【InternLM】书生-浦语大模型demo搭建&服务接口部署&本地映射
目录
前言
一、InternLM大模型介绍
1-1、大模型简介
大模型:大模型是指在机器学习和人工智能领域中,具有大规模参数和复杂结构的模型。这些模型通常由数百万甚至数十亿、数千亿个参数组成,可以用来解决复杂的任务和问题,如自然语言处理、图像识别、语音识别等。
特点和应用场景
- 大规模参数:大模型通常具有庞大的参数量,这使得它们能够处理更加复杂的任务和问题。这些参数可以通过训练过程来学习和调整,以提高模型的性能和准确度。
- 复杂结构:大模型通常由多个神经网络层组成,这些层之间存在复杂的连接和计算关系。这种复杂结构可以帮助模型更好地理解和处理输入数据,从而提高模型的表现能力。
- 应用场景:大模型在各种领域都有广泛的应用。在自然语言处理领域,大模型可以用于机器翻译、文本生成、情感分析等任务。在图像识别领域,大模型可以用于物体检测、图像分类、人脸识别等任务。在语音识别领域,大模型可以用于语音转文字、语音合成等任务。
目前国内一些比较流行的大模型:

1-2、InternLM大模型简介
介绍: InternLM 是一个开源的轻量级训练框架,旨在支持模型预训练,而无需广泛的依赖关系。通过单一代码库,它支持在具有数千个 GPU 的大规模集群上进行预训练,并在单个 GPU 上进行微调,同时实现显著的性能优化。InternLM 在 1024 个 GPU 上训练期间实现了近 90% 的加速效率。下边分别介绍7B和20B的模型

