python基础语法
PyCharm中
if __name__ == "__main__":
'''
使用main+回车即可
'''
一、Python 中文编码
Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法为只要在文件开头加入# -*- coding: UTF-8 -*-或者# coding=utf-8就行了
ps: 注意:# coding=utf-8 的 = 号两边不要空格。
# -*- coding: UTF-8 -*-
print( "你好,世界" )
二、多行语句
Python语句中一般以新行作为语句的结束符。
但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:
total = item_one + \
item_two + \
item_three
ps: 注意括号中的不需要\来维护换行
三、注释
python中单行注释采用 # 开头。
python 中多行注释使用三个单引号 ‘’’ 或三个双引号 “”"。
# 文件名:test.py
# 第一个注释
print ("Hello, Python!") # 第二个注释
'''
这是多行注释,使用单引号。
这是多行注释,使用单引号。
这是多行注释,使用单引号。
'''
"""
这是多行注释,使用双引号。
这是多行注释,使用双引号。
这是多行注释,使用双引号。
"""
四、变量
Number(数字)
String(字符串)
bool(布尔类型)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典)
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
1、多变量赋值
a = b = c = 1
2、判断类型
isinstance()
type()
isinstance 和 type 的区别在于:
type()不会认为子类是一种父类类型。
isinstance()会认为子类是一种父类类型。


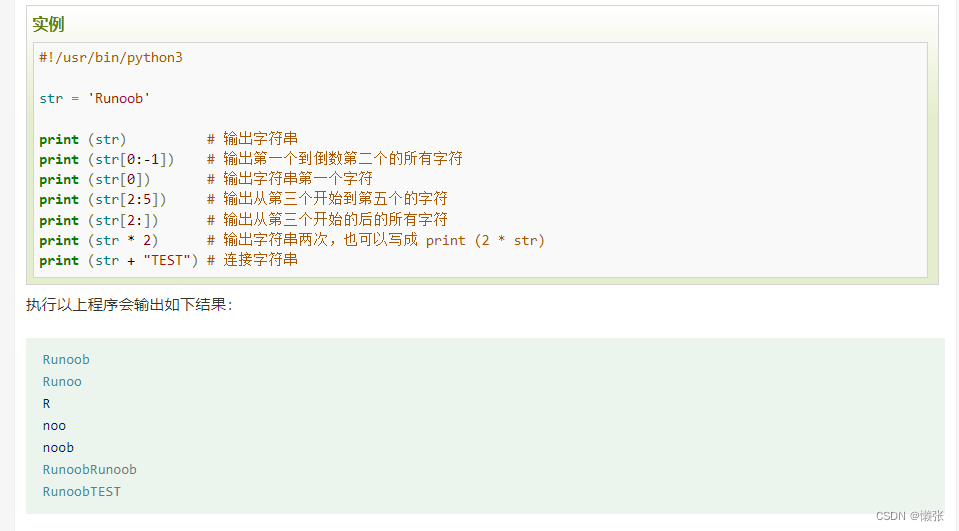
3、字符String
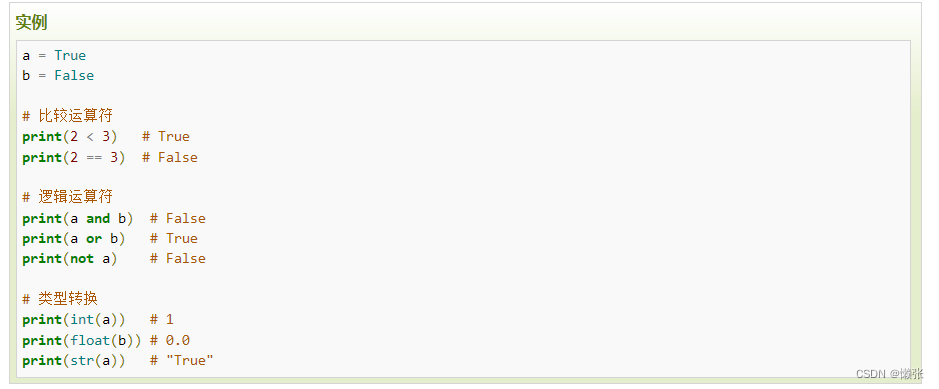
4、布尔
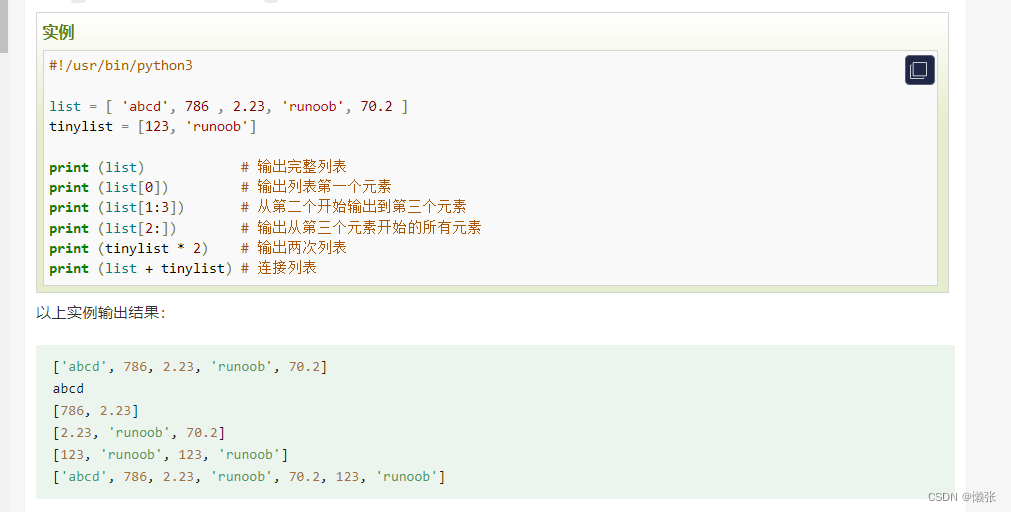
5、List(列表)
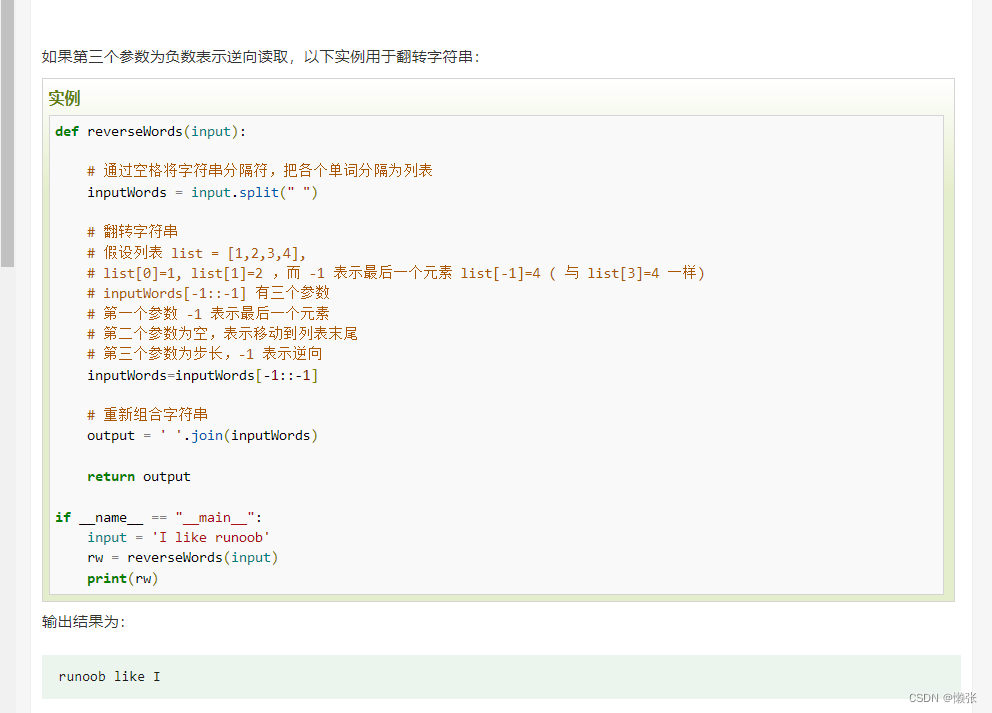
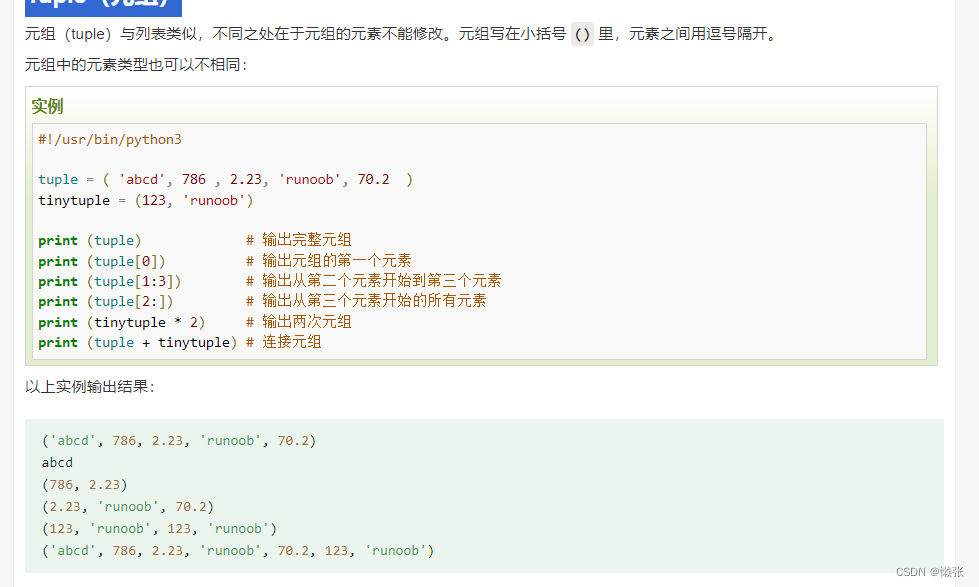
6、Tuple(元组)
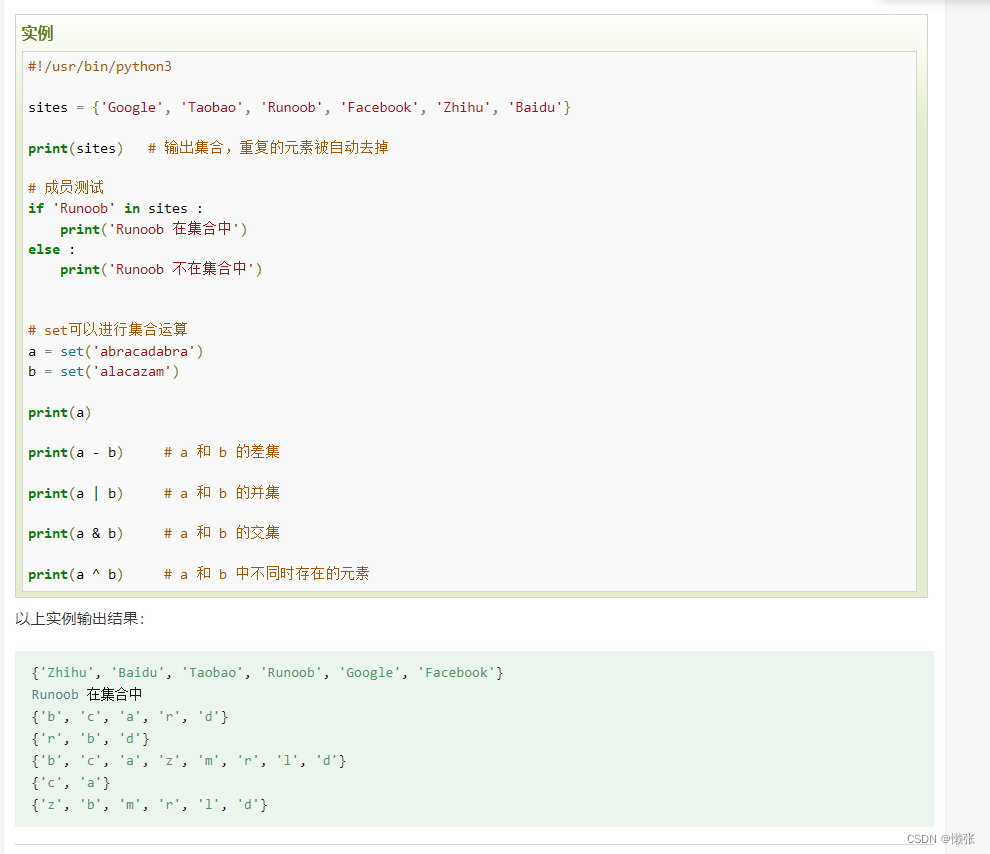
7、Set(集合)
8、 Dictionary(字典)
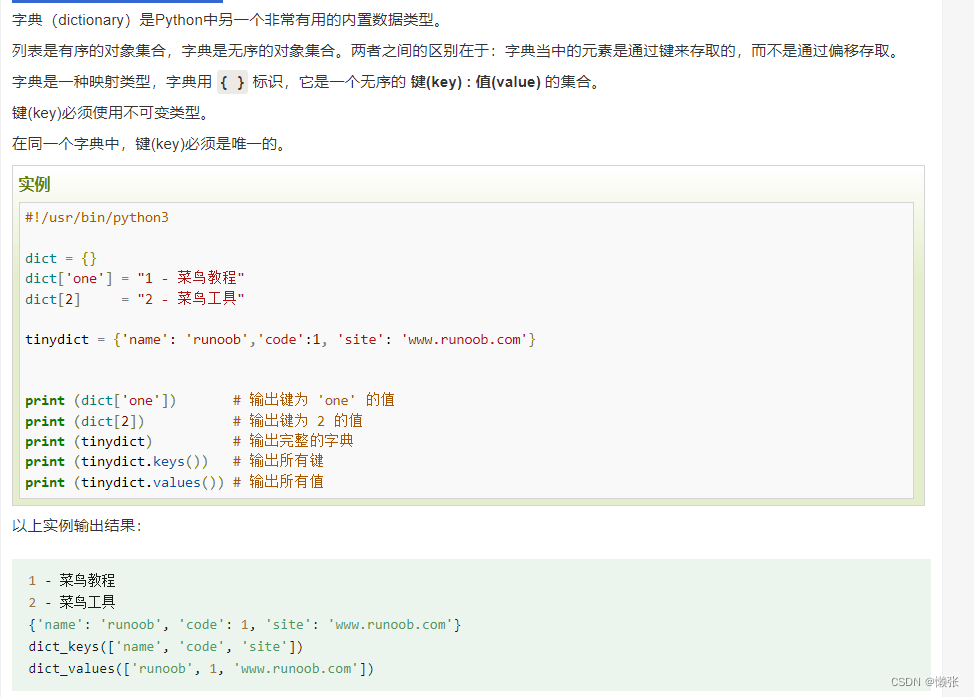
也可以aa = {“zzz”:“zzz”}
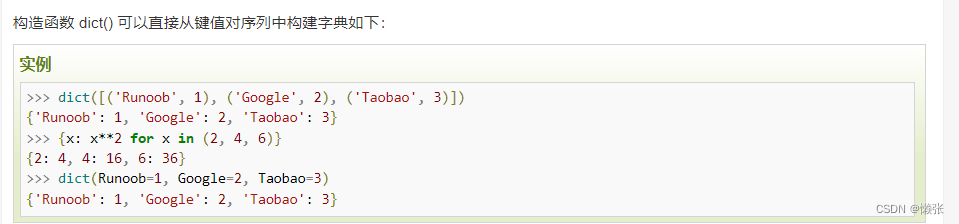
9、推导式
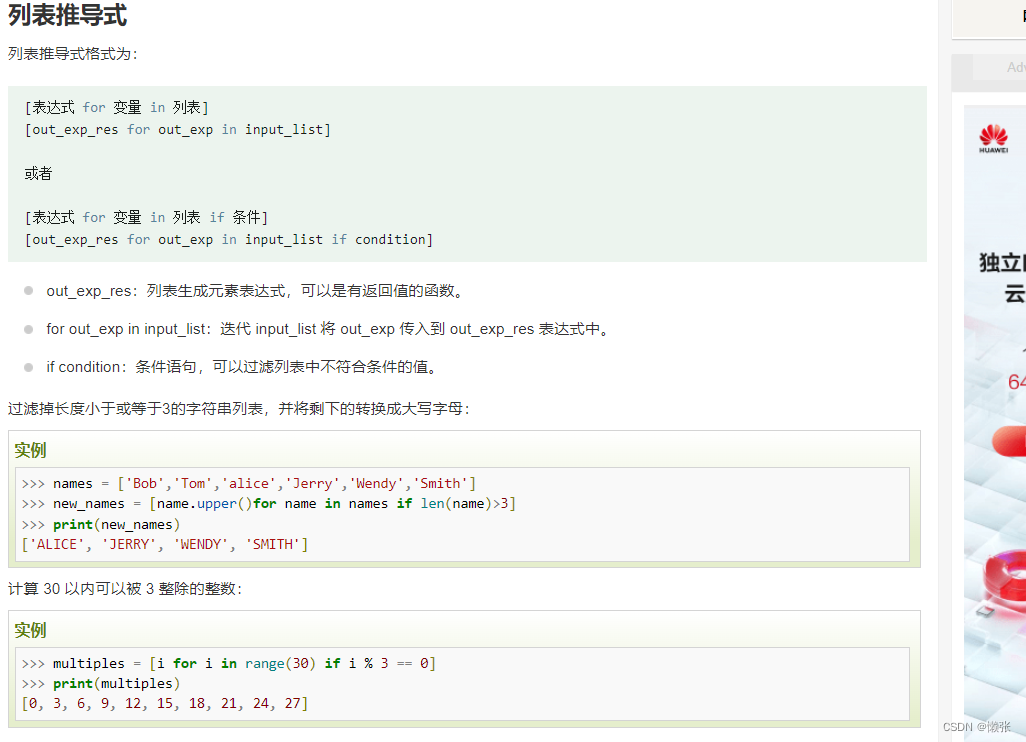
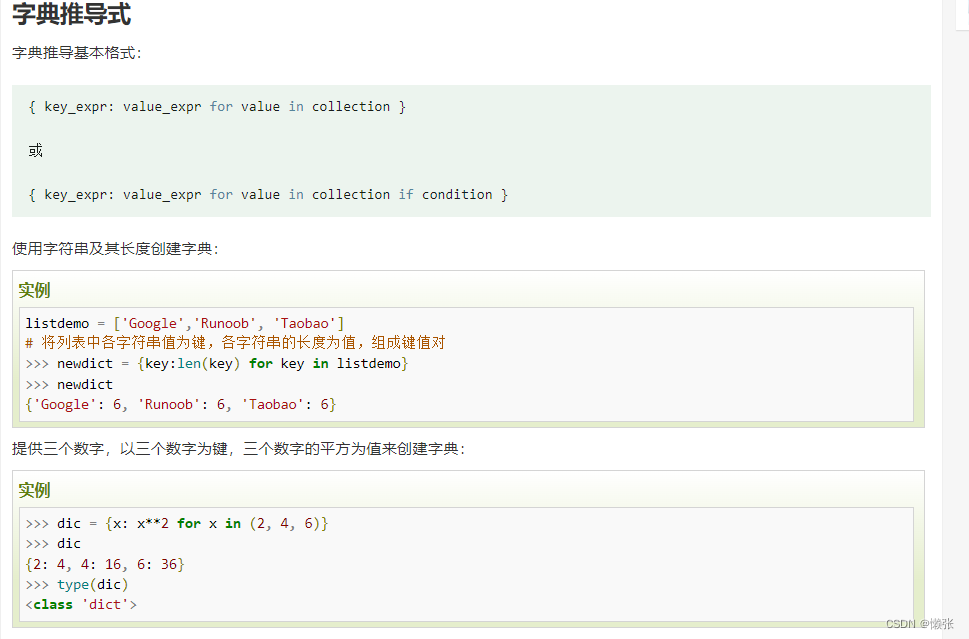
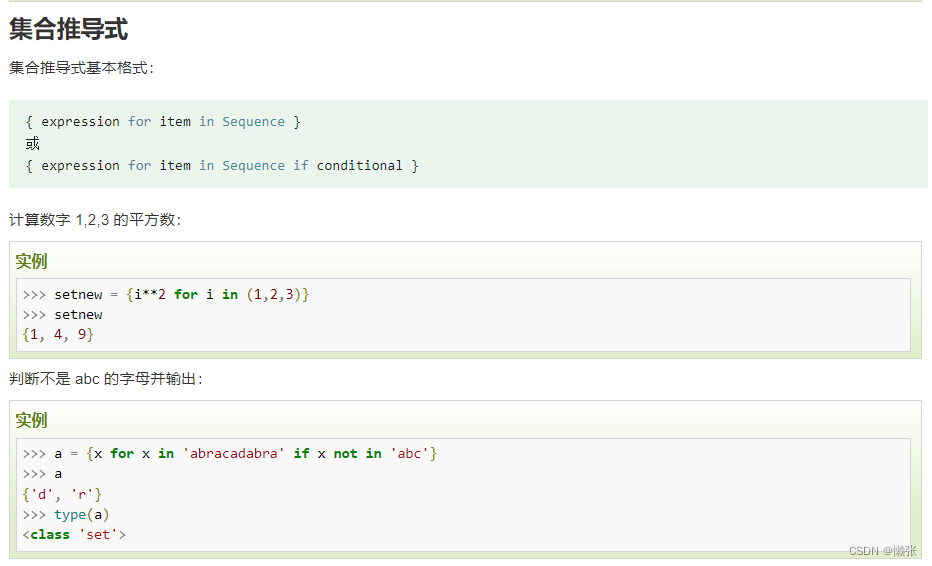
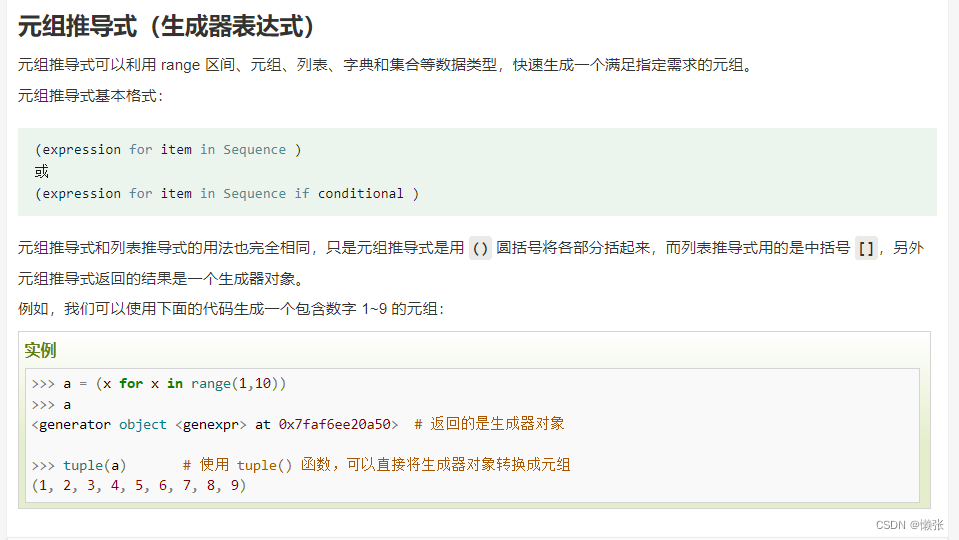

五、类型转换
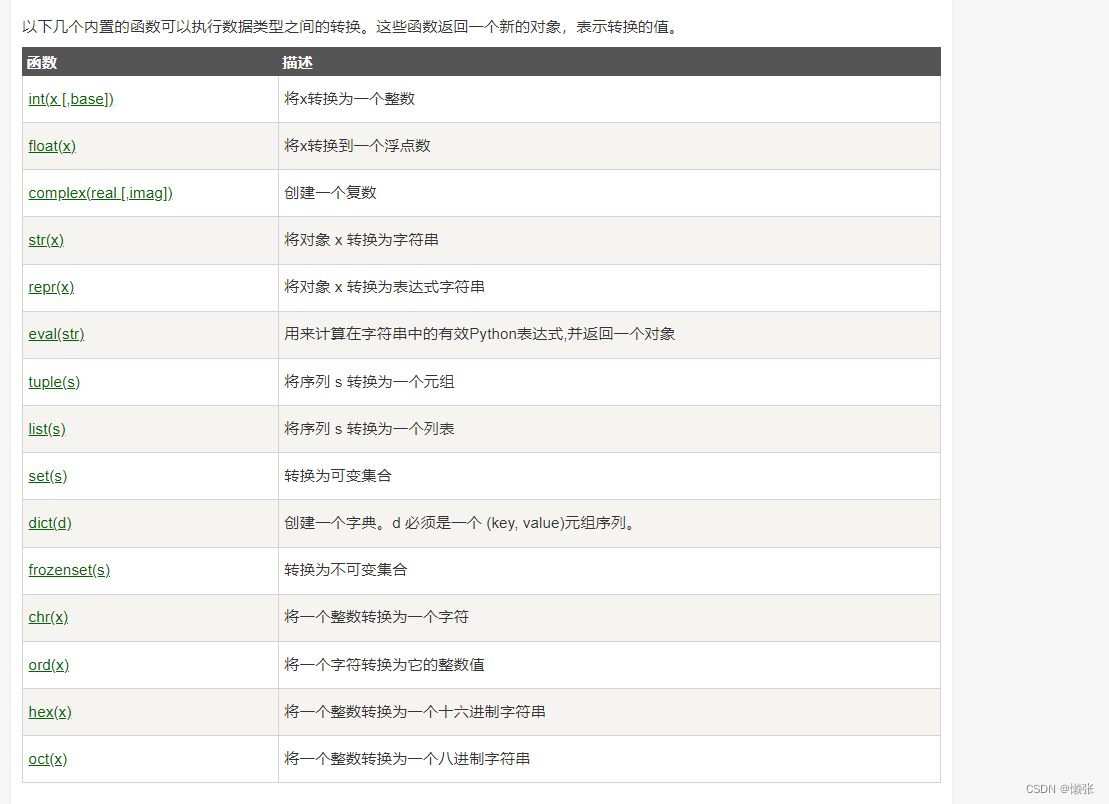
六、运算符
1、Python算术运算符
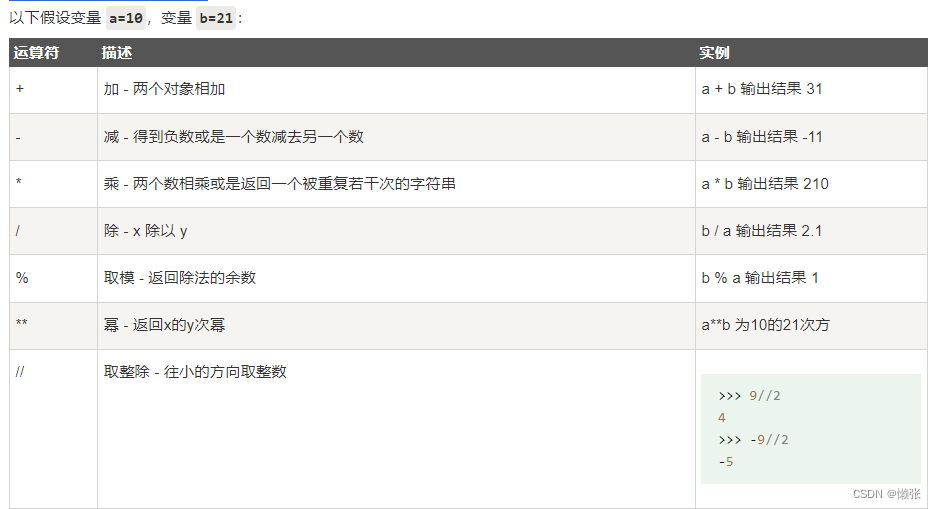
2、Python 比较运算符
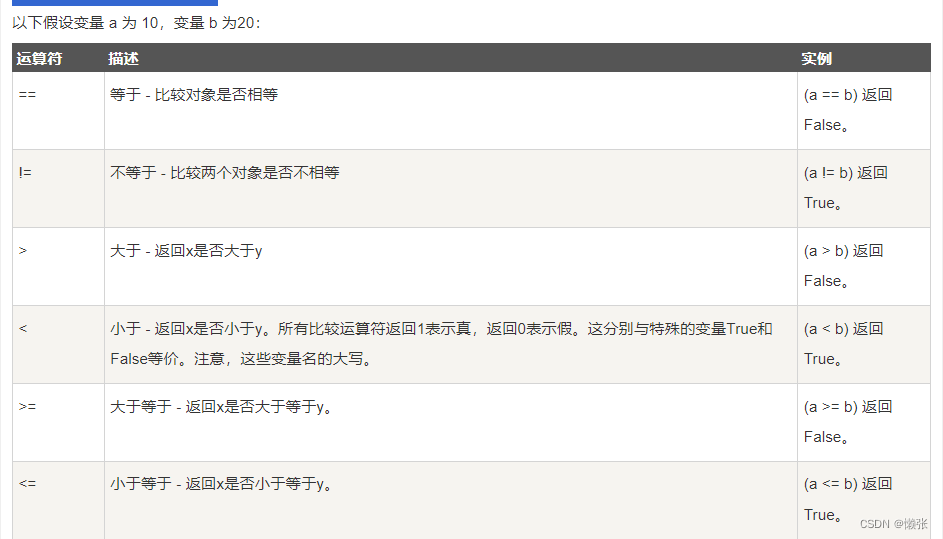
3、Python赋值运算符
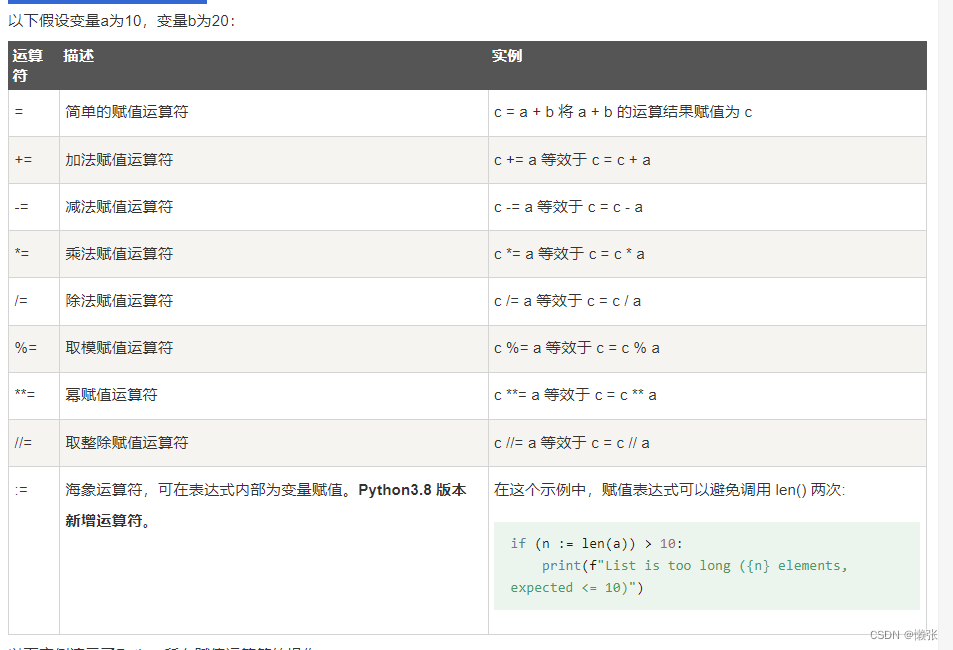
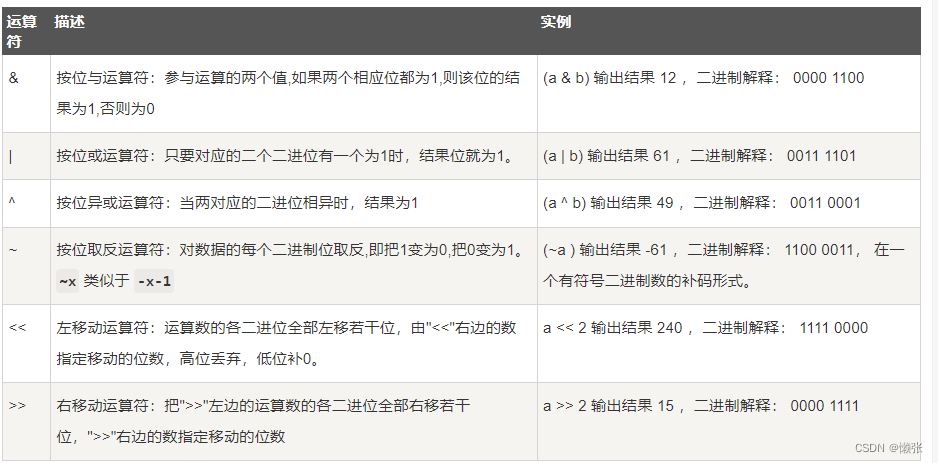
4、 Python位运算符
5、Python逻辑运算符

