浪花 - 主页性能优化
发布时间:2024年01月20日
目录
4. 使用?Spring Data Redis 中操作 Redis
一、缓存
1. 为什么用缓存?
- 数据量大查询慢,用缓存先读取部分数据保存到读写性能更快的介质中(比如内存)
2. 缓存的实现方式
- 分布式缓存:Redis、Memcache 等
- 单机缓存:Ehcache、Caffeine(Java 内存缓存,高性能)、Google Guava
- 单机缓存的缺点:数据不一致
3. Redis
- Remote Dictionary Server(远程词典服务器)
- 基于内存的高性能 NoSQL 数据库
- key - value 存储系统
- Redis 的数据结构:String、Set、Map、Hash、SortedSet
4. 使用?Spring Data Redis 中操作 Redis
- Spring Data:通用数据访问框架,定义了一组增删改查的框架,包括对操作各种数据库的集成
- 使用步骤参考:浪花 - 单机登录升级为分布式 Session 登录-CSDN博客
-
SpringDataRedis 快速入门
- 引入 spring-boot-starter-data-redis 依赖
- application.yml 配置 Redis 信息
- 注入 RedisTemplate
- 调用方法操作 Redis 数据库
- 调用 redisTemplate 中的 API 获取操作指定数据类型的对象 optForValue()
- String Redis Template
- 手动序列化
- 将数据存入 Redis
- 取出数据
