gin-vue-admin二开使用雪花算法生成唯一标识 id
发布时间:2024年01月16日
场景介绍
需求场景: 总部采集分支的数据,由于分支的 id 是子增的主键 id,所以会出现重复的 id,但是这个 id 需要作为标识,没有实际作用,这里选择的是分布式 id 雪花算法生成 id 存储用来标识,这个项目基于 gva 进行开发的,可以使用 sonyflake 和 snowflake 两个实现方式都可以解决这个问题,这里选择 snowflake 进行设计
什么是雪花算法
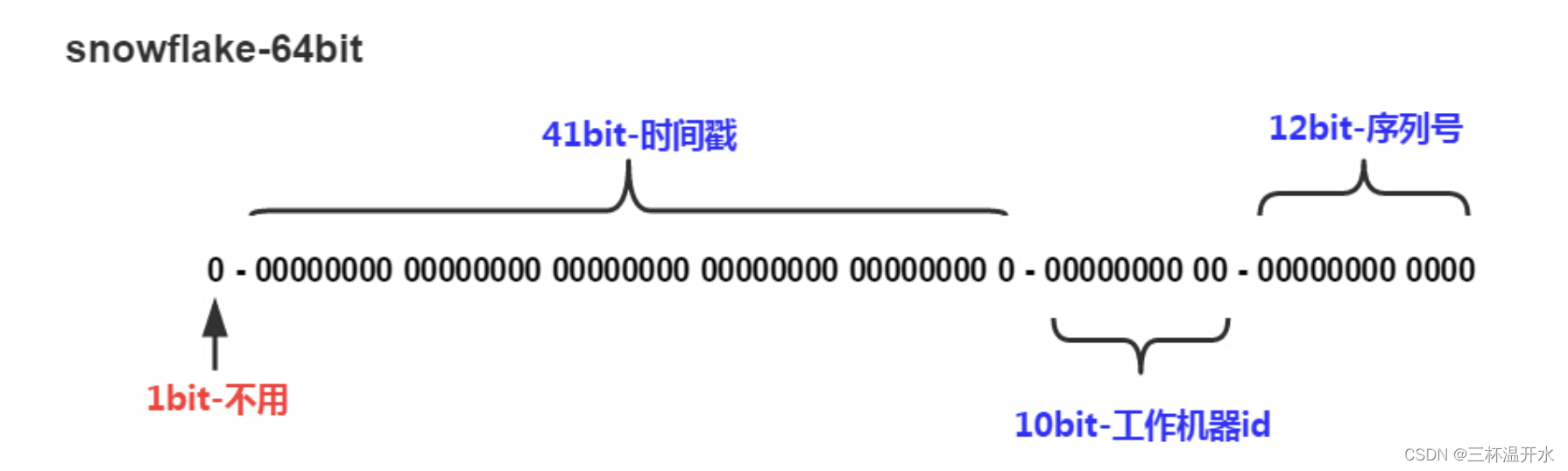
雪花算法,由Twitter开源,是一种分布式唯一ID生成算法。这种算法的主要特点是简单、高效,生成的64位整数ID全局唯一,且趋势递增。在单机上,雪花算法生成的ID也能保持递增特性,但在不同的机器上,由于各自有不同的时间戳,因此生成的ID不会冲突。
这种算法的性能相当高,每秒中能生成数百万的自增ID。因此,雪花算法被广泛应用于分布式系统中需要唯一ID的场景。例如,美团开源的分布式ID生成器Leaf也采用了雪花算法来保证全局唯一和趋势递增。
代码实现
我这边演示是通过插件注入的方式进行对 gva 进行二开,在 gva 后端模块的 server/plugin 中创建一个新的业务目录,里面创建一个 utils 工具文件夹,然后创建一个名字为 snowflake.go 文件,并且在 server 的全局 config.yaml文件配置一个 snowflake,在 main.go 主函数进行初始化以后就可以生成对应的雪花 id 了
拉取 snowflake
go get github.com/bwmarrin/snowflake
config.yaml 添加下面内容
snowflake:
start-time: "2024-01-01" # string
machineID: 1 # int64
plugin/工程目录添加config
// Snowflake 雪花机器结构体
type Snowflake struct {
StartTime string `mapstructure:"start-time" json:"start-time" yaml:"start-time"`
MachineID int64 `mapstructure:"machineID" json:"machineID" yaml:"machineID"`
}
全局config/config.go 中绑定注入这个 Snowflake 结构体
type Server struct {
..........
// 雪花
Snowflake config.Snowflake `mapstructure:"snowflake" json:"snowflake" yaml:"snowflake"`
}
plugin/项目目录 创建 utils/snowflake.go
package utils
import (
"errors"
sf "github.com/bwmarrin/snowflake"
"time"
)
var node *sf.Node
// SnowflakeInit 初始化
func SnowflakeInit(startTime string, machineID int64) (err error) {
var start_time time.Time
start_time, err = time.Parse("2006-01-02", startTime)
if err != nil {
return errors.New("生成 id 失败")
}
sf.Epoch = start_time.UnixNano() / 1000000
node, err = sf.NewNode(machineID)
return
}
// GenID 生成雪花 id
func GenID() int64 {
return node.Generate().Int64()
}
主函数
main.go初始化这个值
func main() {
.....
// 初始化雪花算法方法 SnowflakeInit
if err := utils.SnowflakeInit(global.GVA_CONFIG.Snowflake.StartTime, global.GVA_CONFIG.Snowflake.MachineID); err != nil {
fmt.Println("初始化雪花算法失败", err)
return
}
fmt.Println("测试 id", utils.GenID())
}
结果

文章来源:https://blog.csdn.net/weixin_47024018/article/details/135627389
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 宋仕强论道之华强北的领军企业(四十六)
- Mac NTFS 磁盘读写工具选哪个好?Tuxera 还是 Paragon?
- Vue组件:Vue Router以及路由守卫,含路由的基本使用,配置,路由传参,导航方式,缓存;路由守卫的三种用法
- Rust免杀 Shellcode加载与混淆
- 微信小程序+前后端开发学习材料
- 生产力与生产关系 —— 语音转文字,抛开键盘输入
- GreptimeAI + Xinference 联合方案:高效部署并监控你的 LLM 应用
- 线性代数的艺术
- 【虹科分享】金融服务急需数据层改造
- 位移贴图还原电影3D角色