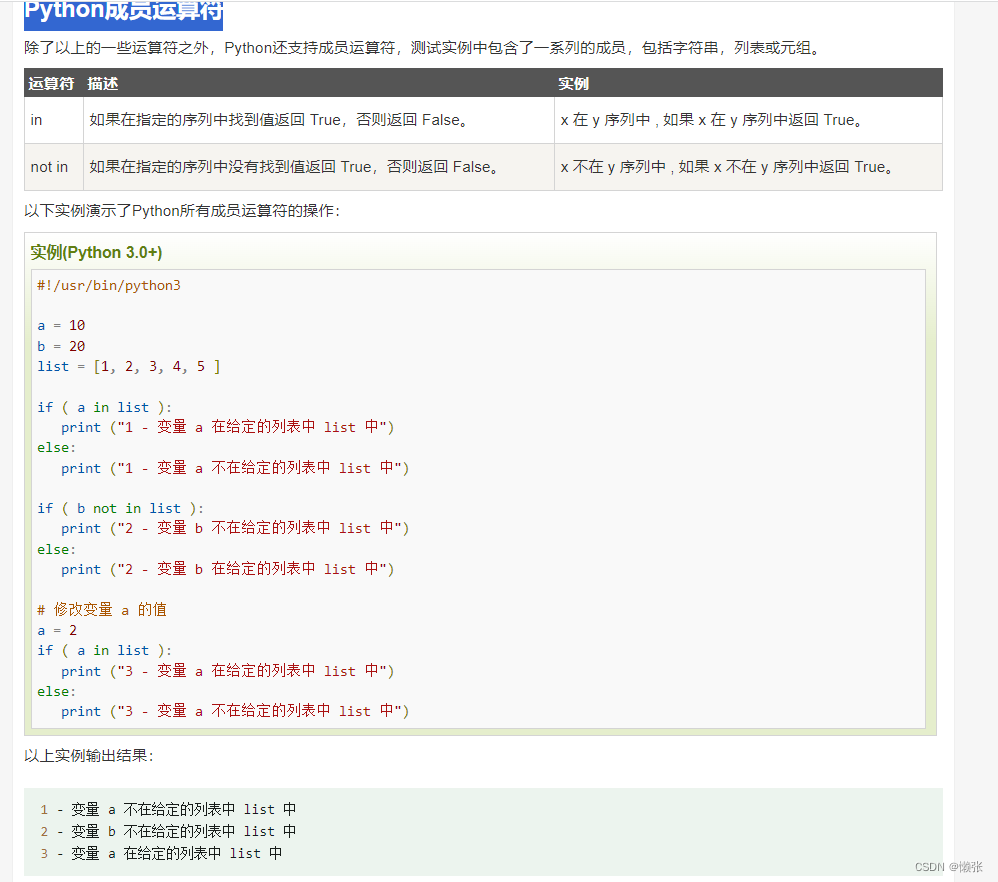
6、Python成员运算符
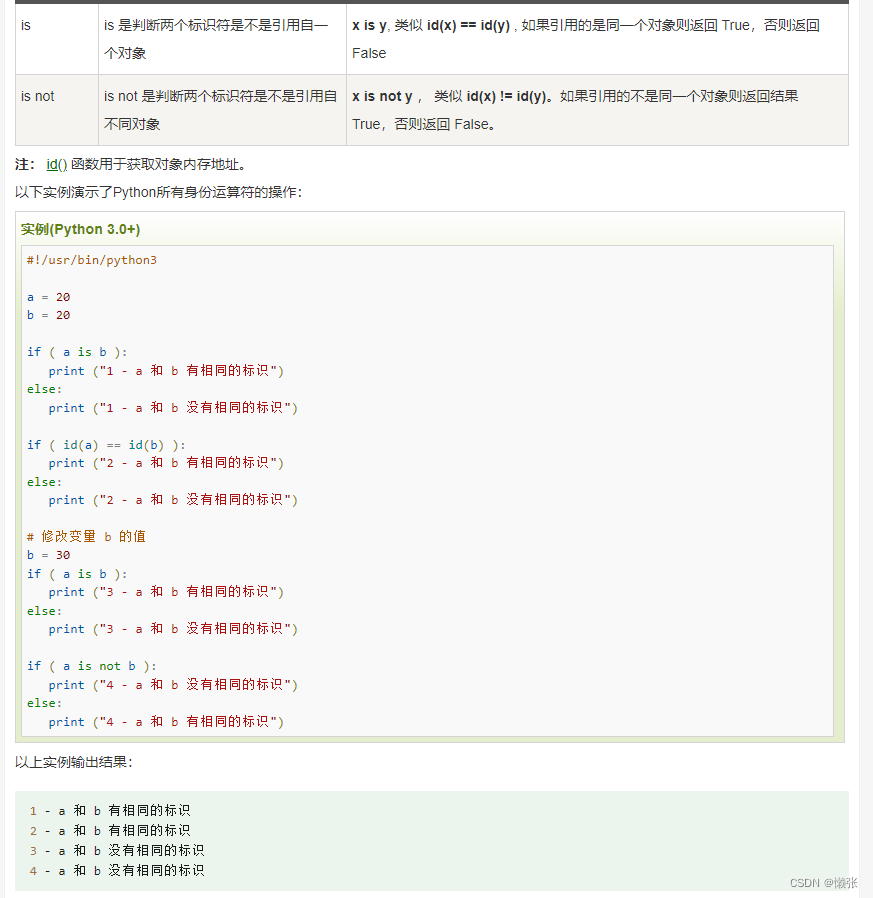
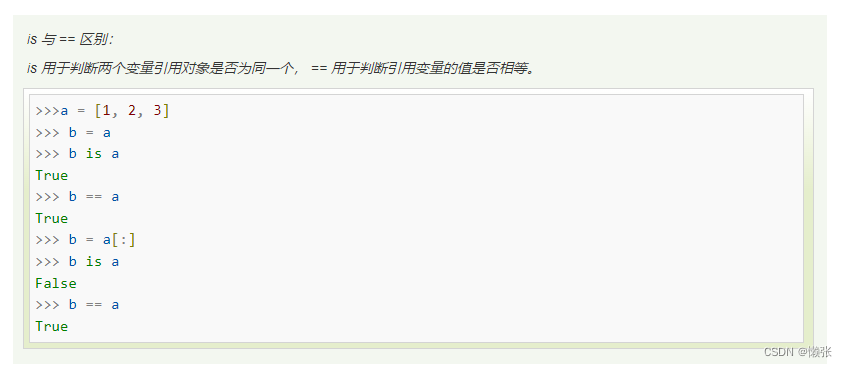
7、 Python身份运算符
七、条件控制
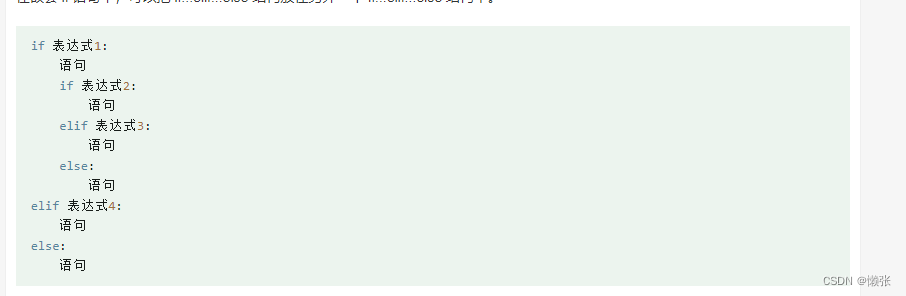
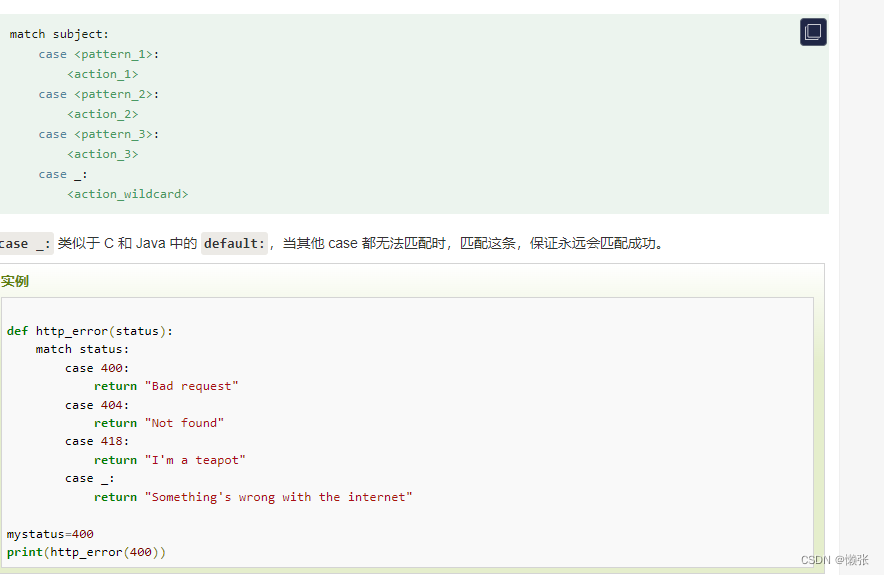
八、循环
1、while循环
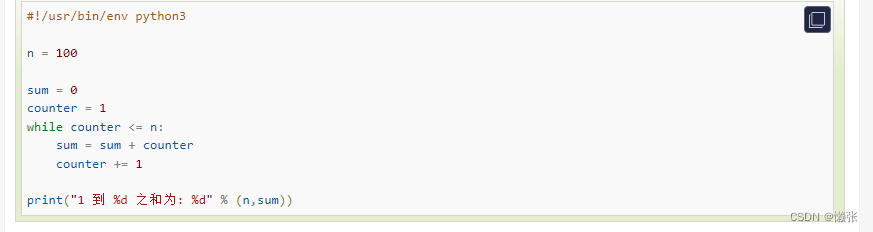
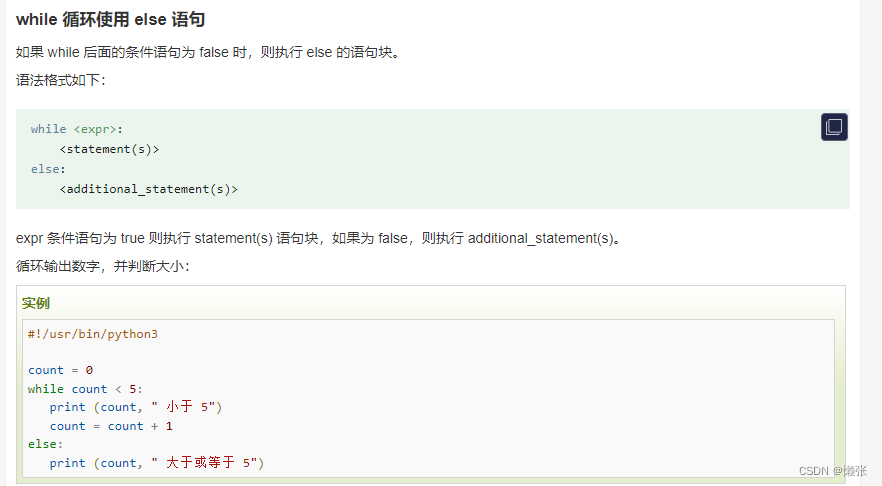
2、for循环
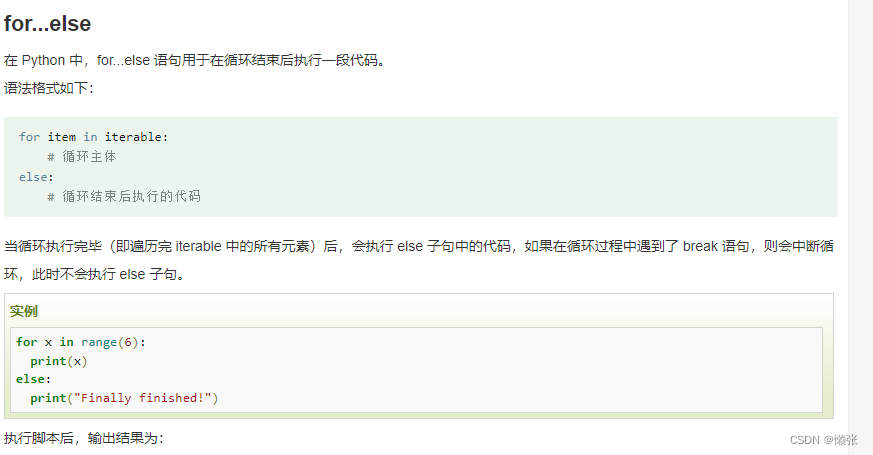
range()函数
其中range(5,10)有5没10
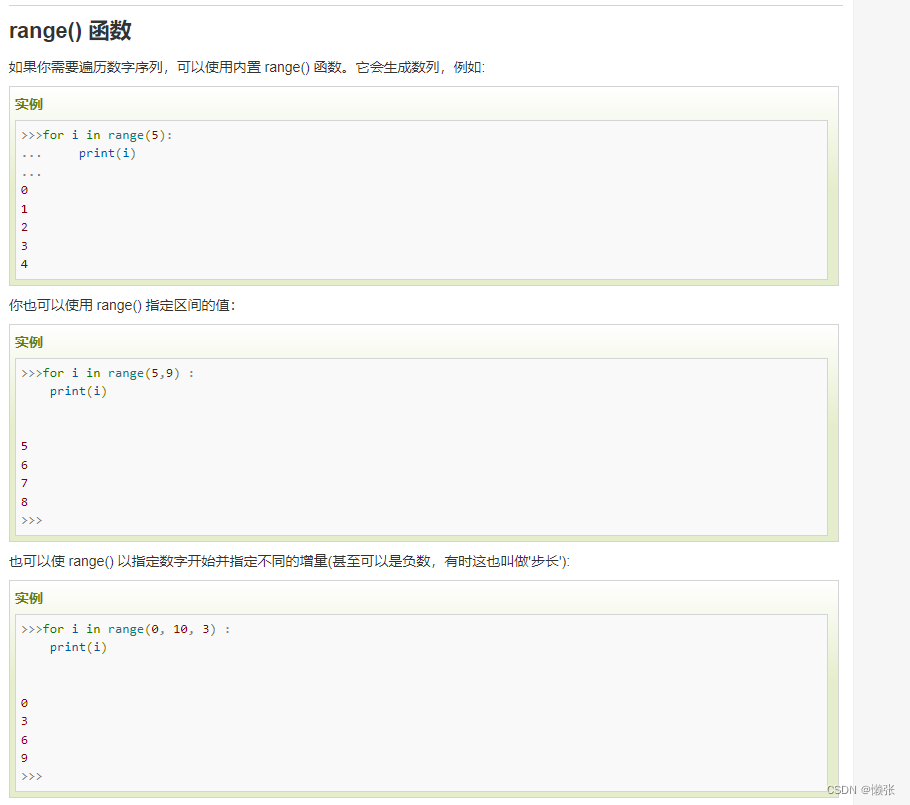
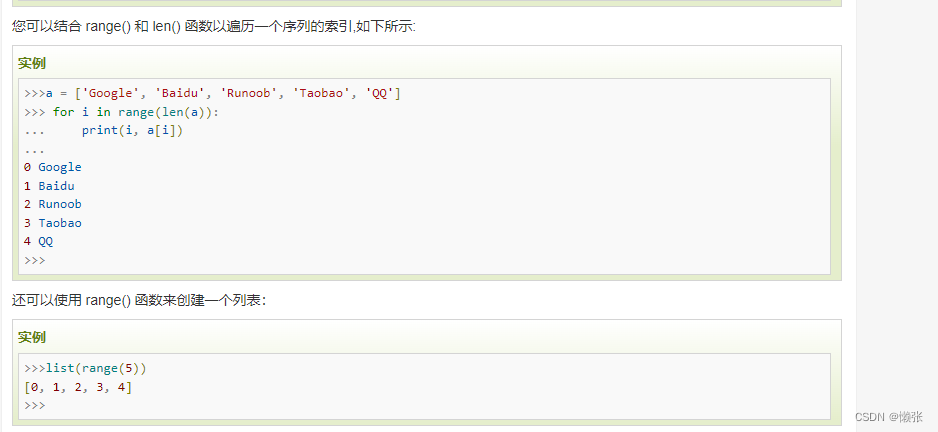
3、跳出循环break 和 continue
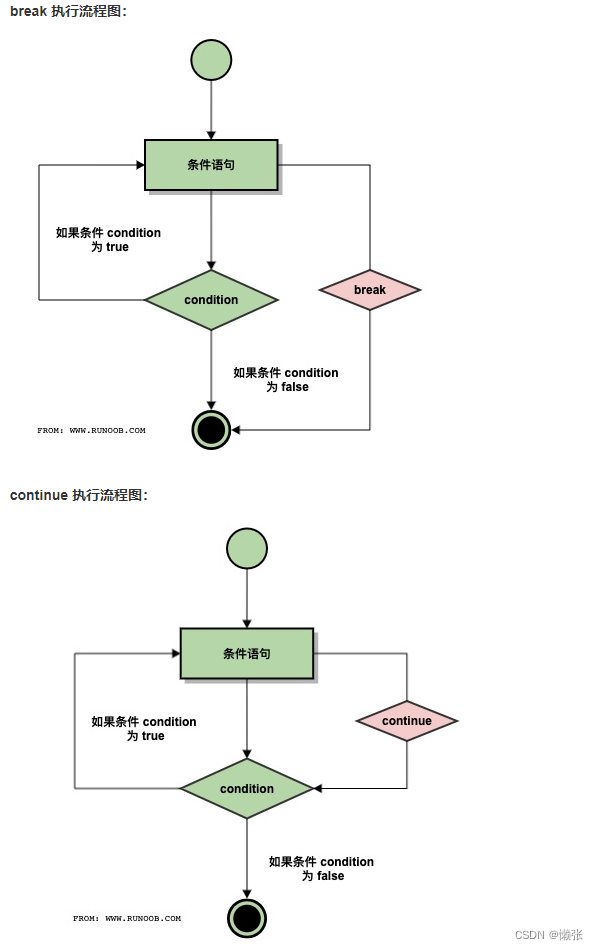
3、pass占位符号
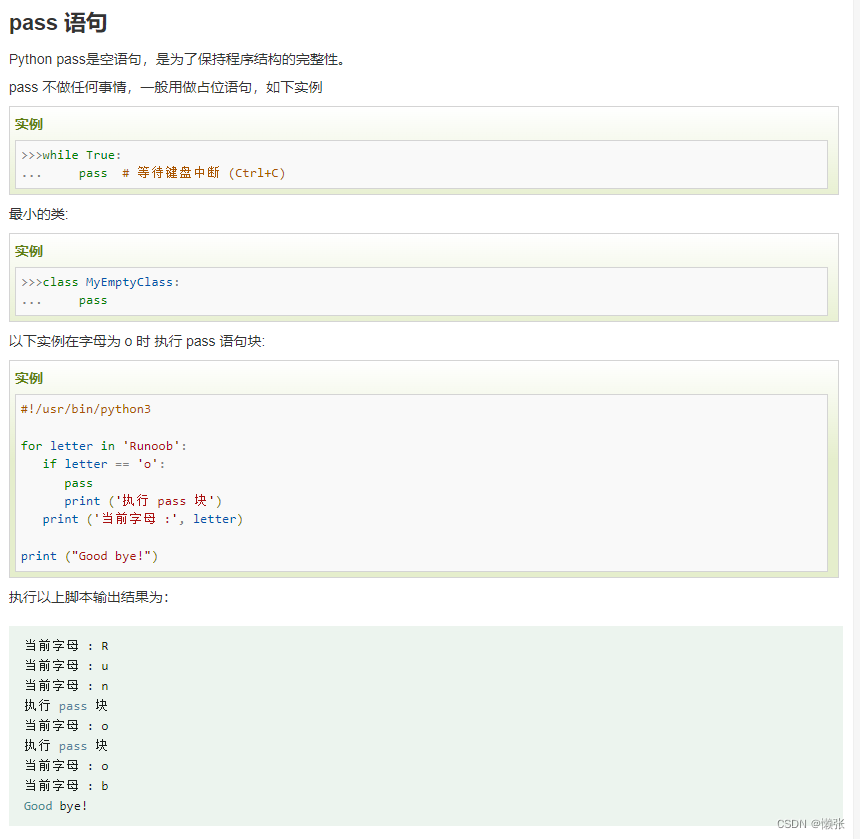
九、迭代器
1、迭代器取值
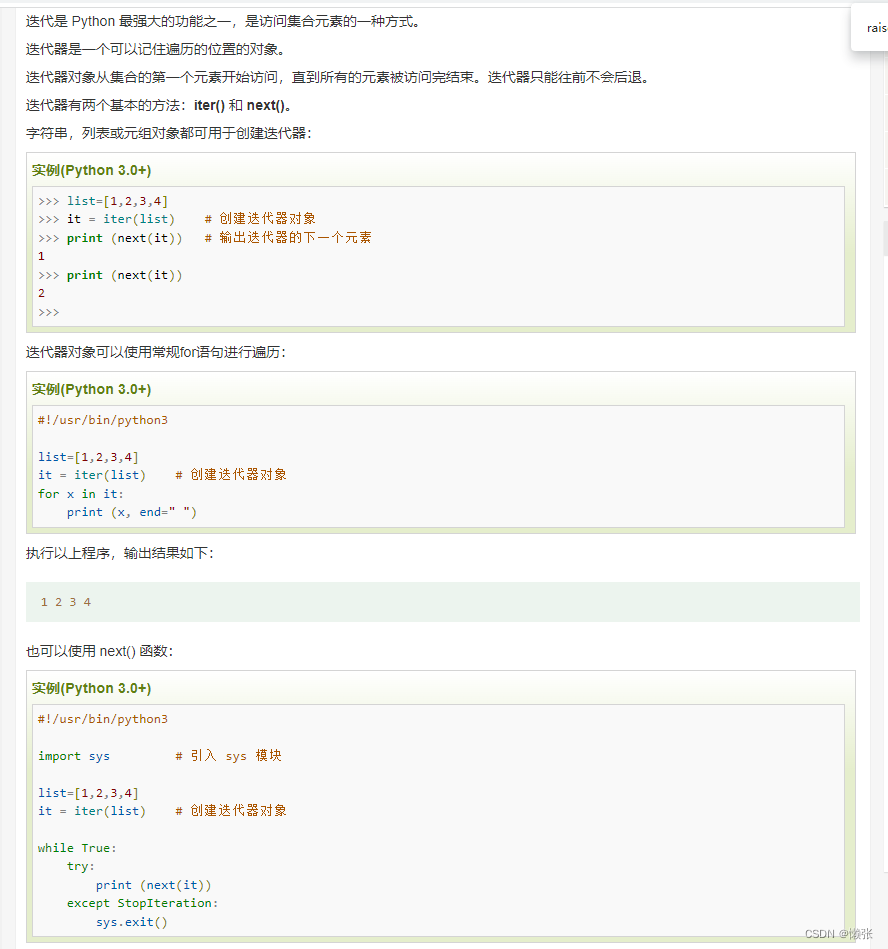
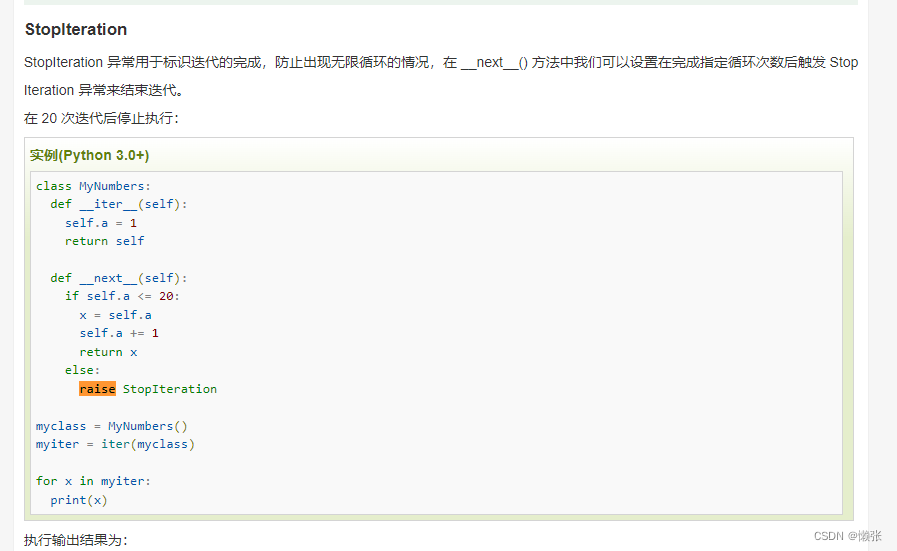
2、停止无限循环
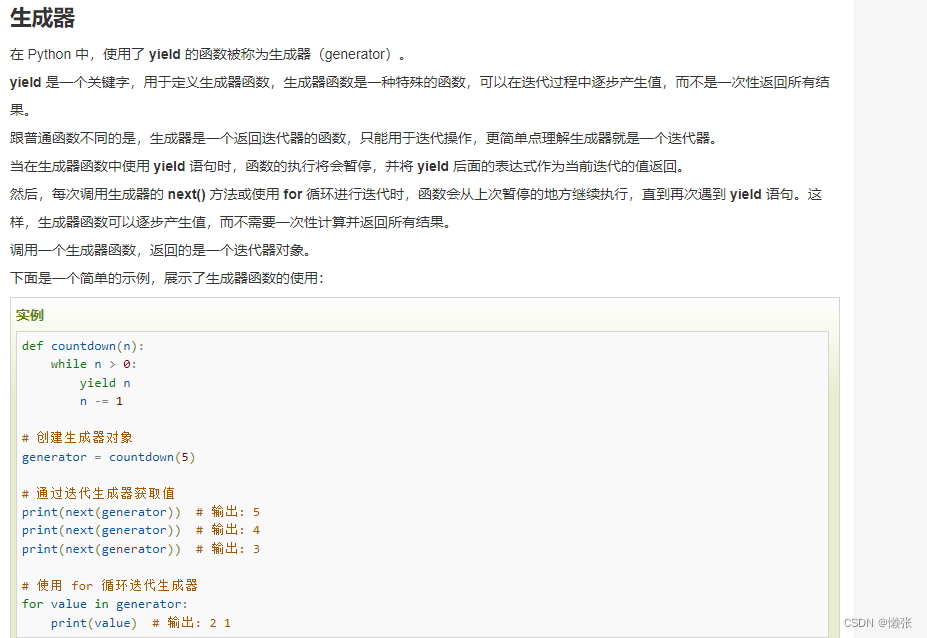
3、函数停止变为迭代器
十、函数
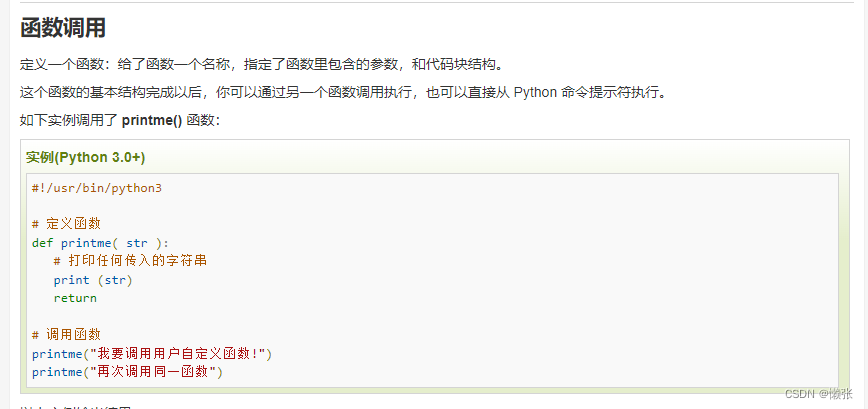
1、自定义函数
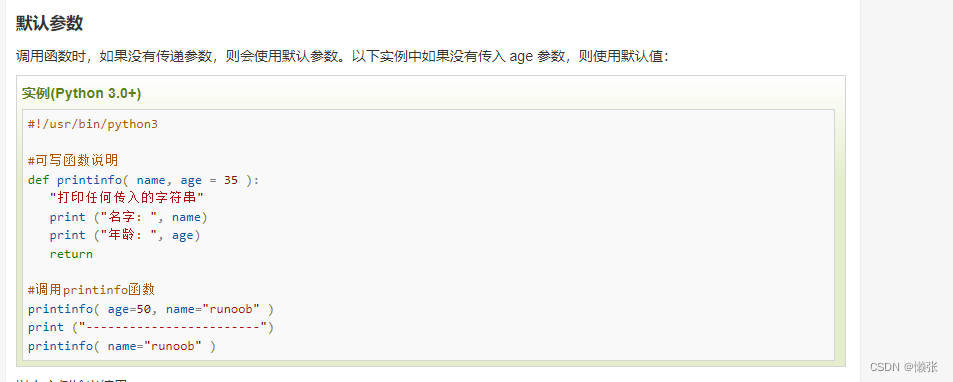
2、默认参数
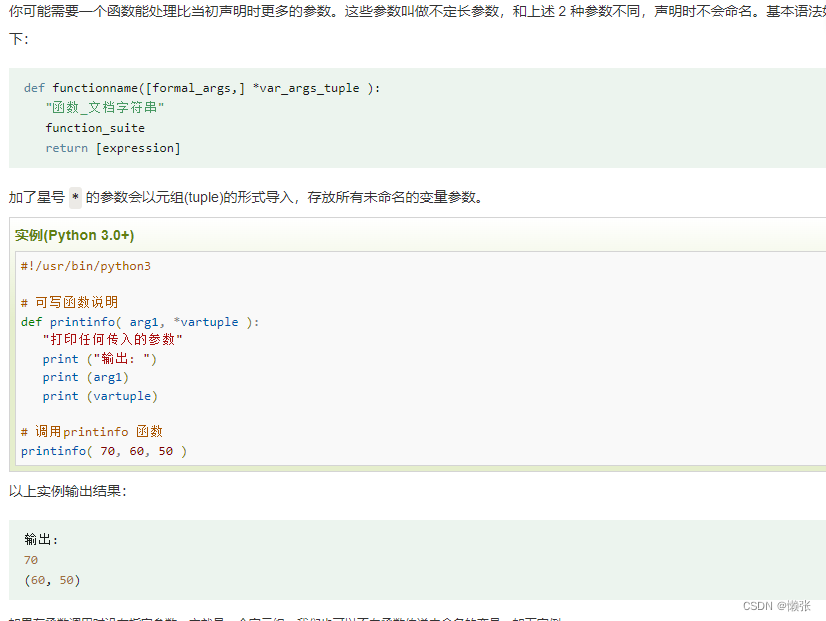
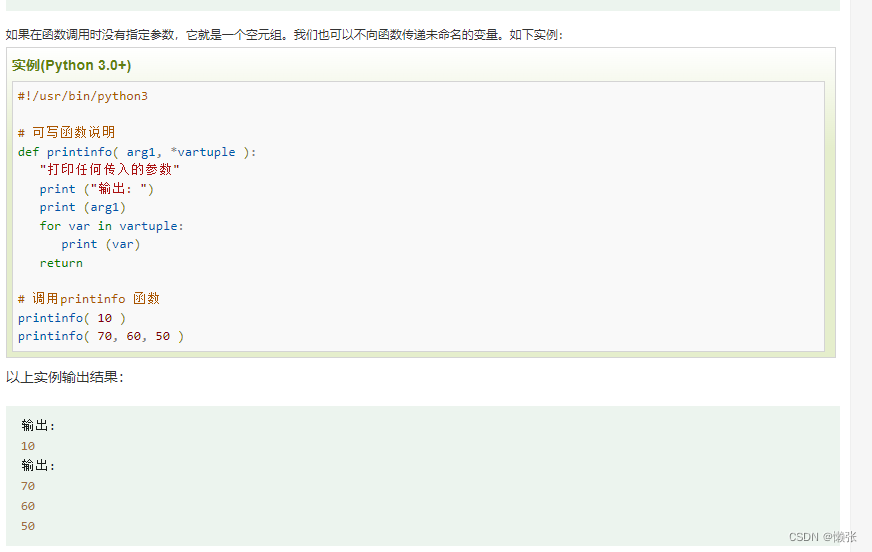
3、元组方式入参
4、字典入参
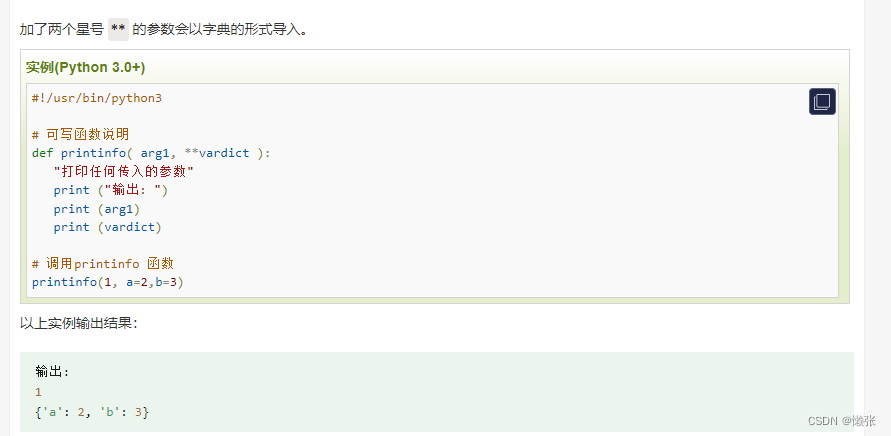
5、*后必须以(参数名=值)传递
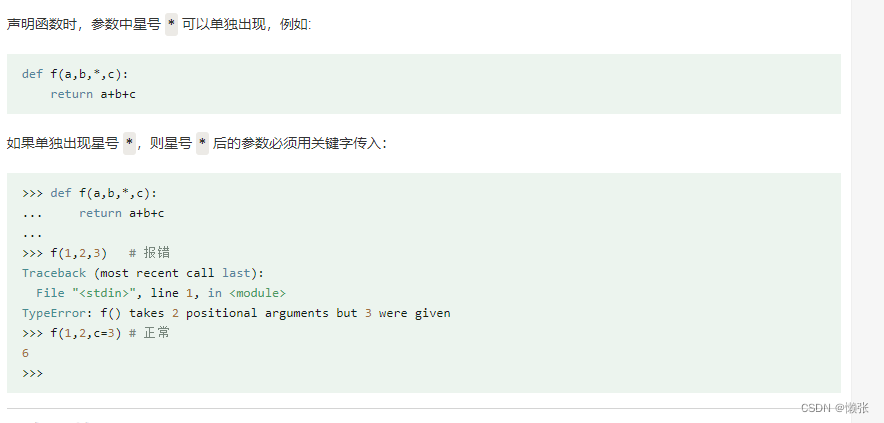

6、匿名函数
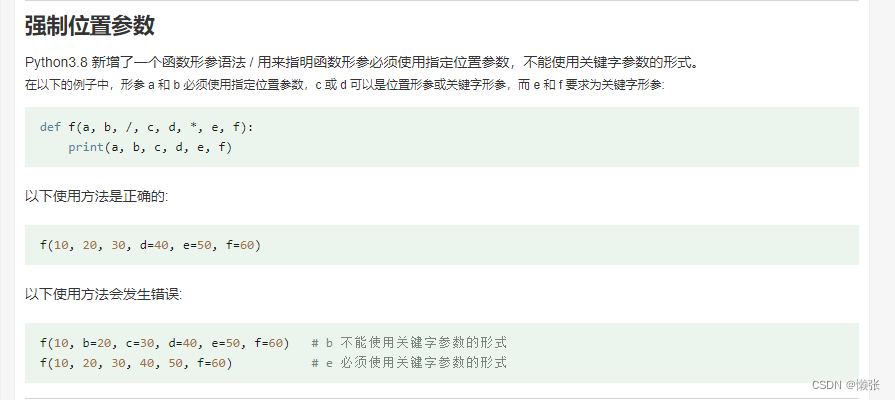
7、强制位置参数/
8、return
None为java的null
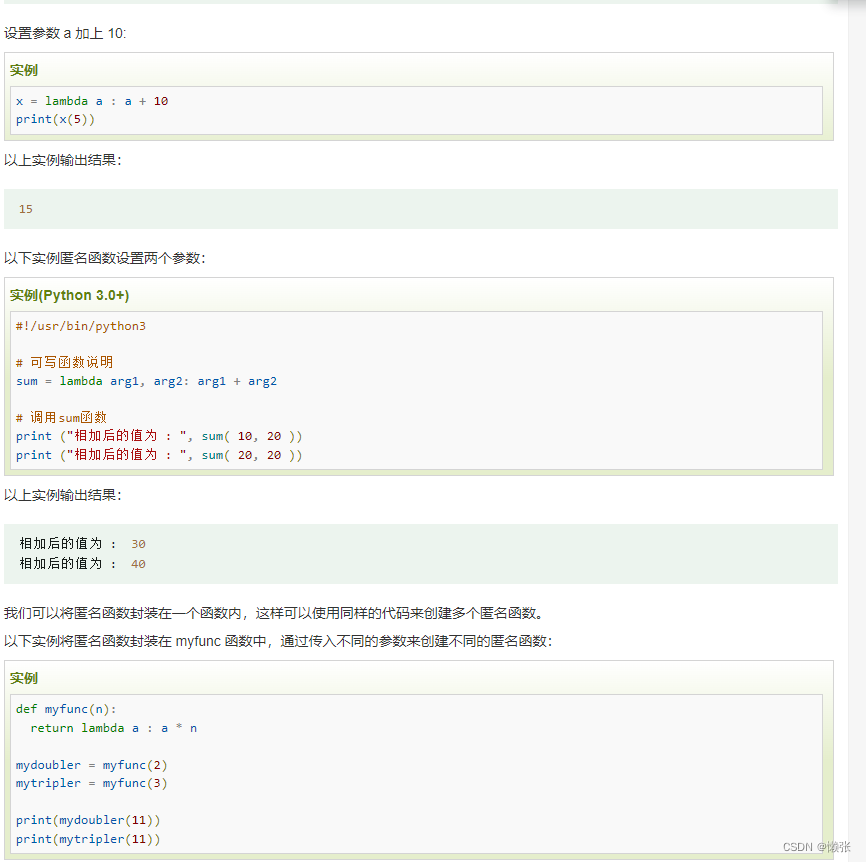
十一、lambda 匿名函数
1、无参lambda
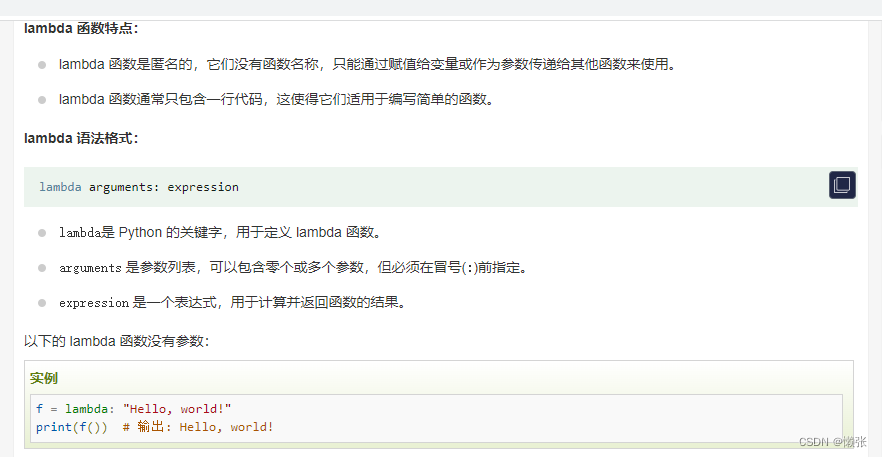
2、有参lambda
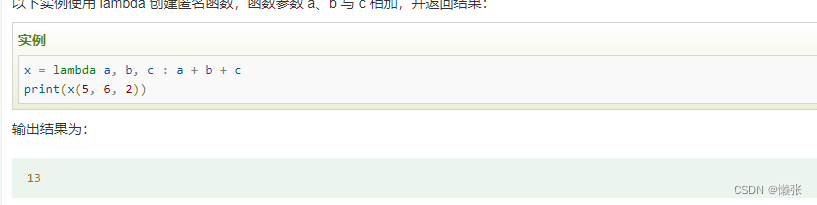
3、函数式入参
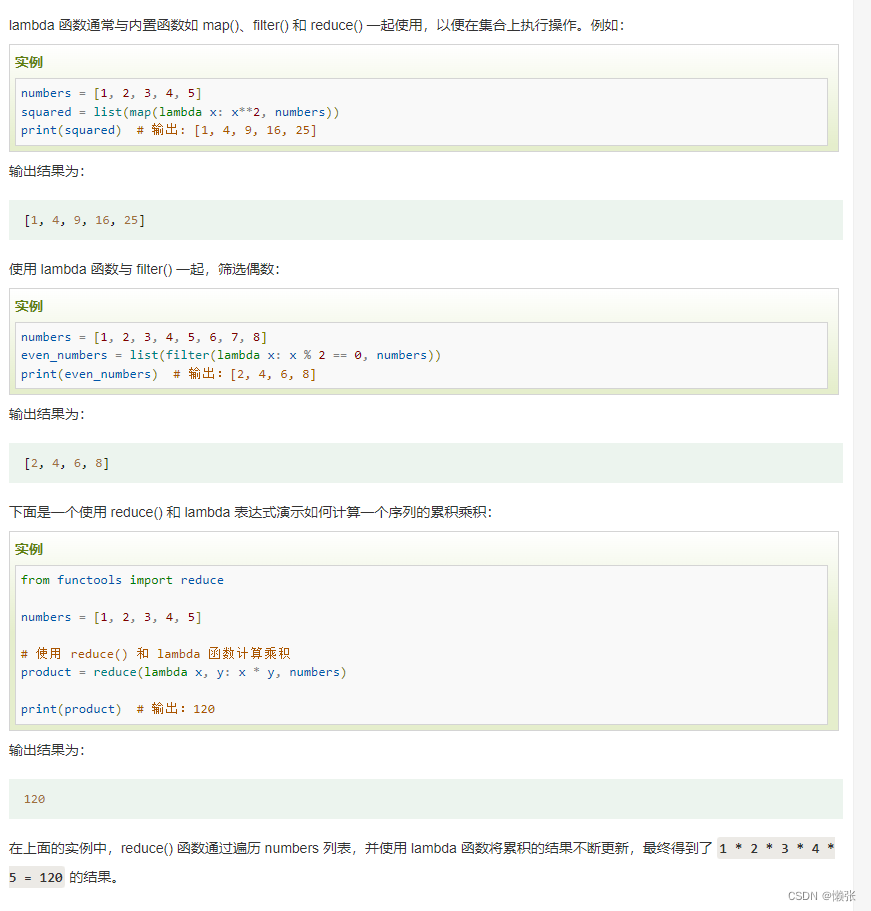
4、函数作为参数
def apply_operation(operation, x, y):
"""
接受一个操作函数,并将它应用到给定的两个参数上
"""
result = operation(x, y)
return result
# 定义一个加法函数
def add(a, b):
return a + b
if __name__ == '__main__':
# 将 add 函数作为参数传递给 apply_operation 函数
sum_result = apply_operation(add, 3, 4)
print(sum_result) # 输出:7
5、判断类型
import types
# 是否为函数类型
print(isinstance(operation, types.FunctionType) )
# 是否为int类型
print(isinstance(operation, int) )
# 是否为str类型和int类型
print(isinstance(operation, (int, str)) )
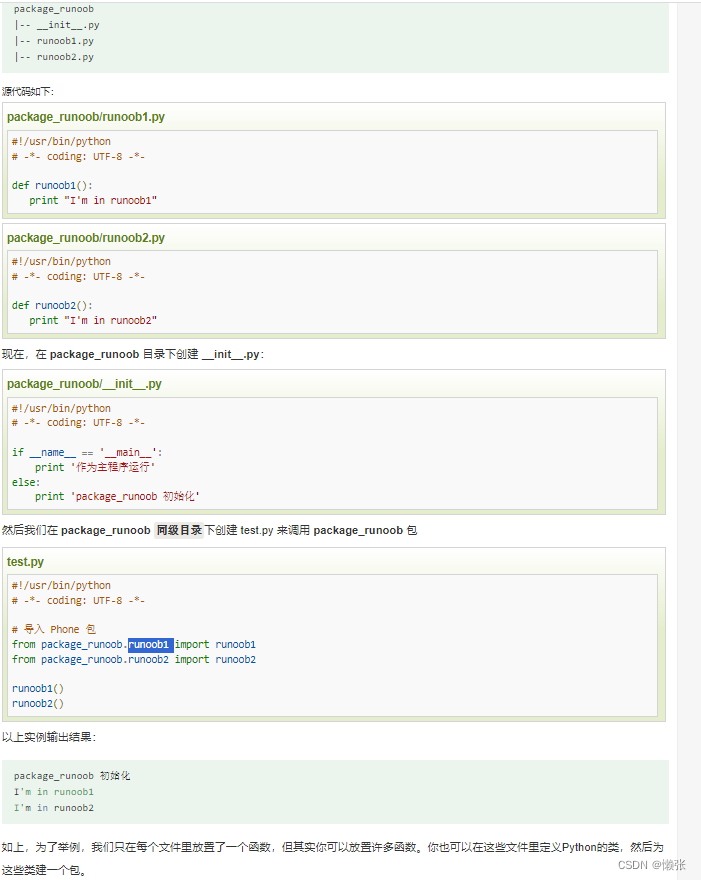
十二、模块
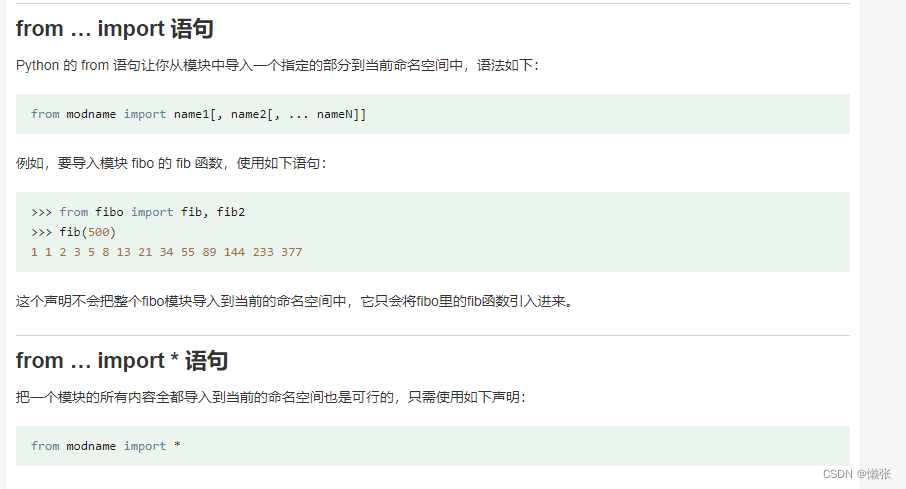
1、引入模块import
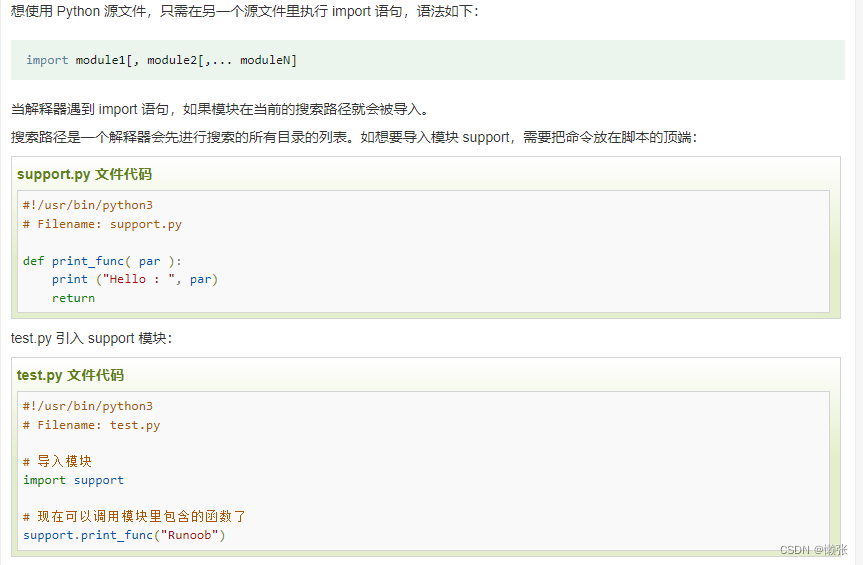

