JS中垃圾数据是如何自动回收的
背景
在JS栈和堆:数据是如何存储的一文中提到了 JavaScript 中的数据是如何存储的,并通过示例代码分析了原始数据类型时存储在栈空间中的,引用数据类型时存储在堆空间中的。通过这两种分配方式,解决了数据的内存分配问题。
不过有些数据在被使用了之后可能就不再需要了,这种称为垃圾数据。这些垃圾数据如果一直保存在内存中,内存会越用越多,所以需要对这些垃圾数据进行回收,以释放有限的内存空间。
垃圾回收机制
通常情况下,垃圾数据回收分为手动回收和自动回收两种策略。
- 手动回收:例外 C/C++ 就是使用手动回收策略,何时分配内存、何时销毁内存都是由代码控制的(调用
malloc函数分配内存,然后再使用,当不再需要这块数据时,手动调用free函数来释放内存),如果一段数据已经不再需要了,但是又没有主动调用销毁函数来销毁,那么这种情况就被称为内存泄漏。 - 自动回收:像 JavaScript、Java、Python 等语言,产生的垃圾数据是由垃圾回收器来释放的,并不需要手动通过代码来释放。
对于 JavaScript 而言,正是这个自动回收资源的特性带来了很多困惑,也让一些开发者误以为可以不关心内存管理,这是一个很大的误解。下面来探讨一下 JavaScript 中的栈中垃圾数据和堆中垃圾数据分别是如何被自动回收的。
调用栈中的数据回收
先看下面一段示例代码:
function foo() {
var a = 1
var b = {name: 'yy'}
function showName() {
var c = 2
var d = {name: 'qq'} // 第 6 行
}
showName()
}
foo()
