Transformer:Attention Is All You Need
封面
? 标题,作者信息,文章出处
背景
? 序列转录模型
一般都用RNN或者CNN,里面包含一个encoder和decoder的框架。
目前主流的处理序列问题像机器翻译,文档摘要,对话系统,QA等都是encoder和decoder框架,
编码器:从单词序列到句子表示
解码器:从句子表示转化为单词序列分布
自回归,编码的时候可以直接把整个句子给你,解码的时候只能一个一个的去生成
过去时候的输出是当前时刻的输入
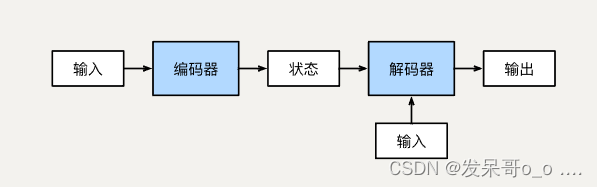
传统的编码器解码器一般使用RNN,这也是在机器翻译中最经典的模型,但正如我们都知道的,RNN难以处理长序列的句子,无法实现并行,并且面临对齐问题。

在计算时将位置与步骤对齐,它们生成一系列隐藏状态h t h_th**t,t tt位置的h t h_th**t使用它的前驱h t ? 1 h_{t-1}h**t?1和当前的输入生成。这种内部的固有顺阻碍了训练样本的并行化,在序列较长时,这个问题变得更加严重
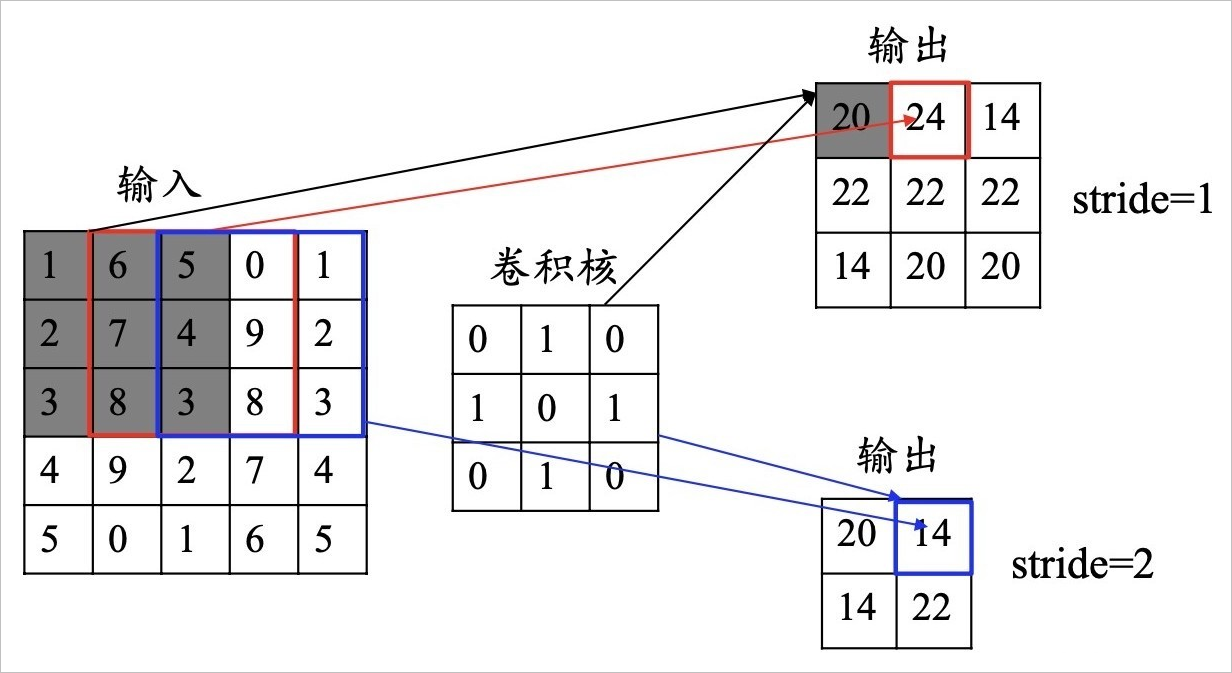
CNN计算的时候,每次都是一个窗口,对于两个像素如果比较远的话,需要很多层卷积才可以把像素连接起来,但Transformer一次就能看到所有的序列,但卷积可以做多个输出通道,一个输出通道可以认为是识别不一样的模式,多头的注意力机制可以模拟CNN的多输出通道的一个效果。
自注意力机制是别人已经提出来的
