大厂大数据面试题收录(1)
目录
3.为什么要重写 equals 和 hashcode()方法?
5.kafka 组件熟悉吗,kafka 如何实现消息的有序的?
8.Hive sql 到 MapReduce 转化的流程清楚吗?
9.你说一下 Flink checkpoint、state 的底层逻辑?
10.如果 checkpoint 设置 10s 一次,状态存储到 HDFS 中,会出现什么问题?
13.模型推理过程中要是单个模型过大,如何发送到 kafka?
1.java 中 object 类有哪些方法?
Object 是所有类的父类,任何类都默认继承 Object,主要包含 9 个方法:
1. clone 方法
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
2. getClass 方法
final 方法,获得运行时类型。
3. toString 方法
该方法用得比较多,一般子类都有覆盖。
4. finalize 方法
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
5. equals 方法
该方法是非常重要的一个方法。一般 equals 和 == 是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。
6. hashCode 方法
该方法用于哈希查找,重写了 equals 方法一般都要重写 hashCode 方法。这个方法在一些具有哈希功能的 Collection 中用到。
7. wait 方法
用于让当前线程失去操作权限,当前线程进入等待序列
8. notify 方法
唤醒在此对象监视器上等待的单个线程。
2.说一下==和equals的区别?
对于基本类型来说是?值比较,对于引用类型来说是比较的是引用;equals 默认情况下是引用比较,只是很多类重写了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下?equals 比较的是值是否相等
3.为什么要重写 equals 和 hashcode()方法?
首先:两个对象相同(即用 equals 比较返回 true),那么它们的 hashCode 值一定相同;
String?str1?=?"通话";
String?str2?=?"通话";
System.out.println(String.format("str1:%d | str2:%d",??str1.hashCode(),str2.hashCode()));
System.out.println(str1.equals(str2));
............ 结果如下:........
str1:1179395 | str2:1179395
true
但是:两个对象的 hashCode 相同,这两个对象并不一定相同(即用 equals 比较返回 false)
String?str1?=?"通话";
String?str2?=?"重地";
System.out.println(String.format("str1:%d | str2:%d",??str1.hashCode(),str2.hashCode()));
System.out.println(str1.equals(str2));
............ 结果如下:........
str1:1179395 | str2:1179395
false
所以,为了避免代码出错,需要重写 equals 和 hashcode 方法。
4.机器学习中,监督学习 和 无监督学习的区别是啥??
机器学习主要分为:监督学习(Supervised Learn)和无监督学习(Unspervised Learn)。
(1)监督学习简单理解就是:我们将教计算机如何去完成任务。
监督学习对未知事物的预测,一般分为两类问题:
回归问题:预测连续值输出,如房屋预测。
分类问题:预测离散值输出,如乳腺癌预测。
监督学习都带有标签。即数据集给出正确答案(有标签,有y值)。
(2)无监督学习简单理解就是,我们打算让计算机自己进行学习。
无监督学习的特点是:没有任何的标签。
训练样本不含有标记(label)信息,既没有类别信息,也不会给定目标值。(没有属性或标签,不知道正确的答案)。
5.kafka 组件熟悉吗,kafka 如何实现消息的有序的?
生产者:通过分区的 leader 副本负责数据以先进先出的顺序写入,来保证消息顺序性。
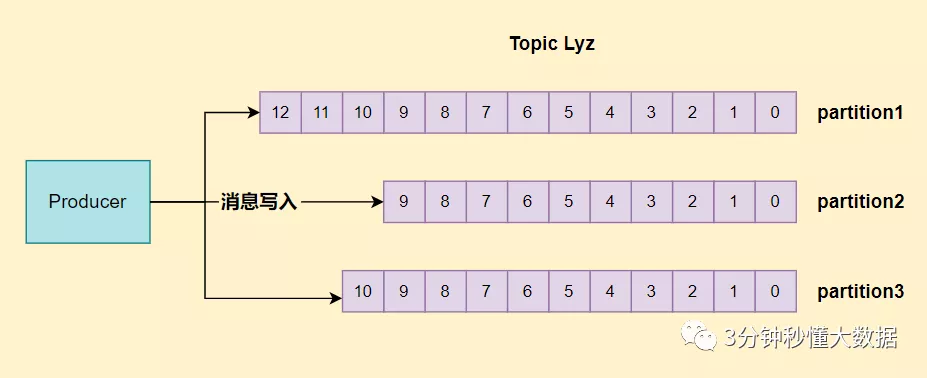
消费者:同一个分区内的消息只能被一个 group 里的一个消费者消费,保证分区内消费有序。
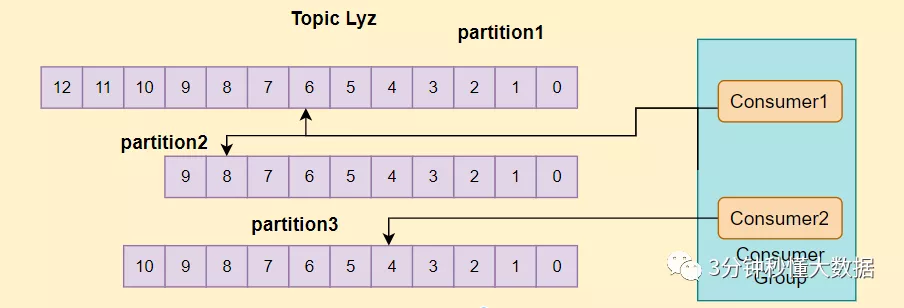
kafka 每个?partition?中的消息在写入时都是有序的,消费时, 每个?partition?只能被每一个消费者组中的一个消费者消费,保证了消费时也是有序的。
整个 kafka 不保证有序。如果为了保证?kafka?全局有序,那么设置一个生产者,一个分区,一个消费者。
6.在大数据组件中,你们一般用的资源管理框架是哪个?