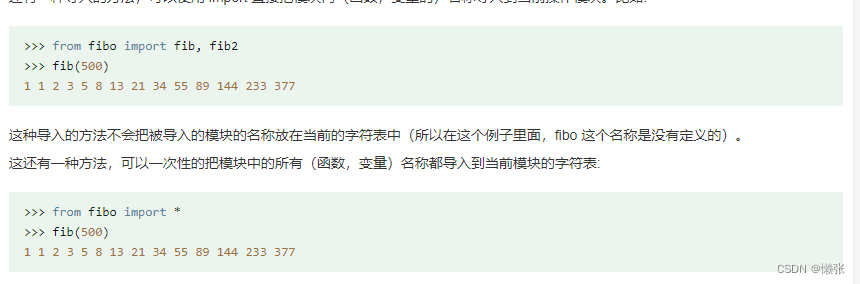
2、引入模块from … import 语句
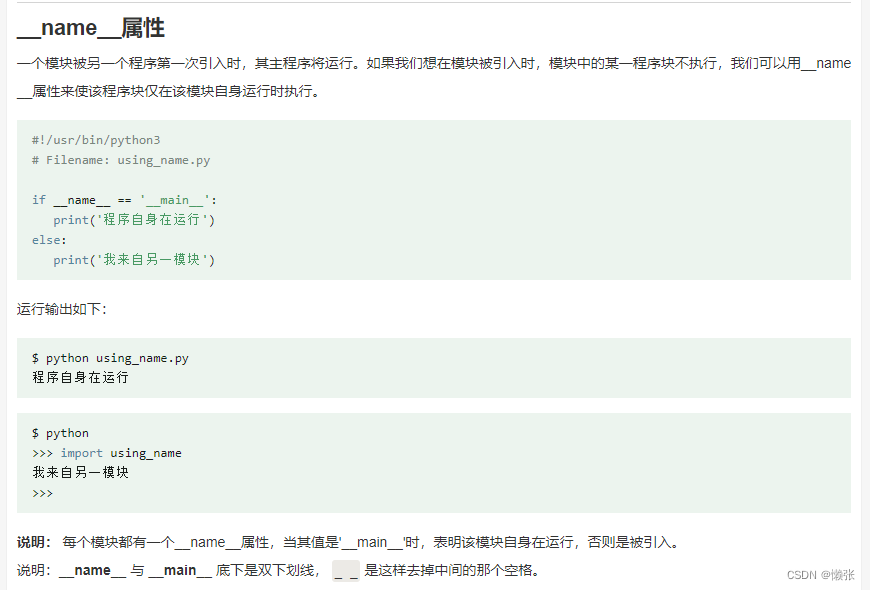
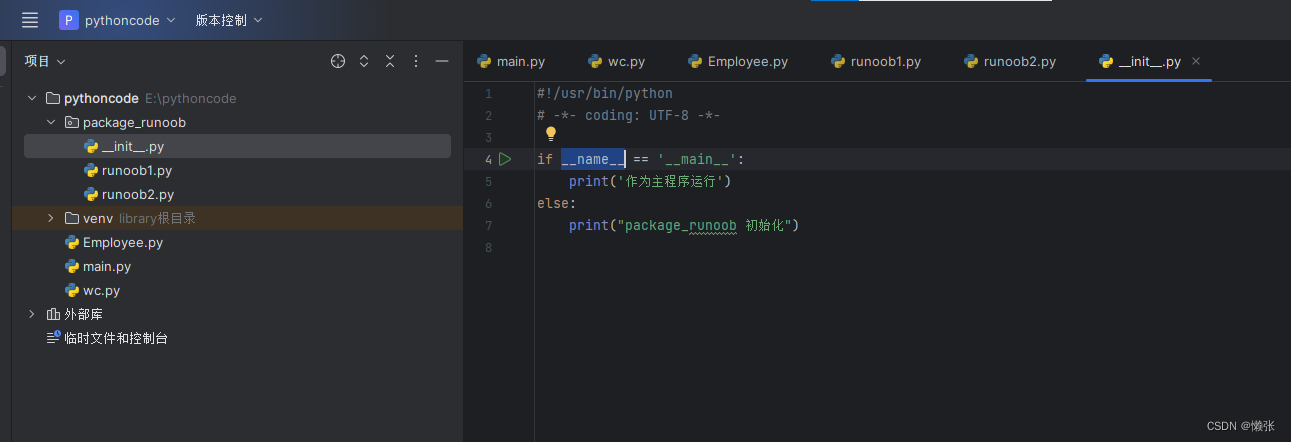
3、__name__属性
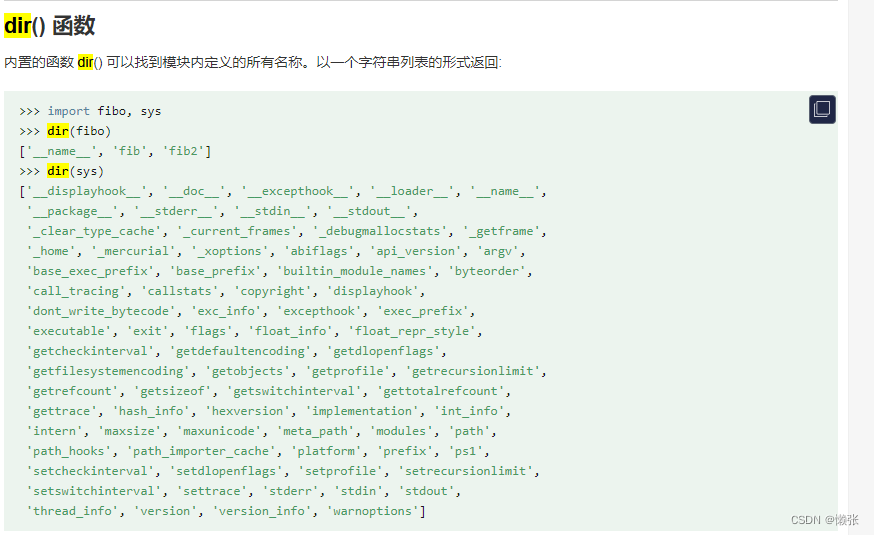
4、dir函数

5、包
6、全局函数

7、reload() 函数

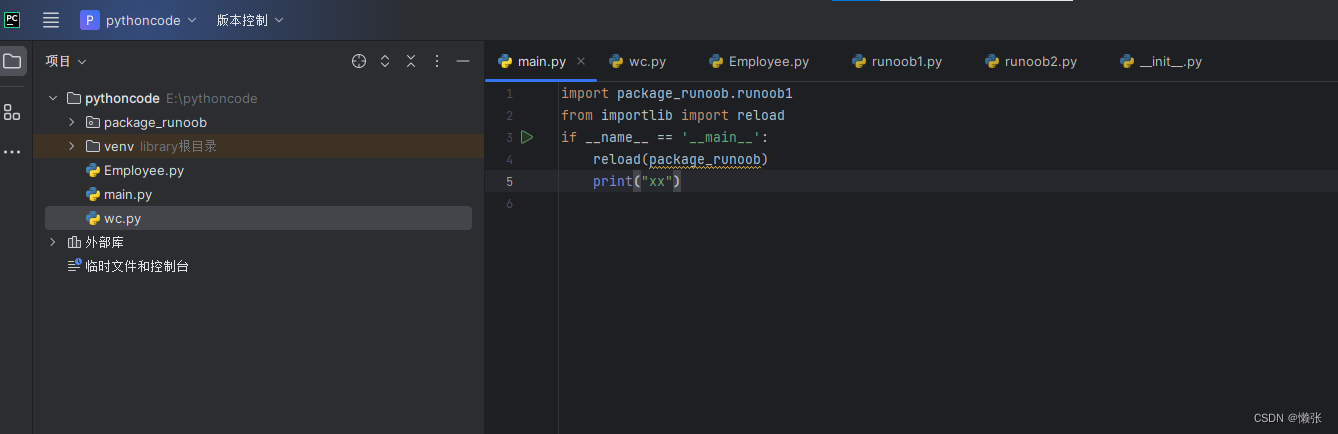
会执行下面的
__name__方法
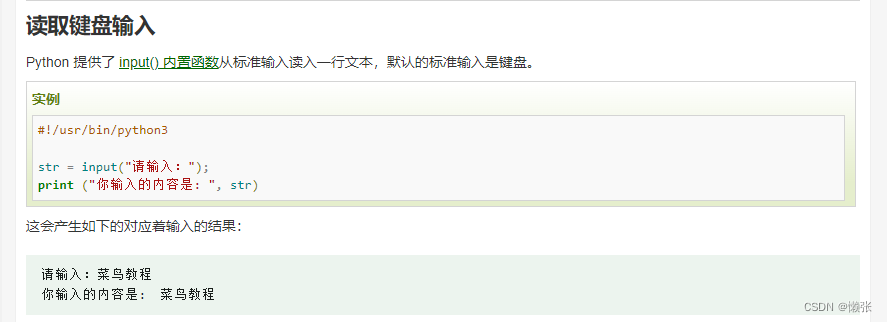
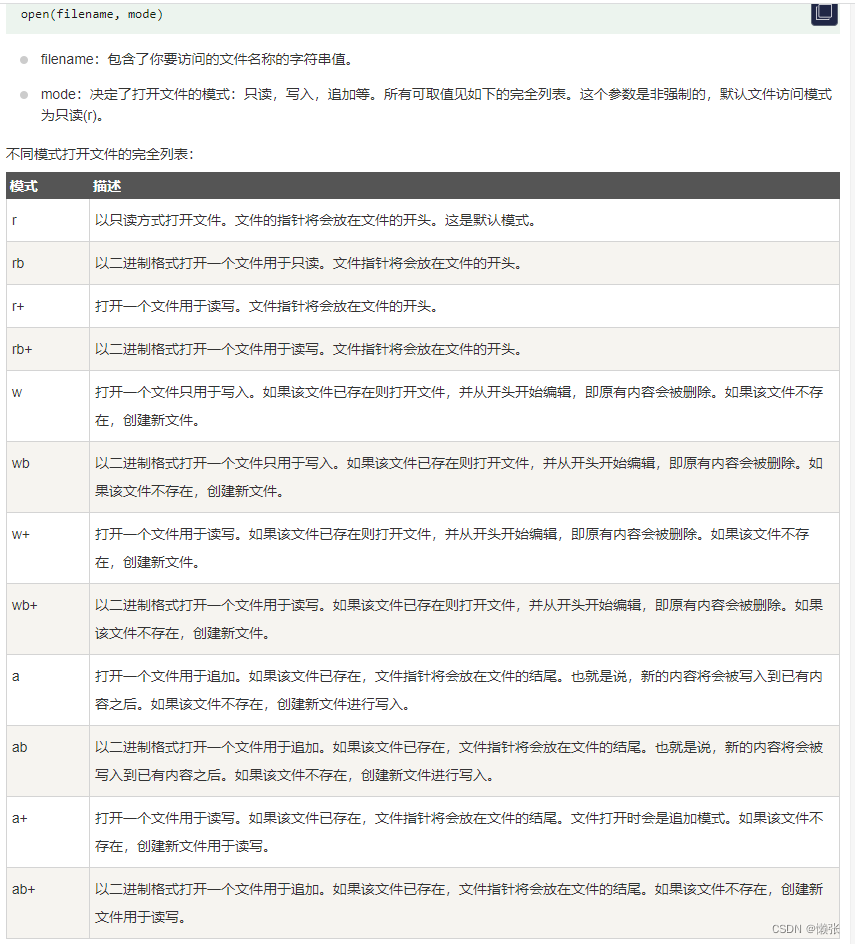
十三、键盘输入+读和写文件(文件I/O)
1、键盘输入
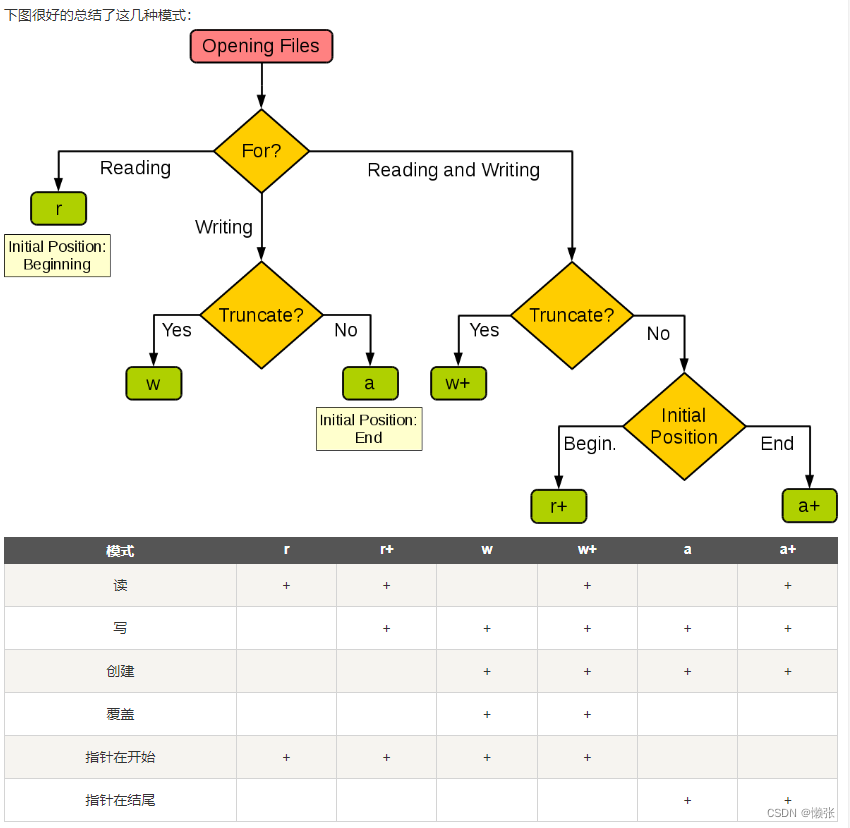
2、文件模式
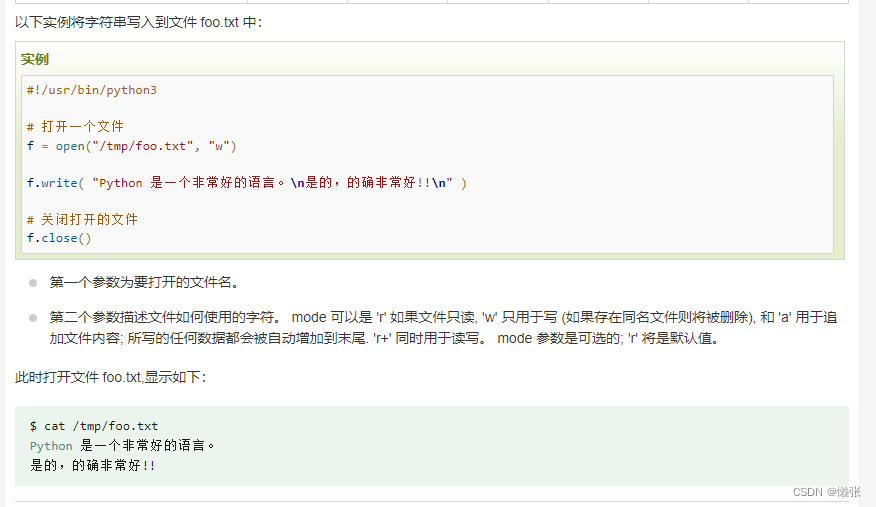
3、写
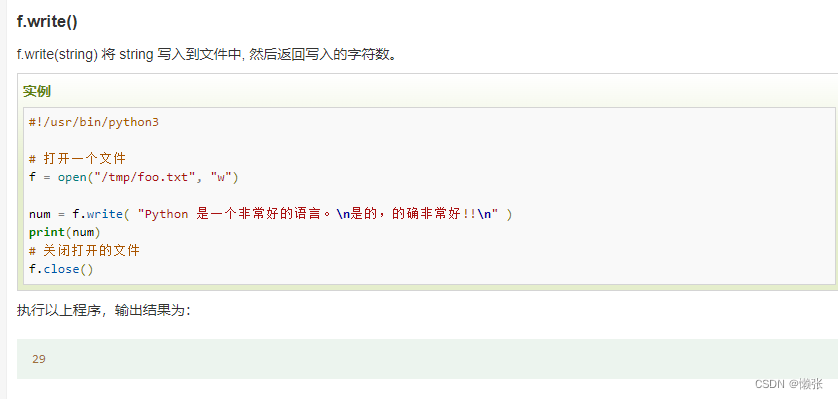
返回写入字数
写非文字
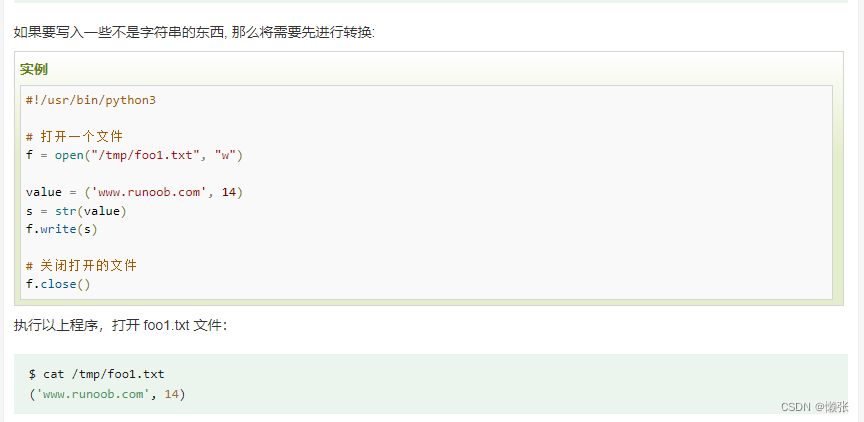
4、读
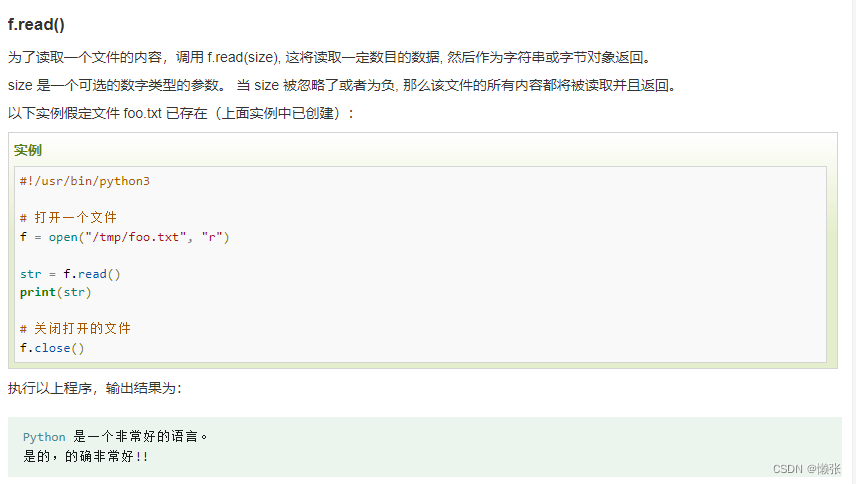
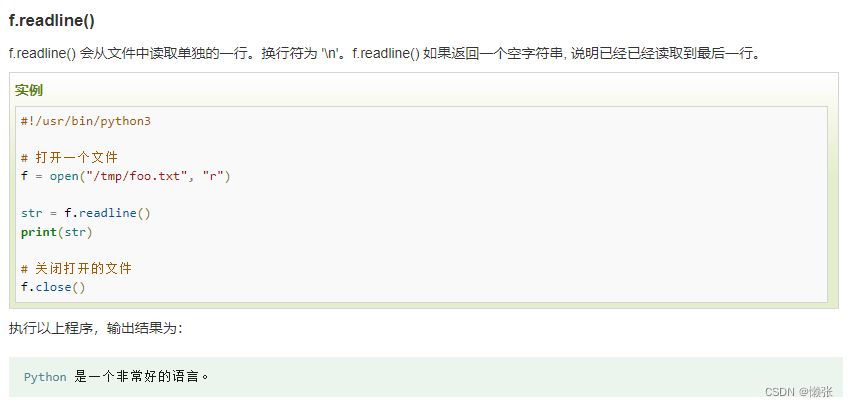
单行读
读取多行
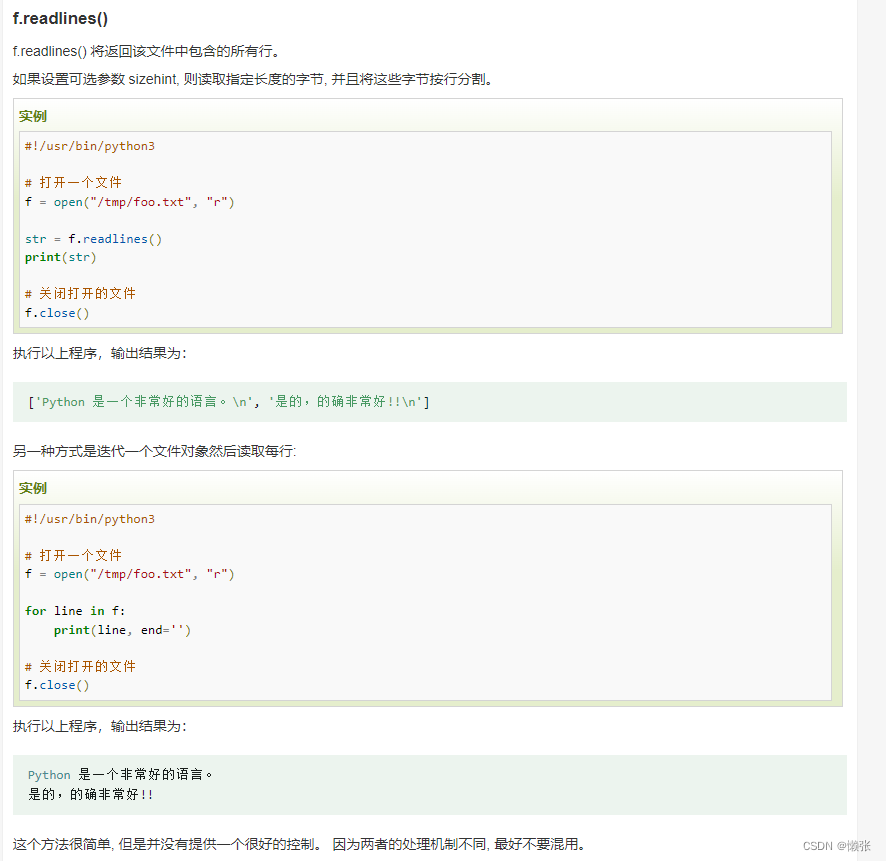
5、所处的位置
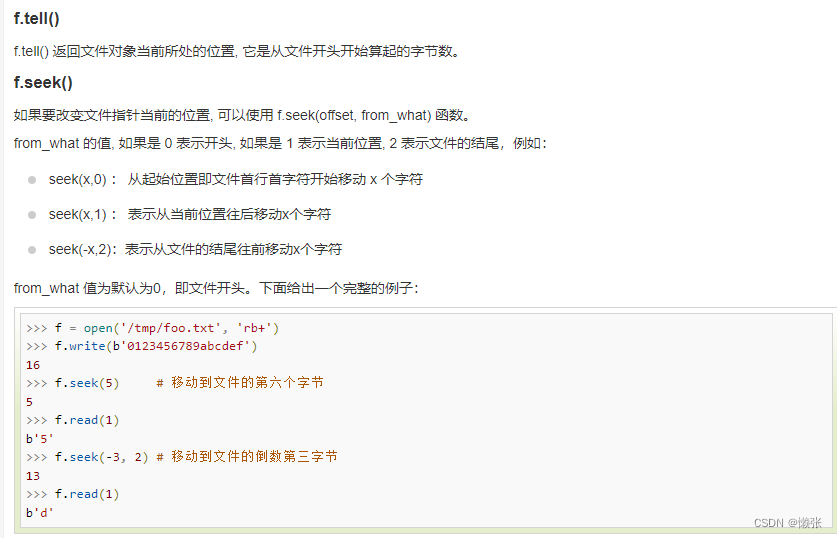
6、关闭流
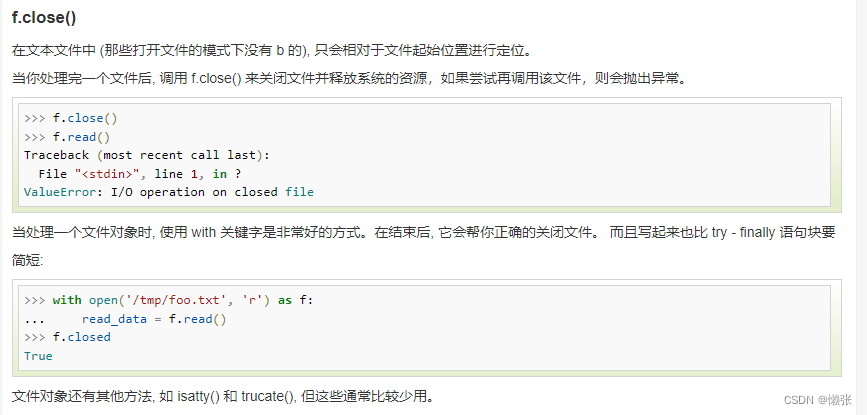
7、序列化pickle 模块
写入
读取
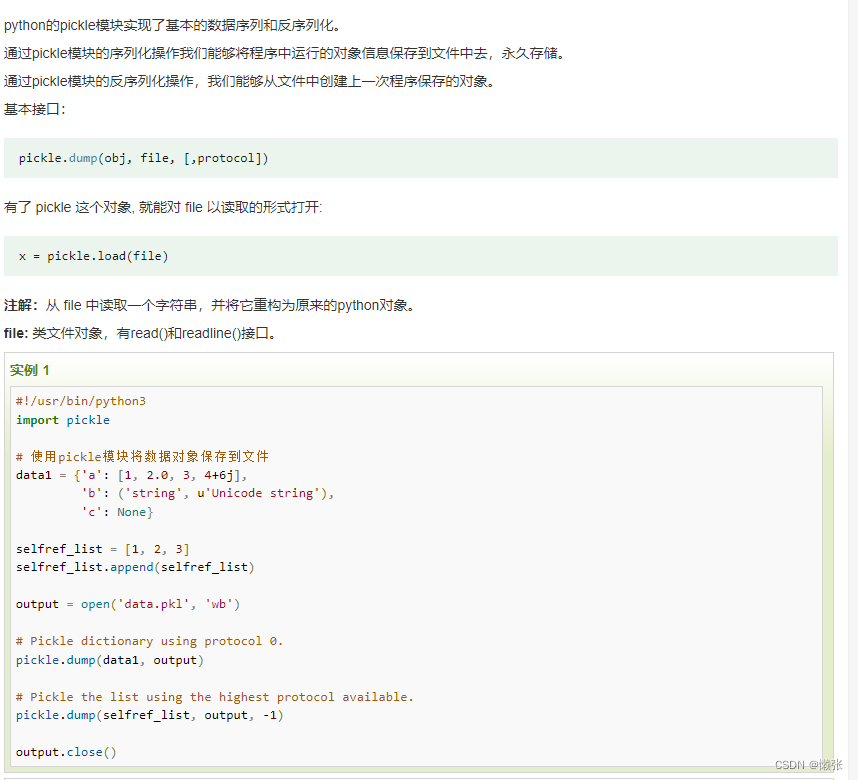
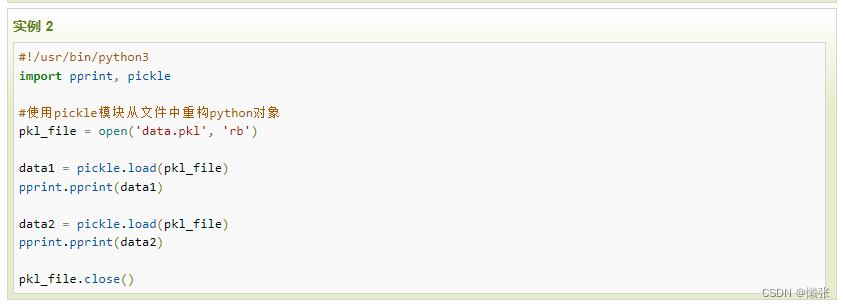
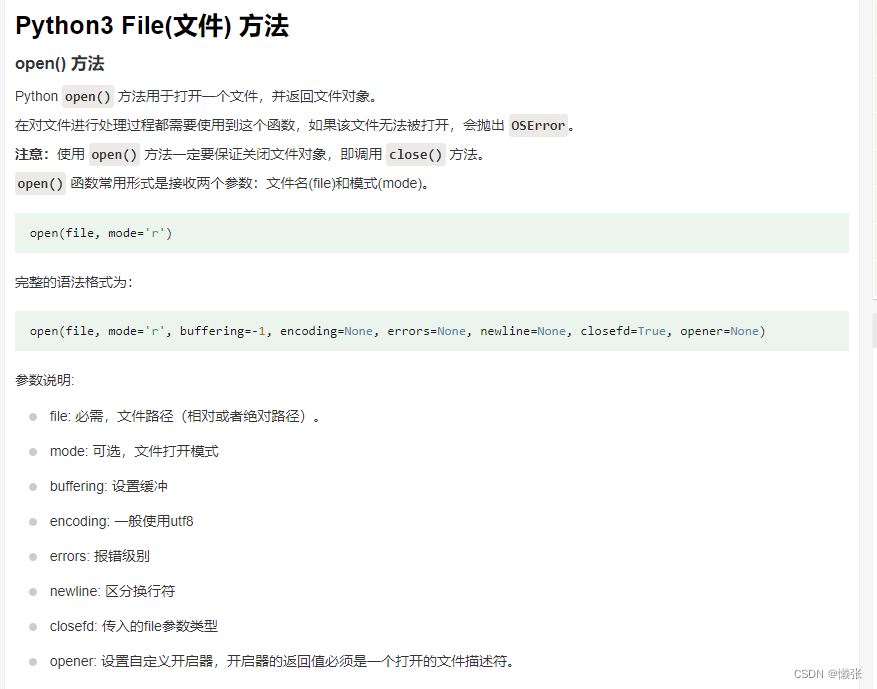
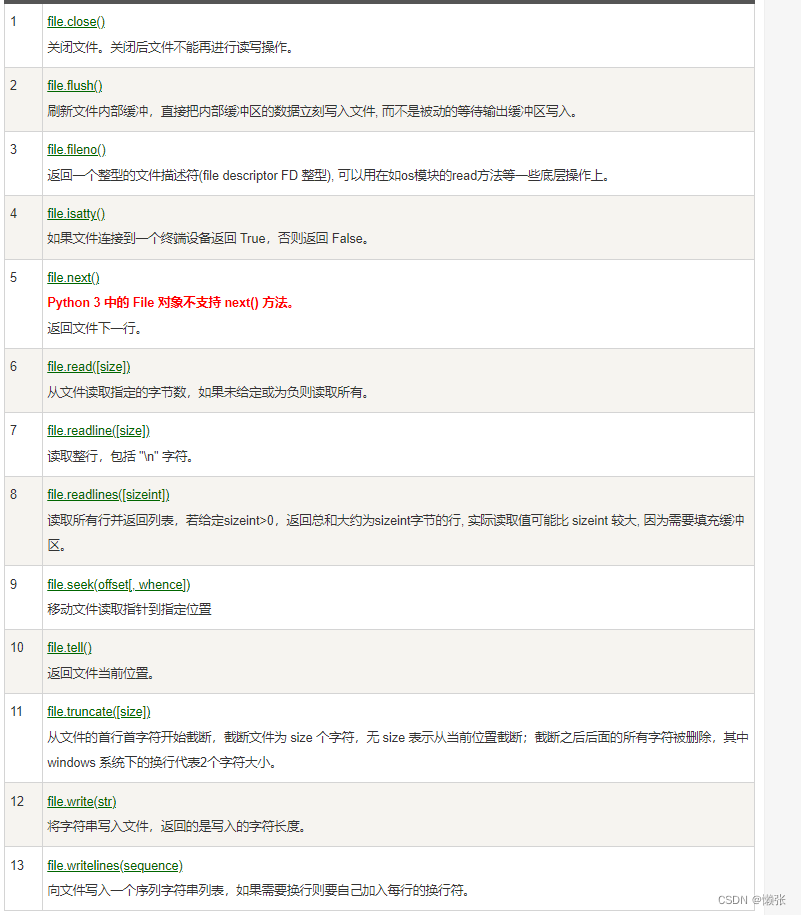
8、file
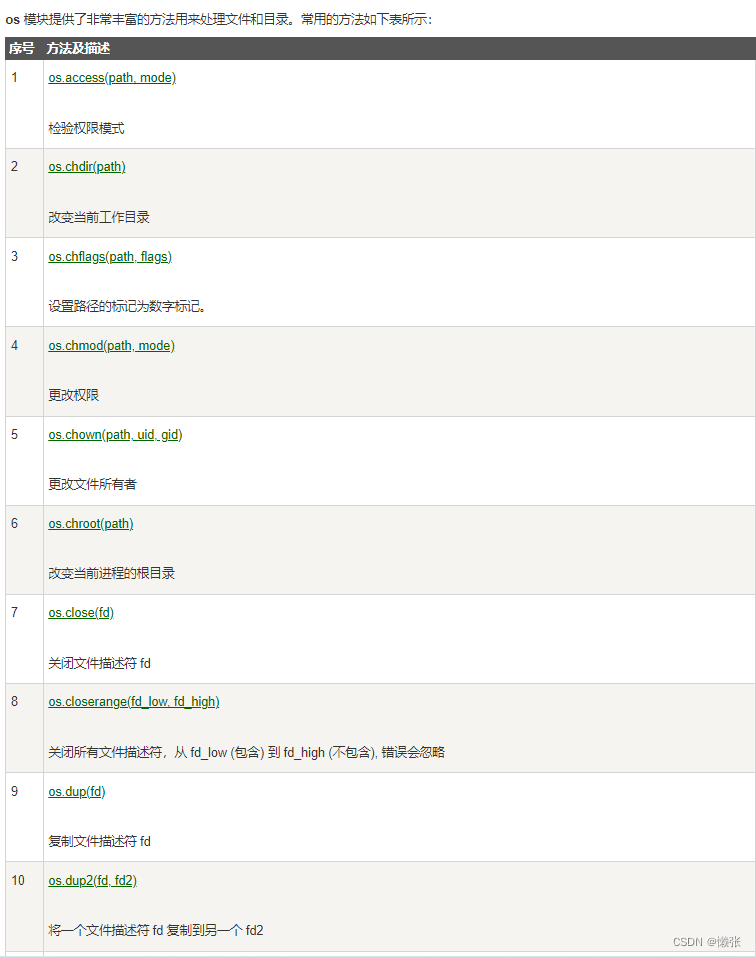
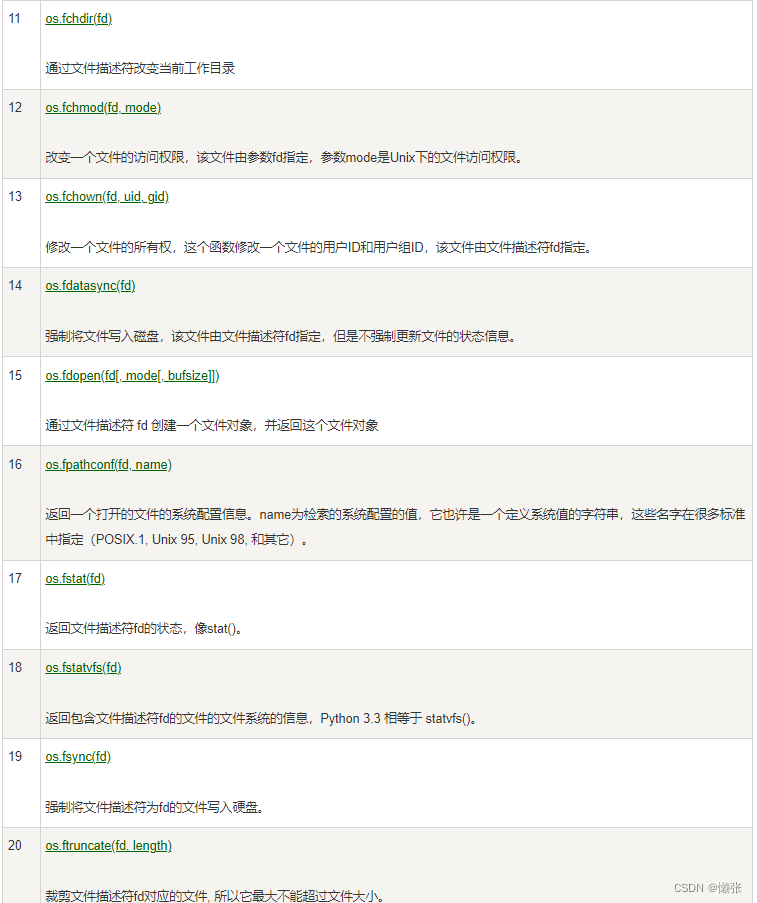
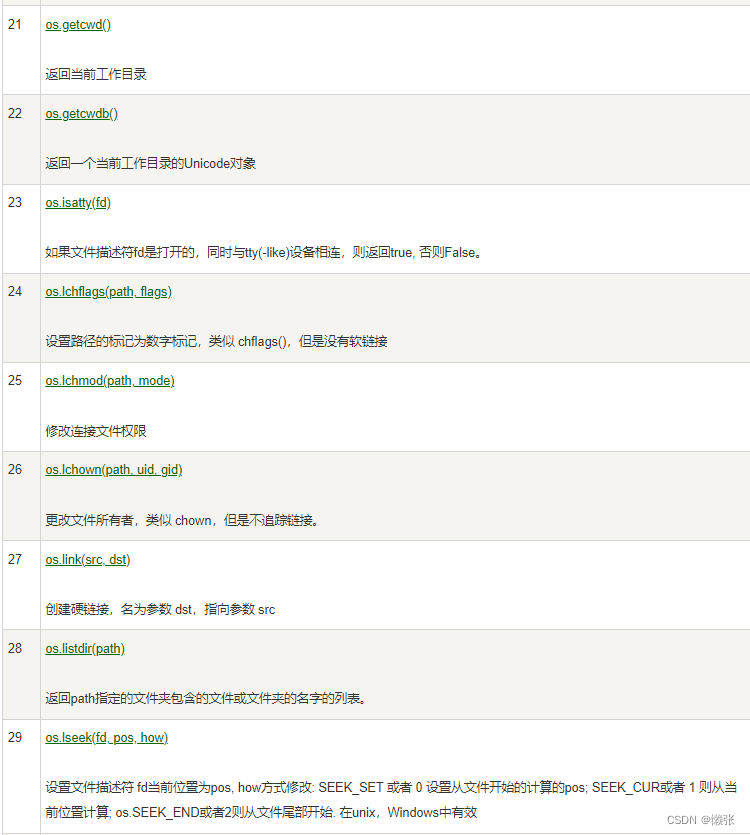
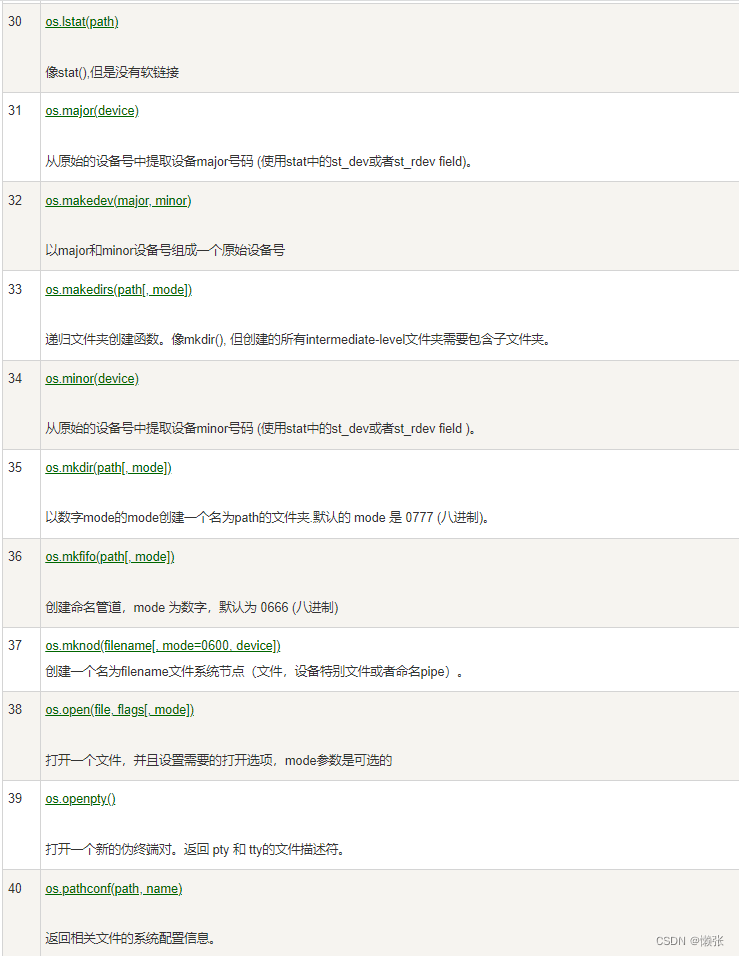
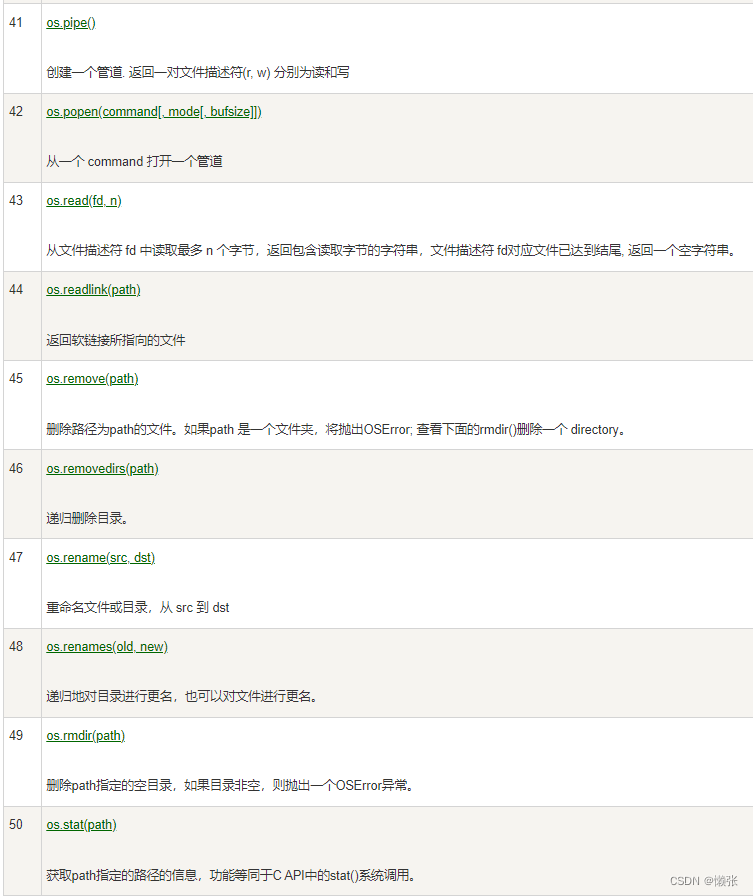
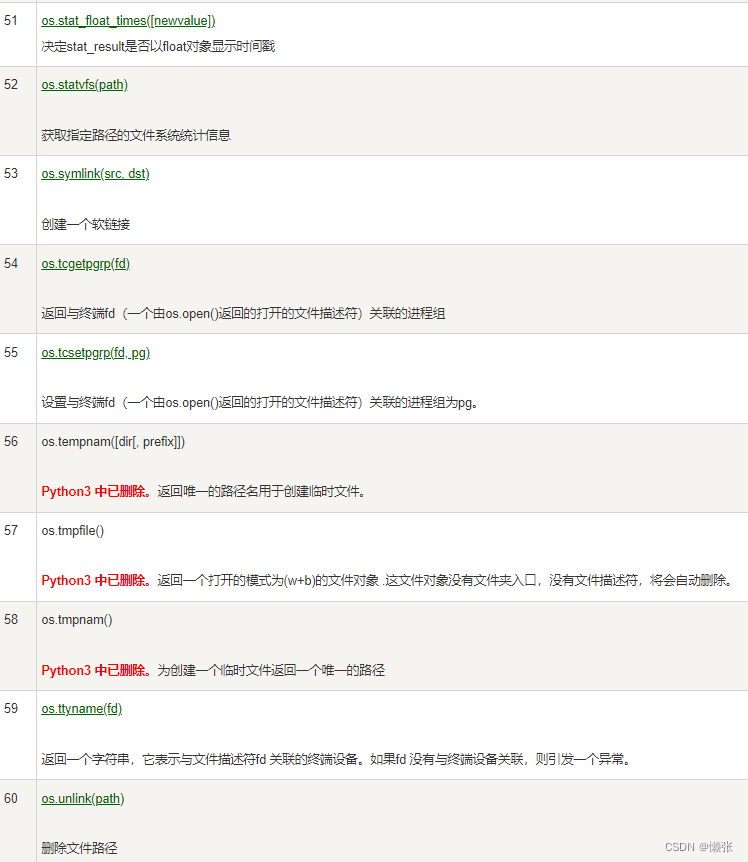
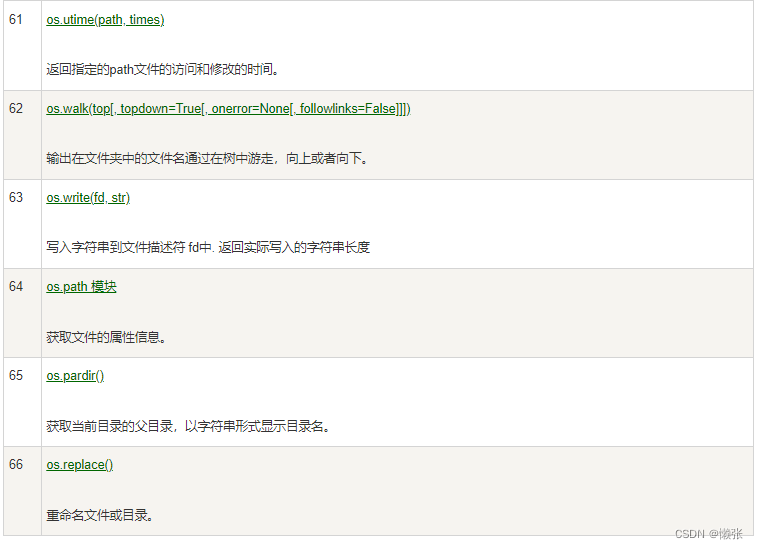
9、os模块
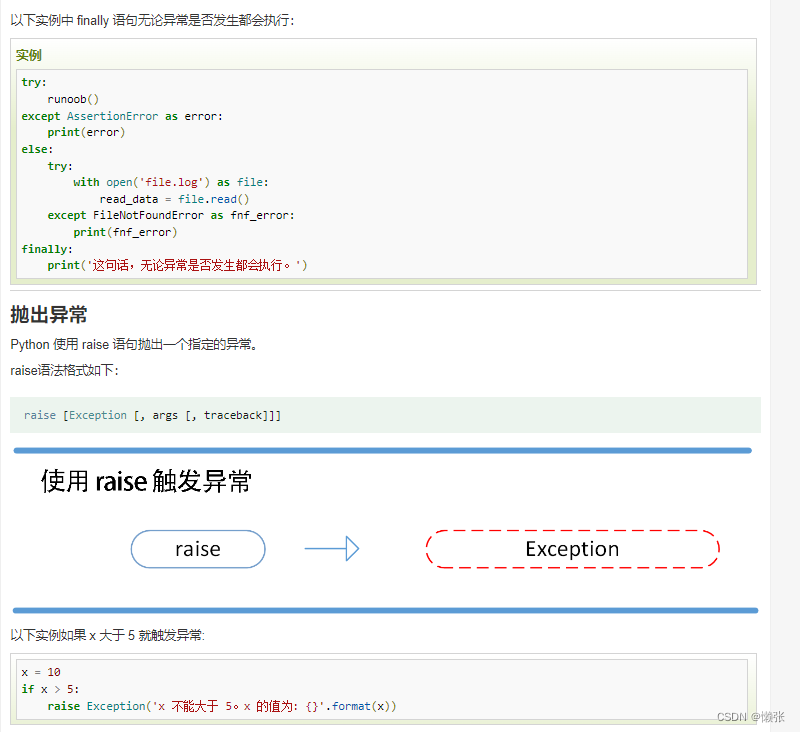
十四、异常
1、异常
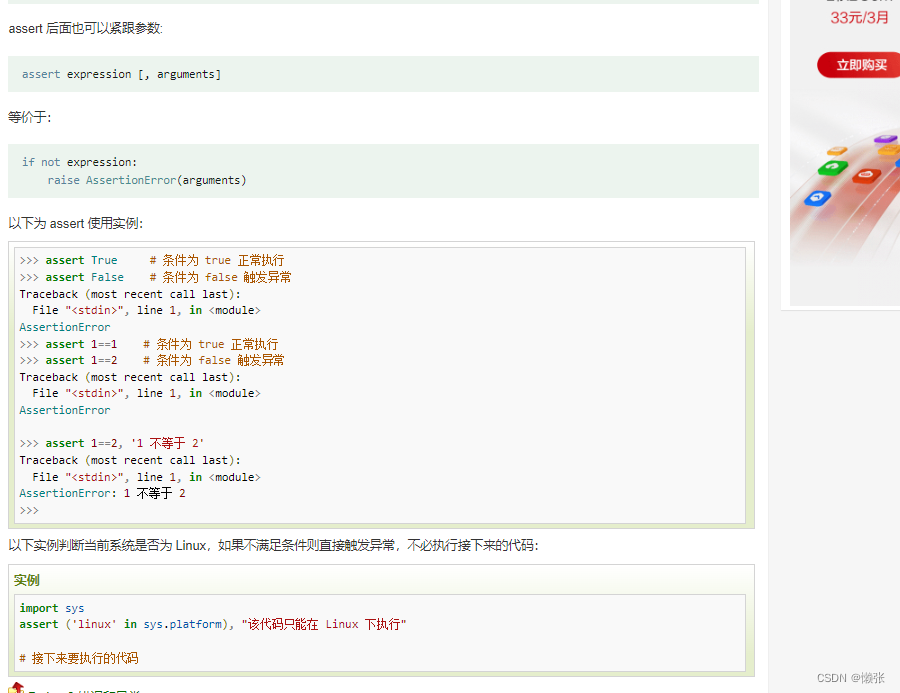
2、断言
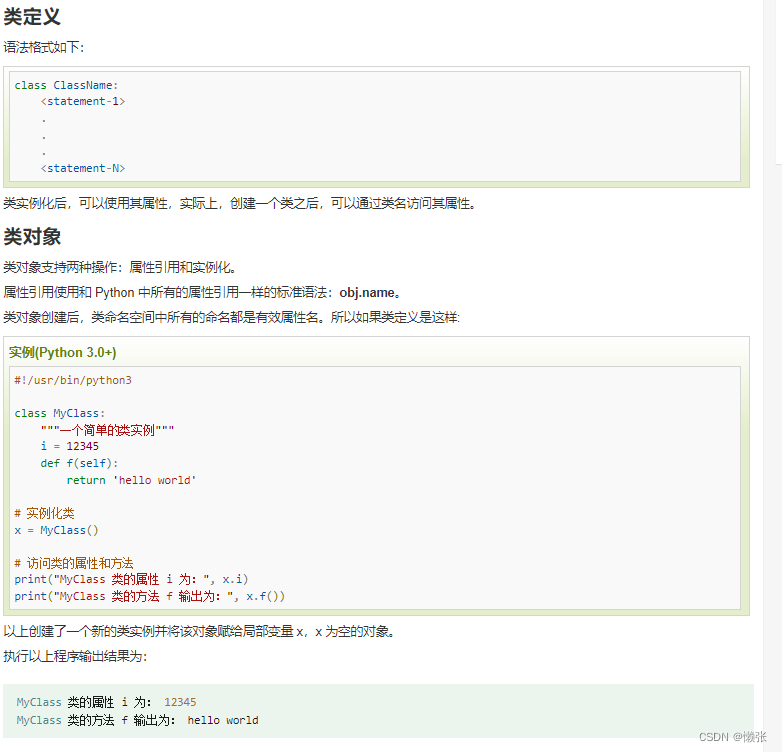
十五、面向对象(类)
1、类创建
2、构造函数__init__()
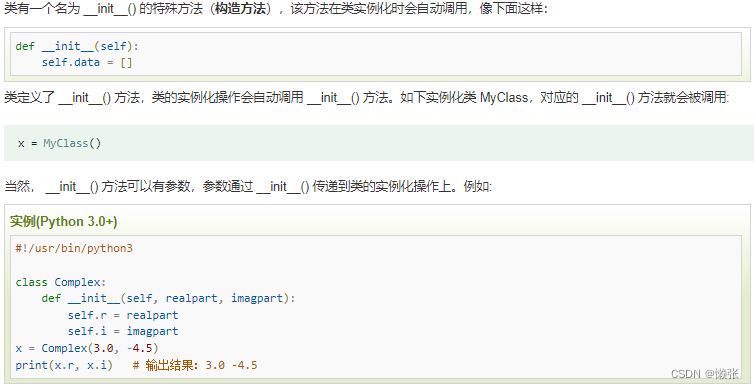
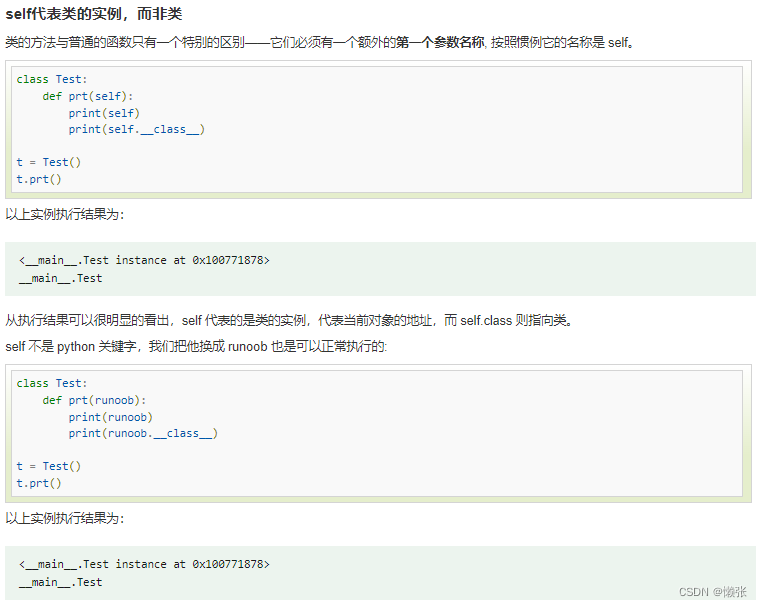
3、类实体(构造函数的参数)
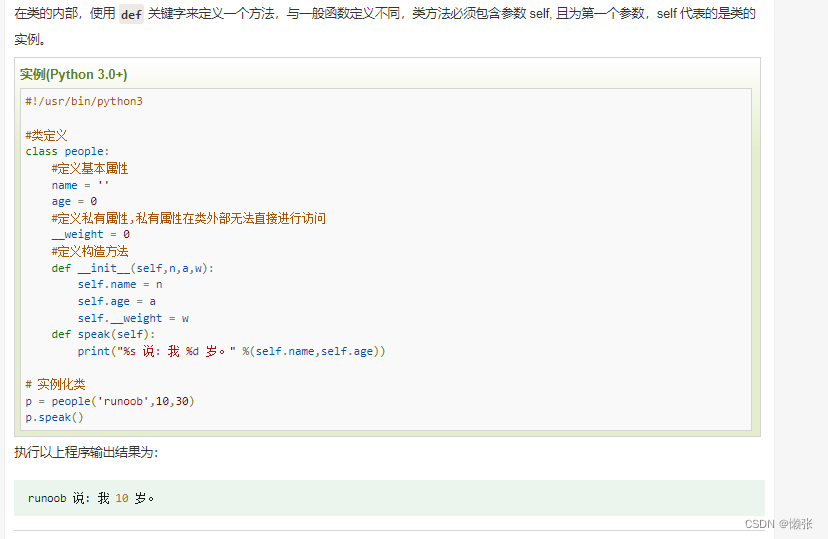
4、类如何写函数
5、继承
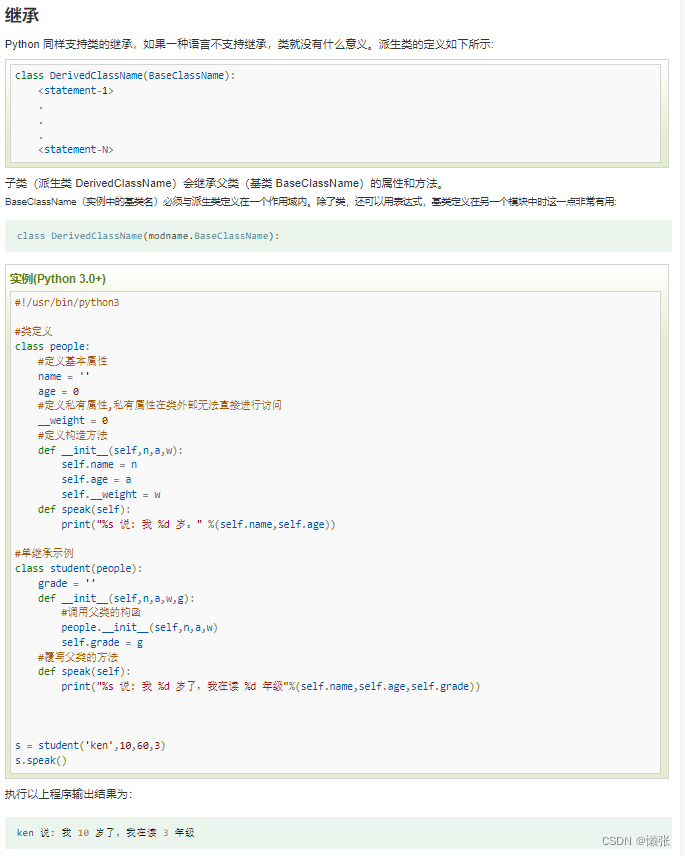
与java不同的是它支持多继承