- 手动反序列化
/**
* Redis 操作测试
* @author 乐小鑫
* @version 1.0
*/
@SpringBootTest
public class RedisTest {
@Resource
private RedisTemplate redisTemplate;
@Test
void test() {
ValueOperations valueOperations = redisTemplate.opsForValue();
// 增
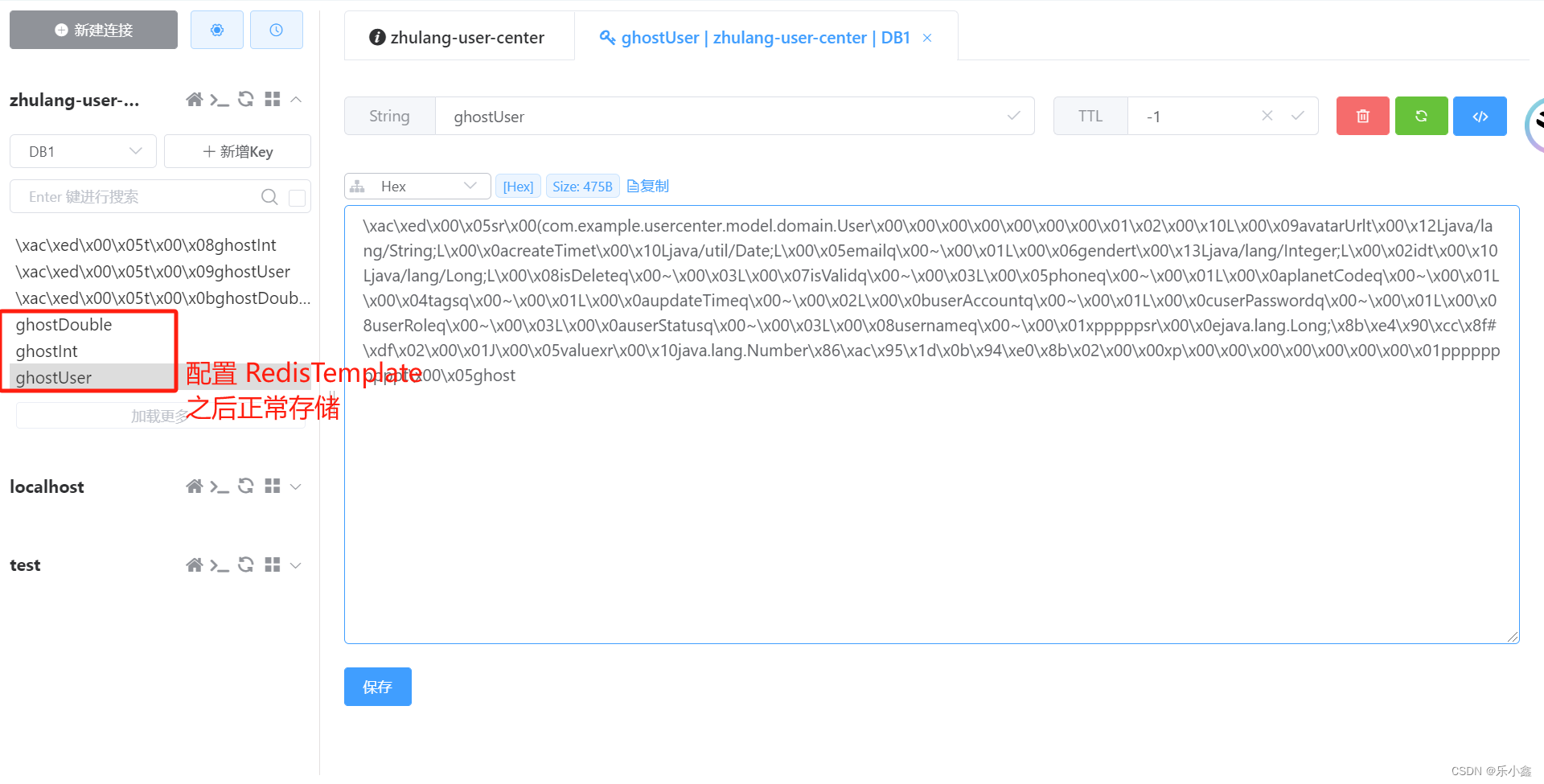
valueOperations.set("ghostString", "dog");
valueOperations.set("ghostInt", 1);
valueOperations.set("ghostDouble", 2.0);
User user = new User();
user.setId(1L);
user.setUsername("ghost");
valueOperations.set("ghostUser", user);
// 查
Object ghost = valueOperations.get("ghostString");
Assertions.assertTrue("dog".equals((String) ghost));
ghost = valueOperations.get("ghostInt");
Assertions.assertTrue(1 == (Integer) ghost);
ghost = valueOperations.get("ghostDouble");
