matplotlib单变量和双变量可视化
发布时间:2023年12月31日
使用seaborn 库的tips数据集,其中包含了某餐厅服务员收集的顾客付小费的相关数据(评论区)
单变量可视化 直方图
直方图是观察单个变量最常用的方法。这些值是经过"装箱"(bin)处理的 直方图会将数据分组后绘制成图来显示变量的分布状况。
import pandas as pd
tips = pd.read_csv('data/tips.csv')
tips['total_bill'].describe()import numpy as np
# 生成等差数列
np.linspace(3.07,50.81,11,endpoint=True)
#
array([ 3.07 , 7.844, 12.618, 17.392, 22.166, 26.94 , 31.714, 36.488,
41.262, 46.036, 50.81 ])fig = plt.figure(figsize=(16,8))
# hist 直方图 bins 将要可视化的数据 均匀的分成多少组 这里传10 就是分成10组
# total_bill 最小值 3.07, 最大值 50.81 从3.07~50.81均匀的分成10组
# [ 3.07 , 7.844, 12.618, 17.392, 22.166, 26.94 , 31.714, 36.488, 41.262, 46.036, 50.81 ]
axis1 = fig.add_subplot(1,1,1)
axis1.hist(tips['total_bill'],bins=10)
axis1.set_title('Histogram of Total Bill')
axis1.set_xlabel('Total Bill')
axis1.set_ylabel('Frequency')
plt.show()?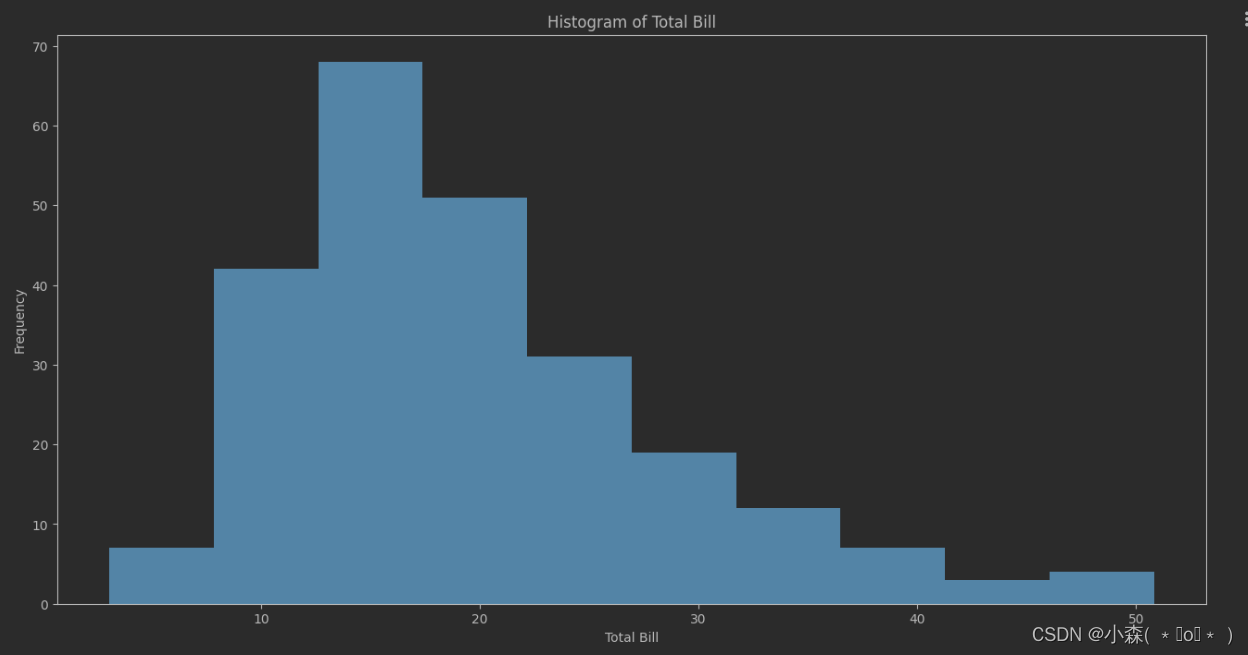
tips[(tips['total_bill']<12.618) & (tips['total_bill']>7.844)]?