6、重写
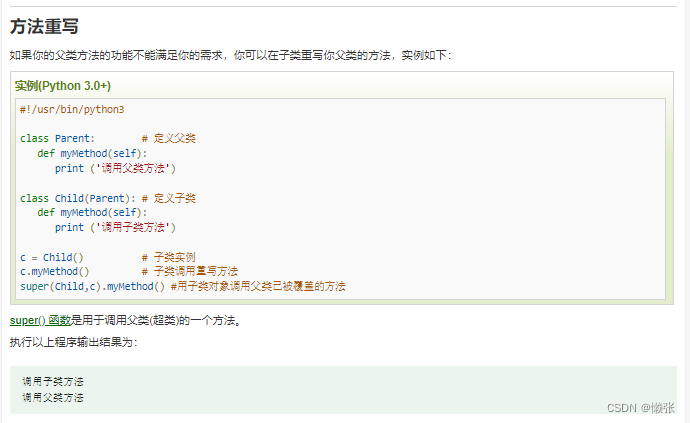
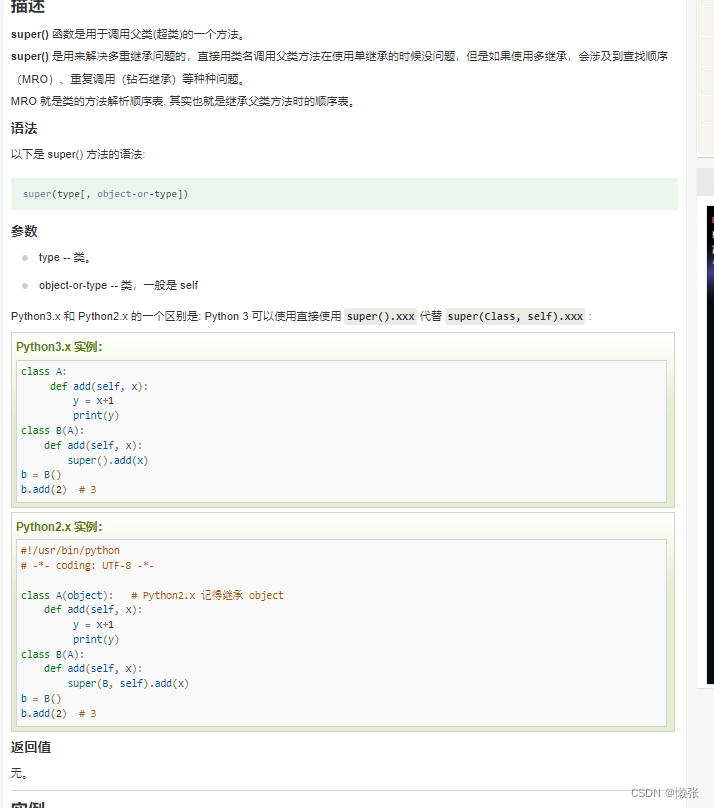
7、掉父类方法
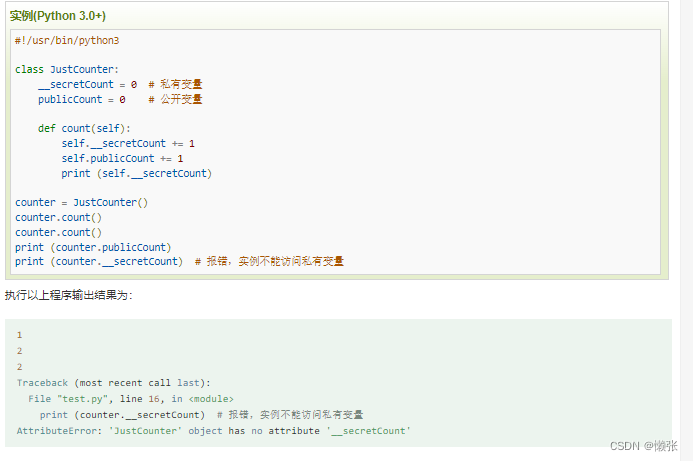
8、 私有变量和私有方法

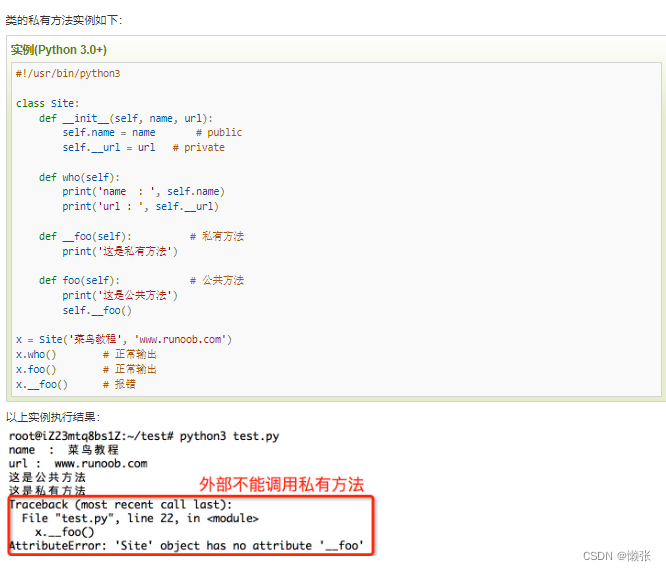
私有属性如何去掉
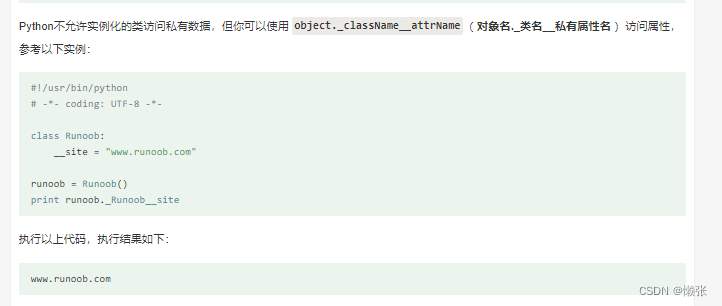
9、类专有方法

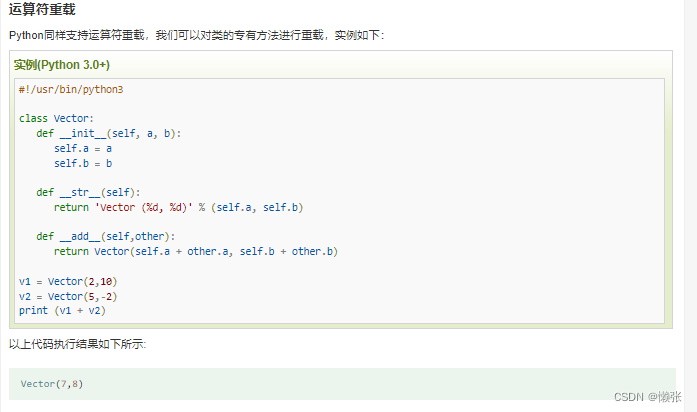
10、运算符重载
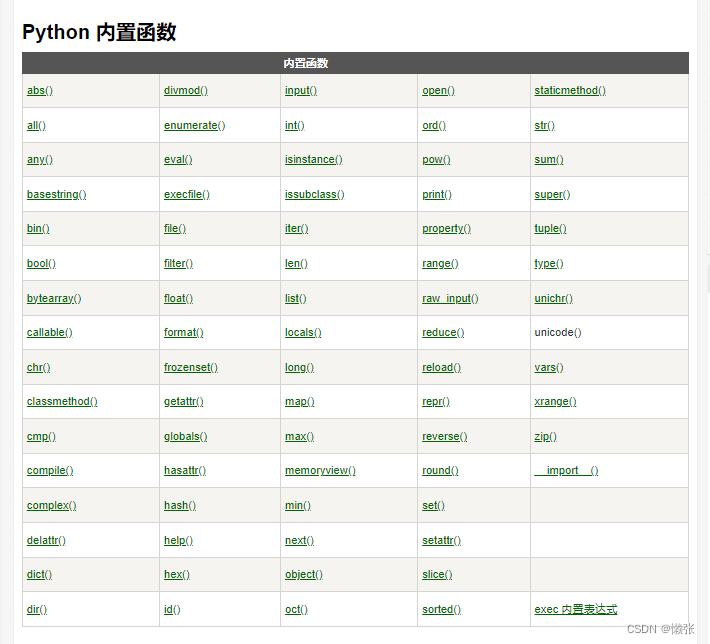
十六、内置函数
十七、作用域
1、修改全局变量(global)
Money = 2000
def AddMoney():
# 想改正代码就取消以下注释:
global Money
Money = Money + 1
print(Money)
return Money
2、内嵌局部修改局部参数(nonlocal )
#!/usr/bin/python3
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
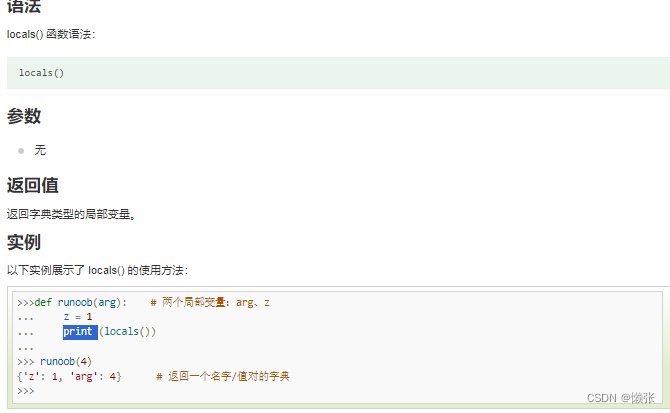
3、获取全局变量和局部变量函数
全局
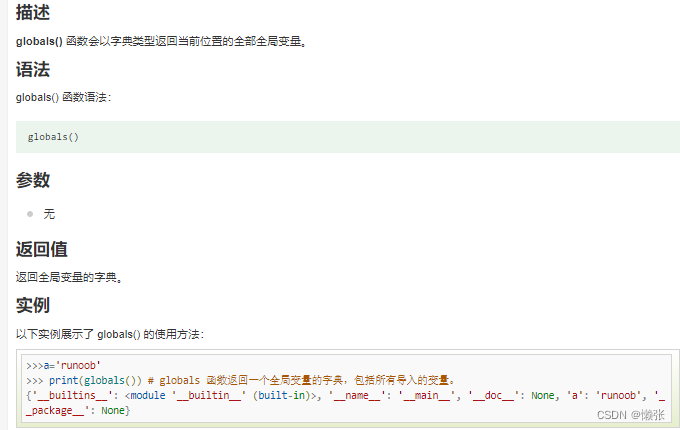
局部
十八、标准库
Python 标准库非常庞大,所提供的组件涉及范围十分广泛,使用标准库我们可以让您轻松地完成各种任务。
以下是一些 Python3 标准库中的模块:
-
os 模块:os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。
-
sys 模块:sys 模块提供了与 Python 解释器和系统相关的功能,例如解释器的版本和路径,以及与 stdin、stdout 和 stderr 相关的信息。
-
time 模块:time 模块提供了处理时间的函数,例如获取当前时间、格式化日期和时间、计时等。
-
datetime 模块:datetime 模块提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等。
-
random 模块:random 模块提供了生成随机数的函数,例如生成随机整数、浮点数、序列等。
-
math 模块:math 模块提供了数学函数,例如三角函数、对数函数、指数函数、常数等。
-
re 模块:re 模块提供了正则表达式处理函数,可以用于文本搜索、替换、分割等。
-
json 模块:json 模块提供了 JSON 编码和解码函数,可以将 Python 对象转换为 JSON 格式,并从 JSON 格式中解析出 Python 对象。
-
urllib 模块:urllib 模块提供了访问网页和处理 URL 的功能,包括下载文件、发送 POST 请求、处理 cookies 等。
1、操作系统接口
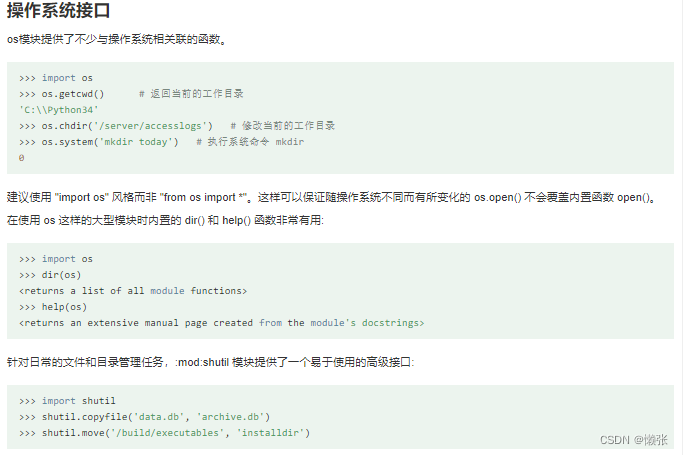
2、文件通配符

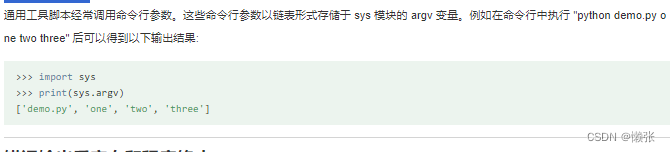
3、 命令行参数
4、 字符串正则匹配

5、数字
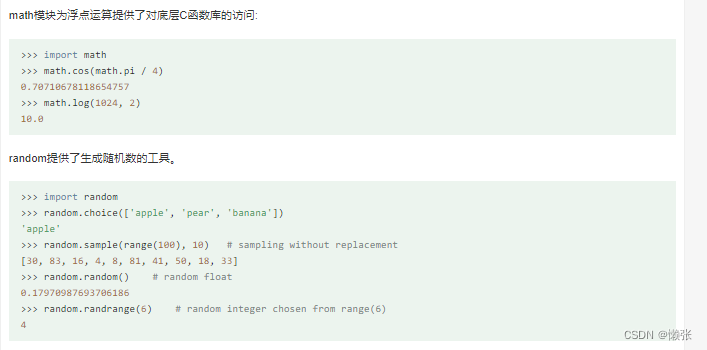
6、 访问互联网
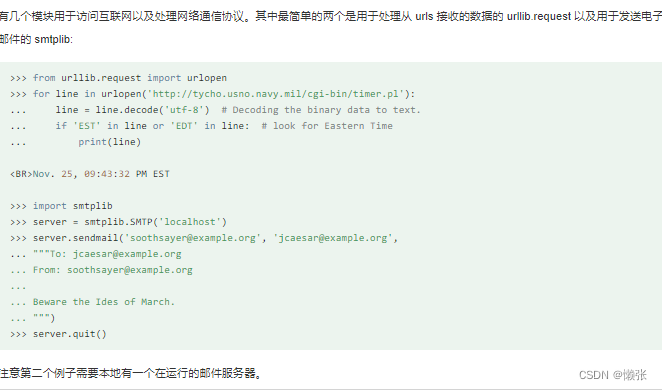
7、日期和时间
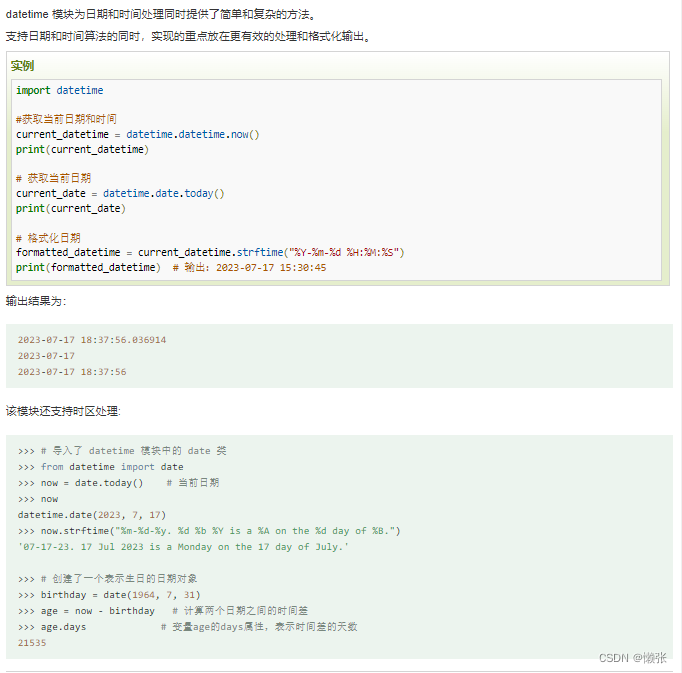
8、 数据压缩