Assertions.assertTrue(2.0 == (Double) ghost);
System.out.println(valueOperations.get("ghostUser"));
valueOperations.set("ghostString", "dog");
redisTemplate.delete("ghostString");
}
}
5. 自定义 RedisTemplate(配置)
- 原生提供的序列化器存储对象时序列化有问题,自定义 RedisTemplate 实现存储 String 类型的 key
/**
* RedisTemplate 配置
* @author 乐小鑫
* @version 1.0
*/
@Configuration
public class RedisTemplateConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
redisTemplate.setKeySerializer(RedisSerializer.string());
return redisTemplate;
}
}
6. 主页推荐用户查询使用缓存
- 不同用户看到的推荐列表不同
- 设计缓存 key
- 在每个键前面加上系统 / 模块 / 业务 / 功能 的前缀,以区分不同业务的缓存
- Redis 内存不能无限增加,一定要设置过期时间!!如果快到限制值了,会开启 Redis 的自动淘汰机制,可能会把重要数据清除掉
直接使用单层的 key 作为键可能会对其他业务产生影响,例如以 username 为 key,其他业务可能也用 username 为 key,用的是同一台 Redis 服务器时会影响其他业务的数据。
设计缓存首先的原则是不要和其他 key 发生冲突
- 推荐用户时先查询缓存中是否有已经缓存好的用户
- 有缓存:直接返回缓存中的数据
- 无缓存:先查询数据库,将数据库中的缓存写入 Redis,再返回数据
- 注意缓存穿透:数据库中没有要查询的数据,但是客户端一直不停发送请求查询数据,缓存中没有,查询就会打到数据库,不停查询缓存中都没有数据,就会不停执行数据库的查询,占用数据库资源,可能会把数据库搞崩
- 解决缓存穿透:缓存空值,即如果数据库中没有数据,就向 Redis 中缓存一个空值,下次再来查询,查询打到 Redis,发现有一个空值就会直接空值,不再查询数据库
/**
* 用户推荐
* @param request
* @return 用户列表
*/
@GetMapping("/recommend")
public BaseResponse<Page<User>> recommendUsers(long pageSize, long pageNum, HttpServletRequest request) {
log.info("推荐用户列表");
ValueOperations valueOperations = redisTemplate.opsForValue();
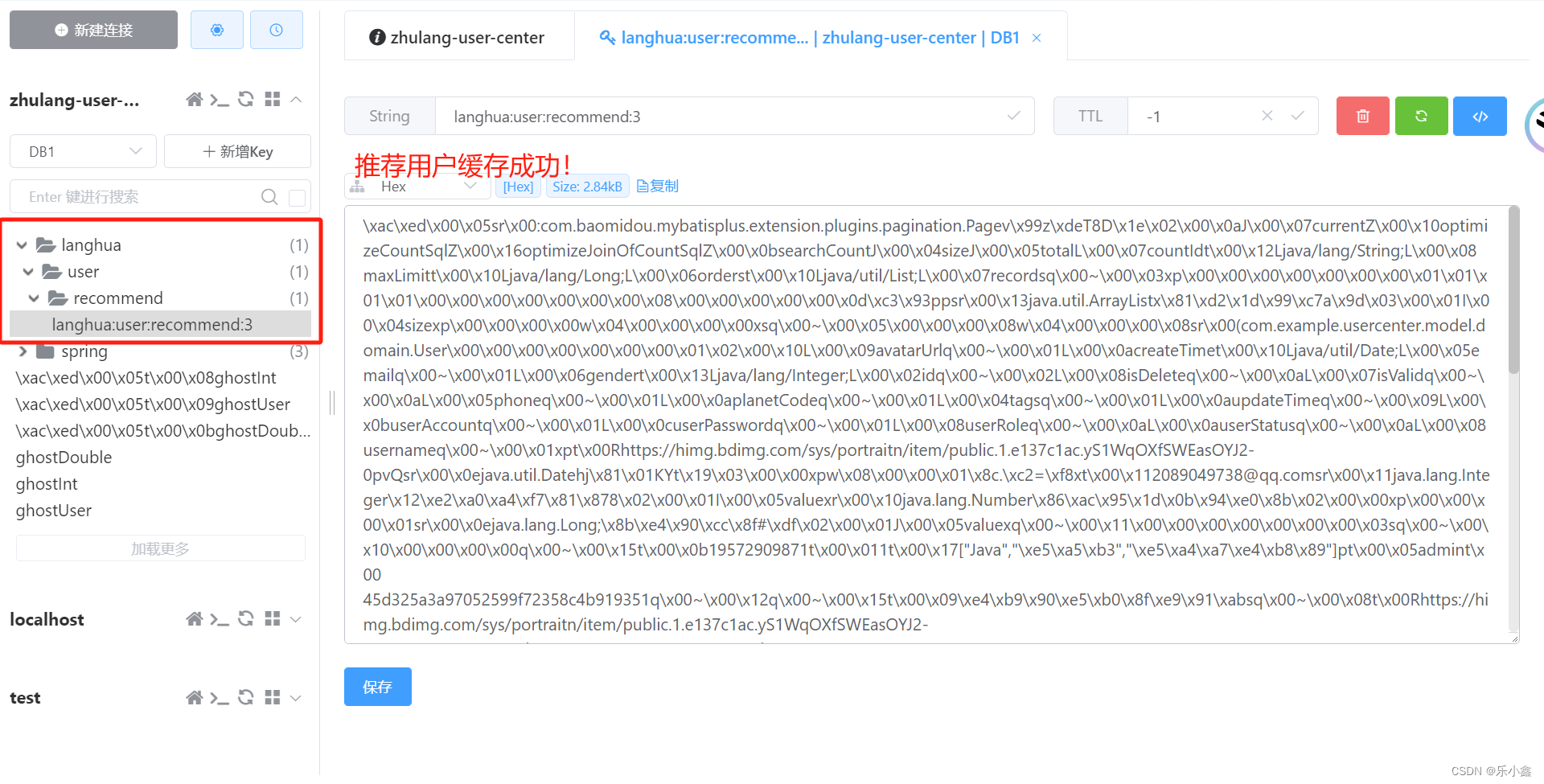
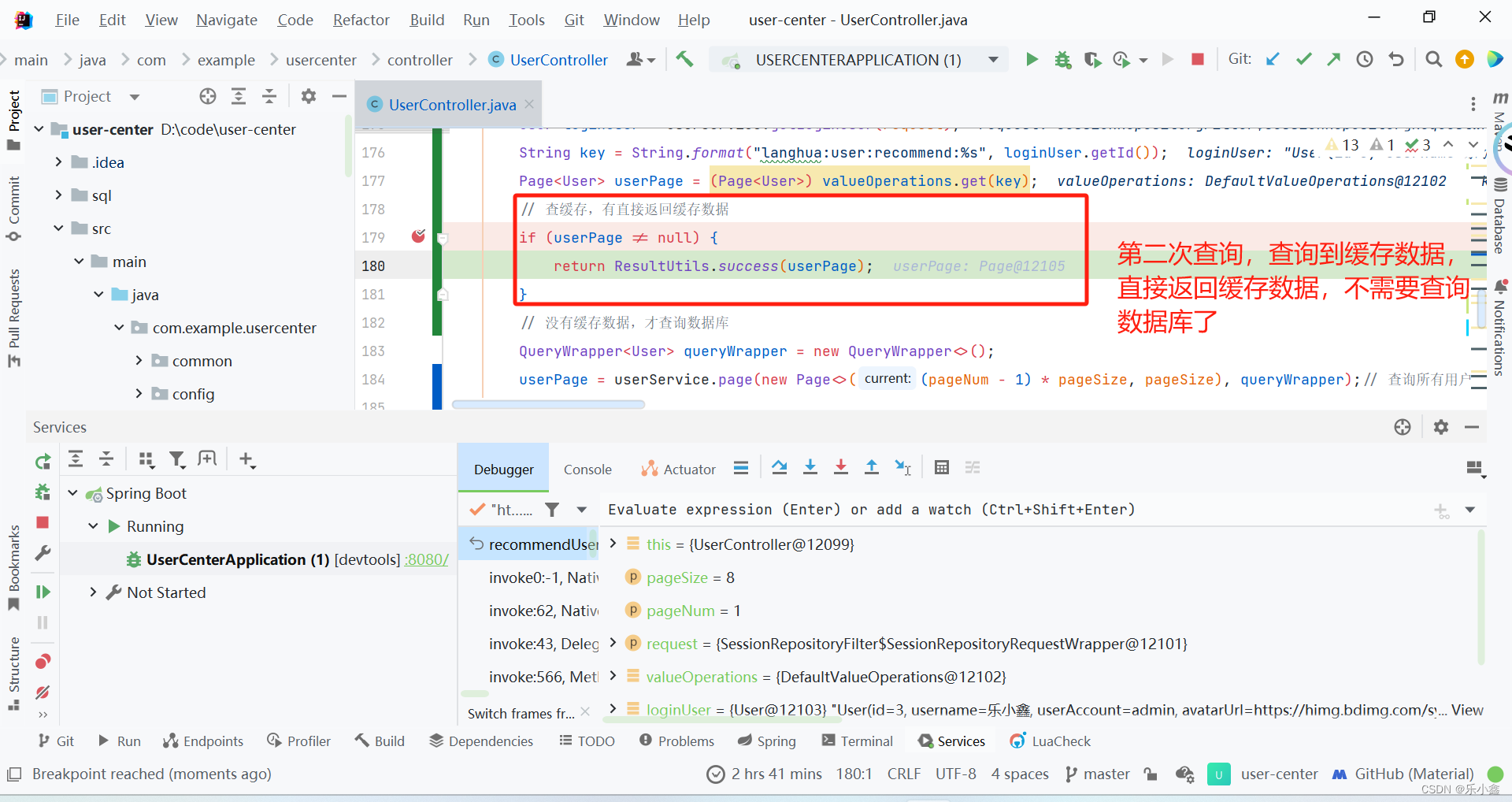
User loginUser = userService.getLoginUser(request);