在以前的时候,attention已经和rnn结合在一起了,但主要是怎么把编码器的东西有效的传给解码器
Transformer允许对依赖关系建模,而不需要考虑它们在输入或输出序列中的距离
在这项工作中,我们提出了Transformer,这是一种避免使用循环的模型架构,完全依赖于注意机制来绘制输入和输出之间的全局依赖关系。Transformer允许更显著的并行化,
在某个翻译任务显示出了可以并行,训练时间少。
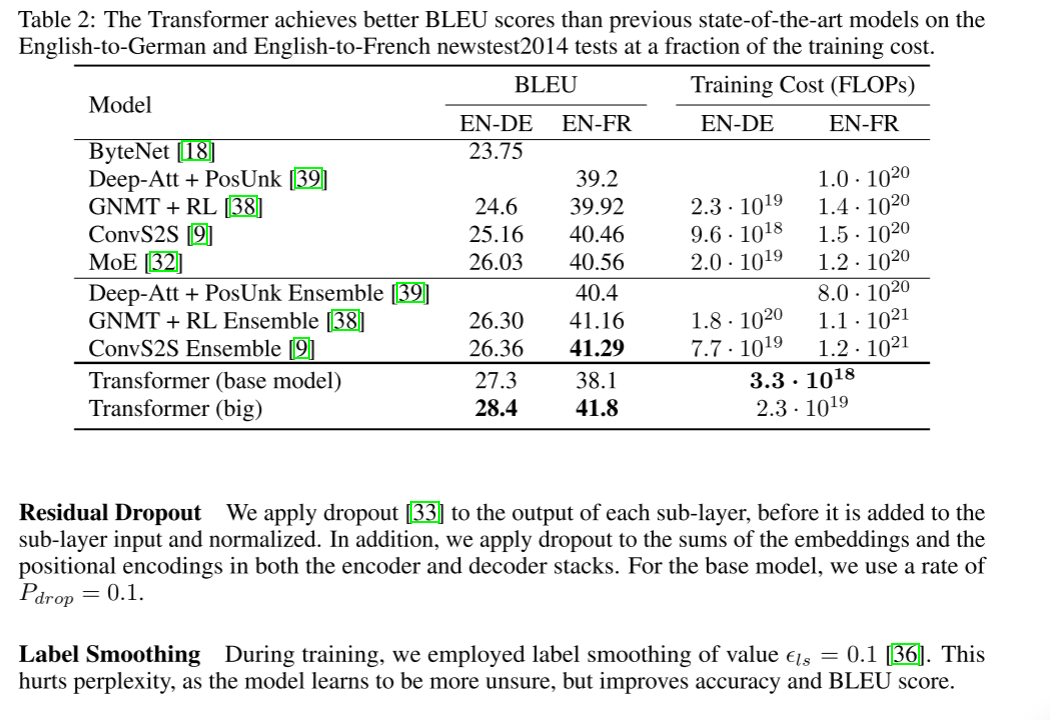
WMT 2014英译德翻译任务中获得了28.4%的BLEU成绩,比最好的成绩还高了百分之2,
使用8个P100 gpu只训练了12小时,在翻译质量上就可以达到一个新的SOTA。
在别的类型的任务也能很好,图像,音频
2背景
注意力机制

三个Attention
第一个Attention是value的加权和,自己和自己的权重是最大的,和其他的相似度做权重
第二个主要是Masked,对t时刻的query的输出,不应该看t时刻后面的query
第三个Key和Value是编码器的输出(Value的加权和),Query是解码器的输入,根据query向量,在编码器的输出里面找出相似的东西,不相似的东西可以忽略掉
PS:
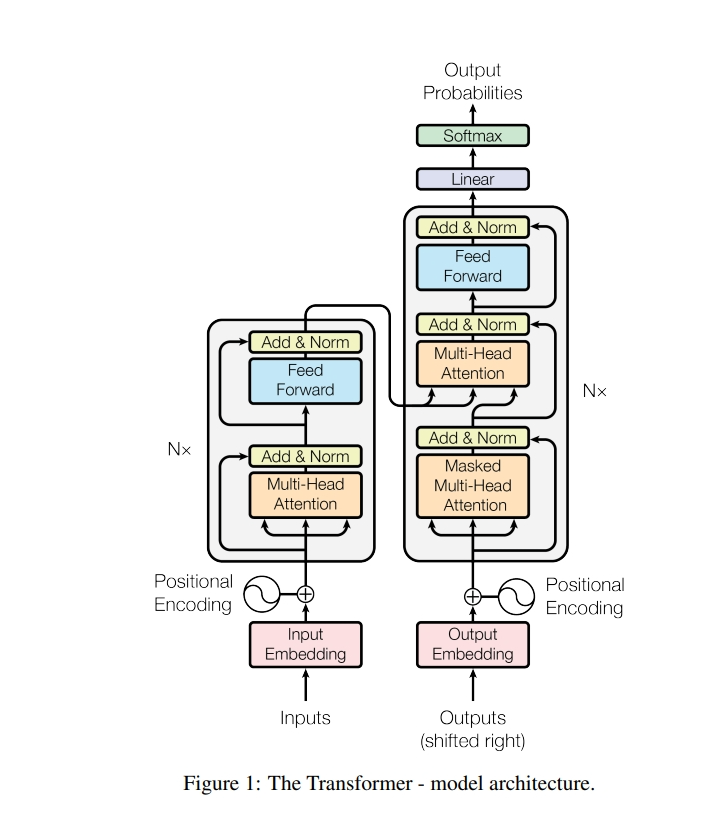
? 左面编码器,右面解码器 解码器在之前时刻的输出为此时的输入
嵌入层,残差链接
?
编码器:
? 一个多头注意力机制,一个MLP
每个子层用一个残差链接
注意力
