ElasticSearch[八]:自定义评分功能、使用场景讲解以及 function_score常用的字段解释
ElasticSearch[八]:自定义评分
一、适用的场景
- 基本介绍
ES 的使用中,ES 会对我们匹配文档进行相关度评分。但对于一些定制化的场景,默认评分规则满足不了我们的要求。这些定制化场景,ES 也是推出了自定义评分方式来进行支持。可以使用 ES 提供的一些函数,什么可以使用较分来让我们的评分规则多样化。我举个大家都很熟悉的场景,在点外卖时候,大家是不是有一个综合排序,比如用户希望通过距离和价格来进行综合排序,这在 mysql 中是不是比较难以实现,接下来我将由简到繁的来教你如何在 ES 中实现这种综合评分排序的功能
1.1 使用场景
1.1.1 根据价格评分排序
在 mysql 中我们可以通过价格从高到低,从低到高排序,但是像订酒店那样,用户有期望价格的,酒店越符合用户的期望价格,评分越高。mysql 的排序这时候是不是有点捉襟见肘了。废话不多说了,直接来 ES 实现。
{
"from": 0,
"size": 12,
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{
"term": {
"price": {
"value": 50,
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"functions": [
{
"filter": {
"match_all": {
"boost": 1.0
}
},
"gauss": {
"price": {
"origin": 50,
"offset": 0,
"scale": "25",
"decay": 0.5
}
}
}
]
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
1.1.2 根据距离评分排序
在我们日常使用的场景,我们经常有需要根据距离来进行排序评分,常见的 App 中都是有一个距离更近,来筛选商户。接下来就来看看 ES 的实现。
{
"from": 0,
"size": 12,
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{
"term": {
"price": {
"value": 50,
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"functions": [
{
"filter": {
"match_all": {
"boost": 1.0
}
},
"gauss": {
"location": {
"origin": {
"lon": 130.380857,
"lat": 31.112834
},
"offset": 0,
"scale": "150km",
"decay": 0.5
}
}
}
]
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
1.1.3 根据距离价格综合评分排序
上面举例了两个单一的场景,要么是价格,要么是距离,那如果想实现复杂点的场景呢,希望通过距离和价格综合排序。比如用户希望订一个距离虹桥火车站近的,价格 200 左右的酒店。废话不多说,直接看实现。
{
"from": 0,
"size": 12,
"query": {
"function_score": {
"query": {
"match_all": {
"boost": 1.0
}
},
"functions": [
{
"filter": {
"match_all": {
"boost": 1.0
}
},
"gauss": {
"location": {
"origin": {
"lon": 130.380857,
"lat": 31.112834
},
"scale": "150km",
"decay": 0.5
},
"multi_value_mode": "MIN"
},
"weight": 1
},
{
"filter": {
"match_all": {
"boost": 1.0
}
},
"gauss": {
"price": {
"origin": 200,
"offset": 0,
"scale": "25",
"decay": 0.5
}
},
"weight": 2
}
],
"score_mode": "sum",
"boost_mode": "replace",
"max_boost": 3.4028235E38,
"boost": 1.0
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
1.1.4 自定义编写脚本
像上面都是 ES 提供给我们现成的功能函数,但是,用户的场景千千万,总有一个场景这些函数会不适合。比如,用户希望酒店的价格的结尾含 8 的评分更高呢。ES 提供的这些函数就不起作用了,但 ES 还提供了终极密法。你可以自定义脚本来决定每个文档的分数。
