【MYSQL】MYSQL 的学习教程(十二)之 MySQL 啥时候用记录锁,啥时候用间隙锁
在「读未提交」和「读已提交」隔离级别下,都只会使用记录锁;而对于「可重复读」隔离级别来说,会使用记录锁、间隙锁和 Next-Key 锁
那么 MySQL 啥时候会用记录锁,啥时候会用间隙锁,啥时候又会用 Next-Key 锁呢?
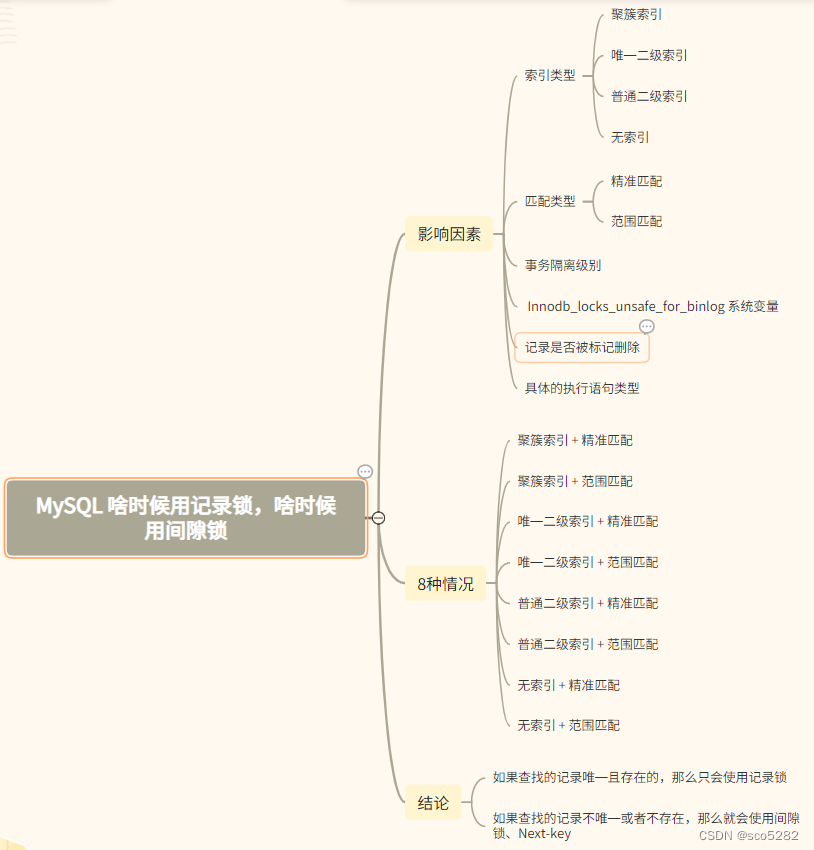
1. 影响因素
影响其使用哪种行级锁的因素有:
- 索引类型(聚簇索引、唯一二级索引、普通二级索引)
- 匹配类型(精确匹配、范围匹配)
- 事务隔离级别
- 是否开启 Innodb_locks_unsafe_for_binlog 系统变量
- 记录是否被标记删除
- 具体的执行语句类型(SELECT、INSERT、DELETE、UPDATE)
测试数据:
// 表结构
CREATE TABLE `test`.`price_test` (
`id` BIGINT(64) NOT NULL AUTO_INCREMENT,
`price` INT(4) NULL,
PRIMARY KEY (`id`));
// 表中数据
1, apple, 10
2, orange, 30
50, perl, 60
2. 8 种情况
在看死锁日志的时候,我们一般先把这个变量 innodb_status_output_locks 打开哈,它是MySQL 5.6.16 引入的:
