tvm 中的python bindings是如何与 C++ 进行交互的呢
我们知道,tvm 使用 python 作为前端编程语言,好处是 python 简单易用,生态强大,且学习成本较低。而实际的代码,都是 c++ 代码。
源码编译 tvm,编译完成之后,会在 build 目录下生成 libtvm.so 和 libtvm_runtime.so 两个文件。
使用 tvm 编译时,需要 libtvm.so,而加载编译后的 so 库实际运行时,需要 libtvm_runtime.so。
tvm 对模型进行编译的过程,可以这么来理解。高级编程语言是符合一定上下文无关文法规则的语言,通过编译器翻译成机器码。而模型 ,可以理解成是一大堆的数学公式,而参数就是数学公式的系数。也就是说是按照一定顺序,有确定参数的数学公式的计算。可以把模型想象成是一个超大的函数,这个函数的函数体部分就是一大堆的数学计算。这样理解的话,就相当于是将这样一个有大量数学计算的超大的函数编译成机器码,翻译成能在特定硬件上运行的二进制代码。
我的理解就是,不管是高级编程语言,还是机器学习模型,本质上都是对计算的一种描述,而编译器所做的事情,就是识别这种对计算的描述,然后经过多层 lowering 的过程,翻译成特定芯片所能识别的指令,能够在特定硬件上运行。
tvm 将模型编译成一个二进制文件,在 linux 系统中就是 elf 格式的文件,比如 shared library。而这个 shared library 的内容是 tvm 的 api 组成的,所以加载这个 library 也需要使用 tvm 的api,这就需要使用 libtvm_runtime.so 了。
好了,言归正传,当我们使用 tvm 的 python dsl 来编译模型时,python 接口是如何与 libtvm.so 进行交互的呢?
tvm ffi
在 tvm 的 python modules 中,封装了一个 _ffi 的模块。该模块中使用到了 ctypes 库,用来与 c 代码进行交互。
ctypes is a foreign function library for Python。ctypes 提供了 C 兼容的数据类型,允许调用 DLL 或者 shared libraries 中的函数。支持将这些 c 中的函数封装到纯 python 中进行使用。
