CNN——ResNet
?????????深度残差网络(Deep residual network,?ResNet)的提出是CNN图像史上的一件里程碑事件,并且让深度学习真正可以继续做下去,斩获2016 CVPR Best Paper。此外ResNet的作者都是中国人,一作何恺明。ResNet被提出以后很多的网络都使用或借鉴了这个结构。该论文的被引用量更是突破了10w+。
论文地址:[1512.03385] Deep Residual Learning for Image Recognition (arxiv.org)
? ? ? ? 在2015的5个竞赛中都获得了第一名而且远远甩开第二名。?
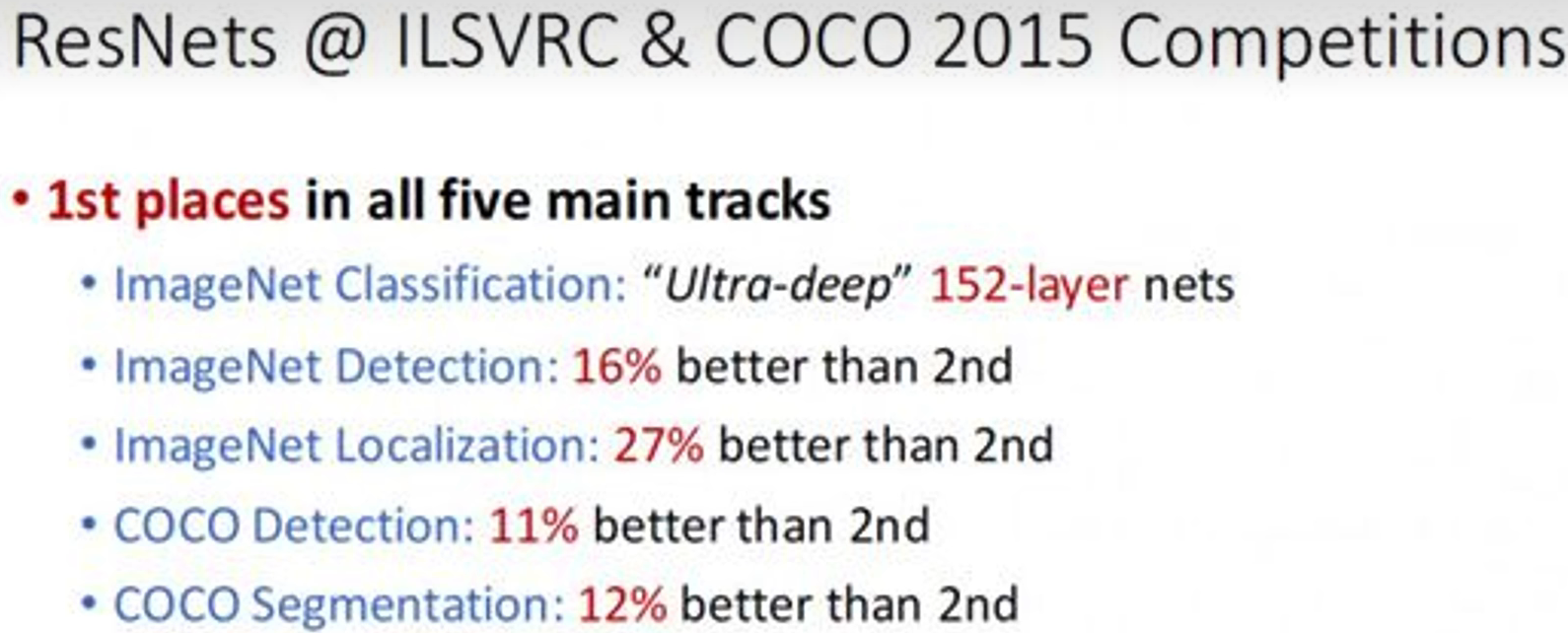
1. ResNet概述? ? ? ??
1.1 研究背景
????????无论是VGG还是GoogleNet都表明增加网络的深度的重要性,网络越深可以提取到越高级的特征。
????????那么是否意味着直接简单的将网络堆深是不是就可以了?