9、 性能度量

10、 测试模块

十九、正则
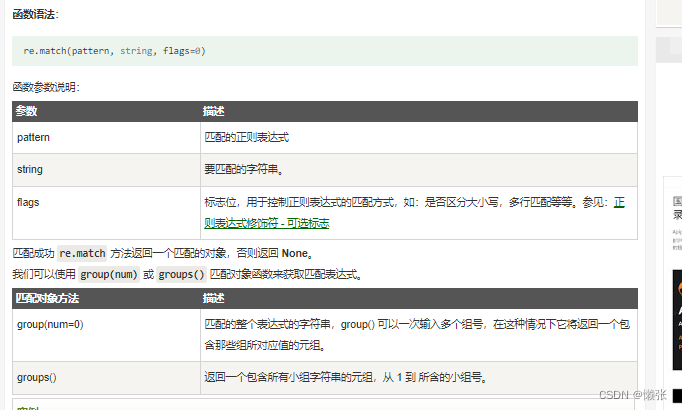
1、 re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 None。
import re
# span()是取出来re.match('www', 'www.runoob.com')返回的是对象中的属性
print(re.match('www', 'www.runoob.com').span()) # 在起始位置到最终位置匹配
print(re.match('com', 'www.runoob.com')) # 起始位置匹配
例如,假设有一个字符串 “2023-12-13”,我们想要提取年、月和日的信息。我们可以使用正则表达式来匹配这个字符串,并使用括号来创建匹配组来捕获这些信息:
import re
# 匹配模式并创建匹配组捕获年、月和日
pattern = r'(\d{4})-(\d{2})-(\d{2})'
match = re.match(pattern, '2023-12-13')
# 获取整个匹配
print(match.group(0)) # 输出: 2023-12-13
# 获取第一个括号匹配的内容(年份)
print(match.group(1)) # 输出: 2023
# 获取第二个括号匹配的内容(月份)
print(match.group(2)) # 输出: 12
# 获取第三个括号匹配的内容(日期)
print(match.group(3)) # 输出: 13
2、re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。

#!/usr/bin/python3
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
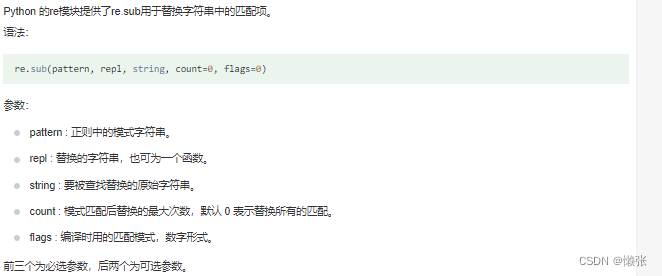
3、检索和替换
#!/usr/bin/python3
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
repl 参数是一个函数
#!/usr/bin/python
import re
# 将匹配的数字乘以 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
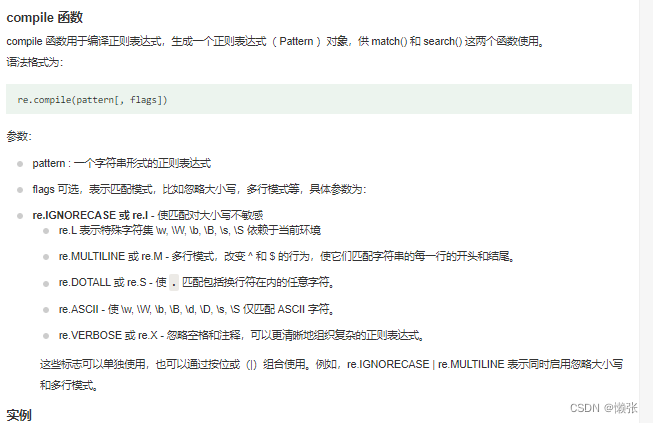
4、compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print( m ) # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
5、 findall

import re
result1 = re.findall(r'\d+','runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(result3)
多个匹配模式,返回元组列表:
import re
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)
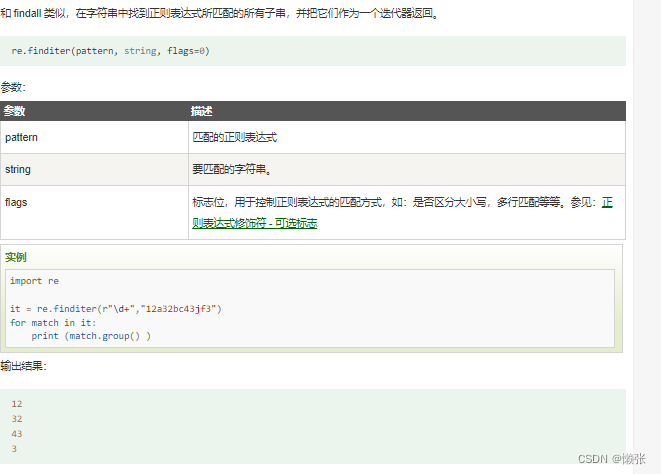
6、re.finditer
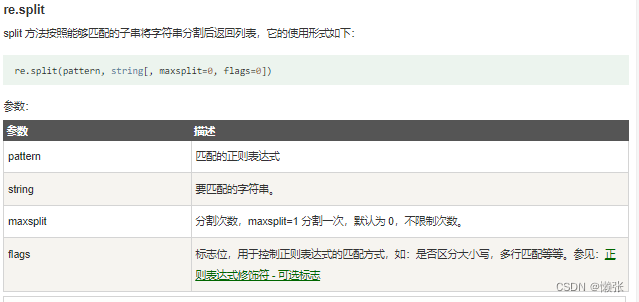
7、re.split
import re
# 分割字符串
result = re.split(r'\s+', 'Splitting this string by spaces')
print(result)
# 输出: ['Splitting', 'this', 'string', 'by', 'spaces']
# 指定最大分割次数为1
result_with_limit = re.split(r'\s+', 'Splitting this string by spaces', maxsplit=1)
print(result_with_limit)
# 输出: ['Splitting', 'this string by spaces']
8、表达式对象

9、表达式和正则表达式修饰符 - 可选标志
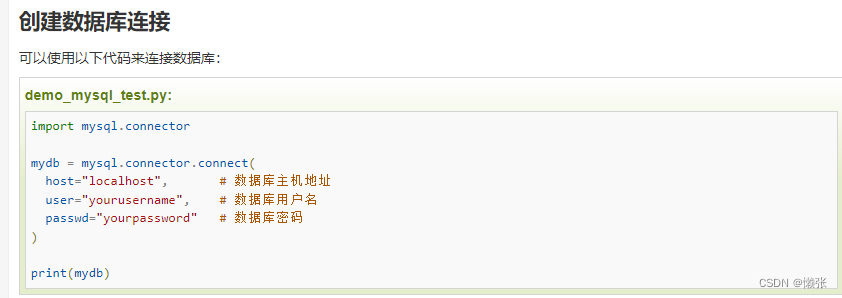
二十、链接数据库mysql
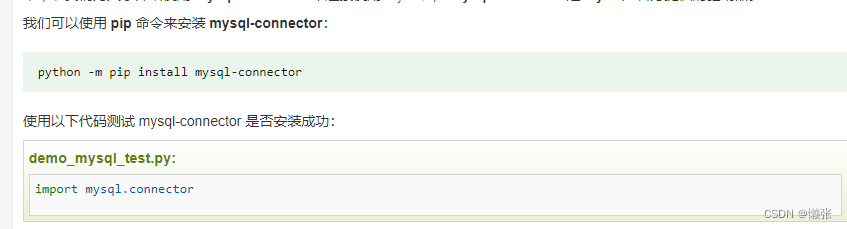
1、创建链接
安装mysql连接包
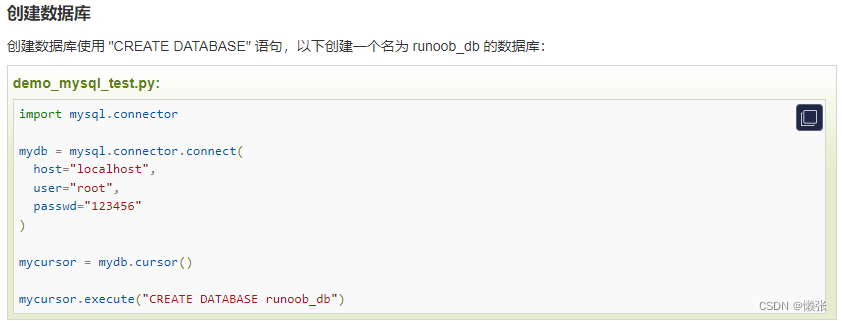
2、创建数据库
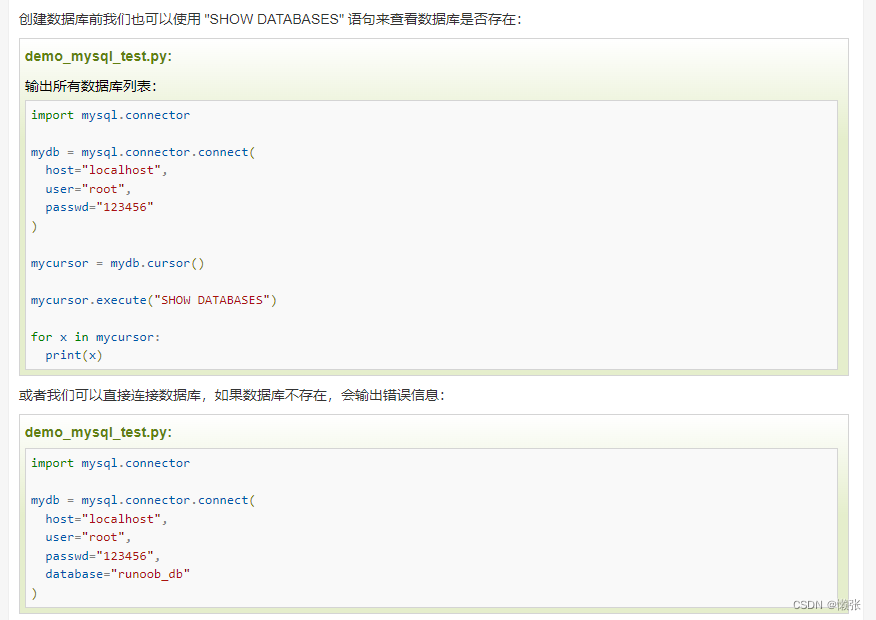
查看数据库是否存在
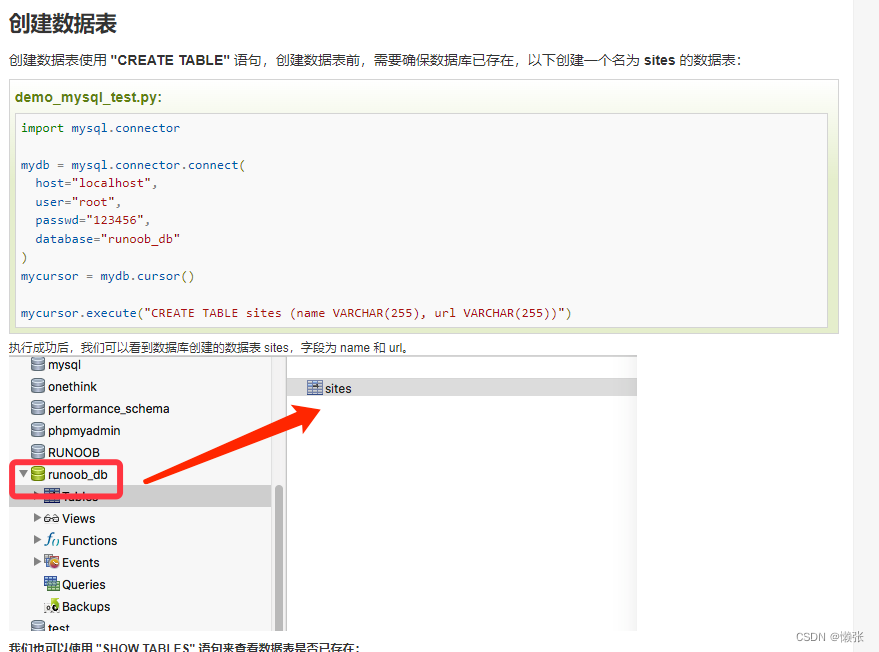
3、创建数据库表
查看数据表是否存在
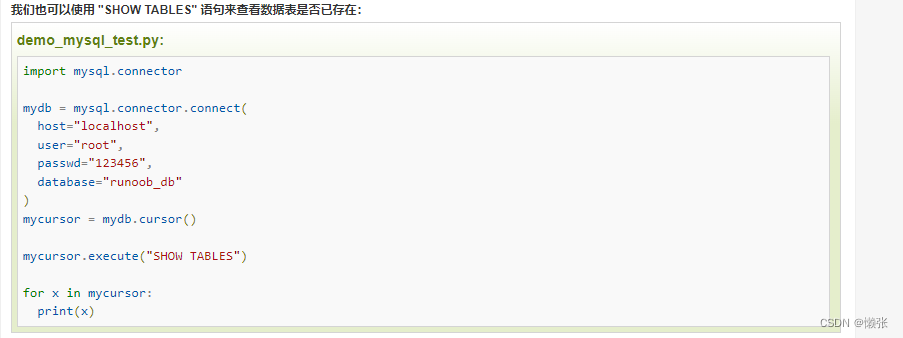
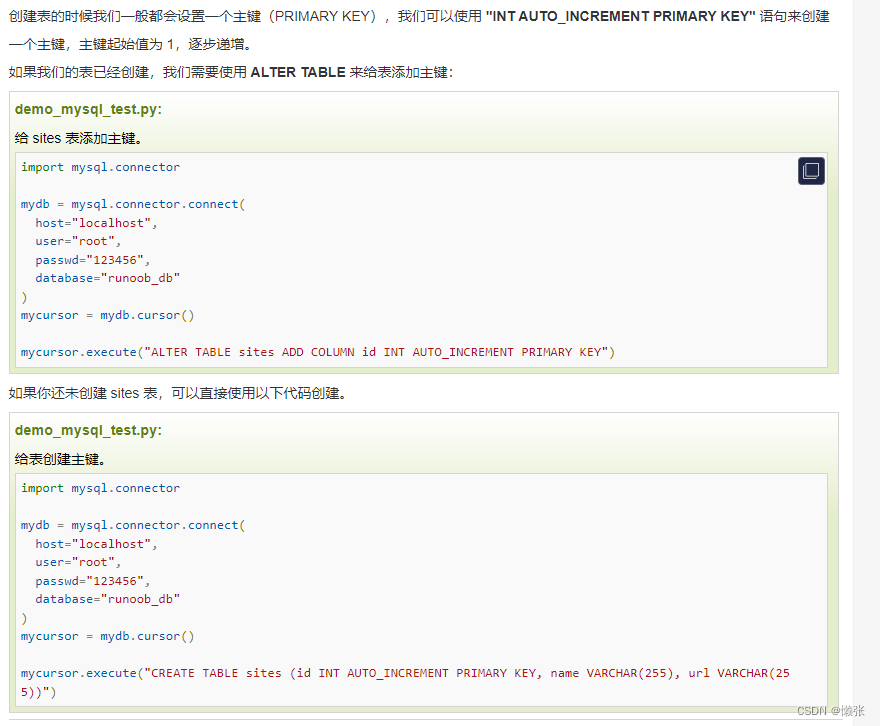
主键设置
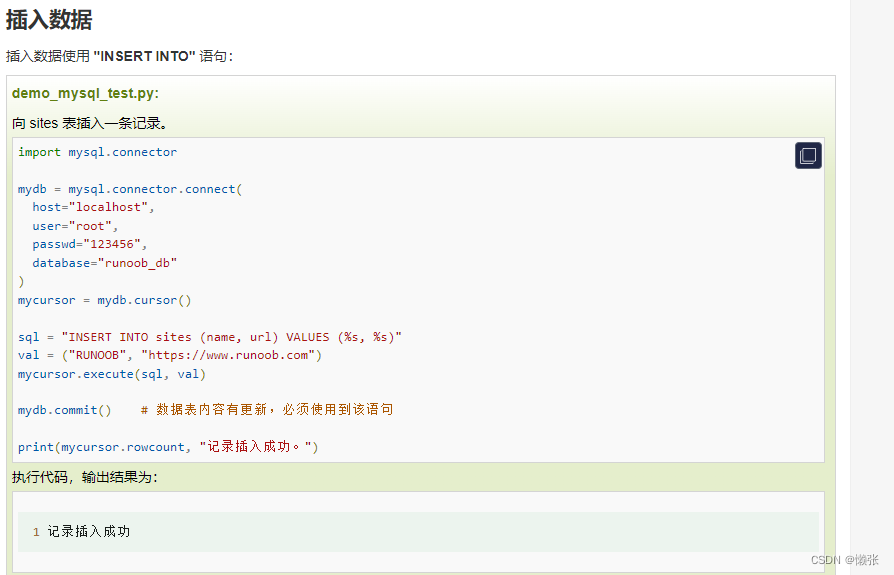
4、插入数据
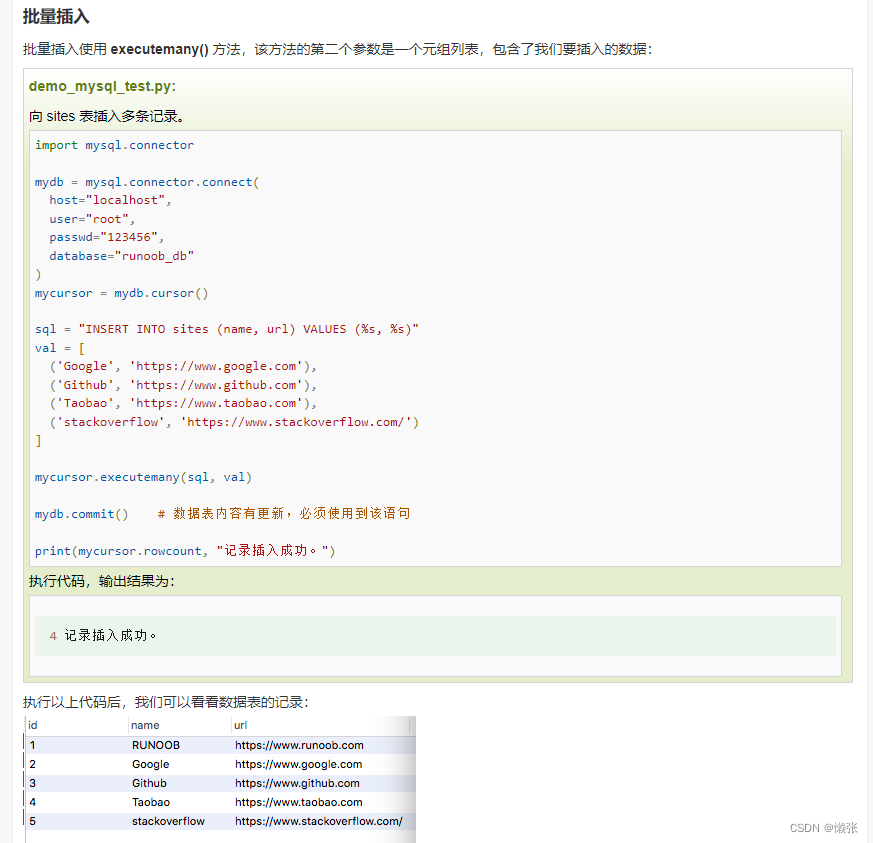
批量插入
获取插入id
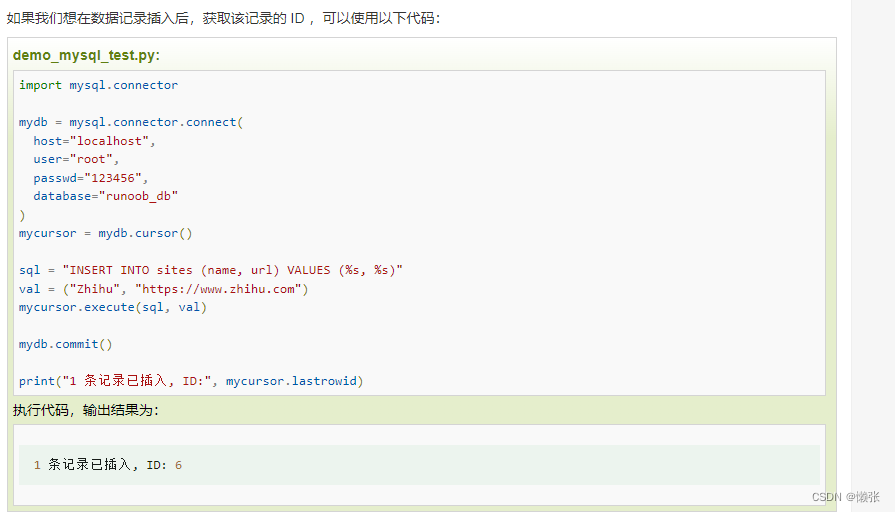
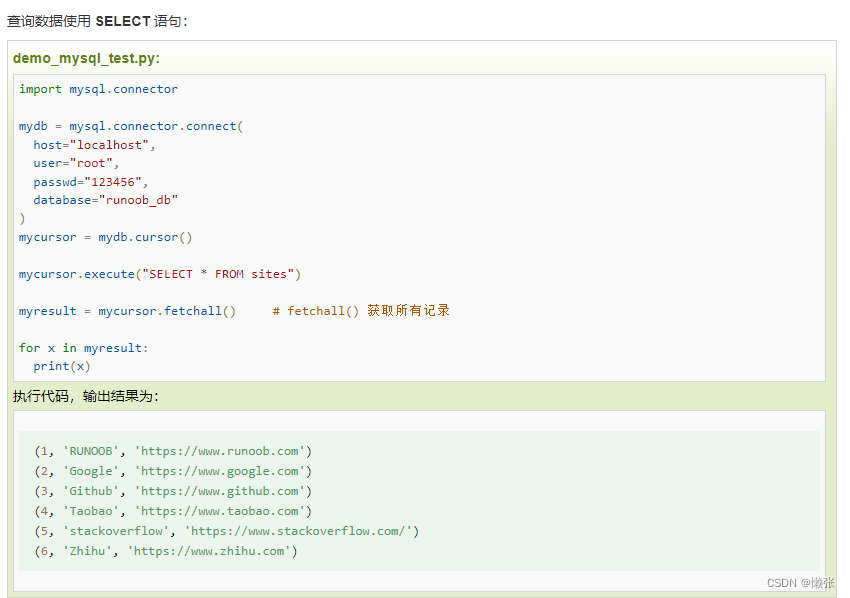
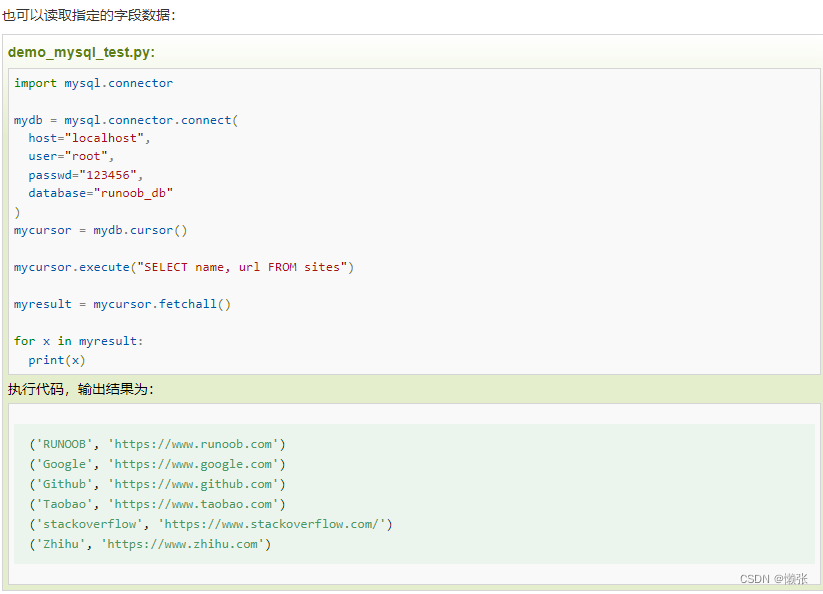
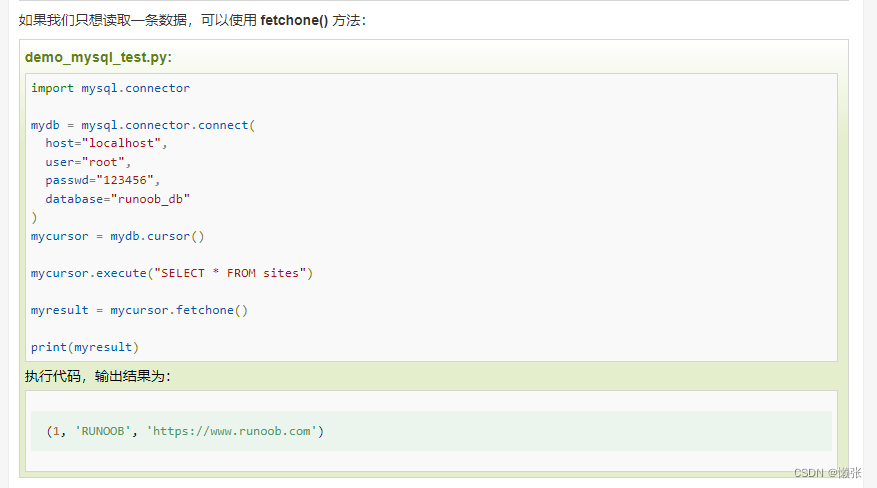
5、查询数据
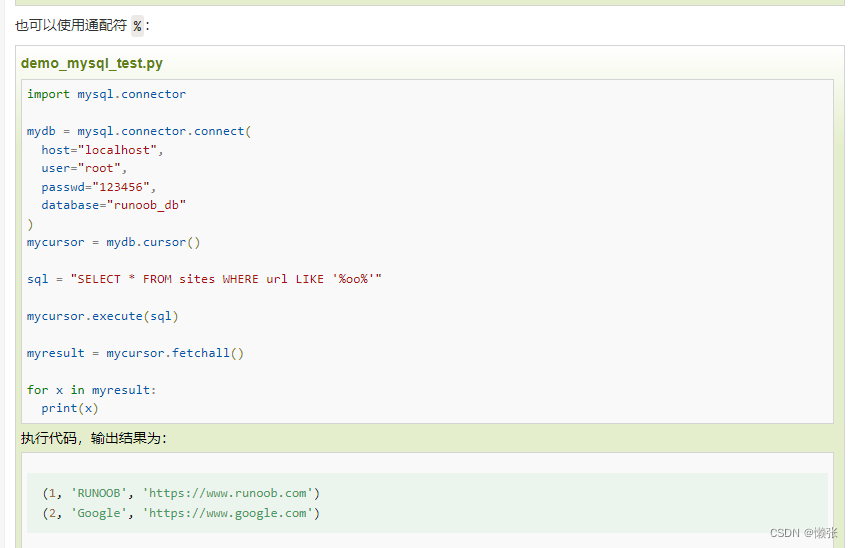
6、防止sql注入
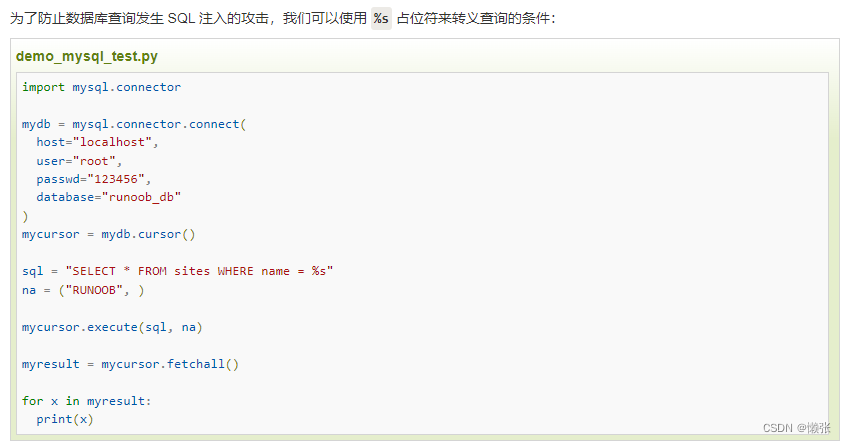
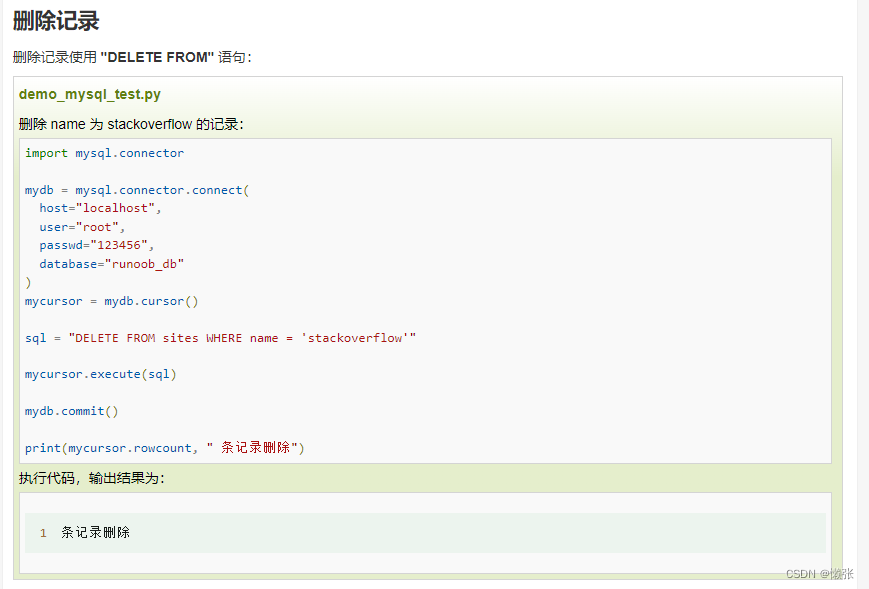
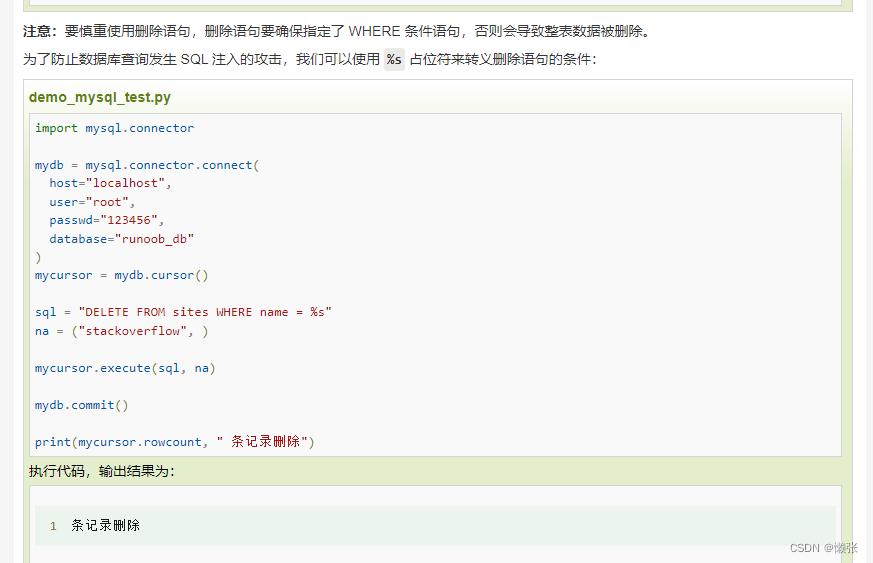
7、删除
8、修改
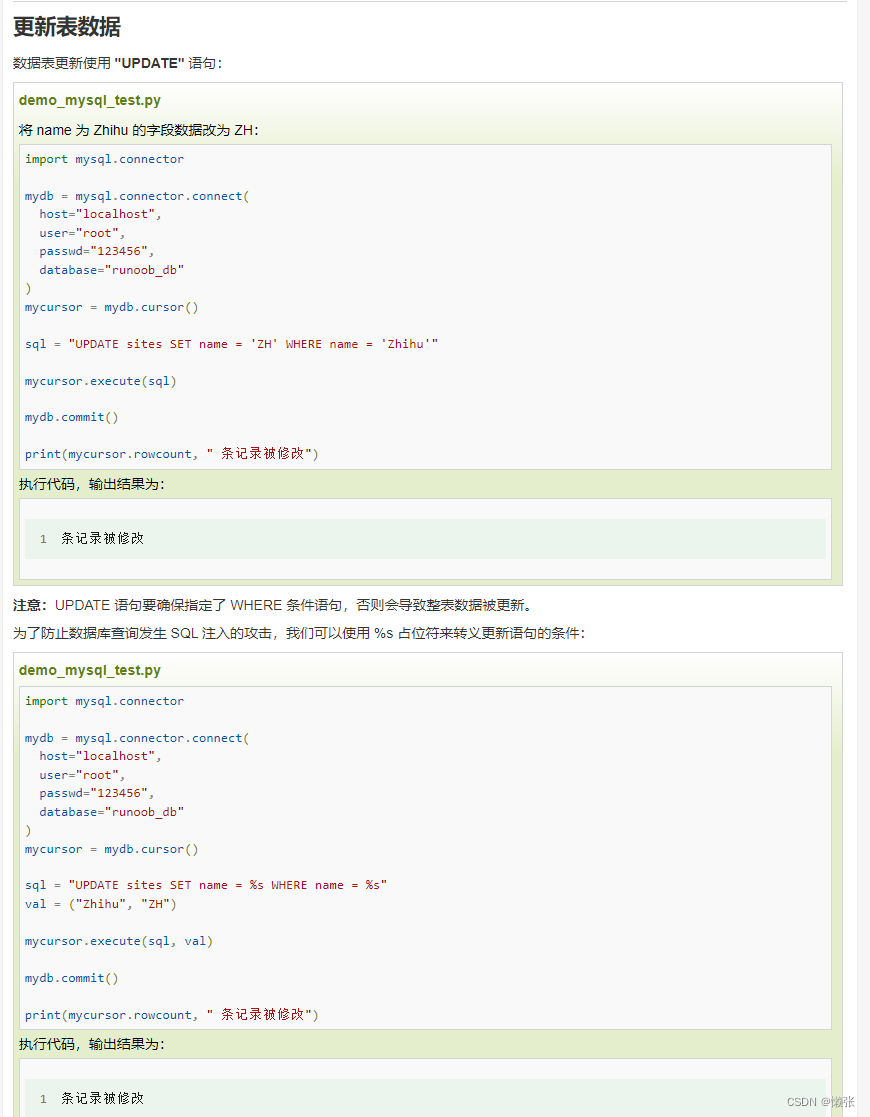
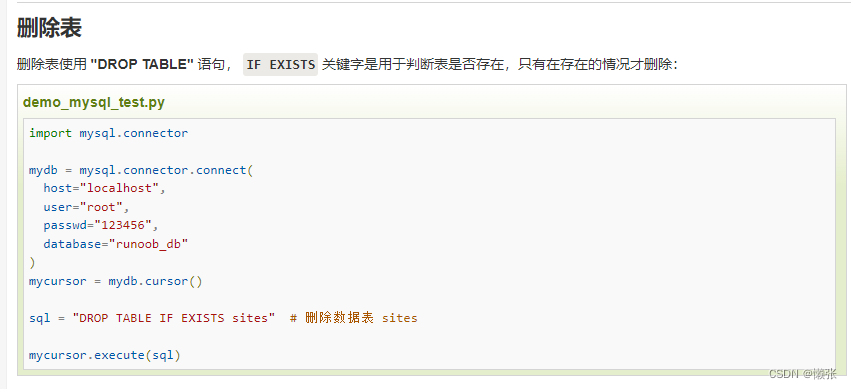
9、删除表
二十一、xml解析
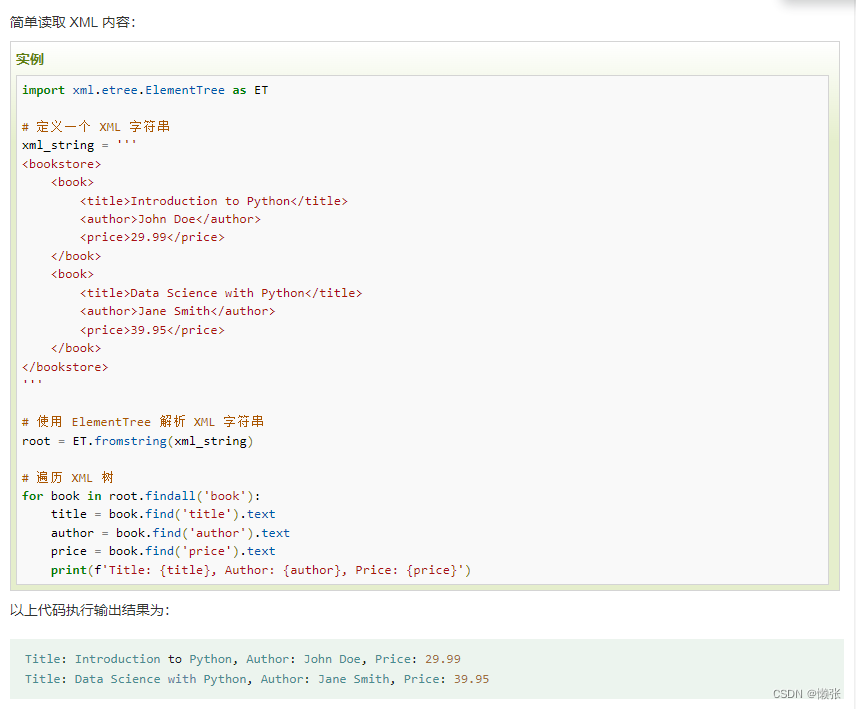
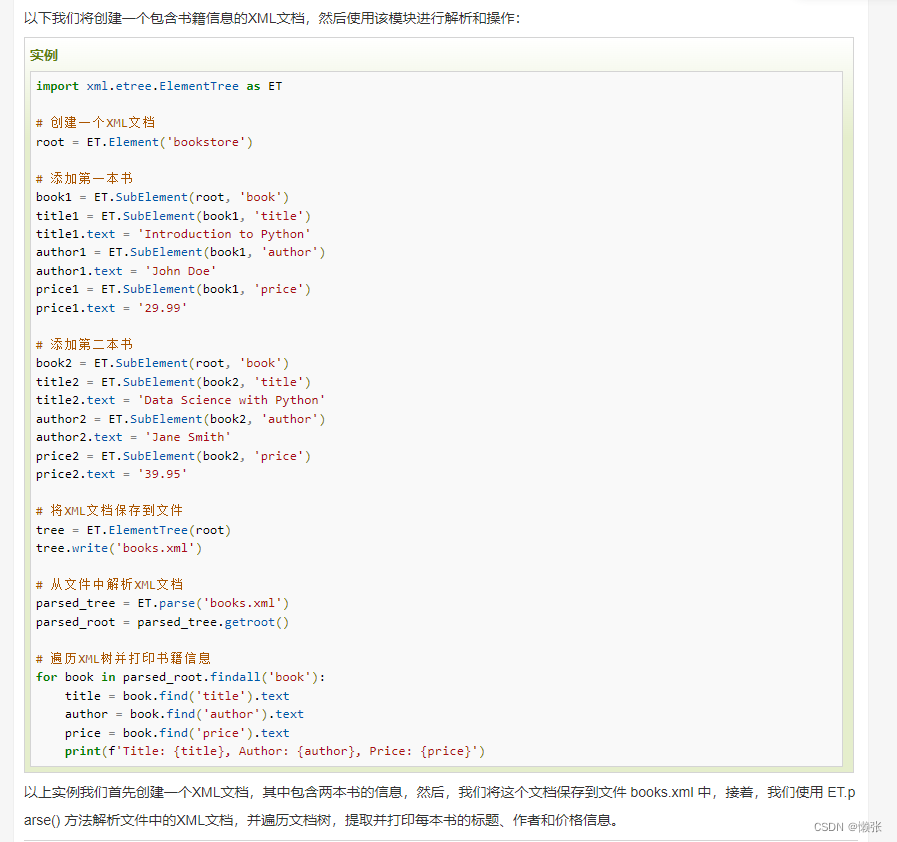
1、使用 ElementTree 解析 xml
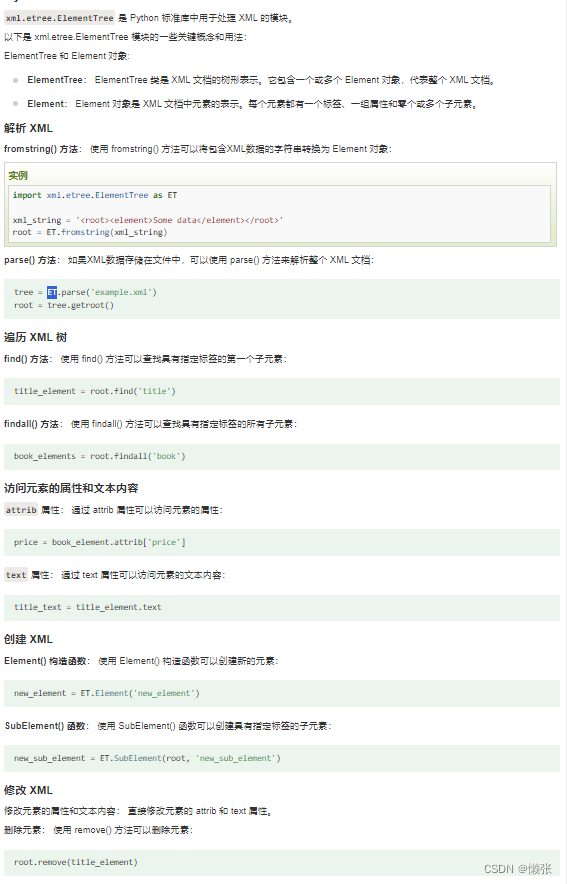
示例
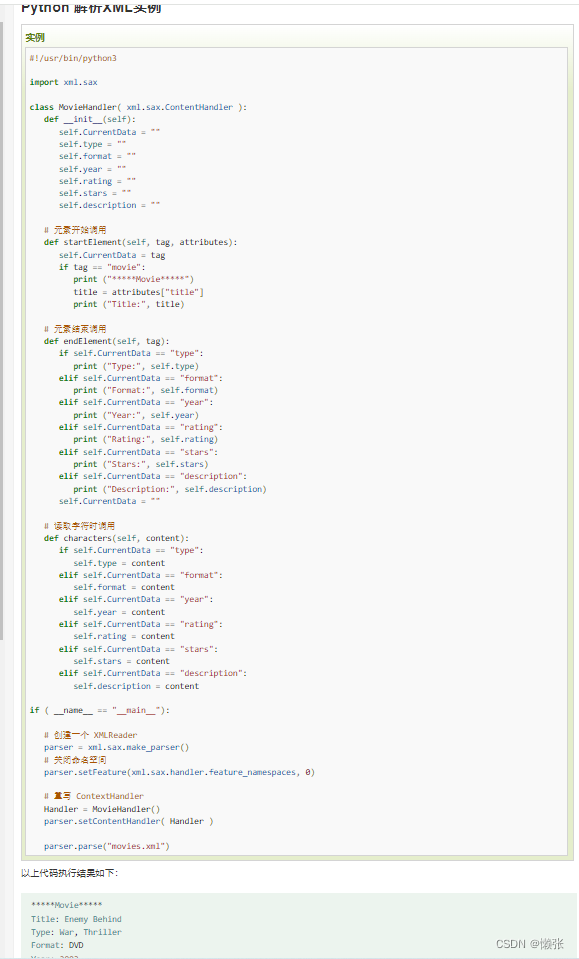
2、使用 SAX 解析 xml

