Flink实时电商数仓(十)
发布时间:2024年01月02日
common模块回顾
- app
- BaseApp: 作为其他子模块中使用Flink - StreamAPI的父类,实现了StreamAPI中的通用逻辑,在其他子模块中只需编写关于数据处理的核心逻辑。
- BaseSQLApp: 作为其他子模块中使用Flink- SQLAPI的父类。在里面设置了使用SQL API的环境、并行度、检查点等固定逻辑。
- bean:存放其他子模块中使用到的javaBean对象,因为如果一直使用jsonObject对象调用数据的话,需要使用类似
getString("字段名")的方式,没有直接使用javaBean对象那么方便。 - constant
- 存储字符串常量
- 为了保证一致性,如果某个常量修改时,只需在这里修改即可对整个项目进行修改
- function
- DorisMapFunction:将javaBean对象转换为对应的json字符串对象,并且将驼峰式命名方式修改为蛇形命名方式。便于写入doris。
- util
- DateFormateUtil
- FlinkSinkUtil
- FlinkSourceUtil
- HBaseUtil
- IkUtil
- JdbcUtil
- SQLUtil
- getUpsertKafakaSQL: 一定要声明主键,支持撤回流
- getDorisSinkSQL: 用于写入Doris
dim层回顾
- Flink-cdc监控mysql中的维度配置表
- 将监控的数据流做成广播流
- 将广播流和读取数据的主流进行connect
- 主流数据根据广播流的配置信息进行分流,注意需要先提前缓存一次配置表信息
- 达到动态拆分数据表的效果
dwd层FlinkSQL回顾
- 注意join时会将所有数据都存储到内存中,需要考虑设置TTL
- 大表join小表时,可以考虑使用lookup join
- 如果数据流有明确的先后关系时,考虑使用Interval join
在支付成功模块,由于订单详情表处理时已经存在撤回流,但支付成功模块也是使用left join方式调用订单详情数据,会导致产生两次撤回流。在后续dws层处理时,要注意对数据进行去重过滤。
dws层回顾
- 如何判断使用FlinkSQL还是StreamAPI
- 如果比较标准化, 比如简单的开窗聚合,一般使用FlinkSQL
- 如果需要使用状态处理数据,比如判断是否为独立用户,使用StreamAPI
交易域sku粒度订单下单各窗口汇总
-
需求分析:从Kafka订单明细主题读取数据,过滤null数据并按照唯一键对数据去重,按照SKU维度分组,统计原始金额、活动减免金额、优惠券减免金额和订单金额,并关联维度信息,将数据写入Doris交易域SKU粒度下单各窗口汇总表
-
思路分析:
- 方案一:按照订单ID进行分组,根据业务逻辑设置定时器取最后一个数据进行发送
- 方案二:将度量值存放到状态中,每次新数据到达时,将新的度量值减去状态中的度量值
-
具体实现
- 因为需要使用状态,故使用BaseApp; 设置端口号10029,并发度4,消费者组为类名,消费者主题名称为dwd订单详情
- 读取dwd下单主题数据,
stream.print() - 过滤清洗:
- 去掉null数据,
stream.flatMap(new FlatMapFunction<>()) - ts: 水位线,不能为空;进行位数的修正,如果是10位的,使用
jsonObj.put("ts", ts*1000) - id: keyby的关键字,不能为空
- sku_id: group by的粒度关键字,也不能为空
- 去掉null数据,
- 添加水位线
- 网络延迟5L
- 添加数据的泛型,提取数据中的ts,作为水位线(注意观察ts的位数,需要为13位,毫秒级)
- 修正度量值,转换数据结构
- 使用id关键字进行分组
- 使用process算子中的状态来进行处理
stream.process(new KeyedProcessFunction<>),返回值为对应的javabean对象 - 在状态中存储上一次的度量值大小,只保存30秒
- 在
processElement()方法中获取状态中的度量值,使用前需要判空,如果为空设置为0,之后才能进行数值计算。 - 创建对应的bean对象,度量值都减去状态中的度量值和更新状态中当前的度量值
- 分组开窗聚合
- 使用skuId进行keyby
- 分组后使用
window算子进行开窗,设置窗口时间,注意Time属于org.apache.flink.streaming.api.windowing.time.Time.seconds() - 使用reduce算子进行聚合计算, 聚合时需要累积所有度量值
new ProcessWindowFunction()获取窗口信息, startTime, EndTime, curTime, 获取到后写入javaBean对象中
- 关联维度信息
- 先分组聚合再关联维度信息的原因:关联维度信息需要join操作,是很耗费性能的大操作。先聚合数据能大幅度减少数据量。
- 启动HBase,查看对的sku_info表中是否存储着对应的维度信息
- 获取外部连接,需要使用生命周期方法(open,close在整个算子执行过程中只运行一次);对应的关联维度信息,即RichMapFunction()
- 在
map方法中使用HBase的API读取表格数据,使用读取到的字段补全原本的信息
- 创建HBase的API:读取表格数据 get
- 获取table
- 创建get对象
- 调用get方法
- 获取数据写入jsonObj
- 写出到Doris
维度关联优化
- 旁路缓存:独立缓存服务有(redis, memcache).