set global innodb_status_output_locks =on;
2.1 读可提交隔离级别
2.1.1 查询条件是主键
加一个记录锁
2.1.2 查询条件是唯一索引
加两个记录锁:主键索引上的一条记录;唯一索引上的一条记录
2.1.3 查询条件是普通索引
对应的所有满足 SQL 查询条件的记录,都会加上锁。同时,这些记录对应主键索引,也会上锁
2.1.4 查询条件列无索引
MySQL 会走聚簇索引进行全表扫描过滤。每条记录都会加上 X 锁。但是,为了效率考虑,MySQL 在这方面进行了改进,在扫描过程中,若记录不满足过滤条件,会进行解锁操作。同时优化违背了2PL原则
2.2 可重复读隔离级别
2.2.1 聚簇索引 + 精确匹配
- 事务 A 执行下面命令:
begin;
select * from price_test where id = 2 for update;
- 事务 B 执行下面命令:
begin;
update price_test set price = 25 where id = 2;
- 执行
show engine innodb status\G;查看锁信息如下图所示
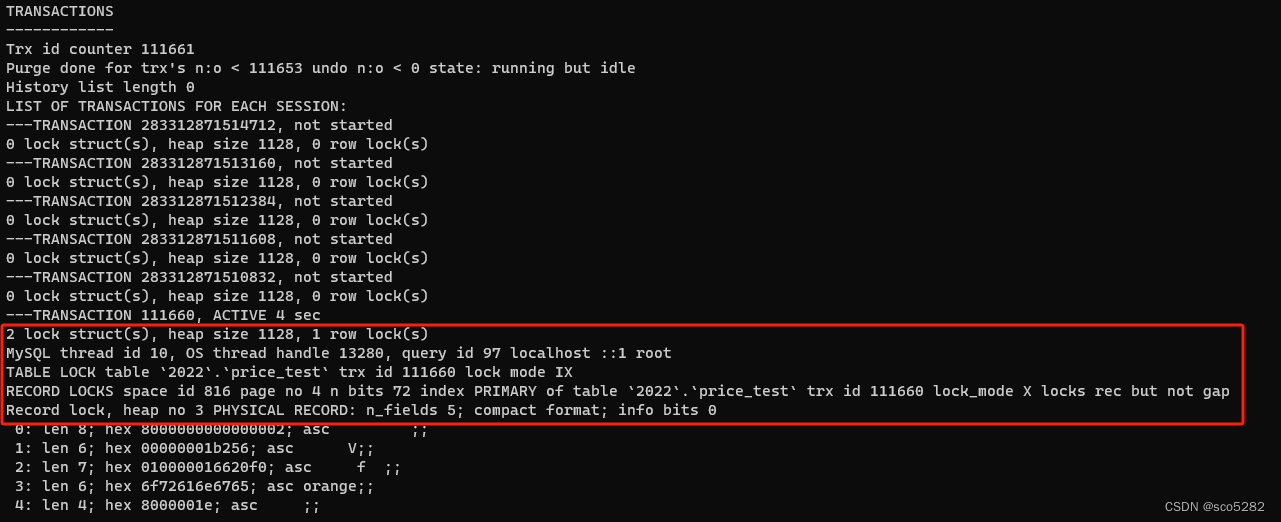
可以看到,其是对 id 为 2 的索引加了一个记录锁
那如果聚簇索引的值找不到对应的记录呢,将会是一个什么样的结果呢?
