Zero-shot RIS SOTA:Text Augmented Spatial-aware Zero-shot Referring Image Segmentation 论文阅读笔记
Zero-shot RIS SOTA:Text Augmented Spatial-aware Zero-shot Referring Image Segmentation 论文阅读笔记
写在前面
??好久没看到有做 Zero-shot RIS 的文章了,看到 arxiv 上面更新了这篇,特意拿出来学习一下。
- 论文地址:Zero-shot RIS SOTA:Text Augmented Spatial-aware Zero-shot Referring Image Segmentation
- 代码地址:原文未提供
- 预计投稿于:AAAI 等顶会
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 6 千粉丝有你的参与呦~
一、Abstract
??本文研究 zero-shot 指代图像分割,旨在没有训练标注的情况下,识别出与指代表达式最相关的目标。之前的方法利用预训练的模型,例如 CLIP,来对齐实例级别的 masks。然而 CLIP 仅考虑了图文对间的全局水平上的对齐,忽视了细粒度的匹配。于是本文引入 Text Augmented Spatial-aware (TAS) zero-shot 指代图像分割框架,无须训练且对任意的视觉编码器鲁棒。TAS 整合了一个 mask proposal 网络用于实例级别的 mask 提取,一个文本增强的视觉-文本匹配得分用于挖掘图文间的关联,一个空间校正器用于 mask 后处理。除了常规的视觉-文本匹配得分外,增强文本的匹配得分包含了 P-score 和 N-score。P-score 通过一个字幕模型弥补视觉-文本鸿沟;N-score 通过负短语挖掘,实现区域-文本对的细粒度对齐。大量实验表明方法的效果很好。