示例
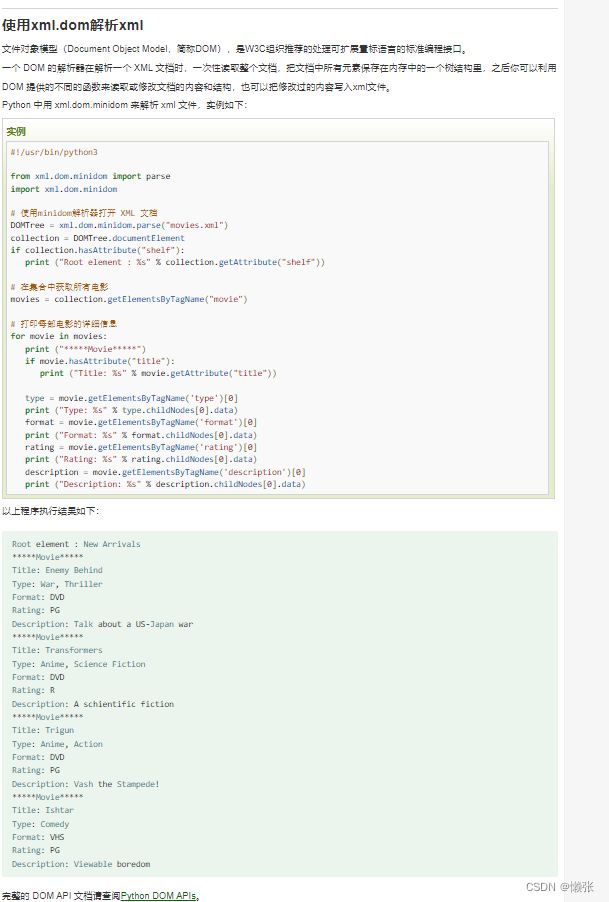
3、使用xml.dom解析xml
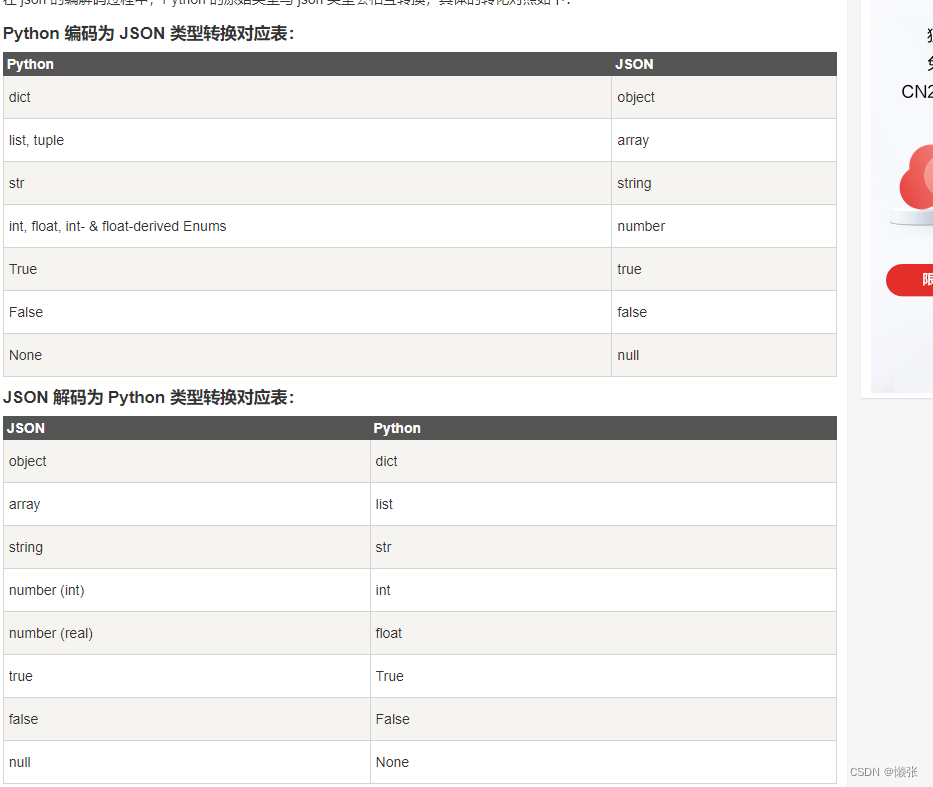
二十二、json解析
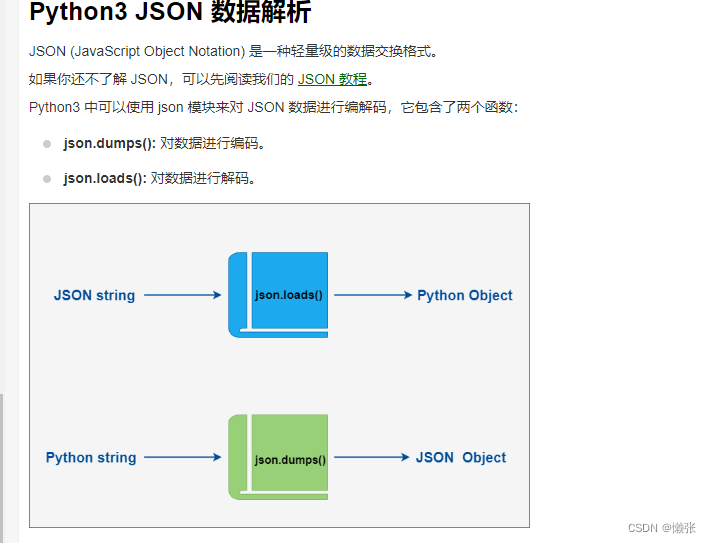
1、解释
2、类型
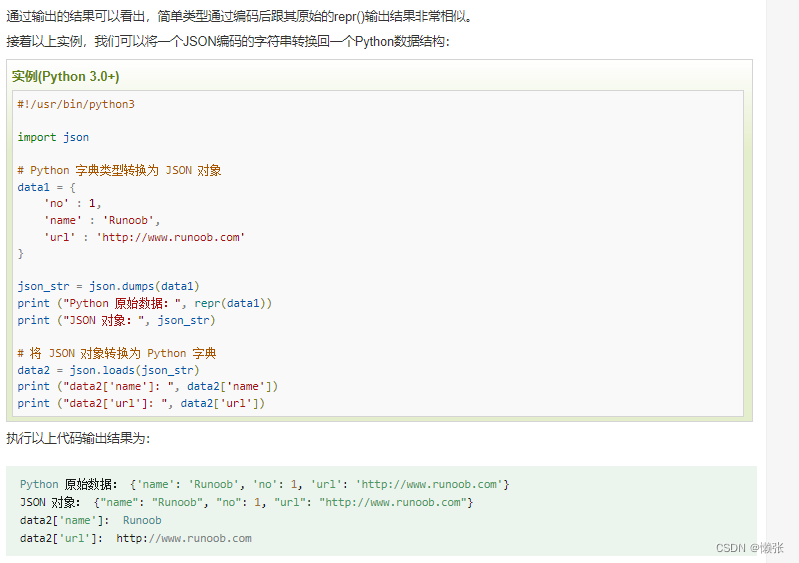
3、解析和转换
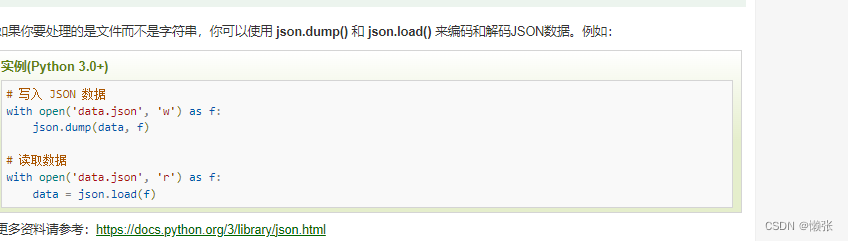
4、json文件
二十三、页面url获取元素 http请求
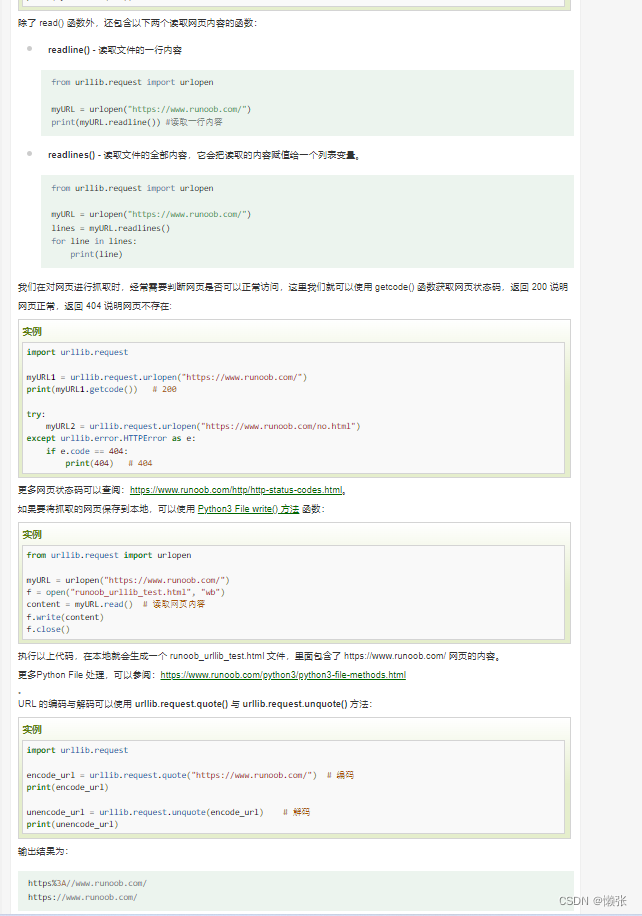
1、读取
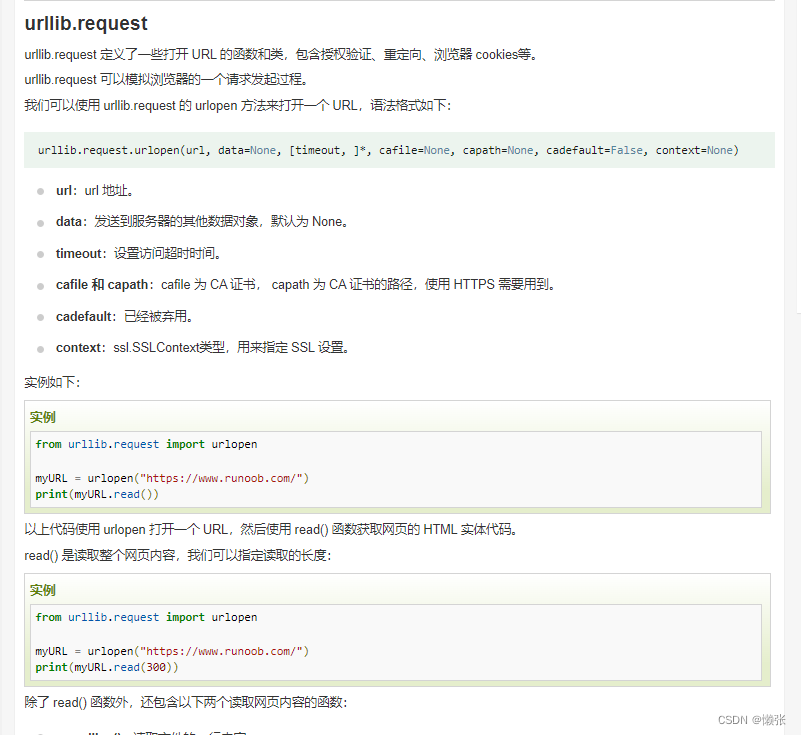
逐行读取 + 请求路径编码与解码
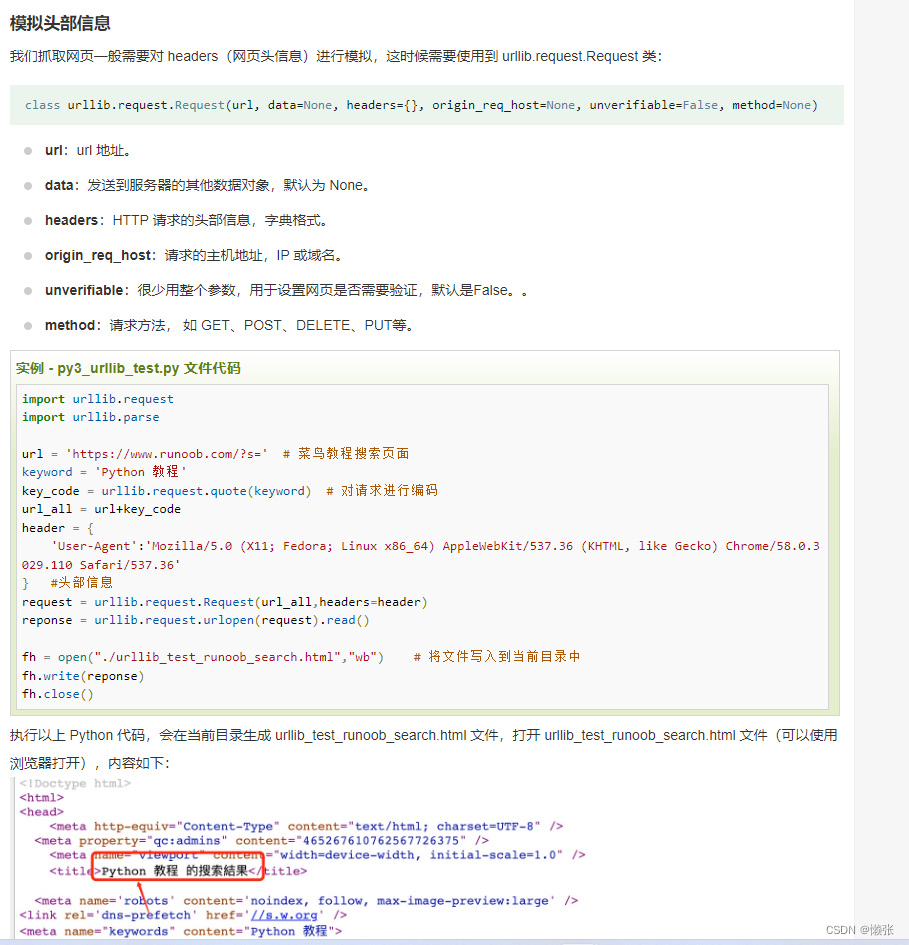
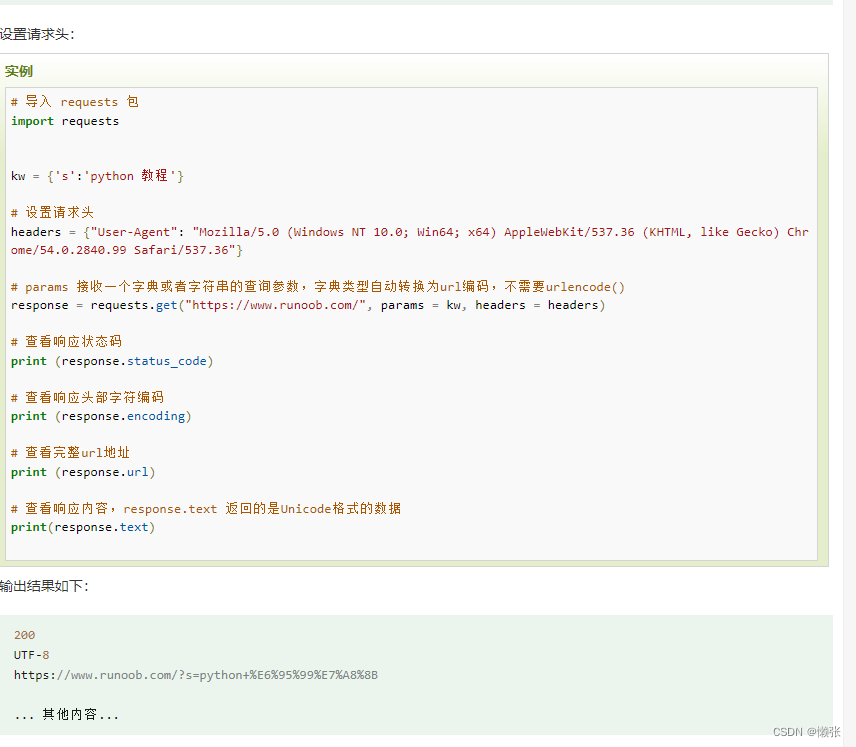
2、模拟请求头
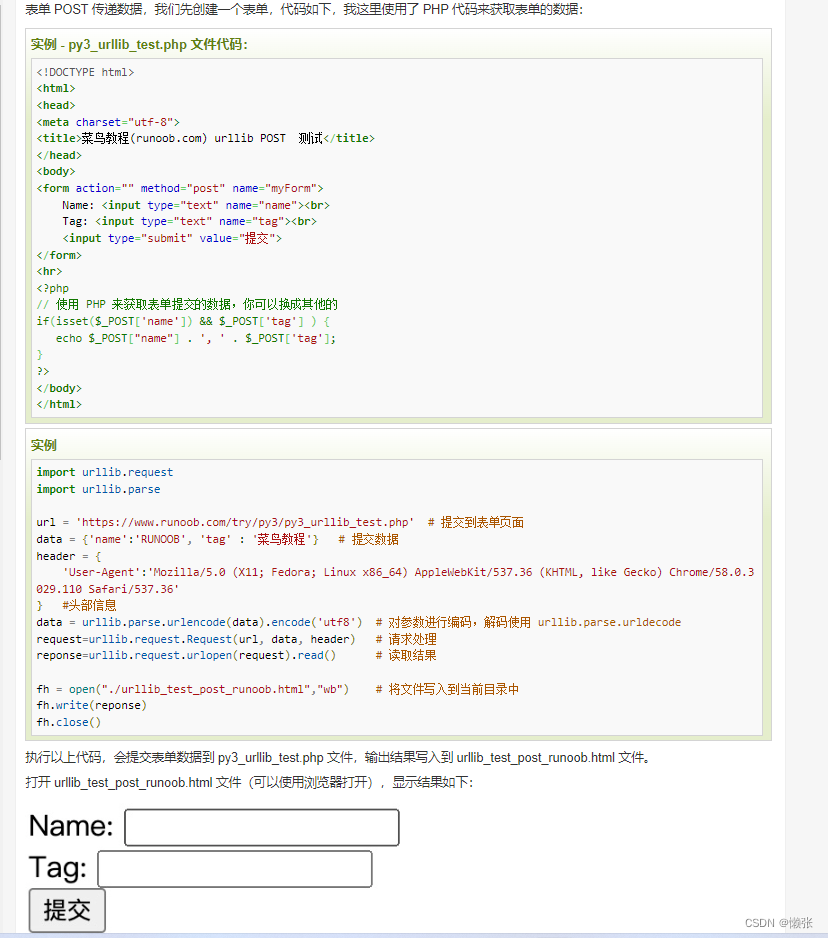
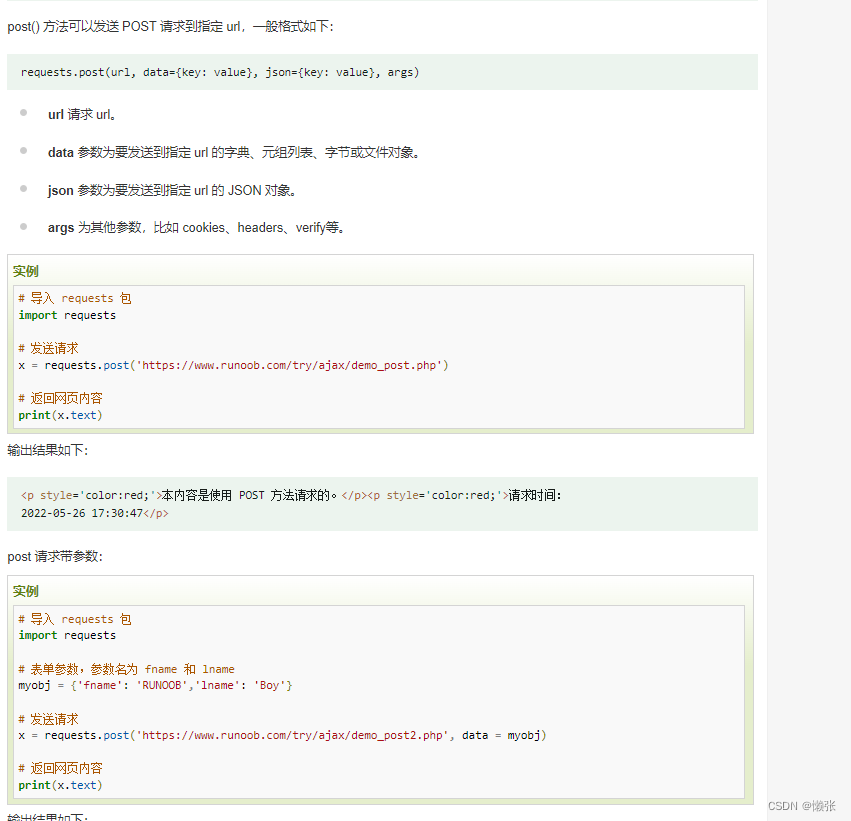
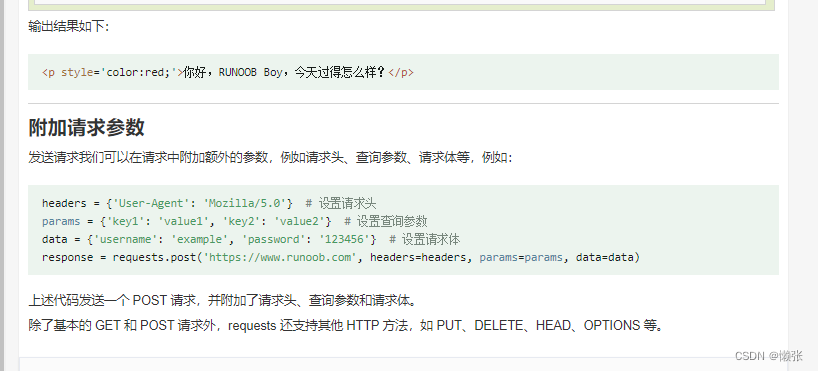
3、提交表单

4、由于read方法后是bytes类型,输出转换
import urllib.request
import urllib.parse
if __name__ == '__main__':
url = 'https://www.runoob.com/try/py3/py3_urllib_test.php' # 提交到表单页面
data = {'name': 'RUNOOB', 'tag': '菜鸟教程'} # 提交数据
header = {
'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} # 头部信息
data = urllib.parse.urlencode(data).encode('utf8') # 对参数进行编码,解码使用 urllib.parse.urldecode
request = urllib.request.Request(url, data, header) # 请求处理
response=urllib.request.urlopen(request).read() # 读取结果
print(response.decode("utf-8"))
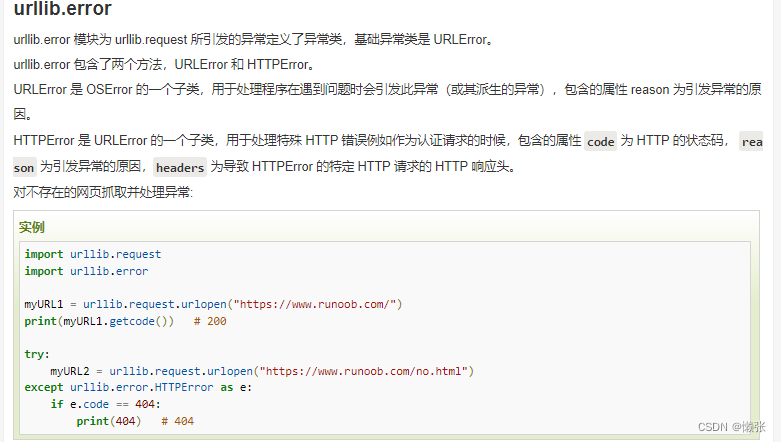
5、urllib.error
6、urllib.parse解析
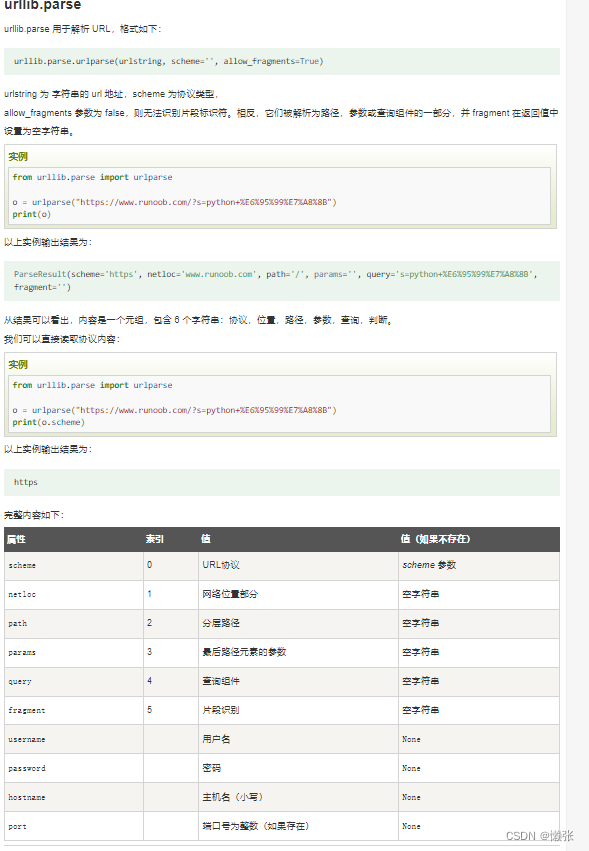
7、超时时间
import urllib.request
url = 'https://www.example.com'
try:
response = urllib.request.urlopen(url, timeout=5) # 设置超时时间为 5 秒
# 处理响应的代码
print(response.read()) # 读取响应内容示例
except urllib.error.URLError as e:
print("Error:", e)
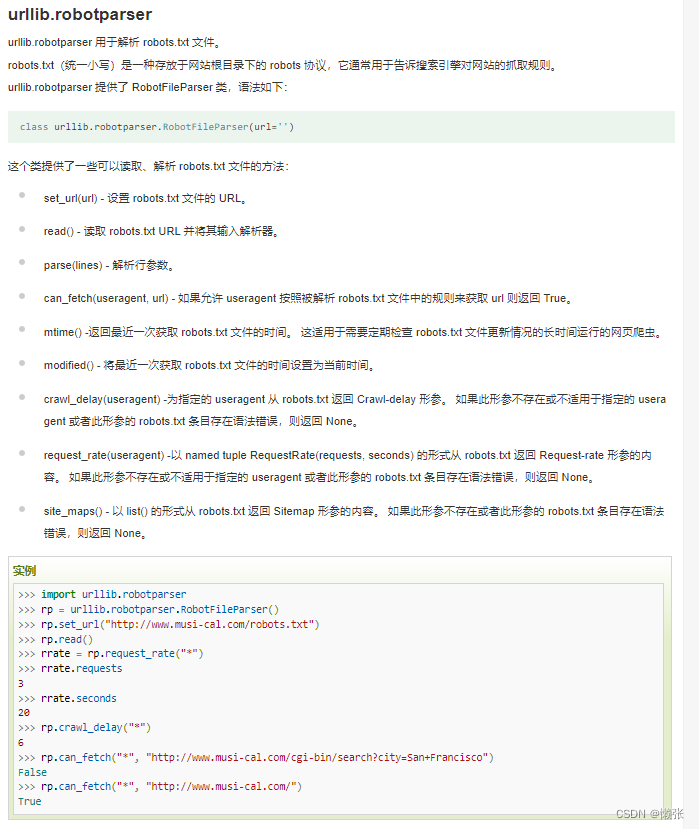
8、urllib.robotparser
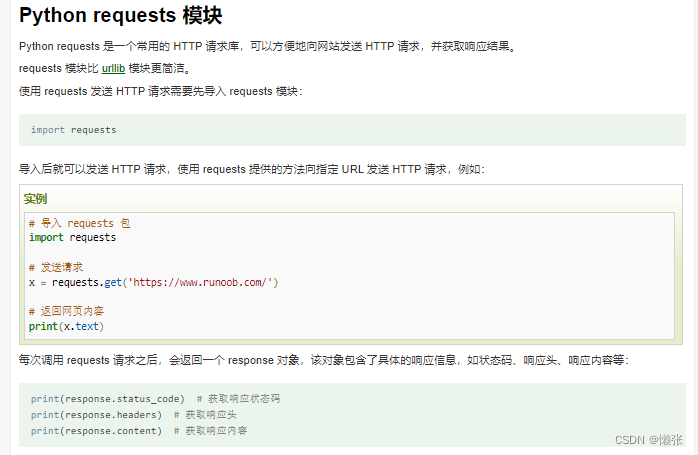
二十四、调取http接口requests模块
1、使用
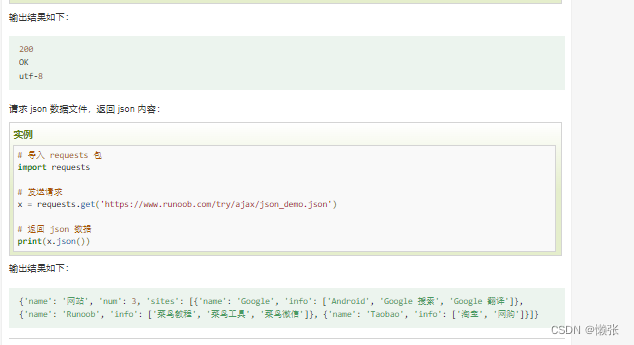
2、方法

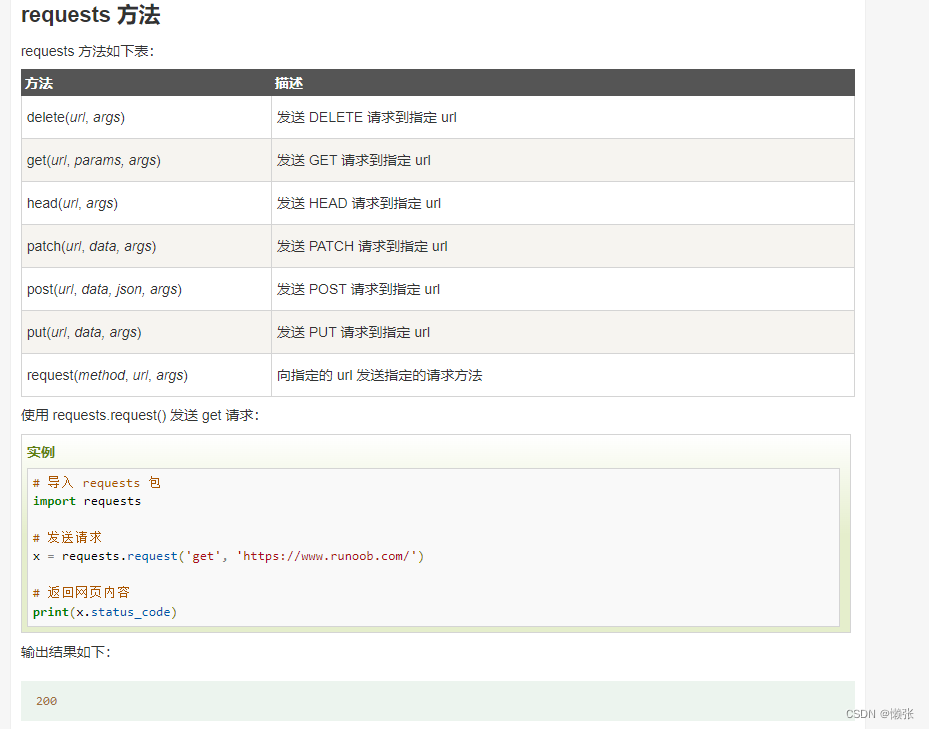
3、request方法
二十五、多线程
1、多线程
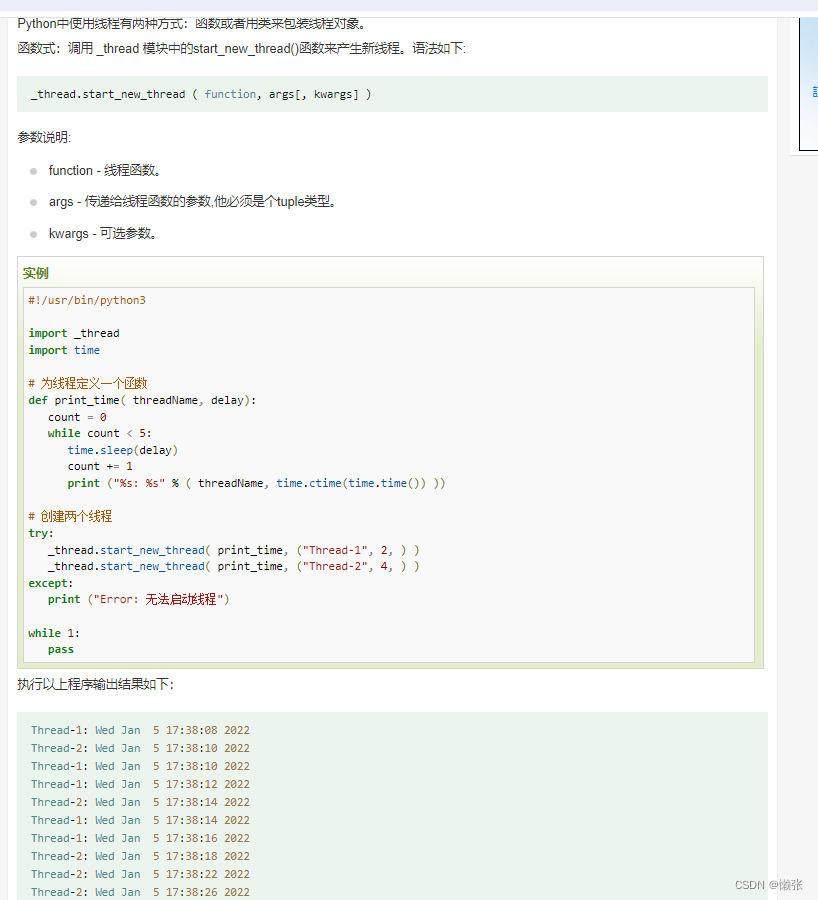
2、线程模块