当执行到第 6 行代码时,其调用栈的堆空间状态图如下所示:
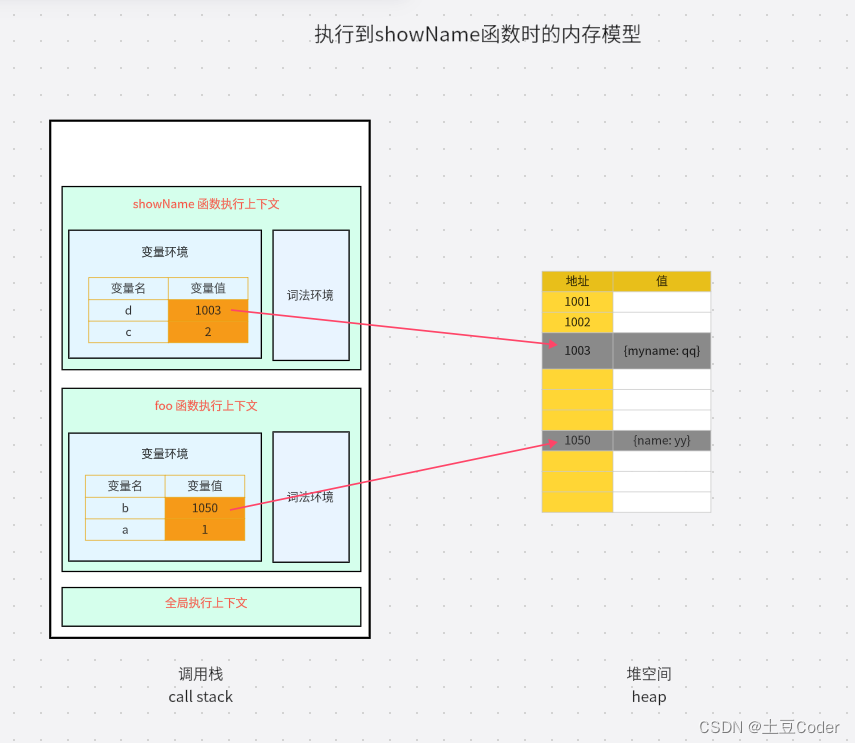
从图中可以看出,原始类型数据被分配到栈中,引用类型数据被分配到堆中。
在执行到 showName 函数时,JavaScript 引擎会创建 showName 函数的执行上下文,并将 showName 函数的执行上下文压入调用栈中,其调用栈状态图就如上图所示,同时还有一个记录当前执行状态的指针(ESP),指向调用栈中 showName 函数的执行上下文,表示当前正在执行 showName 函数。
接着,当 showName 函数执行完成后,函数执行流程就进入了 foo 函数,此时 JavaScript 会将 ESP 下移到 foo 函数的执行上下文,那这时就需要销毁 showName 函数的执行上下文了。
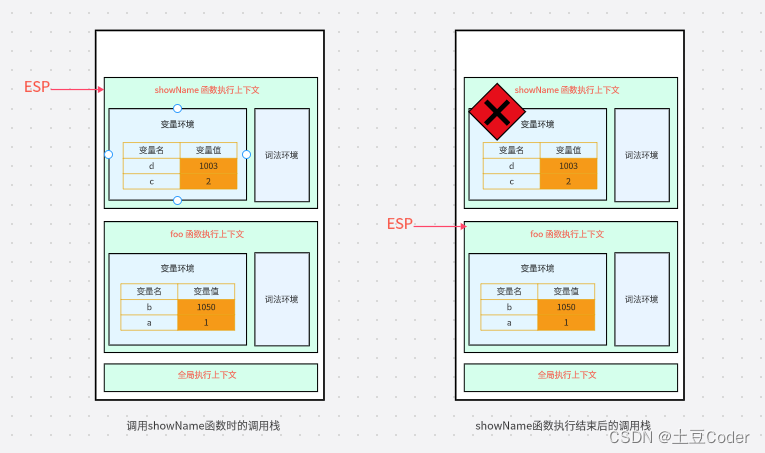
当
showName函数执行结束后,ESP 向下移动到foo函数的执行上下文,此时showName的执行上下文虽然保存在栈内存中但是已经是无效内存了。此时如果foo函数再次调用另外一个函数,这块内容会被直接覆盖掉,用来存放另外一个函数的执行上下文。
堆空间中数据回收
所以,当 foo 函数执行结束后,ESP 应该是指向全局执行上下文,此时 showName 函数和 foo 函数的执行上下文就处于无效状态了,不过保存在堆中的两个对象依然占用着空间,如图所示:
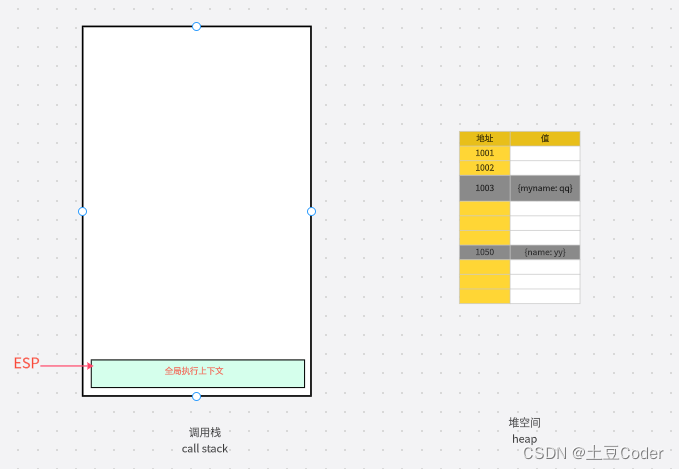
也就是说,1003 和 1005 这两块内存依然被占用着,JavaScript 引擎是如何堆中的垃圾数据的呢?