????????增加网络深度首先会带来的问题就是梯度消失或者梯度爆炸导致难以收敛,但这个问题已经可以通过合适的权重初始化手段,Xavier初始化,MSRA?初始化还有Batch Normalization解决。
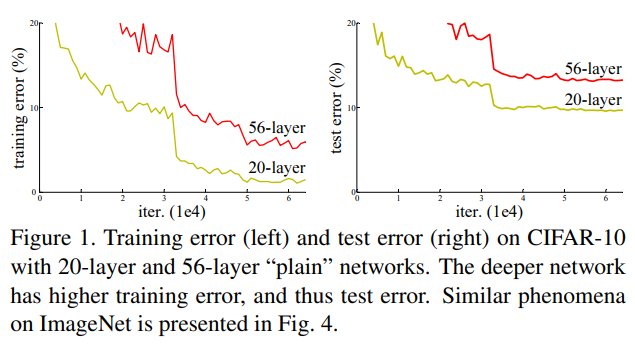
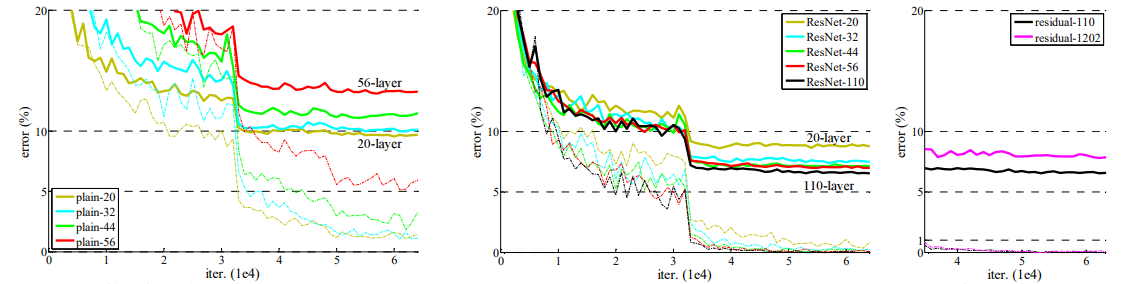
? ? ? ? 另一个问题便是网络退化现象,这既不是梯度消失或者梯度爆炸导致也不是过拟合导致的,如下图所示,56层网络在训练集和测试集上的误差都比20层网络大。并且他们经过实验发现即使更深的网络使用3倍的迭代次数退化现象仍存在。
????????????????????????
1.2?残差学习
? ? ? ? 于是论文提出了一个残差学习框架用来训练那些非常深的神经网络,重新定义了网络的学习方式,让网络可以直接学习输入信息与输出信息的差异(即残差),然后将浅层的特征与深层的特征直接相加进行融合,即使残差为0,通过一个Shortcut connection也可以实现identity mapping恒等映射,通俗理解就是即使什么都没学到,也不会比原来更差。经过这个结构Shortcut connection既没有引入额外的参数,也没有增加计算的复杂度(相加的复杂度很低,微不足道)。
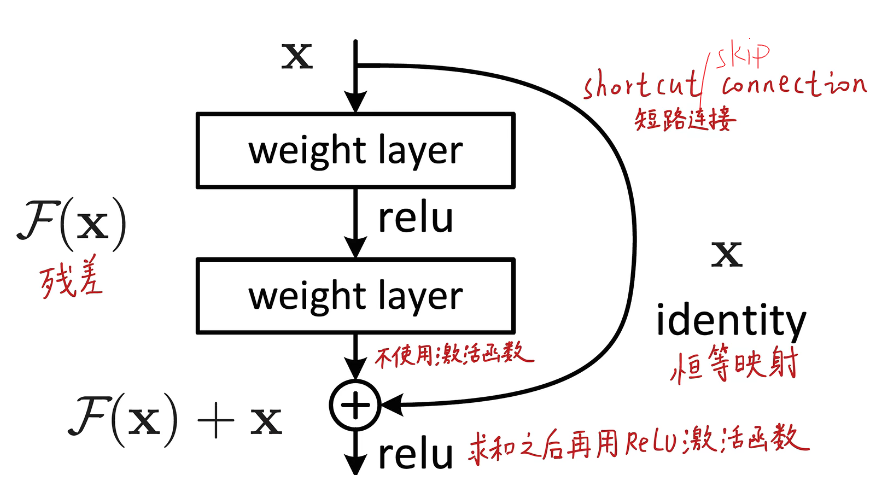
残差网络
- 易于优化收敛
- 解决退化问题
- 让网络可以更深,准确率大大提升?
