB
New permutation: DCAB
New permutation: DCBA
When chars = ABCD results are ['ABCD', 'BACD', 'BCAD', 'BCDA', 'ACBD', 'CABD', 'CBAD', 'CBDA', 'ACDB','CADB', 'CDAB', 'CDBA', 'ABDC', 'BADC', 'BDAC', 'BDCA', 'ADBC', 'DABC', 'DBAC', 'DBCA', 'ADCB', 'DACB', 'DCAB', 'DCBA']
Results: ABCD,BACD,BCAD,BCDA,ACBD,CABD,CBAD,CBDA,ACDB,CADB,CDAB,CDBA,ABDC,
BADC,BDAC,BDCA,ADBC,DABC,DBAC,DBCA,ADCB,DACB,DCAB,DCBA
当调用getPerms()时,首先检查基本情况?。如果chars字符串只有一个字符长,它只能有一个排列:chars字符串本身。函数将此字符串返回为数组。
否则,在递归情况下,函数将chars参数的第一个字符分为head变量和其余部分为tail变量?。函数调用getPerms()递归获取tail字符串的所有排列。第一个for循环?遍历这些排列的每一个,第二个for循环?通过将head字符放在字符串的每个可能位置来创建一个新的排列。
例如,如果getPerms()的chars参数为ABCD,head为A,tail为BCD。getPerms('BCD')调用返回一个尾部排列的数组,['BCD','CBD','CDB','BDC','DBC','DCB']。第一个for循环从BCD排列开始,第二个for循环将A字符串放在head的每个可能位置,产生ABCD,BACD,BCAD,BCDA。这将重复进行剩余的尾部排列,并由getPerms()函数返回整个列表。
使用嵌套循环获取排列:一个不太理想的方法
假设我们有一个简单的自行车锁,如图 6-3,有一个四位数字组合。这个组合有 10,000 种数字排列(0000 到 9999),但只有一个可以打开它。(它们被称为组合锁;然而,在这种情况下更准确的称呼应该是重复排列锁,因为顺序很重要。)
现在假设我们有一个更简单的锁,只有五个字母 A 到 E。我们可以计算可能组合的数量为 5?,或 5×5×5×5,即 625。一个由n个可能性的集合中选择的每个字符的k字符组合锁是n^(k)。但是获取组合本身的列表要复杂一些。

图 6-3:四位数字组合自行车锁有 10?,或 10,000 种可能的重复排列(照片由 Shaun Fisher 提供,CC BY 2.0 许可)。
使用嵌套循环获得重复排列的一种方法是,即一个循环内嵌另一个循环。内部循环遍历集合中的每个元素,而外部循环也做同样的事情,同时重复内部循环。创建所有可能的k字符排列,每个字符从n个可能性的集合中选择,需要k个嵌套循环。
例如,nestedLoopPermutations.py包含生成{A,B,C,D,E}的所有 3 组合的代码:
Python
for a in ['A', 'B', 'C', 'D', 'E']:
for b in ['A', 'B', 'C', 'D', 'E']:
for c in ['A', 'B', 'C', 'D', 'E']:
for d in ['A', 'B', 'C', 'D', 'E']:
print(a, b, c, d)
- nestedLoopPermutations.html *包含等效的 JavaScript 程序:
JavaScript
<script>
for (a of ['A', 'B', 'C', 'D', 'E']) {
for (b of ['A', 'B', 'C', 'D', 'E']) {
for (c of ['A', 'B', 'C', 'D', 'E']) {
for (d of ['A', 'B', 'C', 'D', 'E']) {
document.write(a + b + c + d + "<br />")
}
}
}
}
</script>
这些程序的输出如下:
A A A A
A A A B
A A A C
A A A D
A A A E
A A B A
A A B B
# --snip--
E E E C
E E E D
E E E E
使用四个嵌套循环生成排列的问题在于,它仅适用于恰好为四个字符的排列。嵌套循环无法为任意长度生成排列。相反,我们可以使用递归函数,如下一节所述。
您可以通过本章中的示例来记住有和没有重复的排列之间的区别。没有重复的排列会遍历集合中元素的所有可能的排序,就像我们的婚礼座位表示例一样。有重复的排列会遍历组合锁的所有可能组合;顺序很重要,同一个元素可以出现多次。
重复排列:密码破解器
假设您收到了一份来自一位最近去世的记者的敏感加密文件。在他们的最后一条消息中,记者告诉您该文件包含了一个邪恶的亿万富翁的逃税记录。他们没有解密文件的密码,但他们知道密码正好是四个字符长;可能的字符是数字 2、4 和 8 以及字母 J、P 和 B。这些字符可以出现多次。例如,可能的密码是 JPB2、JJJJ 和 2442。
根据这些信息生成所有可能的四位密码列表,您希望获得集合{J,P,B,2,4,8}的所有可能的四元素重复排列。密码中的每个字符都可以是六个可能的字符之一,使得有 6×6×6×6,或 6?,即 1,296 种可能的排列。我们要生成{J,P,B,2,4,8}的排列,而不是组合,因为顺序很重要;JPB2 与 B2JP 是不同的密码。
让我们向这三个递归算法问题询问有关我们排列函数的问题。我们将使用更具描述性的名称permLength,而不是k:
-
什么是基本情况?
permLength参数为0,表示排列长度为零,表明prefix参数现在包含完整的排列,因此应该在数组中返回prefix。 -
递归函数调用传递了什么参数?
chars字符串是要获取排列的字符,permLength参数开始为chars的长度,prefix参数开始为空字符串。递归调用会递减permLength参数,同时将chars中的一个字符附加到prefix参数。 -
这个参数如何接近基本情况?最终,
permLength参数递减为0。
递归排列重复的算法在permutationsWithRepetition.py中实现:
def getPermsWithRep(chars, permLength=None, prefix=''):
indent = '.' * len(prefix)
print(indent + 'Start, args=("' + chars + '", ' + str(permLength) + ', "' + prefix + '")')
if permLength is None:
permLength = len(chars)
# BASE CASE
if (permLength == 0): # ?
print(indent + 'Base case reached, returning', [prefix])
return [prefix]
# RECURSIVE CASE
# Create a new prefix by adding each character to the current prefix.
results = []
print(indent + 'Adding each char to prefix "' + prefix + '".')
for char in chars:
newPrefix = prefix + char # ?
# Decrease permLength by one because we added one character to the prefix.
results.extend(getPermsWithRep (chars, permLength - 1, newPrefix)) # ?
print(indent + 'Returning', results)
return results
print('All permutations with repetition of JPB123:')
print(getPermsWithRep('JPB123', 4))
等效的 JavaScript 程序在permutationsWithRepetition.html中:
<script type="text/javascript">
function getPermsWithRep(chars, permLength, prefix) {
if (permLength === undefined) {
permLength = chars.length;
}
if (prefix === undefined) {
prefix = "";
}
let indent = ".".repeat(prefix.length);
document.write(indent + "Start, args=(\"" + chars + "\", " + permLength +
", \"" + prefix + "\")<br />");
// BASE CASE
if (permLength === 0) { // ?
document.write(indent + "Base case reached, returning " + [prefix] + "<br />");
return [prefix];
}
// RECURSIVE CASE
// Create a new prefix by adding each character to the current prefix.
let results = [];
document.write(indent + "Adding each char to prefix \"" + prefix + "\".<br />");
for (char of chars) {
let newPrefix = prefix + char; // ?
// Decrease permLength by one because we added one character to the prefix.
results = results.concat(getPermsWithRep(chars, permLength - 1, newPrefix)); // ?
}
document.write(indent + "Returning " + results + "<br />");
return results;
}
document.write("<pre>All permutations with repetition of JPB123:<br />");
document.write(getPermsWithRep('JPB123', 4) + "</pre>");
</script>
这些程序的输出如下所示:
All permutations with repetition of JPB123:
Start, args=("JPB123", 4, "")
Adding each char to prefix "".
.Start, args=("JPB123", 3, "J")
.Adding each char to prefix "J".
..Start, args=("JPB123", 2, "JJ")
..Adding each char to prefix "JJ".
...Start, args=("JPB123", 1, "JJJ")
...Adding each char to prefix "JJJ".
....Start, args=("JPB123", 0, "JJJJ")
....Base case reached, returning ['JJJJ']
....Start, args=("JPB123", 0, "JJJP")
....Base case reached, returning ['JJJP']
# --snip--
Returning ['JJJJ', 'JJJP', 'JJJB', 'JJJ1', 'JJJ2', 'JJJ3',
'JJPJ', 'JJPP', 'JJPB', 'JJP1', 'JJP2', 'JJP3', 'JJBJ', 'JJBP',
'JJBB', 'JJB1', 'JJB2', 'JJB3', 'JJ1J', 'JJ1P', 'JJ1B', 'JJ11',
'JJ12', 'JJ13', 'JJ2J', 'JJ2P', 'JJ2B', 'JJ21', 'JJ22', 'JJ23',
'JJ3J', 'JJ3P', 'JJ3B', 'JJ31', 'JJ32', 'JJ33', 'JPJJ',
# --snip--
getPermsWithRep()函数有一个prefix字符串参数,默认情况下为空字符串。当调用该函数时,首先检查基本情况?。如果permLength,即排列的长度,为0,则返回一个包含prefix的数组。
否则,在递归情况下,对于chars参数中的每个字符,函数创建一个新的前缀?传递给递归的getPermsWithRep()调用。这个递归调用将permLength - 1作为permLength参数传递。
permLength参数从排列的长度开始,每次递归调用递减一次?。prefix参数从空字符串开始,每次递归调用增加一个字符。因此,当达到k == 0的基本情况时,prefix字符串就是k的完整排列长度。
例如,让我们考虑调用getPermsWithRep('ABC', 2)的情况。prefix参数默认为空字符串。该函数对ABC的每个字符进行递归调用,并将其连接到空前缀字符串作为新前缀。调用getPermsWithRep('ABC', 2)会进行三次递归调用:
-
getPermsWithRep('ABC', 1, 'A') -
getPermsWithRep('ABC', 1, 'B') -
getPermsWithRep('ABC', 1, 'C')
这三个调用将各自进行三次递归调用,但将permLength的值设为0而不是1。基本情况发生在permLength == 0时,因此它们返回它们的前缀。这就是生成所有九个排列的方式。getPermsWithRep()函数以相同的方式生成更大集合的排列。
使用递归获取 K-组合
回想一下,对于排列而言,顺序并不重要。然而,生成集合的所有k-组合有点棘手,因为你不希望算法生成重复项:如果你从集合{A,B,C}创建 AB 2-组合,你不希望也创建 BA,因为它与 AB 是相同的 2-组合。
要弄清楚如何编写递归代码来解决这个问题,让我们看看树如何以可视化方式描述生成集合的所有k-组合。图 6-4 显示了来自集合{A,B,C,D}的所有组合的树。