二、引言
??首先介绍下 referring expression segmentation 指代表达分割的定义,应用,手工标注的不易。于是本文研究 zero-shot 指代图像分割来减少成本。接下来是一些方法的介绍,主要是指出直接应用 CLIP 效果不太好。
??于是本文引入文本增强的空间感知 Text Augmented Spatial-aware (TAS) zero-shot 用于指代表达式图像分割框架,由一个 mask proposal 网络,文本增强视觉-文本匹配得分,空间校正器组成。其中文本增强视觉-文本匹配得分由三个得分模块组合得到:第一个得分称之为 V-score,用于衡量 masked 图像和指代表达式间的相似度;第二个得分称之为 P-score,通过迁移 masked inage 到文本内,弥补文本-视觉鸿沟。具体来说,为每个 masked 图像生成一条字幕,接下来计算该字幕与指代表达式的相似性;第三个得分称之为 N-score,计算 masked 图像负表达式的余弦相似度。其中负表达式是在输入图像中的字幕中,挖掘那些名词短语得到。最后对上述三个得分进行线性组合,选择出与指代表达式最相关的 mask。另外由于 CLIP 很难理解方向的描述词,于是提出一种空间校正器作为一个后处理模块。
??在不修改 CLIP 结构或者微调的情况下,本文的方法使用文本增强的方式进行 CLIP 预测,提高了 zero-shot RES 的性能,实验效果很好。
三、相关工作
3.1 Zero-shot 分割
??介绍一些方法,包括 CLIP、ALIGN、ALBEF、Segment Anything Model (SAM)。
3.2 Referring Image Segmentation
??介绍下 Referring Image Segmentation (RIS) 的定义。一些监督方法需要像素级别的标注,但是标注成本很高。最近提出的一些弱监督分割工作仅基于图像文本对数据,另外一些工作进一步利用 CLIP 直接检索出 mask,而无需任何的训练过程。
3.3 Image Captioning
??介绍下 Image Captioning 的定义,但是需要大量的数据。最近的一些大预言模型丰富了生成的文本字幕的多样性。本文采用广泛使用的图像字幕网络 BLIP-2。
四、方法
4.1 总体框架
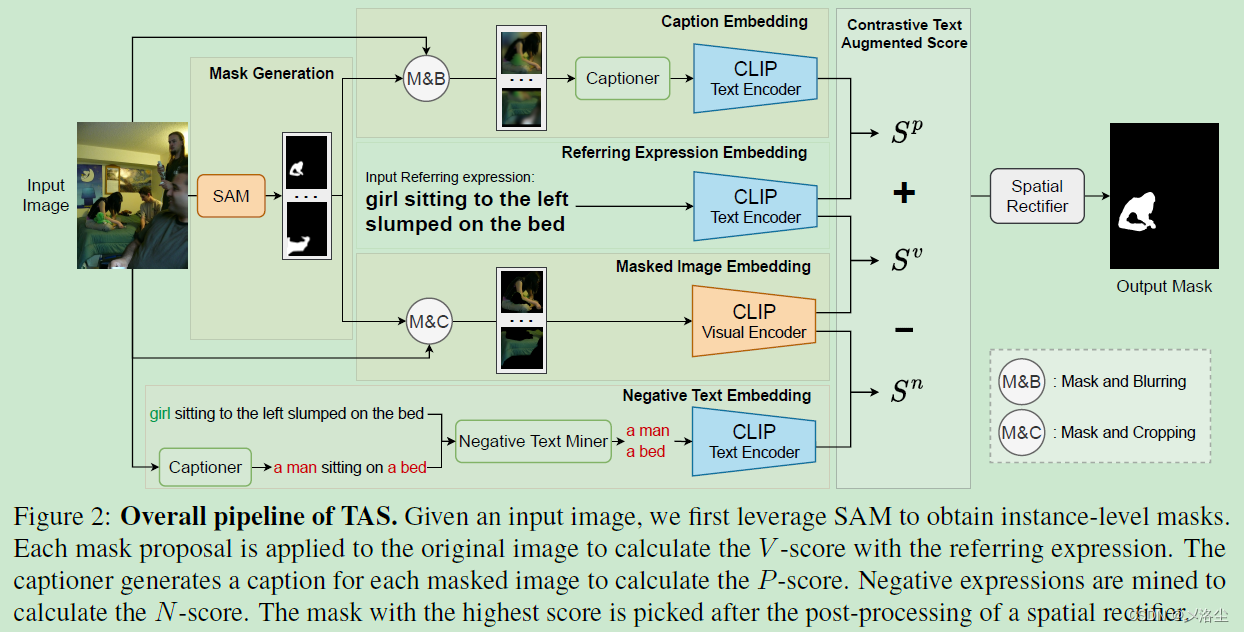
??提出的 Text Augmented Spatial-aware (TAS) 由三个部件组成:mask proposal 网络、文本增强的视觉-文本匹配得分 text-augmented visual-text matching score、空间校正器。Mask proposal 网络首先提取实例级别的 mask proposals。然后计算所有 masked 图像与指代表达式的匹配得分,用于衡量 masks 和文本的相似度。最后通过校正器的后处理,选出与指代表达式最相关的 mask。
4.2 Mask Proposal 网络
??将此任务分解为两过程:mask proposal 提取、masked image-text matching。为获得 mask proposals,采用离线的 mask 提取器,即 SAM 作为 mask proposal 网络,同时这一网络决定了模型的上界。
FreeSOLO vs. SAM
??之前的方法利用 FreeSOLO 来获得所有 masks,然而实验表明最近提出的 SAM 在分割单个目标时的效果更好。 下图展示了一些 mask proposal 网络的比较:

