机器学习模型可解释性的结果分析
模型的可解释性是机器学习领域的一个重要分支,随着 AI 应用范围的不断扩大,人们越来越不满足于模型的黑盒特性,与此同时,金融、自动驾驶等领域的法律法规也对模型的可解释性提出了更高的要求,在可解释 AI?一文中我们已经了解到模型可解释性发展的相关背景以及目前较为成熟的技术方法,本文通过一个具体实例来了解下在 MATLAB 中是如何使用这些方法的,以及在得到解释的数据之后我们该如何理解分析结果。
要分析的机器学习模型
我们以一个经典的人体姿态识别为例,该模型的目标是通过训练来从传感器数据中检测人体活动。传感器数据包括三轴加速计和三轴陀螺仪共6组数据,我们可以通过手机或其他设备收集,训练的目的是识别出人体目前是走路、站立、坐、躺等六种姿态中的哪一种。我们将收集到的数据做进一步统计分析,如求均值和标准差等,最终获得18组数据,即18个特征。然后可以在 MATLAB 中使用分类学习器 App 或者通过编程的形式进行训练,训练得到的模型混淆矩阵如下,可以看到对于某些姿态的识别,模型会存在一定误差。那么接下来我们就通过一系列模型可解释性的方法去尝试解读一下错误判别的来源。
从混淆矩阵中可以看到,模型对于躺 ‘Laying’ 的姿态识别率为 100%,而对于正常走路和上下楼这三种 ‘Walking’ 的姿态识别准确率较低,尤其是上楼和下楼均低于70%。这也符合我们的预期,因为躺的姿态和其他差别较大,而几种走路之间差异较小。
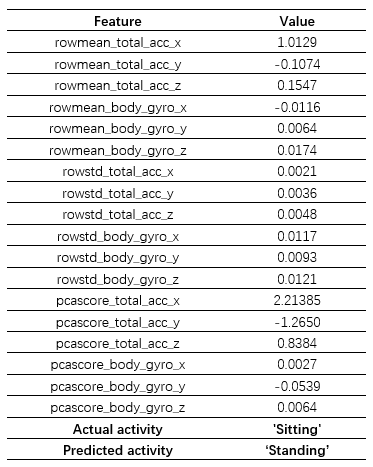
但我们也留意到模型在 ‘Sitting’ 和 ‘Standing’ 之间也产生了较大的误差,考虑到这两者之间的差异,我们想探究一下产生这种分类错误背后的原因。首先我们从图中所示的区域选择了一个样本点 query point,该样本的正确姿态为 ‘Sitting’,但是模型识别成了 ‘Standing’,为便于下一步分析,这里将该样本点所有特征及其取值列举了出来,如前所述一共 18 个,分别对应于原始的6个传感器数据的平均值、标准差以及第一主成分:
使用可解释性方法进行分析
模型可解释性分析的目的在于尝试对机器学习黑盒模型的预测结果给出一个合理的解释,定性地反映出输入数据的各个特征和预测结果之间的关系。对于预测正确的结果,我们可以判断预测过程是否符合我们基于领域知识对该问题的理解,是否有一些偶然因素导致结果碰巧正确,从而保证了模型可以在大规模生产环境下做进一步应用,也可以满足一些法规的要求。
而对于错误的结果,如上文中的姿态识别,我们可以通过可解释性来分析错误结果是由哪些因素导致的,更具体地说,即上述 18 个特征对结果的影响。在此基础上,可以更有针对性地进行特征选择、参数优化等模型改进工作。
接下来我们就尝试用几种不同的可解释性方法来对上文中的 query point 做进一步分析,希望可以找到一些模型分类错误的线索。
2.1 Shapley 值