- 事务 A 执行下面命令,其中 id 为 5 的记录是不存在的
begin;
select * from price_test where id = 5 for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示

加了一个间隙锁,该间隙锁是 (2, 50) 这个范围
- 事务 B 执行如下命令来测试下间隙锁的范围
begin;
// 执行下面任何一个命令,可以通过
update price_test set price = 25 where id = 2;
update price_test set price = 25 where id = 50;
// 执行下面任何一个命令,都将阻塞
insert into price_test(id,name,price) values(3,"test",25);
insert into price_test(id,name,price) values(5,"test",25);
insert into price_test(id,name,price) values(49,"test",25);
聚簇索引 + 精确匹配: 如果能够定位到唯一一条存在的记录,那么其会使用记录锁。如果该记录不存在,那么则会使用间隙锁
2.2.2 聚簇索引 + 范围匹配
- 事务 A 执行下面命令:
begin;
select * from price_test where id >= 2 for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示
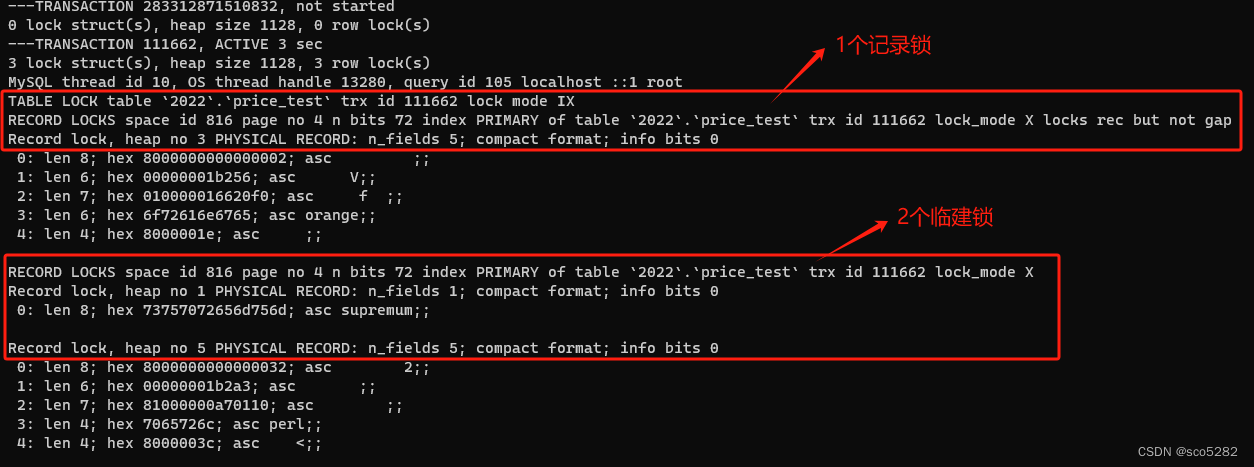
事务 A 一共加了 3 个锁,其中 1 个记录锁,2 个 Next-Key 锁。其中 1 个记录锁是对 id 为 2 的索引加的锁,Next-Key 锁是对 (2, 50] 和 (50, 正无穷) 这两个区间加的锁
- 在事务 B 执行下面命令可以验证间隙锁的加锁区间:
begin;
// 执行下面任意一条语句,都会阻塞
update price_test set price = 25 where id = 2;
update price_test set price = 25 where id = 50;
insert into price_test(id,name,price) values(5,"test",25);
insert into price_test(id,name,price) values(60,"test",25);
如果范围匹配的值并不存在,那么会是什么情况呢?
- 事务 A 执行如下语句,其中 id 为 50 的记录是不存在的。
begin;
select * from price_test where id > 50 for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示

加了 1 个 Next-Key 锁,锁的范围应该是(50, + 无穷)
聚簇索引 + 范围匹配:存在匹配的值,会使用记录锁 + Next-Key 锁;不存在匹配的值,只会使用 Next-Key 锁
2.2.3 唯一二级索引 + 精确匹配
- 事务 A 执行下面命令
begin;
select * from price_test where price = 10 for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示
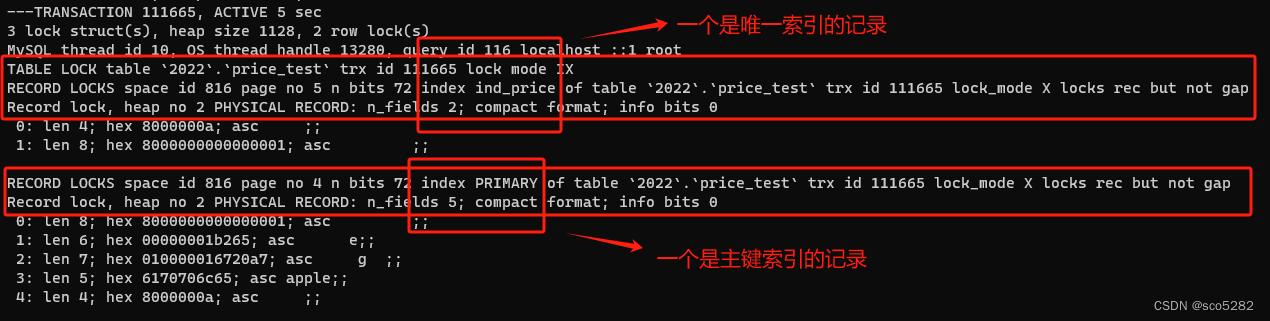
加的行级锁是 2 个记录锁,应该是 price = 10 这条索引记录的锁
- 此时,如果在事务 B 执行下面命令:
begin;
// 执行下面任意一条语句,都会阻塞
update price_test set name = 'test-name' where price = 10;
那如果唯一二级索引的值找不到对应的记录呢,将会是一个什么样的结果呢?