图 6-4:显示来自集合{A,B,C,D}的每个可能k-组合(从 0 到 4)的树
例如,要从这棵树中收集 3-组合,从顶部的根节点开始,进行深度优先树遍历到 3-组合级别,同时记住每个节点的字母直到底部。(深度优先搜索在第四章中讨论。)我们的第一个 3-组合将从根到 1-组合级别的 A 开始,然后到 2-组合级别的 B,然后到 3-组合级别的 C,我们停在那里,得到了我们完整的 3-组合:ABC。对于下一个组合,我们从根到 A 到 B 到 D,得到了组合 ABD。我们继续为 ACD 和 BCD 做同样的操作。我们的树在 3-组合级别有四个节点,从{A,B,C,D}中有四个 3-组合:ABC,ABD,ACD 和 BCD。
请注意,我们通过从根节点开始使用空字符串创建了图 6-4 中的树。这是 0-组合级别,并且适用于从集合中选择零个元素的所有组合;它只是一个空字符串。根的子节点都是来自集合的所有元素。在我们的情况下,这是来自{A,B,C,D}的所有四个元素。虽然集合没有顺序,但在生成这棵树时,我们需要一致地使用集合的 ABCD 顺序。这是因为每个节点的子节点都包括在 ABCD 字符串中它之后的字母:所有 A 节点都有 B、C 和 D 子节点;所有 B 节点都有 C 和 D 子节点;所有 C 节点只有一个 D 子节点;所有 D 节点没有子节点。
虽然它与递归组合函数没有直接关系,但也注意每个级别的k-组合数量的模式:
-
0-组合和 4-组合级别都有一个组合:空字符串和 ABCD,分别。
-
1-组合和 3-组合级别都有四个组合:A,B,C,D 和 ABC,ABD,ACD,BCD,分别。
-
中间的 2-组合级别有最多的六个组合:AB,AC,AD,BC,BD 和 CD。
组合数量增加、在中间达到峰值,然后减少的原因是k-组合是彼此的镜像。例如,1-组合是由未被选中的元素构成 3-组合的:
-
1-组合 A 是 3-组合 BCD 的镜像。
-
1-组合 B 是 3-组合 ACD 的镜像。
-
1-组合 C 是 3-组合 ABD 的镜像。
-
1-组合 D 是 3-组合 ABC 的镜像。
我们将创建一个名为getCombos()的函数,它接受两个参数:一个chars字符串,其中包含要获取组合的字母,以及组合的大小k。返回值是一个字符串数组,其中包含来自字符串chars的组合,每个组合的长度为k。
我们将使用chars参数的头部-尾部技术。例如,假设我们调用getCombos('ABC', 2)来从{A, B, C}获取所有 2-组合。该函数将A设置为头部,BC设置为尾部。图 6-5 显示了从{A, B, C}选择 2-组合的树。
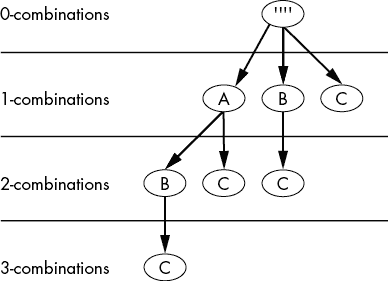
图 6-5:树状图显示了从集合{A, B, C}中的每个可能的 2-组合
让我们问一下我们的三个递归算法问题:
-
什么是基本情况?第一个基本情况是
k参数为0,这意味着请求 0-组合,无论chars是什么,它总是一个空字符串数组。第二种情况是如果chars是空字符串,则是一个空数组,因为从空字符串中无法生成任何可能的组合。 -
传递给递归函数调用的参数是什么?对于第一个递归调用,传递了
chars的尾部和k - 1。对于第二个递归调用,传递了chars的尾部和k。 -
这个参数如何接近基本情况?由于递归调用会减少
k并从chars参数中删除头部,最终k参数会减少到0,或者chars参数会变成空字符串。
生成组合的 Python 代码在combinations.py中:
Python
def getCombos(chars, k, indent=0):
debugMsg = '.' * indent + "In getCombos('" + chars + "', " + str(k) + ")"
print(debugMsg + ', start.')
if k == 0:
# BASE CASE
print(debugMsg + " base case returns ['']")
# If k asks for 0-combinations, return '' as the selection of
# zero letters from chars.
return ['']
elif chars == '':
# BASE CASE
print(debugMsg + ' base case returns []')
return [] # A blank chars has no combinations, no matter what k is.
# RECURSIVE CASE
combinations = []
# First part, get the combos that include the head: # ?
head = chars[:1]
tail = chars[1:]
print(debugMsg + " part 1, get combos with head '" + head + "'")
tailCombos = getCombos(tail, k - 1, indent + 1) # ?
print('.' * indent + "Adding head '" + head + "' to tail combos:")
for tailCombo in tailCombos:
print('.' * indent + 'New combination', head + tailCombo)
combinations.append(head + tailCombo)
# Second part, get the combos that don't include the head: # ?
print(debugMsg + " part 2, get combos without head '" + head + "')")
combinations.extend(getCombos(tail, k, indent + 1)) # ?
print(debugMsg + ' results are', combinations)
return combinations
print('2-combinations of "ABC":')
print('Results:', getCombos('ABC', 2))
等效的 JavaScript 程序在combinations.html中:
<script type="text/javascript">
function getCombos(chars, k, indent) {
if (indent === undefined) {
indent = 0;
}
let debugMsg = ".".repeat(indent) + "In getCombos('" + chars + "', " + k + ")";
document.write(debugMsg + ", start.<br />");
if (k == 0) {
// BASE CASE
document.write(debugMsg + " base case returns ['']<br />");
// If k asks for 0-combinations, return '' as the selection of zero letters from chars.
return [""];
} else if (chars == "") {
// BASE CASE
document.write(debugMsg + " base case returns []<br />");
return []; // A blank chars has no combinations, no matter what k is.
}
// RECURSIVE CASE
let combinations = [];
// First part, get the combos that include the head: // ?
let head = chars.slice(0, 1);
let tail = chars.slice(1, chars.length);
document.write(debugMsg + " part 1, get combos with head '" + head + "'<br />");
let tailCombos = getCombos(tail, k - 1, indent + 1); // ?
document.write(".".repeat(indent) + "Adding head '" + head + "' to tail combos:<br />");
for (tailCombo of tailCombos) {
document.write(".".repeat(indent) + "New combination " + head + tailCombo + "<br />");
combinations.push(head + tailCombo);
}
// Second part, get the combos that don't include the head: // ?
document.write(debugMsg + " part 2, get combos without head '" + head + "')<br />");
combinations = combinations.concat(getCombos(tail, k, indent + 1)); // ?
document.write(debugMsg + " results are " + combinations + "<br />");
return combinations;
}
document.write('<pre>2-combinations of "ABC":<br />');
document.write("Results: " + getCombos("ABC", 2) + "<br /></pre>");
</script>
这些程序的输出如下:
2-combinations of "ABC":
In getCombos('ABC', 2), start.
In getCombos('ABC', 2) part 1, get combos with head 'A'
.In getCombos('BC', 1), start.
.In getCombos('BC', 1) part 1, get combos with head 'B'
..In getCombos('C', 0), start.
..In getCombos('C', 0) base case returns ['']
.Adding head 'B' to tail combos:
.New combination B
.In getCombos('BC', 1) part 2, get combos without head 'B')
..In getCombos('C', 1), start.
..In getCombos('C', 1) part 1, get combos with head 'C'
...In getCombos('', 0), start.
...In getCombos('', 0) base case returns ['']
..Adding head 'C' to tail combos:
..New combination C
..In getCombos('C', 1) part 2, get combos without head 'C')
...In getCombos('', 1), start.
...In getCombos('', 1) base case returns []
..In getCombos('C', 1) results are ['C']
.In getCombos('BC', 1) results are ['B', 'C']
Adding head 'A' to tail combos:
New combination AB
New combination AC
In getCombos('ABC', 2) part 2, get combos without head 'A')
.In getCombos('BC', 2), start.
.In getCombos('BC', 2) part 1, get combos with head 'B'
..In getCombos('C', 1), start.
..In getCombos('C', 1) part 1, get combos with head 'C'
...In getCombos('', 0), start.
...In getCombos('', 0) base case returns ['']
..Adding head 'C' to tail combos:
..New combination C
..In getCombos('C', 1) part 2, get combos without head 'C')
...In getCombos('', 1), start.
...In getCombos('', 1) base case returns []
..In getCombos('C', 1) results are ['C']
.Adding head 'B' to tail combos:
.New combination BC
.In getCombos('BC', 2) part 2, get combos without head 'B')
..In getCombos('C', 2), start.
..In getCombos('C', 2) part 1, get combos with head 'C'
...In getCombos('', 1), start.
...In getCombos('', 1) base case returns []
..Adding head 'C' to tail combos:
..In getCombos('C', 2) part 2, get combos without head 'C')
...In getCombos('', 2), start.
...In getCombos('', 2) base case returns []
..In getCombos('C', 2) results are []
.In getCombos('BC', 2) results are ['BC']
In getCombos('ABC', 2) results are ['AB', 'AC', 'BC']
Results: ['AB', 'AC', 'BC']
每个getCombos()函数调用都有两个递归调用,用于算法的两个部分。对于我们的getCombos('ABC', 2)示例,第一部分?是获取包含头部A的所有组合。在树中,这会生成 1-组合级别下 A 节点下的所有组合。
我们可以通过将尾部和k - 1传递给第一个递归函数调用getCombos('BC', 1) ?来实现这一点。我们将A添加到这个递归函数调用返回的每个组合中。让我们使用信任原则,假设我们的getCombos()正确返回了一个k-组合列表['B', 'C'],即使我们还没有完成编写它。现在我们已经有了包含头部A的所有k-组合的数组来保存我们的结果:['AB', 'AC']。
第二部分?获取不包括头部A的所有组合。在树中,这会生成 1-组合级别中 A 节点右侧的所有组合。我们可以通过将尾部和k传递给第二个递归函数调用getCombos('BC', 2)来实现这一点。这将返回['BC'],因为 BC 是 BC 的唯一 2-组合。
getCombos('ABC', 2)的两个递归调用的结果,['AB', 'AC']和['BC']被连接在一起并返回:['AB', 'AC', 'BC'] ?。getCombos()函数以相同的方式生成更大集合的组合。
获取平衡括号的所有组合
如果每个开括号后面都紧跟一个闭括号,则字符串具有平衡括号。例如,′()()′和′(())′是两对平衡括号的字符串,但′)(()′和′(()′则不是平衡的。这些字符串也被称为Dyck words,以数学家瓦尔特·冯·迪克命名。
一个常见的编码面试问题是编写一个递归函数,给定括号对的数量,生成所有可能的平衡括号的组合。例如,调用getBalancedParens(3)应该返回['((()))', '(()())', '(())()', '()(())', '()()()']。请注意,调用getBalancedParens(``n``)会返回长度为 2n的字符串,因为每个字符串由n对括号组成。
“我们可以尝试通过找到括号字符的所有排列来解决这个问题,但这将导致平衡和不平衡的括号字符串。即使稍后过滤掉无效的字符串,对于n对括号,存在 2n!种排列。该算法速度太慢,不实用。
相反,我们可以实现一个递归函数来生成所有平衡括号的字符串。我们的getBalancedParens()函数接受一个整数,表示括号对的数量,并返回一个平衡括号字符串的列表。该函数通过添加开放或关闭括号来构建这些字符串。只有在剩余要使用的开放括号时才能添加开放括号。只有在迄今为止添加的开放括号比关闭括号多时才能添加关闭括号。
我们将使用名为openRem和closeRem的函数参数跟踪剩余要使用的开放和关闭括号的数量。当前正在构建的字符串是另一个名为current的函数参数,它与permutationsWithRepetition程序中的prefix参数具有类似的作用。第一个基本情况发生在openRem和closeRem都为0且没有更多的括号要添加到current字符串时。第二个基本情况发生在两个递归情况在添加开放和/或关闭括号后接收到平衡括号字符串列表之后。
让我们问一下关于getBalancedParens()函数的三个递归算法问题:
-
什么是基本情况?当剩余要添加到正在构建的字符串中的开放和关闭括号的数量达到
0时。第二个基本情况总是在递归情况完成后发生。 -
递归函数调用传递了什么参数?括号对的总数(
pairs),剩余要添加的开放和关闭括号的数量(openRem和closeRem),以及当前正在构建的字符串(current)。 -
这个参数如何接近基本情况?当我们向
current添加更多的开放和关闭括号时,我们递减openRem和closeRem参数,直到它们变为 0。
balancedParentheses.py文件包含了我们平衡括号递归函数的 Python 代码:
def getBalancedParens(pairs, openRem=None, closeRem=None, current='', indent=0):
if openRem is None: # ?
openRem = pairs
if closeRem is None:
closeRem = pairs
print('.' * indent, end='')
print('Start of pairs=' + str(pairs) + ', openRem=' +
str(openRem) + ', closeRem=' + str(closeRem) + ', current="' + current + '"')
if openRem == 0 and closeRem == 0: # ?
# BASE CASE
print('.' * indent, end='')
print('1st base case. Returning ' + str([current]))
return [current] # ?
# RECURSIVE CASE
results = []
if openRem > 0: # ?
print('.' * indent, end='')
print('Adding open parenthesis.')
results.extend(getBalancedParens(pairs, openRem - 1, closeRem,
current + '(', indent + 1))
if closeRem > openRem: # ?
print('.' * indent, end='')
print('Adding close parenthesis.')
results.extend(getBalancedParens(pairs, openRem, closeRem - 1,
current + ')', indent + 1))
# BASE CASE
print('.' * indent, end='')
print('2nd base case. Returning ' + str(results))
return results # ?
print('All combinations of 2 balanced parentheses:')
print('Results:', getBalancedParens(2))
balancedParentheses.html文件包含了该程序的 JavaScript 等效代码:
<script type="text/javascript">
function getBalancedParens(pairs, openRem, closeRem, current, indent) {
if (openRem === undefined) { // ?
openRem = pairs;
}
if (closeRem === undefined) {
closeRem = pairs;
}
if (current === undefined) {
current = "";
}
if (indent === undefined) {
indent = 0;
}
document.write(".".repeat(indent) + "Start of pairs=" +
pairs + ", openRem=" + openRem + ", closeRem=" +
closeRem + ", current=\"" + current + "\"<br />");
if (openRem === 0 && closeRem === 0) { // ?
// BASE CASE
document.write(".".repeat(indent) +
"1st base case. Returning " + [current] + "<br />");
return [current]; // ?
}
// RECURSIVE CASE
let results = [];
if (openRem > 0) { // ?
document.write(".".repeat(indent) + "Adding open parenthesis.<br />");
Array.prototype.push.apply(results, getBalancedParens(
pairs, openRem - 1, closeRem, current + '(', indent + 1));
}
if (closeRem > openRem) { // ?
document.write(".".repeat(indent) + "Adding close parenthesis.<br />");
results = results.concat(getBalancedParens(
pairs, openRem, closeRem - 1, current + ')', indent + 1));
}
// BASE CASE
document.write(".".repeat(indent) + "2nd base case. Returning " + results + "<br />");
return results; // ?
}
document.write(<pre>"All combinations of 2 balanced parentheses:<br />");
document.write("Results: ", getBalancedParens(2), "</pre>");
</script>
这些程序的输出如下:
All combinations of 2 balanced parentheses:
Start of pairs=2, openRem=2, closeRem=2, current=""
Adding open parenthesis.
.Start of pairs=2, openRem=1, closeRem=2, current="("
.Adding open parenthesis.
..Start of pairs=2, openRem=0, closeRem=2, current="(("
..Adding close parenthesis.
...Start of pairs=2, openRem=0, closeRem=1, current="(()"
...Adding close parenthesis.
....Start of pairs=2, openRem=0, closeRem=0, current="(())"
....1st base case. Returning ['(())']
...2nd base case. Returning ['(())']
..2nd base case. Returning ['(())']
.Adding close parenthesis.
..Start of pairs=2, openRem=1, closeRem=1, current="()"
..Adding open parenthesis.
...Start of pairs=2, openRem=0, closeRem=1, current="()("
...Adding close parenthesis.
....Start of pairs=2, openRem=0, closeRem=0, current="()()"
....1st base case. Returning ['()()']
...2nd base case. Returning ['()()']
..2nd base case. Returning ['()()']
.2nd base case. Returning ['(())', '()()']
2nd base case. Returning ['(())', '()()']
Results: ['(())', '()()']
getBalancedParens()函数?在用户调用时需要一个参数,即括号对的数量。但是,它需要在递归调用中传递额外的信息。这些信息包括剩余要添加的开放括号的数量(openRem),剩余要添加的关闭括号的数量(closeRem)和当前正在构建的平衡括号字符串(current)。openRem和closeRem都以与pairs参数相同的值开始,而current则以空字符串开始。indent参数仅用于调试输出,以显示程序的递归函数调用级别。
函数首先检查剩余要添加的开放和关闭括号的数量?。如果两者都是0,我们已经达到了第一个基本情况,并且current中的字符串已经完成。由于getBalancedParens()函数返回一个字符串列表,我们将current放入列表中并返回它?。
否则,函数继续进行递归。如果可能的话,剩余的开放括号?,函数调用getBalancedParens()并向当前参数添加一个开放括号。如果剩余的关闭括号比开放括号多?,函数调用getBalancedParens()并向当前参数添加一个关闭括号。这个检查确保不会添加不匹配的关闭括号,因为这会使字符串不平衡,比如())中的第二个关闭括号。
在这些递归情况之后是一个无条件的基本情况,它返回从两个递归函数调用返回的所有字符串(当然还有这些递归函数调用所做的递归函数调用,依此类推)?。
幂集:查找集合的所有子集
一个集合的幂集是该集合的每个可能子集的集合。例如,{A, B, C}的幂集是{{ }, {A}, {B}, {C}, {A, B}, {A, C}, {B, C}, {A, B, C}}。这等同于集合的每个可能k组合的集合。毕竟,{A, B, C}的幂集包含了它的所有 0-组合、1-组合、2-组合和 3-组合。
如果你正在寻找一个现实世界的例子,你需要生成一个集合的幂集,想象一下一个面试官要求你生成一个集合的幂集。你几乎不可能需要为任何其他原因生成一个集合的幂集,包括你正在面试的工作。
要找到集合的每个幂集,我们可以重用我们现有的getCombos()函数,用每个可能的k参数重复调用它。这种方法被powerSetCombinations.py和powerSetCombinations.html程序采用,这些程序可以从nostarch.com/recursive-book-recursion的可下载资源文件中获得。
然而,我们可以使用更有效的方法来生成幂集。让我们考虑{A, B}的幂集,即{{A, B}, {A}, {B}, { }}。现在假设我们再添加一个元素 C 到集合中,并且想要生成{A, B, C}的幂集。我们已经生成了{A, B}的幂集中的四个集合;此外,我们有这些相同的四个集合,但是加上了元素 C:{{A, B, C}, {A, C}, {B, C}, {C}}。表 6-3 显示了向集合添加更多元素如何向其幂集添加更多集合的模式。
表 6-3:随着新元素(加粗)添加到集合中,幂集如何增长
| 带有新元素的集合 | 幂集的新集合 | 完整的幂集 |
|---|---|---|
| { } | { } | {{ }} |
| {A} | {A} | {{ }, {A}} |
| {A, B} | {B}, {A, B} | {{ }, {A}, {B}, {A, B}} |
| {A, B, C} | {C}, {A, C}, {B, C}, {A, B, C} | {{ }, {A}, {B}, {C}, {A, B}, {A, C}, {B, C}, {A, B, C}} |
| {A, B, C, D} | {D}, {A, D}, {B, D}, {C, D}, {A, B, D}, {A, C, D}, {B, C, D}, {A, B, C, D} | {{ }, {A}, {B}, {C}, {D}, {A, B}, {A, C}, {A, D}, {B, C}, {B, D}, {C, D}, {A, B, C}, {A, B, D}, {A, C, D}, {B, C, D}, {A, B, C, D}} |
更大集合的幂集类似于更小集合的幂集,这暗示我们可以创建一个递归函数来生成它们。基本情况是一个空集,它的幂集是一个只有空集的集合。我们可以使用头尾技术来实现这个递归函数。对于我们添加的每个新元素,我们希望得到尾部的幂集以添加到我们的完整幂集中。我们还将头元素添加到尾部幂集中的每个集合中。这些一起形成了chars参数的完整幂集。
让我们问三个递归算法问题关于我们的幂集算法:
-
什么是基本情况?如果
chars是空字符串(空集),函数返回一个只有空字符串的数组,因为空集是空集的唯一子集。 -
递归函数调用传递了什么参数?
chars的尾部被传递。 -
这个参数如何接近基本情况?由于递归调用从
chars参数中删除头部,最终chars参数变为空字符串。
getPowerSet()递归函数在powerSet.py中实现:
Python
def getPowerSet(chars, indent=0):
debugMsg = '.' * indent + 'In getPowerSet("' + chars + '")'
print(debugMsg + ', start.')
if chars == '': # ?
# BASE CASE
print(debugMsg + " base case returns ['']")
return ['']
# RECURSIVE CASE
powerSet = []
head = chars[0]
tail = chars[1:]
# First part, get the sets that don't include the head:
print(debugMsg, "part 1, get sets without head '" + head + "'")
tailPowerSet = getPowerSet(tail, indent + 1) # ?
# Second part, get the sets that include the head:
print(debugMsg, "part 2, get sets with head '" + head + "'")
for tailSet in tailPowerSet:
print(debugMsg, 'New set', head + tailSet)
powerSet.append(head + tailSet) # ?
powerSet = powerSet + tailPowerSet
print(debugMsg, 'returning', powerSet)
return powerSet # ?
print('The power set of ABC:')
print(getPowerSet('ABC'))
等效的 JavaScript 代码在powerSet.html中:
<script type="text/javascript">
function getPowerSet(chars, indent) {
if (indent === undefined) {
indent = 0;
}
let debugMsg = ".".repeat(indent) + 'In getPowerSet("' + chars + '")';
document.write(debugMsg + ", start.<br />");
if (chars == "") { // ?
// BASE CASE
document.write(debugMsg + " base case returns ['']<br />");
return [''];
}
// RECURSIVE CASE
let powerSet = [];
let head = chars[0];
let tail = chars.slice(1, chars.length);
// First part, get the sets that don't include the head:
document.write(debugMsg +
" part 1, get sets without head '" + head + "'<br />");
let tailPowerSet = getPowerSet(tail, indent + 1); // ?
// Second part, get the sets that include the head:
document.write(debugMsg +
" part 2, get sets with head '" + head + "'<br />");
for (tailSet of tailPowerSet) {
document.write(debugMsg + " New set " + head + tailSet + "<br />");
powerSet.push(head + tailSet); // ?
}
powerSet = powerSet.concat(tailPowerSet);
document.write(debugMsg + " returning " + powerSet + "<br />");
return powerSet; // ?
}
document.write("<pre>The power set of ABC:<br />")
document.write(getPowerSet("ABC") + "<br /></pre>");
</script>
程序输出如下:
The power set of ABC:
In getPowerSet("ABC"), start.
In getPowerSet("ABC") part 1, get sets without head 'A'
.In getPowerSet("BC"), start.
.In getPowerSet("BC") part 1, get sets without head 'B'
..In getPowerSet("C"), start.
..In getPowerSet("C") part 1, get sets without head 'C'
...In getPowerSet(""), start.
...In getPowerSet("") base case returns ['']
..In getPowerSet("C") part 2, get sets with head 'C'
..In getPowerSet("C") New set C
..In getPowerSet("C") returning ['C', '']
.In getPowerSet("BC") part 2, get sets with head 'B'
.In getPowerSet("BC") New set BC
.In getPowerSet("BC") New set B
.In getPowerSet("BC") returning ['BC', 'B', 'C', '']
In getPowerSet("ABC") part 2, get sets with head 'A'
In getPowerSet("ABC") New set ABC
In getPowerSet("ABC") New set AB
In getPowerSet("ABC") New set AC
In getPowerSet("ABC") New set A
In getPowerSet("ABC") returning ['ABC', 'AB', 'AC', 'A', 'BC', 'B', 'C', '']
['ABC', 'AB', 'AC', 'A', 'BC', 'B', 'C', '']
getPowerSet()函数接受一个参数:包含原始集合字符的字符串chars。基本情况发生在chars是空字符串?时,表示空集。回想一下,幂集是原始集合的所有子集。因此,空集的幂集只是包含空集的集合,因为空集是空集的唯一子集。这就是为什么基本情况返回['']。
递归情况分为两部分。第一部分是获取chars尾部的幂集。我们将使用信任原则,假设调用getPowerSet()返回尾部的幂集正确?,即使在这一点上我们仍在编写getPowerSet()的代码。
为了形成chars的完整幂集,递归情况的第二部分通过将头部添加到每个尾部幂集来形成新集合?。与第一部分的集合一起,这形成了chars的幂集,在函数结束时返回?。
总结
排列和组合是许多程序员不知道如何开始解决的两个问题领域。虽然递归通常是常见编程问题的过于复杂的解决方案,但它非常适合本章任务的复杂性。
本章以简要介绍集合论开始。这为我们的递归算法操作的数据结构奠定了基础。集合是不同元素的集合。子集包括集合中的一些或所有元素。虽然集合的元素没有顺序,排列是集合中元素的特定顺序。而组合没有顺序,是集合中元素的特定选择。集合的k组合是从集合中选择的k个元素的子集。
排列和组合可以包括一个元素,也可以重复元素。我们称这些为无重复排列或组合和有重复排列或组合。这些由不同的算法实现。
本章还解决了在编码面试中常用的平衡括号问题。我们的算法通过从空字符串开始并添加开放和关闭括号来构建平衡括号的字符串。这种方法涉及回溯到较早的字符串,使递归成为一种理想的技术。
最后,本章介绍了一个用于生成幂集的递归函数,即集合中所有可能的k组合的集合。我们创建的递归函数比反复调用组合函数来生成每个可能大小的子集要高效得多。
进一步阅读
生成排列和组合只是揭示了你可以用排列和组合以及数学逻辑领域集合论做什么的冰山一角。以下维基百科文章提供了这些主题的更多细节,每个链接到维基百科文章:
Python 标准库提供了排列、组合和其他算法的实现,位于其itertools模块中。该模块在docs.python.org/3/library/itertools.html中有文档。
排列和组合也在统计和概率数学课程中涵盖。可在 Khan Academy 的计数、排列和组合单元中找到www.khanacademy.org/math/statistics-probability/counting-permutations-and-combinations。
练习问题
通过回答以下问题来测试您的理解:
-
集合的元素是否有特定顺序?排列呢?组合呢?
-
一个包含n个元素的集合有多少排列(不重复)?
-
一个包含n个元素的集合有多少组合(不重复)?
-
{A,B,C}是{A,B,C}的子集吗?
-
计算n选择k的公式是什么,即从n个元素的集合中选择k个元素的可能组合数?
-
确定以下哪些是排列或组合,有或没有重复:
-
AAA,AAB,AAC,ABA,ABB,ABC,ACA,ACB,ACC,BAA,BAB,BAC,BBA,BBB,BBC,BCA,BCB,BCC,CAA,CAB,CAC,CBA,CBB,CBC,CCA,CCB,CCC
-
ABC,ACB,BAC,BCA,CAB
-
(无),A,B,C,AB,AC,BC,ABC
-
(无),A,B,C,AA,AB,AC,BB,BC,CC,AAA,AAB,AAC,ABB,ABC,ACC,BBB,BBC,BCC,CCC
-
绘制一个树图,可用于生成集合{A,B,C,D}的所有可能组合。
-
回答本章中每个递归算法的递归解决方案的三个问题:
-
基本情况是什么?
-
递归函数调用传递了什么参数?
-
这个论点如何接近基本情况?
然后,重新创建本章中的递归算法,而不查看原始代码。
练习项目
为练习,编写一个执行以下任务的函数:
-
本章中的排列函数操作字符串值中的字符。修改它,使得集合由列表(在 Python 中)或数组(在 JavaScript 中)表示,元素可以是任何数据类型的值。例如,您的新函数应该能够生成整数值的排列,而不是字符串。
-
本章中的组合函数操作字符串值中的字符。修改它,使得集合由列表(在 Python 中)或数组(在 JavaScript 中)表示,元素可以是任何数据类型的值。例如,您的新函数应该能够生成整数值的组合,而不是字符串。
七、记忆化和动态规划
原文:Chapter 7 - Memoization and Dynamic Programming
译者:飞龙