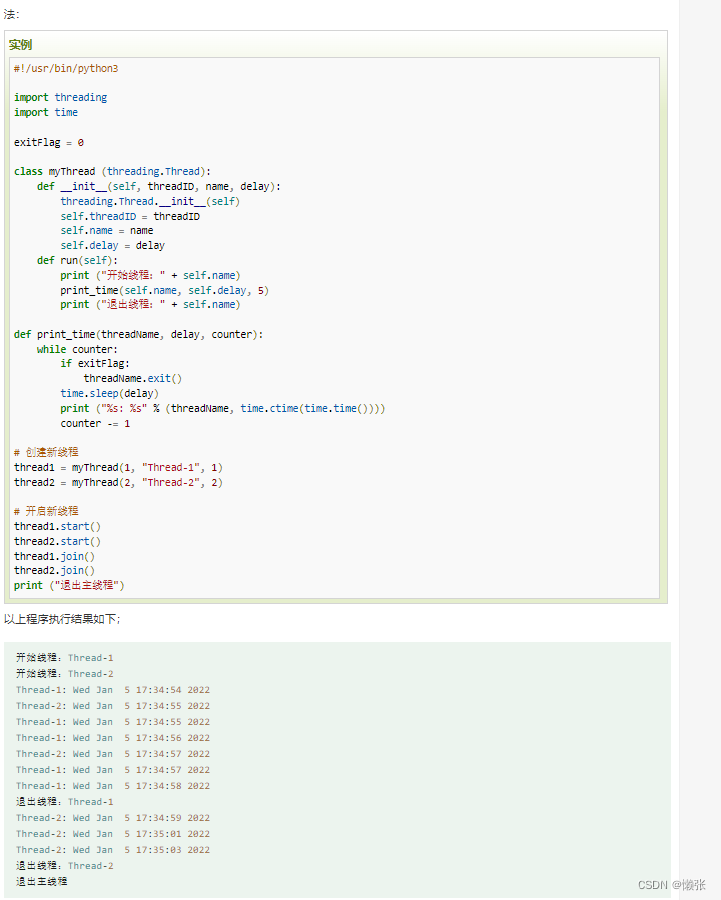
3、线程同步
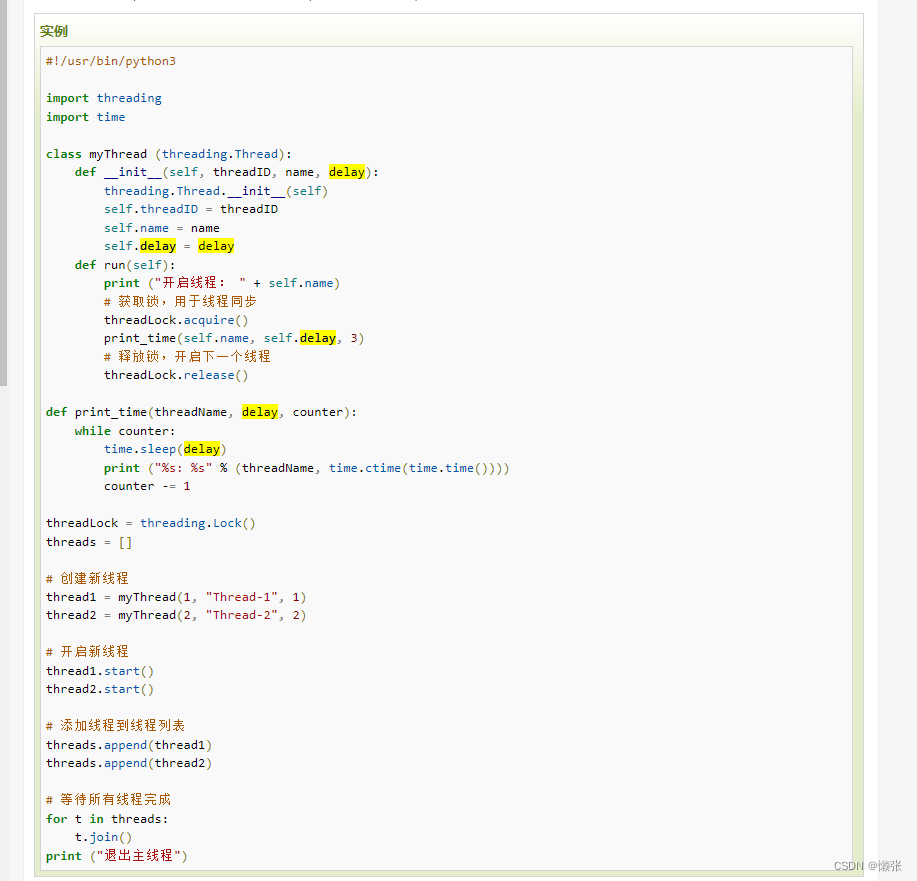
3、线程优先级队列( Queue)

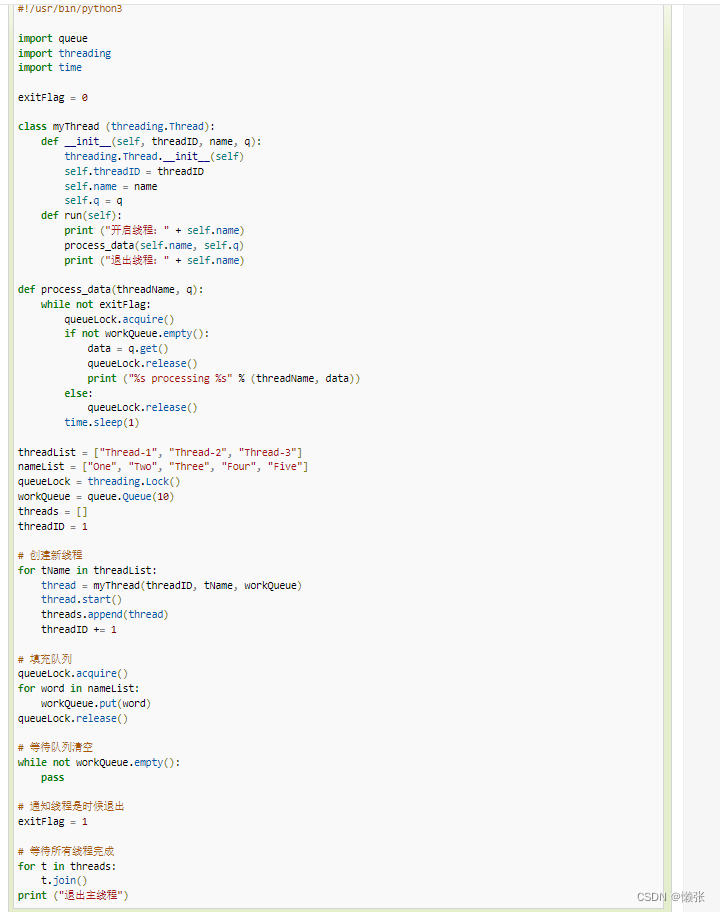
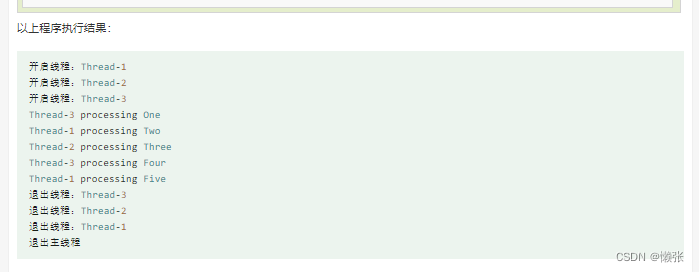
ps:如果设置为10,put超过会阻塞,get为空也会阻塞
二十六、服务端暴漏接口uWSGI 安装配置
windows安装报错
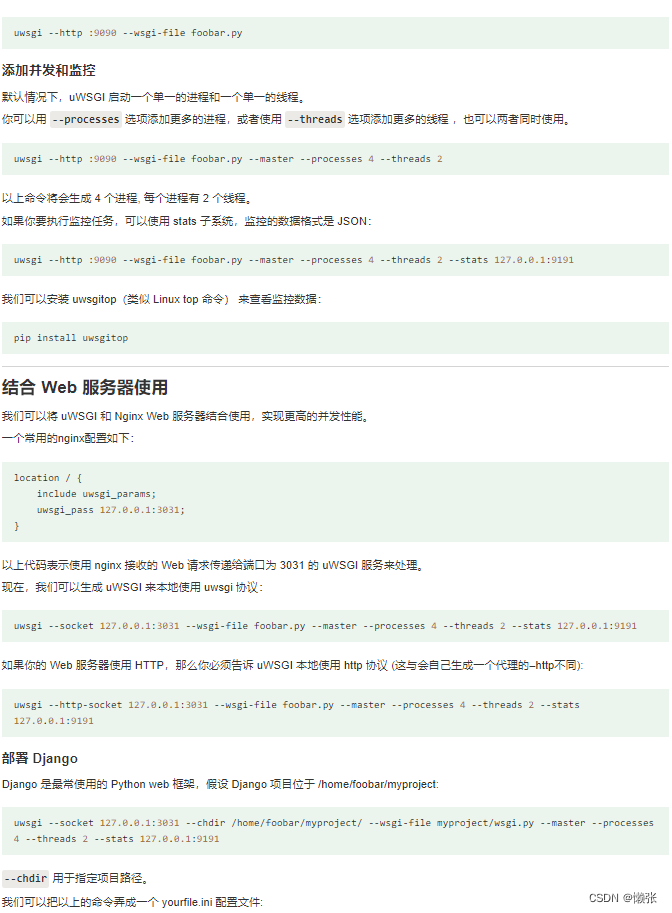
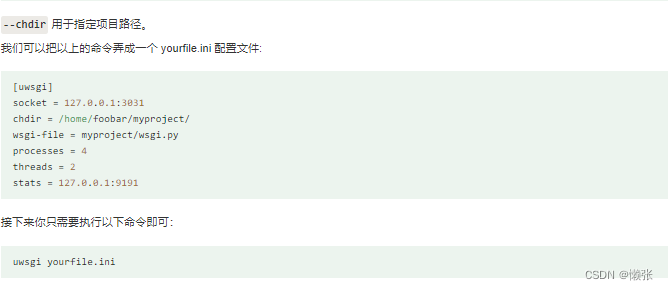
1、安装和简单使用

2、开启和关闭
2.1、菜鸟教程
2.2、配置文件
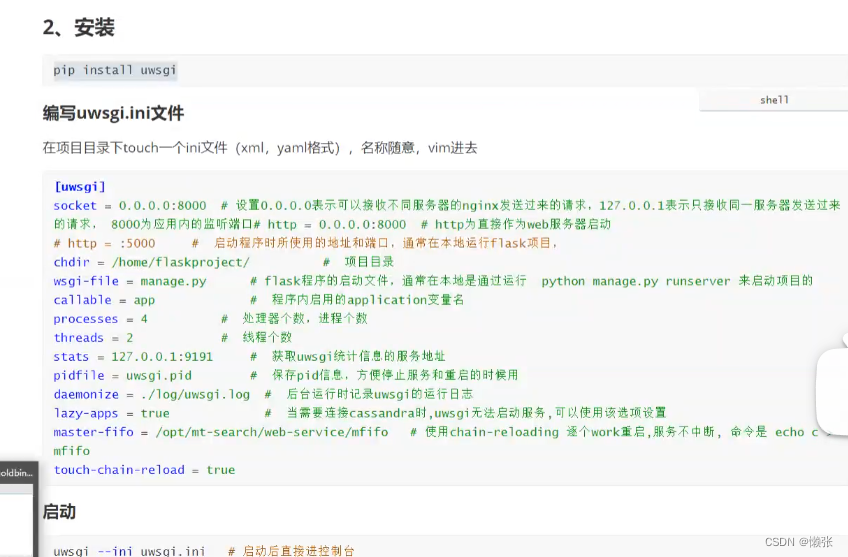
uwsgi.ini
[uwsgi]
socket=127.0.0.1:3034
chdir=/Users/calvin/work/myproject
virtualenv=/Users/calvin/.virtualenvs/myproject
module=django.core.handlers.wsgi:WSGIHandler()
env= DJANGO_SETTINGS_MODULE=myproject.settings
master=True
pidfile=/tmp/myproject-master.pid
vacuum=True
max-requests=5000
daemonize=/var/log/uwsgi/myproject.log

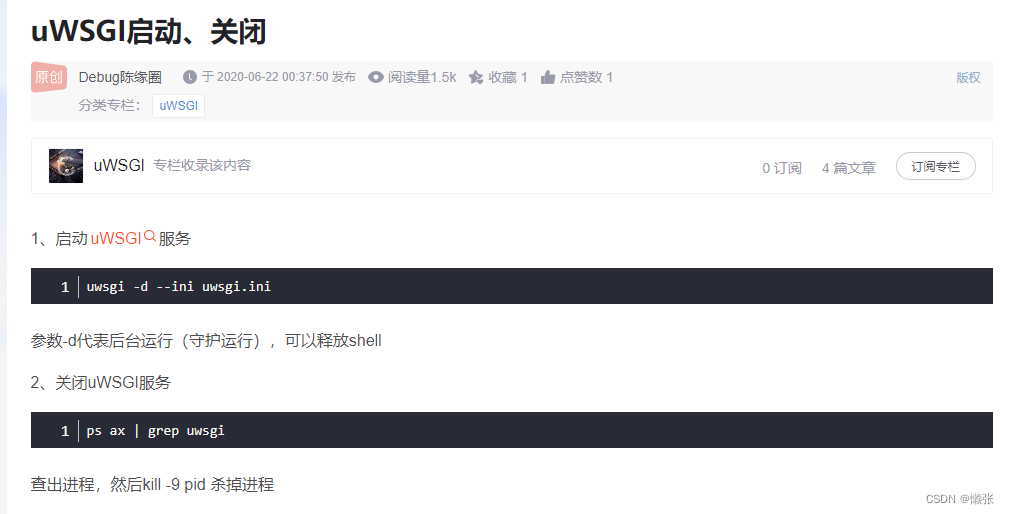
3、定义服务接口
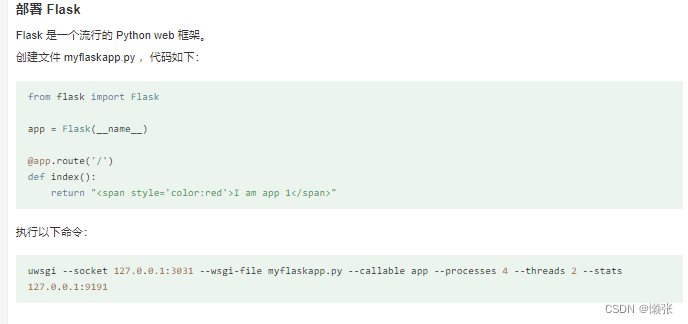
4、使用flask直接充当服务器
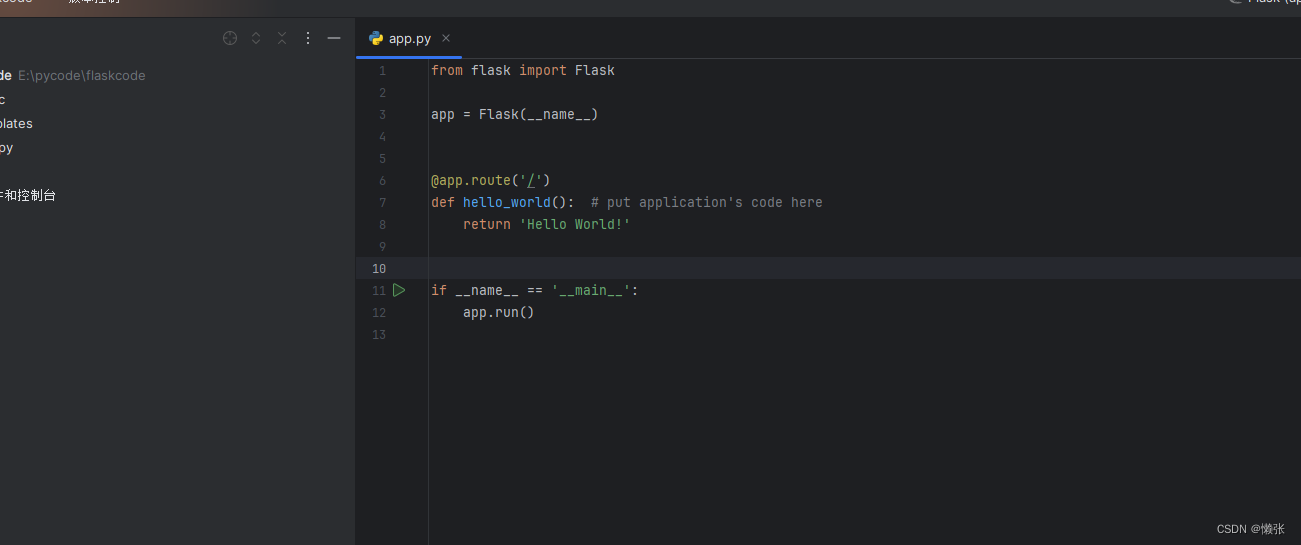
python app.py
为什么可以直接充当服务器还需要uwsgi

5、flask知识
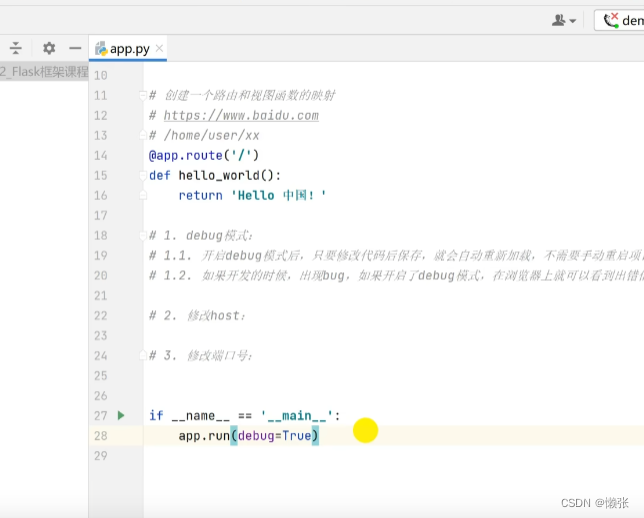
5.1 开启debug模式(修改免重启)
修改代码免重启
出现bug会出现在浏览器上
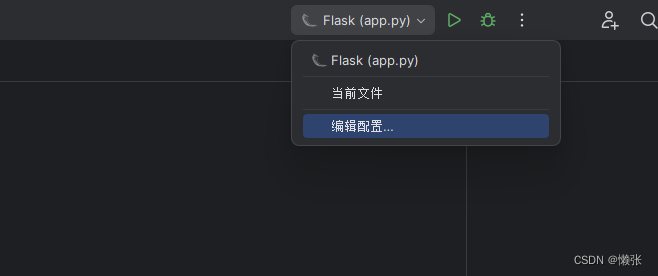
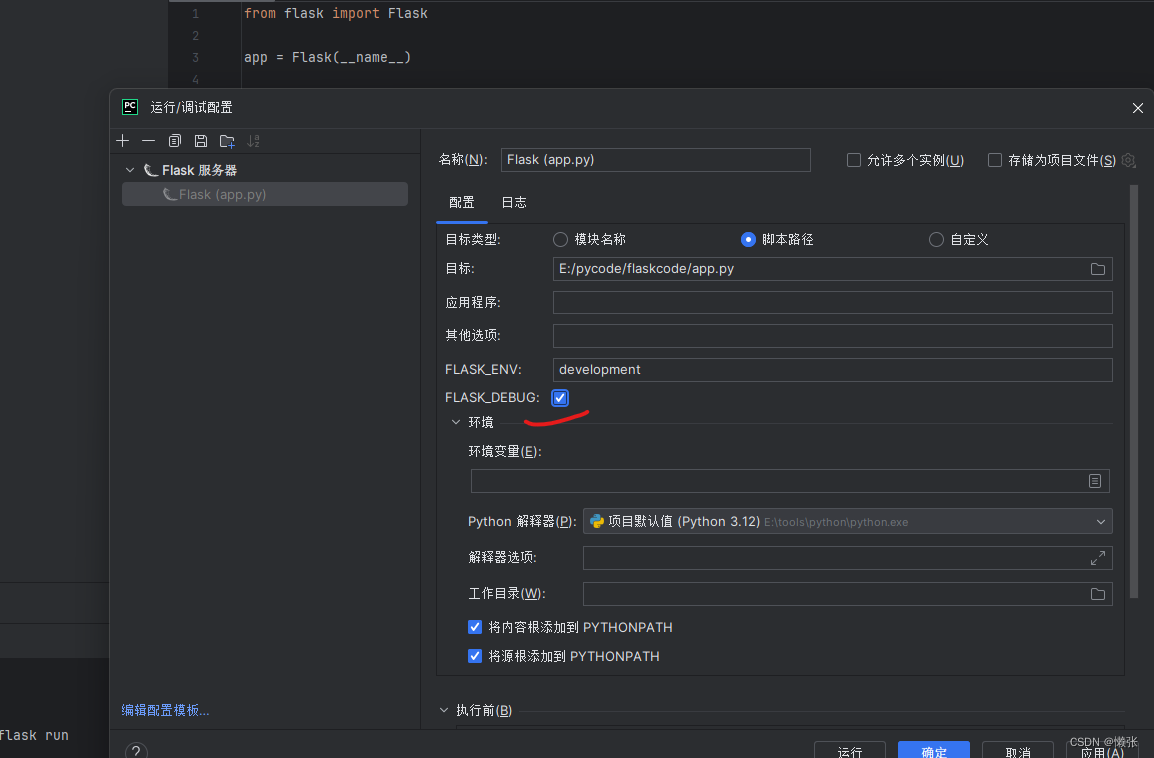
如果是社区版本就不是上述开启的 是修改代码
5.2 host局域网可以访问
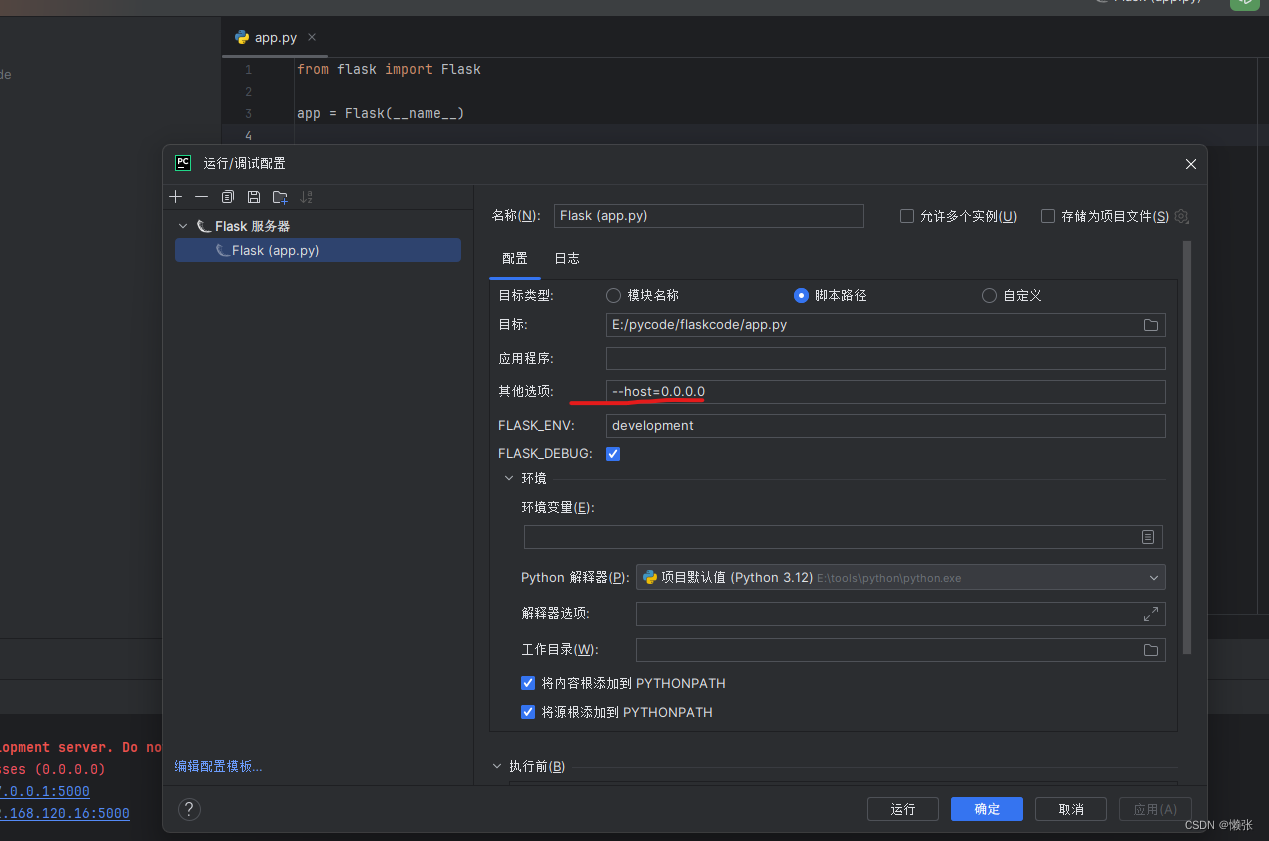
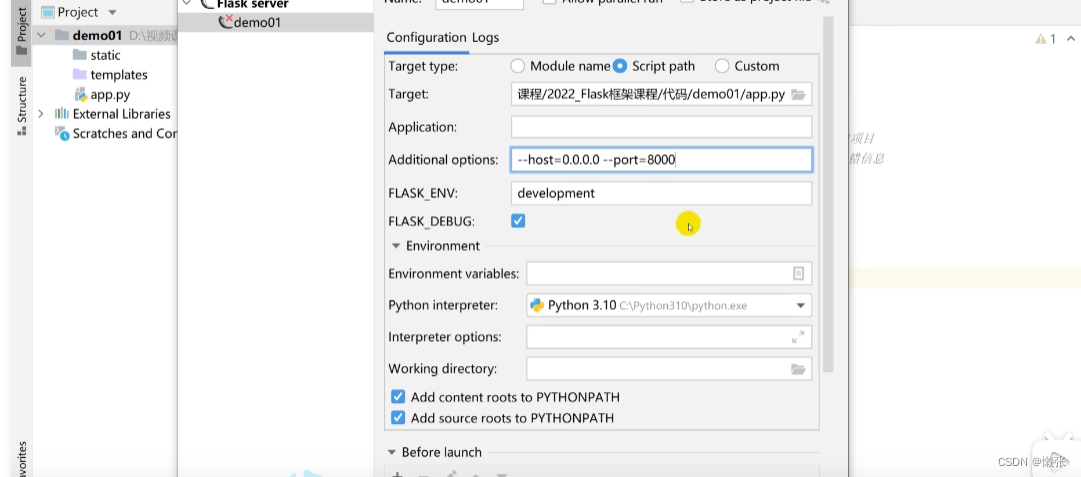
5.3 port
记得空格
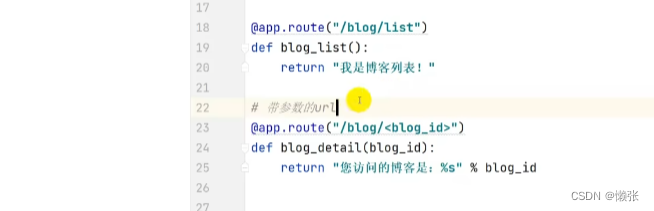
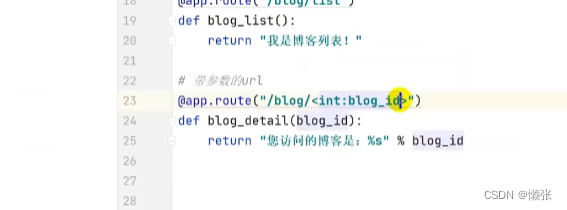
5.4 路径传参
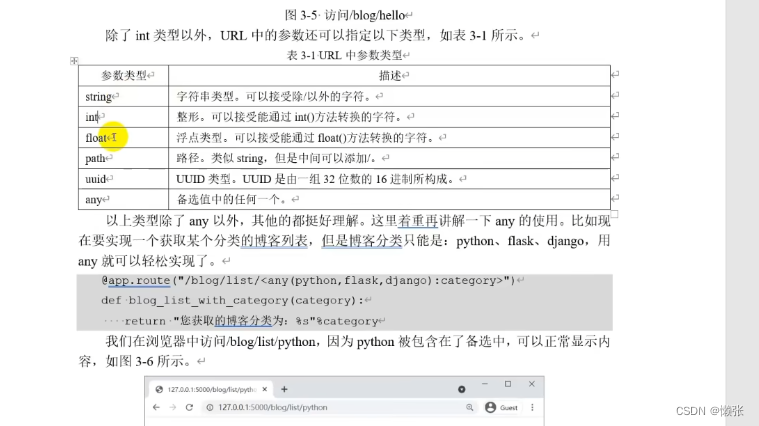
类型限制
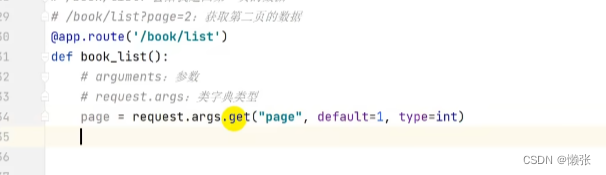
路径拼接例如?age=3,注意要引入request模块
5.5 请求方式

5.6、多个文件多个请求接口如何写
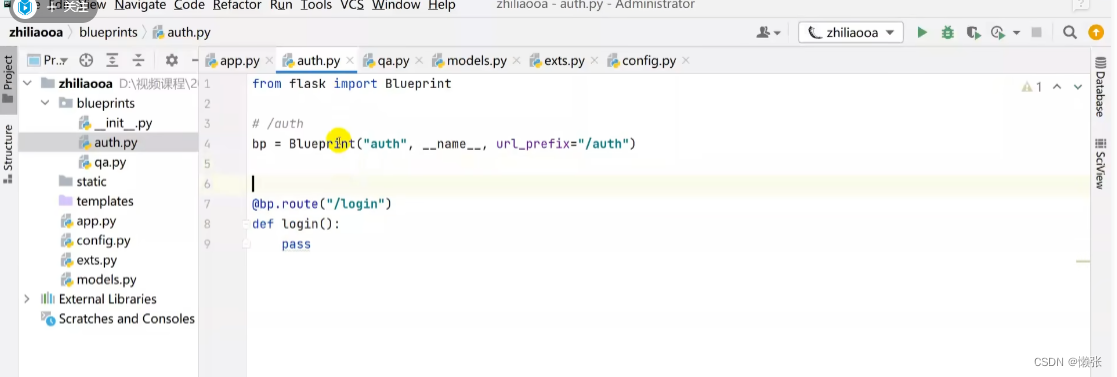
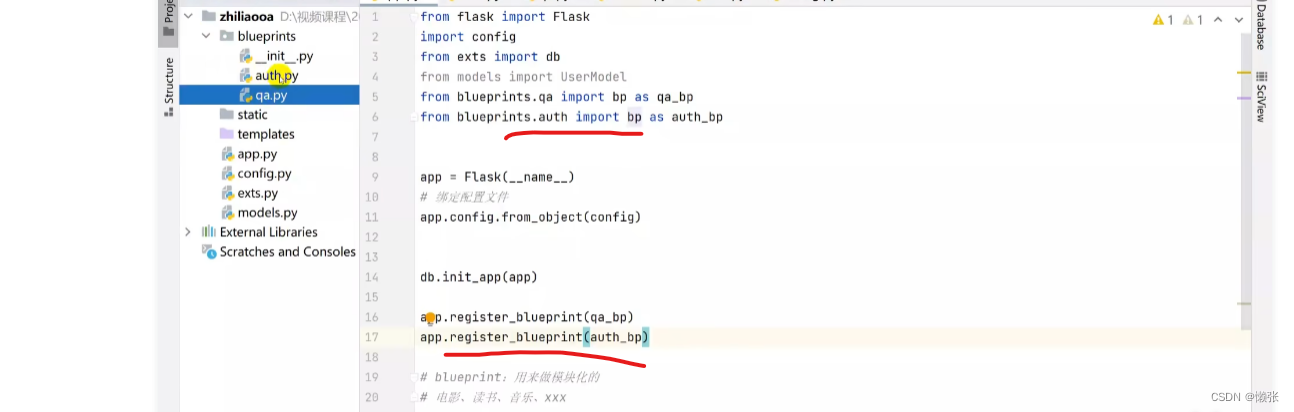
这个页面所有请求都必须带有/auth
再注册
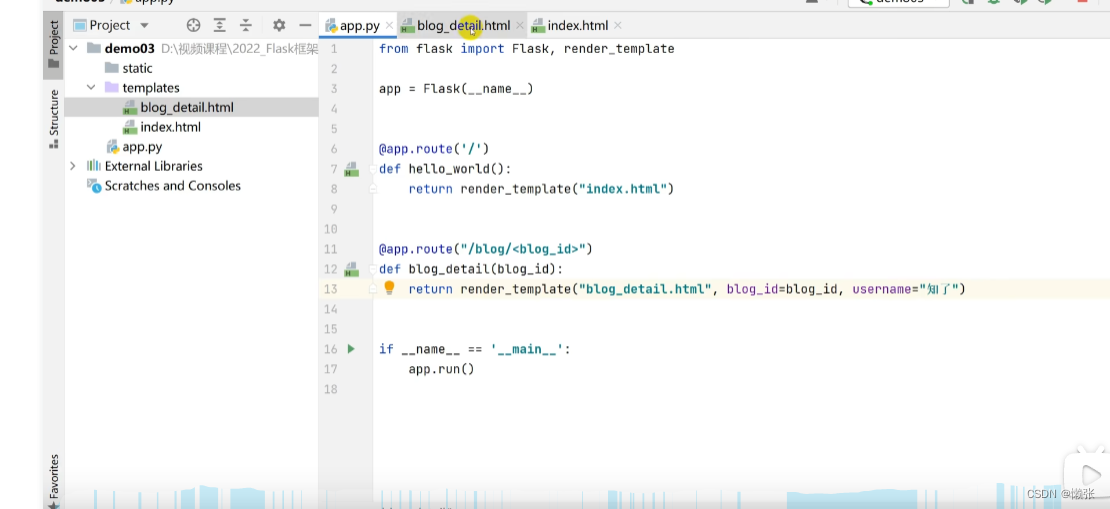
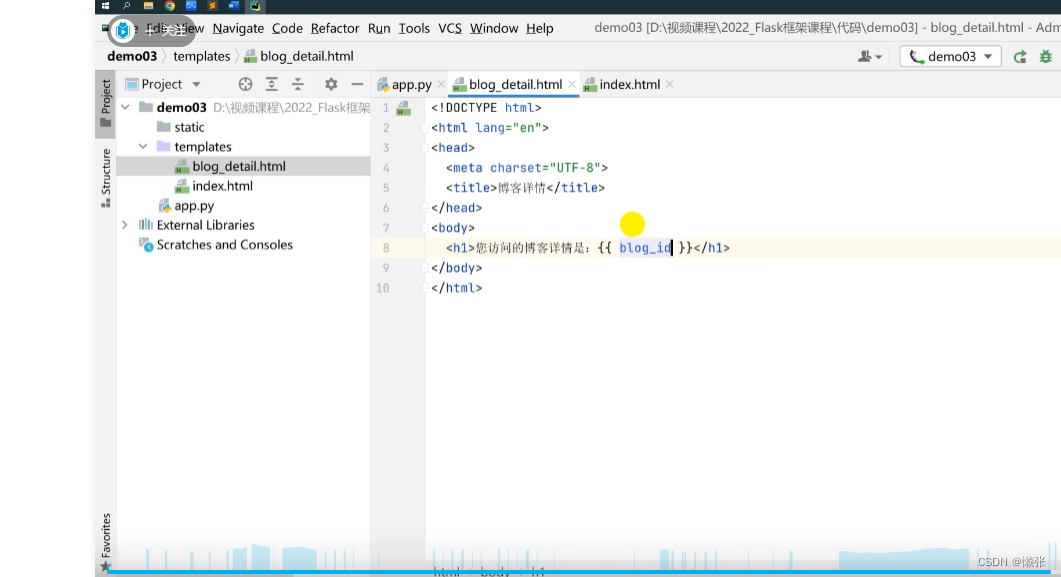
6、页面渲染jinja2,跳转到对应页面
6.1、使用
6.2、过滤器
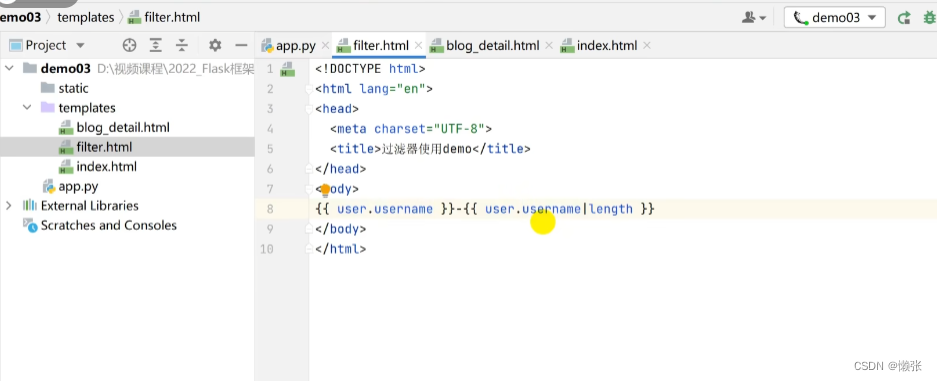
显示为:name-长度
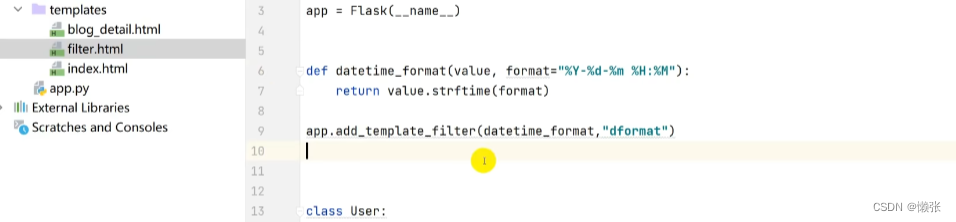
6.3、自定义过滤器