{
"from": 0,
"size": 12,
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{
"term": {
"price": {
"value": 50,
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"functions": [
{
"filter": {
"match_all": {
"boost": 1.0
}
},
"script_score": {
"script": {
"source": "doc['price'].size()==0?0:5",
"lang": "painless"
}
}
}
],
"score_mode": "sum",
"boost_mode": "replace",
"max_boost": 3.4028235E38,
"boost": 1.0
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
二、常用的字段解释
- 整体结构
如果需要使用自定义评分,评分查询结构和正常的查询结构还是有些区别的, 分页和排序和正常的都是一样的,主要还是 query 内的成员,使用的是 function_score。我们来看看图上图框住的就是自定义评分需要使用的特定的查询结构。看看里面是不是还有很多成员,接下来我一一为大家介绍这些成员的含义。

2.1 function_score
2.1.1 query
function_score 第一个成员 query,这个就和大家平时用的一样,筛选符合条件的结果,并把这个结果用作后面的评分函数的数据来源,我们来看看它内部的结构。下图框中,目的是为了查询 price 为 50 的结果

2.1.2 functions
functions,也是我们使用评分函数和编写脚本的地方,他的值是一个数组,也就是我们使用多个函数来进行综合评分,还可以对每个评分进行权重控制,主要有以下几个值
-
filter
filter 主要通过条件匹配结果作用在当前函数上
-
weight
weight 当前函数的权重,函数的分值会乘上 weight
-
ES 提供的几种评分模式,是脚本还是随机等
1. 衰减函数:
先看看官方的图,衰减函数的作用机制, 我们可以设定一个期望值,越接近期望值的分越高,分值在 0-1 之间,分别有三条对应的函数曲线 linear 、 exp 和 gauss (线性、指数和高斯函数)
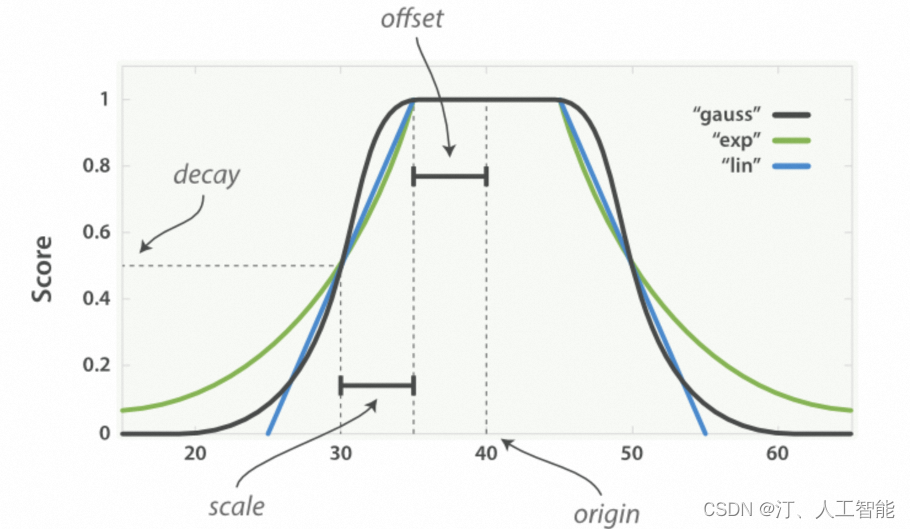
原点(origin):期望值,这个值可以得到满分(1.0)
偏移量(offset):与原点相差在偏移量之内的值也可以得到满分
衰减规模(scale):当值超出了原点到偏移量这段范围,它所得的分数就开始进行衰减了,衰减规模需配合衰减值一起使用。比如衰减规模是 500 米,衰减值是 0.5,那么在 500 米的时候分值就是 0.5,具体衰减速率由函数曲线决定
衰减值(decay):该字段可以被接受的值(默认为 0.5),相当于一个分界点,具体的效果与衰减的模式有关2. script_score:自定义脚本评分, 主要就是我们编写脚本的地方
| 值 | 描述 |
|---|---|
| source | 就是我们需要填写脚本的地方 |
| lang | 使用的脚本语言,几个可选值对应相应的开发语言 |
3. random_score:随机得到 0 到 1 分数
4. field_value_factor:将某个字段的值进行计算得出分数。
2.1.3 score_mode
score_mode,主要是控制我们多个评分函数之间如何运算的,比如 function_score 第一个元素会对结果进行评分,第二元素也会对结果进行评分,我们通过参数来控制这两个的评分是相加还是别的操作,这最终得出来的分值也称为功能分值。有以下几个可选值
| 函数名 | 描述 |
|---|---|
| max | 使用最高分 |
| first | 使用第一个评分函数的分值 |
| multiply | 多个评分函数分值相乘(默认) |
| avg | 多个评分函数分值的平均值 |
| sum | 多个评分函数分值的分数和 |
| min | 使用最小分 |
2.1.4 boost_mode
boost_mode,控制的是查询分值(下图框起来的 1 的部分)和功能分值(下图框起来的 2 的部分)是如何运算的。有以下几个可选值

| 函数名 | 描述 |
|---|---|
| max | 使用查询分数和功能分数里最大值 |
| replace | 使用功能分数,查询分数将被忽略 |
| multiply | 使用查询分数和功能分数相乘(默认) |
| avg | 使用查询分数和功能分数平均值 |
| sum | 使用查询分数和功能分数和 |
| min | 使用查询分数和功能分数里最小值 |