在本章中,我们将探讨记忆化,这是一种使递归算法运行更快的技术。我们将讨论记忆化是什么,如何应用它,以及它在函数式编程和动态规划领域的用处。我们将使用第二章中的斐波那契算法来演示我们编写的代码和 Python 标准库中可以找到的记忆化功能。我们还将了解为什么记忆化不能应用于每个递归函数。
记忆化
记忆化是记住函数对其提供的特定参数的返回值的技术。例如,如果有人让我找到 720 的平方根,即乘以自身的结果为 720 的数字,我将不得不坐下来用铅笔和纸几分钟(或在 JavaScript 中调用Math.sqrt(720)或在 Python 中调用math.sqrt(720))来算出答案:26.832815729997478。如果他们几秒钟后再问我,我就不必重复计算,因为我已经有了答案。通过缓存先前计算的结果,记忆化通过增加内存使用量来节省执行时间。
将记忆化与记忆混淆是许多人现代的错误。 (随时可以做一个备忘录来提醒自己它们的区别。)
自顶向下的动态规划
记忆化是动态规划中的一种常见策略,这是一种涉及将大问题分解为重叠子问题的计算机编程技术。这听起来很像我们已经看到的普通递归。关键区别在于动态规划使用具有重复递归情况的递归;这些是重叠子问题。
例如,让我们考虑第二章中的递归斐波那契算法。进行递归fibonacci(6)函数调用将依次调用fibonacci(5)和fibonacci(4)。接下来,fibonacci(5)将调用fibonacci(4)和fibonacci(3)。斐波那契算法的子问题重叠,因为fibonacci(4)调用以及许多其他调用都是重复的。这使得生成斐波那契数成为一个动态规划问题。
这里存在一个低效:多次执行相同的计算是不必要的,因为fibonacci(4)将始终返回相同的值,即整数3。相反,我们的程序可以记住,如果递归函数的参数是4,函数应立即返回3。
图 7-1 显示了所有递归调用的树状图,包括记忆化可以优化的冗余函数调用。与此同时,快速排序和归并排序是递归分而治之算法,但它们的子问题不重叠;它们是独特的。动态规划技术不适用于这些排序算法。

