如何通过 Prompt 优化大模型 Text2SQL 的效果
前言
在上篇文章中「大模型LLM在Text2SQL上的应用实践」介绍了基于SQLDatabaseChain的Text2SQL实践,但对于逻辑复杂的查询在稳定性、可靠性、安全性方面可能无法达到预期,比如输出幻觉、数据安全、用户输入错误等问题。
本文将从以下4个方面探讨通过Prompt Engineering来优化LLM的Text2SQL转换效果。
1. 问题及思路
2. Prompt概述
3. Text2SQL中的Prompt实践
4. 后续计划
1. 问题及思路
1.1 问题挑战
在自然语言处理(NLP)和人工智能(AI)领域,大型语言模型(LLM)如GPT-3和BERT已经取得显著的进步。然而,在将文本转换为SQL查询(Text to SQL)的任务上,这些模型仍有优化的空间。一些常见的挑战包括:
1. 输出幻觉(Hallucination):LLM在生成SQL语句时会生成一些看似合理,但实际与输入文本无关或错误的查询,这可能是由于模型尚未充分学习到SQL查询的语法和逻辑,导致在推理阶段产生误导性的输出。
2. 数据安全性:在处理敏感数据时,模型可能会生成泄露或篡改敏感信息的SQL语句。
3. 用户输入错误:用户在输入查询时拼写错误或有不合规的操作,这可能导致模型生成错误或高风险的SQL语句。
1.2 解决思路
针对上述问题,我们可以从Prompt Engineering(提示工程)和Fine Tuning(模型微调)两个方面进行考虑。
1. Prompt Engineering是一种通过设计特定的提示词或句子,引导模型生成更符合用户意图的输出的方法。例如,我们可以为模型添加一些关于SQL语法的提示信息,以帮助模型更好地理解SQL语句的结构和规则。通过这种方式,我们可以有效地降低输出幻觉的可能性,提高模型的准确性和稳定性。
2. Fine Tuning则是指在预训练模型的基础上,使用特定的数据集进行微调,以适应特定的任务需求。对于Text-to-SQL任务,我们可以使用包含大量SQL语句的数据集进行Fine Tuning,以提高模型对SQL语句的理解和生成能力。
1.3 思路对比
两者对比如下:
Fine Tuning | Prompt Engineering | |
方法 | 在与目标任务或领域相关的数据集上重新训练模型 | 输入提示的设计和调整,选择合适的关键词、短语或问题来引导模型生成所需的回答 |
复杂度 | 较高,涉及模型的重新训练和参数调整,需要对模型的内部结构和机制有一定的了解 | 较低,涉及到对输入提示的设计和调整,对模型本身的结构和机制要求较低 |
成本与时长 | 高,重新训练模型需要大量的计算资源和时间 | 低,可以通过迭代的方式逐步优化 |
性能 | 较高,模型深度理解特定任务或领域知识 | 稍低,侧重于引导模型生成与提示相关的回答 |
以我们都经历过的参加考试的例子做个通俗的对比:
1. Fine Tuning:考试前根据自己的知识体系,参考考试的题型、历史真题,做好有侧重点的准备;考试过程中根据给定的题目,按照自己的理解直接给出答案。
2. Prompt Engineering:考试前不做额外的准备,带着自己的知识体系去参加考试;考试过程中除了给定的题目外,还会有类似题目的解答思路,按照解答提示来给出答案。
2. Prompt概述
2.1 Prompt概念
Prompt是一种通过设计特定的提示词或句子,引导模型生成更符合用户意图的输出的方法。例如,我们可以为模型添加一些关于SQL语法的提示信息,以帮助模型更好地理解SQL语句的结构和规则。