我们尝试的第一个方法是 Shapley 值,Shapley 值起源于合作博弈理论,它基于严格的理论分析并给出了完整的解释。作为一个局部解释方法,Shapley 值通过对所有可能的特征组合依次计算,从而得到每个特征对预测结果的平均边际贡献,并且这些值是相对于该分类的平均得分而言的。可以简单理解为边际贡献的分值越高,对产生当前预测结果的影响越大。因为有着完善的理论基础且发展时间较长,Shapley 值被广泛应用于金融领域来满足一些法律法规的要求。
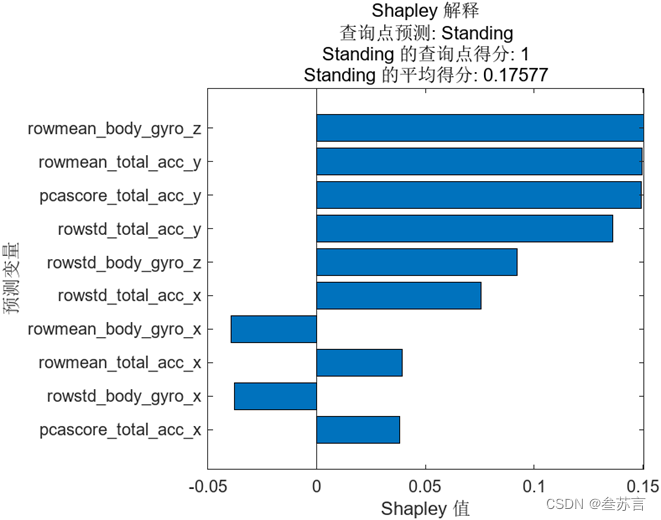
我们之前已经了解到 Shapley 值反应的是每个特征的平均边际贡献,并且这些值是相对于该分类的平均得分而言的。首先需要计算出 ‘Standing’ 的平均得分,我们会将数据集中所有点关于 ‘Standing’ 的预测得分取平均得到相应的值,即 0.17577。而我们关注的样本点预测为 ‘Standing’ 的得分为 1,相对较高,它和所有点的平均值相比差值为 0.82423,Shapley 值反应的正是该样本点中每个特征对这个差值的贡献,其总和也正是 0.82423。
图中显示了排行前十的特征及对应的 Shapley 值,我们可以看到 rowmean_body_gyro_z 的值最大,说明它对错误判别的影响最大,当然紧随其后的几个特征的 Shapley 值也较为接近。
特征 rowmean_body_gyro_z的实际含义为z方向陀螺仪的平均值,为什么这个特征可能导致了错误的结果?我们可以接着往下分析。
2.2 PDP - Partial Dependency Plot
Shapley 值虽然很清晰地给出了各个特征对于最终预测结果的贡献,但是我们需要更多的信息来分析错误产生的来源,一个有效的方法是结合 PDP 又称部分依赖图来进行查看。
PDP 是一个全局解释方法,关注单个特征对某一预测结果的整体影响,其思想是假设所有样本中的该特征等于某一个固定值,从而计算出一个预测结果的平均值。当我们将该特征取一系列值时(取值范围仍然来源于样本),便可以绘制出对应的曲线。我们接着 Shapley 值的分析选择特征 rowmean_body_gyro_z(对应数据中的位置为第6个特征),以及 query point 对应的真实分类 ‘Sitting’ 和错误分类 ‘Standing’ 分别绘制 PDP,在 MATLAB 中使用的方法仍然非常简单,具体代码及对应结果如下:
plotPartialDependence(model,6,'Sitting');
% rowmean_body_gyro_z is the 6th predictor in our data table
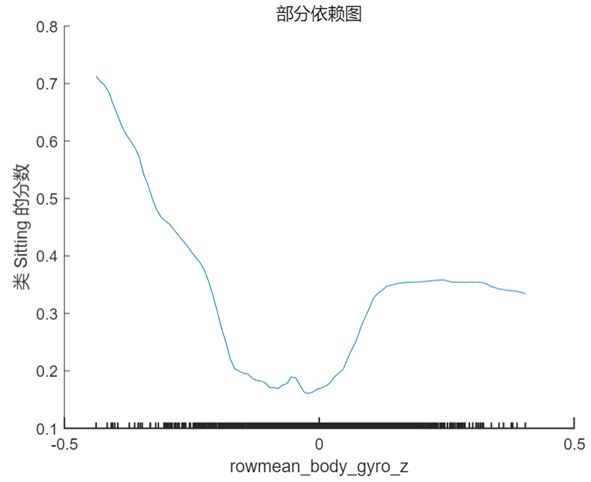
plotPartialDependence(model,6,'Standing');
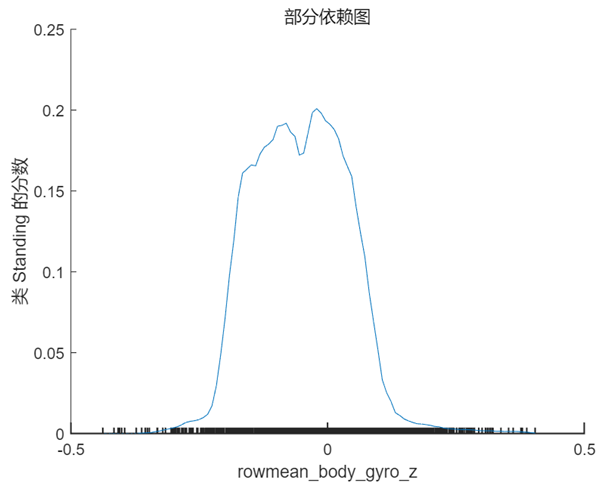
根据上图以及第 1 节中 query point 在该特征的实际取值 0.017 可以看出,当该特征的取值接近于 0 时,分类为 ‘Standing’ 的分数较高,而当取值向两端靠拢尤其是接近于 -0.5 时分类为 ‘sitting’ 的分数较高,甚至大于 0.5,这也符合该点的实际预测值。