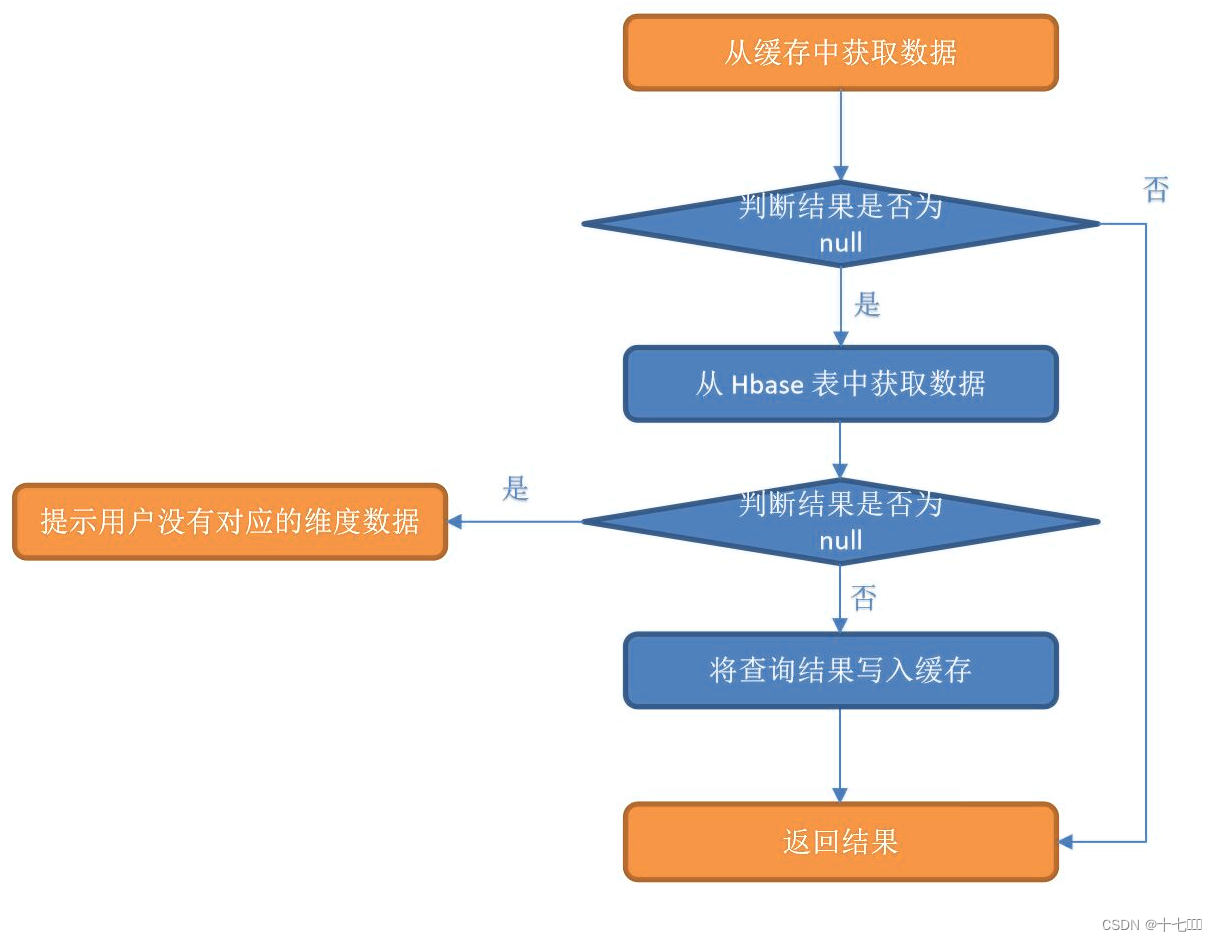
- 使用旁路缓存时要注意保持数据的一致性,如果数据发生修改和删除,直接删除redis中的数据。
同步+旁路缓存模式
- 引入Jedis相关依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
- 创建Redis工具类RedisUtil
- 在RichMapFunction中的open和close方法中获取和关闭HBase和Redisd的连接。
- 拼接对应的redisRowKey
- 读取Redis缓存的数据,jsonObj的字符串
- 判断redis读取到的数据是否为空
- 没有数据:需要读取HBase;
jsonObj = HBaseUtil.getCells(), 读取到数据后,使用jedis.setex()存储到redis - redis有缓存,直接返回
- 没有数据:需要读取HBase;
- 进行维度关联
Dim层写入HBase修正
- 在dim层将数据写入HBase时,需要同时获取Redis的连接。
- 判断redis中的缓存是否发生变化
- 判断数据类型是修改或删除时,删除Redis中对应的数据
- 拼写数据的rowkey
- 使用
jedis.del(rediskey)来删除
文章来源:https://blog.csdn.net/qq_44273739/article/details/135332977
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- http缓存
- 诊断服务通讯保持0X3E服务
- 性能分析与调优: Linux 实现 off-CPU剖析与火焰图
- 11-Kafka
- 处理Synology Photos视频不生成缩略图
- flutter base64图片保存到相册
- StarRocks-3.1.6升级
- 50天精通Golang(第15天)
- Zookeeper集群+Kafka集群
- LeetCode - 460 LFU缓存(Java & JS & Python)