Python操作Excel
Python操作Excel
一、Excel简介
? Excel是Microsoft(微软)为使用Windows和macOS操作系统开发的一款电子表格软件。Excel凭借其直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,一直以来都是最为流行的个人计算机数据处理软件。当然,Excel也有很多竞品,例如Google Sheets、LibreOffice Calc、Numbers等,这些竞品基本上也能够兼容Excel,至少能够读写较新版本的Excel文件,当然这些不是我们讨论的重点。掌握用Python程序操作Excel文件,可以让日常办公自动化的工作更加轻松愉快,而且在很多商业项目中,导入导出Excel文件都是特别常见的功能。
? Python操作Excel需要三方库的支持,如果要兼容Excel 2007以前的版本,也就是xls格式的Excel文件,可以使用三方库xlrd和xlwt,前者用于读Excel文件,后者用于写Excel文件。
? 如果使用较新版本的Excel,即操作xlsx格式的Excel文件,可以使用openpyxl库,当然这个库不仅仅可以操作Excel,还可以操作其他基于Office Open XML的电子表格文件。
? openpyxl并不支持操作Office 2007以前版本的Excel文件。
1.1 xls和xlsx和csv有什么区别
- 文件格式不同
xls是一个特有的二进制格式,其核心结构是复合文档类型的结构,而xlsx的核心结构是XML类型的结构,采用的是基于XML的压缩方式,使其占用的空间更小。xlsx中最后一个x的意义就在于此。
- 版本不同
xls是Excel 2007及以前版本生成的文件格式。xlsx是Excel 2007及以后版本生成的文件格式。
- 兼容性不同
xlsx格式是向下兼容的,可兼容xls格式。
- csv是文本文件,用记事本就能打开。
1.2 安装第三方库
1.2.1 库的分类
-
系统模块
- 是Python自带的模块,无需安装可以直接导入使用,如:math,random,csv,json,pickle,string…
-
自定义模块
- 自定义的py文件就是一个模块,需要先创建文件,再导入
-
第三方模块
- 需要先安装,然后再去使用,如:xlwt,xlrd,openpyxl…
1.2.2 Pycharm中安装
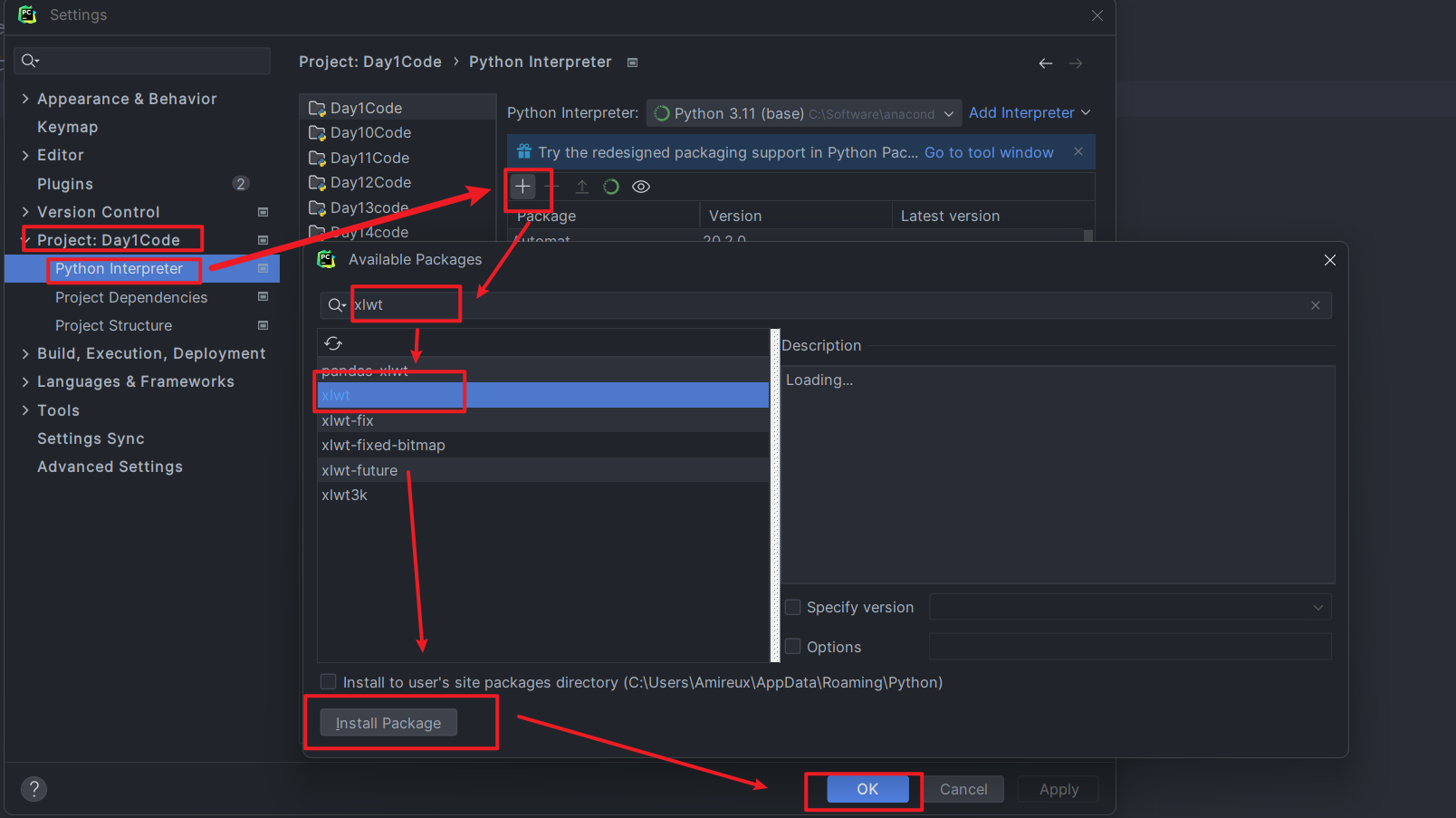
- 按住
Ctrl+Shift+S,打开菜单,然后再左侧的菜单中选择Project:xxx,然后选择Project Interpreter,再点击右侧的+,在新窗口中输入要安装的库名,并选择,最后点击Install Package,然后OK
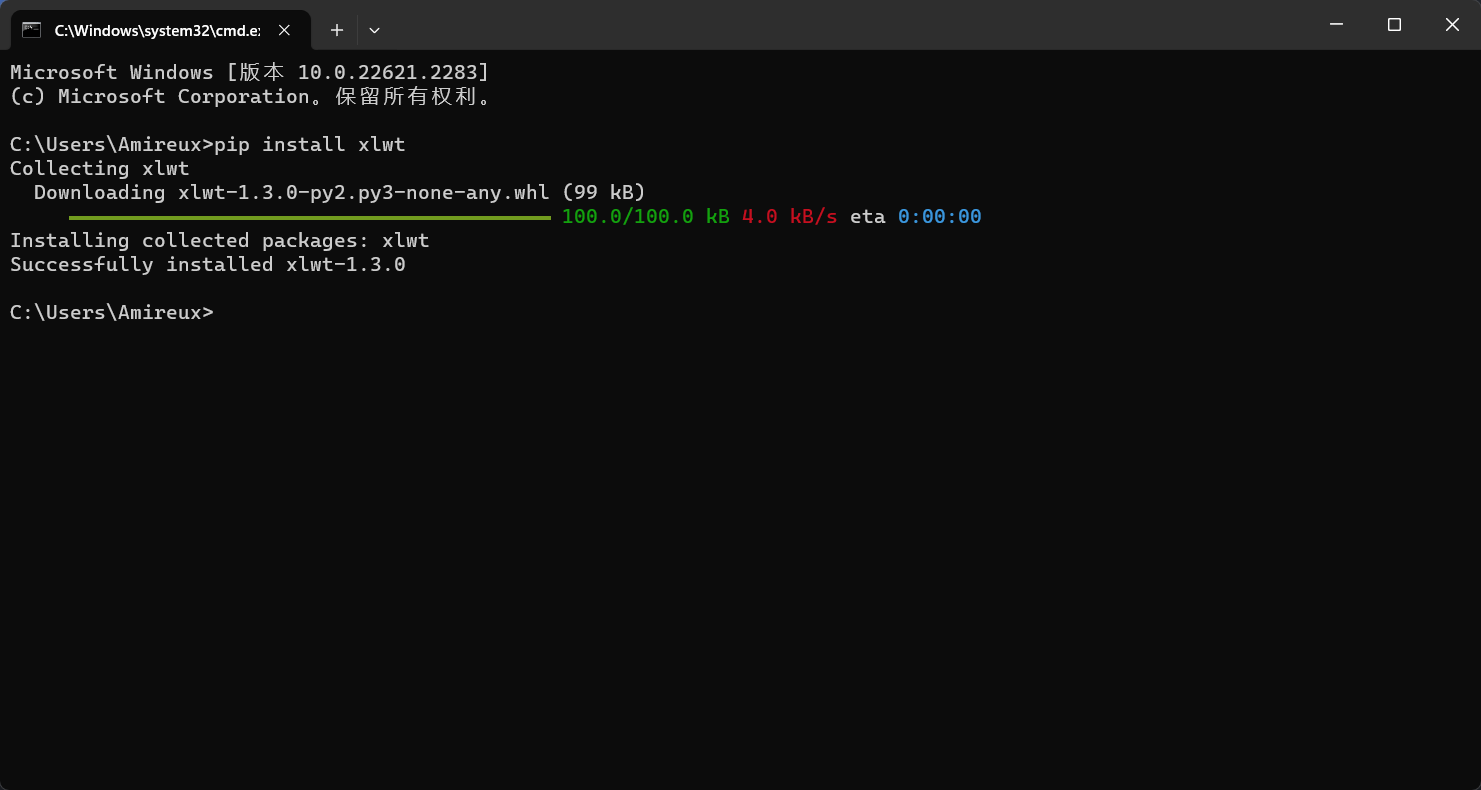
1.2.3 命令行安装
打开cmd窗口,输入pip install xxx,安装,该方式默认安装最新版,
制定版本安装:pip install xxx==1.4.1
二、操作xls格式的Excel文件
做了解
2.1 读取Excel文件
例:在当前工程的data文件夹下有一个名为阿里巴巴2020年股票数据.xls的Excel文件,如果想读取并显示该文件的内容,可以通过如下所示的代码来完成。
- 导入
xlrd包
import xlrd
- 打开Excel文件,得到一个工作簿对象
