基于Segformer实现PCB缺陷检测(步骤 + 代码)
导? 读
????本文主要介绍基于Segformer实现PCB缺陷检测?,并给出步骤和代码。? ??
背景介绍

? ? PCB缺陷检测是电子制造的一个重要方面。利用Segformer等先进模型不仅可以提高准确性,还可以大大减少检测时间。传统方法涉及手动检查,无法扩展且容易出错。利用机器学习,特别是 Segformer模型,提供自动化且精确的解决方案。
? ? ??
实现步骤
????下面是具体步骤:?
??【1】安装所需环境。首先,我们安装所需的库。其中,albumentations用于数据增强,transformers允许访问 Segformer等预训练模型,并xmltodict帮助解析数据集的XML注释。
pip?install?evaluate?albumentations?transformers?accelerate?xmltodict??【2】数据集。这个项目中使用的数据集由Roboflow提供。可以从下面链接获取:
https://universe.roboflow.com/diplom-qz7q6/defects-2q87r/dataset/16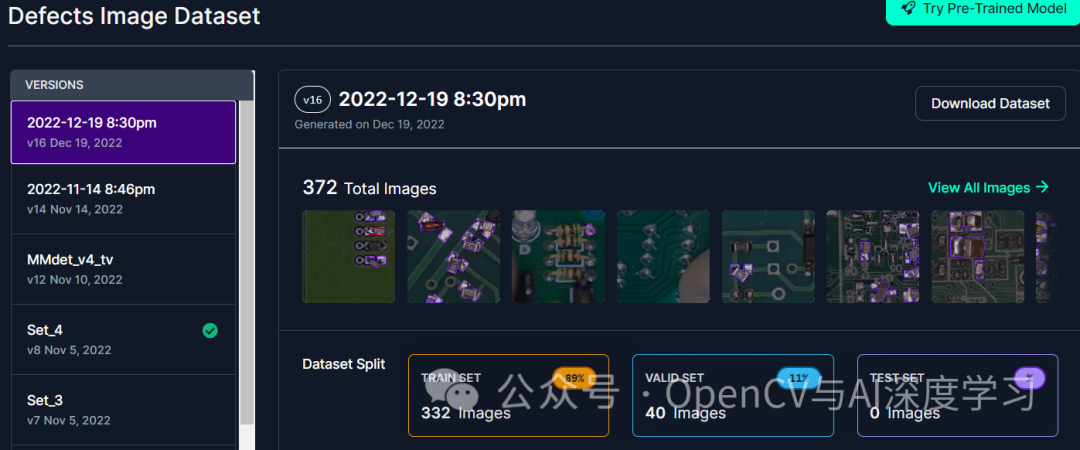
该数据集分为测试文件夹和训练文件夹,由XML格式的图像及其相应注释组成。
# Create train and test setstrain_folder = "drive/..../train/images/"test_folder = "drive/.../validation/images/"train_img_paths = sorted([train_folder + f for f in os.listdir(train_folder) if f.endswith("jpg")])test_img_paths = sorted([test_folder + f for f in os.listdir(test_folder) if f.endswith("jpg")])train_xml_paths = [f[:-3] + "xml" for f in train_img_paths]test_xml_paths = [f[:-3] + "xml" for f in test_img_paths]train_ds = {"image_paths": train_img_paths, "xml_paths": train_xml_paths}test_ds = {"image_paths": test_img_paths, "xml_paths": test_xml_paths}
??? XML文件包含多边形标注信息,指示PCB图像上缺陷的位置。该函数process_mask读取XML标注信息并将其转换为掩码(类似图像的数组)。该掩模对应于PCB图像上的缺陷区域,基本上将缺陷与电路板的其余部分分开。
????该函数首先使用OpenCV读取原始图像。在我们初始化与输入图像大小相同的蒙版之后。根据可视化标志,蒙版可以是3通道RGB蒙版(如彩色图像)或1通道灰度蒙版。最初,该掩码中的所有值都设置为零,这意味着没有缺陷。
??【3】缺陷标注解析。对于每个缺陷标注信息:识别缺陷类型,提取缺陷的多边形形状,该多边形被绘制到初始化的蒙版上。最后,该函数弥合了XML标注信息和适合训练的格式之间的差距。给定 PCB图像及其相应的XML 注释,它会生成一个分割掩模,突出显示有缺陷的区域。掩模可以是适合训练模型的数字格式,也可以是用于人工检查的视觉格式。???????