Prompt的组成包四个元素:
-
Instruction(指令,必需):告诉模型该怎么做,如何使用外部信息,如何处理查询并构建Out。
-
Context(上下文信息,可选):充当模型的附加知识来源。这些可以手动插入到提示中,通过矢量数据库(Vector Database)检索(检索增强)获得,或通过其他方式(API、计算等)引入。
-
Input Data(需要处理的数据,可选):通常(但不总是)是由人类用户(即提示者)In 到系统中的查询。
-
Output Indicator(要输出的类型或格式,可选):标记要生成的文本的开头。

代码示例:
prompt = """ Answer the question based on the context below. If the question cannot be answered using the information provided answer with "I don't know".
Context: Large Language Models (LLMs) are the latest models used in NLP. Their superior performance over smaller models has made them incredibly useful for developers building NLP enabled applications. These models can be accessed via Hugging Face's `transformers` library, via OpenAI using the `openai` library, and via Cohere using the `cohere` library.
Question: Which libraries and model providers offer LLMs?
Answer: """
2.2 Prompt编写原则

1. 关键要素
-
明确目标:清晰定义任务,以便模型理解。
-
具体指导:给予模型明确的指导和约束。
-
简介明了:使用简练、清晰的语言表达Prompt。
-
适当引导:通过示例或问题边界引导模型。
-
迭代优化:根据输出结果,持续调整和优化Prompt。
2. 有效做法
-
强调,可以适当的重复命令和操作。
-
给模型一个出路,如果模型可能无法完成,告诉它说“不知道”,别让它乱“联想”。
-
尽量具体,它还是孩子,少留解读空间。
2.3 Prompt类型

2.3.1 Zero-Shot Prompting
直接向模型提出问题,不需要任何案例,模型就能回答你的问题,基于模型训练的时候提供的大量数据,能做初步的判断。
1. Zero-Shot Prompting 技术依赖于预训练的语言模型。
2. 为了获得最佳性能,它需要大量的样本数据进行微调。像ChatGPT 就是一个例子,它的样本数量是过千亿。
3. 由于Zero-Shot Prompting 技术的灵活性和通用性,它的输出有时可能不够准确,或不符合预期。这可能需要对模型进行进一步的微调或添加更多的提示文本来纠正。
2.3.2 Few-Shot Prompting
向模型提出问题,同时给出少量案例,模型根据给定的案例调整输出的回答。
缺点:依赖于案例的质量,案例如果给的不恰当,模型也会学到不恰当的描述和回答。
**2.3.3 Chain of Thought(CoT)**思维链
Jason Wei等人(2022)引入的思维链(CoT)提示,通过中间推理步骤实现复杂的推理能力。可以将其与少样本提示相结合,以获得更好的结果,以便在回答之前进行推理的更复杂的任务。

有两种方式增加GPT的推理能力,或者CoT能力:
1. 第一种:增加案例,如下所示,第一次回答错误,给一个计算过程的案例,GPT可以通过案例学会简单推理。

2. 第二种:增加关键句,Let’s think step by step,测试人员测了很多类似的句子,最后发现这句话是效果最好的,这个时候不加案例,GPT也具备一定的推理能力。

根据 Wei 等人的论文表明,它仅在大于等于 100B 参数的模型中使用才会有效。如果使用的是小样本模型,这个方法不会生效。
2.3.4 Self-Consistency 自洽
是对CoT的一个补充,让模型生成多个思维链,然后取最多数答案的作为最终结果。其实重复运算多次,取概率最高的那一个,需要借助脚本辅助完成这个功能。

1. 从语言模型中生成多个不同的“推理路径(reasoning paths)”,这些路径可能因模型的随机性或不同的参数设置(如temperature、top_p等)而有所不同。有助于模型更全面地考虑问题,并可能导致更准确或更可靠的最终答案。
2. 对上一步生成的多个推理路径进行“边缘化(marginalize out)”以得到一个最终的、一致的答案。边缘化在这里意味着从多个可能的推理路径中找出最常见或最一致的答案。
2.3.5 Tree of Thoughts(ToT) 思维树
Tree of Thoughts(ToT)框架,用于改进语言模型(LMs)的推理能力。该框架是对流行的“Chain of Thought”方法的一种泛化,允许模型在解决问题的过程中进行更多的探索和策略性前瞻。
ToT允许模型自我评估不同的选择,以决定下一步的行动,并在必要时进行前瞻或回溯,以做出全局性的选择。

