Transformer架构和对照代码详解
1、英文架构图
下面图中展示了Transformer的英文架构,英文架构中的模块名称和具体代码一一对应,方便大家对照代码、理解和使用。

2、编码器
2.1 编码器介绍
? ? ? ? 从宏观?度来看,Transformer的编码器是由多个相同的层叠加? 成的,每个层都有两个?层(?层表?为sublayer)。第?个?层是多头?注意?(multi-head self-attention) 汇聚;第?个?层是基于位置的前馈?络(positionwise feed-forward network)。
? ? ?具体来说,在计算编码器 的?注意?时,查询、键和值都来?前?个编码器层的输出。受 7.6节中残差?络的启发,每个?层都采?了残差连接(residual connection)。在Transformer中,对于序列中任何位置的任何输?x ∈ R d,都要求满 ?sublayer(x) ∈ R d,以便残差连接满?x + sublayer(x) ∈ R d。在残差连接的加法计算之后,紧接着应?层 规范化(layer normalization)。因此,输?序列对应的每个位置,Transformer编码器都将输出?个d维表?向量。
2.2 编码器中各模块的实现
2.2.1 Positionwise FNN实现(对照架构图中的Positionwise FNN组件)
? ? ? ? 基于位置的前馈?络(Positionwise FNN)对序列中的所有位置的表?进?变换时使?的是同?个多层感知机(MLP),这就是称前馈?络是基于位置的(positionwise)的原因。在下?的实现中,输?X的形状(批量??,时间步数或序列 ?度,隐单元数或特征维度)将被?个两层的感知机转换成形状为(批量??,时间步数,ffn_num_outputs) 的输出张量。
代码:
#@save
class PositionWiseFFN(nn.Module):
"""基于位置的前馈?络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))代码解释:?
这段代码是用PyTorch框架定义的一个类 PositionWiseFFN,它是一个基于位置的前馈神经网络(Position-wise Feed-Forward Network),通常用于Transformer架构中。此类实现了一个简单的两层全连接神经网络,每一层后接ReLU激活函数。
代码解释:
类定义:
class PositionWiseFFN(nn.Module):
"""基于位置的前馈?络"""
这里定义了一个名为 PositionWiseFFN 的类,该类继承自 PyTorch 中的 nn.Module 类,这是构建神经网络模块的基础类。
初始化方法 __init__:
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
初始化时,通过 super().__init__(**kwargs) 调用了父类 nn.Module 的初始化方法。
定义了两个线性层(全连接层):self.dense1 和 self.dense2。dense1 输入维度为 ffn_num_input,输出维度为 ffn_num_hiddens;dense2 输入维度与隐藏层输出维度相同,即 ffn_num_hiddens,输出维度为 ffn_num_outputs。
同时定义了一个ReLU激活函数 self.relu,在前馈过程中将被应用在线性层之间。
前向传播方法 forward:
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
在这个方法中,定义了输入数据 X 经过模型的处理流程。首先,X 通过第一个线性层 self.dense1 计算输出。
然后,对线性层的输出应用ReLU激活函数 self.relu 进行非线性变换。
最后,将ReLU激活后的结果送入第二个线性层 self.dense2 进行计算,得到最终的输出。
总结来说,这个类实现了 Transformer 中的一个基本单元——位置感知前馈神经网络,其结构为:输入 -> Linear -> ReLU -> Linear -> 输出。这个模块应用于每个位置上的输入特征上,独立地进行计算并增加非线性表达能力。2.2.2 Add & norm组件的实现
? ? ? ?现在我们关注架构图中的加法和规范化(Add & norm)组件。正如在本节开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
? ? ? ?层规范化和批量规范化:后续将解释在?个?批量的样本内基于批量规范化对数据进?重新中?化和重新缩放的调整。层规范化和批量规范化的?标相同,但层规范化是基于特征维度进?规范化。尽管批量规范化在计算机视觉中被?泛 应?,但在?然语?处理任务中(输?通常是变?序列)批量规范化通常不如层规范化的效果好。?
