webhub123算法工程师的大语言模型LLM技术路线
我们整理了当前认可度最高的一套 大语言模型LLM技术研究资料集合,整理到
已经按照不同阶段做好了分组,点击每个卡片即可访问对应的论文和博客,方便您对技术由全局视图

1 大语言模型架构
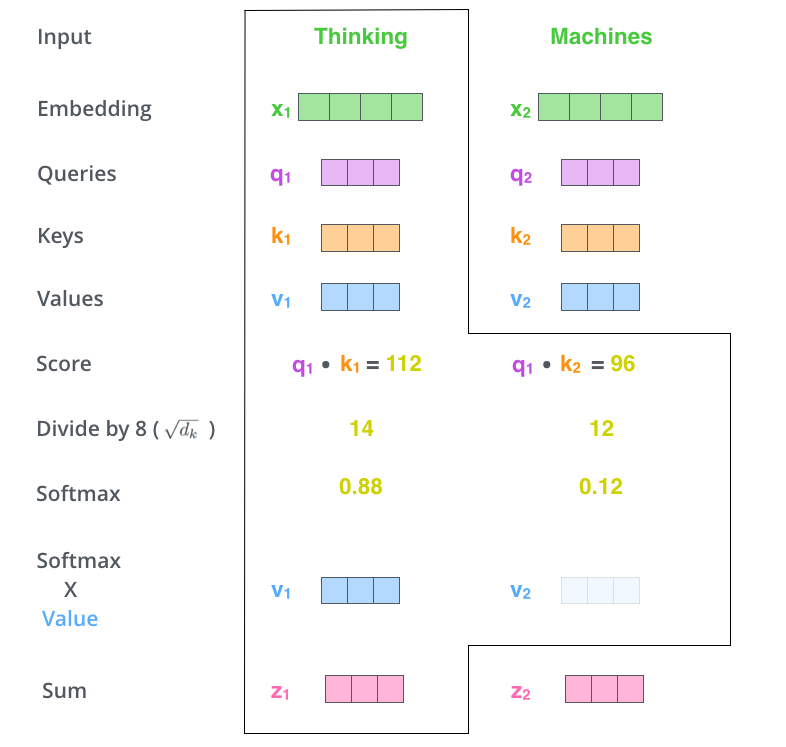
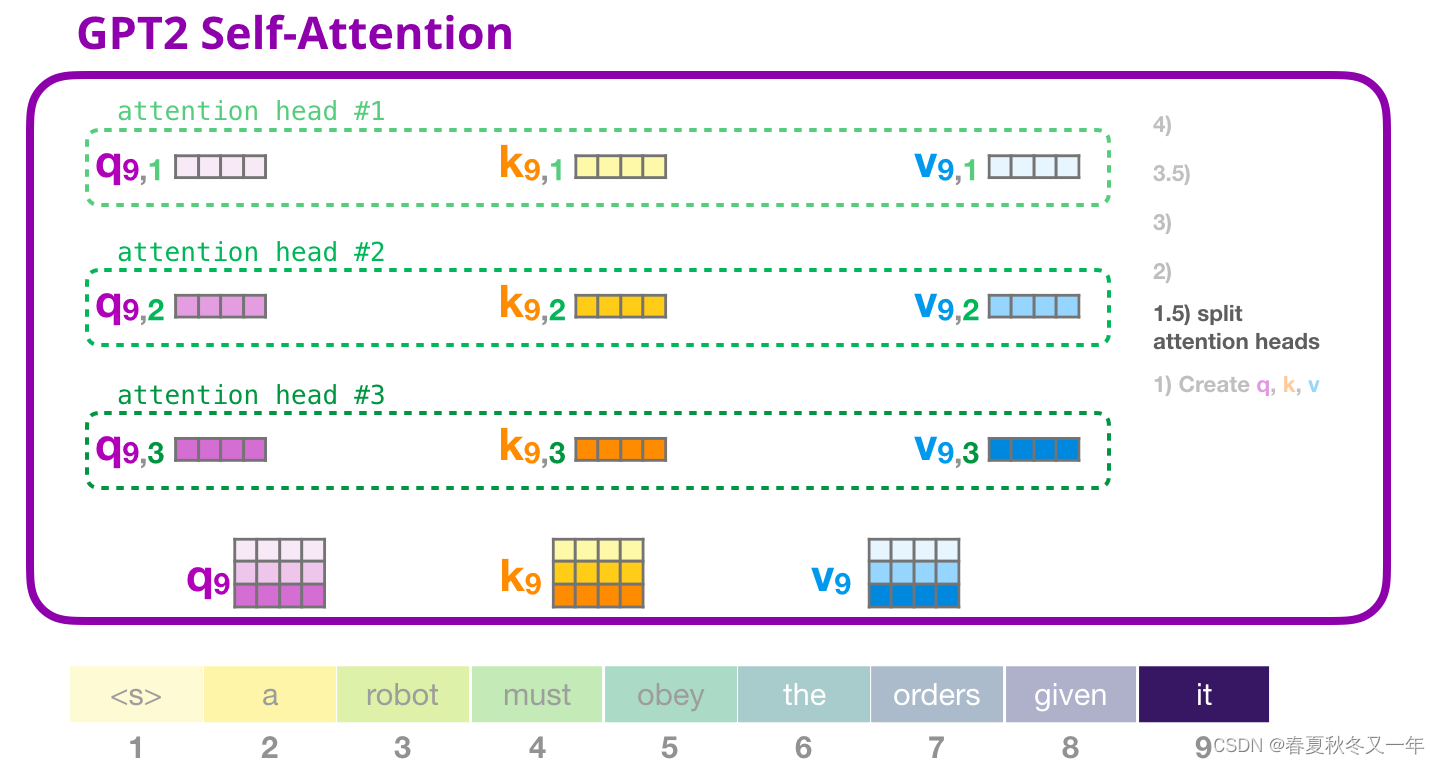
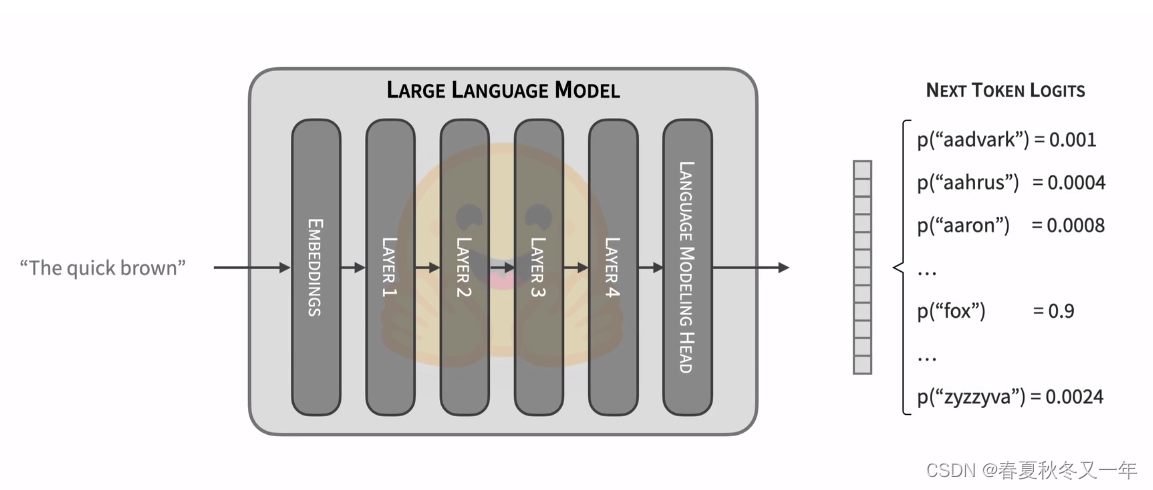
3D可视化各种大语言模型 这里可视化了大语言模型的网络结构,包括GPT-2,GPT-3,Nano-GPT,界面不能切换视角,只能放大缩小。
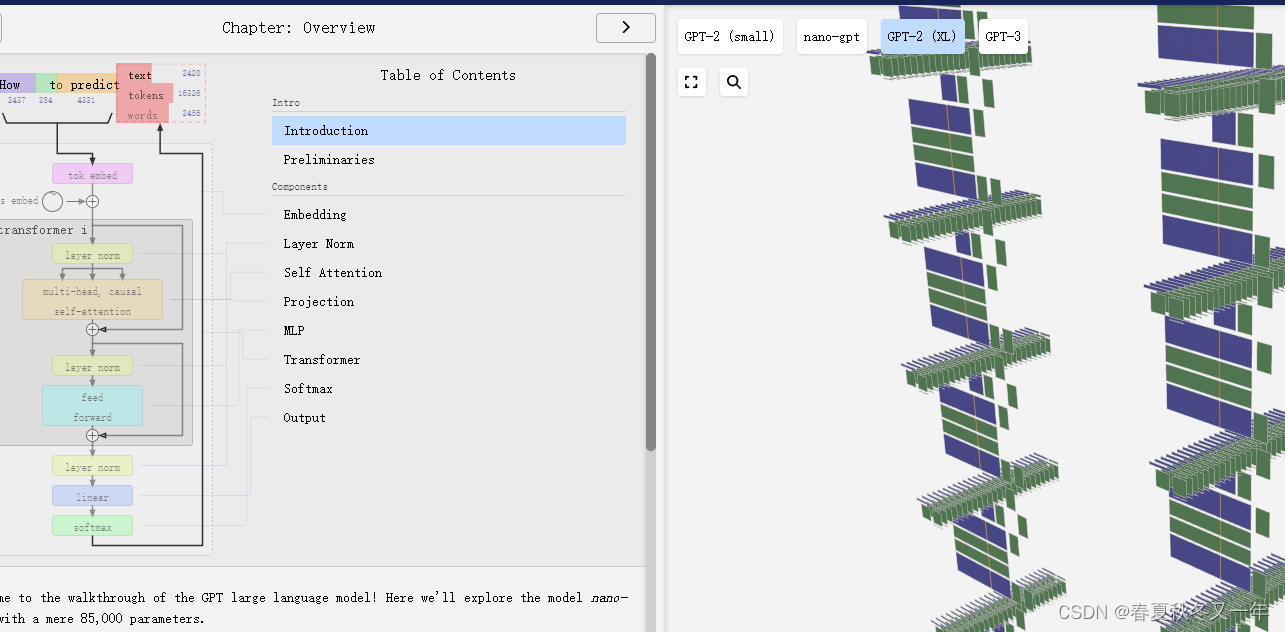
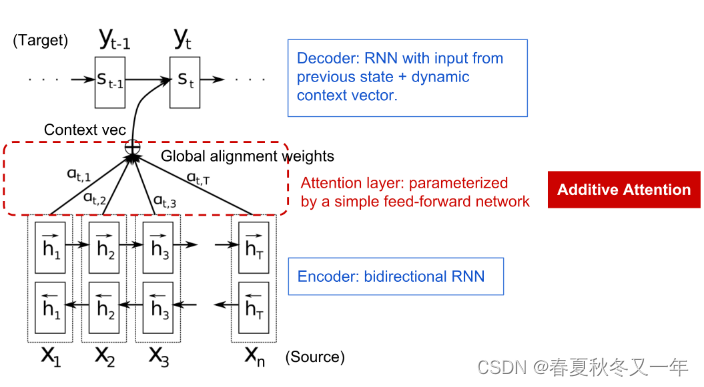