更多的使用 Yarn 作为资源管理工具,现在一大部分业务也上云了,使用的 K8S。
7.那你能谈一下 yarn 的基础架构及调度流程吗?
yarn 的基础架构主要包含 3 大组件,分别为 ResourceManager、ApplicationMaster、NodeManager.
其中:
ResourceManager?是一个全局的资源管理器,负责整个系统的资源管理和分配,主要包括两个组件,即调度器(Scheduler)和应用程序管理器(Applications Manager)。
ApplicationMaster:ApplicationMaster 是 Resource Manager 根据 接收用户提交的作业,按照作业的上下文信息等 分配出一个 container 资源,然后 通知 NodeManager 为用户作业创建出一个 ?ApplicationMaster。
NodeManager:NodeManager 管理 YARN 集群中的每个节点,对节点进行资源监控和健康状态管理。
yarn 的调度流程简单总结如下:
-
客户端提交应用程序给 ResourceManager
-
ResouceManager 收到请求后,将分配 Container 资源,并通知对应的 NodeManager 启动一个 ApplicationMaster。
-
applicationMaster 来运行和管理 container 里面的任务,其中 container 会通过心跳机制向 applicationMaster 来发送运行信息。
-
任务完成之后,application 向 ResourceManager 报告,任务完成,container 进行资源释放。
8.Hive sql 到 MapReduce 转化的流程清楚吗?
Hive 将 SQL 转化为 MapReduce 任务,整个编译过程分为以下几个阶段:
1. sql 解析。HIve 通过 Antlr 对 SQL 进行 词法、语法解析,生成抽象语法树 AST Tree。
2. 语法解析。遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock
3. 生成逻辑执行计划。遍历 QueryBlock,翻译为执行操作树 OperatorTree
4. 优化逻辑执行计划。逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量。
5. 生成物理执行计划。遍历 OperatorTree,翻译为 MapReduce 任务。
6. 优化物理执行计划。物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
9.你说一下 Flink checkpoint、state 的底层逻辑?
先介绍 checkpoint
首先,checkpoint 叫做检查点,是 Flink 实现容错机制的最核心功能,它能根据配置周期性的基于 Stream 中各个 Operator 的状态来生成Snapshot?快照,从而将这些状态数据定期持久化存储下来,当 Flink 程序一旦意外崩溃时,重新运行程序时可以有选择地从这些 Snapshot 进行恢复。
Flink 的 checkpoint 机制原理来自“Chandy-Lamport algorithm”算法
再介绍 state
state 一般指一个具体的 Task/Operator 的状态,主要是用来保存中间的?计算结果?或者?缓存数据。
state 按照 Flink 管理还是用户管理分为:RowState(原始状态)和 Managedstate(托管状态)
-
RowState 由用户自行管理,只支持 字节 数组,所有状态都要转换为二进制字节数组才可以。
-
ManagedState 由 Flink RunTime 管理,支持多种数据结构,如 Map List 等
State 按照 key 划分,可以分为 KeyedState,OperatorState.
keyedState?只能用在 keyStream 上,并且每一个 key 对应一个 state 对象,keyedState 保存在 StateBackend 中,通过 RuntimeContext 访问,实现 Rich Function 接口,支持多种数据结构,如 ListState、MapState、AggregatingState 等
OperatorState ?可以用于所有算子,但整个算子只对应一个?state,实现 CheckpointedFunction 或者 ListCheckpointed 接口,目前只支持 ListState 数据结构。
?
