pytorch基础(十)-dropout
发布时间:2024年01月09日
背景
训练时:通过随机使权重为零的方式使神经元失活
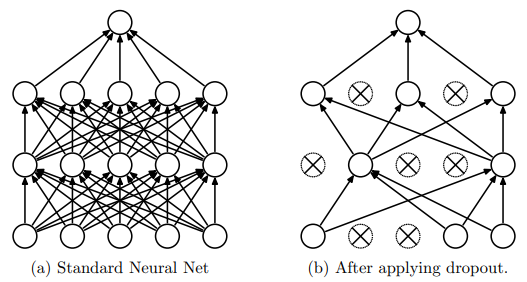
作用:不会产生对某一权重(神经元)的过度依赖
测试时: 所有权重*(1-drop_prob)
nn.Dropout
nn.Dropout(被抛弃的比例)?
放在需要dropout层的前一层
nn.Dropout(drop_prob),
nn.Linear(input_size, outpit_size),
nn.ReLU()经过dropout后训练集的loss升高,可以有效的防止过拟合??
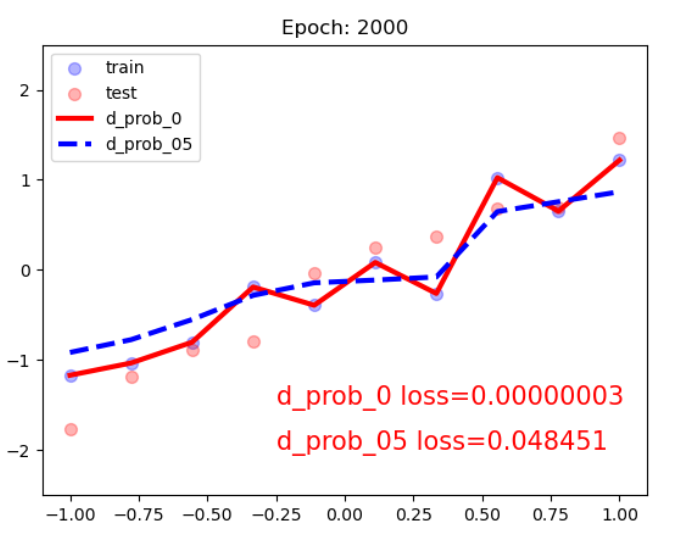
经过dropout后权重的值减小,有效的防止高方差?
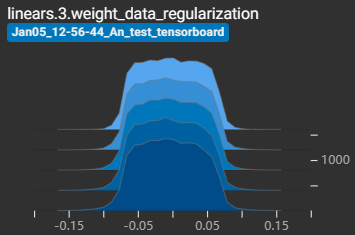
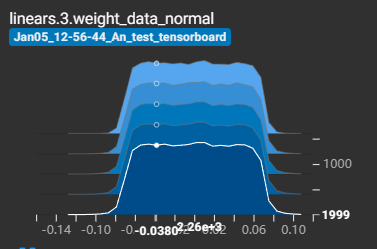 ?
?
实现细节
class Net(nn.Module):
def __init__(self, neural_num, d_prob=0.5):
super(Net, self).__init__()
self.linears = nn.Sequential(
nn.Dropout(d_prob),
nn.Linear(neural_num, 1, bias=False),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.linears(x)
input_num = 10000
x = torch.ones((input_num, ), dtype=torch.float32)
net = Net(input_num, d_prob=0.5)
net.linears[1].weight.detach().fill_(1.)
net.train()
y = net(x)
print("output in training mode", y)
net.eval()
y = net(x)
print("output in eval mode", y)
训练集输出的w*x和验证集输出的w*x的值都为10000左右,为什么?
?
?drop_prob为0.5,输出结果应该在5000左右?为什么会在10000左右?
这是因为,为了方便test时的使用
在test时不再执行所有权重*(1-drop_prob)
而是在train时权重*(1/1-p),在test时就不用额外乘以(1-p)
?
文章来源:https://blog.csdn.net/weixin_62891098/article/details/135406761
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机组成原理第6章-(算术运算)【下】
- 深度学习模型之yolov8实例分割模型TesorRT部署-python版本
- 冒泡排序,选择排序,jdk排序
- 从零开始大数据 2 python简介
- QT+OSG/osgEarth编译之五十一:ColladaDom编译(一套代码、一套框架,跨平台编译,版本:ColladaDom-2.4)
- P1025 [NOIP2001 提高组] 数的划分———C++(动态规划、DFS)
- Java集合框架
- 极狐GitLab DevSecOps 之容器镜像安全扫描
- 蓝牙物联网智能门控系统设计方案
- 延迟加载:程序员的智慧秘籍,优雅演绎慢工出细活!