在24点游戏中,使用链式思考提示的GPT-4仅解决了4%的任务,而使用ToT方法的成功率达到了74%。
2.3.6 ReAct框架
Yao等人(2022)引入了一个框架,其中LLMs以交错的方式生成推理轨迹和任务特定操作,并且允许LLMs与外部工具交互来获取额外信息,从而给出更可靠和实际的回应。ReAct的灵感来自于“行为”和“推理”之间的协同作用,正是这种协同作用使得人类能够学习新任务并做出决策或推理。
下图展示ReAct的一个示例,举例执行问题回答所涉及的不同步骤。

实现流程如下:
(1)用Prompt实现一个样例,比如上面的模板:Thought:xxx ==> Action: Search[xxx];
(2)LLMs会根据模板相同的逻辑,结合CoT思维链方式一步一步思考,并获取外部知识;
(3)最后Action: Finish获取最终结果后结束。
ReAct框架在后续介绍Text2SQL的Agent实现的文章中还会详细介绍,步骤如下:

3. Text2SQL中的Prompt实践
3.1 现有问题
以上篇文中「大模型LLM在Text2SQL上的应用实践」的数据库Chinook为例,需求为统计“连续两个月都下订单的客户有哪些?”,示例代码可参考上文。
结果如下:
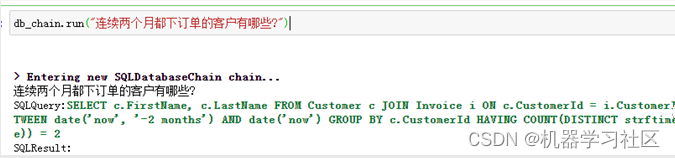
可以看出生成的SQL不准确,只统计了最近两个月中都下订单的客户,和统计需求不相符。那如何解决这个问题?
3.2 解决方案
1. 增强LLM模型能力
我们先从LLM模型的角度考虑。测试案例中用到的是“GPT-3.5-Turbo”,参考Spider排行榜(https://yale-lily.github.io/spider)可以看出GPT-4的效果还是一骑绝尘。