B 站 Andrej Karpathy 从头开始实现一个 GPT 视频有2个小时,由 Andrej Karpathy 一步一步构建一个简单的GPT模型。这里展示的是nanoGPT
2 准备指导数据集
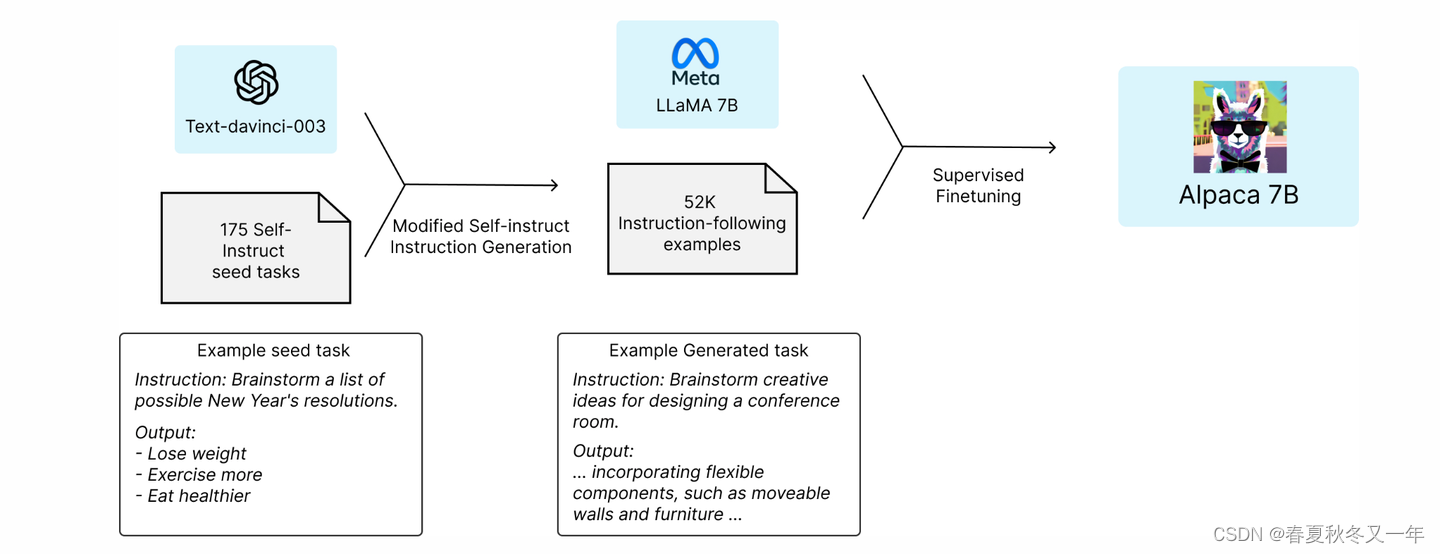
Alpaca 和 Alpaca-GPT4 指导数据集的准备过程 文章直接上代码了,讲解的较少。


google colab 代码展示如何创建微调LLM的数据集
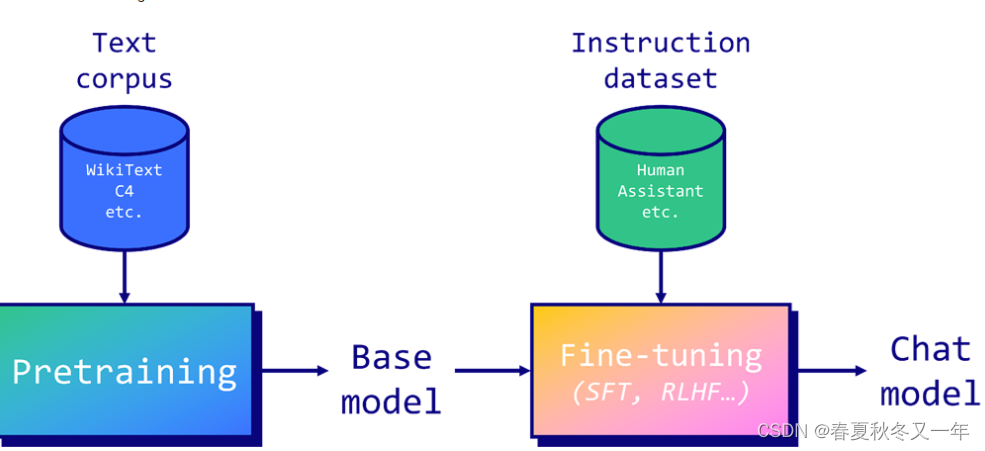

3 预训练模型
训练LLM可用的数据集 包含了一些开源可用的,预训练的、微调的、RLHF的数据集
huggingface 使用transformers 库从头训练一个GPT-2预训练模型
TinyLlama 从头训练一个小的羊驼模型 帮助你理解如何从头训练LLama模型