三、通过 ESJavaApi 实现自定义评分功能
public static void main(String[] args) {
/**构建functions**/
FunctionScoreQueryBuilder.FilterFunctionBuilder[] filterFunctionBuilders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[2];
//第一个评分函数,gauss
Map<String, Double> locationMap = new HashMap<String, Double>();
locationMap.put("lat", 130.11);
locationMap.put("lon", 12.12);
ScoreFunctionBuilder gaussFunctionByLocation = ScoreFunctionBuilders.gaussDecayFunction("location", locationMap, "150km", 0, 0.5);
filterFunctionBuilders[0] = new FunctionScoreQueryBuilder.FilterFunctionBuilder(gaussFunctionByLocation);
//第二个评分函数,自定义评分
String scriptLang = "painless";
String script = "doc['price'].size()==0?0:5";
ScriptScoreFunctionBuilder scriptFunction = ScoreFunctionBuilders.scriptFunction(new Script(Script.DEFAULT_SCRIPT_TYPE, scriptLang, script, Collections.emptyMap(), Collections.emptyMap()));
filterFunctionBuilders[1] = new FunctionScoreQueryBuilder.FilterFunctionBuilder(scriptFunction);
/**function_score**/
//构建query
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//设置query,functions
FunctionScoreQueryBuilder functionScoreQueryBuilder = new FunctionScoreQueryBuilder(boolQueryBuilder, filterFunctionBuilders);
//设置boostMode
functionScoreQueryBuilder.boostMode(CombineFunction.REPLACE);
//设置scoreMode
functionScoreQueryBuilder.scoreMode(FunctionScoreQuery.ScoreMode.SUM);
//设置分页排序
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.from(0);
sourceBuilder.size(12);
sourceBuilder.sort("price", SortOrder.ASC);
//执行
SearchRequest searchRequest = new SearchRequest("index_name");
searchRequest.source(sourceBuilder);
}
参考链接:
https://blog.csdn.net/qq_51641196/article/details/130074051?spm=1001.2014.3001.5502
https://blog.csdn.net/W2044377578/article/details/128636611
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 安全面试总结
- 禅道的使用
- 基于Java Web的“大学生艺术节”管理系统的设计与实现论文
- HBase 超大表迁移、备份、还原、同步演练手册:全量快照 + 实时同步(Snapshot + Replication)不停机迁移方案
- Uniapp微信小程序:轻松实现自定义导航栏,提升用户体验
- 论文速递 | Operations Research11月文章合集
- 【python入门篇】─Python函数(函数的参数,匿名函数,递归函数)
- 华为鸿蒙(HarmonyOS):连接一切,智慧无限
- 中科星图——Sentinel-2_MSI_L2A数据集
- 使用Python基于metricbeat和heartbeat采集数据进行告警