- 事务 A 执行下面命令,其中 price 为 11 的记录是不存在的
begin;
select * from price_test where price = 11 for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示

加了一个间隙锁,该间隙锁是 (10, 30) 这个范围
唯一二级索引 + 精确匹配:唯一二级索引与聚簇索引非常类似,如果能够定位到唯一一条存在的记录,那么其会使用记录锁。如果该记录不存在,那么则会使用间隙锁
2.2.4 唯一二级索引 + 范围匹配
- 事务 A 执行下面命令:
begin;
select * from price_test where price >= 30 for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示
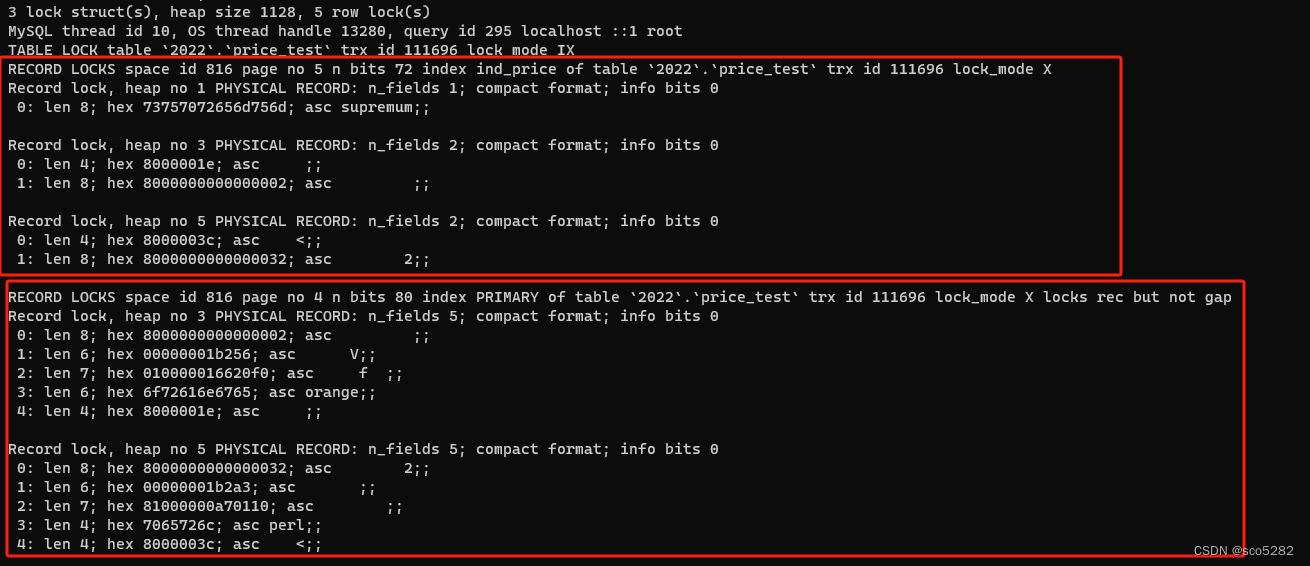
一共加了 5 个行锁,2 个记录锁(price 为 30、60 的记录),3 个 Next-Key 锁, 。3 个 Next-Key 锁则是 (10, 30]、(30,60]、(60, 正无穷)三个范围
- 在事务 B 执行下面命令,每条 SQL 都会阻塞住:
begin;
// 执行下面任意一条语句,都会阻塞
update price_test set name = 'price30' where price = 30;
update price_test set name = 'price60' where price = 60;
insert into price_test(id,name,price) values(5,"test", 20);
insert into price_test(id,name,price) values(5,"test", 40);
insert into price_test(id,name,price) values(5,"test", 70);
如果范围匹配的值并不存在,那么会是什么情况呢?