图 7-1:从fibonacci(6)开始进行的递归函数调用的树状图。冗余的函数调用以灰色显示。
动态规划的一种方法是对递归函数进行记忆化,以便将先前的计算记住以供将来的函数调用使用。如果我们可以重用先前的返回值,重叠子问题就变得微不足道了。
使用记忆化的递归称为自顶向下动态规划。这个过程将一个大问题分解成更小的重叠子问题。相反的技术,自底向上动态规划,从较小的子问题(通常与基本情况有关)开始,并“构建”到原始大问题的解决方案。从第一个和第二个斐波那契数作为基本情况开始的迭代斐波那契算法就是自底向上动态规划的一个例子。自底向上方法不使用递归函数。
请注意,不存在自顶向下递归或自底向上递归。这些是常用但不正确的术语。所有递归已经是自顶向下的,因此自顶向下递归是多余的。而且没有底向上方法使用递归,因此没有自底向上递归这种东西。
函数式编程中的记忆化
并非所有函数都可以进行记忆化。为了理解原因,我们必须讨论函数式编程,这是一种强调编写不修改全局变量或任何外部状态(如硬盘上的文件、互联网连接或数据库内容)的函数的编程范式。一些编程语言,如 Erlang、Lisp 和 Haskell,都是围绕函数式编程概念进行设计的。但你可以将函数式编程特性应用到几乎任何编程语言,包括 Python 和 JavaScript。
函数式编程包括确定性和非确定性函数、副作用和纯函数的概念。介绍中提到的sqrt()函数是一个确定性函数,因为当传入相同的参数时,它总是返回相同的值。然而,Python 的random.randint()函数返回一个随机整数,是非确定性的,因为即使传入相同的参数,它也可能返回不同的值。time.time()函数返回当前时间,也是非确定性的,因为时间不断向前推移。
副作用是函数对其代码和局部变量之外的任何东西所做的任何更改。为了说明这一点,让我们创建一个实现 Python 减法运算符(-)的subtract()函数:
Python
>>> def subtract(number1, number2):
... return number1 - number2
...
>>> subtract(123, 987)
-864
这个subtract()函数没有副作用;调用这个函数不会影响程序代码外的任何东西。从程序或计算机的状态来看,无法判断subtract()函数之前是否被调用过一次、两次或一百万次。函数可能会修改函数内部的局部变量,但这些更改是局限于函数内部的,并与程序的其余部分隔离开来。
现在考虑一个addToTotal()函数,它将数字参数添加到名为TOTAL的全局变量中:
Python
>>> TOTAL = 0
>>> def addToTotal(amount):
... global TOTAL
... TOTAL += amount
... return TOTAL
...
>>> addToTotal(10)
10
>>> addToTotal(10)
20
>>> TOTAL
20
addToTotal()函数确实有副作用,因为它修改了函数外存在的元素:TOTAL全局变量。
副作用不仅仅是对全局变量的简单更改。它还包括更新或删除文件、在屏幕上打印文本、打开数据库连接、对服务器进行身份验证,或者对函数外的数据进行任何其他操作。函数调用在返回后留下的任何痕迹都是副作用。
如果一个函数是确定性的,没有副作用,那么它被称为纯函数。只有纯函数应该被记忆化。在接下来的部分中,当我们对递归斐波那契函数和doNotMemoize程序的不纯函数进行记忆化时,你会明白为什么。
记忆化递归斐波那契算法
让我们对第二章的递归斐波那契函数进行记忆化。请记住,这个函数非常低效:在我的计算机上,递归fibonacci(40)调用需要 57.8 秒来计算。与此同时,fibonacci(40)的迭代版本实际上太快了,以至于我的代码分析器无法测量:0.000 秒。
记忆化可以极大地加速函数的递归版本。例如,图 7-2 显示了原始和记忆化fibonacci()函数对前 20 个斐波那契数的函数调用次数。原始的、非记忆化的函数正在进行大量不必要的计算。
原始的fibonacci()函数的函数调用次数急剧增加(顶部),而记忆化的fibonacci()函数的函数调用次数增长缓慢(底部)。
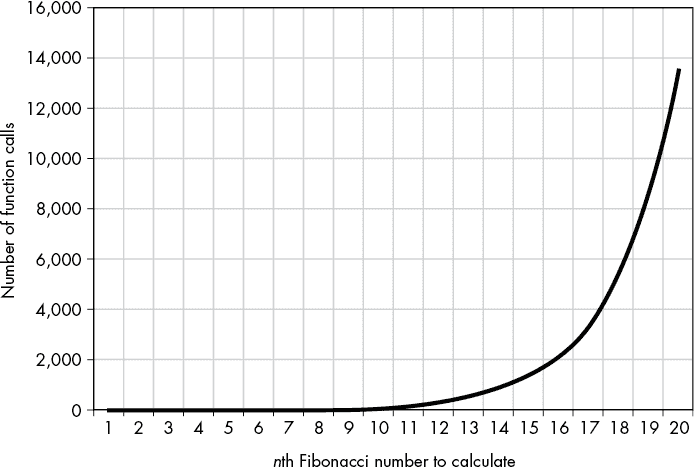
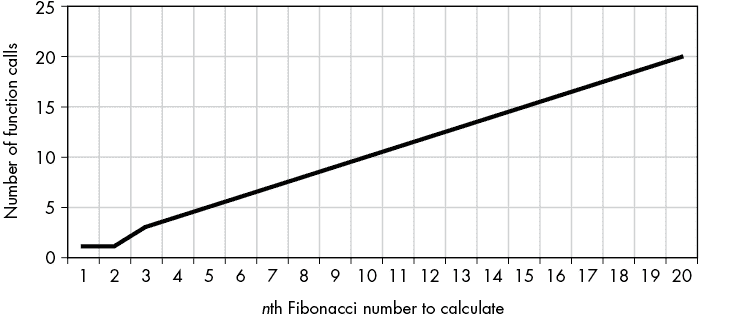
图 7-2:原始的fibonacci()函数的函数调用次数急剧增加(顶部),而记忆化的fibonacci()函数的函数调用次数增长缓慢(底部)。
Python 版本的记忆化斐波那契算法在fibonacciByRecursionMemoized.py中。第二章原始fibonacciByRecursion.html程序的添加已用粗体标记:
fibonacciCache = {} # ? # Create the global cache.
def fibonacci(nthNumber, indent=0):
global fibonacciCache
indentation = '.' * indent
print(indentation + 'fibonacci(%s) called.' % (nthNumber))
if nthNumber in fibonacciCache:
# If the value was already cached, return it.
print(indentation + 'Returning memoized result: %s' % (fibonacciCache[nthNumber]))
return fibonacciCache[nthNumber] # ?
if nthNumber == 1 or nthNumber == 2:
# BASE CASE
print(indentation + 'Base case fibonacci(%s) returning 1.' % (nthNumber))
fibonacciCache[nthNumber] = 1 # ? # Update the cache.
return 1
else:
# RECURSIVE CASE
print(indentation + 'Calling fibonacci(%s) (nthNumber - 1).' % (nthNumber - 1))
result = fibonacci(nthNumber - 1, indent + 1)
print(indentation + 'Calling fibonacci(%s) (nthNumber - 2).' % (nthNumber - 2))
result = result + fibonacci(nthNumber - 2, indent + 1)
print('Call to fibonacci(%s) returning %s.' % (nthNumber, result))
fibonacciCache[nthNumber] = result # ? # Update the cache.
return result
print(fibonacci(10))
print(fibonacci(10)) # ?
JavaScript 版本的记忆化斐波那契算法在fibonacciByRecursionMemoized.html中。第二章原始fibonacciByRecursion.html程序的添加已用粗体标记:
JavaScript
<script type="text/javascript">
let fibonacciCache = {}; // Create the global cache. // ?
function fibonacci(nthNumber, indent) {
if (indent === undefined) {
indent = 0;
}
let indentation = '.'.repeat(indent);
document.write(indentation + "fibonacci(" + nthNumber + ") called.
<br />");
if (nthNumber in fibonacciCache) {
// If the value was already cached, return it.
document.write(indentation +
"Returning memoized result: " + fibonacciCache[nthNumber] + "<br />");
return fibonacciCache[nthNumber]; // ?
}
if (nthNumber === 1 || nthNumber === 2) {
// BASE CASE
document.write(indentation +
"Base case fibonacci(" + nthNumber + ") returning 1.<br />");
fibonacciCache[nthNumber] = 1; // Update the cache. // ?
return 1;
} else {
// RECURSIVE CASE
document.write(indentation +
"Calling fibonacci(" + (nthNumber - 1) + ") (nthNumber - 1).<br />");
let result = fibonacci(nthNumber - 1, indent + 1);
document.write(indentation +
"Calling fibonacci(" + (nthNumber - 2) + ") (nthNumber - 2).<br />");
result = result + fibonacci(nthNumber - 2, indent + 1);
document.write(indentation + "Returning " + result + ".<br />");
fibonacciCache[nthNumber] = result; // Update the cache. // ?
return result;
}
}
document.write("<pre>");
document.write(fibonacci(10) + "<br />");
document.write(fibonacci(10) + "<br />"); // ?
document.write("</pre>");
</script>
如果你将这个程序的输出与第二章中的原始递归斐波那契程序进行比较,你会发现它要短得多。这反映了为达到相同结果所需的计算量的大幅减少:
fibonacci(10) called.
Calling fibonacci(9) (nthNumber - 1).
.fibonacci(9) called.
.Calling fibonacci(8) (nthNumber - 1).
..fibonacci(8) called.
..Calling fibonacci(7) (nthNumber - 1).
# --snip--
.......Calling fibonacci(2) (nthNumber - 1).
........fibonacci(2) called.
........Base case fibonacci(2) returning 1.
.......Calling fibonacci(1) (nthNumber - 2).
........fibonacci(1) called.
........Base case fibonacci(1) returning 1.
Call to fibonacci(3) returning 2.
......Calling fibonacci(2) (nthNumber - 2).
.......fibonacci(2) called.
.......Returning memoized result: 1
# --snip--
Calling fibonacci(8) (nthNumber - 2).
.fibonacci(8) called.
.Returning memoized result: 21
Call to fibonacci(10) returning 55.
55
fibonacci(10) called.
Returning memoized result: 55
55
为了对这个函数进行记忆,我们将创建一个全局变量命名为fibonacciCache的字典(在 Python 中)或对象(在 JavaScript 中)?。它的键是传递给nthNumber参数的参数,它的值是fibonacci()函数返回的整数,给定该参数。每个函数调用首先检查它的nthNumber参数是否已经在缓存中。如果是,缓存的返回值就会被返回?。否则,函数会正常运行(尽管它也会在函数返回之前将结果添加到缓存中? ?)。
记忆函数实际上扩展了斐波那契算法中的基本情况数量。原始的基本情况只适用于第一个和第二个斐波那契数:它们立即返回1。但是,每当递归情况返回一个整数时,它就成为所有未来fibonacci()调用的基本情况。结果已经在fibonacciCache中,可以立即返回。如果您之前已经调用过fibonacci(99),它就像fibonacci(1)和fibonacci(2)一样成为一个基本情况。换句话说,记忆通过增加基本情况的数量来改善具有重叠子问题的递归函数的性能。请注意,当我们的程序第二次尝试找到第 10 个斐波那契数时?,它立即返回了记忆的结果:55。
请记住,虽然记忆可以减少递归算法所做的冗余函数调用的数量,但它不一定会减少调用堆栈上的帧对象的增长。记忆不会防止堆栈溢出错误。再次强调,您可能最好放弃递归算法,选择更直接的迭代算法。
Python 的 functools 模块
通过添加一个全局变量和管理它的代码来为每个想要记忆的函数实现缓存可能会相当麻烦。Python 的标准库有一个functools模块,其中有一个名为@lru_cache()的函数装饰器,它可以自动记忆它装饰的函数。在 Python 语法中,这意味着在函数的def语句之前添加@lru_cache()。
缓存可以设置内存大小限制。装饰器名称中的lru代表最近最少使用的缓存替换策略,这意味着当缓存达到限制时,最近最少使用的条目将被新条目替换。LRU 算法简单快速,尽管其他缓存替换策略可用于不同的软件需求。
fibonacciFunctools.py程序演示了@lru_cache()装饰器的使用。第二章中原始的fibonacciByRecursion.py程序的添加已经用粗体标记出来:
Python
import functools
@functools.lru_cache()
def fibonacci(nthNumber):
print('fibonacci(%s) called.' % (nthNumber))
if nthNumber == 1 or nthNumber == 2:
# BASE CASE
print('Call to fibonacci(%s) returning 1.' % (nthNumber))
return 1
else:
# RECURSIVE CASE
print('Calling fibonacci(%s) (nthNumber - 1).' % (nthNumber - 1))
result = fibonacci(nthNumber - 1)
print('Calling fibonacci(%s) (nthNumber - 2).' % (nthNumber - 2))
result = result + fibonacci(nthNumber - 2)
print('Call to fibonacci(%s) returning %s.' % (nthNumber, result))
return result
print(fibonacci(99))
与在fibonacciByRecursionMemoized.py中实现自己的缓存所需的添加相比,使用 Python 的@lru_cache()装饰器要简单得多。通常,使用递归算法计算fibonacci(99)需要几个世纪。通过记忆,我们的程序在几毫秒内显示了218922995834555169026的结果。
记忆是一种对具有重叠子问题的递归函数很有用的技术,但它可以应用于任何纯函数,以加快运行时,代价是计算机内存。
当您记忆不纯函数时会发生什么?
您不应该将@lru_cache添加到不纯的函数中,这意味着它们是不确定的或具有副作用。记忆通过跳过函数中的代码并返回先前缓存的返回值来节省时间。这对于纯函数来说是可以的,但对于不纯函数可能会导致各种错误。
在非确定性函数中,例如返回当前时间的函数,记忆化会导致函数返回不正确的结果。对于具有副作用的函数,例如向屏幕打印文本的函数,记忆化会导致函数跳过预期的副作用。doNotMemoize.py程序演示了当@lru_cache函数装饰器(在前一节中描述)记忆化这些不纯函数时会发生什么:
Python
import functools, time, datetime
@functools.lru_cache()
def getCurrentTime():
# This nondeterministic function returns different values each time
# it's called.
return datetime.datetime.now()
@functools.lru_cache()
def printMessage():
# This function displays a message on the screen as a side effect.
print('Hello, world!')
print('Getting the current time twice:')
print(getCurrentTime())
print('Waiting two seconds...')
time.sleep(2)
print(getCurrentTime())
print()
print('Displaying a message twice:')
printMessage()
printMessage()
当您运行此程序时,输出如下:
Getting the current time twice:
2022-07-30 16:25:52.136999
Waiting two seconds...
2022-07-30 16:25:52.136999
Displaying a message twice:
Hello, world!
请注意,尽管第二次调用getCurrentTime()比第一次调用晚了两秒,但返回的结果相同。而对printMessage()的两次调用中,只有第一次调用会在屏幕上显示Hello, world!消息。
这些错误很微妙,因为它们不会导致明显的崩溃,而是导致函数的行为不正确。无论如何记忆化函数,一定要彻底测试它们。
总结
记忆化(不是记忆)是一种优化技术,可以通过记住相同计算的先前结果来加速具有重叠子问题的递归算法。记忆化是动态规划领域的常见技术。通过交换计算机内存使用量以改善运行时间,记忆化使一些原本难以处理的递归函数成为可能。
然而,记忆化不能防止堆栈溢出错误。请记住,记忆化并不是使用简单迭代解决方案的替代品。仅仅为了使用递归而使用递归的代码并不会自动比非递归代码更加优雅。
记忆化函数必须是纯函数——即它们必须是确定性的(每次给定相同的参数返回相同的值)并且不能具有副作用(影响函数之外的计算机或程序的任何内容)。纯函数通常在函数式编程中使用,函数式编程大量使用递归。
记忆化是通过为每个要记忆化的函数创建一个称为缓存的数据结构来实现的。您可以自己编写此代码,但 Python 具有内置的@functools.lru_cache()装饰器,可以自动记忆化它装饰的函数。
进一步阅读
动态规划算法不仅仅是简单地记忆化函数。这些算法通常在编程面试和编程竞赛中使用。Coursera 提供了一个免费的“动态规划,贪婪算法”课程www.coursera.org/learn/dynamic-programming-greedy-algorithms。freeCodeCamp 组织还在www.freecodecamp.org/news/learn-dynamic-programing-to-solve-coding-challenges上推出了一系列关于动态规划的课程。
如果您想了解有关 LRU 缓存和其他与缓存相关的函数的更多信息,请参阅官方 Python 文档中的functools模块docs.python.org/3/library/functools.html。有关其他类型的缓存替换算法的更多信息,请参阅维基百科en.wikipedia.org/wiki/Cache_replacement_policies。
练习问题
通过回答以下问题来测试您的理解:
-
什么是记忆化?
-
动态规划问题与常规递归问题有何不同?
-
函数式编程强调什么?
-
一个函数必须具备哪两个特征才能成为纯函数?
-
返回当前日期和时间的函数是确定性函数吗?
-
记忆化如何改善具有重叠子问题的递归函数的性能?
-
将
@lru_cache()函数装饰器添加到归并排序函数中会提高其性能吗?为什么? -
在函数的局部变量中改变值是副作用的一个例子吗?
-
记忆化能防止堆栈溢出吗?
八、尾调用优化
原文:Chapter 8 - Tail Call Optimization
译者:飞龙