wb = xlrd.open_workbook(r"data/阿里巴巴2020年股票数据.xls")
print(wb) # <xlrd.book.Book object at 0x0000024CBAEE5190>
打印结果是一个工作簿对象
- 获取工作簿中的工作表名
sheet_names = wb.sheet_names()
print(sheet_names) # ['股票数据', 'test1', 'test2']
-
获取工作表对象
- 方法一:根据工作表名称获取对象
sheet1 = wb.sheet_by_name("股票数据") print(sheet1) # Sheet 0:<股票数据> print(type(sheet1)) # <class 'xlrd.sheet.Sheet'>,类型为工作表对象- 方法二:根据索引获取对象
sheet2 = wb.sheet_by_index(0) print(sheet2) # Sheet 0:<股票数据> -
获取单元格对象
- xlrd和xlwt的操作中:
row(行),在Excel中,索引为1、2、3、4。。。;对应Python中索引为0、1、2、3。。。col(列),在Excel中,索引为A、B、C、D。。。;对应Python中索引为0、1、2、3。。。- 语法:
sheet.cell(row,col)
- xlrd和xlwt的操作中:
cell1 = sheet1.cell(0, 0) # 对应单元格A1
print(cell1) # text:'Date'
print(type(cell1)) # <class 'xlrd.sheet.Cell'>,类型为单元格对象
-
获取单元格的值
- 方式一:先获取单元格对象,在通过
Value属性访问单元格的值
cell = sheet1.cell(0, 0) v1 = cell.value print(v1) # Date print(type(v1)) # <class 'str'>- 方式二:直接调用
cell_value(row,col)方法取值
v2 = sheet1.cell_value(0, 0) print(v2) # Date print(type(v2)) # <class 'str'> - 方式一:先获取单元格对象,在通过
-
获取某行的某几列的数据
- 方法一:调用
row_values(row,col1,col2)方法,获取row行的col1到col2的数据,左闭右开,返回结果是一个列表,其中的元素是字符串
result1 = sheet1.row_values(0, 0, 2) print(result1) # ['Date', 'High'] print(type(result1)) # <class 'list'>- 参数col1和col2可以省略,即结果为返回某行的数据
result2 = sheet1.row_values(0) print(result2) # ['Date', 'High', 'Low', 'Open', 'Close', 'Volume', 'Adj Close']- 方法二:调用
row_slice(row,col1,col2)方法,获取row行的col1到col2的数据,左闭右开,返回结果是一个列表,其中的元素是单元格对象
