基于LLM大模型的结构化数据批量提取
在当今世界,越来越多的组织致力于数据驱动的决策。 然而,他们通常面临着从非结构化文本数据(例如客户评论或反馈)中提取有价值的见解的挑战。
这篇文章是为想要使用非结构化数据获得有用见解的数据科学家、分析师和决策者量身定制的。 我们探索大型语言模型 (LLM) 的批量用例,重点关注非结构化文本到结构化数据的转换。 通过利用这种方法,企业可以利用结构化信息丰富其数据库,并提高对非结构化数据源的理解。 为了说明此类用例,我们将深入研究客户反馈分析的示例。
这个存储库提供了开始使用此类 LLM 批量用例的常规设置。
NSDT工具推荐:?Three.js AI纹理开发包?-?YOLO合成数据生成器?-?GLTF/GLB在线编辑?-?3D模型格式在线转换?-?可编程3D场景编辑器?-?REVIT导出3D模型插件?-?3D模型语义搜索引擎?-?Three.js虚拟轴心开发包
1、使用案例:客户反馈
让我们以网页上对应于特定产品的客户评论为例。

我们可能有一些可用的结构化信息,例如每个客户给出的星级数。 但是,我们可能需要更多具体信息。 例如,为什么客户给予高或低评价? 为了找到答案,我们需要自己阅读和过滤这些评论。 在对数千种产品进行数百次评论的情况下,这是一个不可行的过程。
理想情况下,也许我们会看到每个主题的评级,例如质量、运输、价格等。这有两个好处:
- 我们将能够更好地确定我们可以改进的地方。
- 我们将帮助客户在购买产品时做出更好的决定。
在下图中,我们可以看到每个主题的评分概览。

根据该图,敏锐的眼睛可能会注意到我们正在对提及某个主题的所有评论进行平均评分。 如果我们收到的评论提到多个主题:“质量很好,运输很差”,那么这种方法就不太有效。 在这种情况下,我们可能会错误地对质量给予低评级,或对运输给予高评级。 然而,为了使我们的示例简单,我们暂时忽略这些类型的评论。
你可能想知道,为什么不让客户直接就这些主题提供反馈呢? 那么这样的话,审核的过程就会变得更加复杂。 这可能会导致客户根本不评价。
那么,我们该怎么做呢? 我们需要一种可扩展的方法来从非结构化文本(即评论)中提取结构化信息(即主题)。
2、使用LLM提取结构化信息
在此示例中,我们使用LLM大模型,因为它的灵活性和易用性。 它使我们无需训练模型即可完成任务。 但请注意,对于非常结构化的输出,一旦收集到足够的样本,也可以训练简单的分类模型。
我们可以采取以下方法:
- 创建巧妙的提示
- 将非结构化文本交给LLM
- 检索 LLM 的结构化输出
- 保存到数据库

我们尝试强制 LLM 输出有效的 JSON,因为我们可以轻松地将原始 JSON 作为 Python 中的对象加载。 例如,我们可以定义 Pydantic BaseModel,并使用它来验证模型输出。 此外,我们可以使用它的定义立即为模型提供正确的格式化指令。 要了解有关强制LLM提供结构化输出的更多信息,请查看我们之前的博客文章。
我们的 Pydantic BaseModel 看起来像这样:
from typing import List, Literal
from pydantic import BaseModel, Field
class DesiredOutput(BaseModel):
topics: List[
Literal[
"quality",
"price",
"shipping",
]
] = Field("Topic(s) in the input text")
然而,模型第一次可能不会正确。 我们可以通过将验证错误反馈到提示中来对模型进行几次尝试。 这种方法可以被认为是拉斯维加斯类型的算法。 流程如下所示:

就是这样! 至少对于基础知识来说是这样。 我们可以扩展它,例如允许通用的用户定义模式,然后可以将其解析为 Pydantic BaseModel。

3、结构化为批处理操作
最后一步,我们将逻辑与输入和输出分开,这样我们就可以轻松地对新批次的数据运行这些操作。

我们可以通过参数化输入评论的位置和 JSON 文件的输出位置来实现这一点。 我们在运行批处理时使用它们来加载评论并存储输出文件。
当我们运行批处理作业时,每次审核都会提示 LLM(使用上一节中描述的逻辑)一次。 评论本身可以使用提示模板动态插入到我们的提示中,该模板在此处的源存储库中实现。
随后,我们可以根据需要使用输出 JSON。 它们应该包含我们在 BaseModel 中指定的所有信息。 在客户评论的示例中,我们现在可以轻松地将评论按主题与可用的结构化信息分组在一起。
在本地运行此操作后,剩下要做的就是使该批处理操作能够在服务器上运行给定的时间间隔。 但我们将其排除在本文的讨论范围之外。
4、泛化解决方案
上述解决方案已经适用于我们想要从非结构化输入数据中提取结构化信息的许多用例。 然而,为了进一步概括,我们还可以添加处理 pdf 文档的功能,因为这些通常是与文本相关的用例的起点。
在较高的层面上,整体解决方案大致变为:
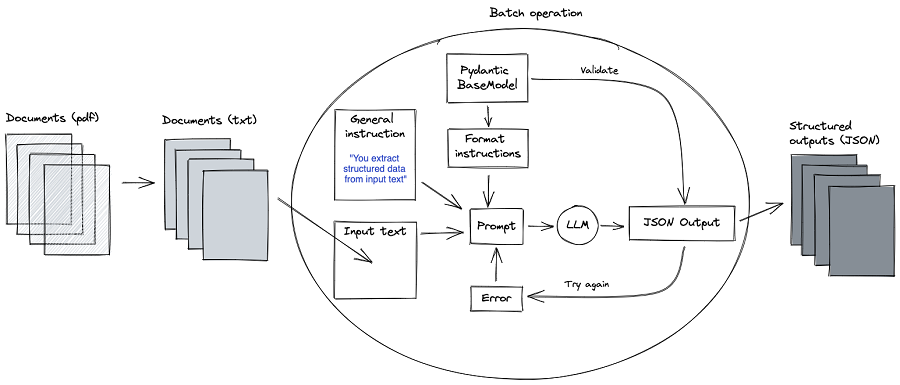
在源代码库中,我们假设了一种简单的情况,即文档足够小,可以一次性通过 LLM。 然而,在某些情况下,pdf 会跨越数十页。 对于LLM来说,输入变得太大,并且需要实施额外的处理。
5、结束语
在这篇博文中,我们探讨了LLM的典型批量用例,重点是从非结构化文本中提取结构化数据。 我们通过客户反馈分析的例子演示了这种方法。 通过使用LLM和精心设计的提示策略,我们可以有效地将非结构化文本数据转换为结构化信息。 然后,我们可以使用这些信息来丰富我们的数据库并促进更好的决策。
提供的存储库以基本形式展示了此类用例,并且可以轻松适应你的特定需求。 我们鼓励你使用自己的数据进行尝试,并探索利用LLM从非结构化文本中提取有价值的见解的可能性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 设计模式--职责链模式
- 【c++primerplus】【10】【对象和类】
- C++编码规范:JSF-AV(未完待续)
- 基于springboot+vue2的课程教学考试系统(Java毕业设计)
- 多微信聚合管理技巧,你一定要知道
- 宠物热潮席卷欧美:探秘宠物经济的蓬勃发展与增长动力
- 【数据库】使用远程管理工具链接Mysql数据库
- c++计算岛屿数量
- Mysql实时数据同步工具Alibaba Canal 使用
- iPhone抹掉数据后能恢复吗?看完这篇文章你就知道了!