huggingface 因果语言模型和mask的语言模型以及如何微调DistilGPT-2模型


meta 训练一个175B参数的LLM的实验日志 它记录了整个训练过程遇到的所有问题,以及处理方案,这个PDF有114页,详细记录了整个训练过程的操作。如果你也要训练大模型,可以参考。

llm360 开源的LLM框架 包含LLM 数据准备、模型训练、参数评估等所有流程

4 监督微调
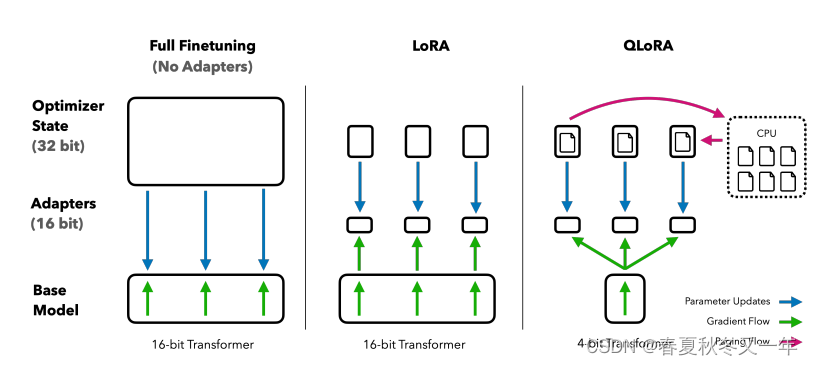
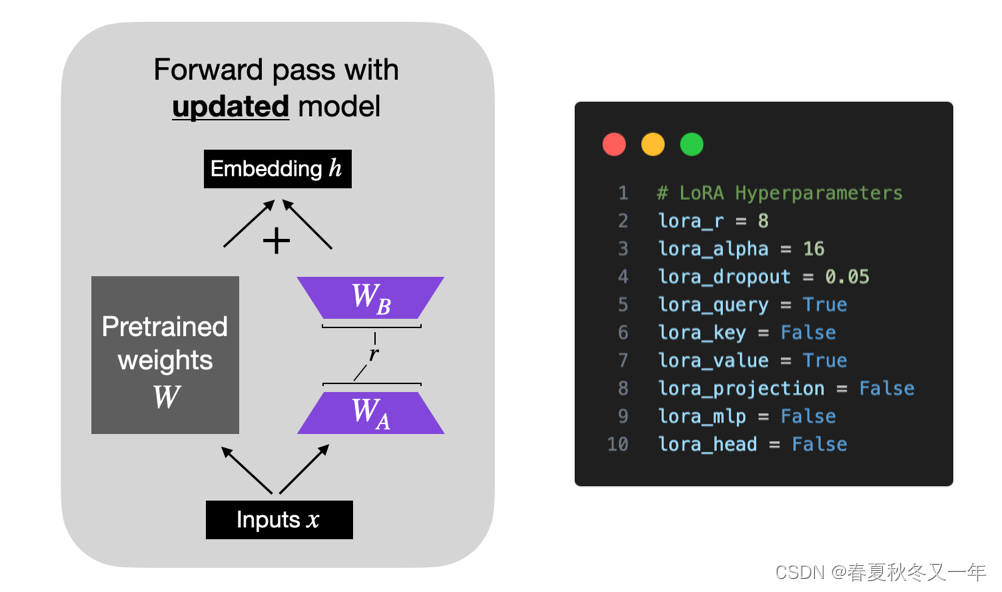
Lora 基于low-rank adapters 只训练部分低秩的adapters,无需训练所有参数。

QLora 高效训练LLM 在4Bit量化模型权重
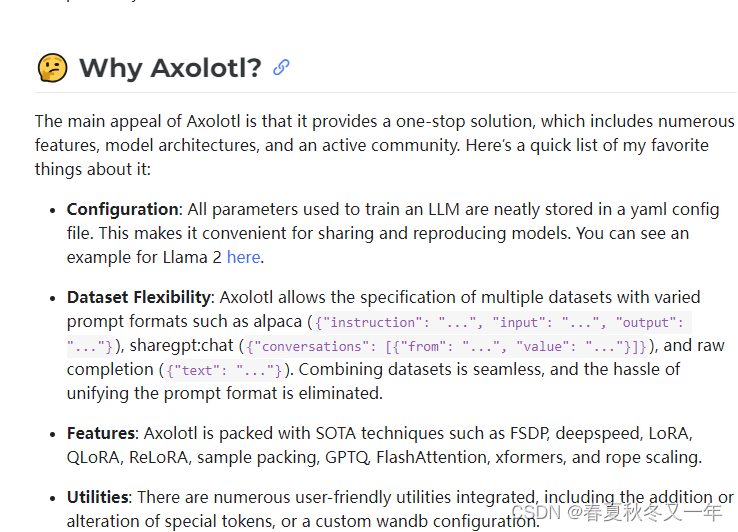
