消息中间件之Kafka(一)
1.简介
- 高性能的消息中间件,在大数据的业务场景下性能比较好,kafka本身不维护消息位点,而是交由Consumer来维护,消息可以重复消费,并且内部使用了零拷贝技术,性能比较好
Broker持久化消息时采用了MMAP的技术,Consumer拉取消息时使用的sendfile技术 - Kafka是最初由Linkedin公司开发,是一个分布式、支持分区(parition)、多副本的(replica),
基于Zookeeper协调的分布式消息系统,它最大的特性就是可以实时地处理大量数据以满足各种需求场景
比如:基于Hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写 - 吞吐量在10w~100w
2.模型设计图

3.特点
- 一个parition只能交给一个consumer消费,因为交给多个consumer让其进行poll拉取消息进行消费,会引起重复消费的问题
- 服务端(broker)和客户端(producer、consumer)之间通信通过TCP协议来完成
- Topic、Partition和Broker之间的关系.
一个topic,代表逻辑上的一个业务数据集,比如按数据库里不同表的数据操作消息区分放入不同topic,订单相关操作消息放入订单topic,用户相关操作消息放入用户topic,对于大型网站来说,后端数据都是海量的.订单消息很可能时非常巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可能会有容量限制问题,那么就可以在topic内部划分多个partition来分片存储数据,不同的parition可以位于不同的机器上,每台机器上都运行一个Kafka的进程Broker - 同时未发布和订阅提供高吞吐量,Kafka的设计目标是以时间复杂度O(1)的方式提供消息持久化能力的,即使对TB级别以上数据也能保证常数时间的访问性能,即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
- 消费消息采用Pull模式,消息被处理的状态是在Consumer端维护的,而不是由服务端维护,Broker无状态,Consumer自己保存offset
4.核心组件
- Topic:Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
- Parition:物理上的概念,一个topic可以分为多个partition,每个partition的内部时有序的
- Broker: 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
- ConsumerGroup: 每个Consumer属于一个特定的ConsumerGroup,一条消息可以被多个不同的ConsumerGroup消费,到那时一个ConsumerGroup中只能有一个Consumer能够消费该消息
- Consumer:消息消费者,从Broker读取消息的客户端
- Producer: 消息生产者,向Broker发送消息的客户端
5.设计机制
5.1 Kafka核心总控制器Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),
它负责管理整个集群中所有分区和副本的状态
1.当某个分区的leader副本出现故障时,由控制器负责为该分区选举出新的leader副本
2.当检测到某个分区的ISR(In-Sync-Replica)集合发生变化时,由控制器负责通知所有的broker更新元数据信息
3.当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到
5.1.1 Controller选举机制
在Kafka集群启动的时候,会自动选举以太broker作为controller来管理整个集群,