- 事务 A 执行下面命令:
begin;
select * from price_test where price >= 70 for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示
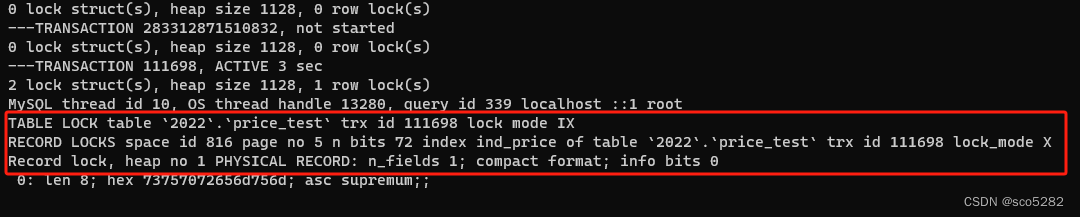
加了一个 Next-key 锁 (60, 正无穷)
聚簇索引 + 范围匹配:存在匹配的值,会使用记录锁 + Next-Key 锁;不存在匹配的值,只会使用 Next-Key 锁
2.2.5 普通二级索引 + 精确匹配
- 事务 A 执行下面命令:
begin;
select * from price_test where name = 'apple' for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示
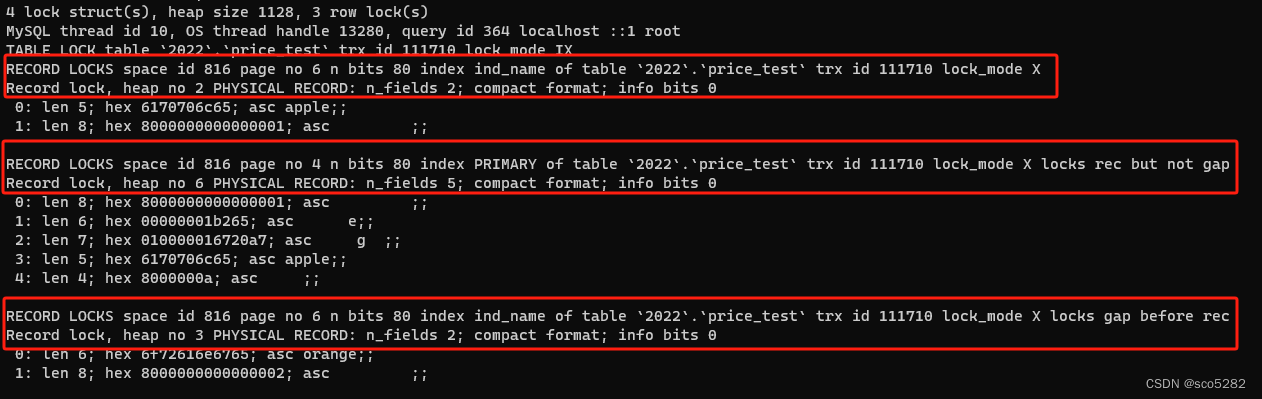
一个记录锁 (name = ‘apple’)、间隙锁(范围: (负无穷,orange))、Next-key 锁(二级索引的记录锁 + 间隙锁)
- 事务 B 执行如下命令验证一下
begin;
// 执行下面任意一条语句,都会阻塞
update price_test set name = 'apple-new' where name = 'apple';
insert into price_test(id,name,price) values(5,"aa", 20);
insert into price_test(id,name,price) values(5,"ha", 20);
// 执行下面的语句正常执行
update price_test set name = 'orange-new' where name = 'orange';
insert into price_test(id,name,price) values(5,"orb", 20);
之所以二级索引的精确匹配会有间隙锁,是因为二级索引可能匹配到多个。因此当匹配到一个的时候,会继续往后匹配,直到匹配到一个不符合的记录,随后就会以该不符合的记录(这里是 orange)作为值做一个间隙锁