axolotl 开源的LLM微调工具,很多开源大语言模型都在使用


Lora最佳实践以及如何选择参数 作者总结了几百次的Lora实验经验

5 从人类反馈来做强化学习RLHF
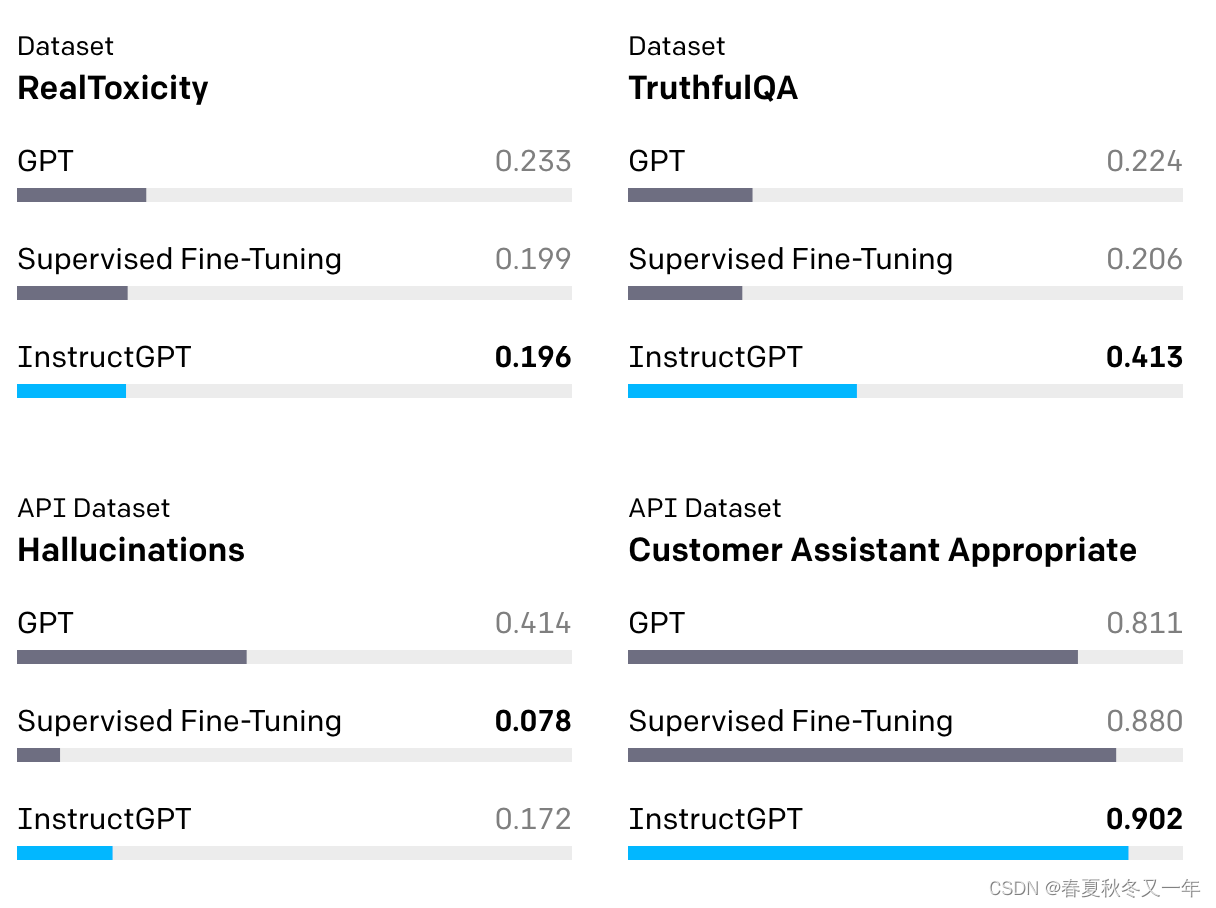
arxiv 论文 Proximal Policy Optimization Algorithms 近端策略优化算法,使用一个奖励函数来预测给定文本是否会被人类排序靠前。
arxiv: Direct Preference Optimization: Your Language Model is Secretly a Reward Model 将预测问题变成了分类问题。使用了一个引用模型而非奖励模型,进而只需要一个超参数。变得更加稳定高效。
huggingface 使用奖励模型训练,强化学习微调LLM
