Transformer and Pretrain Language Models3-5
Transformer结构(优化Tricks)
Transformer在训练和生成过程中,采用了很多小技巧:
首先是训练过程,训练过程中采用了一种叫checkpoint average技术,以及ADAM的一个优化器来进行参数更新,另外的话,为例提高模型的训练效果,防止过拟合,会在残差连接之前加上dropout。
在输出层,也加入了label smoothing的方式来提高训练效率,然后最后在生产过程中给的时候,也采用了更加复杂的一个生成策略

Transformer Performance
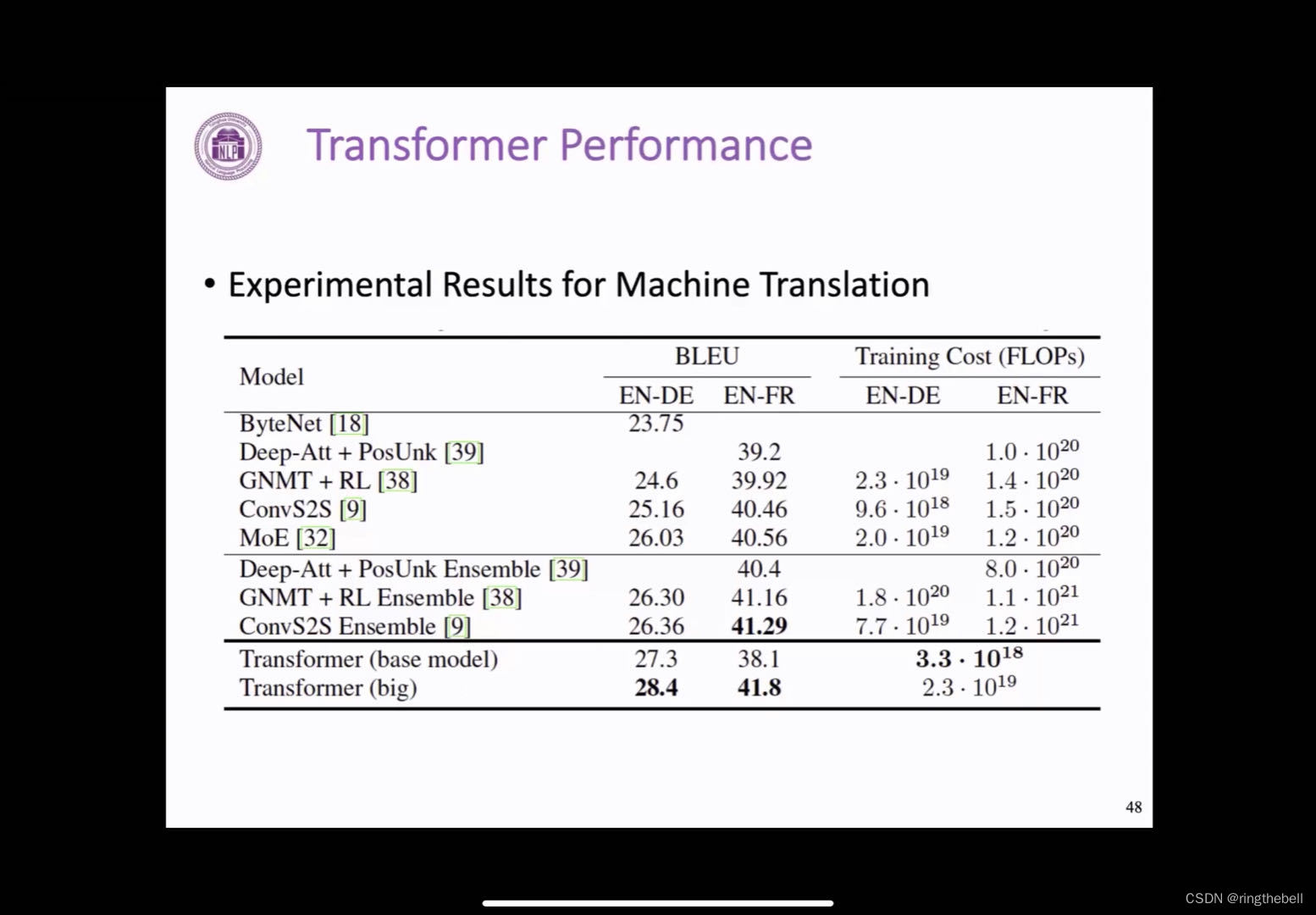
Transformer在机器翻译上的一个效果:
我们可以发现,Transformer也就是最后两行,它相比之前的模型,在评测指标上,也就是BLUE上有一定的提升,而且计算资源的消耗,其实相比之前有一个明显的降低,可以说Transformer之后的几年,几乎在所有的自然语言处理任务上,都取得一个更优的结果,而且这个情况目前正在有的,像计算机视觉等其他领域蔓延的一个趋势。