普通二级索引 + 精确匹配:若匹配到记录,则使用记录锁 + 间隙锁 + Next-Key 锁;否则,只使用间隙锁
2.2.6 普通二级索引 + 范围匹配
- 事务 A 执行下面命令:
begin;
select * from price_test where name >= 'orange' for update;
- 执行
show engine innodb status\G;查看锁信息如下图所示
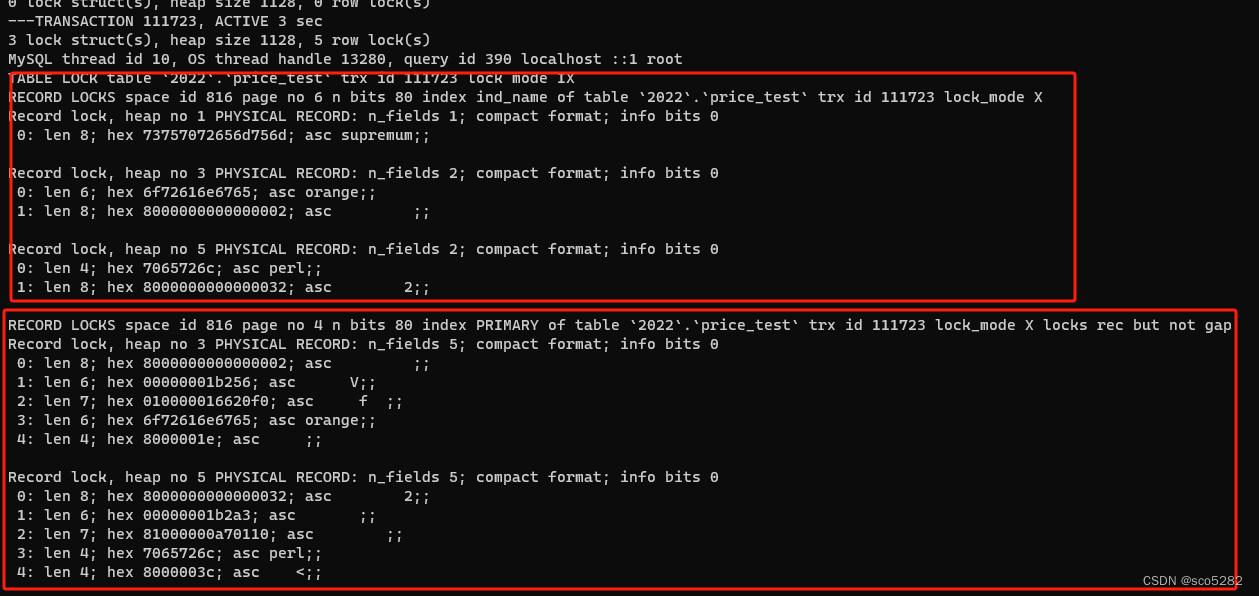
一共有 2 个记录锁,3 个 Next-Key 锁。其中 2 个记录锁应该是 orange 和 perl 两个记录,3 个 Next-Key 锁,应该是 (apple, orange]、[orange, perl)、[perl, 正无穷)
- 事务 B 执行如下命令验证一下:
begin;
// 执行下面任意一条语句,都会阻塞
// 验证记录锁
update price_test set price = 1 where name = 'orange';
update price_test set price = 1 where name = 'perl';
// 验证间隙锁
insert into price_test(id,name,price) values(5,"ba", 20);
insert into price_test(id,name,price) values(5,"orb", 20);
insert into price_test(id,name,price) values(5,"pes", 20);
// 执行下面的语句正常执行
update price_test set price = 1 where name = 'apple';
insert into price_test(id,name,price) values(5,"aa", 20);
普通二级索引 + 范围匹配:存在匹配的值,使用记录锁 + Next-Key 锁;若不存在,则使用 Next-Key 锁
2.2.7 无索引