String key = String.format("langhua:user:recommend:%s", loginUser.getId());
Page<User> userPage = (Page<User>) valueOperations.get(key);
// 查缓存,有直接返回缓存数据
if (userPage != null) {
return ResultUtils.success(userPage);
}
// 没有缓存数据,才查询数据库
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
userPage = userService.page(new Page<>((pageNum - 1) * pageSize, pageSize), queryWrapper);// 查询所有用户
// 将查询出来的数据写入缓存
try {
valueOperations.set(key,userPage);
} catch (Exception e) {
log.error("redis key set error", e);
}
return ResultUtils.success(userPage);
}
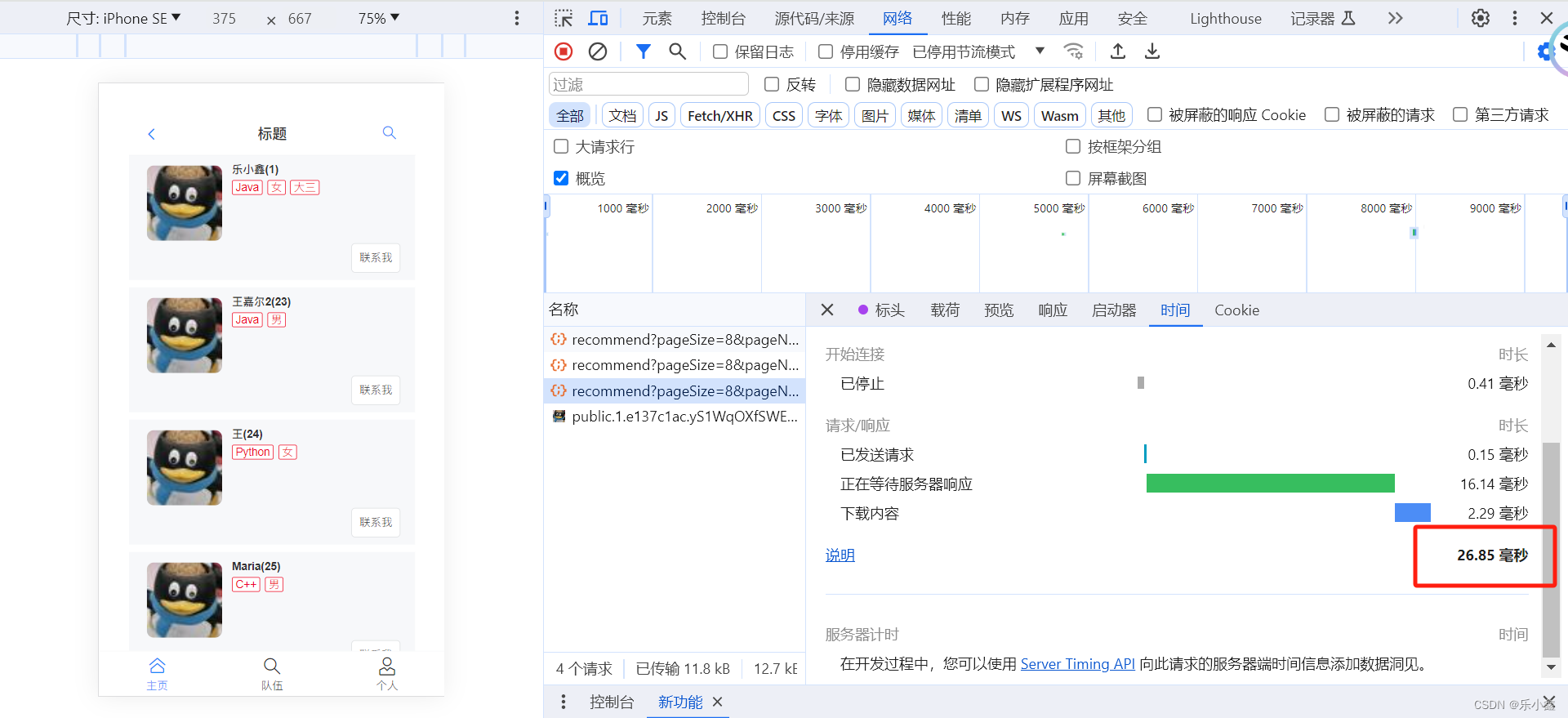
7. 对比查询速度
- 第一次查询:缓存中没有数据,请求打到数据库,1.13 秒

- 后续查询:缓存中已经缓存了用户列表数据,直接返回缓存数据,26.85 毫秒,性能优化显著
8. 缓存预热
- 为什么要缓存预热?