比如使用 ctypes 加载 libc.so
import ctypes
libc = ctypes.CDLL("libc.so")
使用 libc 中的随机函数
print(libc.rand())
在 tvm/_ffi/base.py 中,定义了 _load_lib 函数,用来加载动态库。
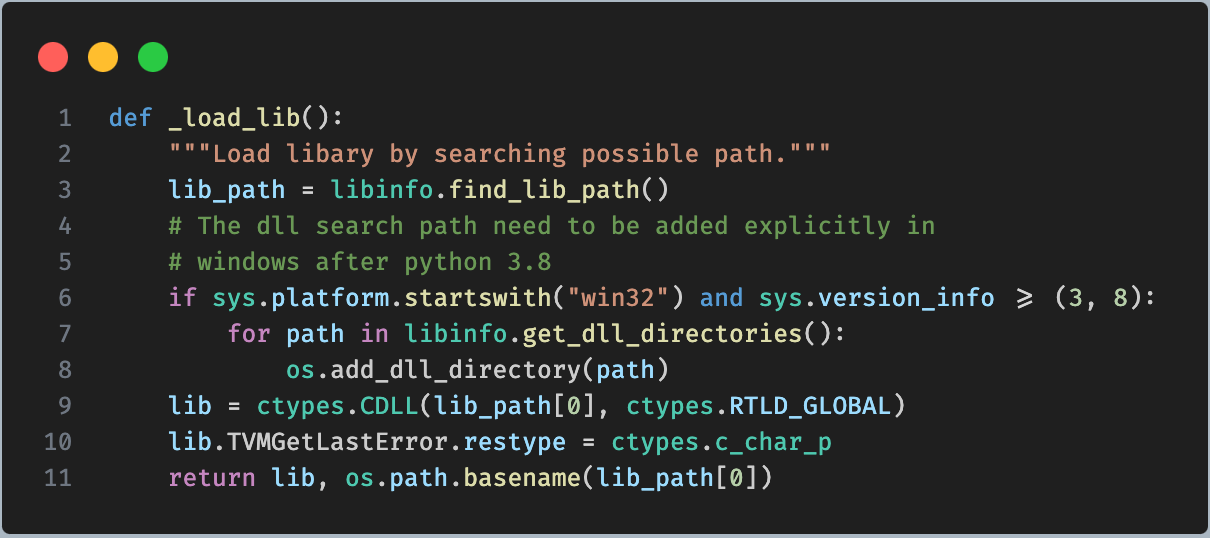
代码中调用了 ctypes.CDLL 方法来加载库。而 lib_path 是通过 libinfo.find_lib_path() 方法返回的。可以继续看下这个函数的实现。该方法定义在 tvm/_ffi/libinfo.py 中。
首先通过 get_all_directories() 获取动态库可能存在的所有可能路径,分别从
- TVM_LIBRARY_PATH 环境变量
- PATH 环境变量
- LD_LIBRARY_PATH 环境变量(linux)或者 DYLD_LIBRARY_PATH 环境变量(mac)
- 构建目录 build, build/Release, 安装目录 install_dir
- TVM_HOME 环境变量
中进行查找。并根据不同的平台获取不同的库的名称,linux 下为
libtvm.so
libtvm_runtime.so
通过各种路径搜索,找到实际库所在的位置。
__init_api
看一个实际调用,比如 tvm/relay/transform/_ffi_api.py 中,
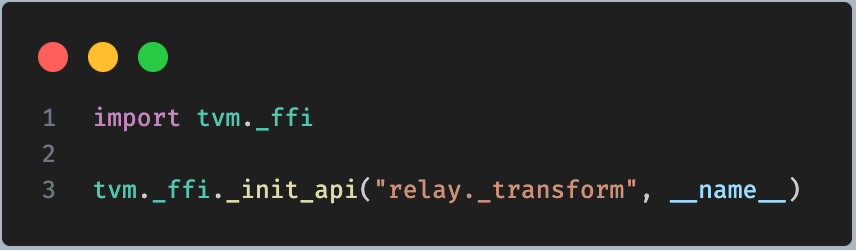
首先 import 了 tvm._ffi,这就是上面我们分析的 tvm 的 ffi,然后调用了 __init_api 方法进行了初始化,实质上就是注册。这里来分析一下这个函数。
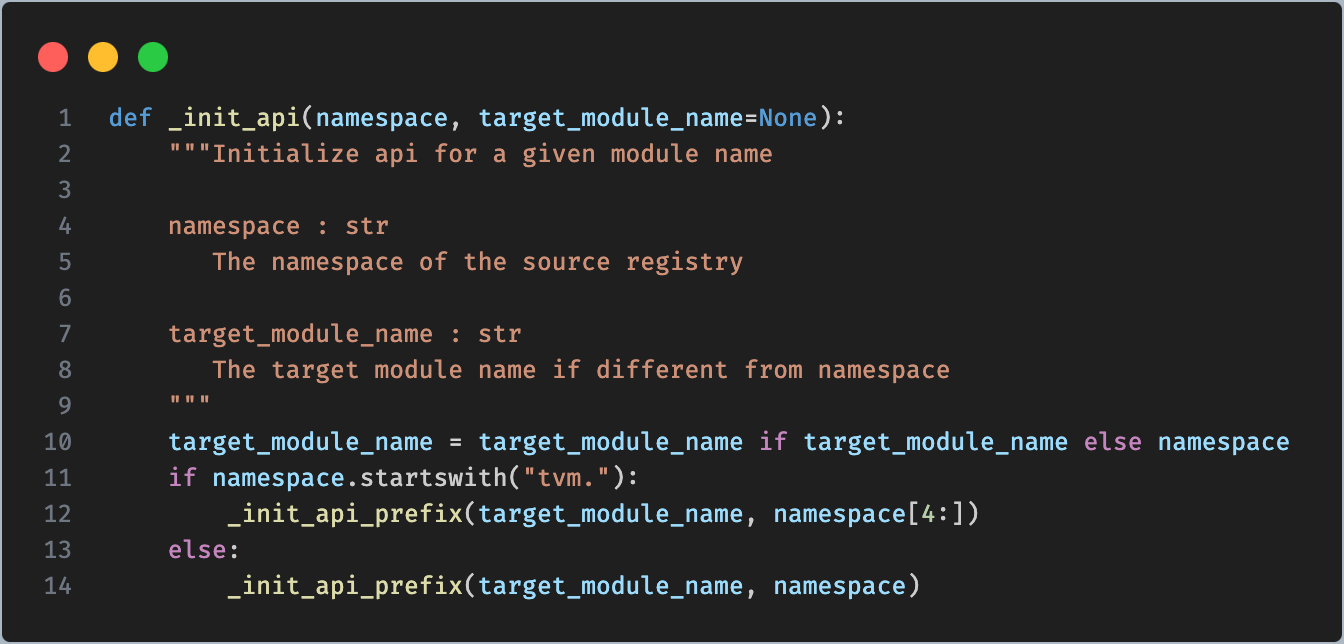
形参对应关系
namespace: relay._transform
target_module_name: __name__