现在可以使?残差连接和层规范化来实现AddNorm类。暂退法也被作为正则化?法使?。
代码:
class AddNorm(nn.Module):
"""残差连接后进?层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)代码解释:
这段代码定义了一个名为 AddNorm 的类,该类继承自 PyTorch 中的 nn.Module 类。这个类在Transformer架构中实现了一个残差连接(Residual Connection)与层规范化(Layer Normalization)相结合的模块。
代码解释:
类定义:
python
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
这个类表示一个神经网络模块,其功能是在执行层规范化操作之前先进行残差连接。
初始化方法 __init__:
python
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
初始化时,调用父类 nn.Module 的初始化方法。
定义了一个 dropout 层,使用了给定的 dropout 参数来控制随机失活的比例。
创建了一个 nn.LayerNorm 对象,用于对指定维度大小(normalized_shape)的数据进行层规范化处理。
前向传播方法 forward:
python
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
在 forward 方法中,模型接收两个输入变量 X 和 Y。
先将输入 Y 通过 dropout 层,以一定概率丢弃部分激活值,从而增加模型的泛化能力。
将经过 dropout 操作后的 Y 与原始输入 X 相加,实现残差连接,允许信息直接从上一层传递到下一层。
最后,将相加的结果送入 self.ln 即 Layer Normalization 层进行规范化处理,确保每一层的输出具有稳定的分布,有利于梯度传播和训练过程。
所以,整个 AddNorm 模块的作用是首先对输入 Y 进行可能的随机失活,然后将其与另一个输入 X 做残差连接,并对结果应用层规范化,这是Transformer模型中常见的结构之一。2.2.3 Multi-head attention组件的实现
? ? ? 在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意?机制学习到不同的? 为,然后将不同的?为作为知识组合起来,捕获序列内各种范围的依赖关系(例如,短距离依赖和?距离依 赖关系)。因此,允许注意?机制组合使?查询、键和值的不同?空间表?(representation subspaces可能是有益的。
? ? ? ?为此,与其只使?单独?个注意?汇聚,我们可以?独?学习得到的h组不同的 线性投影(linear projections) 来变换查询、键和值。然后,这h组变换后的查询、键和值将并?地送到注意?汇聚中。最后,将这h个注意 ?汇聚的输出拼接在?起,并且通过另?个可以学习的线性投影进?变换,以产?最终输出。这种设计被称 为多头注意?(multihead attention)。对于h个注意?汇聚输出,每?个注意?汇聚都 被称作?个头(head)。下图 展?了使?全连接层来实现可学习的线性变换的多头注意?。
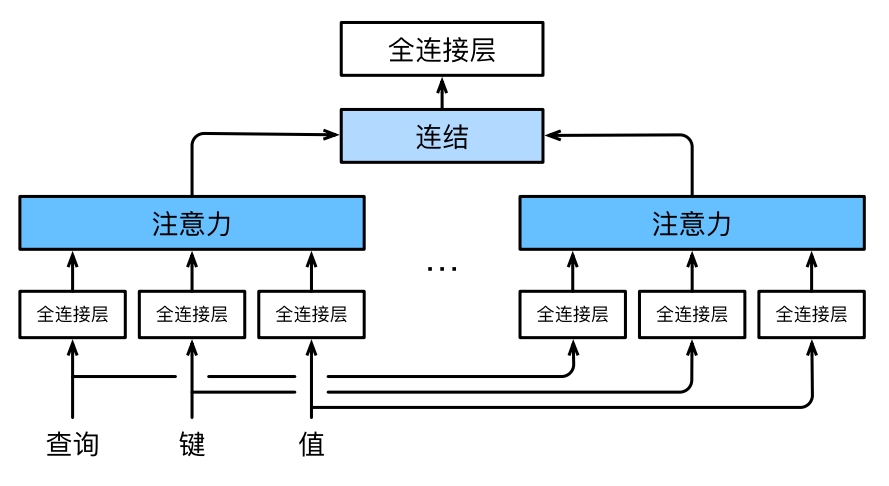
图?多头注意?:多个头连结后做线性变换?
? ? ? 模型:? ? ?