result3 = sheet1.row_slice(0, 0, 2) print(result3) # [text:'Date', text:'High'] print(type(result3)) # <class 'list'>- 同理,参数col1和col2可以省略,即结果为返回某行的数据
result4 = sheet1.row_slice(0) - 方法一:调用
2.2 写入Excel文件
? 写入Excel文件可以通过xlwt 模块的Workbook类创建工作簿对象,通过工作簿对象的add_sheet方法可以添加工作表,通过工作表对象的write方法可以向指定单元格中写入数据,最后通过工作簿对象的save方法将工作簿写入到指定的文件或内存中。
- 导入
xlwt包
import xlwt
- 创建一个新的空的工作簿对象
wb = xlwt.Workbook()
- 向工作簿中添加一张工作表,返回工作表对象
sheet = wb.add_sheet("学生信息表")
-
向工作表中写入数据
- 写法一:直接写入;语法:
sheet.write(row,col,value)
sheet.write(0, 0, "name") sheet.write(0, 1, "age") sheet.write(0, 2, "score")- 写法二:
for循环写入
title_list = ["name", "age", "score"] for i in range(len(title_list)): sheet.write(1, i, title_list[i]) - 写法一:直接写入;语法:
-
保存工作簿
wb.save(r"data/Student.xls")
三、操作xlsx格式的Excel文件
? openpyxl库用于操作2007年之后的office软件。主要指用于操作.xlsx文件
? 安装命令:
pip install openpyxl
? openpyxl的优点在于,当我们打开一个Excel文件后,既可以对它进行读操作,又可以对它进行写操作,而且在操作的便捷性上是优于xlwt和xlrd的。此外,如果要进行样式编辑和公式计算,使用openpyxl也远比上一个章节我们讲解的方式更为简单,而且openpyxl还支持数据透视和插入图表等操作,功能非常强大。
注意:有一点需要再次强调,openpyxl并不支持操作Office 2007以前版本的Excel文件。
3.1 概念简述
- 对象
| 对象名 | 说明 |
|---|---|
| Workbook | 代表一个Excel工作薄,即文件 |
| Worksheet | 代表一个Excel工作薄中的一页(sheet),即工作表 |
| Cell | 代表最简单的一个单元格 |
Workbook对象涉及属性
| Workbook对象的属性 | 说明 |
|---|---|
| active | 获取当前活跃的Worksheet,即工作簿关闭前的那一个工作表 |
| worksheets worksheets[index] | 以列表的形式返回所有Worksheet 以列表的形式返回制定索引的Worksheet |
| read_only | 判断是否以read_only模式打开excel文档 |
| encoding | 获取文档的字符集编码 |
| properties | 获取文档的元数据,如标题、创建者、创建日期等 |
Workbook对象涉及方法
| Workbook 对象的方法 | 说明 |
|---|---|