__name__ 是 python 内置的变量,值就是当前模块的名称,也就是 tvm/relay/transform/__ffi_api。由于 namespace 不是以 tvm. 开头,所以执行 else 分支
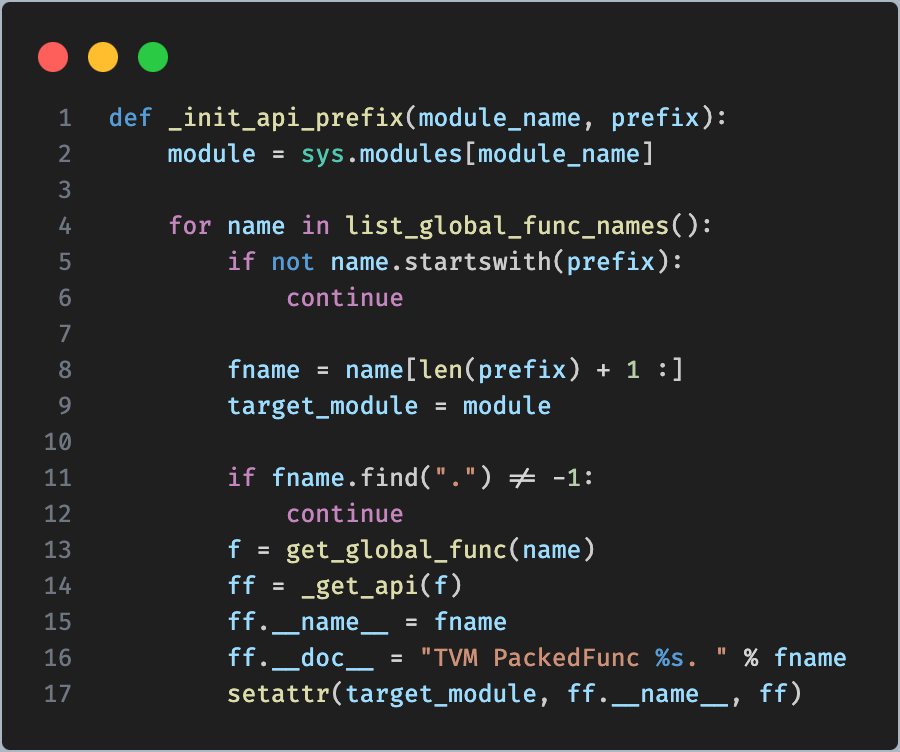
通过 list_global_func_names() 找到所有的全局符号名称,然后逐个遍历,如果名称前缀是 relay._transform 就获取该名称的函数,比如 relay._transform.InferType,然后将函数以属性的方式加入到 target_module 中。最后一行代码,就是为 target_module 设置一个属性。相当于
_transform."InferType" = ff
这样,在 transformer.py 中,对该函数再做了一层封装,

在 python 模块中,就可以直接使用 transform.InferType() 了。
虽然这里已经见到了 tvm 对 c++ 函数的封装,但是并没有看到 c++ 函数是如何交互起来的。而主要就是上面函数中,通过名称获取全局符号的过程。我们重点来分析一下。
_get_global_func
get_global_func 定义在 tvm/_ffi/registry.py 中,实际调用的是 tvm/_ffi/_ctypes/packed_func.py 中的 _get_global_func

handle 其实是一个 ctypes 中的 void。
_LIB 就是上面分析的,tvm 中使用 ctypes.CDLL 来加载动态库后返回的对象。而 _LIB.TVMFuncGetGlobal 实际上就是调用 so 库中的 TVMFuncGetGlobal 函数,这个在 src/runtime/registry.cc 中定义。该函数通过名称获取注册的全局符号。
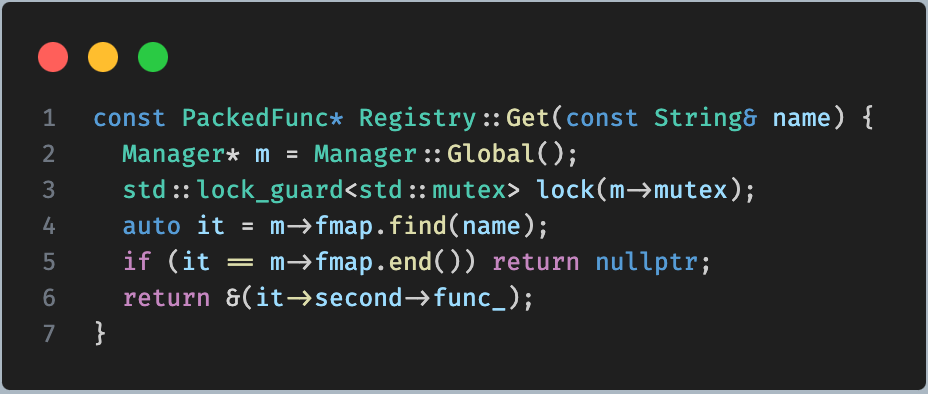
通过函数名,在 fmap 中寻找,返回函数。这个函数都是经过封装的 PackedFunc 指针。
tvm c++ 端的函数注册