编码器的输出是Value的一个加权和,每个Value的权重,是这个Value对应的Key与Query的相似度
masked对后面的东西,权重要设成0(权重变成很大的负数,softMax后就变成0了)
编码器的输出,相似度高的设置其权重高
Input是输入的句子,Output是解码器上一时刻的输出,一个一个右移
Add&Norm是残差连接
masked保证在T时刻不会看到T时刻以后的输入
Output是Value的一个加权和,权重是query和key的相似度来的,内积的值越大说明向量越相似
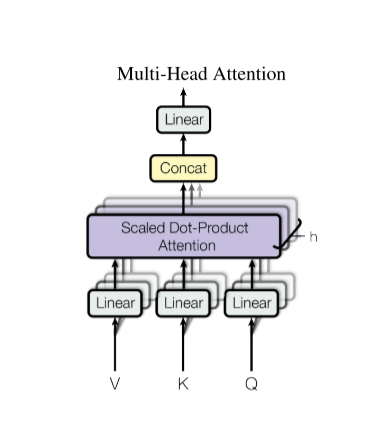

VKQ进入一个线性层,做一个scaled Dot-Product Attention,做h次
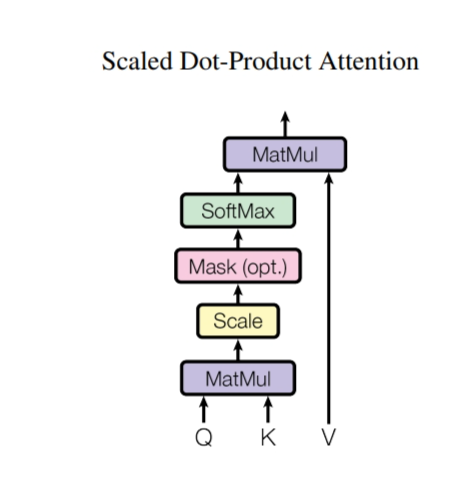
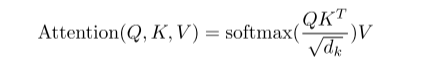
点乘的注意力机制,
SoftMax是n个非负的,加起来等于1的权重,然后把权重作用在Value上面就可以得到输出
当dk比较大的时候,向量的差距会变大,softMax出来的值会向两边靠拢,梯度会比较小,训练时间可能会更长
Mask使得不计算T时刻后面的值,但是注意力机制会显示所有,对于kt,qt之后的值,权重换成一个非常大的负数,softMax之后会变成0
Q和K做矩阵乘法,除dk,做Mask处理,SoftMax,然后在和值的矩阵做矩阵乘法
前馈网络
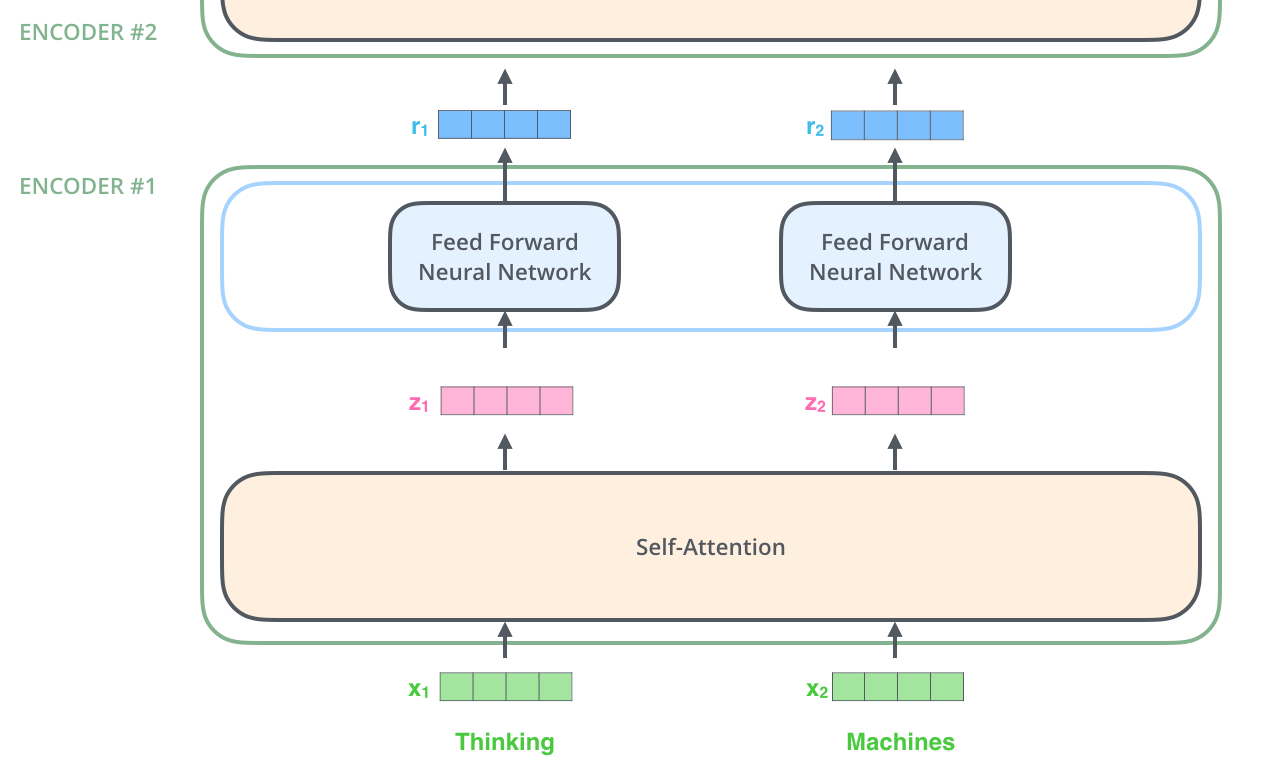
