跑通 yolov5-7.0 项目之训练自己的数据集
yolov5
一、yolov5 源码下载
仓库地址:yolov5-v7.0
二、配置环境,跑通项目
我的环境:python — 3.9,cpu训练,新建的一个python虚拟环境。
博主用的电脑配置不高,又想在本地跑,就用的 cpu 训练的(训练的时候有点慢,但还是可以接受)。
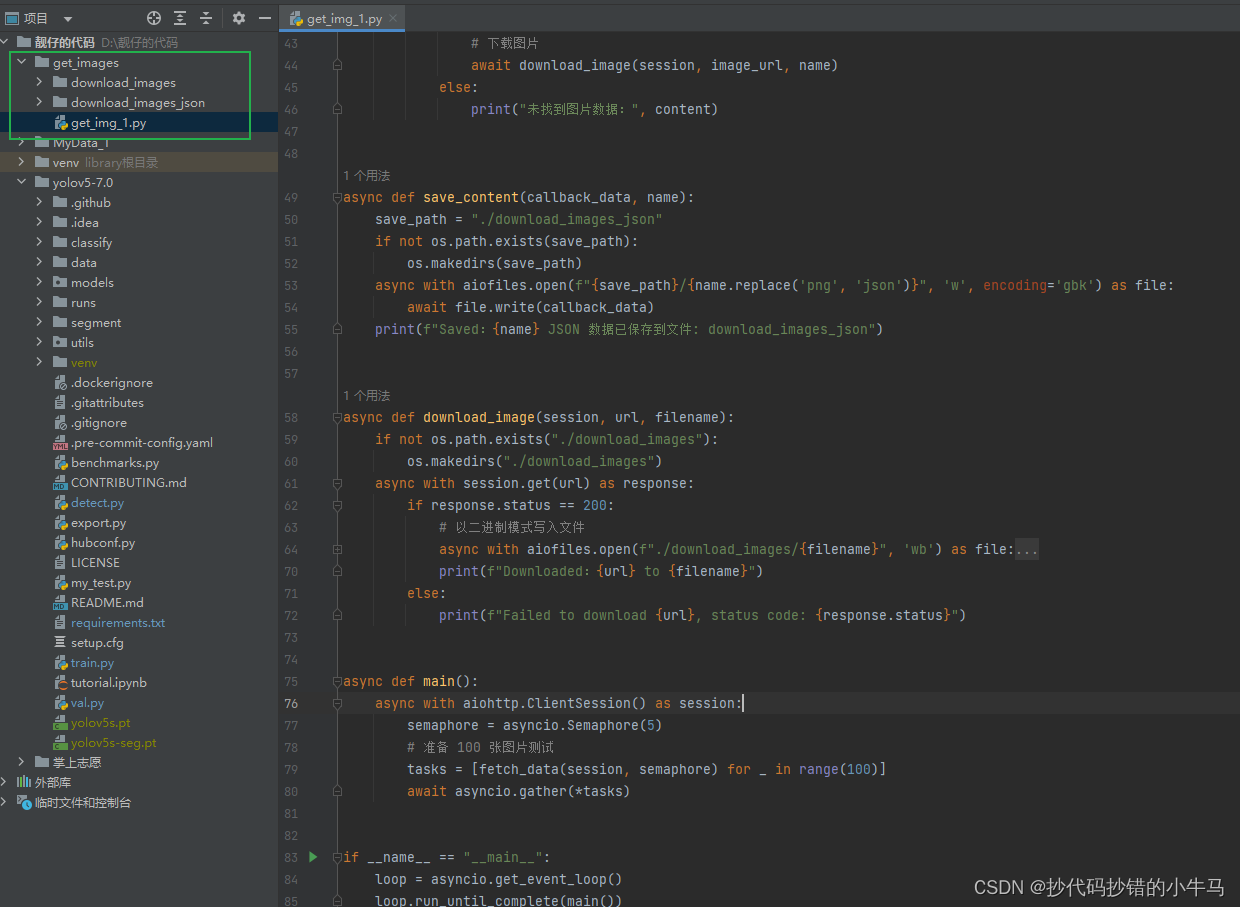
代码拉倒本地打开后,整体结构如下:
安装 requirements.txt 依赖:切到 yolov5-7.0 路径下:
要先修改一下 Pillow>=7.1.2 ,把他改为:Pillow==9.5 为什么要改?点我看看就知道
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
下载好环境后,直接去运行:train.py 先跑一哈。我是 cpu 训练,那就要改一下 train.py 的配置,跑官方的数据,就改一个 cpu 训练那里后,右键运行就是。
成功的话,会提示画出框的图片在哪里的,可以看这个,跑通的结果
三、训练自己的数据集
1、获取验证码数据
验证码数据源
我是分的 图片 和 网站返回的数据各一个文件夹。
2、标注图片,准备数据集
中文版本的:Labelimg-中文编译版
链接:https://pan.baidu.com/s/1u0JcJKR5IhYuSWlPQ_qDTg