还是以上面 InferType 为例。在 tvm 的 src/relay/transforms/type_infer.cc 中,调用宏对 Infertype 进行了注册。
TVM_REGISTER_GLOBAL("relay._transform.Infertype").set_body_typed([]() { return InferType(); });
TVM_REGISTER_GLOBAL 就是注册一个全局函数
#define TVM_REGISTER_GLOBAL(OpName) \
TVM_STR_CONCAT(TVM_FUNC_REG_VAR_DEF, __COUNTER__) = ::tvm::runtime::Registry::Register(OpName)
OpName 对应为算子名称,也就是需要注册的函数,为 relay._transform.Infertype,而函数体部分为实际的 InferType() 函数调用。上面的红展开,就是
TVM_STR_CONCAT(TVM_FUNC_REG_VAR_DEF, __COUNTER__) = ::tvm::runtime::Registry::Register("relay._transform.Infertype").set_body_typed([]() {
return InferType();
});
这里调用了 Register 方法进行注册。
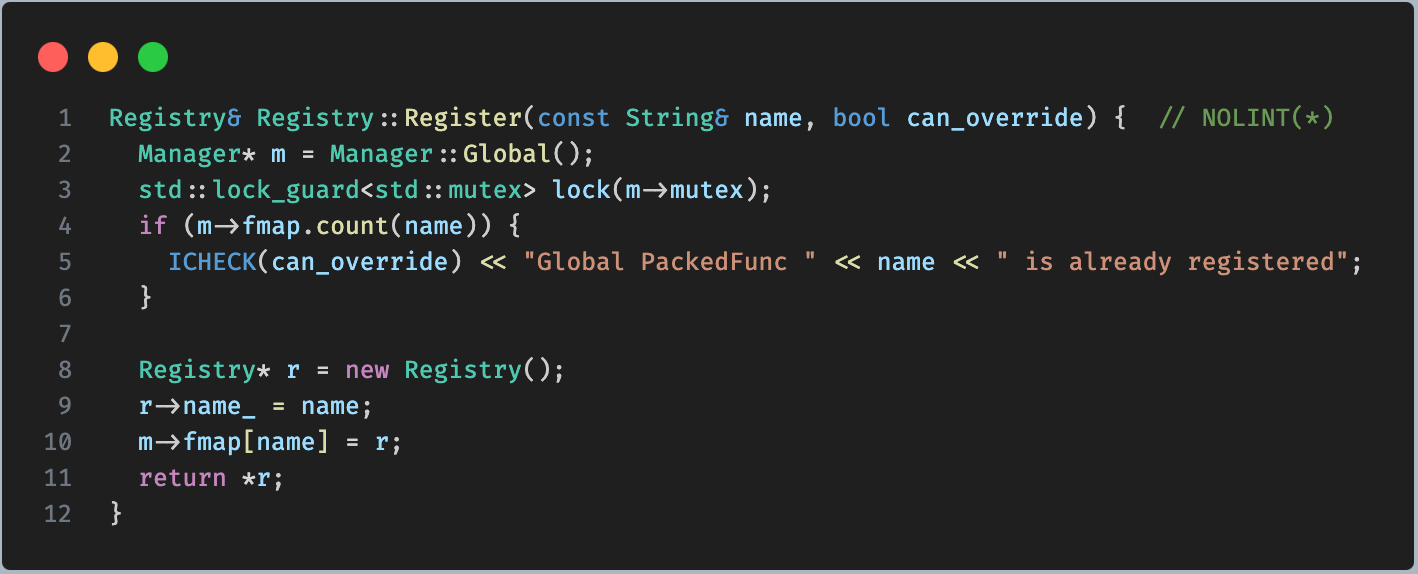
将函数加入到 Global 中。这样就前后对应起来了。
总结
tvm python bindings 通过 ctypes 库,加载 libtvm_runtime.so,通过 _ffi 模块,将 so 库中的所有注册的全局符号都加载到 python,同时对这些 c 函数进行封装,封装成 python 可以直接调用的 python function 的形式。这样在 pure python 中就可以直接使用了。
在 c++ 端的代码中,通过注册机制将函数注册到一个 Global model 中。注册的函数都被封装成了 PackedFunc 的形式。这种形式,可以比较方便的处理 c++ 与 c mangling 不同的问题,因为这里不是使用的编译器编译后的符号,而是经过封装后,tvm自己建立起的通过名字与函数指针之间的对应关系,自己来管理。