10.如果 checkpoint 设置 10s 一次,状态存储到 HDFS 中,会出现什么问题?
如果每隔 10s 就进行 checkpoint,假如 checkpoint 时,状态过小,而 HDFS 的块大小是以 128 M 进行划分,往 HDFS 中写状态时,不可能每次都把 128M 写满,所以就会出现大量的小文件。
这样会反过来影响 HDFS 读文件的效率,导致读取速度非常慢,加大 yarn 集群的负担,从而拖垮整个集群的效率。
11.Flink on k8s 的设计思路能描述一下吗?
目前将组件进行容器化已经成为当前的一个趋势,将 Flink 集群部署到 K8S 上 可以实现资源的合理利用,同时 k8s 是一个开源的容器集群管理系统,可以实现容器集群的?自动化部署、自动扩缩容、维护?等功能。
而 在 K8s 上部署 Flink 集群,主要包含以下几个步骤:
1 启动集群
-
Flink 客户端使用 Kubectl 或者 K8s 的 Dashboard 提交 Flink 集群的资源描述文件,包含 4-5个 yaml 文件。
-
K8s Master 根据这些资源文件将请求分发给 Slave 节点,创建 Flink Master Deployment、TaskManager Deployment、ConfigMap、SVC 四个角色。同时初始化 Dispatcher 和 KubernetesResourceManager。并通过 K8S 服务对外暴露 Flink Master 端口。
-
Client 用户使用 Flink run 命令,通过指定 Flink Master 的地址,将相应任务提交上来,用户的 Jar 和 JobGrapth 会在 Flink Client 生成,通过 SVC 传给 Dispatcher。
-
Dispatcher 收到 JobGraph 后,会为每个作业启动一个 JobMaster,将 JobGraph 交给 JobMaster 进行调度。
-
JobMaster 会向 KubernetesResourceManager 申请资源,请求 Slot。
-
KubernetesResourceManager 从 K8S 集群分配 TaskManager。每个 TaskManager 都是具有唯一标识的 Pod。KubernetesResourceManager 会为 TaskManager 生成一份新的配置文件,里面有 Flink Master 的 service name 作为地址,保障在 Flink Master failover 后,TaskManager 仍然可以重新连接上。
-
K8S 集群分配一个新的 Pod 后,在上面启动 TaskManager。
-
TaskManager 启动后注册到 SlotManager。
-
SlotManager 向 TaskManager 请求 Slot。
-
TaskManager 提供 Slot 给 JobManager,然后任务被分配到 Slot 上运行。
12.那 Flink on K8S 通信怎么处理?
Flink on K8S 通信 包含 四种通信方式:
1. POD 内部通信。直接通过 localhost 相互访问就可以。
2. 同节点的 POD 之间通信。??通过默认的 docker 网桥互连容器直接通信就可。
3. 不同节点的 POD 之间通信;通过安装 Flannel 组件,pod 的 ip 分配由 flannel 统一分配,通讯过程也是走 flannel 的网桥。
4. 外部网络与 POD 之间通信。使用 Service 服务,通过 lable 关联到后端的 Pod 容器。
Service 分配的 ip 叫 cluster ip,这是一个固定的虚拟 ip,这个 ip 只能在 k8s 集群内部使用,如果 service 需要对外提供,只能使用 Nodeport 方式映射到主机上,使用主机的 ip 和端口对外提供服务。(另外还可以使用 LoadBalance 方式,但这种方式是在 gce 这样的云环境里面使用的 )。
13.模型推理过程中要是单个模型过大,如何发送到 kafka?
在 kafka 中,默认单条消息最大为 1 M,当单条消息长度超过 1 M 时,就会出现发送到 broker 失败,从而导致消息在 producer 的队列中一直累积,直到撑爆生产者的内存。
所以在实际生产环境中,由于我们的单个模型是 5 M 多,所以刚开始出现上述的 发送到 broker 失败问题。
解决办法,只往 kafka 中发送消息体的 ID、 Location、Name,这样 消费者消费数据时,直接根据对应ID、Location 可以消费到模型。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前端笔试题(一)
- 【LeetCode每日一题】2809. 使数组和小于等于 x 的最少时间
- 洛谷 P7995 [USACO21DEC] Walking Home B
- 软件测试面试题:如何测试App性能?
- android常用技术整理
- 【复杂网络分析与可视化】——通过CSV文件导入Gephi进行社交网络可视化
- 复高斯分布的概率密度函数 probability distribution functions (PDFs)
- ARM CCA机密计算架构软件栈简介
- 12-桥接模式(Bridge)
- JMeter使用