? ? ? ?在实现过程中通常选择缩放点积注意?作为每?个注意?头。为了避免计算代价和参数代价的?幅增?,我 们设定。值得注意的是,如果将查询、键和值的线性变换的输出数量设置为
,则可以并?计算
个头。在下?的实现中,
是通过参数num_hiddens指定的。
? ? ?代码:
#@save
class MultiHeadAttention(nn.Module):
"""多头注意?"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens?的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values?的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第?项(标量或者?量)复制num_heads次,
# 然后如此复制第?项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)代码详细解释:
代码定义了一个名为MultiHeadAttention的类,它是实现Transformer中多头注意力机制的核心模块。这个类基于PyTorch框架构建,并且遵循了Dive into Deep Learning (d2l) 一书中的实现风格。以下是对代码逐段详细解释:
类定义与初始化:
继承自nn.Module,这是PyTorch中所有神经网络模块的基础类。
初始化函数__init__接收多个参数:
key_size, query_size, value_size: 分别是键、查询和值向量的维度。
num_hiddens: 每个注意力头内部的隐藏层维度(每个头的输入和输出维度)。
num_heads: 多头注意力的头数。
dropout: 注意力机制中的 dropout 率,用于防止过拟合。
bias: 可选布尔值,决定线性变换层是否使用偏置项。
定义内部属性:
self.num_heads:保存注意力头的数量。
self.attention:实例化一个d2l.DotProductAttention对象,这是一个点积注意力子模块,包含了缩放点积注意力计算以及可能的dropout操作。
self.W_q, self.W_k, self.W_v:分别对应三个线性层,将查询、键、值映射到隐藏层维度(即num_hiddens)。
self.W_o:最后一个线性层,将从多头注意力得到的结果转换回原始的num_hiddens维度。
forward方法:
输入包括queries, keys, values,它们通常是从编码器或解码器的不同位置获取的特征向量,形状为 (batch_size, query_or_key_value_pairs_num, num_hiddens);valid_lens 是序列的有效长度,对于变长序列做掩码处理时有用,其形状可以是 (batch_size,) 或 (batch_size, query_num)。
首先通过对应的线性层(self.W_q, self.W_k, self.W_v)将查询、键和值投影到新的空间,并通过transpose_qkv函数进行转置和重塑,使得形状变为 (batch_size*num_heads, query_or_key_value_pairs_num, num_hiddens/num_heads),这样就可以实现并行计算多个注意力头。
如果传入了有效长度valid_lens,则会对其进行复制以匹配多个注意力头的数量。
调用self.attention(点积注意力)来计算注意力得分并加权求和得到上下文向量,同时应用dropout和masking。
通过transpose_output函数对结果进行反向转置和重塑,合并来自所有注意力头的输出,恢复成单个注意力头的形状(batch_size, query_num, num_hiddens)。
最后,将整合后的注意力输出通过线性层self.W_o进一步映射到最终的输出维度。
总之,这段代码实现了多头注意力机制,它能够并行地执行多个注意力头的计算,并将各个头的输出融合在一起,从而增强了模型捕捉不同表示子空间中信息的能力。2.3 编码器的整体实现
2.3.1?EncoderBlock
有了组成Transformer编码器的基础组件,现在可以先实现编码器中的?个层。下?EncoderBlock类包含 两个?层:多头?注意?和基于位置的前馈?络,这两个?层都使?了残差连接和紧随的层规范化。
代码:
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))代码解释:
这段代码定义了一个名为EncoderBlock的类,它是Transformer模型中的编码器部分的基本组成单元,即一个编码块。这个类继承自PyTorch的nn.Module基类,并在初始化函数中构建了两个主要组成部分:多头注意力机制(Multi-Head Attention)和前馈神经网络(Position-wise Feed-Forward Network, FFN)。同时,该类还包含了两个用于添加残差连接(Add)与层归一化(Norm)的子模块。
初始化方法 __init__:
接收多个参数,如关键尺寸(key_size)、查询尺寸(query_size)、值尺寸(value_size)、隐藏层大小(num_hiddens)、层归一化的形状(norm_shape)、FFN输入维度(ffn_num_input)、FFN隐藏层维度(ffn_num_hiddens)、注意力头的数量(num_heads)、dropout率等。