c++ 代码中将函数经过封装,以名字和方法映射的方式进行注册。而在 python 中通过加载动态库后,将所有注册的函数再次进行封装,使得 Python 中可以直接调用。这样就完成了 python 与 c++ 动态库之间的交互。
那再多思考一个问题:
python 语言,比如 cython,是解释执行的。而通过 ctypes 的方式加载的动态库,是经过 aot 的方式进行编译的,为什么这里可以直接执行呢?
我的理解是,这里可以将 c++ 代码做一个类比。比如 c++ 中,动态加载动态库可以通过 dlopen 的方式打开,通过编译器 aot 编译成可执行文件,然后运行。
而 python,是解释执行的。通过 python 二进制文件经过前端处理翻译成字节码的形式,在虚拟机中解释执行。可以将 ctypes 加载动态库的操作 CDLL 看成是 dlopen,实际也确实是这样来实现的。那 python 虚拟机在解释执行时,如果刚好运行到这个 c 函数,其实就相当于获取到这个c函数的地址,直接转到这个c函数对应的机器码处执行。
而在虚拟机或者 JIT 机制中,比如 jvm,会将 hot code 编译成机器码直接执行,所以直接执行这个机器码是可以的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Halcon计算封闭区域(孔洞)的面积area_holes
- C++ 之LeetCode刷题记录(十二)
- vue项目nginx部署二级目录
- POJ - 3311 Hie with the Pie(Java & JS & Python & C)
- 个人实现的QT拼图游戏(开源),QT拖拽事件详解
- 使用k8s 配置 RollingUpdate 滚动更新实现应用的灰度发布
- vue中对keep-alive的理解
- Spring Cloud Validation 使用正则表达式校验
- 使用ffmpeg实现视频旋转并保持清晰度不变
- 引导和服务