我们将LLM模型切换为GPT-4测试下效果,结果如下:
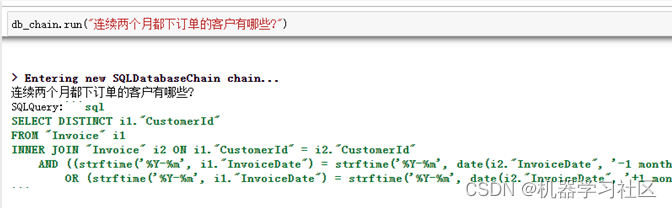
效果:生成的SQL基本上满足我们的需求。
成本:GPT-4的费用通常为GPT-3.5的10倍左右。所以该方案不是我们的首选方案。但其生成的SQL可以作为后续的参考和输入。
2. Prompt Engineering
采用Prompt的方式来实现。其中自定义Prompt信息包括:Database中Table Schema信息,Table Row数据样本和Few-shot Examples。
PromptTemplate示例代码如下:
from langchain.prompts import PromptTemplate
TEMPLATE = """Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Use the following format:
Question: "Question here"
SQLQuery: "SQL Query to run"
SQLResult: "Result of the SQLQuery"
Answer: "Final answer here"
Only use the following tables:
{table_info}.
Some examples of SQL queries that correspond to questions are:
{few_shot_examples}
Question: {input}"""
其中{table_info}包括Table Schema信息和Table Row数据样本,可通过LangChain中的SQLDatabase来获得,其封装在db.table_info中,示例内容如下:
CREATE TABLE "Track" (
"TrackId" INTEGER NOT NULL,
"Name" NVARCHAR(200) NOT NULL,
"AlbumId" INTEGER,
"MediaTypeId" INTEGER NOT NULL,
"GenreId" INTEGER,
"Composer" NVARCHAR(220),
"Milliseconds" INTEGER NOT NULL,
"Bytes" INTEGER,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("TrackId"),
FOREIGN KEY("MediaTypeId") REFERENCES "MediaType" ("MediaTypeId"),
FOREIGN KEY("GenreId") REFERENCES "Genre" ("GenreId"),
FOREIGN KEY("AlbumId") REFERENCES "Album" ("AlbumId")
)
SELECT * FROM 'Track' LIMIT 3;
TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice
1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.99
2 Balls to the Wall 2 2 1 None 342562 5510424 0.99
3 Fast As a Shark 3 2 1 F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman 230619 3990994 0.99
整体的测试代码如下:
from langchain.utilities import SQLDatabase
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain import hub
# Initialize database
db = SQLDatabase.from_uri("sqlite:///xxx/Chinook.db")
# Pull down prompt
prompt = hub.pull("rlm/text-to-sql")
# Initialize model
model = ChatOpenAI()
# few shot examples
few_shots = {
"List all artists.": "SELECT * FROM artists;",
"Find all albums for the artist 'AC/DC'.": "SELECT * FROM albums WHERE ArtistId = (SELECT ArtistId FROM artists WHERE Name = 'AC/DC');",
"连续两个月都下订单的客户有哪些?":"SELECT DISTINCT a.'CustomerId', a.'FirstName', a.'LastName' FROM 'Customer' a JOIN 'Invoice' b ON a.'CustomerId' = b.'CustomerId' JOIN 'Invoice' c ON a.'CustomerId' = c.'CustomerId' AND ((strftime('%Y-%m', b.'InvoiceDate') = strftime('%Y-%m', date(c.'InvoiceDate', '-1 month'))) OR (strftime('%Y-%m', b.'InvoiceDate') = strftime('%Y-%m', date(c.'InvoiceDate', '+1 month'))))"
}
# Create chain with LangChain Expression Language
inputs = {
"table_info": lambda x: db.get_table_info(),
"input": lambda x: x["question"],
"few_shot_examples": lambda x: few_shots,
"dialect": lambda x: db.dialect,
}
sql_response = (
inputs
| prompt
| model.bind(stop=["\nSQLResult:"])
| StrOutputParser()
)
# Call with a given question
sql_response.invoke({"question": "连续两个月都下订单的客户有哪些?"})
结果如下:

效果:生成的SQL满足我们的需求。
成本:增加的Prompt上下文信息所占tokens的费用,与GPT-4相比基本在10%左右。
**根据Prompt信息,**测试相似拓展问题,结果情况如下:
案例1:统计“连续两个月都下订单的客户总共有多少个?”

结果:生成的SQL满足我们的需求。
案例2:统计“连续两个月都下订单的客户的订单总共有多少个?”

结果:生成的SQL满足我们的需求,虽然不是最优解。
4. 后续计划
本文介绍了通过Few-shot Prompting来优化Text2SQL生成结果的案例,总的来说,Prompt Engineering提供了一种有效的方法来优化LLM在Text2SQL应用上的效果。通过精心设计的提示,我们可以引导模型更好地理解和处理用户的查询,从而提高查询的准确性和效率。除了使用Few-shot Prompting,还可以考虑Agent、CoT等相关技术对Text2SQL效果的优化,后续共同探讨。同时也期待更多的研究和应用来探索和利用大型语言模型的潜力。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
建立了大模型技术交流群,大模型学习资料、数据代码、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

参考文献:
https://python.langchain.com/docs/use_cases/qa_structured/sql
https://blog.langchain.dev/query-construction/
https://blog.langchain.dev/llms-and-sql/
https://www.promptingguide.ai/zh/techniques/fewshot
https://zhuanlan.zhihu.com/p/663355618
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!