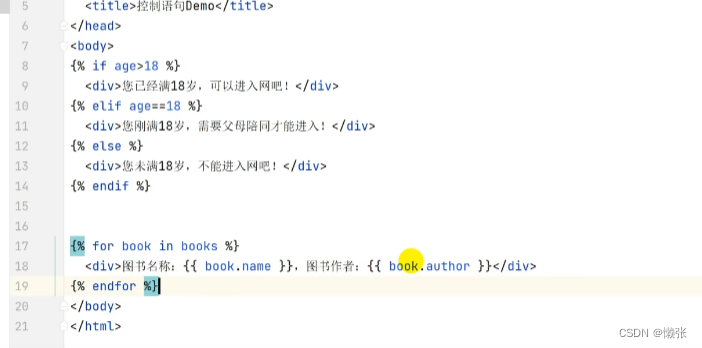
6.4、控制语句
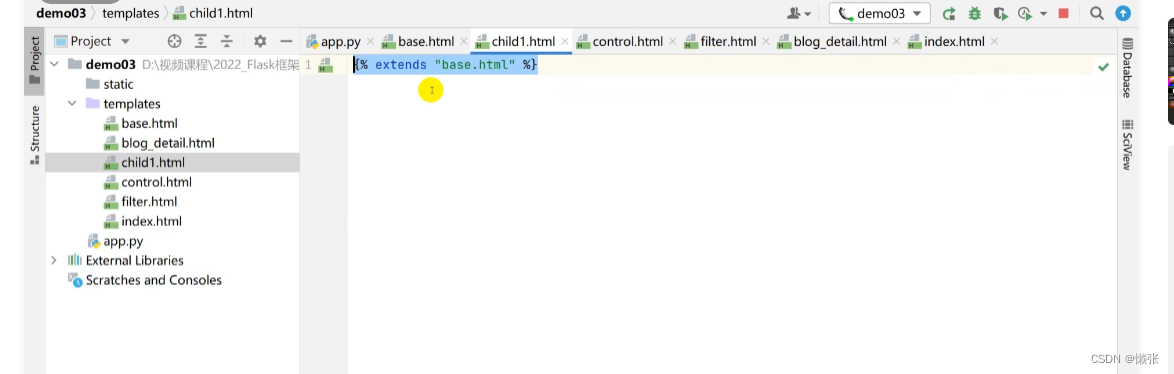
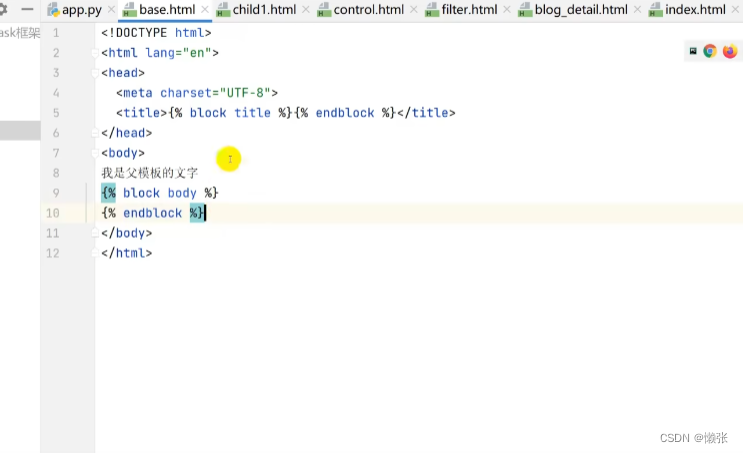
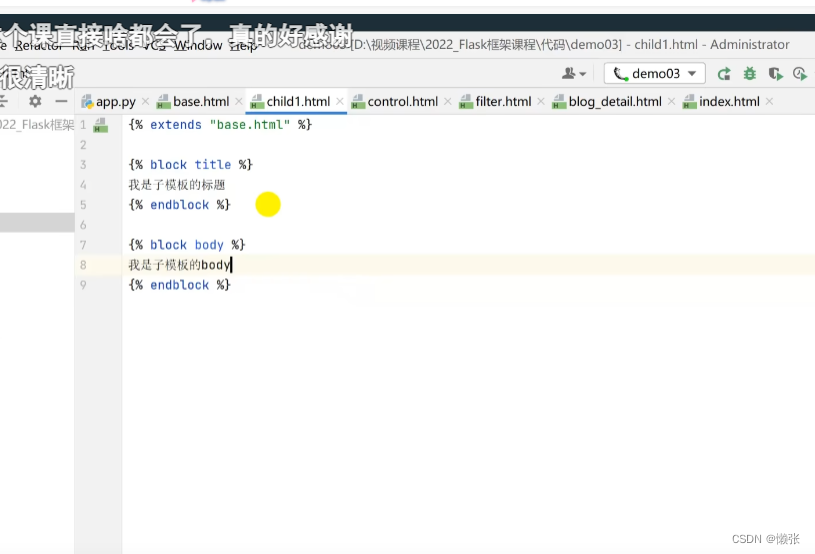
6.5 继承
替换继承中的文字内容(例如详情内容不一样)
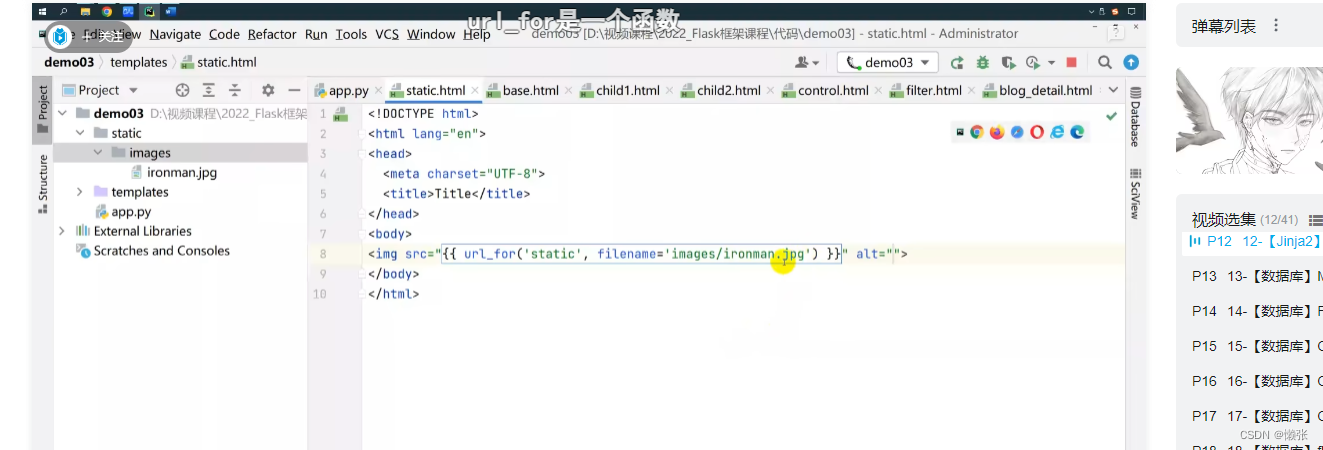
6.6、静态资源
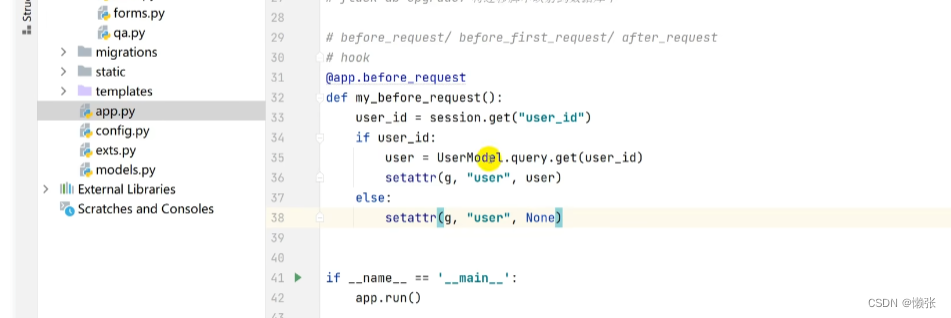
6.7 钩子函数
ps:只看注解就行
前
后

7、 flask更多入门
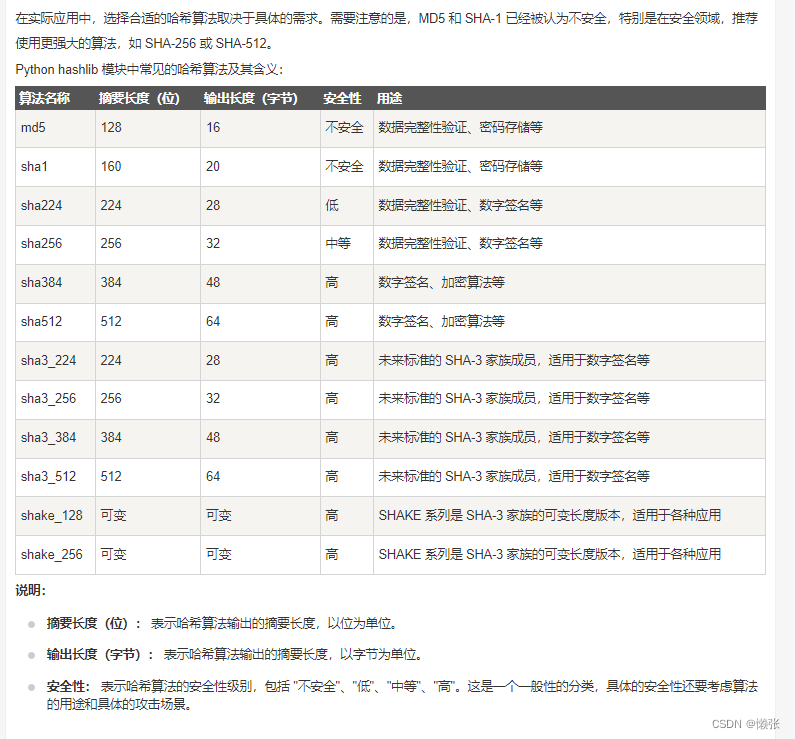
二十七、Python hashlib 模块(加密)
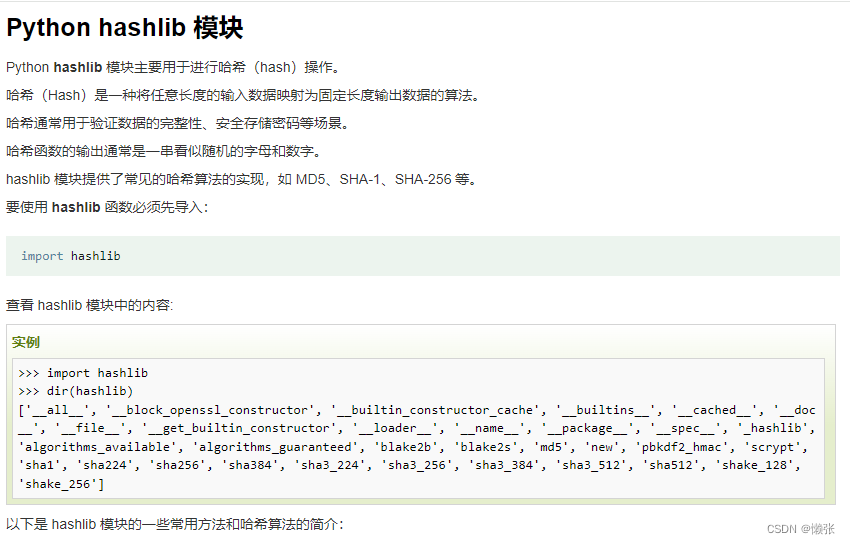
1、 常用方法
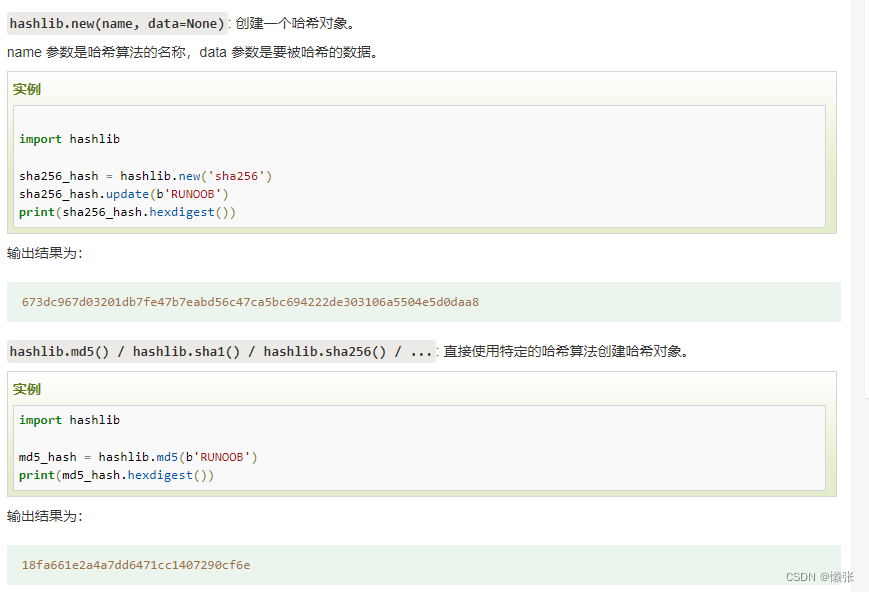
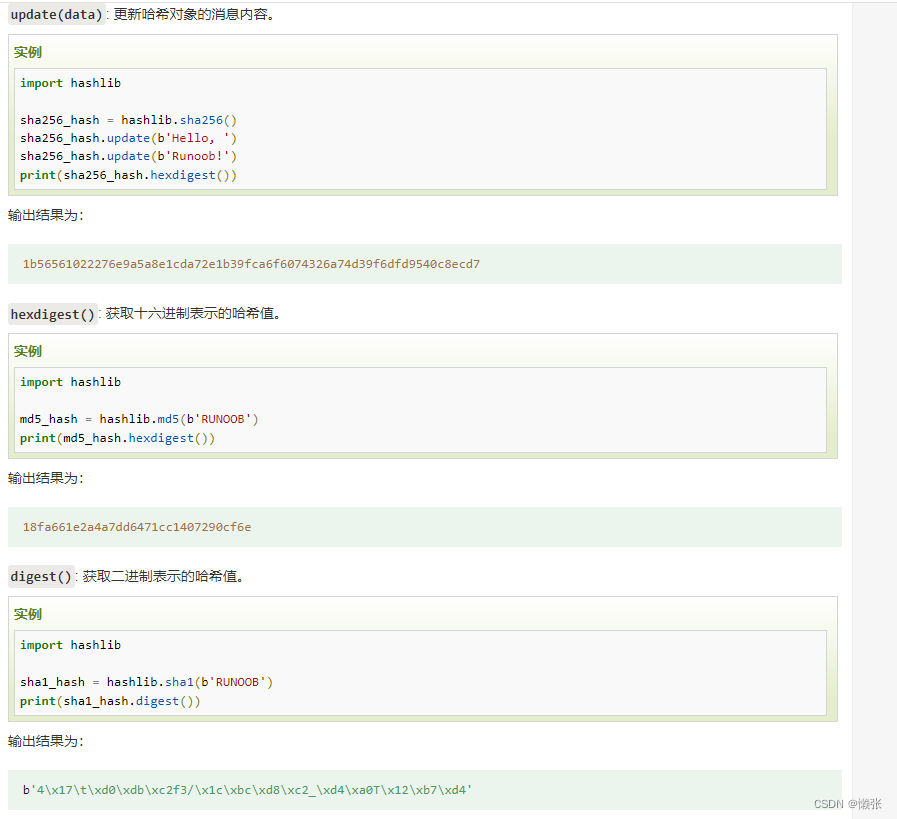
2、哈希对象方法
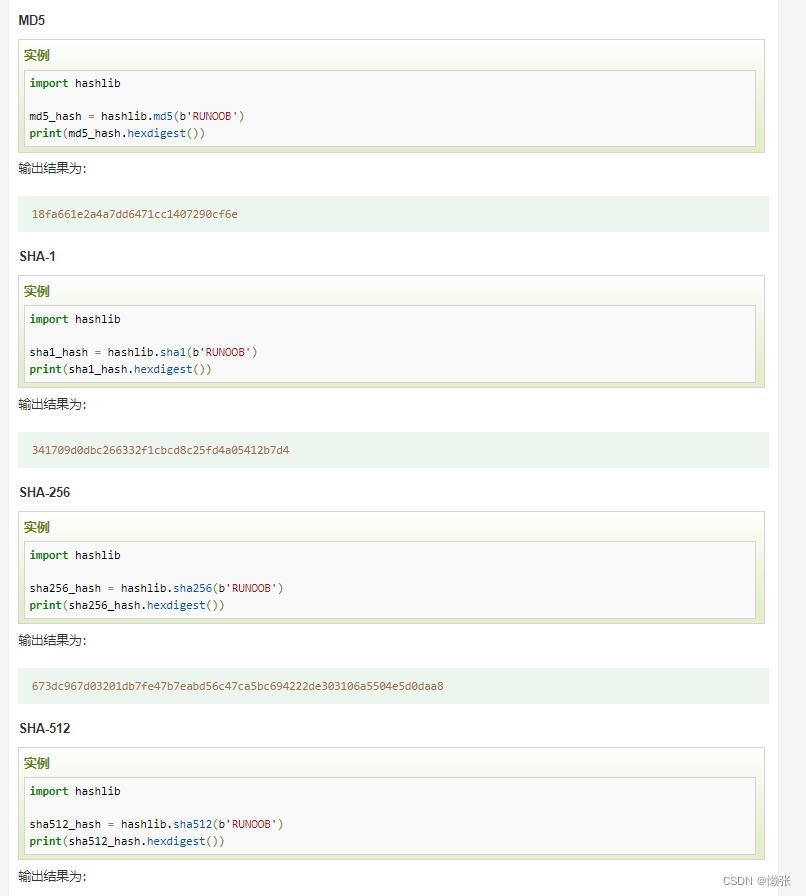
3、常见哈希算法
4、方法
二十八、饼图pyecharts 模块
1、安装
pip install pyecharts
查看版本
import pyecharts
print(pyecharts.__version__)
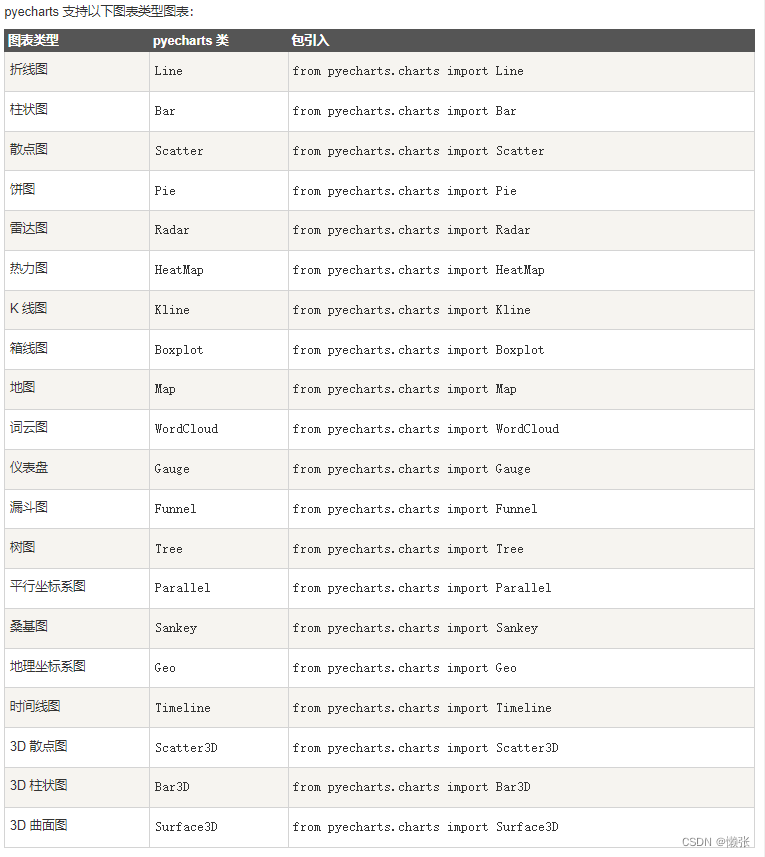
2、pyecharts 图表类型
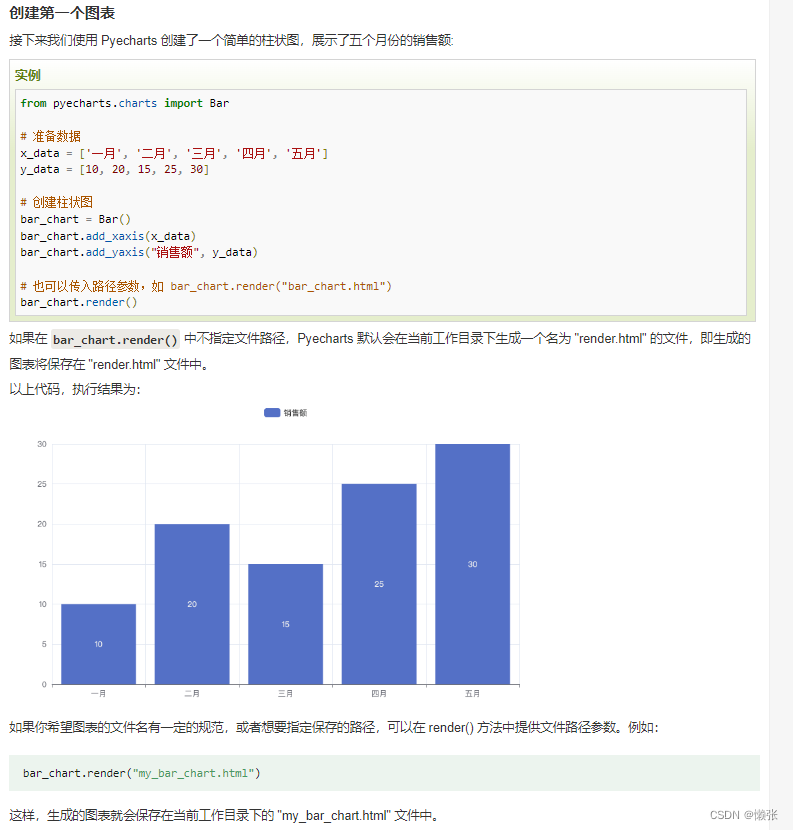
3、创建第一张图表
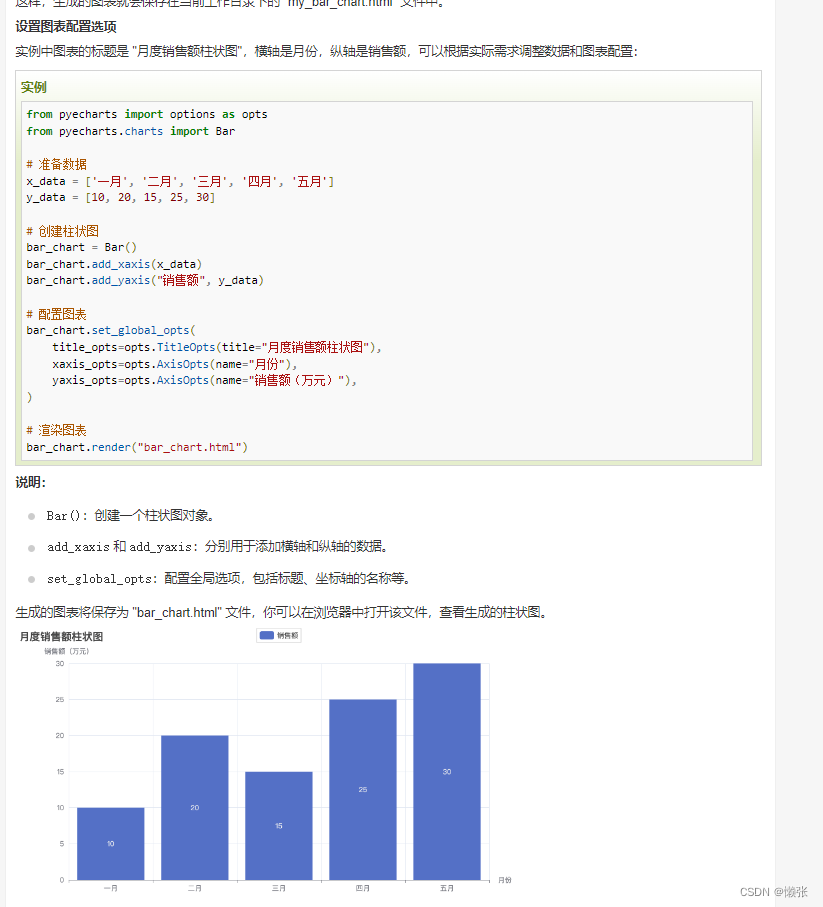
4、设置图标配置选项
5、使用主题
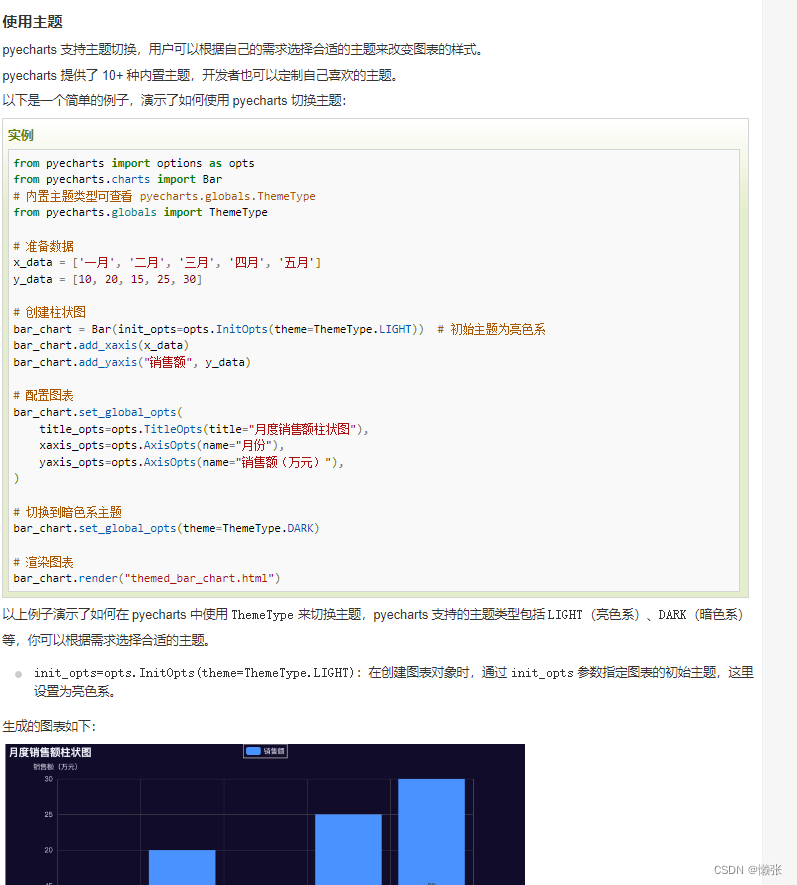

6、设置全局配置选项
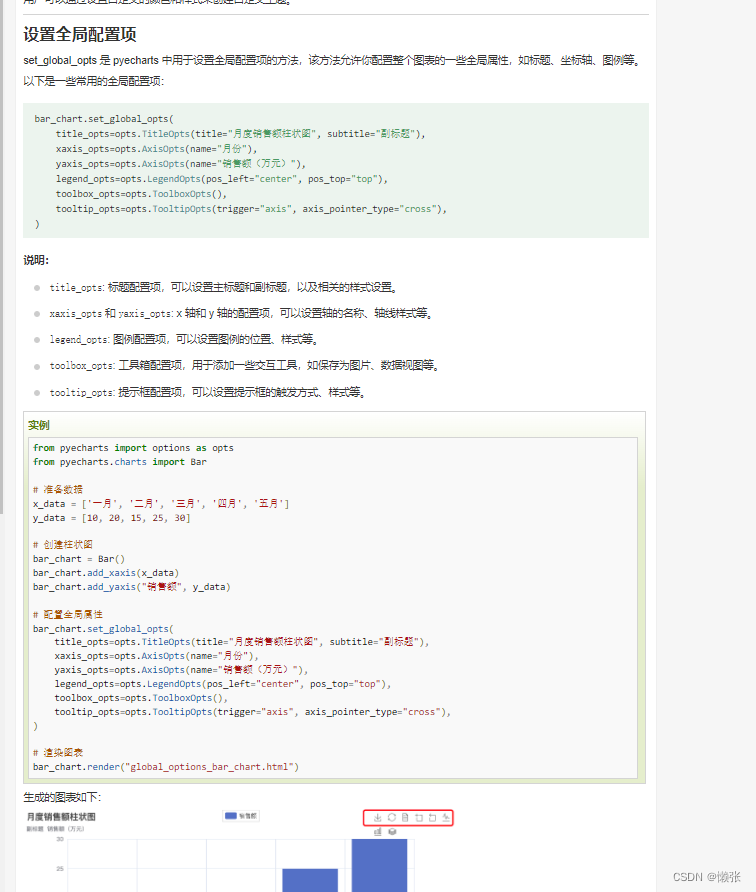
二十九、pip
三十、日期
1、时间戳
2、时间元组
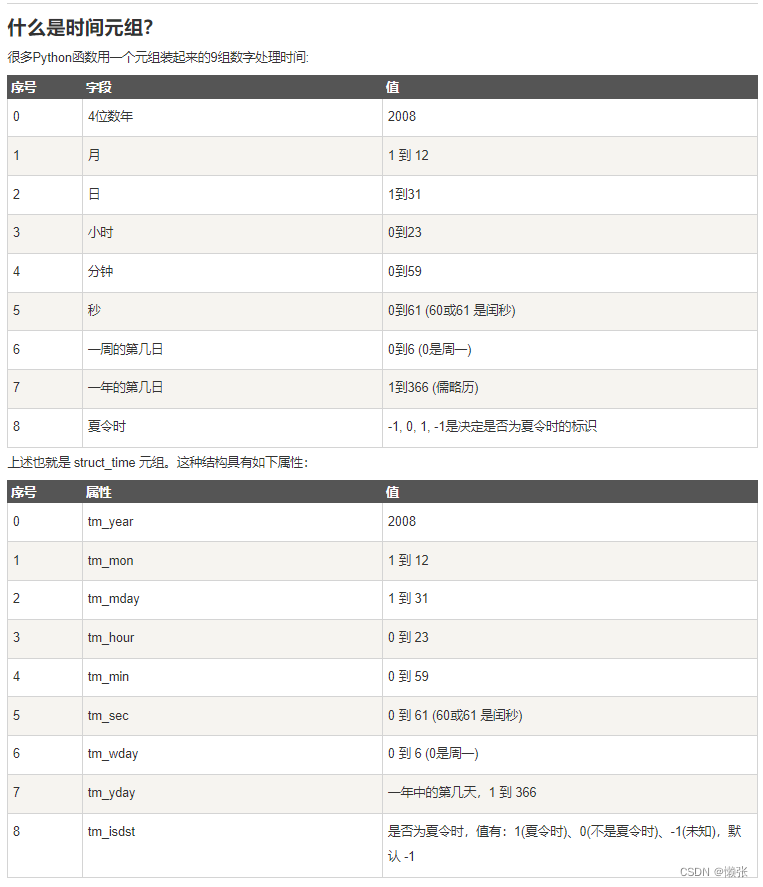
3、获取当前时间
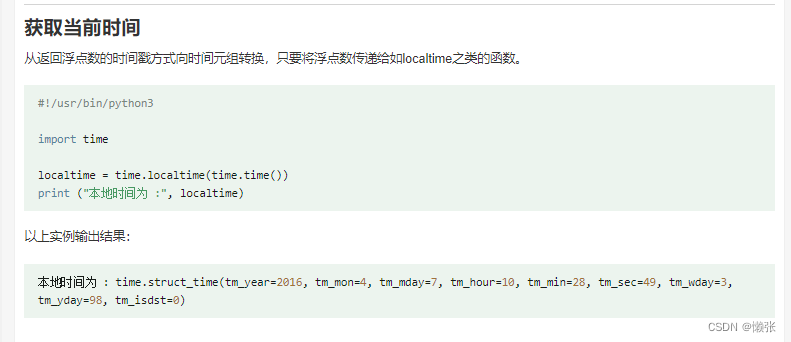
4、格式化时间
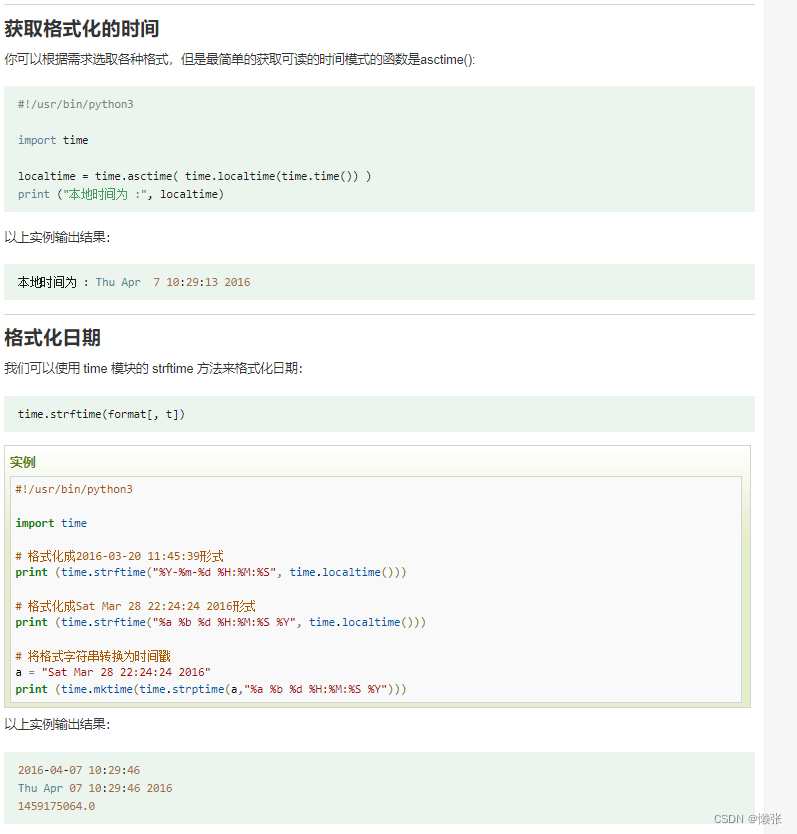

5、获取某月日历
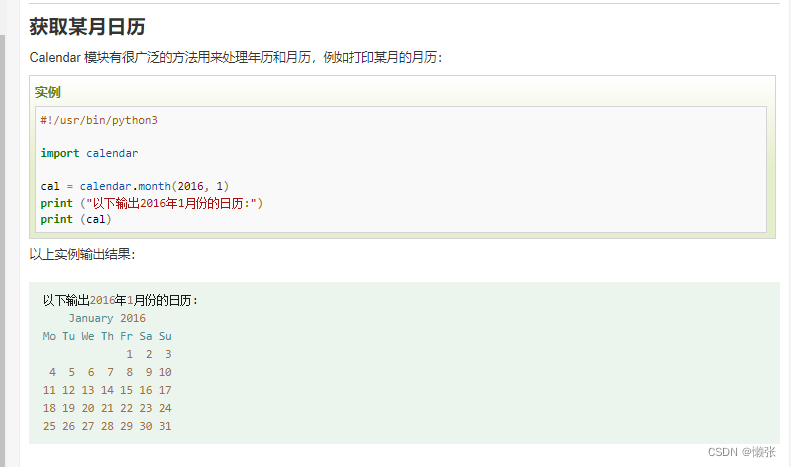
6、time函数
备忘录
1、not 相反
msg =None
print(not msg != None)
2、判断空
msg =[]
print(not msg)
3、方法参数和返回值类型注释
def test(a: 注释类型 = 1, b: 注释类型) -> 返回值类型
return a + b
def test(a: int = 1, b: str) -> int
return a + b
4、全局设置镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 局部安装使用指定镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
5、升级pip
python -m pip install --upgrade pip
6、追加环境变量

7、enumerate内置函数
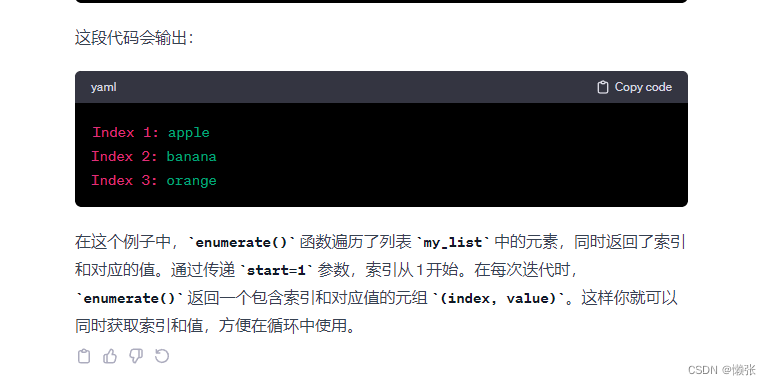
my_list = ['apple', 'banana', 'orange']
for index, value in enumerate(my_list, start=1):
print(f"Index {index}: {value}")
8、json转对象
import json
# 定义一个 Person 类来表示 JSON 中的数据结构
class Person:
def __init__(self, name, age, city):
self.name = name
self.age = age
self.city = city
# JSON 数据
json_data = '{"name": "John", "age": 30, "city": "New York"}'
# 将 JSON 转换为 Python 对象
data_dict = json.loads(json_data)
# 创建 Person 类的实例
person = Person(data_dict['name'], data_dict['age'], data_dict['city'])
# 访问实例的属性
print(person.name) # 输出: John
print(person.age) # 输出: 30
print(person.city) # 输出: New York
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据分析的基本步骤
- springboot/java/php/node/python高级婚纱定制系统【计算机毕设】
- go grpc高级用法
- day08
- Go 如何通过代码进行格式化 gomft命令
- 交叉熵在机器学习里做损失的意义
- 华为机试真题实战应用【赛题代码篇】-路灯照明(附Java、C++和python代码)
- uniapp 常用定时器实现方式
- 在 Windows 操作系统中,你可以使用以下快捷键来最小化或还原桌面上所有打开的窗口
- 关于使用Element Plus的upload组件上传文件报错问题