通过部分依赖图我们对 Shapley 值的分析结果有了更清楚的认识,虽然该样本点的预测结果是错误的,但结合原始数据可以看出,这样的结果是有迹可循且合理的。
在讨论下一步工作之前,我们再尝试一个新的可解释性方法。
2.3 LIME - Local Interpretable Model-Agnostic Explanations
除了 Shapley 值,LIME 是另外一个应用广泛的局部解释方法,其简单易理解,基本思想是针对关注的样本点,在附近范围内生成扰动数据并用黑盒模型获得对应的预测结果,然后使用这些数据训练出一个局部近似的可解释模型,通过该模型帮助分析原始机器学习模型的预测过程。MATLAB 中可以使用线性模型与决策树模型作为局部的可解释模型。
值得一提的是,由于近似模型的训练使用随机生成的扰动数据,模型的预测结果以及特征排序也会出现一定的随机性。我们仍然考虑上文中姿态识别模型的 query point,使用线性模型对该点做近似分析,具体代码及结果如下:
limeObj = lime(model, humanActivityData,?'QueryPoint',queryPt,'NumImportantPredictors',6);
f = plot(limeObj);
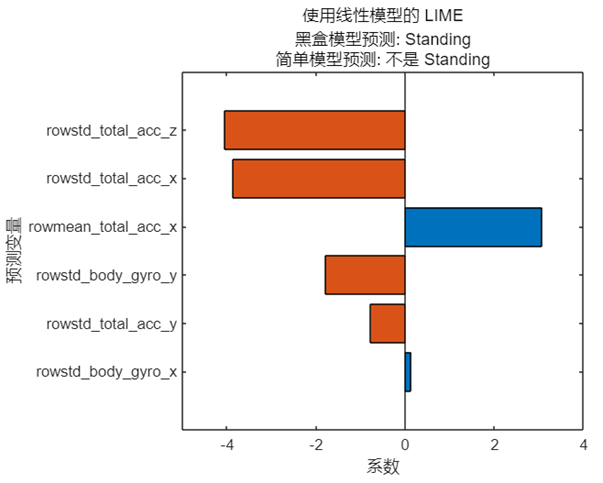
由于是线性模型,预测结果只是简单地给出是否为 ‘Standing’,而横坐标反映的是线性模型中每个特征对应的系数。一个有趣的现象是简单模型的预测结果与黑盒模型的预测结果并不相同,这是否意味着这样的结果是无效的、甚至是错误的?
我们先来选择 rowstd_total_accd_z 与 towmean_total_acc_x,即系数正值和负值中绝对值最大的两个特征(对应在数据中的位置为 9 和 1),采用上文中介绍的方法分别绘制 PDP,我们将 ‘Sitting’ 和 ‘Standing’ 两个类别的曲线绘制在一张图中,结果如下:
plotPartialDependence(model,9,{'Sitting','Standing'}, humanActivityDataTest)
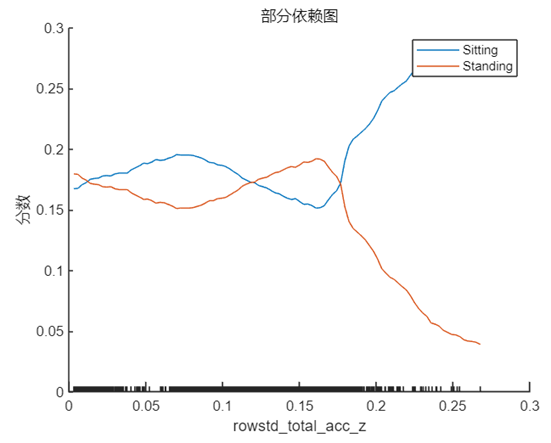
plotPartialDependence(model,1,{'Sitting','Standing'}, humanActivityDataTest);
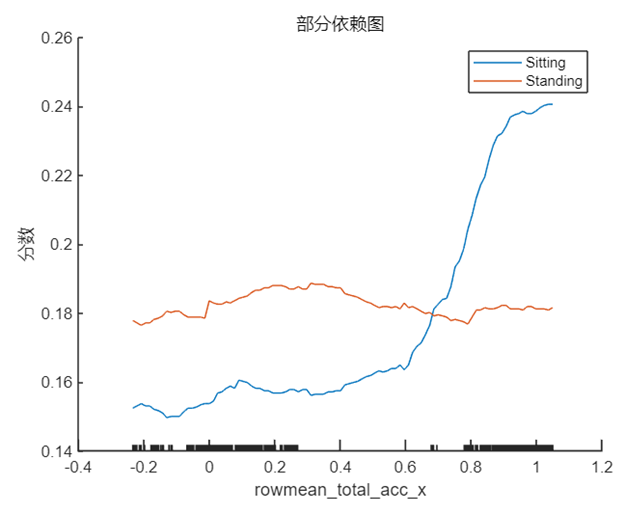
这两个特征分别代表 z 方向加速度的标准差与 x 方向加速度的均值,结合第 1 节中其在该样本点的实际取值 rowstd_total_acc_z=0.0048 以及 rowmean_total_acc_x=1.0129 可以看出,1.0129 对于模型做出正确预测会起到十分积极的作用,这可能也是简单模型能够做出不是 ‘Standing’ 的原因,因为站立的姿态通常不会在 x 方向产生较大的加速度,与此同时简单模型的 rowstd_total_acc_z 的系数虽然很大,但是取值较小,这意味着z方向加速度标准差较小,数据比较集中,从 PDP 中也能看出在该点对于 ‘Standing’ 和 ‘Sitting’ 的区分度并不高,要在数值增大之后才会对结果有较为显著的影响。