? ? ? ?通过这个结构,论文中提出了ResNet合集,随着深度增加网络性能还在增加,在高达152层时,网络仍然有着较低的复杂度(比VGG16还低),并且在 ImageNet的测试集上进行评测,达到了3.57%的错误率,这一结果赢得?ILSVRC 2015?分类比赛的第一名,超过了人类的水平。最后甚至还实验了超过1000层的网络。

1.3 Resnet机理
????????resnet有效的真实原因还有待研究,原论文也只是做出了猜测,并没有很严格的理论证明。后续也有非常多的人做出了不一样的或者进一步的论证
1.恒等映射这一路梯度是1,可以防止梯度消失。虽然网络退化和梯度消失没什么关系,但Resnet确实可以防止梯度消失,加快收敛速度
2.集成学习。ResNet相当于几个网络的集成。

3.神经网络难以拟合恒等映射
????????纵观深度神经网络的发展,为了让网络能力越来越强,在神经网络引入了很多非线性。这也使得特征随着层层前向传播得到完整保留(什么也不做)的可能性都微乎其微,有的时候?“什么都不做”反而是最好的,但是“什么都不做”(恒等映射)恰好是当前神经网络最难做到的东西之一。可以认为Residual Learning的初衷,其实是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化。
4.

还有一些别的说法

? ? ? ? 众所周知,深度学习和炼丹一样,ResNet有效因为因为实验结果就是好。
1.4 结论
1.残差网络可以解决网络退化问题,可以重新让网络变得更深,性能越好
2.残差网络收敛速度更快
2. 网络结构详解?
1.ResNet18,34,50,101,152
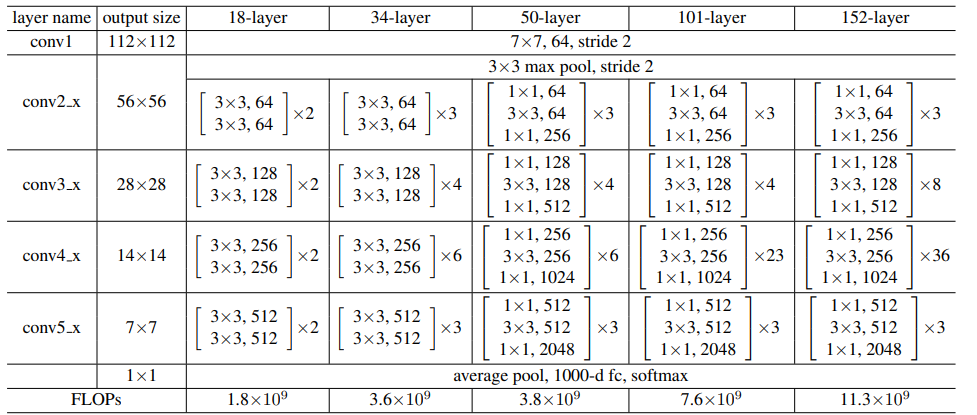
? ? ? ? 网络结构类似于VGG,除第一个卷积层外,全部采用3×3卷积,padding=1。除第一次下采样外,下采样通过步长为2的卷积来实现。此外还在卷积后激活前使用了BN。
????????其中,根据Block类型,可以将这五种ResNet分为两类:(1) 一种基于BasicBlock,浅层网络ResNet18, 34都由BasicBlock搭成;(2) 另一种基于Bottleneck,深层网络ResNet50, 101, 152乃至更深的网络,都由Bottleneck搭成。Block相当于积木,每个layer都由若干Block搭建而成,再由4层layer组成整个网络。
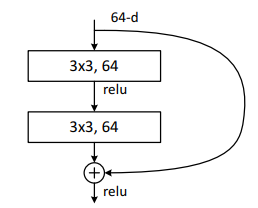
????????BasicBlock包括两个3×3卷积(如下图),除了conv2_x通过最大池化降采样外,每一层第一个BasicBlock的第一次卷积步长为2进行下采样。
????????????????????????????????????????????????????????
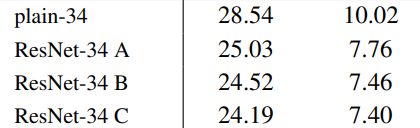
????????对于下采样的残差连接,会出现两者尺寸和通道数不一样的问题,无法直接相加,论文中给出了两种方案,(A)浅层使用1×1卷积核步长为2同时不改变通道数,仍然使用恒等映射直接相加,但是对于新增加的维度则全部使用0来代替。这种方案不增加任何的参数。(B)还是使用1x1的卷积步长为2,但是输出的通道数设置需要和下采样后的通道数匹配(如下图)。
????????????????????????????????????????