在上一章中,我们介绍了使用记忆化来优化递归函数。本章探讨了一种称为尾调用优化的技术,这是编译器或解释器提供的一种功能,用于避免堆栈溢出。尾调用优化也称为尾调用消除或尾递归消除。
本章旨在解释尾调用优化,而不是为其背书。我甚至会建议永远不要使用尾调用优化。正如你将看到的,重新排列函数的代码以使用尾调用优化通常会使其变得难以理解。你应该考虑尾调用优化更像是一种黑客或变通方法,用于使递归在你本不应该使用递归算法的情况下工作。记住,一个复杂的递归解决方案并不自动成为一个优雅的解决方案;简单的编码问题应该用简单的非递归方法来解决。
许多流行编程语言的实现甚至不提供尾调用优化作为一项功能。这些包括 Python、JavaScript 和 Java 的解释器和编译器。然而,尾调用优化是一种你应该熟悉的技术,以防你在你的代码项目中遇到它。
尾递归和尾调用优化的工作原理
要利用尾调用优化,一个函数必须使用尾递归。在尾递归中,递归函数调用是递归函数的最后一个操作。在代码中,这看起来像是一个return语句返回递归调用的结果。
要看到这个过程,回想一下第二章中的factorialByRecursion.py和factorialByRecursion.html程序。这些程序计算了一个整数的阶乘;例如,5!等于 5 × 4 × 3 × 2 × 1,即 120。这些计算可以通过递归来进行,因为factorial(n)等同于n * factorial(n - 1),其中n == 1是基本情况,返回1。
让我们重写这些程序以使用尾递归。下面的factorialTailCall.py程序有一个使用尾递归的factorial()函数:
Python
def factorial(number, accum=1):
if number == 1:
# BASE CASE
return accum
else:
# RECURSIVE CASE
return factorial(number - 1, accum * number)
print(factorial(5))
factorialTailCall.html程序有等效的 JavaScript 代码:
JavaScript
<script type="text/javascript">
function factorial(number, accum=1) {
if (number === 1) {
// BASE CASE
return accum;
} else {
// RECURSIVE CASE
return factorial(number - 1, accum * number);
}
}
document.write(factorial(5));
</script>
请注意,factorial()函数的递归情况以return语句结束,返回对factorial()的递归调用的结果。为了允许解释器或编译器实现尾调用优化,递归函数所做的最后一个操作必须是返回递归调用的结果。在进行递归调用和return语句之间不能发生任何指令。基本情况返回accum参数。这是累加器,在下一节中解释。
要理解尾调用优化的工作原理,记住第一章中函数调用时发生了什么。首先,创建一个帧对象并将其存储在调用堆栈上。如果函数调用另一个函数,将创建另一个帧对象并将其放在调用堆栈的第一个帧对象的顶部。当函数返回时,你的程序会自动从调用堆栈的顶部删除帧对象。
堆栈溢出发生在太多的函数调用没有返回的情况下,导致帧对象的数量超过调用堆栈的容量。对于 Python 来说,这个容量是 1,000 个函数调用,对于 JavaScript 程序来说大约是 10,000 个。虽然这些数量对于典型程序来说已经足够了,但递归算法可能会超过这个限制,导致堆栈溢出,从而使你的程序崩溃。
回想一下第二章,帧对象存储了函数调用中的局部变量,以及函数完成时返回的指令地址。然而,如果函数递归情况中的最后一个动作是返回递归函数调用的结果,就没有必要保留局部变量。函数在递归调用之后不涉及任何局部变量,因此当前帧对象可以立即被删除。下一个帧对象的返回地址信息可以与被删除的旧帧对象的返回地址相同。
由于当前帧对象被删除而不是保留在调用堆栈上,调用堆栈永远不会增长并且永远不会导致堆栈溢出!
回想一下第一章,所有递归算法都可以使用堆栈和循环来实现。由于尾调用优化消除了对调用堆栈的需求,我们实际上是在使用递归来模拟循环的迭代代码。然而,在本书的前面,我曾经说过适合递归解决方案的问题涉及类似树的数据结构和回溯。没有调用堆栈,没有尾递归函数可能做任何回溯工作。在我看来,每个可以使用尾递归实现的算法都更容易和更可读地使用循环来实现。仅仅因为递归而使用递归并不会自动更加优雅。
尾递归中的累加器
尾递归的缺点在于它要求重新排列递归函数,使得最后一个动作是返回递归调用的返回值。这会使我们的递归代码变得更加难以阅读。事实上,本章的factorialTailCall.py和factorialTailCall.html程序中的factorial()函数比第二章的factorialByRecursion.py和factorialByRecursion.html程序中的版本更难理解一些。
在我们的尾调用factorial()函数中,一个名为accum的新参数跟随着递归函数调用产生的计算结果。这被称为累加器参数,它跟踪了一个计算的部分结果,否则这个结果将会被存储在一个局部变量中。并不是所有的尾递归函数都使用累加器,但它们充当了尾递归无法在最后的递归调用之后使用局部变量的一种变通方法。请注意,在factorialByRecursion.py的factorial()函数中,递归情况是return number * factorial(number - 1)。乘法发生在factorial(number - 1)递归调用之后。accum累加器取代了number局部变量的位置。
还要注意,factorial()的基本情况不再返回1,而是返回accum累加器。当factorial()被调用时,number == 1并且达到基本情况时,accum存储了要返回的最终结果。调整代码以使用尾调用优化通常涉及更改基本情况以返回累加器的值。
你可以把factorial(5)函数调用看作是转换成以下的return,如图 8-1 所示。

图 8-1:factorial(5)转换为整数 120 的过程
重新排列递归调用作为函数中的最后一个动作,并添加累加器,会使你的代码变得比典型的递归代码更难理解。但这并不是尾递归的唯一缺点,我们将在下一节中看到。
尾递归的限制
尾递归函数需要重新排列它们的代码,使其适合编译器或解释器的尾调用优化功能。然而,并非所有编译器和解释器都提供尾调用优化作为一项功能。值得注意的是,CPython(从python.org下载的 Python 解释器)不实现尾调用优化。即使你将递归函数写成递归调用作为最后一个动作,它仍会在足够多的函数调用后导致堆栈溢出。
此外,CPython 可能永远不会将尾调用优化作为一项功能。Python 编程语言的创始人 Guido van Rossum 解释说,尾调用优化可能会使程序更难调试。尾调用优化会从调用堆栈中移除帧对象,从而移除帧对象可以提供的调试信息。他还指出,一旦实现了尾调用优化,Python 程序员将开始编写依赖于该功能的代码,他们的代码将无法在不实现尾调用优化的非 CPython 解释器上运行。
最后,我同意,van Rossum 不同意递归是日常编程的基本重要部分的观点。计算机科学家和数学家倾向于把递归放在一个高位。但尾调用优化只是一个解决方案,使一些递归算法实际可行,而不是简单地因堆栈溢出而崩溃。
虽然 CPython 不支持尾调用优化,但这并不意味着实现 Python 语言的其他编译器或解释器不能具有尾调用优化。除非尾调用优化明确地成为编程语言规范的一部分,否则它不是编程语言的特性,而是编程语言的个别编译器或解释器的特性。
缺乏尾调用优化并不是 Python 独有的。自第 8 版以来,Java 编译器也不支持尾调用优化。尾调用优化是 JavaScript 的 ECMAScript 6 版本的一部分;然而,截至 2022 年,只有 Safari 浏览器的 JavaScript 实现实际上支持它。确定你的编程语言的编译器或解释器是否实现了这一功能的一种方法是编写一个尾递归阶乘函数,尝试计算 100,000 的阶乘。如果程序崩溃,那么尾调用优化没有被实现。
就个人而言,我认为尾递归技术不应该被使用。正如第二章所述,任何递归算法都可以用循环和堆栈来实现。尾调用优化通过有效地移除调用堆栈来防止堆栈溢出。因此,所有尾递归算法都可以仅用循环来实现。由于循环的代码比递归函数简单得多,应该在任何可以使用尾调用优化的地方使用循环。
此外,即使实现了尾调用优化,也可能存在潜在问题。由于尾递归仅在函数的最后一个动作是返回递归调用的返回值时才可能发生,因此对于需要两个或更多递归调用的算法来说,尾递归是不可能的。例如,考虑斐波那契数列算法调用fibonacci(n - 1)和fibonacci(n - 2)。尽管后者的递归调用可以进行尾调用优化,但对于足够大的参数,第一个递归调用将导致堆栈溢出。
尾递归案例研究
让我们来检查一些在本书中早些时候展示的递归函数,看看它们是否适合尾递归。请记住,由于 Python 和 JavaScript 实际上并未实现尾调用优化,这些尾递归函数仍然会导致堆栈溢出错误。这些案例研究仅用于演示目的。
尾递归反转字符串
第一个例子是我们在第三章中制作的反转字符串的程序。这个尾递归函数的 Python 代码在reverseStringTailCall.py中:
Python
def rev(theString, accum=''): # ?
if len(theString) == 0:
# BASE CASE
return accum # ?
else:
# RECURSIVE CASE
head = theString[0]
tail = theString[1:]
return rev(tail, head + accum) # ?
text = 'abcdef'
print('The reverse of ' + text + ' is ' + rev(text))
等效的 JavaScript 在reverseStringTailCall.html中:
JavaScript
<script type="text/javascript">
function rev(theString, accum='') { // ?
if (theString.length === 0) {
// BASE CASE
return accum; // ?
} else {
// RECURSIVE CASE
let head = theString[0];
let tail = theString.substring(1, theString.length);
return rev(tail, head + accum); // ?
}
}
let text = "abcdef";
document.write("The reverse of " + text + " is " + rev(text) + "<br />");
</script>
将reverseString.py和reverseString.html中的原始递归函数转换为涉及添加累加器参数。如果没有为它传递参数,则默认情况下将累加器命名为accum,设置为空字符串?。我们还将基本情况从return ''更改为return accum?,将递归情况从return rev(tail) + head(在递归调用返回后执行字符串连接)更改为return rev(tail, head + accum)?。您可以将rev('abcdef')函数调用视为转换为以下return,如图 8-2 所示。
通过有效地使用累加器作为跨函数调用共享的本地变量,我们可以使rev()函数成为尾递归。