提取码:895i
先熟悉了解我们需要用到的几个东西:
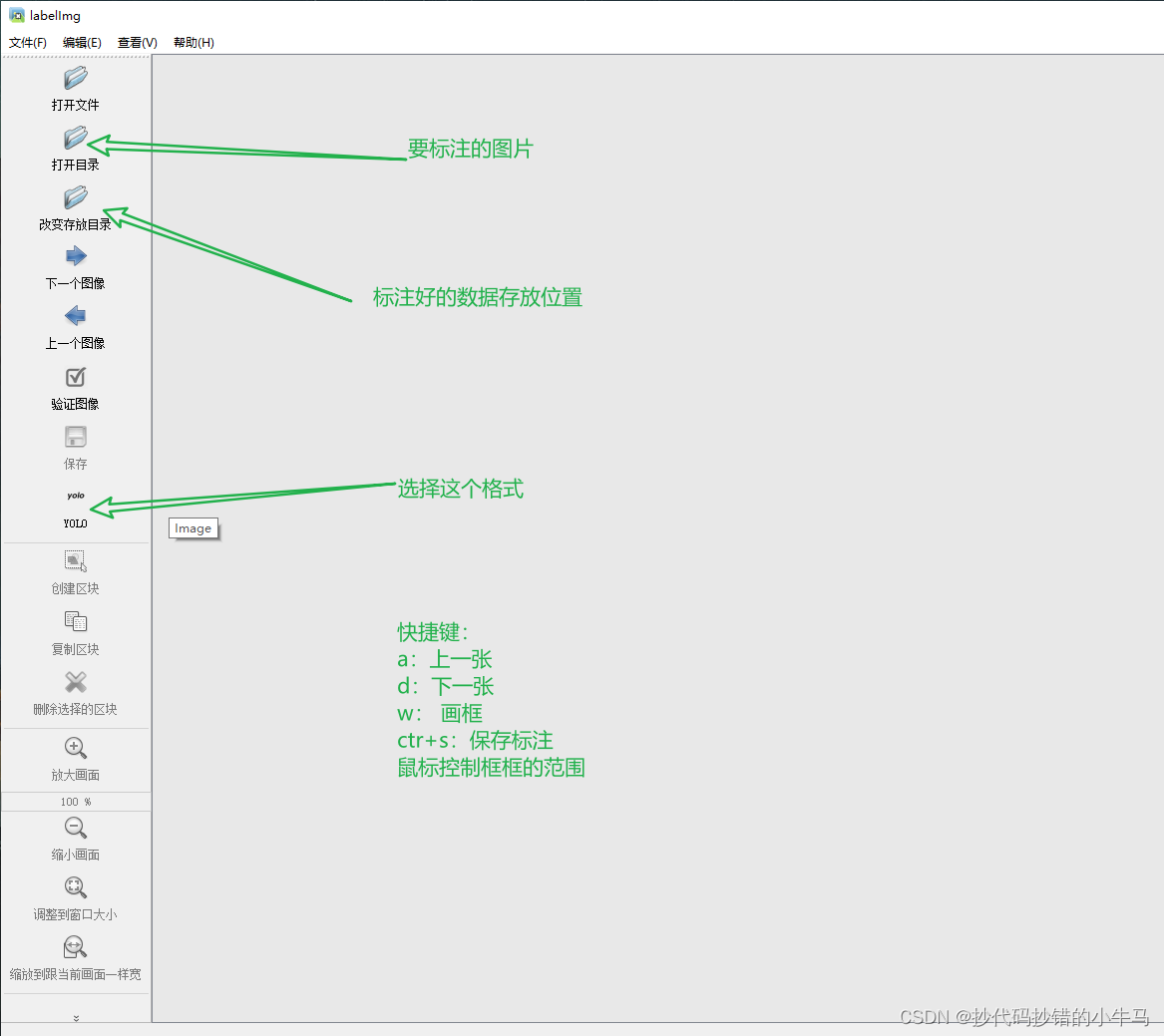
快捷键:
a:上一张
d:下一张
w: 画框
ctr+s:保存标注
鼠标控制框框的范围
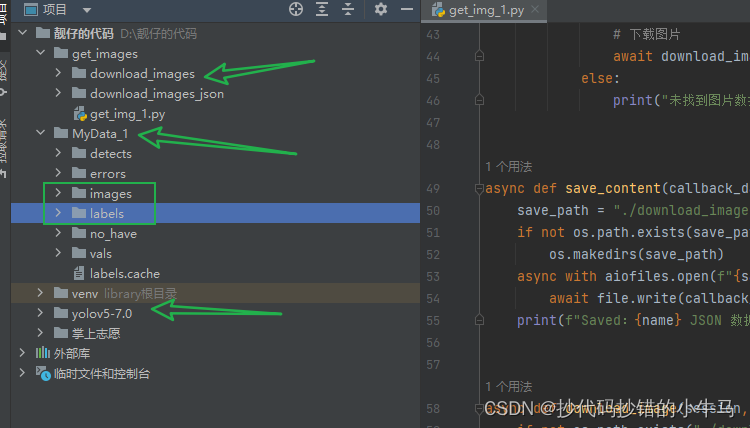
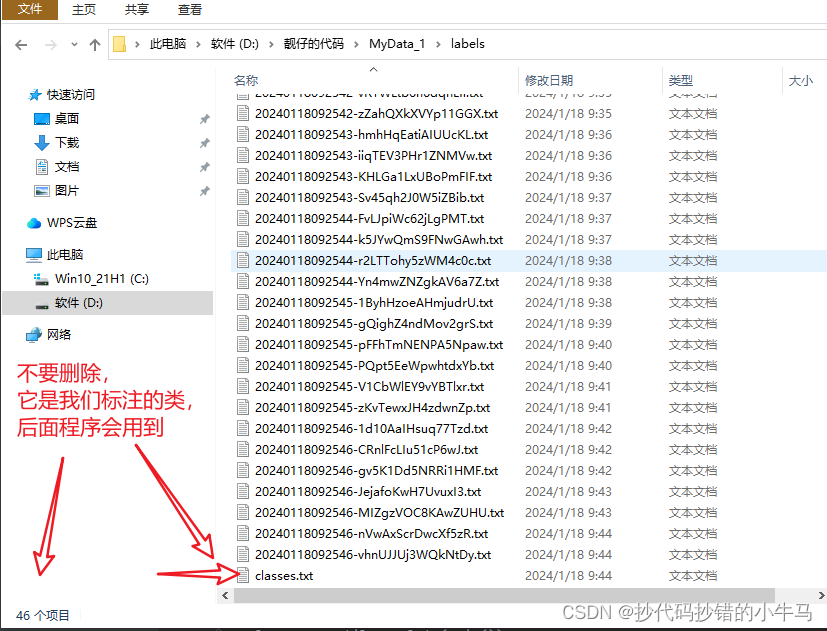
注意:先要在 yolov5-7.0 同级别下创建一个 MyData_1 文件夹(可自定义),但里面的 images 和 labels文件夹的名称最好不要改 (改了可能会报错)。先就创建这两个文件夹哈,其他的后面会介绍的。
这里的 images 是放我们上面下载的图片数据,labels 是放我们用 Labelimg 标注完成生成的东西。
如图:
标注的类,我们直接写一个 1 就 ok。
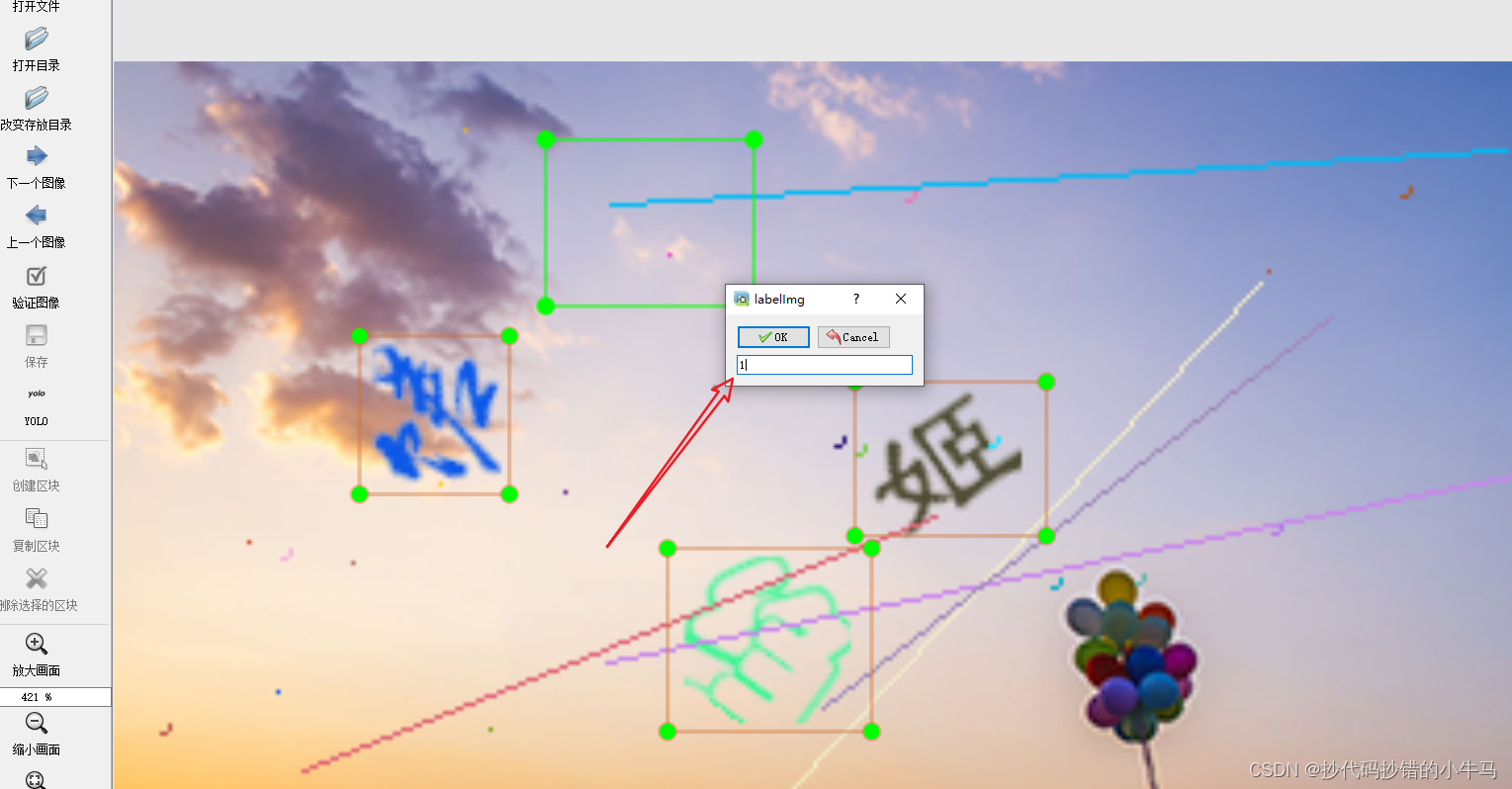
最后:准备的100张,标了 45 张就没搞了
好,数据集搞好了。准备开训
3、开始训练自己的数据集
1、train.py 训练数据集
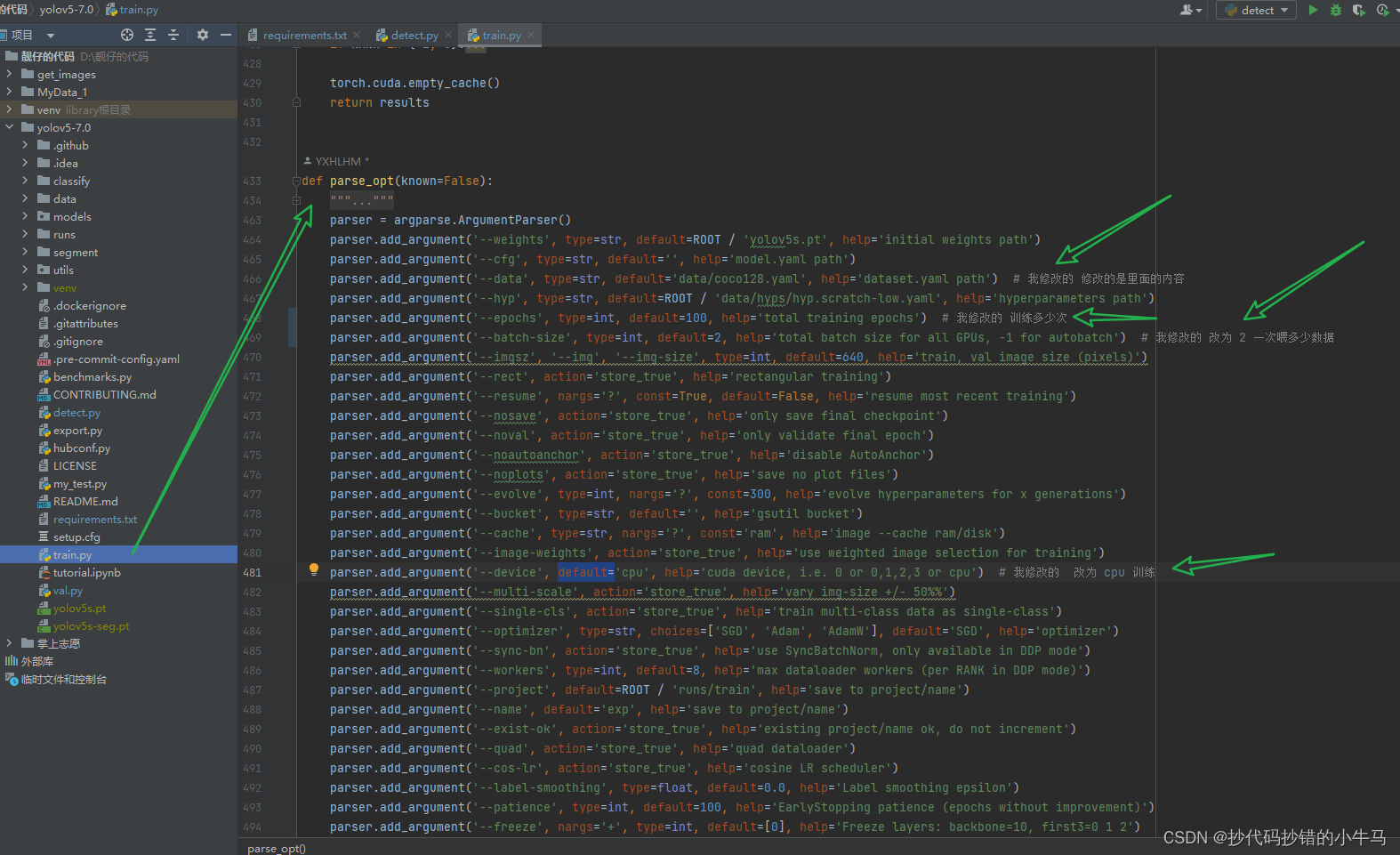
进入 train.py 文件,查看 parse_opt 方法修改配置:
def parse_opt(known=False):
"""
opt模型主要参数解析:
--weights:初始化的权重文件的路径地址