??从上图中可以看出,SAM 效果更好,因此模型的上界更高。FreeSOLO 在区分遮挡或重叠场景时效果比 SAM 差,于是本文采用 SAM 作为 mask proposal 网络。
4.3 文本增强的视觉-文本匹配得分
??Mask proposal 网络提供了实例级别的 masks,但并未包含语义信息。为缓解 CLIP 的限制,引入文本引导的视觉-文本匹配得分, V-score、P-score、N-score。
V-score
??给定输入图像
I
∈
R
H
×
W
×
3
I\in \mathbb{R}^{H\times W\times3}
I∈RH×W×3 和指代表达式
T
r
T_r
Tr?。SAM 从输入图像中提取一系列二值化的 masks
M
\mathbb{M}
M,然后将对应的前景区域裁剪出来,送入 CLIP 视觉编码器。通过 CLIP 提取出的视觉和文本特征用于计算余弦相似度:
I
m
=
c
r
o
p
(
I
,
m
)
S
m
v
=
cos
?
(
E
v
(
I
m
)
,
E
t
(
T
r
)
)
\begin{aligned} &I_m=\mathsf{crop}(I,m)\\ &\mathbf{S}_m^\mathrm{v}=\cos(\mathrm{E}_v(I_m),\mathrm{E}_t(T_r)) \end{aligned}
?Im?=crop(I,m)Smv?=cos(Ev?(Im?),Et?(Tr?))?其中
c
r
o
p
\mathsf{crop}
crop 表示 masking 和 cropping 操作。
E
v
\mathrm{E}_v
Ev? 和
E
t
\mathrm{E}_t
Et? 表示 CLIP 视觉和文本编码器,
c
o
s
\mathsf{cos}
cos 表示两种特征的余弦相似度,输出结果为
S
m
\mathbf{S}_m
Sm?,表示视觉-文本匹配得分。CLIP 视觉和文本编码器可以被任意的预训练模型代替。
P-score
??使用一个图像字幕模型为每个 masked image 生成补充的字幕。之后利用 CLIP 文本编码器编码这一字幕,并计算与指代表达式的余弦得分。这一过程表示如下:
S
m
p
=
cos
?
(
E
t
(
C
m
)
,
E
t
(
T
r
)
)
\mathrm{S}_m^\mathrm{p}=\cos(\mathrm{E}_t(C_m),\mathrm{E}_t(T_r))
Smp?=cos(Et?(Cm?),Et?(Tr?))其中
S
p
\mathrm{S}^\mathrm{p}
Sp 为 P-score,用于衡量字幕和指代表达式的相似度。同时该字幕模型可以用任意的字幕模型代替,
S
p
\mathrm{S}^\mathrm{p}
Sp 的效果也高度取决于生成字幕的质量。
N-score
??考虑到图像中的多个目标可能属于不相关的指代表达式,于是提出 N-score 过滤掉这些目标。为区分这些目标,收集负表达式。然后将 masked image 和这些负表达式的相似度记为负的 N-score。此得分性能取决于负的表达式。
??为挖掘不相关的表达式,首先对于输入的图像,生成一个总体的字幕。然后使用 spacy 提取名词短语,将其视为潜在的负表达式。需要注意的是可能有多个短语指向同一目标。为避免这种情况,使用 Wordnet 来去除那些包含同义词的短语。具体来说,计算两个名词的路径相似度(?未知其意),然后决定是否需要消除这种同义词。而剩下的名词短语集
T
n
\mathbb{T}_n
Tn? 用于计算与 masked images 间的余弦相似度。定义
S
m
\mathrm{S}_m
Sm? 为整体短语的平均相似度值:
S
m
n
=
?
1
∣
T
n
∣
∑
T
∈
T
n
cos
?
(
E
v
(
I
m
)
,
E
t
(
T
)
)
\mathrm{S}_m^\mathrm{n}=-\frac1{|\mathrm{T}_n|}\sum_{T\in\mathrm{T}_n}\cos(\mathrm{E}_v(I_m),\mathrm{E}_t(T))
Smn?=?∣Tn?∣1?T∈Tn?∑?cos(Ev?(Im?),Et?(T))需要注意的是
S
n
\mathrm{S}^\mathrm{n}
Sn 是个负分数,因为其衡量的是 masked image 与目标表达式不相关的概率。
S
n
\mathrm{S}^\mathrm{n}
Sn 同样与字幕模型相关,更详细的字幕有益于捕捉更多地负表达式。
The text-augmented visual-text matching score
??由于上述三种得分都是基于 CLIP 计算的余弦相似度,于是通过线性组合得到最终的视觉-文本匹配得分,同时输出最高得分的 mask:
S
m
=
S
m
v
+
α
S
m
p
+
λ
S
m
n
m
^
=
argmax
?
m
∈
M
S
m
\begin{aligned}\mathbf{S}_m&=\mathbf{S}_m^\mathrm{v}+\alpha\mathbf{S}_m^\mathrm{p}+\lambda\mathbf{S}_m^\mathrm{n}\\\hat{m}&=\underset{m\in\mathbb{M}}{\operatorname*{argmax}}\mathbf{S}_m\end{aligned}
Sm?m^?=Smv?+αSmp?+λSmn?=m∈Margmax?Sm??其中
m
^
\hat{m}
m^ 为最高得分
S
\mathbf{S}
S 的 mask。
4.4 空间校正器
??由于 CLIP 并未考虑空间关系,于是提出一个空间解析器用于后处理,强制模型从特定区域中选择 masks。这一过程可以划分为三步:方向描述鉴定、位置计算、空间校正。
方向描述鉴定
??首先通过 spacy 从指代表达式 T r T_r Tr? 中提取方向词,并检查其是否为 “up、bottom、left、right”。如果描述词中没有方向词,则无需应用空间校正器。
位置计算
??接下来为每个 mask 计算其中心点,从而作为位置的表示。具体来说,平均所有前景像素的坐标为 mask 的中心点位置。
空间校正
??在得到中心点位置后,在相应的方向范围内选择所有得分 S S S 中最大的作为 mask。在这个后处理之后,就能限制 CLIP 关注到特定区域了,从而解决方向描述的问题,校正其错误的预测。
五、实验
5.1 数据集和指标
??RefCOCO、RefCOCO+、RefCOCOg、PhraseCut test set;
??overall Intersection over Union (oIoU)、mean Intersection over Union (mIoU)
5.2 实施细节
??默认采用 ViT-H+SAM,超参数 predicted iou threshold 和 stability score threshold 都设为 0.7。points per side 设为 8。对于 BLIP-2,采用 OPT-2.7b 模型。对于 CLIP,采用 RN50 和 ViT-B/32。输出图像尺寸 224 × 224 224\times224 224×224。在 RefCOCO 数据集上, λ = 0.1 \lambda=0.1 λ=0.1;在 RefCOCO+ 数据集上, λ = 1 \lambda=1 λ=1,所有数据集上的 α = 0.1 \alpha=0.1 α=0.1。
5.3 Baseline
??Baseline 方法可以划分为两种类型:基于激活图的、基于图像文本相似度的。本文采用 mask proposals 作为激活图,然后选择最大平均激活分数的 mask。类似的方法有:Grad-CAM、Score Map、Clip-Surgery。而基于相似度的方法有:Region Token、Global-Local、Text-only、CLIP-only、TSEG。
5.4 结果
不同数据集的性能