1-2-1、InternLM-7B
介绍:InternLM-7B基础模型拥有70亿参数,并且有为实际场景定制的聊天模型,支持8k的上下文窗口长度。
使用开源评估工具OpenCompass对其评估结果如下:

1-2-2、InternLM-20B
介绍:在超过2.3T token的数据上进行了预训练,包括高质量英语、中文以及代码数据。chat版本还经过了SFT和RLHF训练,与7B模型相比,数据进行了更高质量的清晰,补充了更多数据,并且支持16k的上下文长度。
使用开源评估工具OpenCompass对其评估结果如下:

二、从0开始搭建InternLM-Chat-7B 智能对话 Demo
2-0、环境搭建
环境:租用autoDL,环境选torch1.11.0,ubuntu20.04,python版本为3.8,cuda版本为11.3,使用v100来进行实验。
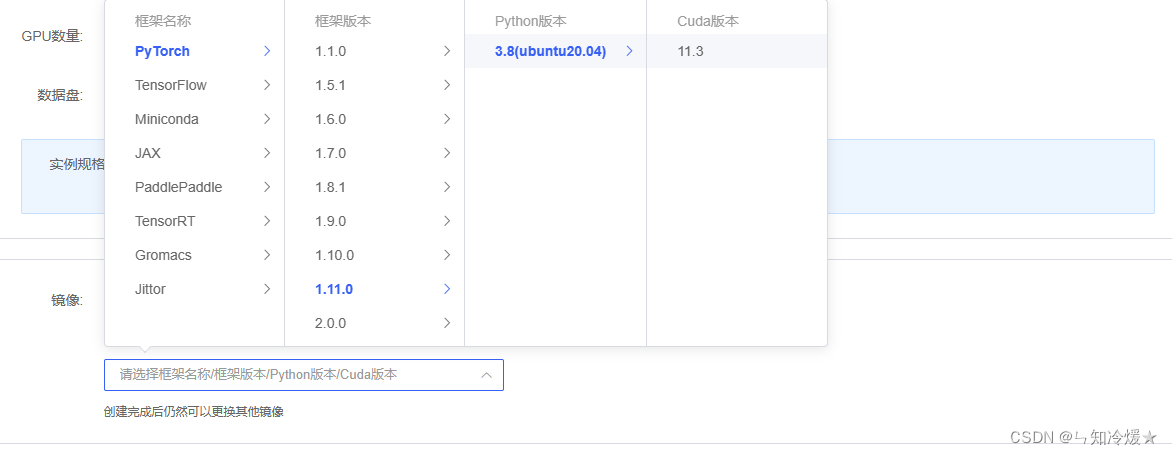

2-1、创建虚拟环境
bash # 请每次使用 jupyter lab 打开终端时务必先执行 bash 命令进入 bash 中