--cfg:模型yaml文件的路径地址
--data:数据yaml文件的路径地址
--hyp:超参数文件路径地址
--epochs:训练轮次
--batch-size:喂入批次文件的多少
--img-size:输入图片尺寸
--rect:是否采用矩形训练,默认False
--resume:接着打断训练上次的结果接着训练
--nosave:不保存模型,默认False
--notest:不进行test,默认False
--noautoanchor:不自动调整anchor,默认False
--evolve:是否进行超参数进化,默认False
--bucket:谷歌云盘bucket,一般不会用到
--cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
--image-weights:使用加权图像选择进行训练
--device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
--multi-scale:是否进行多尺度训练,默认False
--single-cls:数据集是否只有一个类别,默认False
--adam:是否使用adam优化器
--sync-bn:是否使用跨卡同步BN,在DDP模式使用
--local_rank:DDP参数,请勿修改
--workers:最大工作核心数
--project:训练模型的保存位置
--name:模型保存的目录名称
--exist-ok:模型目录是否存在,不存在就创建
"""
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='dataset.yaml path') # 我修改的 修改的是里面的内容
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs') # 我修改的 训练多少次
parser.add_argument('--batch-size', type=int, default=2, help='total batch size for all GPUs, -1 for autobatch') # 我修改的 改为 2 一次喂多少数据
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # 我修改的 改为 cpu 训练
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Logger arguments
parser.add_argument('--entity', default=None, help='Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
return parser.parse_known_args()[0] if known else parser.parse_args()
