C++(14.5)——再谈拷贝构造与深浅拷贝
? ? ? ?上篇文章中,通过模拟的方式完成了类对象中常用的函数。在本篇文章中,将通过一个例子来进一步说明拷贝构造与深浅拷贝。
目录
(注:本文需要使用上一篇文章中模拟实现关于类的函数)
1.再谈深浅拷贝与拷贝构造:
例子如下:
string str("https://legacy.cplusplus.com/");
string sub1, sub2, sub3;
size_t pos1 = str.find(':');
sub1 = str.substr(0, pos1 - 0);
cout << sub1.c_str() << endl;
size_t pos2 = str.find('/', pos1 + 3);
sub2 = str.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << sub2.c_str() << endl;
sub3 = str.substr(pos2 + 1);
cout << sub3.c_str() << endl;上述代码的目的是将中存储的网址进行分隔。但是当运行代码时,编译器会显示错误:
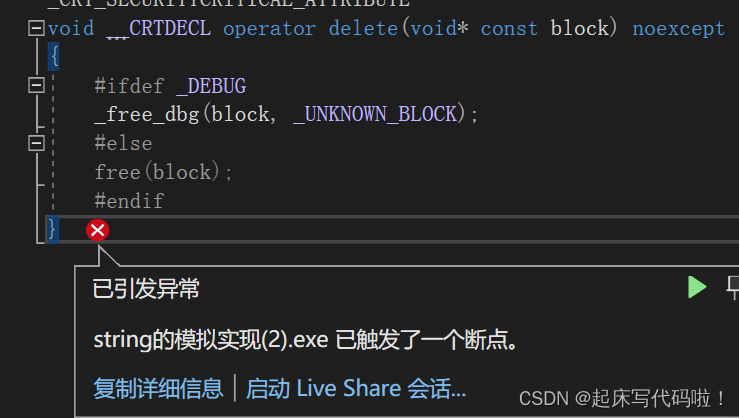
引起错误的根源在于下面给出的代码:
sub1 = str.substr(0, pos1 - 0);对于代码如下:
string substr(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
size_t end = pos + len;
if (len == npos || pos + len >= _size)
{
end = _size;
}
string str;
str.reserve(end - pos);
for (size_t i = pos; i < end; i++)
{
str += _str[i];
}
return str;
}? ? ? ?通过上述代码,不难得出其整体逻辑为:函数返回
类型的对象
,
作为右操作数用来给
赋值。由于
函数的返回值不是引用返回,所以,
函数并没有返回
本身,而是返回
的一个临时拷贝,为了方便描述,这里命名为
。并且,在模拟实现的整个过程中并没有人为编写拷贝构造函数,因此,
对于
的拷贝是一个浅拷贝。
? ? ? 对于浅拷贝也就是简单的值拷贝,者导致了,
中的指针
_
指向同一块空间,即:
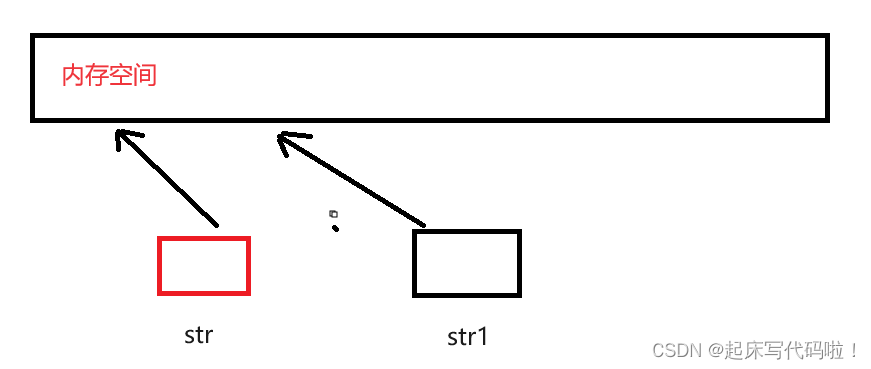
?当函数结束时,会自动调用析构函数来释放
中开辟的空间,但是,此时
依旧指向了被清理的空间,因此是一个野指针,当
作为返回值用于给
赋值时,会因为野指针问题而引起错误。
为了避免上述错误,需要将拷贝构造的方式由浅拷贝改为深拷贝,所以需要人为编写拷贝构造函数。对于深拷贝,即不但需要对某些类型的变量完成值拷贝,还需要将变量中的资源一并进行拷贝,具体代码如下:
string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_capacity = s._capacity;
_size = s._size;
}对于用给
赋值,同样也有浅拷贝的问题,因此,需要按照深拷贝的思想,来人为编写一个运算符重载,具体步骤如下:
假设传递的参数为,则先开辟一块新的空间
,内部内容与参数均和
相同,然后通过
来释放
,最后,让
赋值给
,具体操作如下:
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[]_str;
_str = tmp;
_capacity = s._capacity;
_size = s._size;
}
return *this;
}再有了上述两个函数后,对于文章一开始给出的代码就可以正常运行,运行结果如下: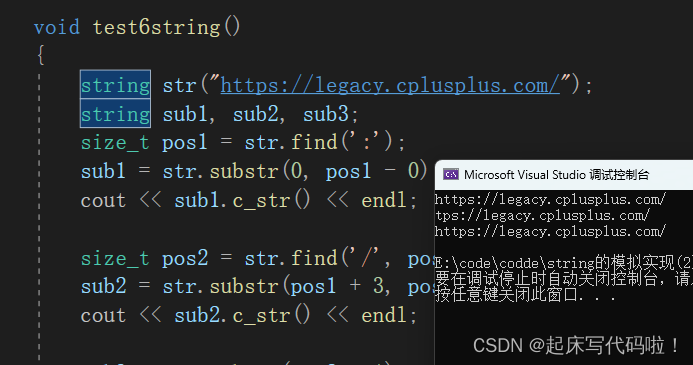
2. 流插入与流提取:?
2.1 流插入:
在上一篇文章中,针对输出类型的对象时,是通过一个函数来返回对象中存储字符串的指针_
,在外部通过
函数对返回的指针进行打印,即:
const char* c_str() const
{
return _str;
}上述方式并没有直接通过运算符重载让直接对对象进行打印,对于运算符重载的代码如下:
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}对于流插入的运算符重载,原理较为简单,因此不做解释。
通过下面的代码对于流插入的功能进行测试:
?
void test5string()
{
string s1("hello world");
cout << s1 << endl;测试结果如下:
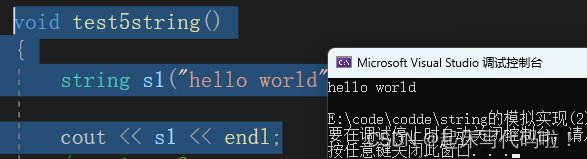
2.2 流提取:
对于流提取的运算符重载,其代码实现方式如下:
istream& operator>>(istream& in, string& s)
{
char ch;
in >> ch;
while (ch != ' ' && ch != '\n')
{
s += ch;
in >> ch;
}
return in;
}通过下面的代码对流提取功能进行测试:
运行代码,此时发现,流插入的过程并不会自动结束,而是无限循环下去: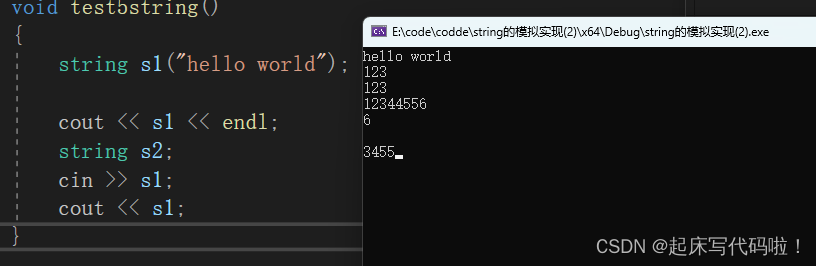
并且,即使是人为手动输入换行符或者空格,流提取的过程也不会结束。造成上述错误的原因,是因为在函数传参时,两个参数分别是操作符,为了区分,在函数中通过引用更名为
。对于
或者
并不能识别或者说获取空格或者换行。例如对于下面的代码:
char ch1, ch2;
cin >> ch1 >> ch2;
cout << ch1 << ch2;(注:这里的并不是运算符重载的流提取,而是库中的?