图 8-2:rev('abcdef')对字符串fedcba进行的转换过程
尾递归查找子字符串
一些递归函数自然地使用尾递归模式。如果您查看第二章中findSubstring.py和findSubstring.html程序中的findSubstringRecursive()函数,您会注意到递归情况的最后操作是返回递归函数调用的值。不需要进行任何调整使此函数成为尾递归。
尾递归指数
exponentByRecursion.py和exponentByRecursion.html程序,也来自第二章,不是尾递归的好候选。这些程序有两个递归情况,当n参数为偶数或奇数时。这没问题:只要所有递归情况都将递归函数调用的返回值作为它们的最后操作,函数就可以使用尾调用优化。
但是,请注意n 为偶数的 Python 代码递归情况:
Python
# --snip--
elif n % 2 == 0:
# RECURSIVE CASE (when n is even)
result = exponentByRecursion(a, n / 2)
return result * result
# --snip--
并注意等效的 JavaScript 递归情况:
JavaScript
# --snip--
} else if (n % 2 === 0) {
// RECURSIVE CASE (when n is even)
result = exponentByRecursion(a, n / 2);
return result * result;
# --snip--
这个递归情况没有递归调用作为它的最后操作。我们可以摆脱result本地变量,而是两次调用递归函数。这将减少递归情况到以下内容:
# --snip--
return exponentByRecursion(a, n / 2) * exponentByRecursion(a, n / 2)
# --snip--
但是,现在我们有两个对exponentByRecursion()的递归调用。这不仅使算法执行的计算量翻倍,而且函数执行的最后操作是将两个返回值相乘。这与递归斐波那契算法的问题相同:如果递归函数有多个递归调用,那么至少有一个递归调用不能是函数的最后操作。
尾递归奇偶数
要确定一个整数是奇数还是偶数,可以使用%模数运算符。表达式number%2 == 0如果number是偶数,则为True,如果number是奇数,则为False。但是,如果您更喜欢过度设计更“优雅”的递归算法,可以在isOdd.py中实现以下isOdd()函数(isOdd.py的其余部分稍后在本节中介绍):
Python
def isOdd(number):
if number == 0:
# BASE CASE
return False
else:
# RECURSIVE CASE
return not isOdd(number - 1)
print(isOdd(42))
print(isOdd(99))
# --snip--
等效的 JavaScript 在isOdd.html中:
JavaScript
<script type="text/javascript">
function isOdd(number) {
if (number === 0) {
// BASE CASE
return false;
} else {
// RECURSIVE CASE
return !isOdd(number - 1);
}
}
document.write(isOdd(42) + "<br />");
document.write(isOdd(99) + "<br />");
# --snip--
我们有两个isOdd()的基本情况。当number参数为0时,函数返回False以表示偶数。为简单起见,我们的isOdd()实现仅适用于正整数。递归情况返回isOdd(number - 1)的相反值。
您可以通过一个例子看到这是如何工作的:当调用isOdd(42)时,函数无法确定42是偶数还是奇数,但知道答案与41是奇数还是偶数相反。函数将返回not isOdd(41)。这个函数调用,反过来返回isOdd(40)的相反布尔值,依此类推,直到isOdd(0)返回False。递归函数调用的数量决定了在最终返回值返回之前作用于返回值的not运算符的数量。
然而,这个递归函数对于大数参数会导致堆栈溢出。调用isOdd(100000)会导致 100,001 个函数调用而没有返回,这远远超出了任何调用堆栈的容量。我们可以重新排列函数中的代码,使递归情况的最后一个操作是返回递归函数调用的结果,使函数成为尾递归。我们在isOdd.py中的isOddTailCall()中这样做。以下是isOdd.py程序的其余部分:
Python
# --snip--
def isOddTailCall(number, inversionAccum=False):
if number == 0:
# BASE CASE
return inversionAccum
else:
# RECURSIVE CASE
return isOddTailCall(number - 1, not inversionAccum)
print(isOddTailCall(42))
print(isOddTailCall(99))
JavaScript 等效代码在isOdd.html的其余部分中:
JavaScript
# --snip--
function isOddTailCall(number, inversionAccum) {
if (inversionAccum === undefined) {
inversionAccum = false;
}
if (number === 0) {
// BASE CASE
return inversionAccum;
} else {
// RECURSIVE CASE
return isOddTailCall(number - 1, !inversionAccum);
}
}
document.write(isOdd(42) + "<br />");
document.write(isOdd(99) + "<br />");
</script>
如果这个 Python 和 JavaScript 代码是由支持尾调用优化的解释器运行的,调用isOddTailCall(100000)不会导致堆栈溢出。然而,尾调用优化仍然比简单使用%模运算符确定奇偶性要慢得多。
如果您认为递归,无论是否有尾递归,是确定正整数是否为奇数的一种极其低效的方法,那么您是完全正确的。与迭代解决方案不同,递归可能会因堆栈溢出而失败。添加尾调用优化以防止堆栈溢出并不能修复不适当使用递归的效率缺陷。作为一种技术,递归并不自动比迭代解决方案更好或更复杂。而且尾递归永远不是比循环或其他简单解决方案更好的方法。
总结
尾调用优化是编程语言的编译器或解释器的一个特性,可以用于特别编写为尾递归的递归函数。尾递归函数将递归函数调用的返回值作为递归情况中的最后一个操作返回。这允许函数删除当前帧对象,并防止调用堆栈在进行新的递归函数调用时增长。如果调用堆栈不增长,递归函数不可能导致堆栈溢出。
尾递归是一种解决方案,允许一些递归算法在处理大参数时不会崩溃。然而,这种方法需要重新排列代码,可能需要添加一个累加器参数。这可能会使您的代码更难理解。您可能会发现,牺牲代码的可读性不值得使用递归算法而不是迭代算法。
进一步阅读
Stack Overflow(网站,而不是编程错误)在stackoverflow.com/questions/33923/what-is-tail-recursion上对尾递归的基础进行了详细讨论。
Van Rossum 在两篇博文中写到了他决定不使用尾递归的原因,网址分别为neopythonic.blogspot.com.au/2009/04/tail-recursion-elimination.html和neopythonic.blogspot.com.au/2009/04/final-words-on-tail-calls.html。
Python 的标准库包括一个名为inspect的模块,允许您在 Python 程序运行时查看调用堆栈上的帧对象。inspect模块的官方文档位于docs.python.org/3/library/inspect.html,Doug Hellmann 的 Python 3 Module of the Week 博客上有一个教程,网址为pymotw.com/3/inspect。
练习问题
通过回答以下问题来测试您的理解:
-
尾调用优化可以防止什么?
-
递归函数的最后一个动作与尾递归函数有什么关系?
-
所有编译器和解释器都实现尾调用优化吗?
-
什么是累加器?
-
尾递归的缺点是什么?
-
快速排序算法(第五章介绍)可以重写以使用尾调用优化吗?
九、绘制分形
原文:Chapter 9 - Drawing Fractals
译者:飞龙
{kind=link}
当然,递归最有趣的应用是绘制分形。 分形是在不同尺度上重复自己的形状,有时是混乱的。 这个术语是由分形几何学的创始人 Benoit B. Mandelbrot 在 1975 年创造的,源自拉丁语frāctus,意思是破碎或断裂,就像破碎的玻璃一样。 分形包括许多自然和人造形状。 在自然界中,您可能会在树的形状,蕨类叶子,山脉,闪电,海岸线,河网和雪花的形状中看到它们。 数学家,程序员和艺术家可以根据一些递归规则创建复杂的几何形状。
递归可以使用惊人地少的代码行生成复杂的分形艺术。 本章介绍了 Python 的内置“turtle”模块,用于使用代码生成几种常见的分形。 要使用 JavaScript 创建海龟图形,您可以使用 Greg Reimer 的“jtg”库。 为简单起见,本章仅介绍了 Python 分形绘图程序,而没有 JavaScript 等价物。 但是,本章介绍了“jtg”JavaScript 库。
海龟图形
海龟图形是 Logo 编程语言的一个特性,旨在帮助孩子们学习编码概念。 此功能自那时以来已在许多语言和平台上复制。 其核心思想是一个叫做海龟的对象。
海龟充当可编程笔,在 2D 窗口中绘制线条。 想象一只真正的海龟在地面上拿着一支笔,随着它移动,它在身后画一条线。 海龟可以调整其笔的大小和颜色,或者“抬起笔”,以便在移动时不绘制。 海龟程序可以产生复杂的几何图形,如图 9-1。
当您将这些指令放在循环和函数中时,即使是小程序也可以创建令人印象深刻的几何图形。 考虑以下spiral.py程序:
Python
import turtle
turtle.tracer(1, 0) # Makes the turtle draw faster.
for i in range(360):
turtle.forward(i)
turtle.left(59)
turtle.exitonclick() # Pause until user clicks in the window.
当您运行此程序时,海龟窗口会打开。 海龟(由三角形表示)将在图 9-1 中追踪螺旋图案。 虽然不是分形,但它是一幅美丽的图画。

