[排序篇] 快速排序
目录
往期回顾???
| [排序篇] 冒泡排序 | [排序篇] 冒泡排序-CSDN博客 |
?
前言?
上一节我们学习了冒泡排序,但是它的执行效率很低,时间复杂度达到了O()。?什么概念?
假设计算机每秒可以运行 10 亿次(10^9次),那么对 1 亿个数进行排序,冒泡排序需要多长时间?
现在我们来简单计算一下:?
首先,对于 N 个数来说,冒泡排序需要执行 N^2 次操作。
- 在这种情况下,N = 1亿,所以操作次数为 (1亿)^2 = 10^16次。
接下来,我们将操作次数除以计算机每秒运行的次数,以确定所需的秒数。
- 秒数 = 操作次数 / 每秒运行次数
- 秒数 = 10^16 / 10^9 = 10^7 = 1千万秒
为了将秒数转换为更容易理解的时间单位,我们继续进行以下计算:
将1千万秒除以60,以确定所需的分钟数。
- 分钟数 = 秒数 / 60 = 1千万 / 60 ≈ 166,667分钟
将分钟数除以60,以确定所需的小时数。
- 小时数 = 分钟数 / 60 ≈ 166,667 / 60 ≈ 2,778小时
将小时数除以24,以确定所需的天数。
- 天数 = 小时数 / 24 ≈ 2,778 / 24 ≈ 115天
结果显示,对1亿个数进行冒泡排序大概需要115天。所以冒泡排序并不理想,因此就有人在冒泡排序的基础上进行了改进,这就是有名的快速排序算法。
一、概念?
快速排序算法,顾名思义,它的特点就是快、效率高,是处理大数据最快的排序算法之一。
- 最坏的情况下,每一次基准数都是序列中最小或者最大的元素,这时快速排序就是冒泡排序,其时间复杂度就是冒泡排序的时间复杂度:T[n] = n * (n-1) = n^2 + n,也就是 O(
)
- 平均时间复杂度为 O (NlogN),其中递归算法的时间复杂度公式:T[n] = aT[n/b] + f(n)
二、快速排序算法?
假设我们现在对 "9 1 3 10 14 5 6 8 17 12" 这 10 个数进行排序。首先在这个序列中随便找一个数作为基准数。为了方便,就让第一个数 9 作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在 9 的右边,比基准数小的数放在 9 的左边,类似下面这种排列。
5 1 3 8 6 9 14 10 17 12
在初始状态下,数字 9 在序列的第 1 位。我们的目标是将 9 挪到序列中间的某个位置,假设这个位置是 k。现在就需要寻找这个 k,并且以第 k 位为分界点,左边的数都小于等于 9,右边的数都大于等于 9。那么该如何实现呢?方法如下:
分别从初始数组序列 "9 1 3 10 14 5 6 8 17 12" 两端开始 "寻找"。先从右往左找一个小于 9 的数,再从左往右找一个大于 9 的数,然后交换它们。这里可以用两个变量 i 和 j,分别指向序列最左边和最右边。我们假设这两个变量是一对情侣?"女孩 i" 和 "男孩 j"。刚开始的时候让 "女孩 i" 指向序列的最左边(即 i=0),指向数字 9 。让 "男孩 j" 指向序列的最右边(即 j=9),指向数字 12。?
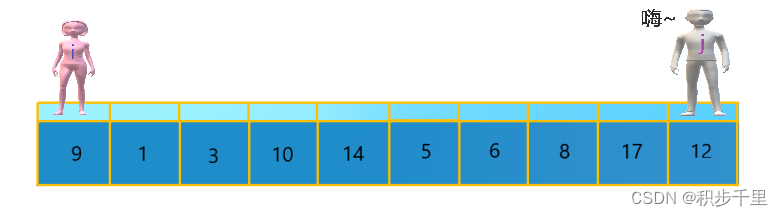
由于以最左边的数为基准数,所以需要让 "男孩 j" 先出动,这一点非常重要(请先想想为什么,第五节再做补充说明)。
"男孩 j" 一步一步地向左移动(即 j--),直到找到一个小于 9 的数停下来。接下来 "女孩 i" 再一步一步向右移动(即 i++),直到找到一个大于 9 的数停下来。最后 "男孩 j" 停在了数字 8 的位置,"女孩 i" 停在了数字 10 的位置。

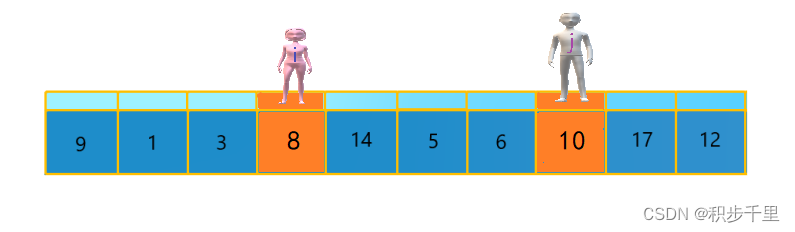
现在交换 "女孩 i" 和 "男孩 j" 所指向的元素的值。交换之后的序列如下。
9 1 3 8 14 5 6 10 17 12
到此,第一次交换结束。接下来 "男孩 j" 继续向左移动(温馨提示,每次必须是 "男孩 j" 先出发)。他发现了 6(比基准数 9 要小,满足要求)停了下来。 "女孩 i" 也继续向右移动,她发现了 14(比基准数 9 要大,满足要求)停了下来。此时再次进行交换,交换后的序列如下。
9 1 3 8 6 5 14 10 17 12??