# 创建虚拟环境
conda create -n internlm
# 激活虚拟环境
conda activate internlm
2-2、导入所需要的包
# 升级pip
python -m pip install --upgrade pip
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
2-3、模型下载
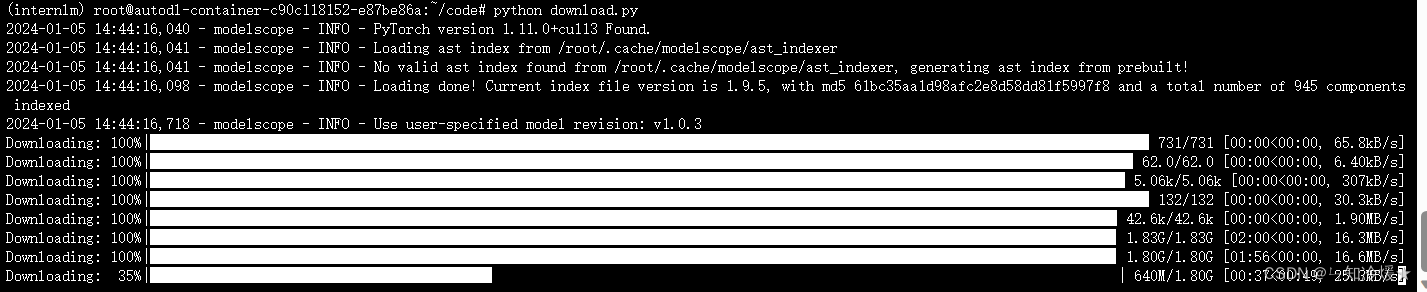
概述:使用魔搭社区下载模型,使用到了snapshot_download函数,第一个参数为模型名称,参数 cache_dir 为模型的下载路径(我这里的路径在/root/model下),将下列代码写入到一个py文件中,使用命令:python 文件名 来执行下载。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='/root/model', revision='v1.0.3')
下载图片如下:需要预留大约20G的空间。
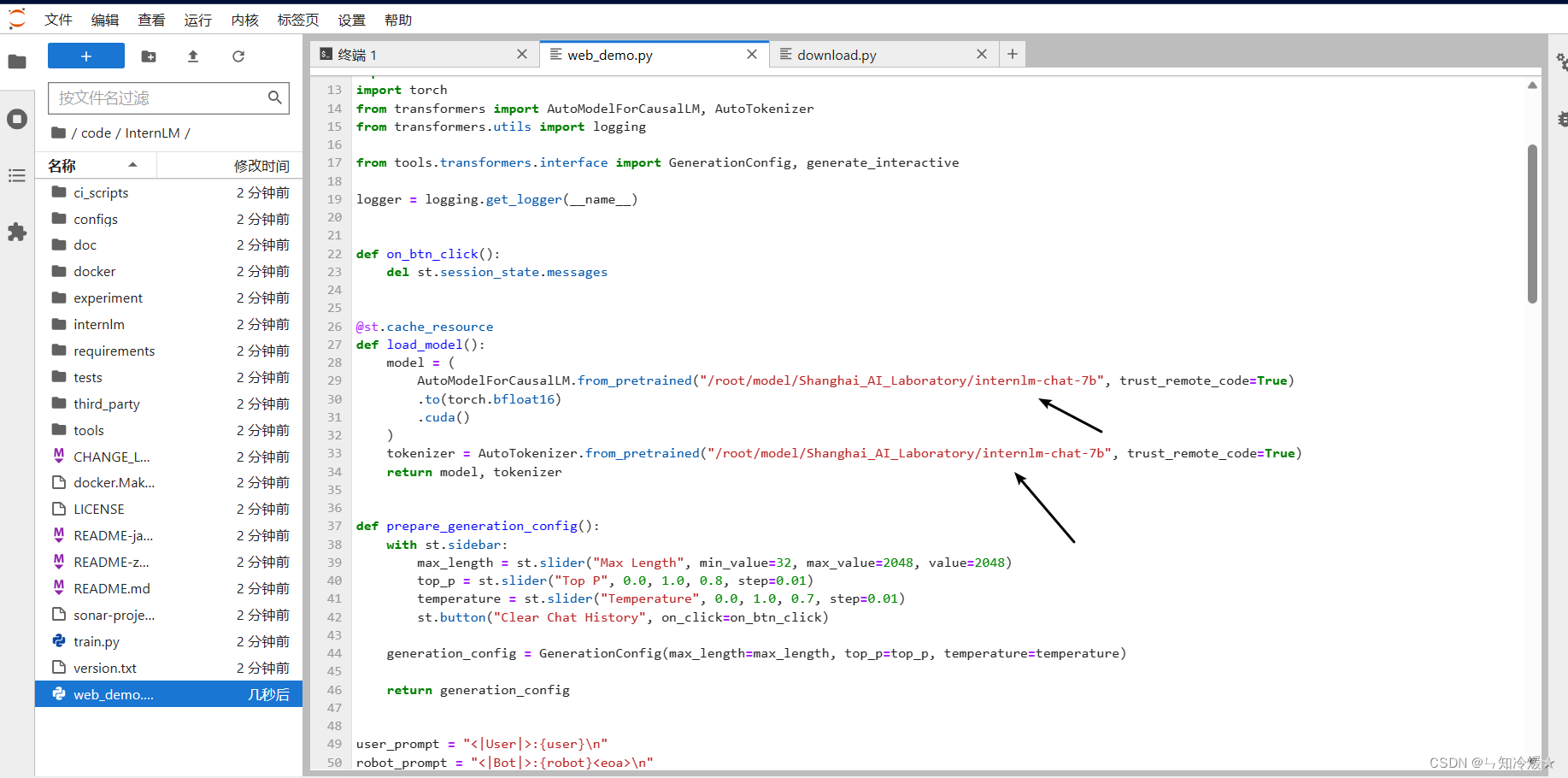
2-4、代码克隆
# 创建目录
cd root
mkdir code
# 克隆项目
cd /root/code