图 9-1:使用 Python 的“turtle”模块绘制的螺旋
海龟图形系统中的窗口使用笛卡尔 x 和 y 坐标。 水平 x 坐标的数字向右增加,向左减少,而垂直 y 坐标的数字向上增加,向下减少。 这两个坐标一起可以为窗口中的任何点提供唯一的地址。 默认情况下,原点(坐标点在 0,0 处)位于窗口的中心。
海龟还有一个heading,或者方向,是从 0 到 359 的数字(一个圆被分成 360 度)。 在 Python 的“turtle”模块中,0 的 heading 面向东(朝屏幕的右边缘),并且顺时针增加; 90 的 heading 面向北,180 的 heading 面向西,270 的 heading 面向南。 在 JavaScript 的“jtg”库中,此方向被旋转,以便 0 度面向北,并且逆时针增加。 图 9-2 演示了 Python“turtle”模块和 JavaScript“jtg”库的 heading。
图 9-2:Python 的“turtle”模块(左)和 JavaScript 的“jtg”库(右)中的航向
在 JavaScript 的“jtg”库中,进入inventwithpython.com/jtg,将以下代码输入到页面底部的文本字段中:
JavaScript
for (let i = 0; i < 360; i++) { t.fd(i); t.lt(59) }
这将在网页的主要区域绘制与图 9-1 中显示的相同螺旋线。
基本海龟函数
海龟图形中最常用的函数会导致海龟改变航向并向前或向后移动。turtle.left()和turtle.right()函数从当前航向开始旋转海龟一定角度,而turtle.forward()和turtle.backward()函数根据当前位置移动海龟。
表 9-1 列出了一些海龟的函数。第一个函数(以“turtle.”开头)是为 Python,第二个(以“t.”开头)是为 JavaScript。完整的 Python 文档可在docs.python.org/3/library/turtle.html找到。在 JavaScript 的“jtg”软件中,您可以按 F1 键显示帮助屏幕。
表 9-1:Python 的“turtle”模块和 JavaScript 的“jtg”库中的海龟函数
| Python | JavaScript | 描述 |
|---|---|---|
goto(x, y) | xy(x, y) | 将海龟移动到 x,y 坐标。 |
setheading(deg) | heading(deg) | 设置海龟的航向。在 Python 中,0 度是东(右)。在 JavaScript 中,0 度是北(向上)。 |
forward(steps) | fd(steps) | 以面对的方向将海龟向前移动一定步数。 |
backward(steps) | bk(steps) | 以面对的相反方向将海龟向后移动一定步数。 |
left(deg) | lt(deg) | 将海龟的航向向左转动。 |
right(deg) | rt(deg) | 将海龟的航向向右转动。 |
penup() | pu() | “提起笔”以使海龟在移动时停止绘制。 |
pendown() | pd() | “放下笔”以使海龟在移动时开始绘制。 |
pensize(size) | thickness(size) | 更改海龟绘制线条的粗细。默认值为1。 |
pencolor(color) | color(color) | 更改海龟绘制线条的颜色。这可以是常见颜色的字符串,如red或white。默认值为black。 |
xcor() | get.x() | 返回海龟当前的 x 坐标。 |
ycor() | get.y() | 返回海龟当前的 y 坐标。 |
heading() | get.heading() | 以 0 到 359 的浮点数返回海龟当前的航向。在 Python 中,0 度是东(右)。在 JavaScript 中,0 度是北(向上)。 |
reset() | reset() | 清除任何绘制的线条,并将海龟移回原始位置和航向。 |
clear() | clean() | 清除任何绘制的线条,但不移动海龟。 |
表 9-2 中列出的函数仅在 Python 的“turtle”模块中可用。
表 9-2:仅 Python 的海龟函数
| Python | 描述 |
|---|---|
begin_fill() | 开始绘制填充形状。此调用之后绘制的线条将指定填充形状的周长。 |
end_fill() | 绘制以调用turtle.begin_fill()开始的填充形状。 |
fillcolor( color ) | 设置用于填充形状的颜色。 |
hideturtle() | 隐藏代表海龟的三角形。 |
showturtle() | 显示代表海龟的三角形。 |
tracer( drawingUpdates , delay ) | 调整绘制速度。将delay设置为0,表示在乌龟绘制每条线后延迟 0 毫秒。传递给drawingUpdates的数字越大,乌龟绘制的速度就越快,因为模块在更新屏幕之前绘制的次数越多。 |
update() | 将任何缓冲线(稍后在本节中解释)绘制到屏幕上。在乌龟完成绘制后调用此函数。 |
setworldcoordinates( llx , lly , urx, ury ) | 重新调整窗口显示坐标平面的哪一部分。前两个参数是窗口左下角的 x、y 坐标。后两个参数是窗口右上角的 x、y 坐标。 |
exitonclick() | 当用户单击任何位置时,暂停程序并关闭窗口。如果在程序的最后没有这个命令,乌龟图形窗口可能会在程序结束时立即关闭。 |
在 Python 的turtle模块中,线条会立即显示在屏幕上。然而,这可能会减慢绘制数千条线的程序。更快的方法是缓冲——即暂时不显示几条线,然后一次性显示它们。
通过调用turtle.tracer(1000, 0),你可以指示turtle模块在程序创建了 1,000 条线之前不显示这些线。在程序完成调用绘制线条的函数后,最后调用turtle.update()来显示剩余的缓冲线。如果你的程序仍然花费太长时间来绘制图像,可以将一个更大的整数,如2000或10000,作为第一个参数传递给turtle.tracer()。
谢尔宾斯基三角形
在纸上绘制的最简单的分形是谢尔宾斯基三角形,它是在第一章介绍的。这个分形是由波兰数学家瓦茨瓦夫·谢尔宾斯基于 1915 年描述的(甚至早于术语分形的出现)。然而,这种图案至少有数百年的历史。
要创建一个谢尔宾斯基三角形,首先绘制一个等边三角形——一个三边长度相等的三角形,就像图 9-3 中左边的那个。然后在第一个三角形内部绘制一个倒置的等边三角形,就像图 9-3 中右边的那个。你将得到一个形状,如果你熟悉塞尔达传说视频游戏,它看起来像三角力量。
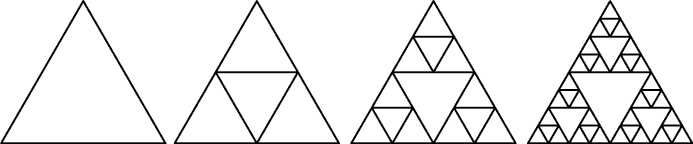
图 9-3:一个等边三角形(左)和一个倒置的三角形相加形成了一个谢尔宾斯基三角形,递归地添加了额外的三角形
当你绘制内部的倒置三角形时,一个有趣的事情发生了。你形成了三个新的正立等边三角形。在这三个三角形的每一个内部,你可以绘制另一个倒置的三角形,这样就会创建出九个三角形。这种递归在数学上可以无限进行,尽管在现实中,你的笔无法不断地绘制更小的三角形。
这种描述一个与自身的一部分相似的完整对象的属性被称为自相似性。递归函数可以产生这些对象,因为它们一遍又一遍地“调用”自己。实际上,这段代码最终必须达到一个基本情况,但在数学上,这些形状具有无限的分辨率:你理论上可以永远放大这个形状。
让我们编写一个递归程序来创建谢尔宾斯基三角形。递归的drawTriangle()函数将绘制一个等边三角形,然后递归调用这个函数三次来绘制内部的等边三角形,就像图 9-4 中那样。midpoint()函数找到距离函数传递的两个点等距离的点。这对于内部三角形使用这些等距离的点作为它们的顶点是很重要的。
图 9-4:三个内部三角形,中点用大点显示
请注意,此程序调用了turtle.setworldcoordinates(0, 0, 700, 700),这使得 0, 0 原点位于窗口的左下角。右上角的 x、y 坐标为 700, 700。sierpinskiTriangle.py的源代码如下:
import turtle
turtle.tracer(100, 0) # Increase the first argument to speed up the drawing.
turtle.setworldcoordinates(0, 0, 700, 700)
turtle.hideturtle()
MIN_SIZE = 4 # Try changing this to decrease/increase the amount of recursion.
def midpoint(startx, starty, endx, endy):
# Return the x, y coordinate in the middle of the four given parameters.
xDiff = abs(startx - endx)
yDiff = abs(starty - endy)
return (min(startx, endx) + (xDiff / 2.0), min(starty, endy) + (yDiff / 2.0))
def isTooSmall(ax, ay, bx, by, cx, cy):
# Determine if the triangle is too small to draw.
width = max(ax, bx, cx) - min(ax, bx, cx)
height = max(ay, by, cy) - min(ay, by, cy)
return width < MIN_SIZE or height < MIN_SIZE
def drawTriangle(ax, ay, bx, by, cx, cy):
if isTooSmall(ax, ay, bx, by, cx, cy):
# BASE CASE
return
else:
# RECURSIVE CASE
# Draw the triangle.
turtle.penup()
turtle.goto(ax, ay)
turtle.pendown()
turtle.goto(bx, by)
turtle.goto(cx, cy)
turtle.goto(ax, ay)
turtle.penup()
# Calculate midpoints between points A, B, and C.
mid_ab = midpoint(ax, ay, bx, by)
mid_bc = midpoint(bx, by, cx, cy)
mid_ca = midpoint(cx, cy, ax, ay)
# Draw the three inner triangles.
drawTriangle(ax, ay, mid_ab[0], mid_ab[1], mid_ca[0], mid_ca[1])
drawTriangle(mid_ab[0], mid_ab[1], bx, by, mid_bc[0], mid_bc[1])
drawTriangle(mid_ca[0], mid_ca[1], mid_bc[0], mid_bc[1], cx, cy)
return
# Draw an equilateral Sierpinski triangle.
drawTriangle(50, 50, 350, 650, 650, 50)
# Draw a skewed Sierpinski triangle.
#drawTriangle(30, 250, 680, 600, 500, 80)
turtle.exitonclick()
当你运行这段代码时,输出看起来像图 9-5。

图 9-5:标准谢尔宾斯基三角形
谢尔宾斯基三角形不一定要用等边三角形来绘制。只要使用外部三角形的中点来绘制内部三角形,你可以使用任何类型的三角形。注释掉第一个drawTriangle()调用,并取消注释第二个(在# Draw a skewed Sierpinski triangle.注释下面),然后再次运行程序。输出将看起来像图 9-6。

图 9-6:一个倾斜的谢尔宾斯基三角形
drawTriangle()函数接受六个参数,对应于三角形的三个点的 x、y 坐标。尝试尝试不同的值来调整谢尔宾斯基三角形的形状。你也可以将MIN_SIZE常量更改为较大的值,以使程序更快地达到基本情况,并减少绘制的三角形数量。
谢尔宾斯基地毯
一个类似于谢尔宾斯基三角形的分形形状可以使用矩形来绘制。这种模式被称为Sierpiński carpet。想象将一个黑色矩形分成 3×3 的网格,然后“切除”中心矩形。在网格的周围八个矩形中重复这种模式。当这样递归地完成时,你会得到一个像图 9-7 的图案。

图 9-7:谢尔宾斯基地毯
绘制地毯的 Python 程序使用turtle.begin_fill()和turtle.end_fill()函数来创建实心的填充形状。乌龟在这些调用之间绘制的线用于绘制形状,就像图 9-8 中那样。

图 9-8:调用turtle.begin_fill(),绘制路径,然后调用turtle.end_fill()创建填充形状。
当 3×3 的矩形变得小于一边的六个步骤时,基本情况就会到达。你可以将MIN_SIZE常量更改为较大的值,以使程序更快地达到基本情况。sierpinskiCarpet.py的源代码如下:
import turtle
turtle.tracer(10, 0) # Increase the first argument to speed up the drawing.
turtle.setworldcoordinates(0, 0, 700, 700)
turtle.hideturtle()
MIN_SIZE = 6 # Try changing this to decrease/increase the amount of recursion.
DRAW_SOLID = True
def isTooSmall(width, height):
# Determine if the rectangle is too small to draw.
return width < MIN_SIZE or height < MIN_SIZE
def drawCarpet(x, y, width, height):
# The x and y are the lower-left corner of the carpet.
# Move the pen into position.
turtle.penup()
turtle.goto(x, y)
# Draw the outer rectangle.
turtle.pendown()
if DRAW_SOLID:
turtle.fillcolor('black')
turtle.begin_fill()
turtle.goto(x, y + height)
turtle.goto(x + width, y + height)
turtle.goto(x + width, y)
turtle.goto(x, y)
if DRAW_SOLID:
turtle.end_fill()
turtle.penup()
# Draw the inner rectangles.
drawInnerRectangle(x, y, width, height)
def drawInnerRectangle(x, y, width, height):
if isTooSmall(width, height):
# BASE CASE
return
else:
# RECURSIVE CASE
oneThirdWidth = width / 3
oneThirdHeight = height / 3
twoThirdsWidth = 2 * (width / 3)
twoThirdsHeight = 2 * (height / 3)
# Move into position.
turtle.penup()
turtle.goto(x + oneThirdWidth, y + oneThirdHeight)
# Draw the inner rectangle.
if DRAW_SOLID:
turtle.fillcolor('white')
turtle.begin_fill()
turtle.pendown()
turtle.goto(x + oneThirdWidth, y + twoThirdsHeight)
turtle.goto(x + twoThirdsWidth, y + twoThirdsHeight)
turtle.goto(x + twoThirdsWidth, y + oneThirdHeight)
turtle.goto(x + oneThirdWidth, y + oneThirdHeight)
turtle.penup()
if DRAW_SOLID:
turtle.end_fill()
# Draw the inner rectangles across the top.
drawInnerRectangle(x, y + twoThirdsHeight, oneThirdWidth, oneThirdHeight)
drawInnerRectangle(x + oneThirdWidth, y + twoThirdsHeight, oneThirdWidth, oneThirdHeight)
drawInnerRectangle(x + twoThirdsWidth, y + twoThirdsHeight, oneThirdWidth, oneThirdHeight)
# Draw the inner rectangles across the middle.
drawInnerRectangle(x, y + oneThirdHeight, oneThirdWidth,
oneThirdHeight)
drawInnerRectangle(x + twoThirdsWidth, y + oneThirdHeight, oneThirdWidth,
oneThirdHeight)
# Draw the inner rectangles across the bottom.
drawInnerRectangle(x, y, oneThirdWidth, oneThirdHeight)
drawInnerRectangle(x + oneThirdWidth, y, oneThirdWidth, oneThirdHeight)
drawInnerRectangle(x + twoThirdsWidth, y, oneThirdWidth,
oneThirdHeight)
drawCarpet(50, 50, 600, 600)
turtle.exitonclick()
您还可以将DRAW_SOLID常量设置为False并运行程序。这将跳过对turtle.begin_fill()和turtle.end_fill()的调用,以便只绘制矩形的轮廓,如图 9-9 所示。
尝试将不同的参数传递给drawCarpet()。前两个参数是地毯左下角的 x、y 坐标,而后两个参数是宽度和高度。您还可以将MIN_SIZE常量更改为较大的值,以使程序更快地达到基本情况,并减少绘制的矩形数量。
图 9-9:Sierpiński 地毯,只绘制了矩形的轮廓
另一个 3D Sierpiński 地毯使用立方体而不是正方形。在这种形式中,它被称为Sierpiński 立方体或Menger 海绵。它最早由数学家卡尔·门格在 1926 年描述。图 9-10 显示了在视频游戏Minecraft中创建的 Menger 海绵。

图 9-10:3D Menger 海绵分形
分形树
虽然 Sierpiński 三角形和地毯等人造分形是完全自相似的,但分形可以包括没有完美自相似性的形状。数学家 Benoit B. Mandelbrot(他的中间名字母递归地代表 Benoit B. Mandelbrot)构想的分形几何包括自然形状,如山脉、海岸线、植物、血管和星系的聚类。仔细观察,这些形状继续由简化几何的光滑曲线和直线难以包容的“粗糙”形状组成。
例如,我们可以使用递归来复制分形树,无论是完全还是不完全自相似。生成树需要创建一个具有两个子分支的分支,这些分支从父分支发出,角度和长度减小。它们产生的 Y 形状被递归重复,以创建一棵树的逼真图像,如图 9-11 和 9-12 所示。

图 9-11:使用一致的角度和长度生成的完全自相似的分形树
电影和视频游戏可以在程序生成中使用这种递归算法,自动(而不是手动)创建树、蕨类植物、花朵和其他植物等 3D 模型。使用算法,计算机可以快速创建由数百万棵独特树组成的整个森林,节省了大量人类 3D 艺术家的辛苦努力。