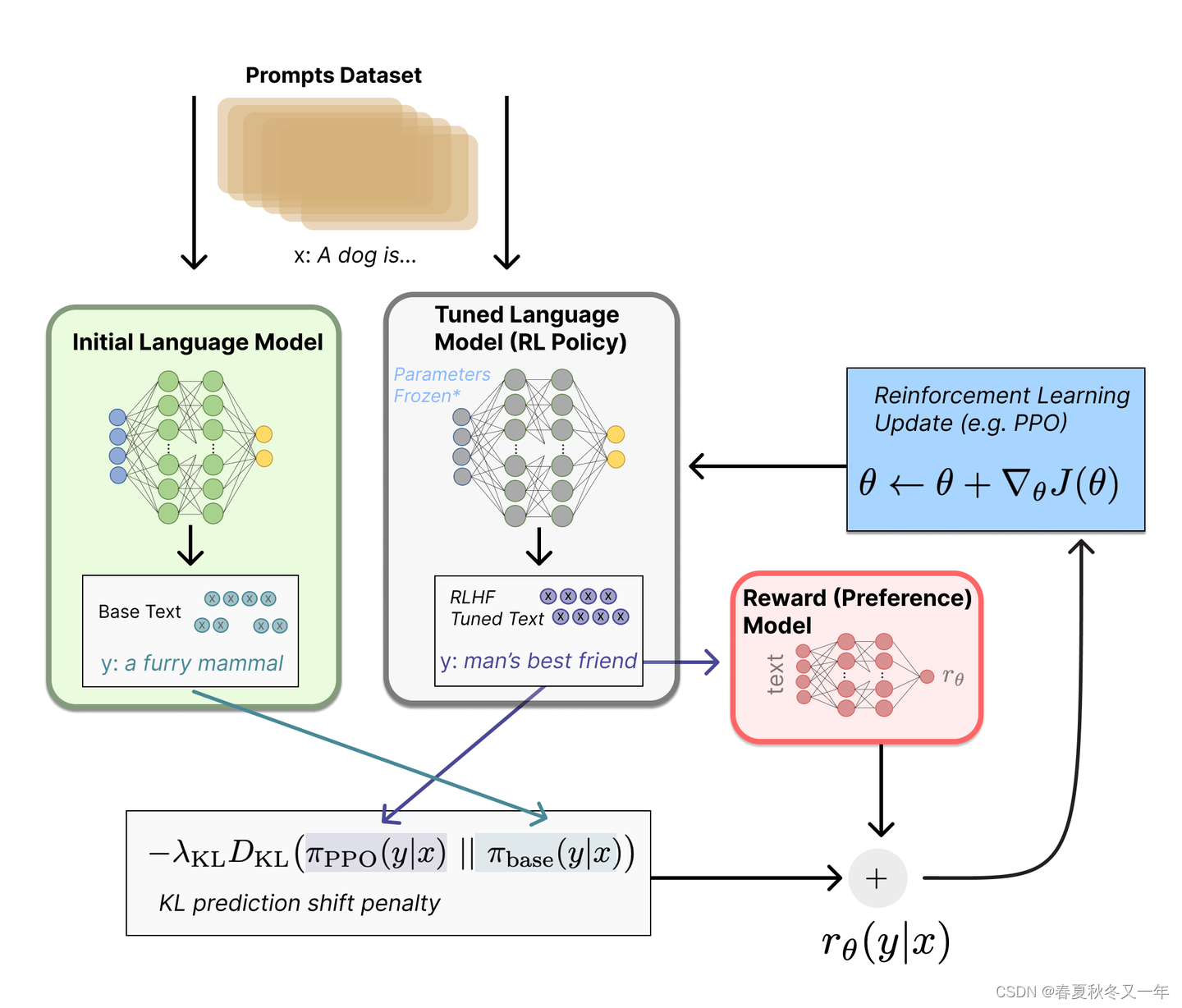
“StackLLaMA”: 用 RLHF 训练 LLaMA 的手把手教程
LLM Training: RLHF and Its Alternatives 介绍了RLHF和其他替代方案
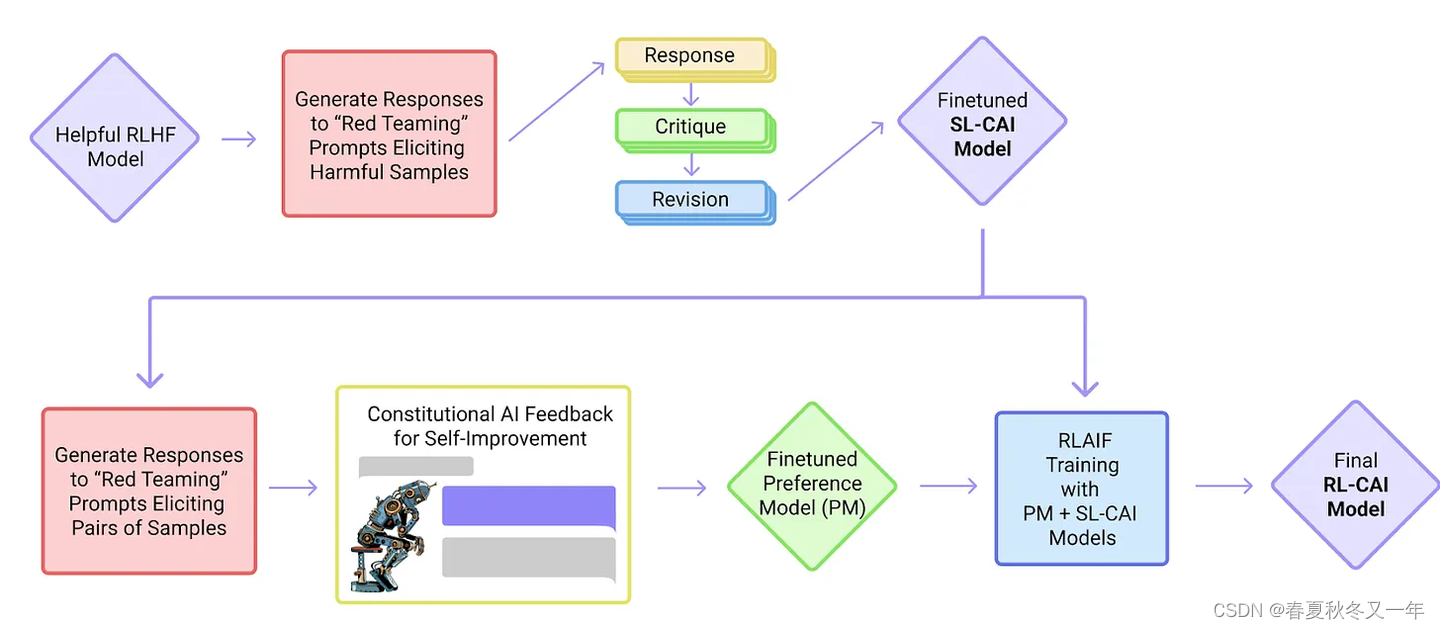
6 模型评估
Github EleutherAI 开源的LLM评估框架


towardsdatascience 评估NLP任务中的文本输出BLEU评分
arxiv 论文:中科大、微软亚洲研究院等 评估LLM调查报告
7 量化
量化模型是将模型中的高精度浮点数转化成低精度的int或其他类型得到的新的,花销更小,运行更快的模型。