)
运行代码,向两个字符变量中依次插入下面的字符:
输出结果如下:
为了解决此问题,可以使用语言中的
或者
中的
来解决。具体操作如下:
istream& operator>>(istream& in, string& s)
{
char ch;
ch = in.get();
while ( ch !=' '&& ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}利用下面的代码来测试流提取的功能:
void test7string()
{
string s1;
cin >> s1;
cout << s1;
}输入内容如下:
?输出如下:
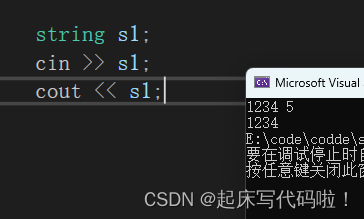
在上面给出的流提取运算符重载中,如果提取到的字符为空或者是换行符,则循环终止。从结果可以看出,当输入空格
,这一串字符时,结果只输出了
,说明通过使用
的方式成功的拿到了空格。
如果,针对一个类型的变量连续使用两次流提取,即:
void test7string()
{
string s1;
cin >> s1;
cout << "第一次流提取:";
cout << s1<<endl;
cin >> s1;
cout << endl;
cout << "第二次流提取:";
cout << s1;
}运行效果如下: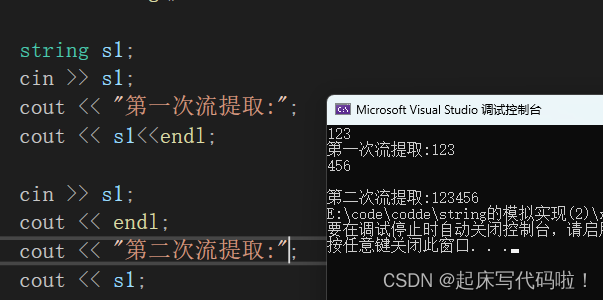
不难发现,针对一个类型的对象进行两次输入时,第二次的仍然保留了第一次的输入。并不符合
的功能,为了解决上述问题,需要额外再引进一个函数,在进行流提取之前,清理对象中的内容,即:
void clear()
{
_size = 0;
_str[0] = '\0';
}在给定了清理函数后,对流提取的运算符重载再进行改进,即:
?
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch;
ch = in.get();
while ( ch !=' '&& ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}再次运行代码,此时针对一个对象进行两次输入的结果为: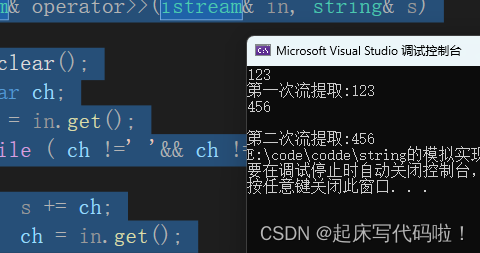
对于流提取,其作用过程通过前面的运算符重载来实现,而此运算符重载中需要调用函数
_
。这个函数都需要在插入前检查空间是否足够,不足则取调用函数进行扩容。假设,针对一个对象输入长度很长的字符串,即:

针对上述一个长度很长的字符产,需要不断的取调用函数进行扩容。即使人为在流提取之前手动开辟一块空间,空间的大小也不好确定。为了解决上述问题,引入下面的代码解决:
?