train.py 中我修改的配置
- –weights:初始权重,直接用 官方的
yolov5s.pt - –data:这里我们直接找到位置,进去改里面的东西就好 (把原来的全删啦)
这里的vals是放你要验证的数据:这里面要包括 图片和 对应图片的标注数据(我是直接去 images里面找的 5 张图片 和 他们对应的标注数据)后面val.py会用到的,这里先说明一下。如图:
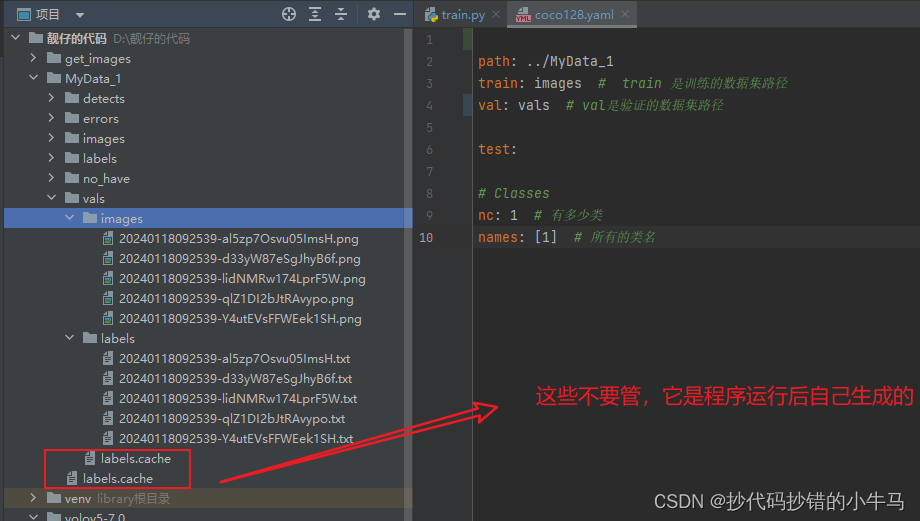
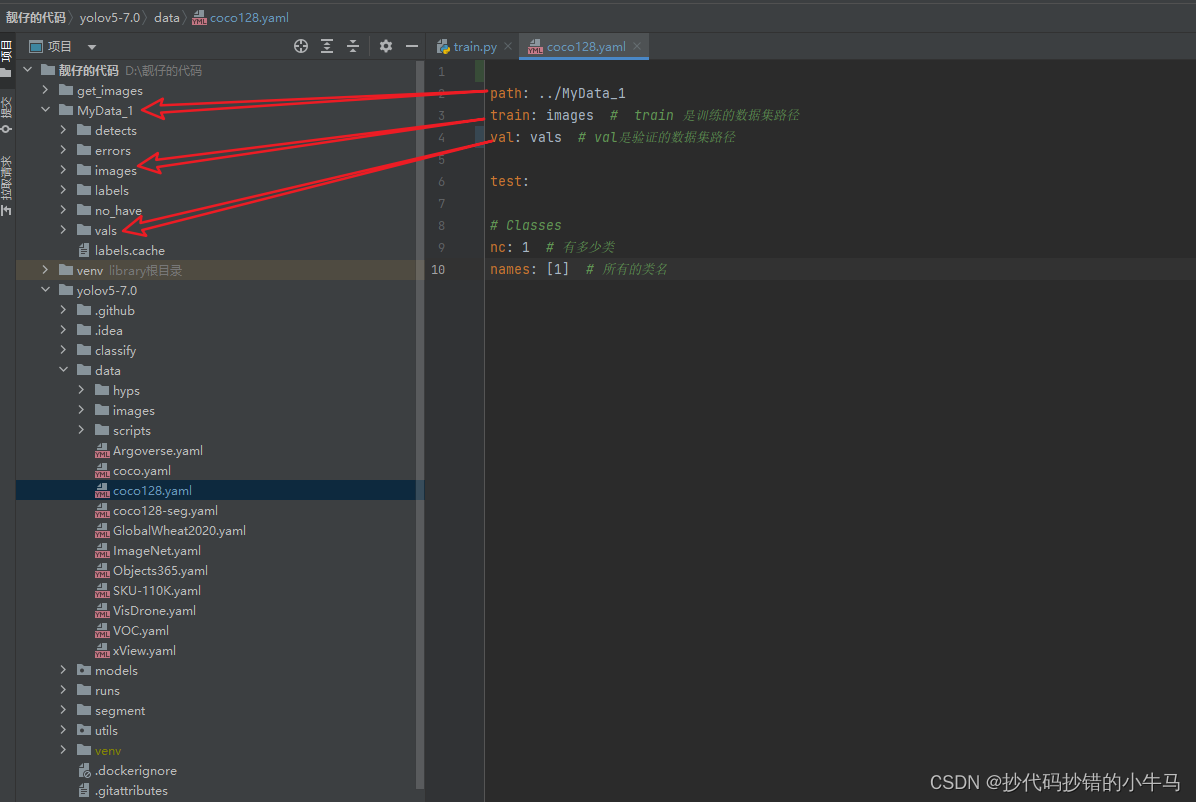
路径代码对应如下:
path: ../MyData_1
train: images # train 是训练的数据集路径
val: vals # val是验证的数据集路径
test:
# Classes
nc: 1 # 有多少类
names: [1] # 所有的类名
弄好后,直接开跑,在 train.py 里面,右键运行:没报错的话,等它停止就OK。(我 45 张图片,100轮,训了快 2 个小时。)
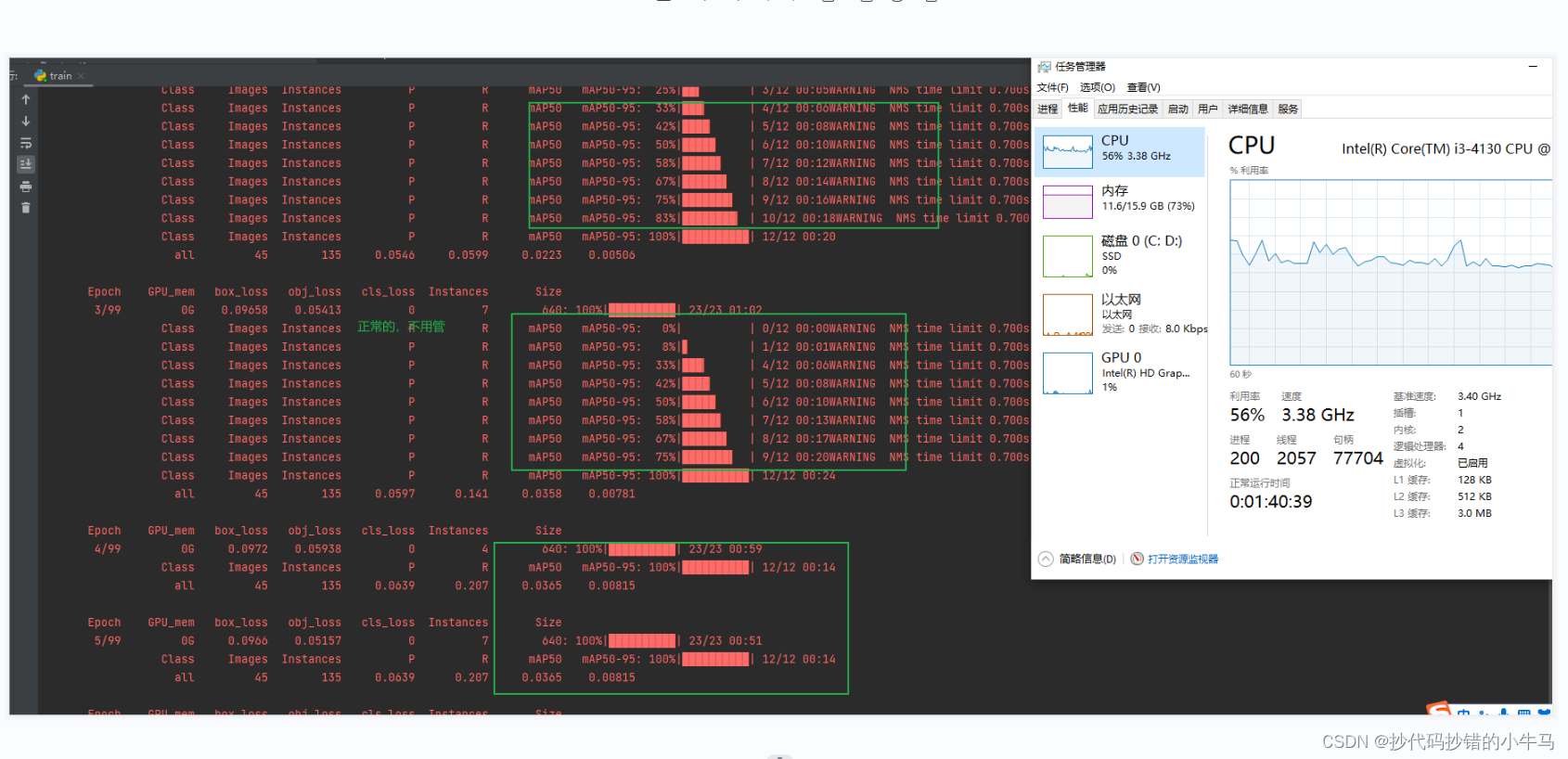
好好好,训完了就好啊,去看看给我指出的位置下有些啥子东西嘛。
这样的图看不太懂:
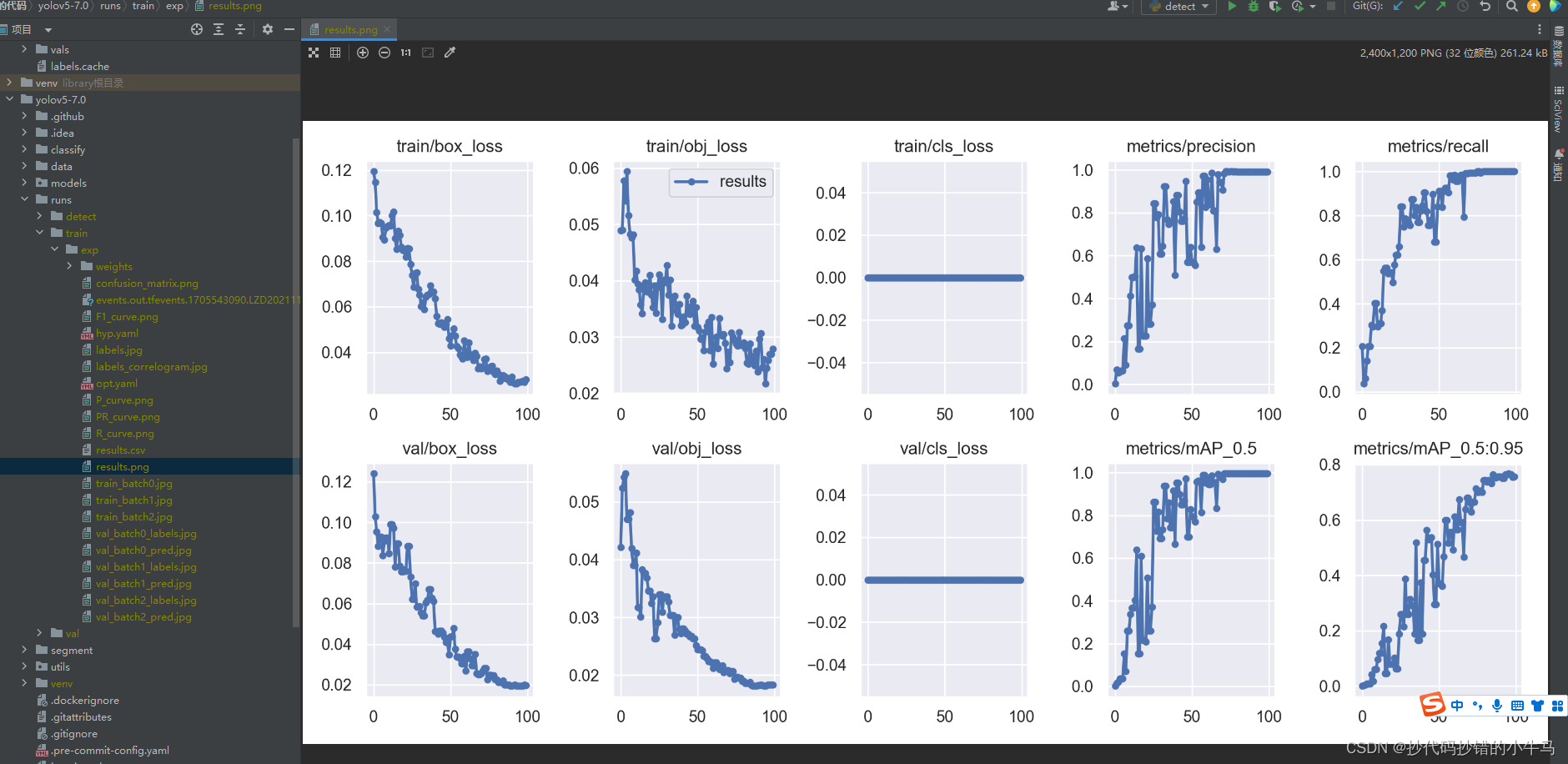