llama.cpp meta的LLama模型的c/c++接口 llama.cpp 运行期占用内存更小,推断速度也更快,同样的模型,7B 基础模型举例,32位浮点数的模型占用空间 27G,llama.cpp 量化后占用内存 9G 左右,推断速度为15字/秒。
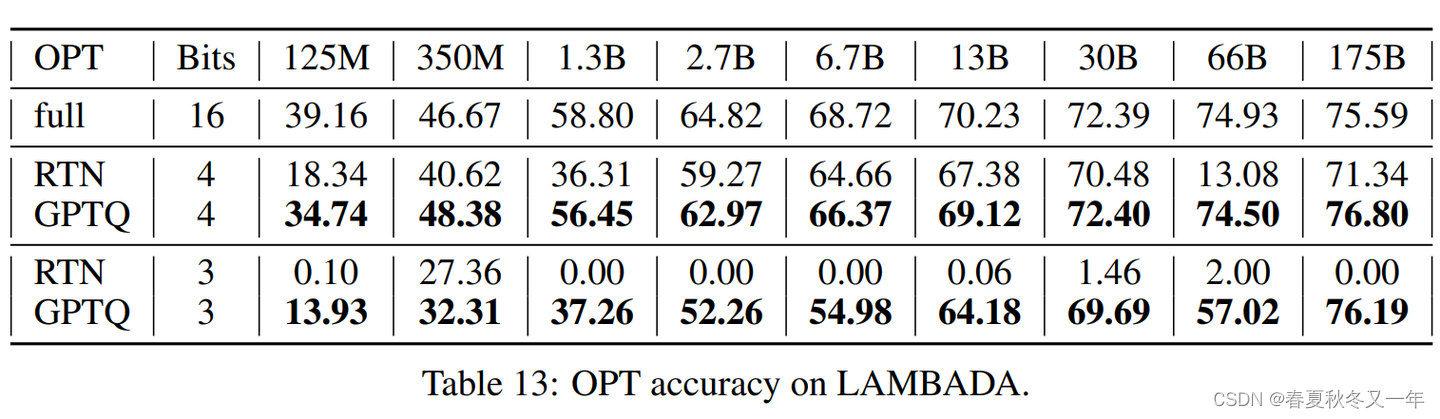
GPTQ 量化技术 arxiv论文 一种后训练量化方法,相比其他后训练量化方法可以有效的处理10亿参数以上的模型。他基于Hessian matrix(海森矩阵)完成模型量化,而非常见的基于统计的方法。
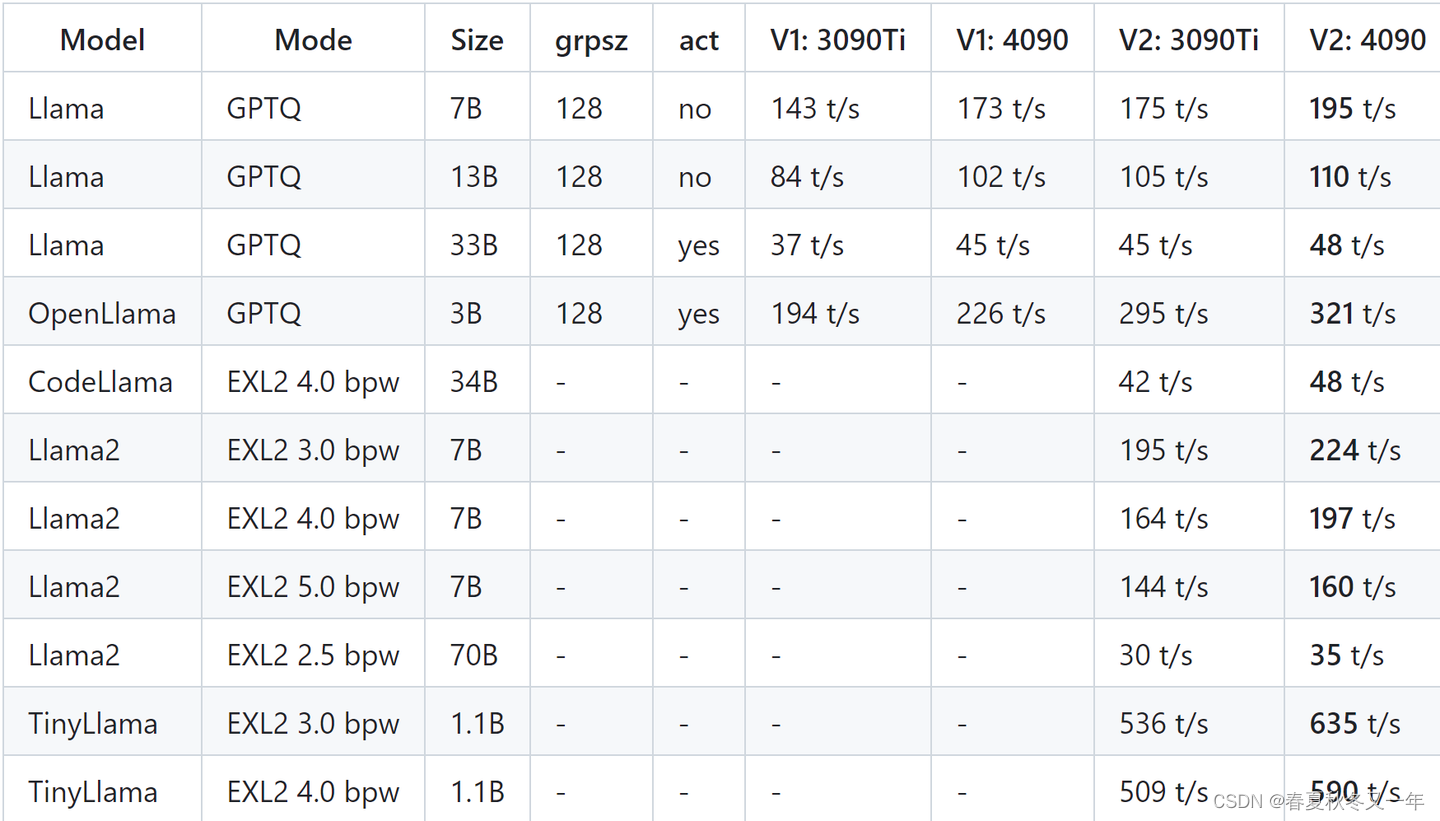
mlabonne系列: 使用ExLlamaV2库量化Mistral更快执行LLM
mlabonne系列: 使用GGUF和llama.cpp量化llama模型
medium博客: 理解Activation-Aware Weight(AWQ)量化技术

8 推理优化