| get_sheet_names | 获取所有工作表的名称(该方法已经被废弃,推荐使用:通过Workbook 的sheetnames 属性即可获取) |
| get_sheet_by_name | 通过工作表名称获取WorkSheet对象(该方法已经被废弃,推荐使用:通过Worksheet[‘表名’]获取) |
| get_active_sheet | 获取活跃的工作表 |
| remove_sheet | 删除一个工作表 |
| create_sheet | 创建一个工作表 |
| copy_worksheet | 在Workbook 内复制工作表 |
Worksheet对象涉及属性
| Worksheet 对象的属性 | 说明 |
|---|---|
| title | 工作表的标题 |
| dimensions | 表示工作表的大小,这里的大小是指数据的工作表大小,即,左上角的坐标和右下角的坐标 |
| max_row | 工作表最大行数 |
| min_row | 工作表最小行数 |
| max_column | 工作表最大列数 |
| min_column | 工作表最小列数 |
| rows | 按行获取单元格 |
| columns | 按列获取单元格 |
| freeze_panes | 冻结窗口 |
| values | 按行获取工作表内容 |
Worksheet对象涉及相关方法
| Worksheet 对象的相关方法 | 说明 |
|---|---|
| iter_rows | 按行获取所有单元格,内置属性有:min_row、max_row、min_col和max_col |
| iter_columns | 按列获取所有单元格 |
| append | 在工作表末尾添加数据 |
| merged_cells | 合并多个单元格 |
| unmerged_cells | 移除合并的单元格 |
Cell对象涉及属性和方法
| Cell 对象的属性 | 说明 |
|---|---|
| row | 单元格所在的行 |
| column | 单元格所在的列 |
| value | 单元格的值 |
| coordinate | 单元格的坐标 |
-
openpyxl中cell方法的行索引和列索引
-
需要提醒大家一点,
openpyxl获取指定的单元格有两种方式,一种是通过**cell方法**,需要注意,该方法的行索引和列索引都是从1开始的,这是为了照顾用惯了Excel的人的习惯;另一种是通过索引运算,通过指定单元格的坐标,例如C3、G255,也可以取得对应的单元格,再通过单元格对象的value属性,就可以获取到单元格的值。通过上面的代码,相信大家还注意到了,可以通过类似sheet['A2:C5']或sheet['A2':'C5']这样的切片操作获取多个单元格,该操作将返回嵌套的元组,相当于获取到了多行多列。 -
openpyxl中cell方法的行索引和列索引都是从1开始的;区别于xlrd和xlwt中是从0开始的
-
xlrd和xlwt中
row: Excel: 1 2 3 4 ..... Python:0 1 2 3 .... col: Excel:A B C D.... Python:0 1 2 3.... -
openpyxl
row: Excel: 1 2 3 4 ..... Python:1 2 3 4 ..... col: Excel:A B C D.... Python:1 2 3 4 .....