没得事,后面就会慢慢懂的,我们现在就看这些图片就OK:
1、train_batch0.jpg 这是程序训练时画的框。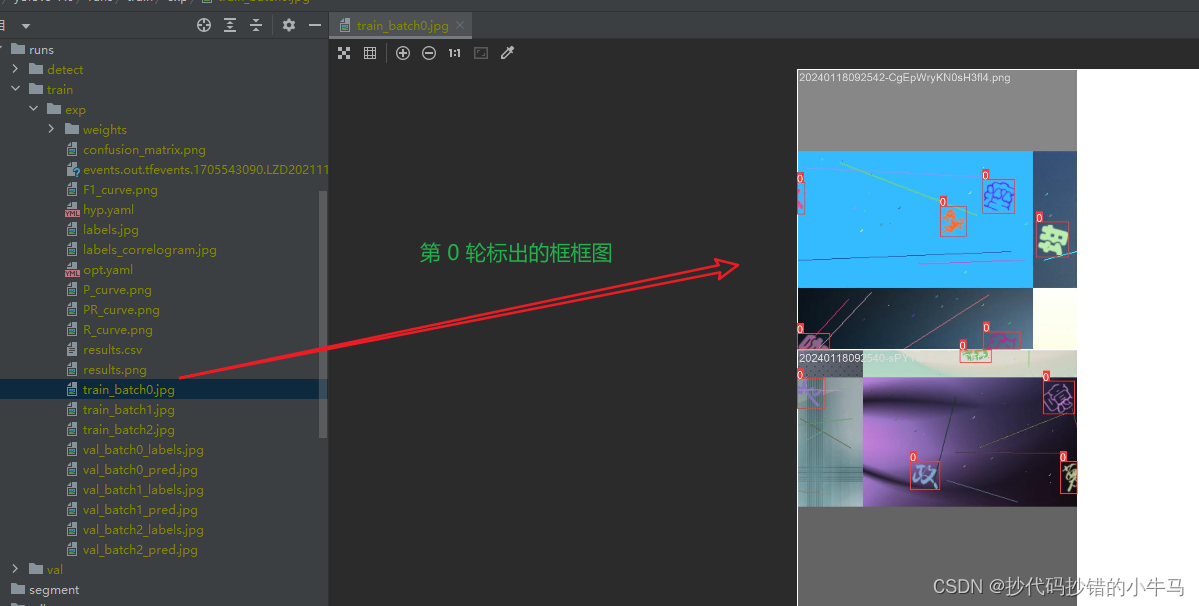 2、
2、val_batch2_labels.jpg 这张图是 我们 人工画的框框图。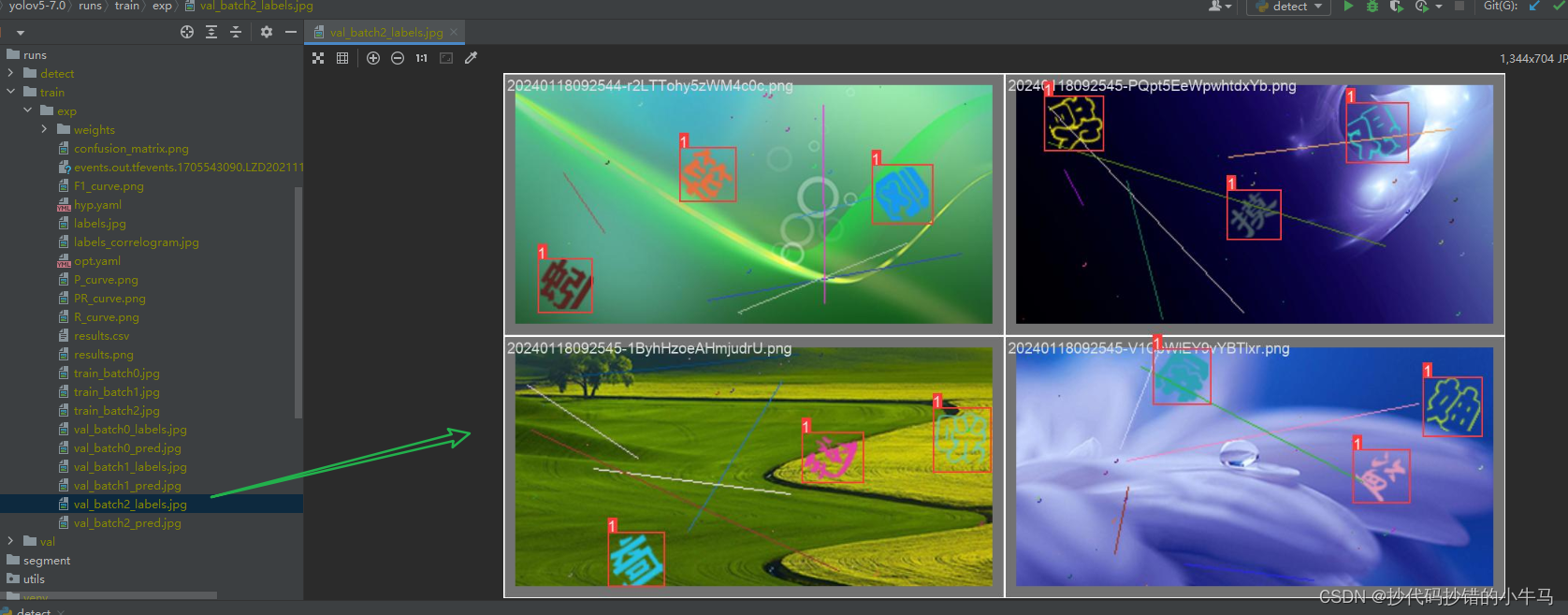
3、val_batch2_pred.jpg 这是程序模型预测识别画出来的框框图。
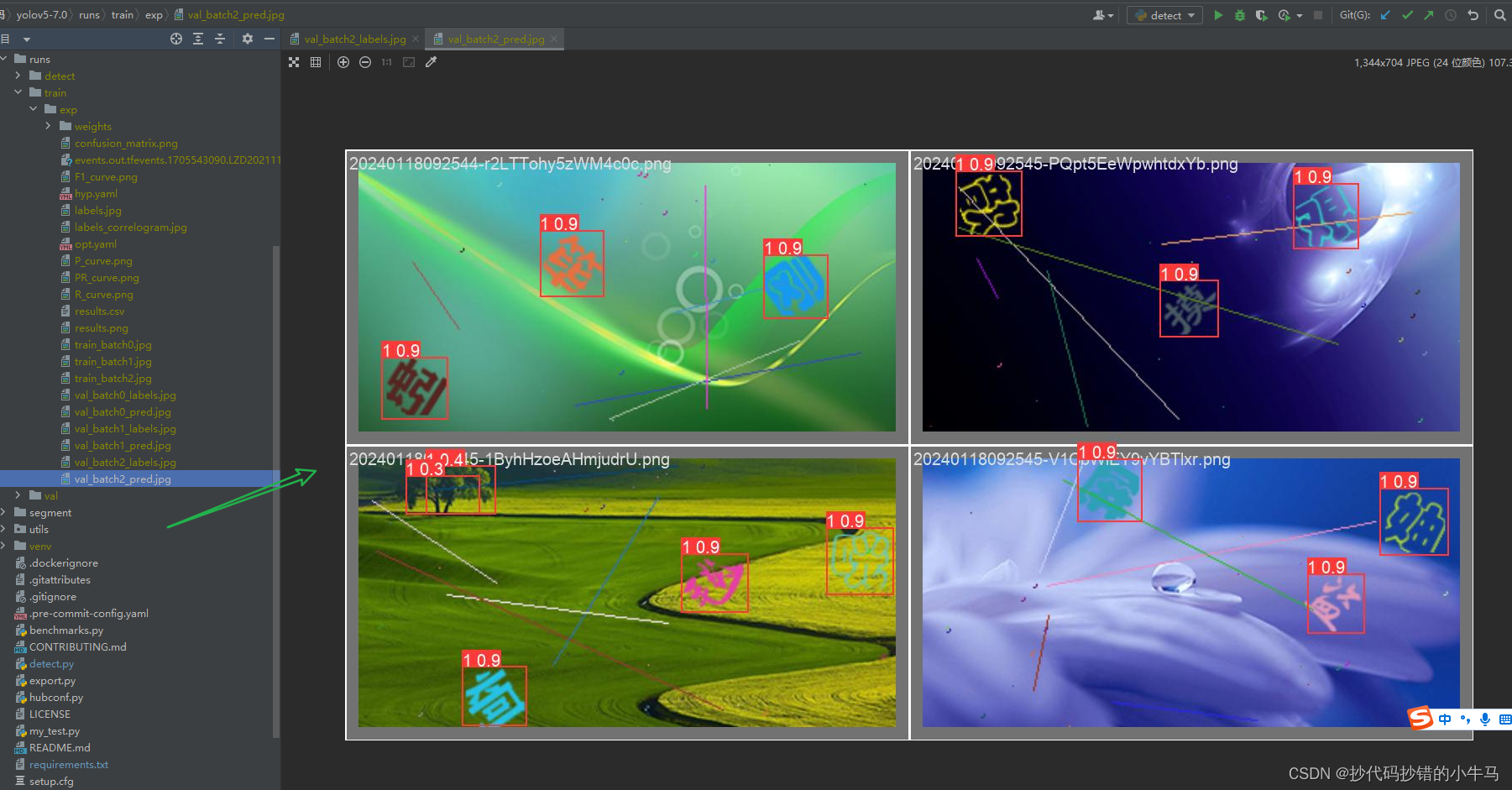
看嘛,上面的 0.3 0.4 的框框就是错的,这个 0.3 这些小数点可以理解为:程序模型画的框 与 我们人工画的框的相似度。后面可以选择 相似度 > 0.8 (或其他值)来保障识别的准确度。
初看,没得啥子问题,再看还是感觉没啥子问题… 嘿,yolov5 给了程序帮你看:val.py 是专门来验证测试你的模型的。yolov5 之前的版本叫 test.py,后面更新给改名了。
2、val.py 验证测试你的模型
测试的话是要测试图片和其标注的数据的哈,就是哪个 vals 文件夹,为了方便就直接从你训练的数据集拿一些就行的。看看我的:(都要对应好哈)
验证一下,找到 val.py 这里就 改 2 个参数,那个 weights 找到你训练完产生的模型哈,best.pt 是最佳的模型,last.pt是最好一轮的模型。