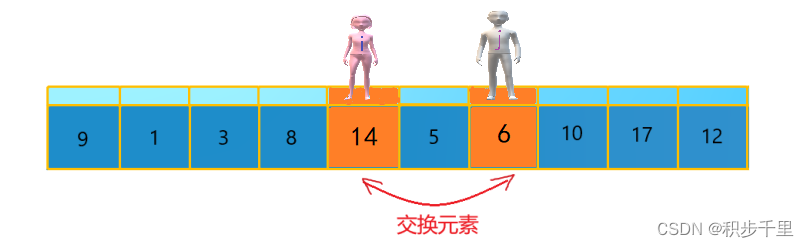
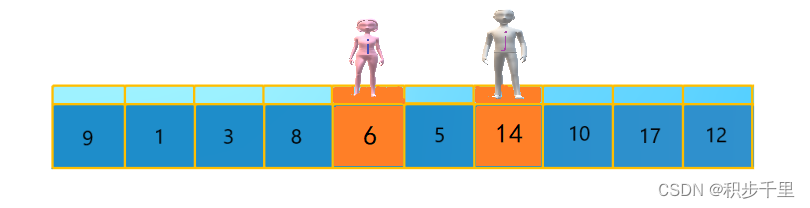
第二次交换结束,"寻找" 继续。 "男孩 j" 继续向左移动,他发现了 5(比基准数 9 要小,满足要求)又停了下来。 "女孩 i" 继续向右移动,好巧!此时 "女孩 i" 和 "男孩 j" 相遇了,"女孩 i" 和 "男孩 j" 都走到 5 的位置,说明此次 "寻找" 结束。我们将基准数 9 和 5 进行交换,交换后的序列如下。
5 1 3 8 6 9 14 10 17 12?
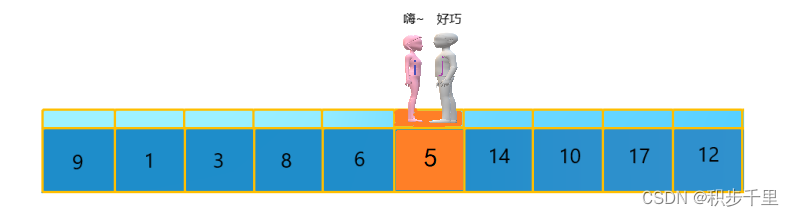
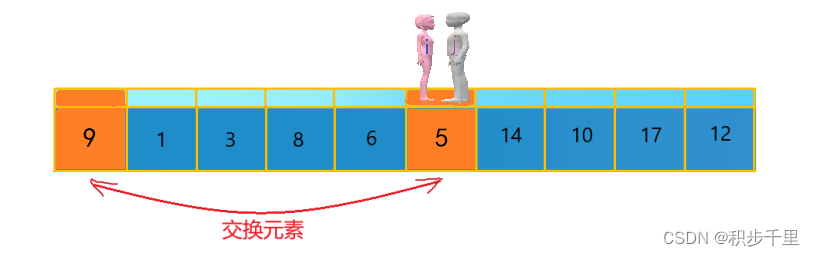

到此第一轮 "寻找" 真正结束。此时以基准数 9 为分界点,9 左边的数都小于等于 9,9 右边的数都大于等于 9。回顾以上过程,"男孩 j" 的使命就是要找到小于基准数的数,而 "女孩 i" 的使命就是要找到大于基准数的数,直到 i 和 j 相遇为止。
至此我们已经将原来的序列,以 9 为分界点拆分成了两个序列,左边的序列是 "5 1 3 8 6",右边的序列是 "14 10 17 12"。接下来还需要分别处理这两个序列,因为 9 左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理 9 左边和右边的序列即可。现在先来处理 9 左边的序列。
- 左边的序列是 "5 1 3 8 6"。将这个序列以 5 为基准数,使得 5 左边的数都小于等于 5,5 右边的数都大于等于 5。调整后的序列的顺序应该是:"3 1 5 8 6"
- 接下来继续处理 5 左边的序列 "3 1" 和右边的序列 "8 6"。对序列 "3 1" 以 3 为基准数进行调整,调整后的序列为:"1 3"。而序列 “1” 只有一个数,则不需要进行任何处理。至此我们对序列 "3 1" 已全部处理完毕,得到的序列是:"1 3"。
- 序列 "8 6" 的处理也仿照此方法,调整后的序列为:"6 8"。
最后得到的序列如下:?