Attention已经把序列信息提取出来了,做一次汇聚,对每个点独立做就可以。
Position Encoding会在输入信息加入当前词在句子中的位置
为什么要用自注意力机制

正则
使用大量的dropout层,但dropout率不是特别高
结论
多头注意力机制
我们提出了第一个完全基于注意的序列转导模型Transformer,用多头自我注意取代了编解码器结构中最常用的递归层
对于翻译任务,Transformer的训练速度比基于递归或卷积层的体系结构快得多。
在2014年WMT英语到德语和WMT 2014英语到法语的翻译任务中,我们都达到了一个新的艺术水平
我们计划将Transformer扩展到涉及文本以外的输入和输出模式的问题,如图像、音频和视频
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- YACS(上海市计算机学会竞赛平台)二星级题单——闯关升级
- 基本操作(六)yum方式安装nginx
- CSS 使用技巧
- leetcode第 381 场周赛最后一题 差分,对称的处理
- Human3.6m数据集预处理的一个小步骤
- Java开发安全之:Unreleased Resource: Streams需确保流得到释放
- 【低功耗】芯片低功耗-硬件
- POWERBUILDER如何解析xml
- python发送邮件的时候出现 error (535, b‘5.7.3 Authentication unsuccessful‘) 解决方法
- 下载知虾数据分析软件:优化店铺运营、提高转化率的利器