? ? ? ? 论文中对比了两种方案的效果,还加了一种C方案:无论是否降采样都使用1×1卷积后再连接,实际中不会用C方案,因为他增加了很多参数。由于参数量A<B<C,所以误差也会有一点点不同。A方案已经可以解决退化的问题且不会增加额外的参数,但通过0填充的维度确实没有进行残差学习。一般采用B方案
?????????????????????????????????????????????
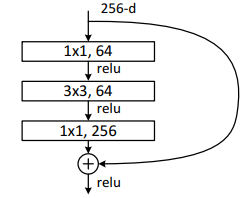
? ? ? ? 为了减低深层次网络参数量和计算量,深层次网络采用了Bottleneck。先通过1×1卷积降维四倍(减少通道数)再使用3×3卷积通道数不变,最后通过1×1卷积升回维度。
????????同样的除了conv2_x通过最大池化降采样外,每一层第一个Bottleneck进行下采样,1×1卷积降维两倍,3×3卷积步长为2进行下采样,1×1卷积升高4倍维度。
??
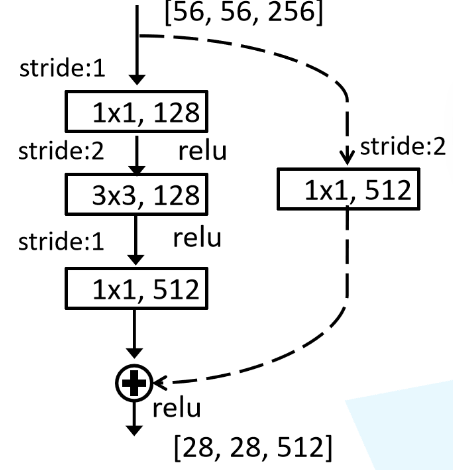
? ? ? ? 最后使用全局平均池化,连接一个输出为1000的全连接层,使用Softmax完成分类。
2.ResNet20,32,44,56,110
? ? ? ? 论文在CIFAR-10数据集也进行了实验。针对32×32的小尺寸这个网络变种只有三个阶段。第一个7×7卷积变成3×3,步长也为1,没了最大池化层。

????????设置卷积层个数n={3,5,7,9,18,200},可以得到ResNet20,32,44,56,110。此外设置n=200,得到了1202层。在训练这个1000多层的网络的时候没有遇到训练退化的问题,并且他的训练误差小于0.1%。尽管1202层网络的训练误差和110层网络是相似的,但是它的测试结果却要差于110层的网络。论文猜测可能是由于过拟合造成的。因为对于这样的一个小数据集,也许并不需要一个有着1202层网络进行训练。
3. ResNet在Pytorch实现
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义基本块 BasicBlock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
# 第一个卷积层,3x3卷积核,stride用于控制步幅
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels) # 批归一化
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
# 如果步幅不为1或输入通道数不等于输出通道数*expansion,使用额外的卷积层来匹配维度
if stride != 1 or in_channels != self.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # 将残差连接到输出
out = F.relu(out)
return out
# 定义瓶颈结构 Bottleneck
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.shortcut = nn.Sequential()
# 如果步幅不为1或输入通道数不等于输出通道数*expansion,使用额外的卷积层来匹配维度
if stride != 1 or in_channels != out_channels * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * self.expansion)
)
def forward(self, x):
residual = x
out = self.relu(self.bn1(self.conv1(x)))
out = self.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
residual = self.shortcut(residual) # 匹配维度
out += residual # 将残差连接到输出
out = self.relu(out)
return out
# 定义ResNet模型
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], stride=1)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
layers = []
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# 不同深度的ResNet模型的创建函数
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def ResNet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
def ResNet50():
return ResNet(Bottleneck, [3, 4, 6, 3])
def ResNet101():
return ResNet(Bottleneck, [3, 4, 23, 3])
def ResNet152():
return ResNet(Bottleneck, [3, 8, 36, 3])
? ? ? ? ?
# 定义基本块 BasicBlock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != self.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
# 定义ResNet模型
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=1000):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# 创建不同深度的ResNet模型的函数
def ResNet20():
return ResNet(BasicBlock, [3, 3, 3])
def ResNet32():
return ResNet(BasicBlock, [5, 5, 5])
def ResNet44():
return ResNet(BasicBlock, [7, 7, 7])
def ResNet56():
return ResNet(BasicBlock, [9, 9, 9])
def ResNet110():
return ResNet(BasicBlock, [18, 18, 18])
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!