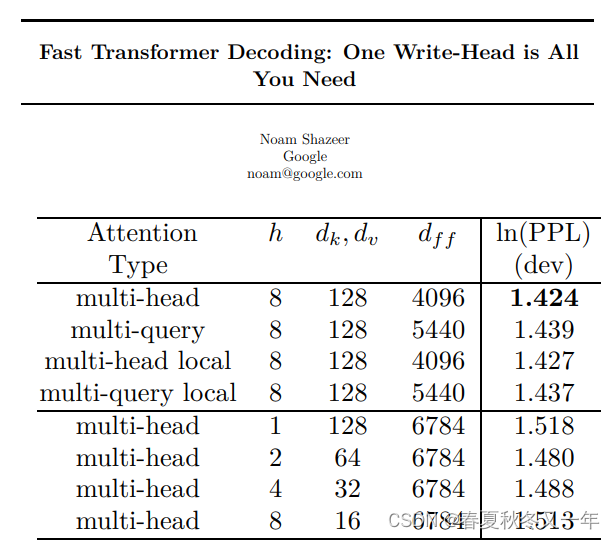
Fast Transformer Decoding: Multi-Query Attention技术论文
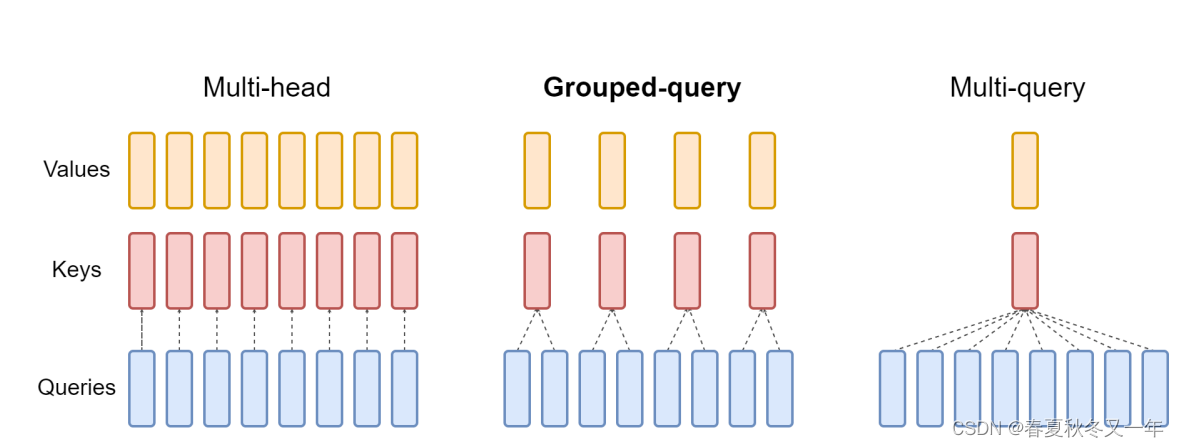
google arxiv论文: Grouped-Query Attention (GQA)
追一科技: transformers中的位置编码 RoPE技术论文
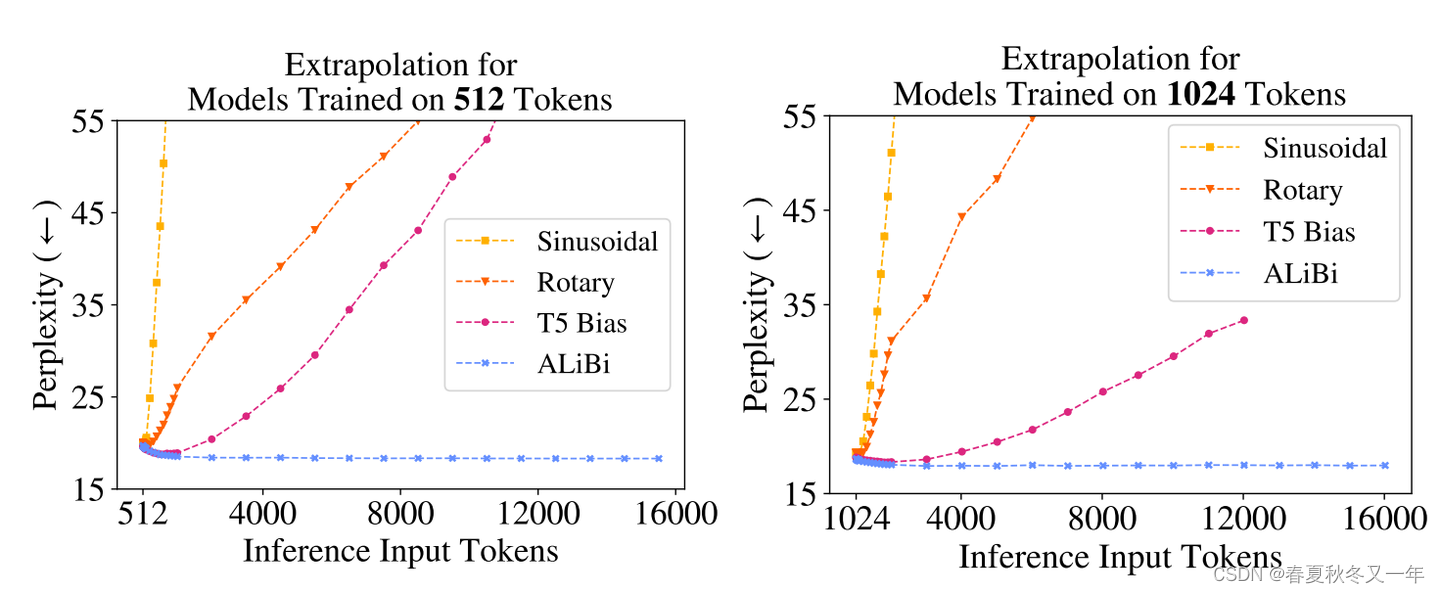
AliBi:使用了线性biases的attention以增强输入文本长度
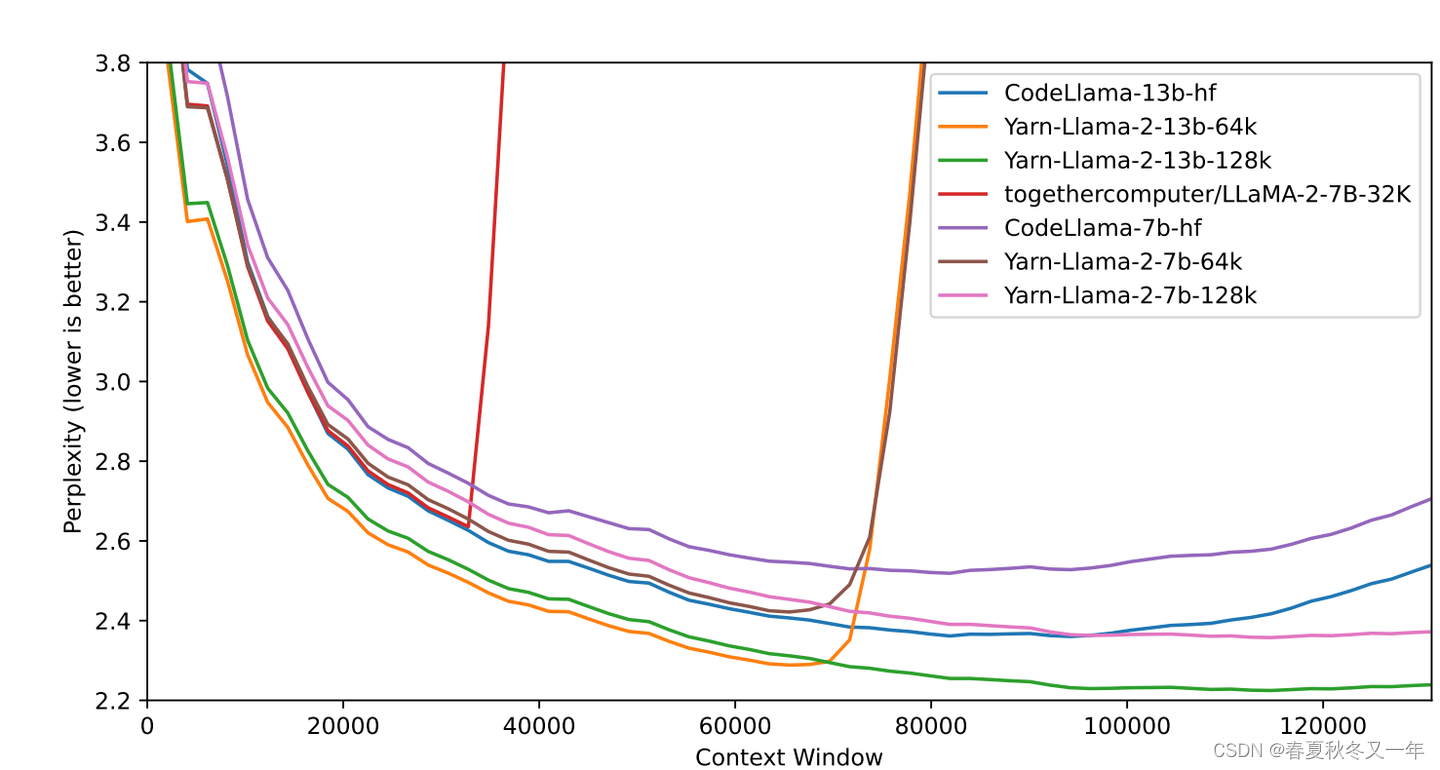

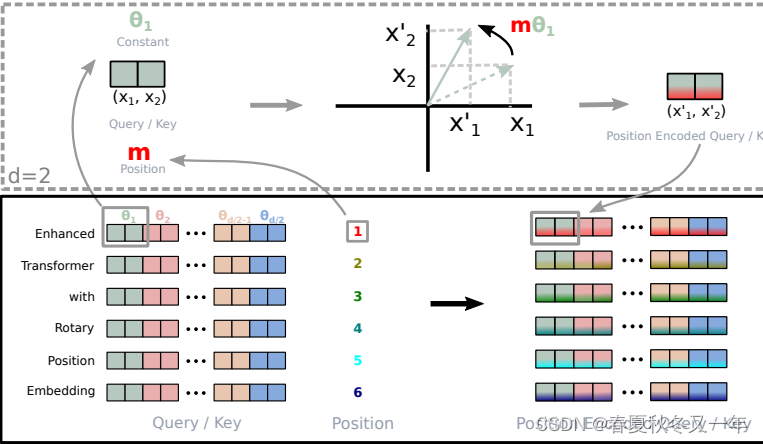
eleuther ai的技术博客: RoPE的拓展 Rotary Position Embedding

LLM中拓展上下文的技术总结 这个博客总结了很多LLM中使用的上下文拓展技术,分析了难点和解决方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于人工蜂群算法优化的Elman神经网络数据预测 - 附代码
- computed和watch和watchEffect 相同和不同
- 网络通信(4)-数据链路层解析
- vite 打包二级目录记录
- 【Oracle数据库】两个服务端通过一个端口分别读写两个数据库账户下的表
- MyBatis中延迟加载,全局和局部的开启使用与关闭
- LeetCode-Z 字形变换(6)
- C++内存布局(一)
- ip数据库.
- 打破枯燥工作日,用Python统计键盘和鼠标点击次数,钉钉告诉你今天摸鱼了多少次!