机器学习_假设(预测)函数——h(x)、损失(误差)函数——L(w, b)
假设(预测)函数——h(x)
方程式 y’=wx+b
也可以写成:
h (x)=wx+b
其中,需要注意以下两点。
- y’指的是所预测出的标签,读作y帽(y-hat)或y撇。
- h(x)就是机器学习所得到的函数模型,它能根据输入的特征进行标签的预测。
我们把它称为假设函数,英文是hypothesis function(所以选用首字母h作为函数符号)。
机器学习的过程,是一个不断假设、探寻、优化的过程,在找到最佳的函数f(x)之前,现有的函数模型不一定是很准确的。它只是很多
种可能的模型之中的一种–因此我们强调,假设函数得出的结果是y’,而不是y本身。所以假设函数有时也被叫作预测函数(predication function )。在机器学习中看到h(x)、f(x)或者p(x),基本上它们所要做的都是一回事。
所以,机器学习的具体目标就是确定假设函数h(x)。
- 确定b,也就是y轴截距,这里称为偏置,有些机器学习文档中,称它为w0(或θ0)。
- 确定w,也就是斜率,这里称为特征x的权重,有些机器学习文档中,称它为w1(或θ1)。一旦找到了参数w和b的值,整个函数模型也就被确定了。
损失(误差)函数——L(w, b)
在继续寻找最优参数之前,需要先介绍损失和损失函数。
如果现在已经有了一个假设函数,就可以进行标签的预测了。那么,怎样才能够量化这个模型是不是足够好?比如,一个模型是3x+5,另一个是100x+1,怎样评估哪一个更好?
这里就需要引入损失(loss)这个概念。
损失,是对糟糕预测的惩罚。损失也就是误差,也称为成本(cost)或代价。名字虽多,但都是一个意思,也就是当前预测值和真实值之间的差距的体现。它是一个数值,表示对于单个样本而言模型预测的准确程度。如果模型的预测完全准确,则损失为0;如果不准确,就有损失。在机器学习中,我们追求的当然是比较小的损失。
不过,模型好不好还不能仅看单个样本,而是要针对所有数据样本找到一组平均损失“较小”的函数模型。样本的损失的大小,从几何意义上基本上可以
理解为y和y’之间的几何距离。 这个损失很大, 不靠谱 这个好一些
平均距离越大,说明误差越大,模型越离谱。如图所示,左边模型所有数据点的平均损失很明显大过右边模型。
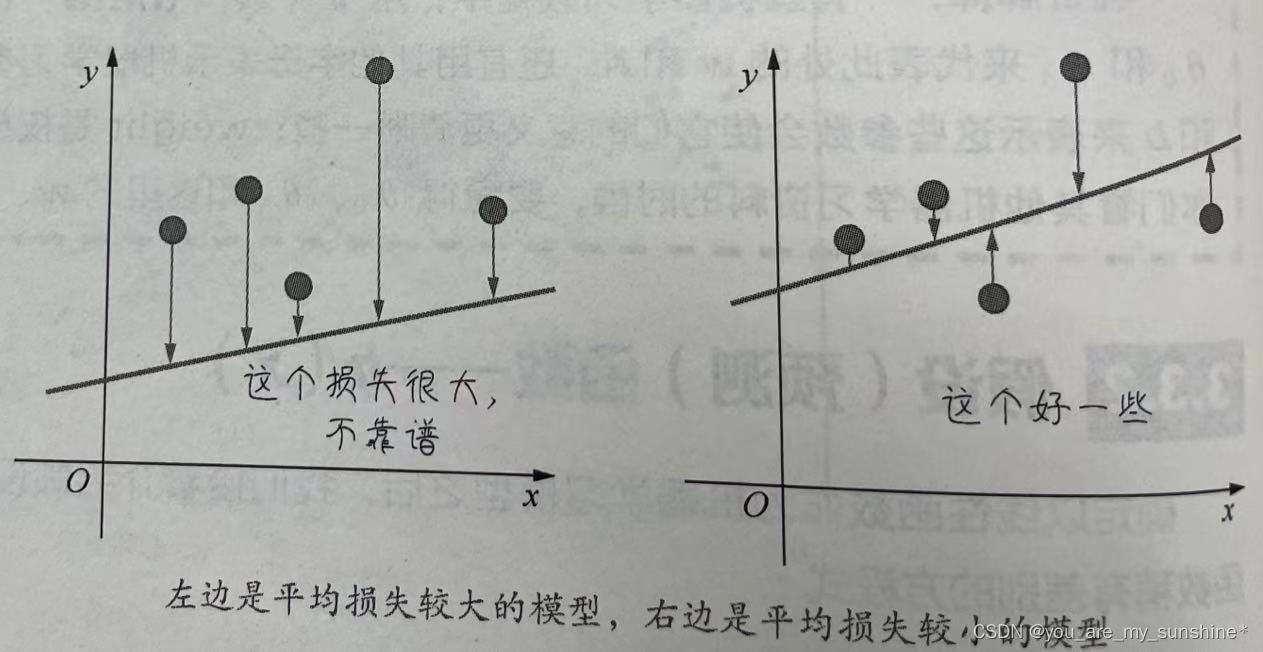
因此,针对每一组不同的参数,机器都会针对样本数据集算一次平均损失。计算平均损失是每一个机器学习项目的必要环节。
损失函数( loss function)L(w,b)就是用来计算平均损失的。