场景分析:当缓存里没有数据时,第一个用户进来需要查询数据库才能看到响应数据,页面响应时间较久,对有些用户不友好
解决方案:在所有用户进入之前预先缓存好数据,程序员自己加载缓存,而不是等到用户进入再触发
- 优点:每个用户来访问响应都很快,提升用户体验
- 缺点
- 增加开发成本
- 预热时机需要谨慎选择:预热的时机太早可能会缓存到错误数据或老数据
- 需要占用额外空间
注意?在分析一个技术的优缺点时,要从整个项目从 0 到 1 的整个软件生命周期去考虑(需求分析开始到项目部署上线和维护)
- 缓存预热的实现
- 定时任务
- 手动触发
二、定时任务
使用定时任务,每天刷新所有用户的推荐列表(缓存预热)
- 缓存预热的意义(新增数据少、总数据量大)
- 缓存占用空间不能太大,需要给其他缓存预留空间
- 缓存数据的周期(根据业务需求来选择)
1. Spring Scheduler
- SpringBoot 默认已经整合,直接使用即可
- 使用步骤
- 主类(程序入口)添加注解开启定时任务支持:@EnableScheduling
- 要定时执行的方法添加 @Scheduled 注解
- 通过 cron 表达式指定定时任务执行周期:在线Cron表达式生成器 (qqe2.com)
- ?运行项目等待定时任务执行
/**
* 缓存预热定时任务
* @author 乐小鑫
* @version 1.0
*/
@Component
@Slf4j
public class PreCacheUser {
@Resource
private RedisTemplate redisTemplate;
@Resource
private UserService userService;
List<Long> mainUserList = Arrays.asList(3L);// 重要用户列表,为该列表的用户开启缓存预热
@Scheduled(cron = "0 5 21 ? * * ")
public void doPreCacheUser() {
// 查出用户存到 Redis 中
