垂直领域大模型的应用更亲民
在之前的文章有介绍过: 普通人(包括程序员)怎么follow大模型的发展和如何成为提示词工程师.通用大模型类似ChatGPT等,一般公司和程序员是无法超越。所以今天介绍一下大模型垂直领域的应用的做法.
1、通用大模型离我们有点距离
(1)、训练成本贵
国内证劵公司训练大模型花费的钱做过测算。起码100万美金以上,这对一些小型企业是没办法承担的。
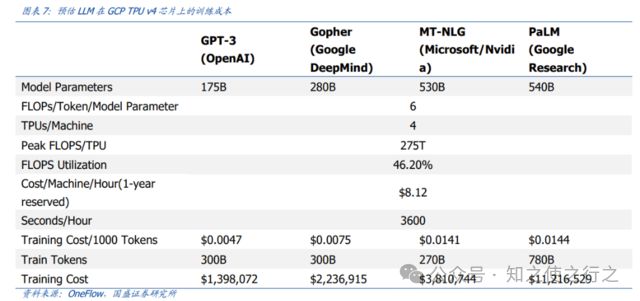
(2)、技术积累时间长
冰冻三尺,非一日之寒,openai的成功并非偶然, ,而是背后无数的努力堆砌而成。
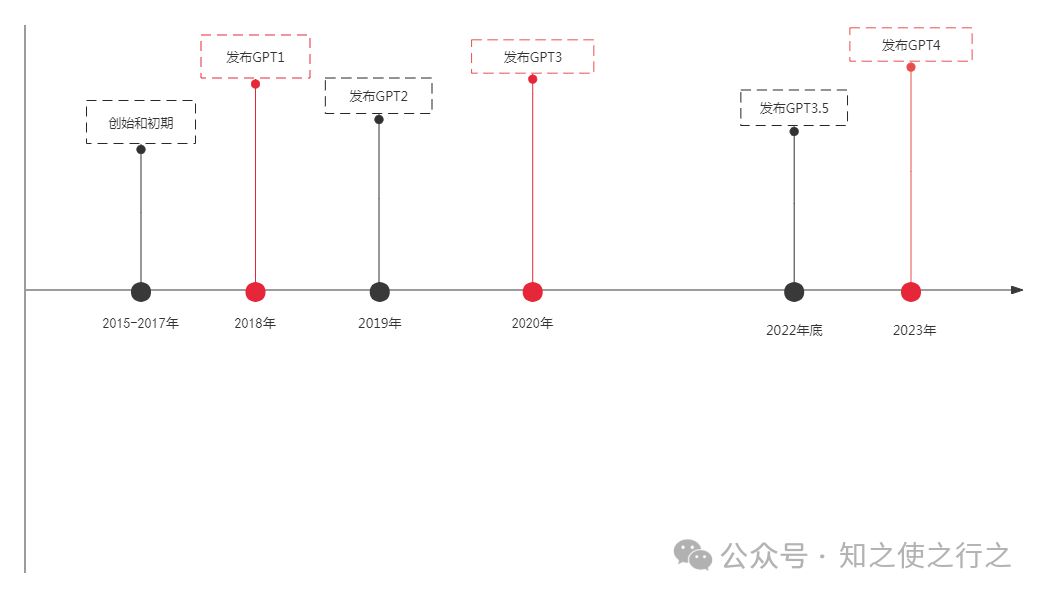
(3)、东施效颦
并不是每块落石,都能激起水花朵。失败是常态。chatgpt的成功是属于幸存者偏差,它的成功,不一定代表所有人都能成功,即使成功也不一定超越过。
(4)、通用模型在生产效率上有受限

虽然2023年以来几乎很多公司都发出了自己的通用大模型,但是都还停留在“开放闲聊”阶段,这种泛娱乐的方式带来生产率是有限的。所以,以“开放闲聊”为产品形态的ChatGPT为例,“尝鲜“的流量在6月达到巅峰之后,就开始了出现下滑。
2、国内垂直领域应用和发展现状
人们需要的是能帮助我们实实在在地解决问题,能提高生产力和工作效率的工具。
下面的垂直领域应用的模型,基本上覆盖我们生活的方方面面:

当然不止上面所列的应用.更多请关注我
3、一般垂直大模型怎么做

Continue PreTraining: 一般垂直大模型是基于通用大模型进行二次的开发。为了给模型注入领域知识,就需要用领域内的语料进行继续的预训练。
SFT: 通过SFT可以激发大模型理解领域内的各种问题并进行回答的能力(在有召回知识的基础上)。
RLHF: 通过RLHF可以让大模型的回答对齐人们的偏好,比如行文的风格。
4、总结
一般垂直领域大模型不会直接让模型生成答案,而是跟先检索相关的知识,然后基于召回的知识进行回答。这种方式能减少模型的幻觉,保证答案的时效性,还能快速干预模型对特定问题的答案。
参考文章
https://blog.nghuyong.top/2023/08/26/NLP/llm-domain-specific/
https://github.com/hiyouga/LLaMA-Factory
https://github.com/HqWu-HITCS/Awesome-Chinese-LLM
https://github.com/liguodongiot/llm-action
https://writerbuddy.ai/blog/ai-industry-analysis
https://zhuanlan.zhihu.com/p/613665464
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何手动升级Chrome插件/Chrome扩展程序?
- 机器学习 --- Adaboost
- Consul使用详解
- 【ubuntu 22.04】安装中文版系统、中文语言包和中文输入法
- ubuntu 20.04 docker及nvidia-docker2安装
- flutter学习-day23-使用extended_image处理图片的加载和操作
- 基于SpringBoot+Vue的图书个性化推荐系统
- 【计算机网络】第四章摘要重点
- C# String 类在开发中常用到的方法汇总【详细版】
- 2024.1.14 总结一下:工作三年了