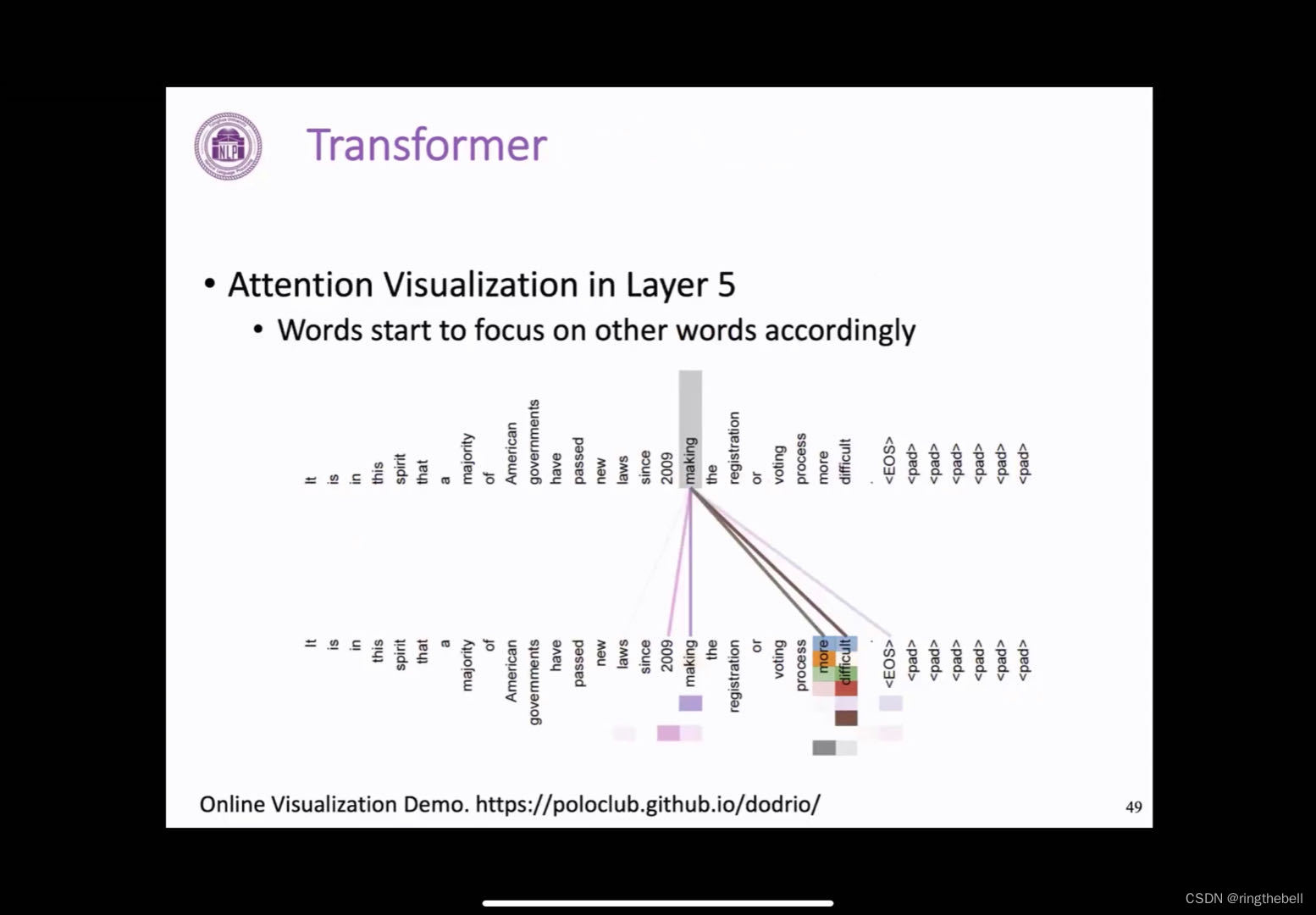
在Transformer结构中,之前讲到的attention其实是一个非常重要的一个部分,了解attention是否可以很好地建模这个token之间的关系,进行一些可视化的分析,以下展示的是第五层的一个attention的一个结果,然后下面这些不同行的色块表示的是不同的注意力,我们可以发现对于making这样一个单词,他的注意力基本上都在关注loss,making ,more difficult这些存在语义或者句法上关系联系的词,这其实也说明了Transformer的注意力机制确实捕捉到了输入句子中不同单词之间的一个关系。
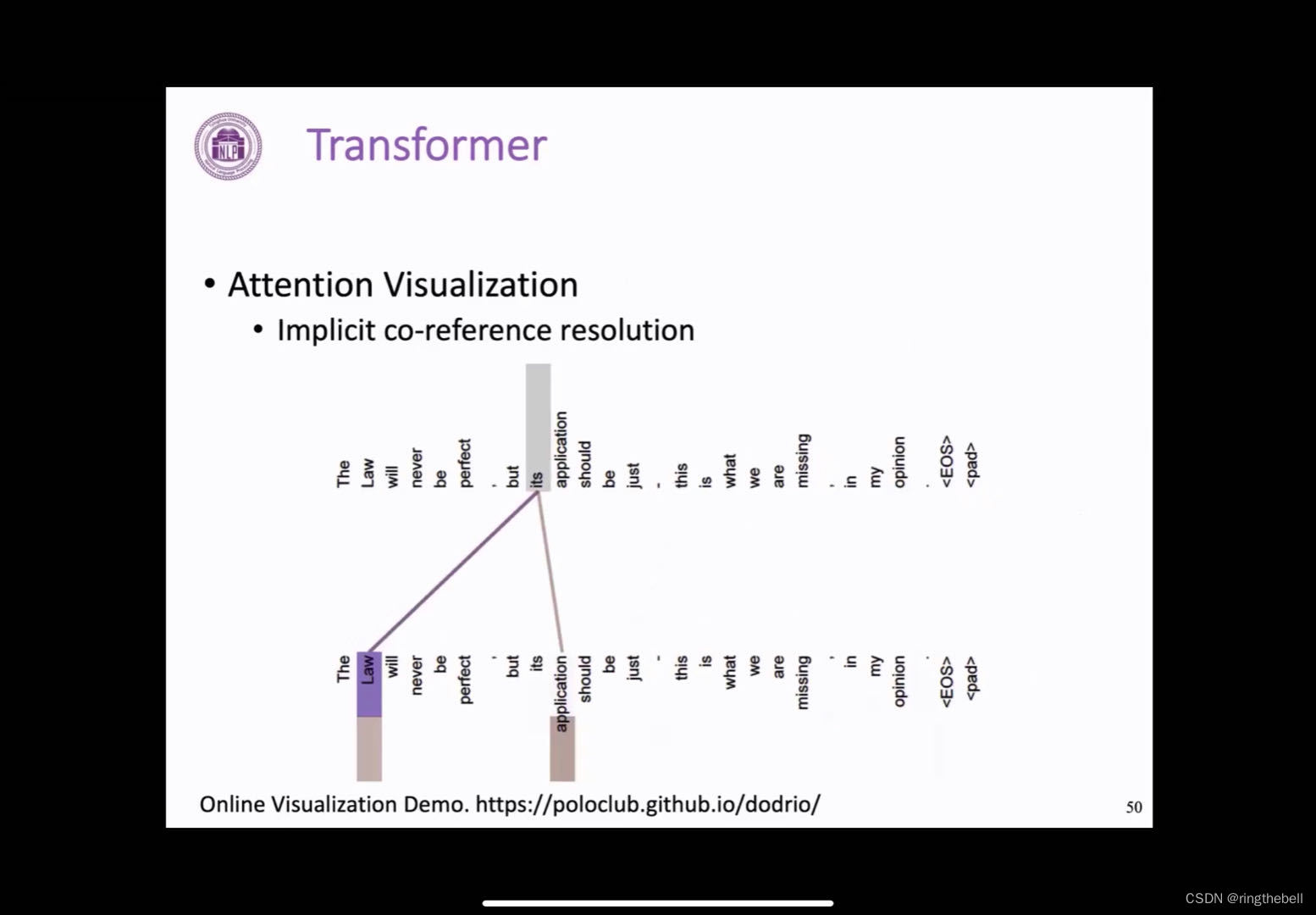
这里还有另外的一个可视化的结果,这里是两个注意力头的一个情况,我们可以清楚的发现,这两个注意力头其实捕捉到的是一个句子中的一个指代关系,然后在这个句子中its其实指代的就是前面提到的law,这样的对应关系,其实都是Transformer模型根据自己的数据自己训练得到的,我们并没有添加任何的外部的限制和帮助,这也充分的说明了Transformer的attention其实具有强大的文本建模和表示能力。
左下方是一个可视化网站,可以输入句子尝试,去看一下Transformer中attention的情况
Transformer summary总结
优点:
1、Transformer是一个具有很强表示能力的模型,而且在很多这个任务中都得到了一个验证,目前也有将这些工作迁移到视觉,然后存储到网络等其他领域的一些工作。
2、这个模型结构本身非常适合并行计算,因为它的attention的计算过程,包括后面前馈网络计算过程,其实都是可以进行,这个对目前GPU等加速设备非常友好。
3、我们通过对attention的一个可视化也可以发现,这个注意力模块其实很好地建模了句子中token和token之间的关系。
4、另外我们从发展到现在的角度来回看当时提出的这样一个Transformer的模型,我们可以发现,它其实给后续的预训练语言模型带来了很多启发,并且成为目前预训练模型的最主要的一个框架,极大地推动了NLP领域的发展。
当然,他其实有一些不可避免的一些缺点:
1、模型本身对于参数很敏感,优化过程非常困难,可能对于优化器的选择,一些超参数的设置,都可能对训练产生一个很大的影响。
2、这样的话,它处理文本的一个复杂度其实是和文本长度n是一个平方的关系,就导致它可能对于长度特别长的文本束手无策。当前很多模型可能都会设置一个最大的输入长度,比如说512

以上为Transformer的相关知识
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c 语言,指针,指针的指针
- 深圳恒峰——配网行波型故障预警定位装置
- JS解构赋值:
- 2023年度五大容灾关键词
- Pandas.Series.max() 最大值 详解 含代码 含测试数据集 随Pandas版本持续更新
- 需求分析的结构化和面向对象方法
- Docker学习与应用(五)-DockerFile
- C++语法中宏的用法汇总和代码实战
- LeetCode-删除排序链表中的重复元素问题
- react函数组件中Hooks和ahooks的区别