?双变量可视化 散点图
散点图用于表示一个连续变量随另一个连续变量的变化所呈现的大致趋势。
fig = plt.figure(figsize=(12,8))
axis1 = fig.add_subplot(1,1,1)
# 绘制散点图 点一个参数散点的x坐标, 第二个参数就是点的y坐标
axis1.scatter(tips['total_bill'],tips['tip'])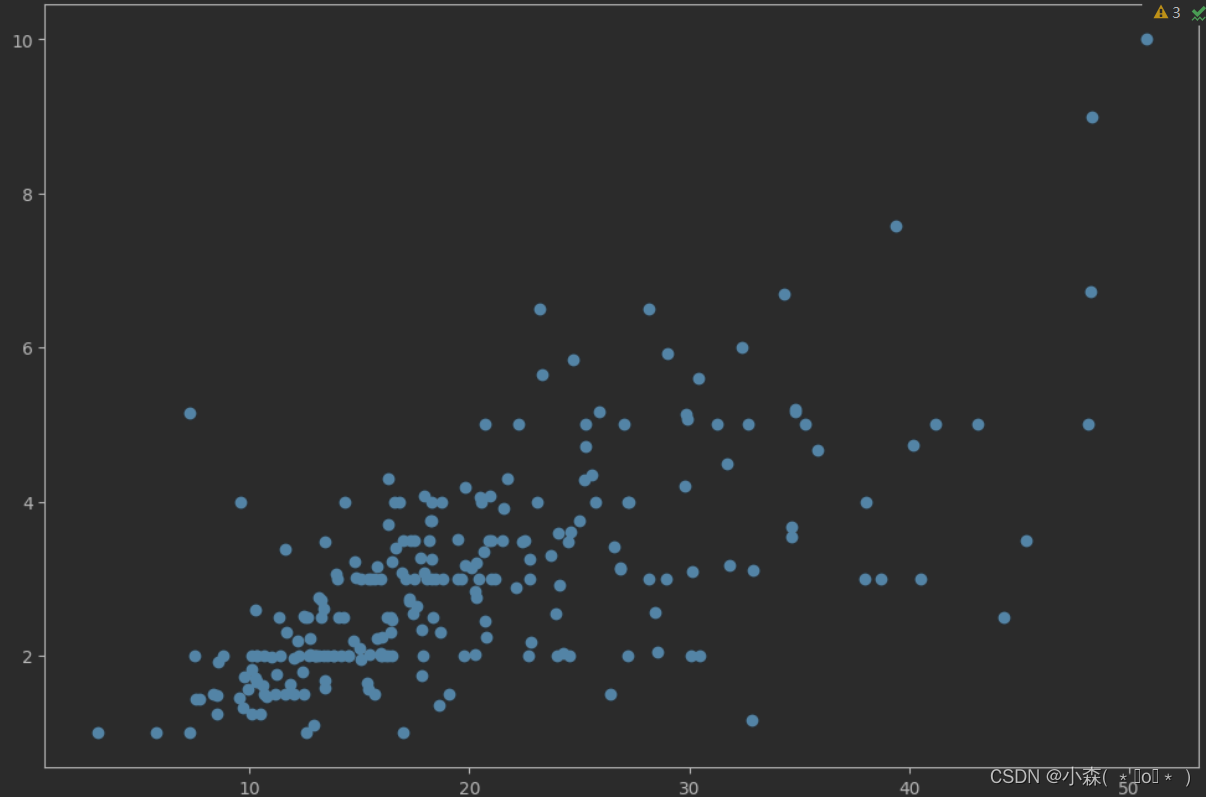 ?
?
def encode_sex(sex):
if sex == 'Female':
return 0
else:
return 1
tips['sex_color'] = tips['sex'].apply(encode_sex)
fig = plt.figure(figsize=(20,8))
axes1 = fig.add_subplot(1,1,1)
axes1.scatter(x = tips['total_bill'],y=tips['tip'],s = tips['size']*20, c= tips['sex_color'],alpha=0.5)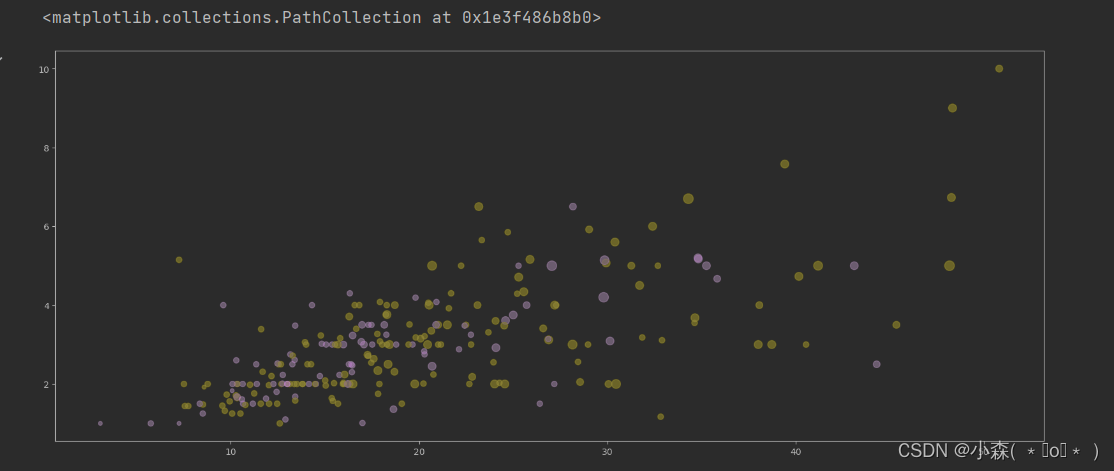 ?
?
fig = plt.figure(figsize=(20,8))
# 绘图区域可以分成几行 几列 当前图绘制在第几个位置上 位置从1开始计数的
# fig.add_subplot(1,1,1)
fig.add_subplot(3,3,1)
fig.add_subplot(3,3,5)
fig.add_subplot(3,3,9) ?
?
Matplotlib绘图步骤:
导入Matplotlib.pyplot
准备数据
创建图表,坐标轴
绘制图表
设置标题,x,y轴标题等?
文章来源:https://blog.csdn.net/qq_64685283/article/details/135315366
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鸿蒙 - arkTs: 页面路由
- C++ enum class 如何使用
- 【EI会议征稿通知】第四届工业制造与结构材料国际学术会议(IMSM 2024)
- Ubuntu安装Samba
- 2024--Django平台开发-Django知识点(六)
- 【Python可视化系列】一文教会你绘制美观的直方图(理论+源码)
- 动态住宅代理IP是什么?如何配置使用?
- 2023年广东省网络安全A模块(笔记详解)
- Linux环境配置
- 系分笔记数据库反规范化、SQL语句和大数据