这里要强调一下:损失函数L是参数w和b的函数,不是针对x的函数。我们会有一种思维定势,总觉得函数一定是表示x和y之间的关系。现在需要大家换一个角度去思考问题,暂时忘掉x和y,聚焦于参数。对于一个给定的数据集来说,所有的特征和标签都是已经确定的,那么此时损失值的大小就只随着参数w和b而变。也就是说,现在x和y不再是变量,而是定值,而W和b在损失函数中成为了变量。
计算数据集的平均损失非常重要,简而言之就是:如果平均损失小,参数就好;如果平均损失大,模型或者参数就还要继续调整。
这个计算当前假设函数所造成的损失的过程,就是前面提到过的模型内部参数的评估的过程。机器学习中的损失函数很多,主要包括以下几种。
用于回归的损失函数。
- 均方误差(Mean Square Error,MSE)函数,也叫平方损失或L2损失函数。
- 平 均绝对误差(Mean Absolute Error,MAE)函数,也叫L1损失函数。
- 平均偏差误差(mean bias error )函数。
用于分类的损失函数。 - 交叉熵损失(cross-entropy loss )函数。
- 多分类SVM损失(hinge loss )函数。
一般来说,选择最常用的损失函数就可以达到评估参数的目的。
最后,根据样本的数量求平均值,则损失函数L为:
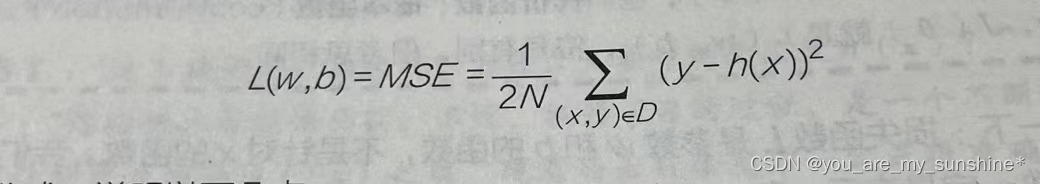
关于以上公式,说明以下几点。
- (x,y)为样本,x是特征(微信公众号广告投放金额),y是标签(销售额)。
- h(x)是假设函数wx+b,也就是y’。
- D指的是包含多个样本的数据集。
- N指的是样本数量(此例为200)。N前面还有常量2,是为了在求梯度的时候,抵消二次方后产生的系数,方便后续进行计算,同时增加的这个常量并不影响梯度下降的最效结果。
- 而L呢,对于一个给定的训练样本集而言,它是权重w和偏置b的函数,它的大小随着 w和b的变化而变。
学习机器学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
…
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【GDAL】Windows下VS+GDAL开发环境搭建
- 三极管的奥秘:如何用小电流控制大电流
- 如何获取2024年交易日历?
- 860. 染色法判定二分图 (染色法判定二分图,模板题)
- 中国电子学会2020年9月份青少年软件编程Scratch图形化等级考试试卷B一级真题(含答案)
- 渗透测试之逆向使用IDA pro软件修改.exe小程序打开对话框显示的文字
- Resolume Arena(VJ音视频软件):创意无限,视听艺术的新境界
- 【CGAL系列】---Mesh修复
- 代码随想录算法训练营day4|24.两两交换链表中的节点、19.删除链表的倒数第N个节点、链表相交、142.环形链表II
- uView Drawer 抽屉