?1 3 5 6 8 9?14 10 17 12?
对于 9 右边的序列 "14 10 17 12" 也模拟刚才的过程,直到不可拆分出新的子序列为止。最终将会得到这样的序列:
?1 3 5 6 8 9?10 12 14 17?
到此, 排序全部结束。细心的你可能已经发现,快速排序的每一轮处理其实就是将这一轮的基准数归位,直到所有的数都归位为止,排序就结束了。下面以一个整体图来描述下整个算法的处理过程。

快速排序之所以比较快,是因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样只能在相邻的数之间进行交换,交换的距离就大得多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的,都是 O(),它的平均时间复杂度为 O (NlogN)。其实,快速排序是基于一种叫做 "二分" 的思想。
三、快速排序算法代码??
#include <stdio.h>
static int a[64], n; //定义全局变量,存储序列元素和记录序列长度
void quick_sort(int left, int right)
{
int i, j, t, basic;
if (left > right)
return;
basic = a[left]; //basic中存的就是基准数
i = left;
j = right;
while (i != j) {
//顺序很重要,要先从右往左找
while (a[j] >= basic && i < j)
j--;
//再从左往右找
while (a[i] <= basic && i < j)
i++;
//交换两个数在数组中的位置
if (i < j) { //当女孩i和男孩j没有相遇时
t = a[i];
a[i] = a[j];
a[j] = t;
}
}
//最终将基准数归位
a[left] = a[i];
a[i] = basic;
//观察数组a序列的变化过程
// for (int k = 0; k < n; k++)
// printf("%d ", a[k]);
// printf("\n");
quick_sort(left, i-1); //递归处理左边的元素
quick_sort(i+1, right);//递归处理右边的元素
}
int main()
{
int i;
//读入数据
scanf("%d", &n);
for (i = 0; i < n; i++)
scanf("%d", &a[i]);
//快速排序调用
quick_sort(0, n-1);
//输出排序后的结果
for (i = 0; i < n; i++)
printf("%d ", a[i]);
printf("\n");
return 0;
}可以输入以下数据进行验证:??
10
9 1 3 10 14 5 6 8 17 12?
运行结果是:
1 3 5 6 8 9 10 12 14 17?
下面是程序执行过程中数组 a 的变化过程,带下划线的数表示的是已归位的基准数。
9 1 3 10 14 5 6 8 17 12
5 1 3 8 6 9 14 10 17 12?
3 1 5 8 6 9 14 10 17 12?
1 3 5 8 6 9 14 10 17 12?
1 3 5 8 6 9 14 10 17 12?
1 3 5 6 8 9 14 10 17 12?
1 3 5 6 8 9 14 10 17 12?
1 3 5 6 8 9 12 10 14 17?
1 3 5 6 8 9 10 12 14 17?
1 3 5 6 8 9 10 12 14 17?
1 3 5 6 8 9 10 12 14 17?