选举的过程时集群中每个broker都会尝试在zookeeper上创建一个/controller的临时节点,
zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控制器controller
当这个controller角色的broker宕机了,此时zookeeper临时节点就会消失,集群里其他broker
会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,这就是我们说的选举机制,zookeeper又会保证有一个broker成为新的controller
5.2 Partition副本选举Leader机制
controller感知到分区Leader所在的broker挂了(controller监听了很多zk节点可以感知到broker存活)
controller会从ISR(In-sync replica)列表(参数unclean.leader.election.enable=false)里挑第一个broker作为leader(第一个broker最先放进ISR列表,
可能时同步数据最多的副本)
如果参数unclean.leader.election.enable为true,代表ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选leader
这种设置,可以提高可用性,但是选出的新leader有肯恩那个数据少很多,
副本进入ISR列表有两个条件:
1.副本节点不能那个产生分区,必须能与zk保持会话以及跟leader副本网络连通
2.副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步之后的副本,是由replica.lag.time.max.ms配置决定的,超过
这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
5.3 消费者消费消息的offset记录机制
每个consumer会定期将自己消费分区的offset提交给kafka内部topic:_consumer_offsets,
提交过去的时候,key时consumerGroupId+topic+分区号,value就是当前offset的值,
kafka会定期清理topic里的消息,最后就保留最新的那条数据,因为_consumer_offset可能会接收高并发的请求,
kafka默认给其分配50个分区(可以通过offsets.topic.num.paritions设置),这样可以通过加机器的方式抗大并发
5.4 消费者的rebalance机制
rebalance就是说如果消费组里的消费者数量有变化或者消费的分区数有变化,fafka会重新分配消费者消费分区的关系,比如consumer group中某个消费者挂了,此时会自动把分配给它的分区交给其他的消费者,如果它又重启了,那么,又会把一些分区重新交还给他
注意:relablance只针对subscribe这种不指定分区消费的情况,如果通过assign这种消费方式指定了分区,kafka不会进行rebalance,如下情况可能会触发消费者realance:
1.消费组里的consumer增加或减少了
2.动态给topic增加了分区
3.消费者组订阅了更多的topic,rebalance过程中,消费者无法从kafka消费消息,这对kafka的TPS会有影响,如果kafka集群内节点较多,比如数百个,那rebalance可能会耗时极多,所以尽量避免在系统高峰期的rebalance发生
5.5 producer发布消息机制
1.写入方式
producer采用push模式将消息发布到broker,每条消息都被append到partition中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)
2.消息路由
producer发送消息到broker时,会根据分区算法选择将其存储到哪一个partition,路由机制为:
2.1 指定了partition,则直接使用
2.2 未指定partition但指定key,通过对key的value进行hash选出一个partition
2.3 partition和key都未指定,使用轮询选出一个partition
3.写入流程
3.1 producer先从zookeeper的/brokers/…/state/节点找到该partition的leader
3.2 producer消息发送给该leader
3.3 leader将消息写入本地log
3.4 followers从leader pull消息,写入本地log后向leader发送ACK
3.5 leader收到所有的ISR中的replica的ACK后,增加HW(high watermark,最后commit的offset)并向producer发送ACK
5.6 HW与LEO机制
5.6.1
HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offse)作为HW,consumer最多只能消费到HW所在的位置,另外每个replica都有HW,leader和follower各自负责更新自己的状态.,对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replica同步后更新HW,此时消息才能被Consumer消费,这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取,对于来自内部broker的读取请求,没有HW的限制
5.6.2
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种方式极大的影响了吞吐率。而异步复制的方式下,follower异步的从leader复制数据,数据只要被,leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据,而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率,还可以设置消息发送端对于发出消息持久化机制参数acks的设置
5.6.3 模型图解释

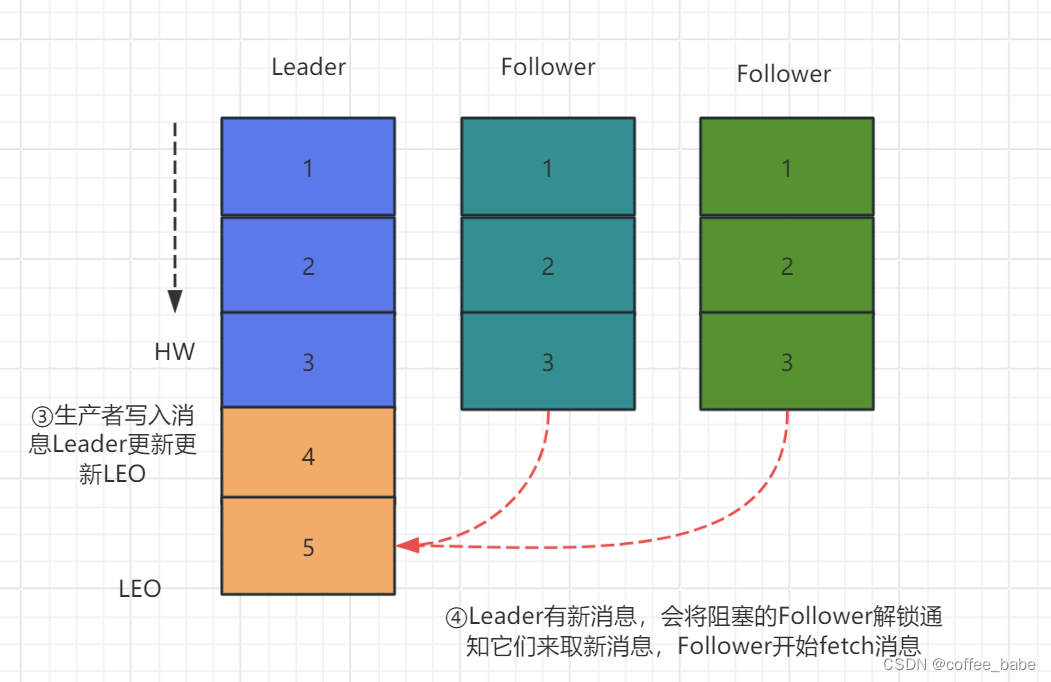
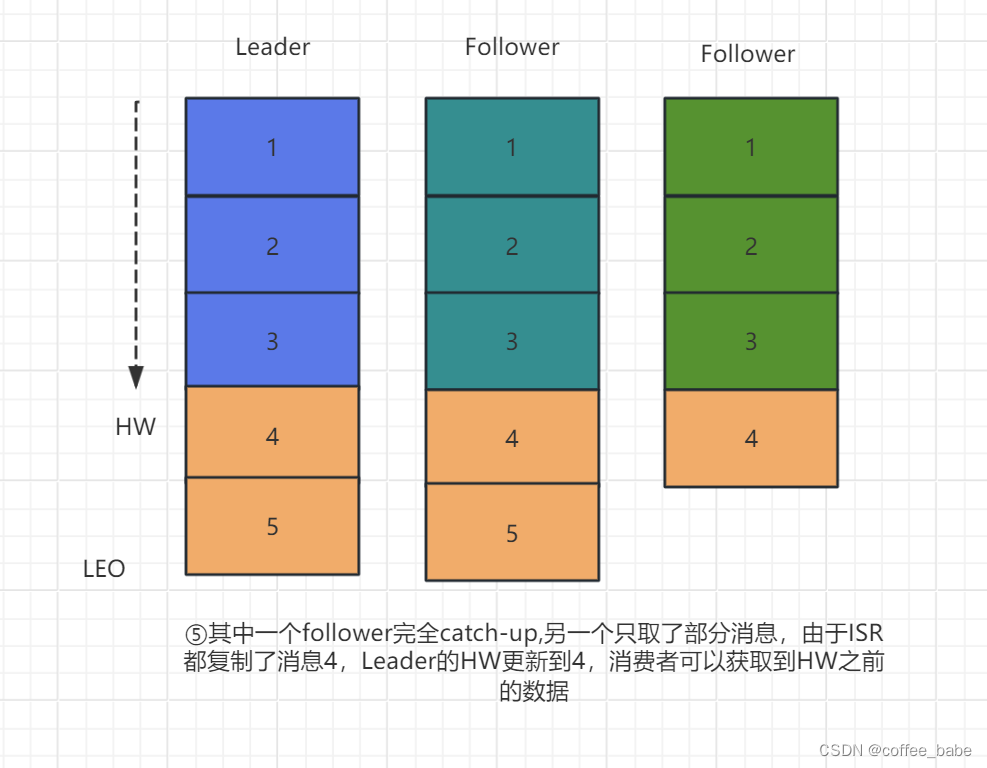
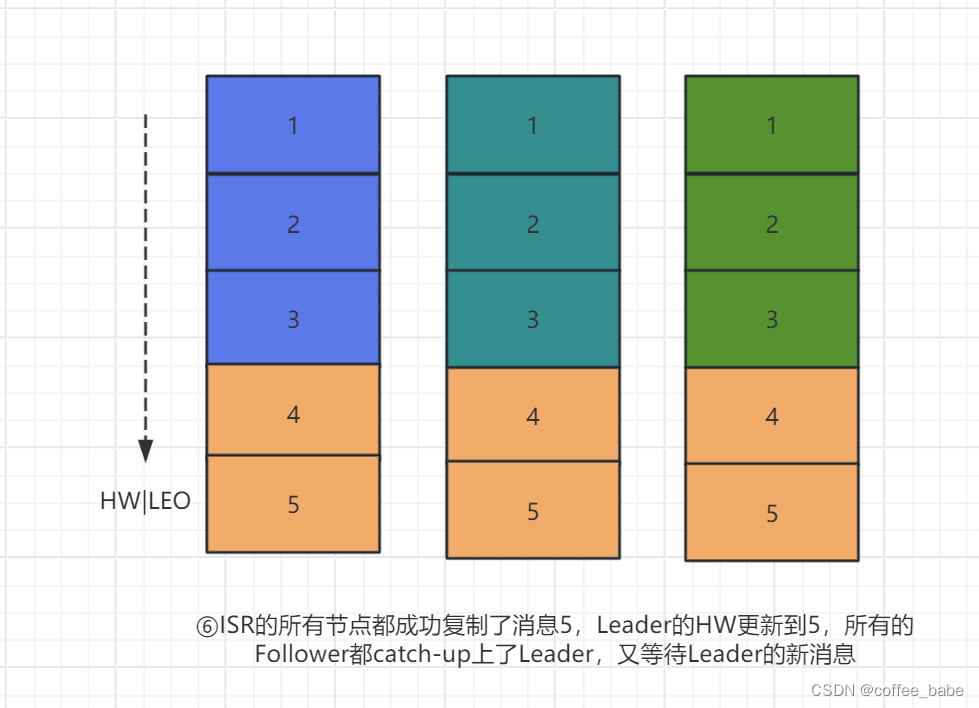
5.7 日志分段存储
5.7.1
Kafka一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(Segment)存储,
每个段的消息都存储在不一样的log文件里,这种特性方便old segment file快速被删除,kafka规定了一个段位的log文件
最大为1G,做这个限制的目的是为了方便把log文件加载到内存去操作
5.7.2 文件类型
- index文件:部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index中,如果要定位消息的offset会在这个文件里快速定位,再去log文件里找具体消息
00000000000000000000.index - log文件:消息存储文件,主要存offset和消息体 00000000000000000000.log
- timeindex文件: 消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息的发送时间戳与对应的,offset到timeindex文件,如果需要按照时间来定位消息的offset,会先在这个文件里找
00000000000000000000.log
5.7.3
KafkaBroker有一个参数,log.setgment.bytes,限定了每个日志段文件的大小,最大就是1GB.