istream& operator>>(istream& in, string& s)
{
s.clear();
char tmp[128];
char ch = in.get();
int i = 0;
while ( ch !=' '&& ch != '\n')
{
tmp[i++] = ch;
if (i == 127)
{
tmp[i] = '\0';
s += tmp;
i = 0;
}
ch = in.get();
}
if (i > 0)
{
tmp[i] = '\0';
s += tmp;
}
return in;
}上述代码中,创建了一个能存储字符的字符数组,在利用
获取字符后,不会直接向
中进行添加,而是先向
插入,当数组的下标等于
时,向数组中最后一个位置插入\
。再一次性插入到
中。如果数组中字符的下标最终小于
,则会通过下面的代码进行判断,再一次性插入。这种方法针对于输入很长的内容的情况,减少了调用扩容函数的次数。
3. 深拷贝再优化:
? ? ? ?对于文章开头给出拷贝构造,假设需要利用类型对象
对
进行拷贝构造,即:
则整体的动作过程为:
? ? ? ?让开辟与
大小相同的空间,然后把
中的内容拷贝到
中。
? ? ? ?但是对于拷贝构造,还有一种更为简化的编写方法,即:
string(const string& s)
{
string tmp(s._str);
swap(tmp);
}直接通过构造函数,构建一个临时对象,其中
中的容量,大小,以及内容均与
相同。再通过交换函数
来交换
指针指向的对象以及
二者的的资源。
而对于上面赋值的深拷贝,其简化的编写方法为:
string& operator=( string s)
{
swap(s);
return *this;
}直接通过交换函数交换
,
指针指向对象的资源,然后再返回
即可。
4. 模式实现 的代码:
的代码:
?
#include<assert.h>
#include<iostream>
using namespace std;
namespace violent
{
class string
{
public:
string(const char* str ="")
{
_capacity = strlen(str);
_size = _capacity;
_str = new char[_size + 1];
strcpy(_str, str);
}
/*string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_capacity = s._capacity;
_size = s._size;
}*/
string(const string& s)
{
string tmp(s._str);
swap(tmp);
}
string& operator=( string s)
{
swap(s);
return *this;
}
/*string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[]_str;
_str = tmp;
_capacity = s._capacity;
_size = s._size;
}
return *this;
}*/
const char* c_str() const
{
return _str;
}
size_t size() const
{
return _size;
}
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator end() const
{
return _str + _size;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos <= _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[]_str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
void append(const char* s)
{
size_t len = strlen(s);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, s);
_size += len;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* s)
{
append(s);
return *this;
}
void insert(size_t pos, char ch)
{
assert(pos < _size);
if(_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
int end = _size;
while (end >=(int)pos)
{
_str[end + 1] = _str[end];
end--;
}
_str[pos] = ch;
_size++;
}
void insert(size_t pos, const char* s)
{
assert(pos < _size);
size_t len = strlen(s);
if (_size + len > _capacity)
{
reserve(_size + len);
}
int end = _size;
while (end >= pos + len)
{
_str[end + 1] = _str[end];
end--;
}
strncpy(_str + pos, s,len);
_size += len;
}
const static size_t npos = -1;
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len >= npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
void swap(string& s1)
{
std::swap(_str, s1._str);
std::swap(_size, s1._size);
std::swap(_capacity, s1._capacity);
}
size_t find(char ch, size_t pos = 0)
{
assert(pos < _size);
size_t end = _size;
for (size_t i = pos; i < end; i++)
{
if (_str[i] == 'ch')
{
return i;
}
}
return npos;
}
size_t find(const char* s, size_t pos = 0)
{
assert(pos < _size);
const char* str = strstr(_str + pos, s);
if (str == nullptr)
{
return npos;
}
else
{
return str - _str;
}
}