垃圾回收器的工作流程
代际假说(The Generational Hypothesis)是垃圾回收领域中的一个重要术语,后续垃圾回收策略都是建立在该假说基础上的,而且不仅适用于 JavaScript,同样适用于大多数动态语言,如 Java、Python等。它有两个特点:
- 大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问
- 不死的对象,会活得更久
在 V8 中会把堆分为新生代和老生代两个区域:新生代存放的是生存时间短的对象,老生代中存放的生存时间久的对象。新生区通常只支持 1-8M 容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器以便更高效地实施垃圾回收:
- 副垃圾回收器,主要负责新生代的垃圾回收
- 主垃圾回收器,主要负责老生代的垃圾回收
副垃圾回收器
通常情况下,大多数小的对象都会被分配到新生区,所以说这个区域虽然不大,但是垃圾回收频率较高。
新生代中用 Scavenge 算法来处理,它把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如图所示
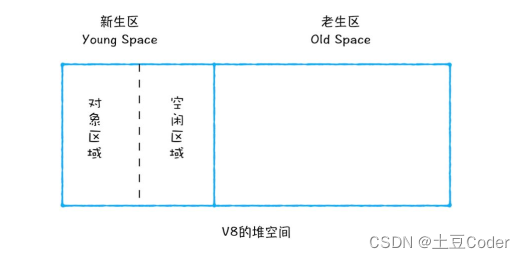
新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作:
首先要对对象区域中的垃圾做标记(标记空间中活动对象和非活动对象,所谓活动对象就是还在使用的对象,非活动对象就是可以进行垃圾回收的对象);标记完成后进入垃圾清理阶段(在所有标记完成后统一清理内存中所有被标记为可回收的对象),副垃圾回收器会把这些存活的对象复制到空闲区域中,同时还会把这些对象有序的排列起来,所以这个复制过程也就相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了(一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们将其称为内存碎片。当内存中出现了大量内存碎片后如果需要分配较大连续内存时就可能出现内存不足的情况,所以最后一步需要整理这些内存碎片,但这步是可选的)。
完成复制后,对象区域与空闲区域进行角色翻转,这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生代中的这两块区域无限重复使用下去。
由于新生代中的 Scavenge 算法在执行清理操作时,都需要将存活对象从对象区域复制到空闲区域,因此会产生复制的时间成本,如果新生区设置得太大了,每次清理的时间就会过长,所以为了执行效率,一般新生代的空间会被设置得比较小。
也正是因为新生代的空间不大,很容易被存活的对象装满,为解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象,会被移动到老生区中。
主垃圾回收器
主垃圾回收器主要负责老生中的垃圾回收。除了新生区中晋升的对象,一些大的对象会直接被分配到老生区。老生区对象有两个特点:占用空间大、存活时间长。
由于老生区对象比较大,若要在老生区中使用 Scavenge 算法进行垃圾回收是不合适的,因为复制这些大对象将会花费较多的时间,从而导致回收执行效率低下的同时还会浪费一半的空间,因此,主垃圾回收器采用的方式是标记-清除(Mark-Sweep):