git clone https://gitee.com/internlm/InternLM.git
注意:克隆好项目后需要进入/root/code/InternLM/web_demo.py中,将其中的29和33行的模型替换为本地模型,我这里的路径为/root/model/Shanghai_AI_Laboratory/internlm-chat-7b
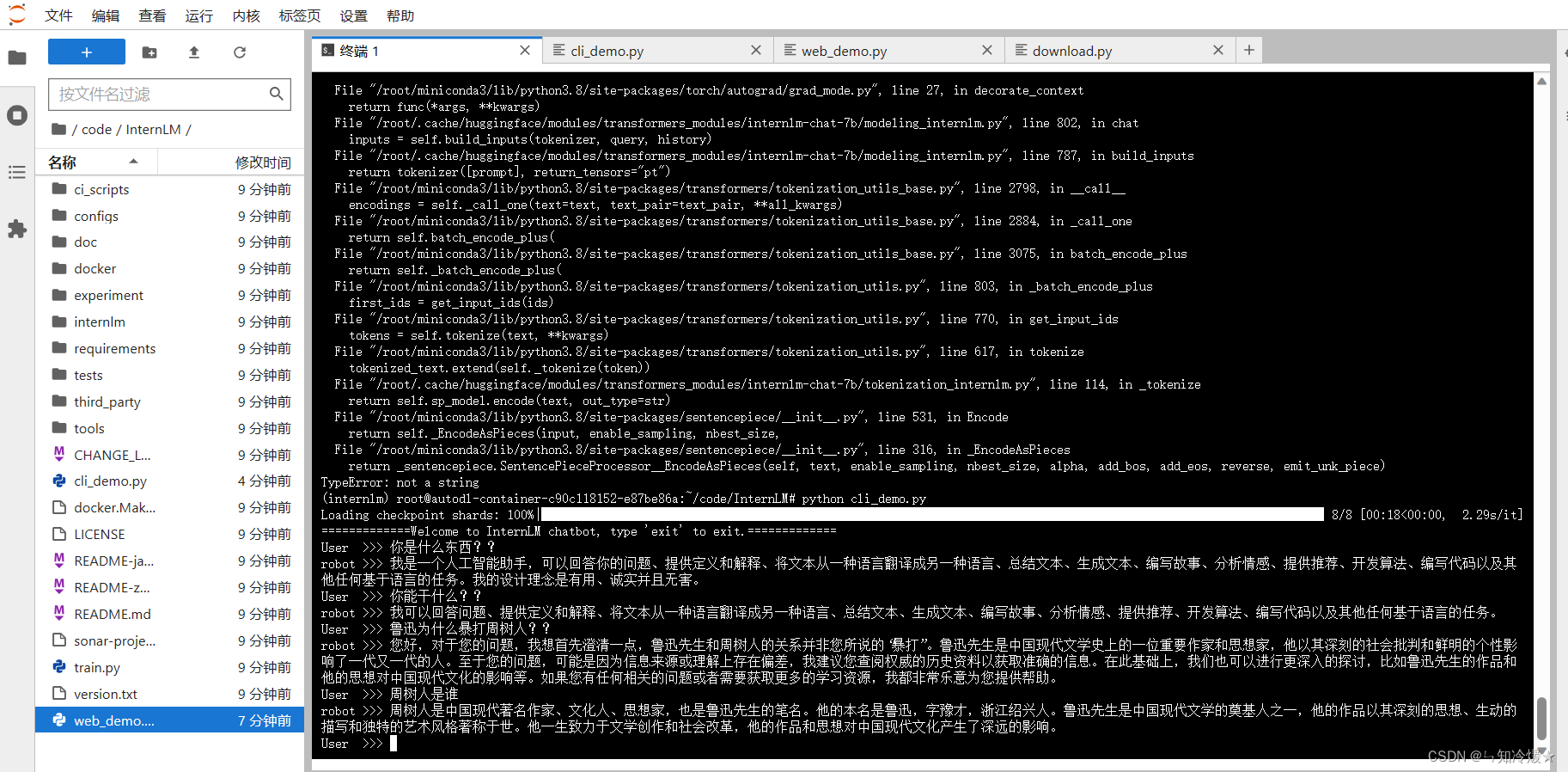
2-5、终端运行
我们可以在 /root/code/InternLM 目录下新建一个 cli_demo.py 文件,将以下代码填入其中,之后使用python命令执行脚本:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 填模型路径
model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
# 加载预训练的分词器、预训练的模型。
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
#
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
# 评估模式
model = model.eval()
messages = []