def process_mask(img_path, xml_path, visualize=False):img = cv2.imread(img_path)num_dim = 3 if visualize else 1mask = np.zeros((img.shape[0], img.shape[1], num_dim))# Read xml content from the filewith open(xml_path, "r") as file:xml_content = file.read()data = xmltodict.parse(xml_content)# If has defect maskif "object" in data["annotation"]:objects = data["annotation"]["object"]# Single defects are annotated as a single dict, not a listif not isinstance(objects, List):objects = [objects]for obj in objects:defect_type = obj["name"]polygon = obj["polygon"]poly_keys = list(polygon.keys())# Get number of (x, y) pairs - polygon coordspoly_keys = [int(k[1:]) for k in poly_keys]num_poly_points = max(poly_keys)# Parse ordered polygon coordinatespoly_coords = []for i in range(1, num_poly_points+1):poly_coords.append([int(float(polygon[f"x{i}"])),int(float(polygon[f"y{i}"]))])poly_coords = np.array(poly_coords)# Draw defect segment on maskfill_color = color_map[defect_type] if visualize else id_cat_map[defect_type]mask = cv2.fillPoly(mask, pts=[poly_coords], color=fill_color)#Optionalif visualize:cv2.imwrite("output.jpg", mask)mask = Image.open("output.jpg")return mask
? 【4】探索性数据分析。在训练模型之前,最好先了解数据。在这里,我们检查缺陷类型的分布并在样本图像上可视化缺陷。
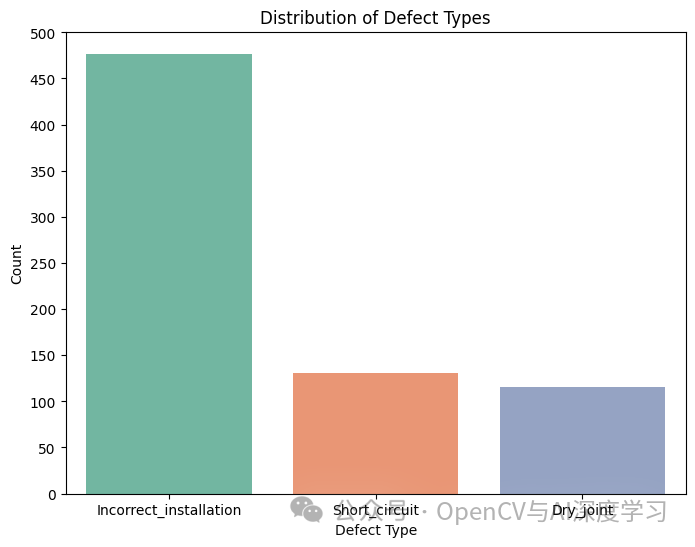



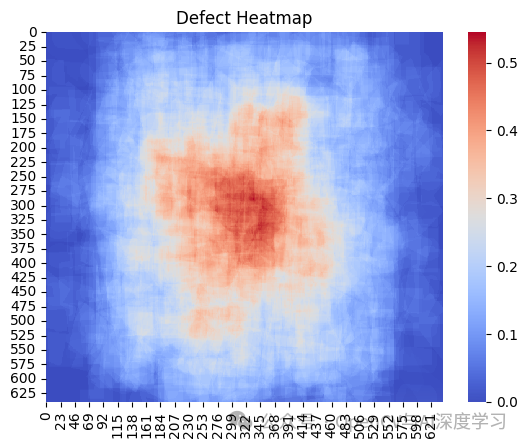
????缺陷热力图显示了常见的缺陷位置,箱线图显示了缺陷尺寸的分布。
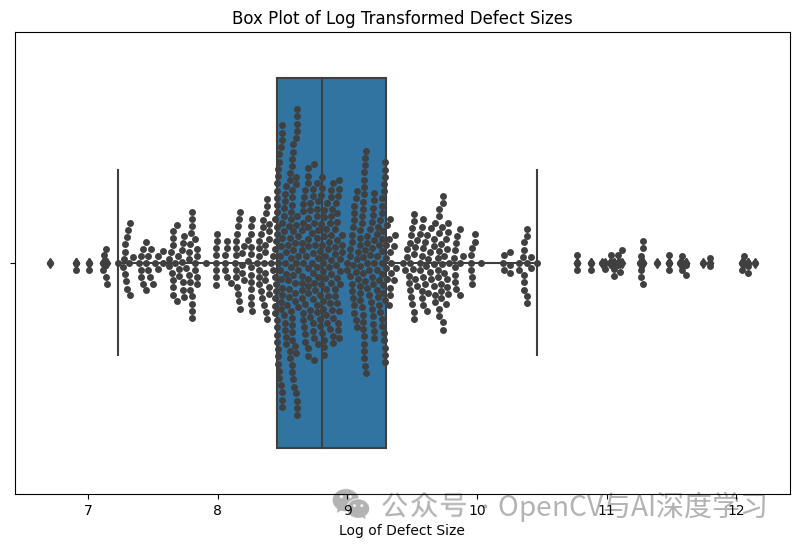
????该函数旨在通过读取边界框详细信息来计算 XML 注释中存在的每个缺陷的大小。
def get_defect_sizes(xml_paths):sizes = []for xml_path in xml_paths:with open(xml_path) as f:data = xmltodict.parse(f.read())objects = []if 'object' in data['annotation']:objects = data['annotation']['object']if not isinstance(objects, list):objects = [objects]for obj in objects:bndbox = obj['bndbox']width = int(bndbox['xmax']) - int(bndbox['xmin'])height = int(bndbox['ymax']) - int(bndbox['ymin'])sizes.append(width * height)return sizes