定性分析

5.5 消融实验
超参数 α \alpha α 和 β \beta β 的敏感性

提出模块的重要性

masked images 输入格式的影响

image captioning 模型的重要性

TAS 能够泛化到其它的图像-文本对比模型吗?

TAS 能够应用于实际场景吗?
??TAS 无需很高的计算资源,所有实验执行在单块 RTX 3090 上,整个模型大约 22GB,包含一个 mask 生成模块 (SAM),字幕器 (BLIP2),masked 图像-文本匹配(CLIP)。推理速度 3.63 秒/张图像。
六、结论
??本文提出文本增强的空间感知 Text Augmented Spatialaware (TAS) 框架应用于 zero-shot RIS,由一个 mask proposal 模块、一个文本增强的视觉-文本匹配得分 text-augmented visual-text matching score、一个空间校正器 spatial rectifier 组成。首先利用离线的 SAM 得到实例级别的 masks,然后文本增强的视觉-文本匹配得分用于选择出与指代表达式最相关联的 mask。接着是空间校正器中的后处理操作,能够解决方向描述的问题。实验效果很好。
七、限制
??其中一个限制是 SAM 偶尔未能生成理想的 mask proposals,因此限制了性能。此外本文的框架上界受限于部署的图像-文本对比模型。另一个限制在于 TAS 不能解决复杂的场景。此外,对于指代表达式中的代称不是太能理解,可能需要未来的大语言模型。
写在后面
??通篇看下来,这篇文章写的是关于 zero-shot 的方法,但是目前基于 SAM 的方法确实很厉害。所以不知道这篇论文会不会进入审稿人的眼中呢?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Ninja H2 HySE川崎的氢能增压摩托车真的来了,像在开火箭?
- 聊聊PowerJob的QueryConvertUtils
- Spring注解驱动开发(三)
- 一文读懂$mash 通证的 “Fair Launch” 规则,将公平发挥极致
- Java小案例-RocketMQ的11种消息类型,你知道几种?(普通消息和批量消息)
- SpringBoot多环境配置以及热部署
- TemporalKit的纯手动安装
- 使用React实现随机颜色选择器,JS如何生成随机颜色
- What is `ByteArrayInputStream` does?
- pyqtgraph 教程