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("User >>> ")
if input_text == "exit":
break
response, history = model.chat(tokenizer, input_text, history=messages)
messages.append((input_text, response))
print(f"robot >>> {response}")
交互界面如下:
三、服务器接口部署
3-0、LMDeploy介绍:
LMDeploy 是一个用于压缩、部署、服务 LLM 的工具包,由 MMRazor 和 MMDeploy 团队开发。它具有以下核心功能:
-
高效推理引擎(TurboMind):开发持久批处理(又称连续批处理)、阻塞KV缓存、动态拆分融合、张量并行、高性能CUDA内核等关键特性,确保LLM推理的高吞吐和低延迟。
-
交互式推理模式:通过在多轮对话过程中缓存注意力的k/v,引擎会记住对话历史,从而避免历史会话的重复处理。
-
量化:LMDeploy 支持多种量化方法和量化模型的高效推理。量化的可靠性已在不同尺度的模型上得到验证。

3-1、环境安装&开启学术加速
概述:先启动环境,然后安装lmdeploy部署框架以及相关依赖包。
bash # 请每次使用 jupyter lab 打开终端时务必先执行 bash 命令进入 bash 中
# 激活虚拟环境
conda activate internlm
python3 -m pip install lmdeploy
pip install shortuuid
pip install fastapi
pip install uvicorn
在autodl上开启学术加速:帮助文档
source /etc/network_turbo
3-2、启动
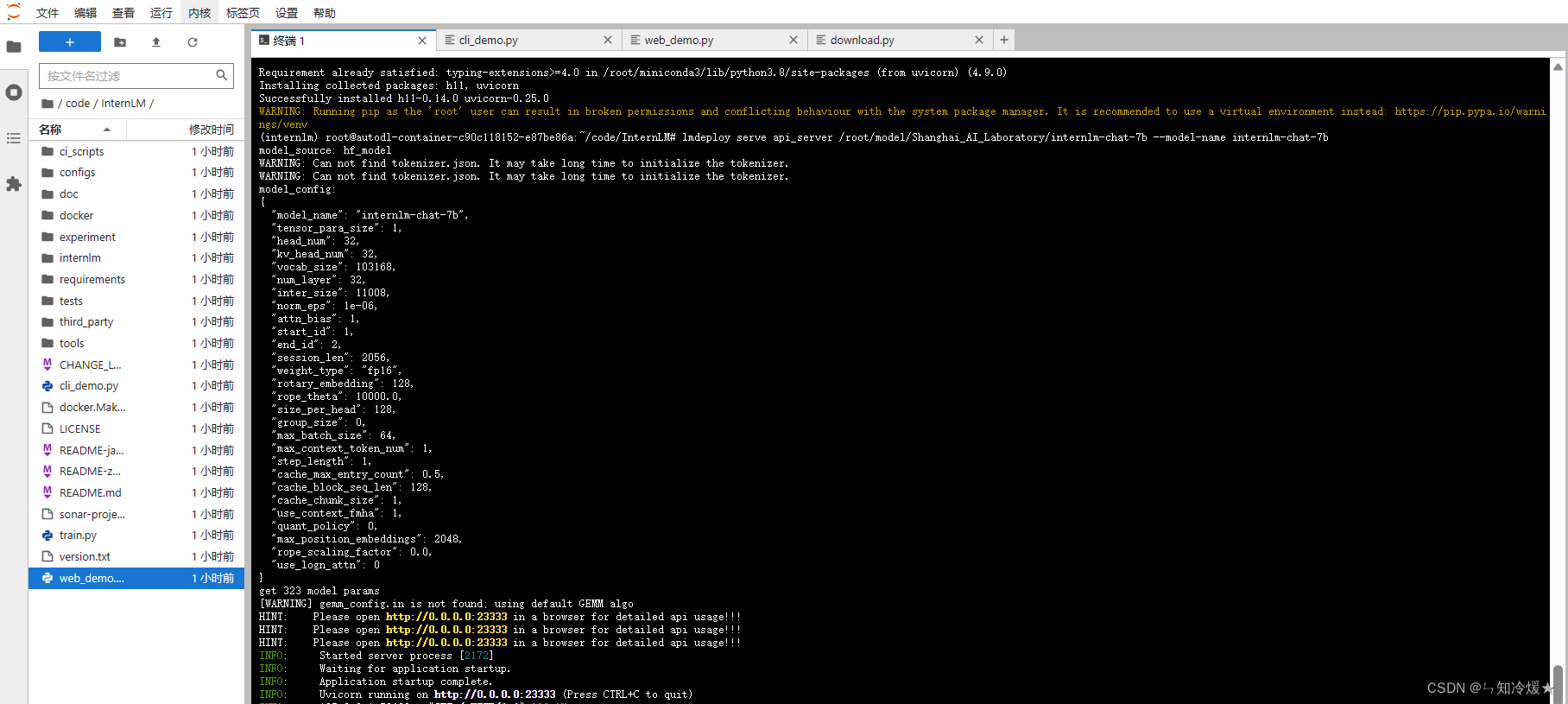
lmdeploy serve api_server /root/model/Shanghai_AI_Laboratory/internlm-chat-7b --model-name internlm-chat-7b
界面如下:
3-3、映射
第一步::点击自定义服务,下载桌面工具。如下所示:
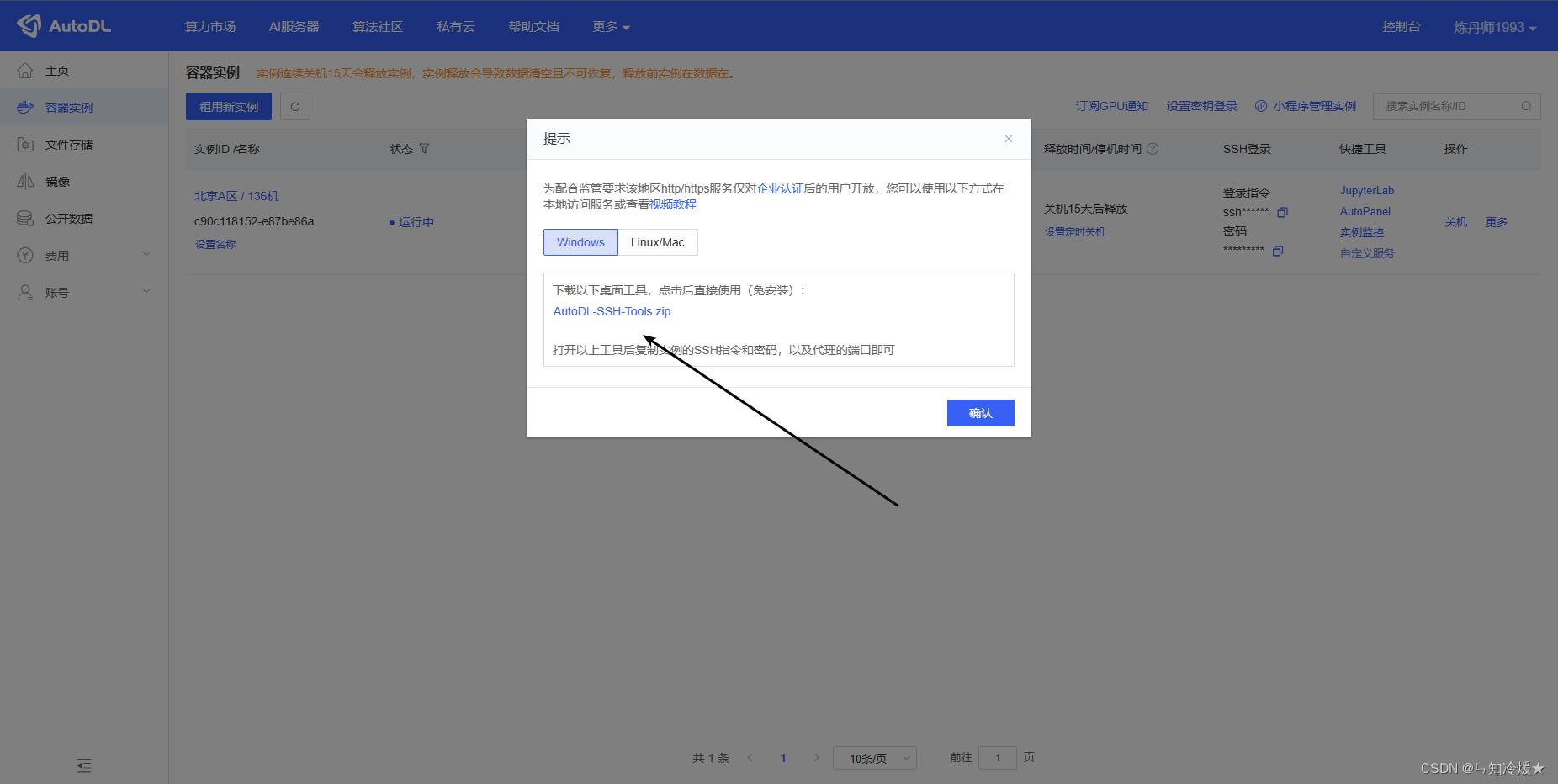
第二步:输入SSH指令、密码、以及端口号。

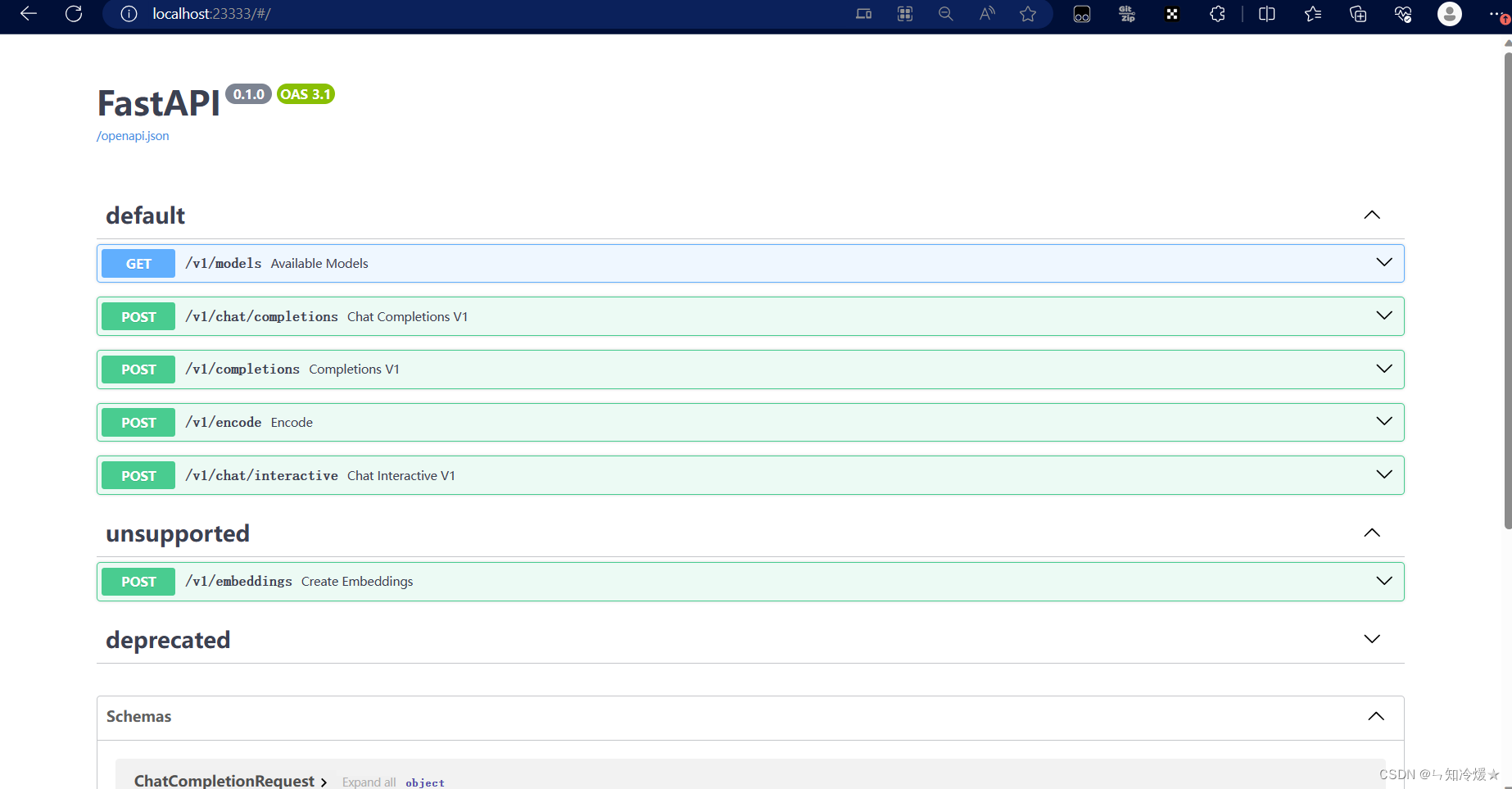
第三步:点击下方的访问地址,打开fastapi界面。
3-4、请求示例