图 9-12:使用随机改变分支角度和长度创建的更真实的树
我们的分形树程序每两秒显示一个新的随机生成的树。fractalTree.py的源代码如下:
Python
import random
import time
import turtle
turtle.tracer(1000, 0) # Increase the first argument to speed up the drawing.
turtle.setworldcoordinates(0, 0, 700, 700)
turtle.hideturtle()
def drawBranch(startPosition, direction, branchLength):
if branchLength < 5:
# BASE CASE
return
# Go to the starting point & direction.
turtle.penup()
turtle.goto(startPosition)
turtle.setheading(direction)
# Draw the branch (thickness is 1/7 the length).
turtle.pendown()
turtle.pensize(max(branchLength / 7.0, 1))
turtle.forward(branchLength)
# Record the position of the branch's end.
endPosition = turtle.position()
leftDirection = direction + LEFT_ANGLE
leftBranchLength = branchLength - LEFT_DECREASE
rightDirection = direction - RIGHT_ANGLE
rightBranchLength = branchLength - RIGHT_DECREASE
# RECURSIVE CASE
drawBranch(endPosition, leftDirection, leftBranchLength)
drawBranch(endPosition, rightDirection, rightBranchLength)
seed = 0
while True:
# Get pseudorandom numbers for the branch properties.
random.seed(seed)
LEFT_ANGLE = random.randint(10, 30)
LEFT_DECREASE = random.randint( 8, 15)
RIGHT_ANGLE = random.randint(10, 30)
RIGHT_DECREASE = random.randint( 8, 15)
START_LENGTH = random.randint(80, 120)
# Write out the seed number.
turtle.clear()
turtle.penup()
turtle.goto(10, 10)
turtle.write('Seed: %s' % (seed))
# Draw the tree.
drawBranch((350, 10), 90, START_LENGTH)
turtle.update()
time.sleep(2)
seed = seed + 1
这个程序产生完全自相似的树,因为LEFT_ANGLE、LEFT_DECREASE、RIGHT_ANGLE和RIGHT_DECREASE变量最初是随机选择的,但对所有递归调用保持不变。random.seed()函数为 Python 的随机函数设置一个种子值。随机数种子值使程序产生看似随机的数字,但对树的每个分支使用相同的随机数序列。换句话说,相同的种子值每次运行程序都会产生相同的树。(我从不为我说的双关语道歉。)
要看到这个过程,输入以下内容到 Python 交互式 shell 中:
Python
>>> import random
>>> random.seed(42)
>>> [random.randint(0, 9) for i in range(20)]
[1, 0, 4, 3, 3, 2, 1, 8, 1, 9, 6, 0, 0, 1, 3, 3, 8, 9, 0, 8]
>>> [random.randint(0, 9) for i in range(20)]
[3, 8, 6, 3, 7, 9, 4, 0, 2, 6, 5, 4, 2, 3, 5, 1, 1, 6, 1, 5]
>>> random.seed(42)
>>> [random.randint(0, 9) for i in range(20)]
[1, 0, 4, 3, 3, 2, 1, 8, 1, 9, 6, 0, 0, 1, 3, 3, 8, 9, 0, 8]
在这个例子中,我们将随机种子设置为 42。当我们生成 20 个随机整数时,我们得到1、0、4、3等。我们可以生成另外 20 个整数,并继续接收随机整数。然而,如果我们将种子重置为42,再次生成 20 个随机整数,它们将与之前的相同的“随机”整数。
如果你想创建一个更自然、不那么自相似的树,用以下行替换#记录分支末端的位置。注释后的行。这会为每个递归调用生成新的随机角度和分支长度,更接近树在自然界中生长的方式:
Python
# Record the position of the branch's end.
endPosition = turtle.position()
leftDirection = direction + random.randint(10, 30)
leftBranchLength = branchLength - random.randint(8, 15)
rightDirection = direction - random.randint(10, 30)
rightBranchLength = branchLength - random.randint(8, 15)
你可以尝试不同范围的random.randint()调用,或者尝试添加更多的递归调用,而不仅仅是两个分支。
英国海岸线有多长?科赫曲线和雪花
在我告诉你关于科赫曲线和雪花之前,考虑这个问题:英国的海岸线有多长?看一下图 9-13。左边的地图有一个粗略的测量,将海岸线长度约为 2000 英里。但右边的地图有一个更精确的测量,包括了更多海岸的角落,长度约为 2800 英里。
图 9-13:大不列颠岛,粗略测量(左)和更精确测量(右)。更精确地测量海岸线长度增加了 800 英里。
曼德布罗特关于英国海岸线等分形的关键见解是,你可以继续越来越近地观察,每个尺度上都会有“粗糙”。因此,随着你的测量变得越来越精细,海岸线的长度也会变得越来越长。这条“海岸线”将沿着泰晤士河上游,深入陆地沿着一岸,然后回到英吉利海峡的另一岸。因此,对于我们关于大不列颠海岸线长度的问题的答案是,“这取决于。”
Koch 曲线分形具有与其海岸线长度或周长相关的类似特性。Koch 曲线最早由瑞典数学家赫尔格·冯·科赫于 1902 年提出,是最早被数学描述的分形之一。要构造它,取长度为b的线段并将其分成三等分,每部分长度为b/3。用长度也为b/3 的“凸起”替换中间部分。这个凸起使得 Koch 曲线比原始线段更长,因为现在我们有四条长度为b/3 的线段。(我们将排除原始线段的中间部分。)这个凸起的创建可以在新的四条线段上重复。图 9-14 展示了这个构造过程。

图 9-14:将线段分成三等分(左),在中间部分添加一个凸起(右)。现在我们有长度为b/3 的四段线段,可以再次添加凸起(底部)。
要创建科赫雪花,我们从一个等边三角形开始,并从其三边构造三个科赫曲线,如图 9-15 所示。

图 9-15:在等边三角形的三边上创建三个科赫曲线,形成科赫雪花
每次创建一个新的凸起,都会将曲线的长度从三个b/3 长度增加到四个b/3 长度,或 4b/3。如果你继续在等边三角形的三边上这样做,你将创建科赫雪花,就像图 9-16 中所示的那样。(小点状图案是因为轻微的舍入误差导致turtle模块无法完全擦除中间的b/3 段。)你可以继续永远创建新的凸起,尽管我们的程序在它们变得小于几个像素时停止。
图 9-16:科赫雪花。由于小的舍入误差,一些内部线条仍然存在。
kochSnowflake.py的源代码如下:
Python
import turtle
turtle.tracer(10, 0) # Increase the first argument to speed up the drawing.
turtle.setworldcoordinates(0, 0, 700, 700)
turtle.hideturtle()
turtle.pensize(2)
def drawKochCurve(startPosition, heading, length):
if length < 1:
# BASE CASE
return
else:
# RECURSIVE CASE
# Move to the start position.
recursiveArgs = []
turtle.penup()
turtle.goto(startPosition)
turtle.setheading(heading)
recursiveArgs.append({'position':turtle.position(),
'heading':turtle.heading()})
# Erase the middle third.
turtle.forward(length / 3)
turtle.pencolor('white')
turtle.pendown()
turtle.forward(length / 3)
# Draw the bump.
turtle.backward(length / 3)
turtle.left(60)
recursiveArgs.append({'position':turtle.position(),
'heading':turtle.heading()})
turtle.pencolor('black')
turtle.forward(length / 3)
turtle.right(120)
recursiveArgs.append({'position':turtle.position(),
'heading':turtle.heading()})
turtle.forward(length / 3)
turtle.left(60)
recursiveArgs.append({'position':turtle.position(),
'heading':turtle.heading()})
for i in range(4):
drawKochCurve(recursiveArgs[i]['position'],
recursiveArgs[i]['heading'],
length / 3)
return
def drawKochSnowflake(startPosition, heading, length):
# A Koch snowflake is three Koch curves in a triangle.
# Move to the starting position.
turtle.penup()
turtle.goto(startPosition)
turtle.setheading(heading)
for i in range(3):
# Record the starting position and heading.
curveStartingPosition = turtle.position()
curveStartingHeading = turtle.heading()
drawKochCurve(curveStartingPosition,
curveStartingHeading, length)
# Move back to the start position for this side.
turtle.penup()
turtle.goto(curveStartingPosition)
turtle.setheading(curveStartingHeading)
# Move to the start position of the next side.
turtle.forward(length)
turtle.right(120)
drawKochSnowflake((100, 500), 0, 500)
turtle.exitonclick()
科赫雪花有时也被称为科赫岛。它的海岸线将是无限长的。虽然科赫雪花可以放入本书一页的有限区域,但其周长的长度是无限的,证明了,尽管看起来违反直觉,有限可以包含无限!
希尔伯特曲线
填充曲线是一条 1D 曲线,它弯曲直到完全填满 2D 空间而不交叉。德国数学家大卫·希尔伯特于 1891 年描述了他的填充曲线。如果你将一个 2D 区域分成一个网格,希尔伯特曲线的单一 1D 线可以穿过网格中的每个单元格。
图 9-17 包含希尔伯特曲线的前三次递归。下一次递归包含前一次递归的四个副本,虚线显示了这四个副本如何连接在一起。

图 9-17:希尔伯特填充曲线的前三次递归
当单元格变成无穷小点时,1D 曲线可以像 2D 正方形一样填满整个 2D 空间。令人费解的是,这样可以从严格的 1D 线创建一个 2D 形状!
hilbertCurve.py的源代码如下:
Python
import turtle
turtle.tracer(10, 0) # Increase the first argument to speed up the drawing.
turtle.setworldcoordinates(0, 0, 700, 700)
turtle.hideturtle()
LINE_LENGTH = 5 # Try changing the line length by a little.
ANGLE = 90 # Try changing the turning angle by a few degrees.
LEVELS = 6 # Try changing the recursive level by a little.
DRAW_SOLID = False
#turtle.setheading(20) # Uncomment this line to draw the curve at an angle.
def hilbertCurveQuadrant(level, angle):
if level == 0:
# BASE CASE
return
else:
# RECURSIVE CASE
turtle.right(angle)
hilbertCurveQuadrant(level - 1, -angle)
turtle.forward(LINE_LENGTH)
turtle.left(angle)
hilbertCurveQuadrant(level - 1, angle)
turtle.forward(LINE_LENGTH)
hilbertCurveQuadrant(level - 1, angle)
turtle.left(angle)
turtle.forward(LINE_LENGTH)
hilbertCurveQuadrant(level - 1, -angle)
turtle.right(angle)
return
def hilbertCurve(startingPosition):
# Move to starting position.
turtle.penup()
turtle.goto(startingPosition)
turtle.pendown()
if DRAW_SOLID:
turtle.begin_fill()
hilbertCurveQuadrant(LEVELS, ANGLE) # Draw lower-left quadrant.
turtle.forward(LINE_LENGTH)
hilbertCurveQuadrant(LEVELS, ANGLE) # Draw lower-right quadrant.
turtle.left(ANGLE)
turtle.forward(LINE_LENGTH)
turtle.left(ANGLE)
hilbertCurveQuadrant(LEVELS, ANGLE) # Draw upper-right quadrant.
turtle.forward(LINE_LENGTH)
hilbertCurveQuadrant(LEVELS, ANGLE) # Draw upper-left quadrant.
turtle.left(ANGLE)
turtle.forward(LINE_LENGTH)
turtle.left(ANGLE)
if DRAW_SOLID:
turtle.end_fill()
hilbertCurve((30, 350))
turtle.exitonclick()
尝试通过减小LINE_LENGTH来缩短线段的长度,同时增加LEVELS来增加递归的层次。因为这个程序只使用海龟的相对移动,你可以取消注释turtle.setheading(20)这一行来以 20 度角绘制希尔伯特曲线。图 9-18 显示了使用LINE_LENGTH为10和LEVELS为5时产生的绘图。

图 9-18:希尔伯特曲线的五个级别,线长为10
希尔伯特曲线进行 90 度(直角)转弯。但尝试将ANGLE变量调整几度至89或86,并运行程序查看变化。您还可以将DRAW_SOLID变量设置为True,以生成填充的希尔伯特曲线,如图 9-19。

图 9-19:填充的希尔伯特曲线的六个级别,线长为5
总结
分形的广阔领域结合了编程和艺术的最有趣的部分,使得这一章节成为最有趣的写作。数学家和计算机科学家谈论他们领域的高级主题产生的美丽和优雅,但递归分形能够将这种概念上的美丽转化为任何人都能欣赏的视觉美。
本章介绍了几种分形和绘制它们的程序:谢尔宾斯基三角形、谢尔宾斯基地毯、程序生成的分形树、科赫曲线和雪花、以及希尔伯特曲线。所有这些都是使用 Python 的turtle模块和递归调用自身的函数绘制的。
进一步阅读
要了解更多关于使用 Python 的turtle模块绘图的知识,我在github.com/asweigart/simple-turtle-tutorial-for-python写了一个简单的教程。我还在github.com/asweigart/art-of-turtle-programming上有一个个人的乌龟程序集合。
关于英国海岸线长度的问题来自曼德布罗特在 1967 年的一篇论文的标题。这个想法在维基百科上有很好的总结。可汗学院有更多关于科赫雪花几何的内容。
3Blue1Brown YouTube 频道有关分形的出色动画,特别是“分形通常不是自相似”的视频和“分形魅力:填充曲线”视频。
其他填充曲线需要递归来绘制,例如皮亚诺曲线、戈斯珀曲线和龙曲线,值得在网上进行研究。
练习问题
通过回答以下问题来测试您的理解:
-
什么是分形?
-
笛卡尔坐标系中的 x 和 y 坐标代表什么?
-
笛卡尔坐标系中的原点坐标是什么?
-
什么是程序生成?
-
什么是种子值?
-
科赫雪花的周长有多长?
-
什么是填充曲线?
练习项目
为了练习,为以下每个任务编写一个程序:
- 创建一个乌龟程序,绘制如图 9-20 所示的盒子分形。这个程序类似于本章介绍的谢尔宾斯基地毯程序。使用
turtle.begin_fill()和turtle.end_fill()函数来绘制第一个大的黑色正方形。然后将这个正方形分成九个相等的部分,在顶部、左侧、右侧和底部的正方形中绘制白色正方形。对四个角落的正方形和中心正方形重复这个过程。
图 9-20:一个绘制了两层的盒子分形
- 创建一个乌龟程序,绘制 Peano 填充曲线。这类似于本章中的希尔伯特曲线程序。图 9-21 显示了 Peano 曲线的前三次迭代。虽然每个希尔伯特曲线迭代被分割成 2×2 的部分(依次分割成 2×2 的部分),Peano 曲线被分割成 3×3 的部分。

图 9-21:Peano 曲线的前三次迭代,从左到右。底部一行包括每个曲线部分分割的 3×3 部分。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TCP/IP详解——IP协议,IP选路
- 白码ERP快速实现库存不足时自动生成采购单功能
- springboot 项目访问静态资源遇到的问题,WebMvcConfigurer和WebMvcConfigurationSupport
- 存储:双磁盘RAID0磁盘阵列搭建
- Latex宏包gbt7714的格式问题:去掉OL
- 如何用电源模块综合测试系统测试逆变器电源输出电压?
- 转换操作符转换类型:普通函数指针(普通函数、类的静态函数)、类的成员函数指针
- MySQL深度分页优化问题
- 【PHP】函数strpos():判断一个字符串是否包含另一个字符串
- Docker实战05|Docker构建流程分析