????最后,群图重点关注缺陷尺寸在整个数据集中的分布和扩散。
? 【5】数据增强。该albumentations库用于人为扩展训练数据集,有助于提高模型的泛化能力。唯一指定的增强是水平翻转,它将以 50% 的概率水平翻转图像。???????
transform = A.Compose([A.HorizontalFlip(p=0.5)])
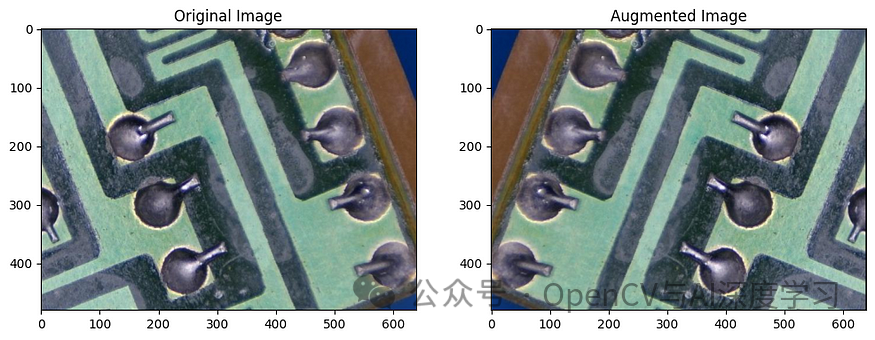
?【6】图像预处理。将图像及其掩模预处理为适合Segformer模型的格式。
preprocessor = SegformerImageProcessor()????我们将定义一个继承自PyTorchDataset类的自定义数据集类。这个自定义数据集允许我加载和预处理 PCB 图像及其相应的缺陷掩模。
????使用 OpenCV 加载图像。使用前面讨论的函数生成缺陷掩模process_mask。使用之前初始化的图像预处理图像及其掩模SegformerImageProcessor。此步骤将图像转换为张量格式,并确保它们具有适合 Segformer 模型的大小和标准化。返回预处理的图像和掩模张量。???????
class DefectSegmentationDataset(Dataset):def __init__(self, dataset, mode):self.image_paths = dataset["image_paths"]self.xml_paths = dataset["xml_paths"]def __len__(self):return len(self.image_paths)def __getitem__(self, idx):# Read imageimage = cv2.imread(self.image_paths[idx])# Get maskmask = process_mask(self.image_paths[idx], self.xml_paths[idx])mask = mask.squeeze()mask = Image.fromarray(mask.astype("uint8"), "L")# Return preprocessed inputsinputs = preprocessor(image, mask, ignore_index=None, return_tensors="pt")inputs["pixel_values"] = inputs["pixel_values"].squeeze(0)inputs["labels"] = inputs["labels"].squeeze(0)return inputs
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- GBASE南大通用SQL API 中的 SQL
- Android GPS基础原理
- 在JavaFX中的module-info.java的大坑,实现怎么删除这个后不会报错“需要JavaFX运行组件”
- C++从零开始的打怪升级之路(day6)
- shell脚本概念构成及脚本变量详解
- 智慧文旅运营综合平台:重塑文化旅游产业的新引擎
- 什么是好的FPGA编码风格?(1)--尽量避免组合逻辑环路(Combinational Loops)
- 服务器安装Mysql5.7
- 计算机专业大学生如何十分钟写好论文中的文献综述呢?
- win10下安装detectron2-0.5(0.6应该也可以)