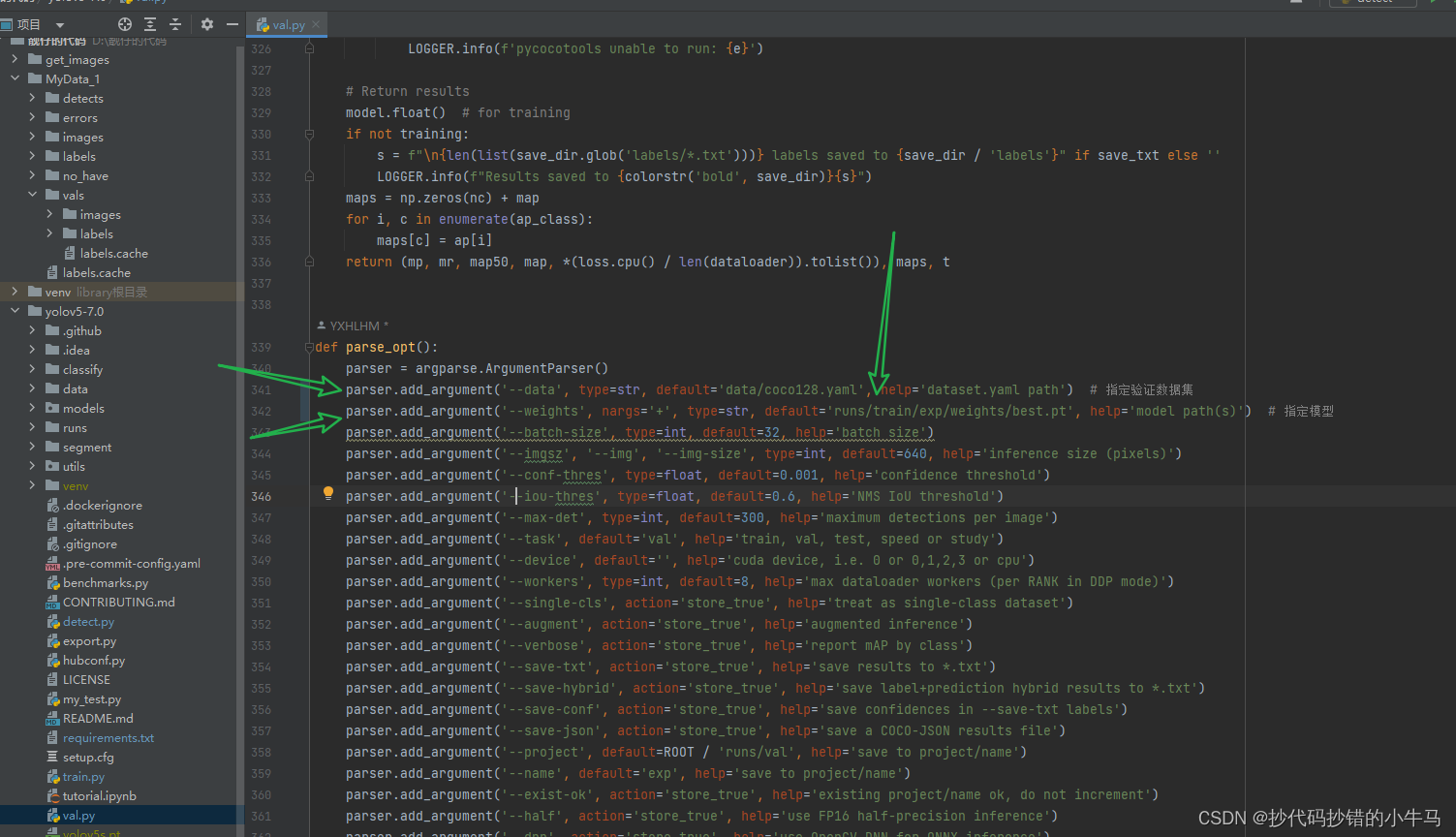
要验证的数据集 我们在 coco128.yaml 的 val 指定了的哈
改好配置后,直接在 val.py 右键润,结果:
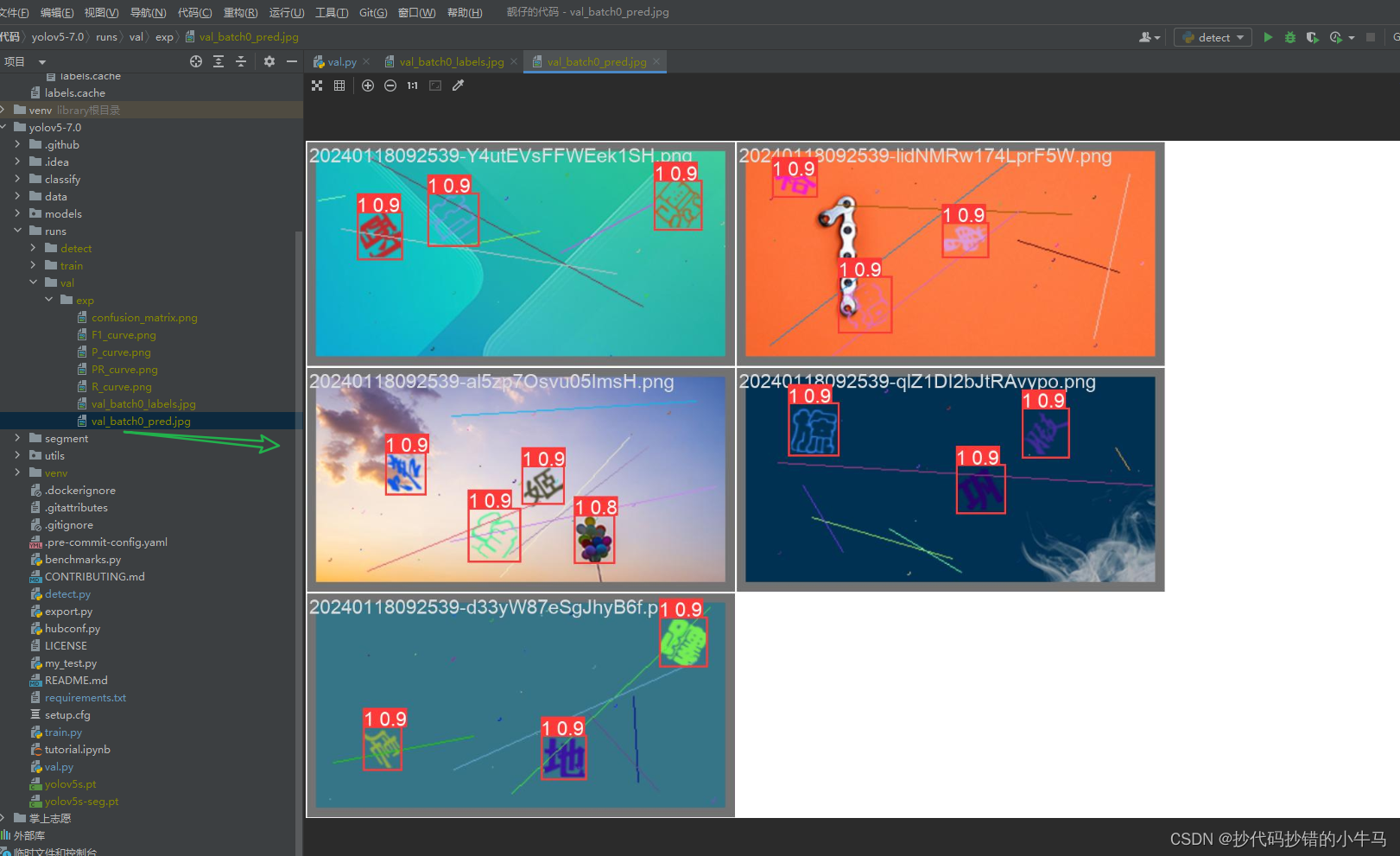
虽然只验证了 5 张,但还是能说明,训练的模型还是不错滴。( 0.8 那个框框是错的哈,还是要加大数据集的训练才更准),总的来看还是很可以的,起码文字没有少标出来。
3、detect.py 正式用你的模型
detect:查明,察觉;测出,检测,识别的意思。
直接拿一些没有出现在你训练数据集的图片,来试试。还是在之前获取训练图片的那个网站中找。
建一个文件夹:no_have。 我找了一张图片,看看训练好的模型聪不聪明,能不能画出文字的框框。
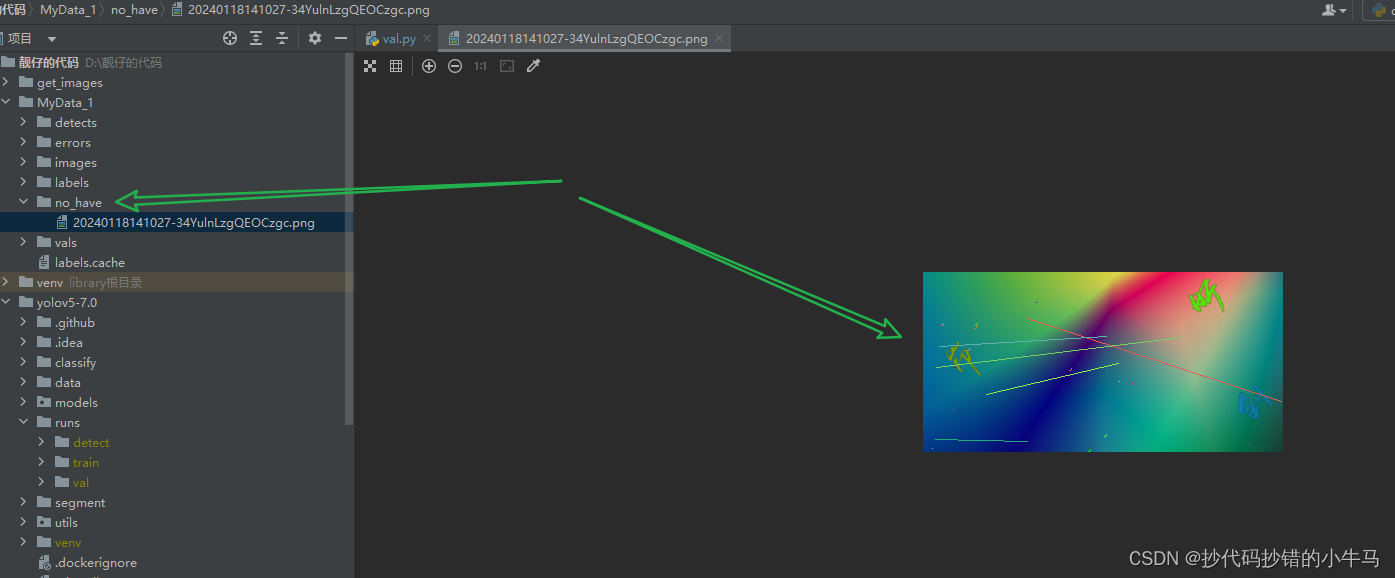
结果:
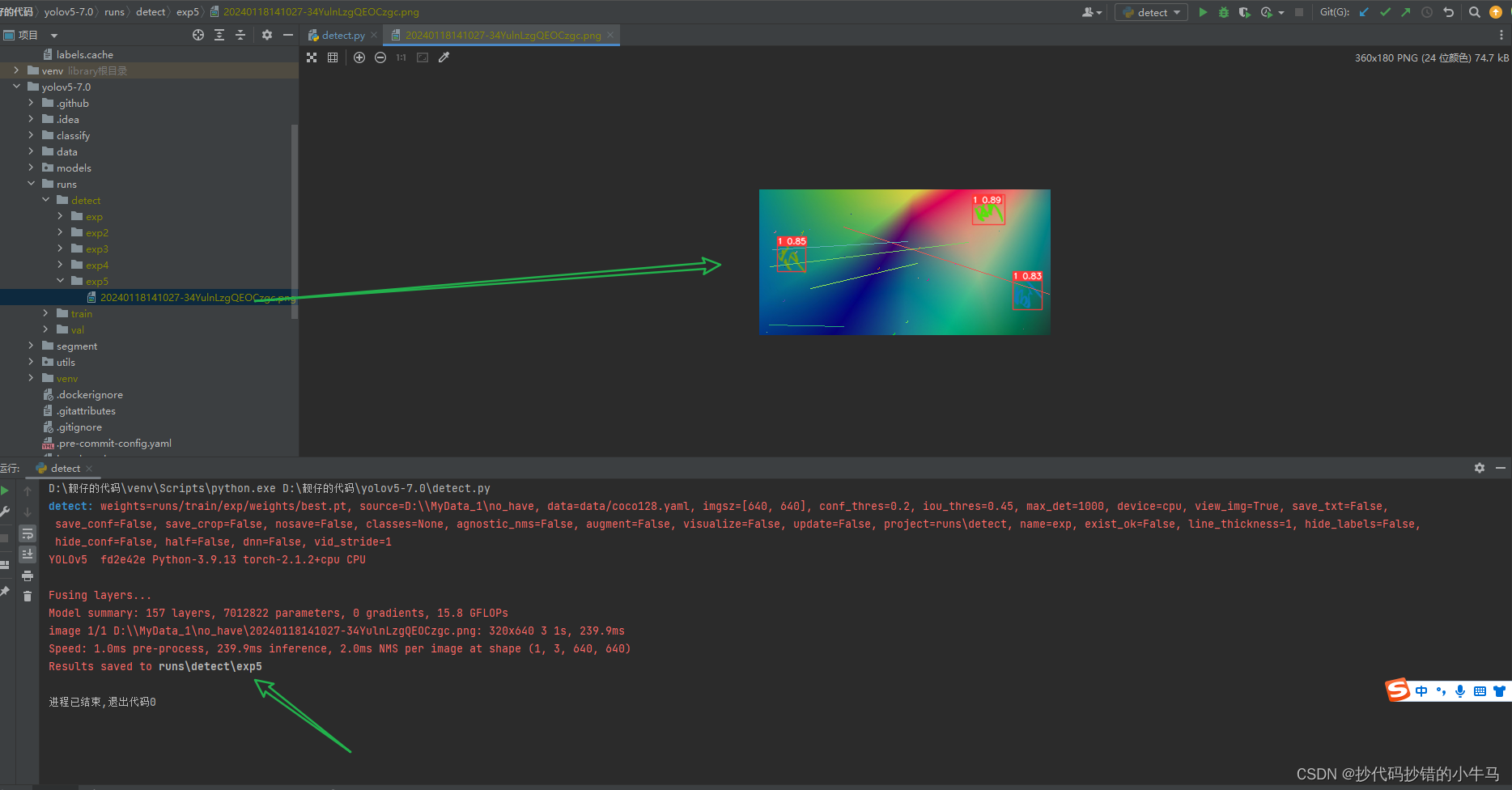
好好好, 图片上是啥子字我都不知道,结果它都给我框出来了。 very very good 不错 !!!
四、遇到的报错、踩坑
1、import git 错误
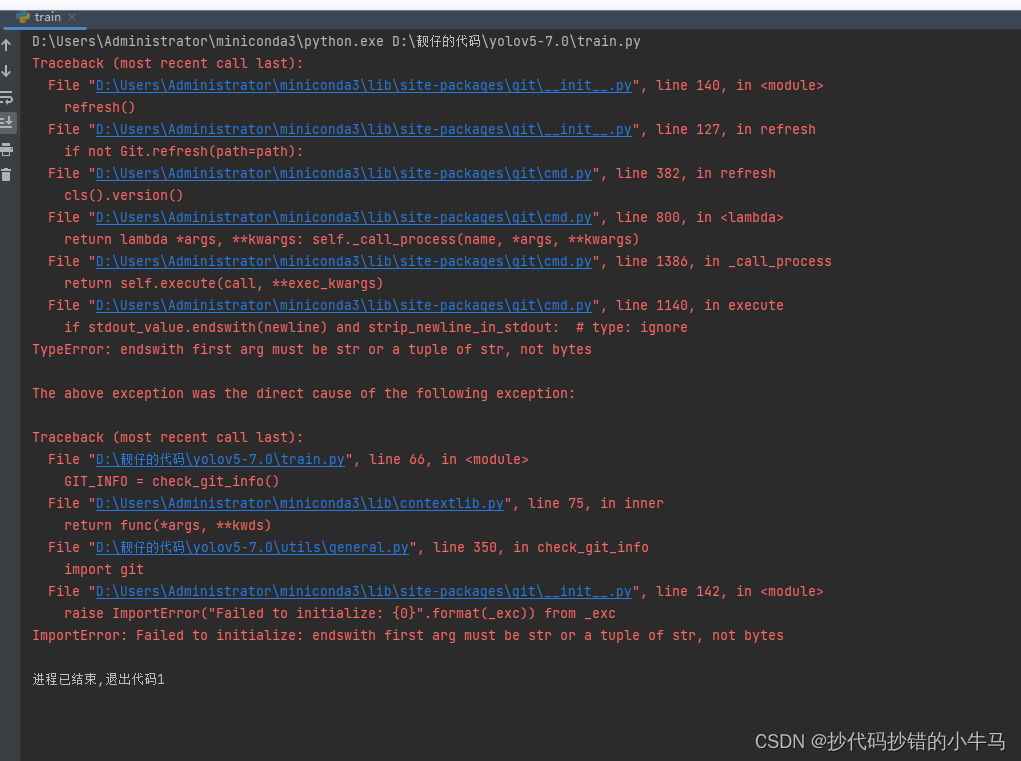
网上说加上,就能行,
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
但我还是报错,这里让我搞了好久

电脑的 git 环境也没问题,它就是错。我在另一台电脑上也是报错,那你我是直接把它报错的地方文件的代码 注释了就没问题了。(目前没发现问题)。现在的电脑我胡乱的加一些 git 环境变量再重启,它就好了
2、no detections
运行 detect.py 时 不出框框,并提示 no detections :没有检测的东西
开始是我觉得数据集训练的少了(2张图片),然后才加到 45 张图片的。结果还是报错,后来去一个一个的看参数:
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3') # 我修改的
我加了个:default=1, 把它改成:default=0, 或者 不要 default 这个参数指定就能出框(但我的类就是1啊,我改成 0 又有框,还没搞懂,再看看,后面来修改)
3、Pillow 版本过高引起的报错
参考:参考链接
降低 Pillow 版本就好
先卸载它:
pip uninstall Pillow
再指定低版本安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Pillow==9.5
好的,到这里就先结束了,下一篇就记录一下爬虫程序怎么对接训练好的模型。~ bye ~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!