string substr(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
size_t end = pos + len;
if (len == npos || pos + len >= _size)
{
end = _size;
}
string str;
str.reserve(end - pos);
for (size_t i = pos; i < end; i++)
{
str += _str[i];
}
return str;
}
void clear()
{
_size = 0;
_str[0] = '\0';
}
~string()
{
delete[]_str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
private:
char* _str = nullptr;
size_t _capacity = 0;
size_t _size = 0;
};
void print_str(const string& s)
{
for (size_t i = 0; i < s.size(); i++)
{
cout << s[i] << ' ';
}
string::const_iterator it2 = s.begin();
while (it2 != s.end())
{
cout << *it2 << ' ';
it2++;
}
}
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.clear();
char tmp[128];
char ch = in.get();
int i = 0;
while ( ch !=' '&& ch != '\n')
{
tmp[i++] = ch;
if (i == 127)
{
tmp[i] = '\0';
s += tmp;
i = 0;
}
ch = in.get();
}
if (i > 0)
{
tmp[i] = '\0';
s += tmp;
}
return in;
}
void test1string()
{
string s1;
string s2("hello world");
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
cout << endl << endl << endl;
cout << "测试[]的访问功能;";
for (size_t i = 0; i < s2.size(); i++)
{
cout << s2[i] << ' ';
i++;
}
cout << endl;
cout << "测试[]对于返回值的修改功能:";
for (size_t i = 0; i < s2.size(); i++)
{
s2[i]++;
cout << s2[i] << ' ';
}
cout << endl;
cout << "测试迭代器访问:";
string::iterator it1 = s2.begin();
while (it1 != s2.end())
{
cout << *it1 << ' ';
it1++;
}
cout << endl << endl << endl;
cout << "print_str测试:";
print_str(s2);
}
void test2string()
{
string s2("hello world");
cout << s2.c_str() << endl;
s2 += 'x';
cout << s2.c_str() << endl;
s2 += "yyyyyy";
cout << s2.c_str() << endl;
cout << endl << endl;
s2.insert(0, 'a');
cout << s2.c_str() << endl;
s2.insert(3, "wwwww");
cout << s2.c_str() << endl;
}
void test3string()
{
string s3("hello world");
s3.erase(5, 3);
cout << s3.c_str() << endl;
string s4("hello world");
s4.erase(5, 100);
cout << s4.c_str() << endl;
}
void test4string()
{
string s1("hello world");
cout << s1.c_str() << endl;
string s2("hahaha");
string s3(s1);
cout << s3.c_str() << endl;
s1 = s2;
cout << s1.c_str() << endl;
}
void test5string()
{
string s1("hello world");
cout << s1 << endl;
string s2;
cin >> s1 ;
cout << s1;
}
void test6string()
{
string str("https://legacy.cplusplus.com/");
string sub1, sub2, sub3;
size_t pos1 = str.find(':');
sub1 = str.substr(0, pos1 - 0);
cout << sub1.c_str() << endl;
size_t pos2 = str.find('/', pos1 + 3);
sub2 = str.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << sub2.c_str() << endl;
sub3 = str.substr(pos2 + 1);
cout << sub3.c_str() << endl;
}
void test7string()
{
string s1;
cin >> s1;
cout << "第一次流提取:";
cout << s1<<endl;
cin >> s1;
cout << endl;
cout << "第二次流提取:";
cout << s1;
}
}?
#include"string.h"
int main()
{
violent::test7string();
return 0;
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 思政课程如何提升学习效率?这个方法分享给你
- Unity 2D标签跟随3D物体移动
- 写点东西《全栈工具箱 :Python版》
- MacBook安装Nginx
- Linux(CentOS)安装Redis教程
- 攻防世界——simple-check-100
- Wordpress seo优化该怎么做?
- 在校教师如何利用CHAT写个人总结?
- k8s控制器之CronJob--第二弹使用CronJob执行自动任务
- 英语不重要?别闹了,程序员!