四、快速排序之递归函数讲解
快速排序是基于 "二分法" 和 "递归" 来实现的。对于一些零基础或者对递归函数不熟悉的同学来说,看了以上的这段代码可能会有点吃力,因此,在这里简要说明递归函数的实现过程。
以下是截取出来的递归函数代码:
void quick_sort(int left, int right)
{
int i, j, t, basic;
/* 省略中间实现的部分代码 */
quick_sort(left, i-1); //递归处理左边的元素
quick_sort(i+1, right);//递归处理右边的元素
}?在开始讲述递归函数实现之前,我们先来复习一下栈帧的知识。
- 在函数调用过程中,系统会根据函数的局部变量、参数的数量和大小,以及其他与函数执行相关的信息(如返回地址、调用者保存的寄存器等),为其分配大小合适的独立栈空间(称为栈帧)。
- 函数入栈和出栈操作,都遵循先进后出(Last-In-First-Out,LIFO)的原则。当函数返回时,相应的栈帧会被释放而从栈顶弹出,以便为后续的函数调用腾出空间。
- 这种先进后出的特性确保了函数调用的顺序和递归的执行顺序,使得递归调用可以按照正确的顺序返回到上一层调用的位置。
看到这里相信大家对函数调用已经有了初步的认识,了解函数调用的原理对于理解递归函数是非常重要的,不然当你打印查看整个递归的过程会有很多的疑惑。比如:
- ?程序执行过程中出现了 left=1, right=0 时,已满足了 left > right 的条件而函数也立即返回了,为什么还能继续执行递归?quick_sort(i+1, right) 函数。
- 这就需要你了解函数调用的原理,才能理解这个递归过程了。
- 前面我们已经知道,快速排序是要先处理完序列的左边元素(调用?quick_sort(left, i-1) 递归实现)后,才能继续处理右边的元素 (调用?quick_sort(i+1, right) 递归实现)。
- 在处理左边元素的这个过程,每调用一次 quick_sort() 函数,系统就会为它分配一个独立的栈帧空间(这个栈帧是有序号的,遵循先进后出原则)。因此,当程序出现了 left=1, right=0 时,只是当前栈帧的 quick_sort(i+1, right)?函数退出而已,但是上一层的? quick_sort(i+1, right)?函数并没有退出,所以我们打印时才看到 quick_sort(i+1, right) 函数能继续递归执行。
下图是递归函数调用的过程(仅仅列举了其中几次调用):

从上图可以看出,每次递归调用?quick_sort 函数入栈的内容都是一致。需要注意的是,栈帧的大小是有限制的,因为栈空间是有限的。如果函数的栈帧过大,超过了可用的栈空间,可能会导致栈溢出错误。这通常发生在递归调用过程中,如果递归的深度太大,栈空间可能会被耗尽。
五、补充说明
还记得,第二节提到的 “序列以最左边的数为基准数,需要让 "男孩 j" 先出动” 的提示吗?。在这里来进行补充说明,为什么 “以最左边的数为基准数,必须要让 "男孩 j" 先出动”。?
试想一下, 假设我们现在需要对 “9 1 3 10” 序列进行排序,依然以 9 基准数。
- 如果让 "女孩 i" 先出动(找到大于基准数的数停下来),是不是要 "寻找" 到 10 这个位置才能停止,然而10 的位置刚好就是 "男孩 j" 的位置。
- 还记得吗?前边说过当 "女孩 i" 和 "男孩 j"? 相遇时表示此次 "寻找" 结束。当 9 和 10 交换位置后就结束了本次排序工作,调整后的序列为:10 1 3 9。
- 紧接着仿照之前的 "二分" 法,左边的序列是 "10 1 3",以 10 为基准数,继续让 "女孩 i" 先出动,此时 "女孩 i" 已找不到比 10 更大的数了,只能被迫在 3 位置与?"男孩 j"? 相遇,调整后的序列为:3?1 10。
- 经过一番调整后,最终的序列顺序为:1 3 10 9。
- 看到这里相信大家已经明白,为什么 “以最左边的数为基准数,必须要让 "男孩 j" 先出动” 了吧。
- 如果让 "女孩 i" 先出动,排序的结果是不准确的!
总结
- 快速排序算法是冒泡排序的升级版,速度快、效率高,是处理大数据最快的排序算法之一。
- 最坏的情况下,快速排序就是冒泡排序,时间复杂度是O(
- 排序时,以最左边的数为基准数,必须要让 "男孩 j" 先出动。
- 当 "女孩 i" 和 "男孩 j" 相遇时,就说明此次 "寻找" 结束。
- 快速排序是基于 "二分法" 和 "递归调用" 来实现的。
- 递归函数,每次调用系统都会重新分配一个大小合适的栈帧来存储函数参数等信息。当前函数执行完毕并返回时,对应的栈帧会从栈顶弹出,返回到上一层函数的执行位置。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微服务的拆分规范和原则
- Spring之事务
- HCIA-Datacom题库(自己整理分类的)——其他网络协议【完】
- IDEA中怎么用Postman?这款插件你试试
- 江西速欣商务咨询有限公司:深度解析停息挂账,助您财务重启
- 有关quick bi中lod_include函数有多个过滤条件报错问题分析
- GEE机器学习——Classifier.explain()查看训练模型的过程和变量重要性分析
- Vue学习计划-Vue3--核心语法(九)slot插槽
- 小市值策略-单因子
- ssm/php/node/python基于的高校学生实习管理系统设计