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做log rolling,正在被写入的那个日志段文件,叫做active log segment
5.8 消费模式
- 集群消费: 一个ConsumerGroup中,只能有一个消费者消费消息
- 广播消费:一个ConsumerGroup中,每个消费者都可以消费到消息
6.线上规划
6.1概要设计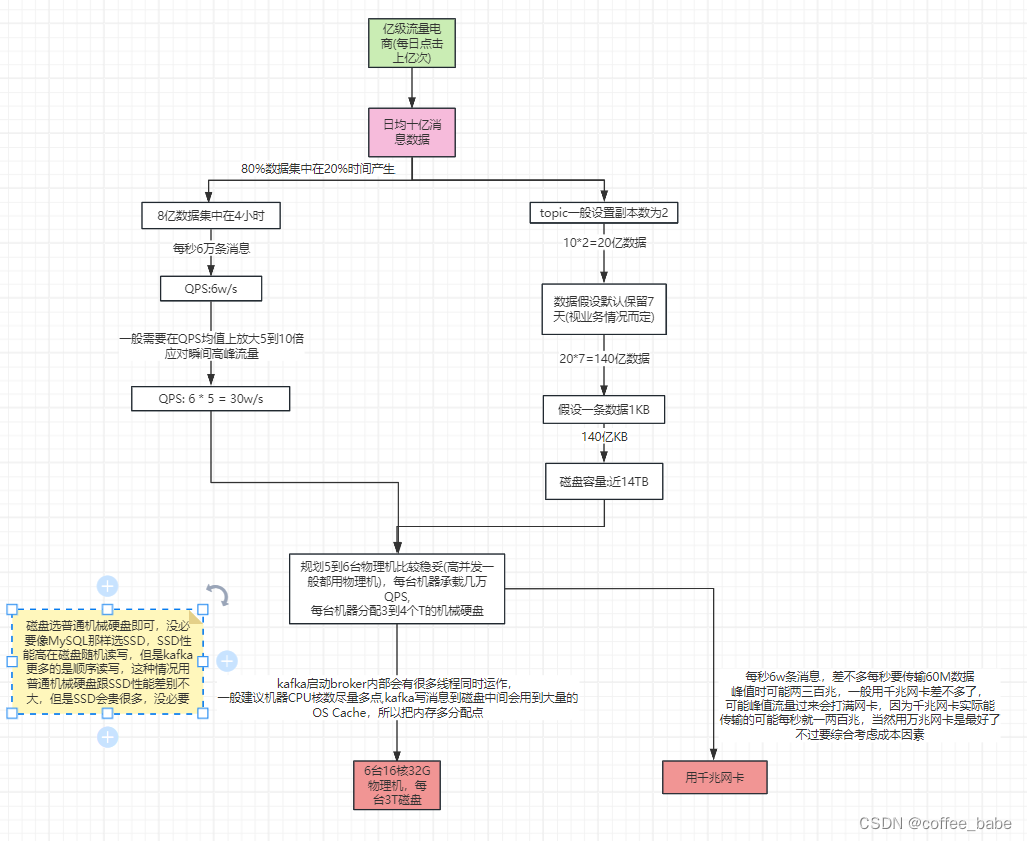
6.2 JVM参数设置
export KAFKA_HEAP_OPTS="-Xmx16G
-Xms16G -Xmn10G -XX:MetaspaceSize=256M
-XX:+UseG1GC -XX:MaxGCPauseMillis=50
-XX:G1HeapRegionSIze=16M"
Kafka是由Scala语言开发,运行在JVm上,需要对JVM参数合理设置
修改/bin/kafka-start-server.sh中的jvm设置,假设机器是32G内存,可进行如上设置:
这种大内存的情况一般都要用G1垃圾收集器,因为年轻代内存比较大,用G1可以设置GC最大停顿时间,不至于一次minor gc就花费太长时间,当然,因为像Kafka、RocketMQ ES这些中间件,写数据到磁盘会用到操作系统的Page Cache,所以JVM内存不宜分配过大,需要给操作系统的缓存预留出几个G
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 手把手教你学会接口自动化系列十四-如何用python操作excel的sheet自动化测试之前的准备工作
- uni-app中代理的两种配置方式
- C#下将点云数据保存为PLY格式
- PyQt5 QFileDialog 详解
- 08 通信协议之UART
- 万辰集团十年经营首度亏损,泡沫式增长是喜是忧?
- 第7章-第6节-Java中的Map集合
- 反射UnityEditor.GameView设置GamePlayMode分辨率
- 火爆!大厂流出的接口版本号规约,速度收藏
- 配网行波故障定位与预警装置_工作原理_精确定位|深圳鼎信