需要说明的是,通过 LIME 得到的特征排序(或系数大小)和 Shapley 值得到的结果相差较大,部分原因是在 LIME 中基于随机扰动生成的数据得到的模型和黑盒模型原本就存在一定差异,可以尝试使用不同的随机数或使用其他简单模型来得到多样化的结果进行对比分析。
回到刚才的问题,这样的简单模型是否是无效的?其实机器学习的模型预测本身是一个十分复杂的过程,这是与黑盒模型强大的功能分不开的,无论是哪种解释方法,目的都是帮助我们窥探预测的机理,从某一个角度理解分析产生这样结果的原因,这些不同的角度相结合可以让我们逐渐接近一个更加全面的分析结果,因此都是有意义的。
后续工作
获得模型的解释结果只是第一步,在得到以上分析结果之后我们接下来可以做些什么呢?
现在我们已经知道 rowmean_body_gyro_z, rowstd_total_acc_z 等几个特征对错误的分类结果有较大影响,我们可以进一步从原始数据分析更深层次的原因,比如我们采集的这个样本点的数据是否有误差?如果原始数据没问题,那么求平均值或标准差的特征提取方式是否合适?是否应该选择更加复杂的统计方式获取特征?在模型的训练阶段是否可以通过修改代价函数等手段提高预测准确率?
显然通过对一个样本的分析,就得出关于整个模型的结论是不严谨的。以上分析结果提供给了我们一些思路和线索,我们可以对更多样本点做类似分析,再结合其他手段去做下一步的改进。
采用类似的方法,我们还可以对判断正确的样本进行可解释性的分析,来和我们对该问题的先验知识进行对比,从而验证模型是否正确。
???免费分享一些我整理的人工智能学习资料给大家,整理了很久,非常全面。包括一些人工智能基础入门视频+AI常用框架实战视频、图像识别、OpenCV、NLP、YOLO、机器学习、pytorch、计算机视觉、深度学习与神经网络等视频、课件源码、国内外知名精华资源、AI热门论文等。
下面是部分截图,加我免费领取
目录
一、人工智能免费视频课程和项目
二、人工智能必读书籍
最后,我想说的是,自学人工智能并不是一件难事。只要我们有一个正确的学习方法和学习态度,并且坚持不懈地学习下去,就一定能够掌握这个领域的知识和技术。让我们一起抓住机遇,迎接未来!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以点击链接领取?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringBoot ElasticSearch 聚合排序
- 一文稿定 Postman 接口自动化测试
- 【Jenkins】Pipeline 简单使用
- HTML代码加固:保障网站安全
- 【通义千问】大模型Qwen GitHub开源工程学习笔记(5)-- 模型的微调【全参数微调】【LoRA方法】【Q-LoRA方法】
- 【2058错误】sql软件链接数据库 mysql 报错误2058
- 你是无醇葡萄酒的爱好者吗?
- Unity布料系统Cloth
- 前端 position定位
- Python采集微博评论做词云图