for (Long userId : mainUserList) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Page<User> userPage = userService.page(new Page<>(1, 20), queryWrapper);// 查询所有用户
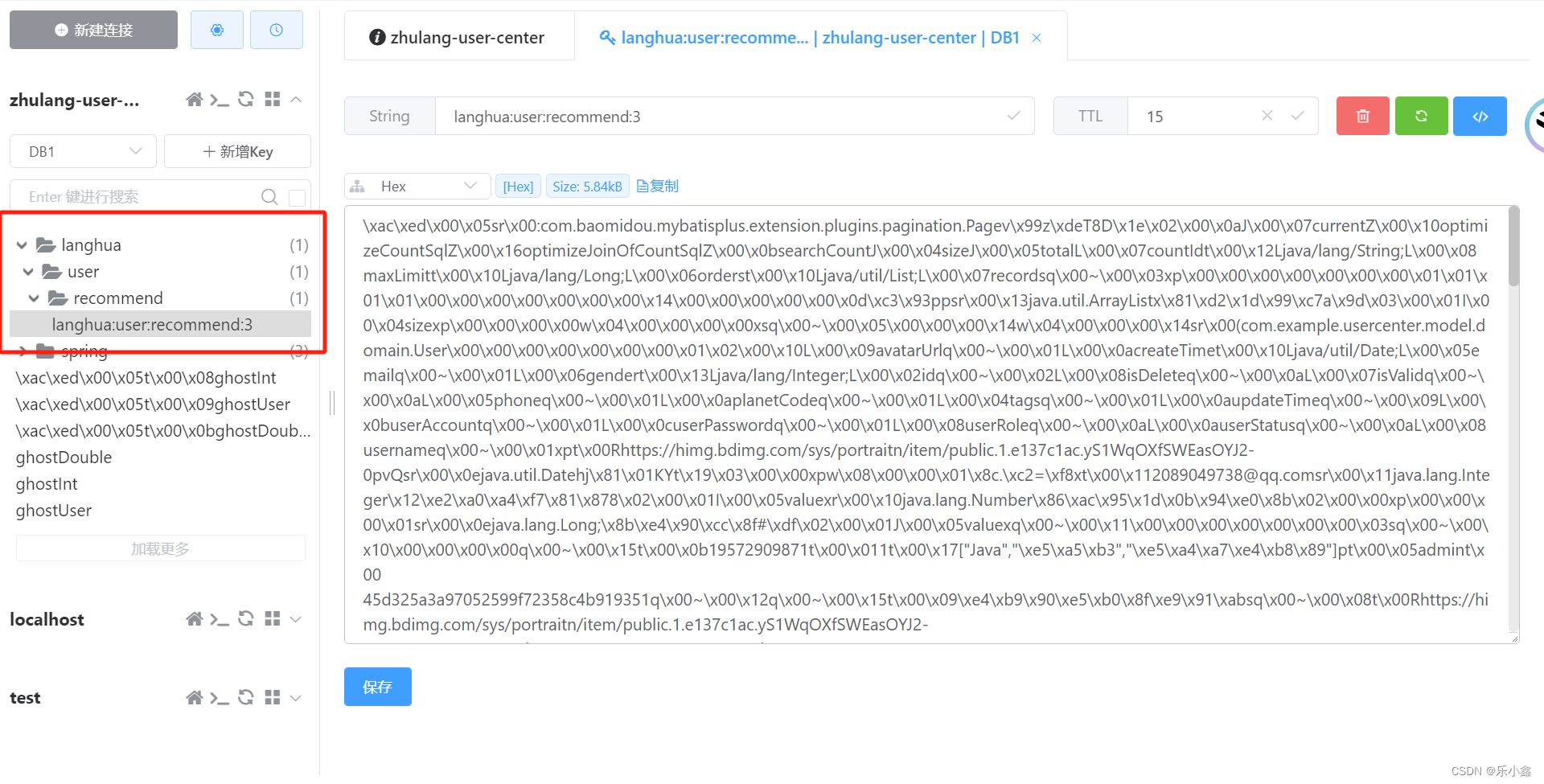
String key = String.format("langhua:user:recommend:%s", userId);
ValueOperations valueOperations = redisTemplate.opsForValue();
// 将查询出来的数据写入缓存
try {
valueOperations.set(key,userPage,30000, TimeUnit.MILLISECONDS);
} catch (Exception e) {
log.error("redis key set error", e);
}
}
}
}
- 定时任务添加缓存成功??
2. 其他
- Quartz:独立于 Spring 的定时任务框架
- XXL-Job 等分布式任务调度平台
文章来源:https://blog.csdn.net/m0_74059961/article/details/135713223
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 发动机装备3d虚拟在线云展馆360度展示每处细节
- 上海东海职业技术学院低代码实训平台建设项目竞争性磋商公告
- PyInstaller打包Django项目生成exe文件
- Pytest:单元测试的宠儿,让 Bug 无处藏身!
- 使用Python的pymysql库连接MySQL数据库
- 【苏州】买套二手房需要多少钱?
- 11.java面向对象
- 下一站,上岸@24考研er
- 学习笔记:C++之 switch语句
- 第7章-第9节-Java中的Stream流(链式调用)