# 写python代码请求接口
import requests
# 定义请求URL和要发送的数据
url = 'http://localhost:23333/v1/chat/interactive'
data = {
"prompt": "你好",
"session_id": -1,
"interactive_mode": False,
"stream": False,
"stop": False,
"request_output_len": 512,
"top_p": 0.8,
"top_k": 40,
"temperature": 0.8,
"repetition_penalty": 1,
"ignore_eos": False
}
# 发送POST请求
response = requests.post(url, json=data)
# 获取响应数据
result = response.json()
# 打印结果
print(result)
结果:

附录
1、配置本地端口(服务器端口映射到本地)
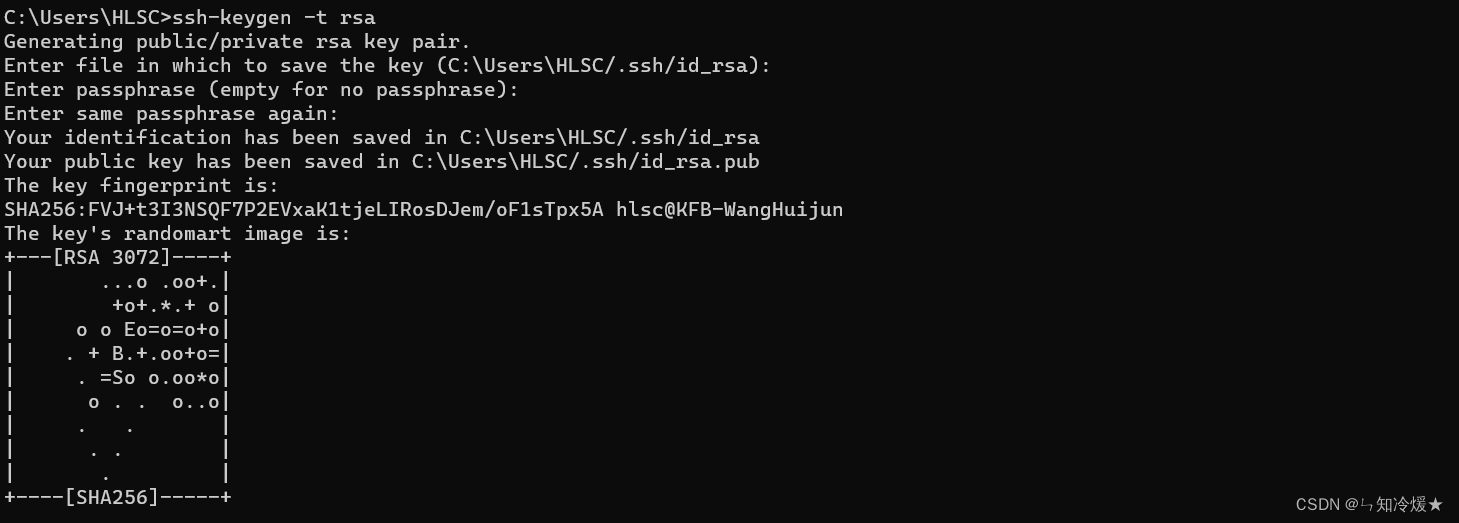
- 步骤一:本地打开命令行窗口生成公钥,全点击回车就ok(不配置密码)。
# 使用如下命令
ssh-keygen -t rsa
默认放置路径如下图所示:
-
步骤二:打开默认放置路径,复制公钥,在远程服务器上配置公钥。
-
步骤三:本地终端输入命令
# 6006是远程端口号(如下图所示,远程启动的端口号为6006),33447是远程ssh连接的编号,
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 33447
如下图所示:

本地打开如下图所示:
参考文章:
词云制作网站.
轻松玩转书生·浦语大模型趣味 Demo.
InternLM-Github.
总结
睡到自然醒的周六??ヽ(°▽°)ノ?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Win10电脑蓝牙默认音量100的设置教程
- 【论文】 虚拟机 和 Linux容器 的 最新性能比较
- 易模真人手办定制:好技术、好服务,共建消费者满意的新一代大众定制平台
- css 一行展示4个元素,不足的左对齐
- 泛型选择(简略)
- 使用git工具把项目文件上传到github 的操作
- 在奋斗中提升自我,实现梦想——中国人民大学与加拿大女王大学金融硕士项目
- IO的多路复用
- 圆通单号查询,圆通速递物流查询,将指定派件员的单号筛选出来
- Linux 【C编程】IO进阶— 阻塞IO、非阻塞IO、 多路复用IO、 异步IO