首先是标记过程阶段。标记阶段是从一组根元素开始,递归遍历这组根元素,遍历过程中,能到达的元素称为活动对象,没有到达的元素判断为垃圾数据。
比如上面的示例代码中,当 showName 函数执行退出后,此时的调用栈和堆空间如图所示
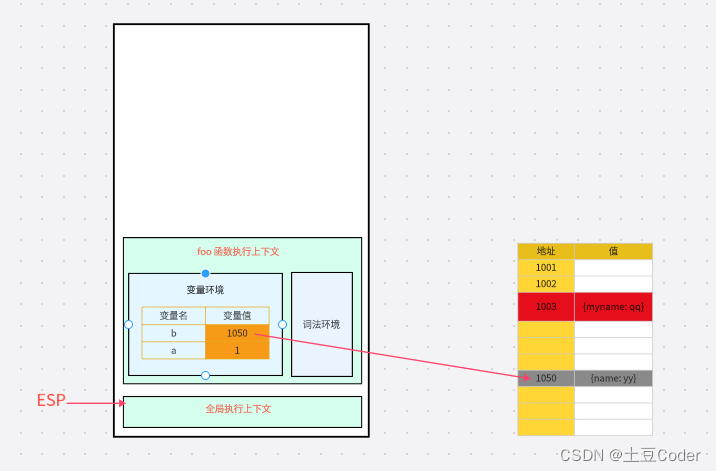
当 showName 函数执行结束之后,ESP 向下移动,指向了 foo 函数的执行上下文,这时候如果遍历调用栈,是不会找到引用 1003 地址的变量的,也就意味着 1003 这块数据为垃圾数据,被标记为红色。由于 1005 这块数据被变量 b 引用了,所以这块数据会被标记为活动对象,这就是大致的标记过程。
接下来是垃圾的清除过程。它和副垃圾回收器的垃圾清除过程完全不同,可以理解为这个过程是清除掉红色标记数据的过程,可参考下图大致理解
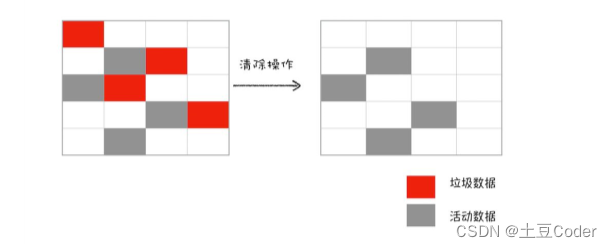
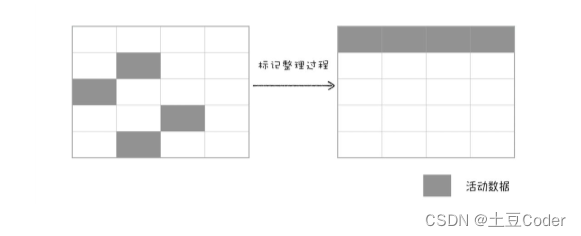
这种标记和清除的过程就是“标记-清除”算法,不过对一块内存多次执行标记-清除后,会产生大量不连续的内存碎片,而碎片过多会导致大对象无法分配到足够的连续内存,于是又产生了另外一种算法——标记-整理(Mark-Compact)。这个标记过程仍然与标记-清除算法里一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存,可参考下图大致理解
全停顿
由于 JavaScript 是运行在主线程上的,一旦执行垃圾回收算法,正在执行的 JavaScript 脚本都需要暂停下来,待垃圾回收完毕后再恢复脚本执行,我们将这种行为叫做全停顿(Stop-The-World)。
在 V8 新生代的垃圾回收中,因其空间较小,且存活对象较少,所以全停顿的影响不大,但是老生代就不一样了。如果在执行垃圾回收过程中,占用主线程时间过长,例如 500ms,比如页面正在执行一个 JavaScript 动画,因为垃圾回收器在工作,就会导致这个动画在这 500ms 内无法执行,从而造成页面卡顿现象。
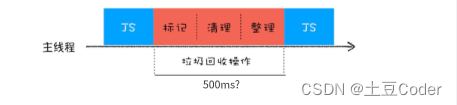
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们将这个算法称为增量标记算法(Incremental Marking)。如图所示
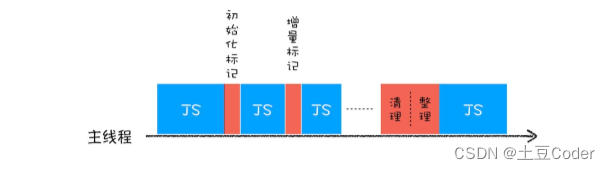
使用增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CodeReview 小工具
- UE 动画系统框架介绍及使用
- 【Codelab】如此简单!一文带你学会 15 个 HarmonyOS JS 组件
- 《JVM由浅入深学习【八】 2024-01-12》JVM由简入深学习提升分(JVM的垃圾回收算法)
- 单片机原理及应用:独立式键盘控制LED与多功能按键识别
- 杰理AC63蓝牙名修改
- 幂指函数及其求导
- Hudi0.14.0 集成 Spark3.2.3(IDEA编码方式)
- c 宏转字符串与拼接
- 阿里大佬倾力推荐:Spring Cloud Alibaba学习笔记,让你成为架构领域的佼佼者