定义内部属性:
attention: 使用d2l库中的MultiHeadAttention类创建一个多头注意力子模块,其参数由传入的关键、查询、值尺寸以及隐藏层大小、注意力头数量和dropout率确定。
addnorm1 和 addnorm2: 分别是两次残差连接后接层归一化的组合模块,这里使用的是自定义的AddNorm类,它包含加法操作(Add)和层归一化(Norm),并接收norm_shape和dropout作为参数。
ffn: 创建一个位置感知的前馈神经网络子模块,利用PositionWiseFFN类实现,其参数包括FFN的输入维度、隐藏层维度和输出维度(此处与隐藏层大小相同)。
正向传播方法 forward:
输入参数为X(编码器的输入序列)和valid_lens(有效序列长度)。
首先,将X传递给attention子模块计算多头注意力结果,并通过addnorm1模块进行残差连接和层归一化,得到中间表示Y。
最后,将经过注意力机制处理后的Y传递给ffn子模块进行前馈神经网络计算,再通过addnorm2模块进行第二次残差连接和层归一化,从而得到最终的编码块输出。
综上所述,EncoderBlock类实现了Transformer编码器的一个完整基本块,包括多头注意力机制和前馈神经网络结构,并结合了残差连接和层归一化来优化训练过程和提高模型性能。?2.3.2?TransformerEncoder
? ? ? ?实现的Transformer编码器的代码中,堆叠了num_layers个EncoderBlock类的实例。由于这?使?的是 值范围在?1和1之间的固定位置编码,因此通过学习得到的输?的嵌?表?的值需要先乘以嵌?维度的平? 根进?重新缩放,然后再与位置编码相加。
代码:
class TransformerEncoder(d2l.Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌?值乘以嵌?维度的平?根进?缩放,
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[i] = blk.attention.attention.attention_weights
return X代码解释:?
这段代码定义了一个名为TransformerEncoder的类,它是基于深度学习框架实现的一个Transformer模型的编码器部分。这个类继承自d2l库中的Encoder基类,并在初始化和前向传播过程中实现了以下功能:
初始化方法 __init__:
接收一系列参数,包括词汇表大小(vocab_size)、关键尺寸(key_size)、查询尺寸(query_size)、值尺寸(value_size)、隐藏层大小(num_hiddens)、归一化形状(norm_shape)、FFN输入维度(ffn_num_input)、FFN隐藏层维度(ffn_num_hiddens)、注意力头数量(num_heads)、编码器层数量(num_layers)以及dropout率等。
创建一个词嵌入层:使用nn.Embedding来将输入的词索引映射到隐藏向量空间。
创建一个位置编码层:通过d2l.PositionalEncoding类为输入序列添加位置信息,以帮助模型理解序列中元素的位置关系。
构建编码器块:利用循环结构创建指定数量(num_layers)的EncoderBlock实例,并将其串联成一个序列,存储在self.blks属性中。
正向传播方法 forward:
输入参数为X(输入序列的词索引),valid_lens(有效序列长度列表,用于处理变长序列时的掩码操作)以及其他可能的额外参数。
首先,对输入序列进行词嵌入操作并应用位置编码。这里乘以math.sqrt(self.num_hiddens)是为了确保在加入位置编码后,数值范围保持合理,同时避免了因维度增大而导致的梯度消失或爆炸问题。
然后,遍历所有的编码器块,对每个编码块执行前向传播计算,并将当前块的注意力权重保存在self.attention_weights列表中,便于后续可视化或分析。
最终返回经过所有编码块处理后的输出表示X。
总结起来,TransformerEncoder类构建了一个完整的Transformer编码器结构,它包含了词嵌入、位置编码以及多层由多头注意力机制和前馈神经网络组成的编码块,在处理输入序列时能够捕获上下文依赖和位置信息。3、解码器(待续)
Transformer解码器也是由多个相同的层组成。在DecoderBlock(解码器模块)类中实现的每个层包含三个子层:解码器自注意力(decoder attention)、编码器-解码器注意力(encoder-decoder attention)和基于位置的前馈网络(PositionWiseFFN)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 多门店自助点餐+外卖二合一小程序系统源码:自助点餐+外卖配送 带完整搭建教程
- SpringBoot + Vue 前端后分离项目精进版本
- LeetCode Hot100 239.滑动窗口最大值
- 机器视觉系统选型-参数—景深
- 谷歌DeepMind最新研究:对抗性攻击对人类也有效,人类和AI都会把花瓶认成猫!
- LabVIEW交变配流泵性能测试系统
- Web连接eNSP防火墙
- react pwa应用示例
- Footprint 批量下载方案:为机器学习提供优质区块链数据
- ???????配置MUX VLAN示例(接入层设备)