如果查询条件列没有索引,主键索引的所有记录,都将加上 X 锁,每条记录间也都加上间隙 Gap 锁。大家可以想象一下,任何加锁并发的 SQL,都是不能执行的,全表都是锁死的状态。如果表的数据量大,那效率就更低
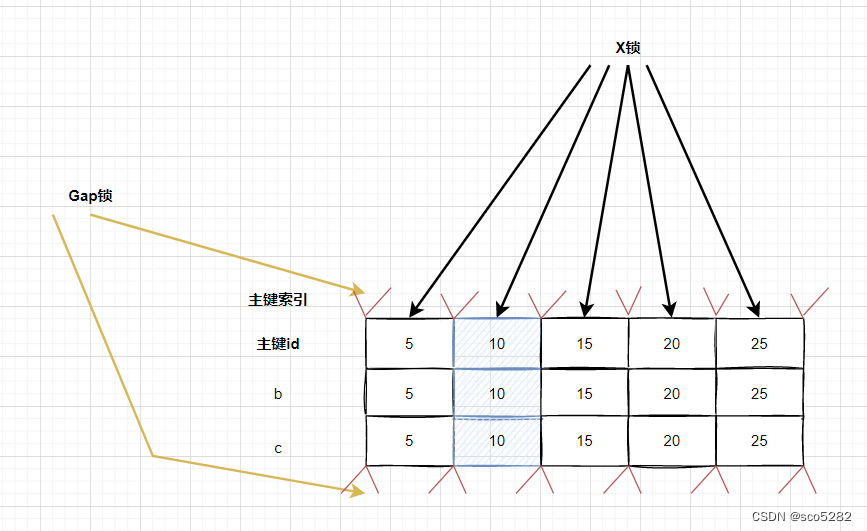
在这种情况下,MySQL 做了一些优化,即 semi-consistent read,对于不满足条件的记录,MySQL 提前释放锁,同时 Gap 锁也会释放。而 semi-consistent read 是如何触发的呢:要么在 Read Committed 隔离级别下;要么在 Repeatable Read 隔离级别下,设置了 innodb_locks_unsafe_for_binlog 参数。但是 semi-consistent read 本身也会带来其他的问题,不建议使用。
2.3 Serializable 串行化
在 Serializable 串行化的隔离级别下,对于写的语句,比如 update account set balance= balance-10 where name=‘Jay’;,跟RC和RR隔离级别是一样的。不一样的地方是,在查询语句,如 select balance from account where name = ‘Jay’;,在 RC 和 RR 是不会加锁的,但是在 Serializable 串行化的隔离级别,即会加锁
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 4-Docker命令之docker load
- 基于华为MRS实时消费Kafka通过Flink落盘至HDFS的Hive外部表的调度方案
- 爬虫工作量由小到大的思维转变---<第二十章 Scrapy几个常规参数的调整策略心得>
- 嵌入式学习四
- React面试题:React如何判断什么时候重新渲染组件?
- BED 文件格式 chip-seq m6a数据可视化会用到
- 【LearnOpenGL基础入门——5】着色器
- 中霖教育:专业不对口,能考会计师吗?
- springboot配置快速启动
- Edge扩展插件安装位置