-
-
3.2 读取Excel文件
例:在当前工程的data文件夹下有一个名为阿里巴巴2020年股票数据.xlsx的Excel文件,如果想读取并显示该文件的内容,可以通过如下所示的代码来完成。
- 导入
openpyxl包
import openpyxl
- 获取左右工作表名称
sheet_list = wb.sheetnames
print(sheet_list) # ['股票数据']
-
获取找工作表对象
- 方法一:获取指定索引处的工作表对象
- wb.worksheets:获取一个列表,其中的元素是工作表对象
sheet1 = wb.worksheets[0] print(sheet1) # <Worksheet "股票数据">- 方法二:active获取工作簿中活跃的工作表对象、
sheet2 = wb.active print(sheet2) # <Worksheet "股票数据">- 方法四:wb[工作表的名称]
sheet3 = wb["股票数据"] print(sheet3) # <Worksheet "股票数据"> - 方法一:获取指定索引处的工作表对象
-
获取工作表的行数和列数(范围)
- 获取工作表的最大行数和最大列数
max_row = sheet1.max_row max_column = sheet1.max_column print(max_row, max_column) # 255 7- 获取工作表的大小,这里的大小是指数据的工作表大小,即,左上角的坐标和右下角的坐标
dimensions = sheet1.dimensions print(dimensions) # A1:G255 -
获取单元格对象
- 方法一:索引获取
cell1 = sheet1["A1"] print(cell1) # <Cell '股票数据'.A1>- 方法二:cell(row,col)获取
cell2 = sheet1.cell(1, 1) print(cell2) # <Cell '股票数据'.A1> -
获取单元格的值
print(cell1.value) # Date
-
获取指定行
- 获取第一行
row = sheet1[1] print(row)结果为元组类型,其中的元素为单元格对象
- 获取单元格中的值
for i in row: print(i.value) -
获取指定列
获取行和列的方式一样
- 获取“A”列数据
col = sheet1["A"] print(col)结果为元组类型,其中的元素为单元格对象
- 获取单元格中的值
for i in col: print(i.value) -
获取多行多列
- 获取A2到C8的数据
cells = sheet1["A2:C8"] print(cells)结果为元组类型,二维元组
- 遍历获取单元格中的值
for row in cells: # 获取每行 for cell in row: # 获取每行中的列 print(cell.value)
3.3 写入Excel文件
注意:当写入数据的时候,一定要保证目标文件处于关闭状态,否则会报权限被拒绝错误
- 导入
openpyxl包
import openpyxl
-
创建工作簿
- 当创建一个工作簿时,会默认自动创建一张工作表
wb = openpyxl.Workbook() print(wb.sheetnames) # ['Sheet']- 修改工作表名
sheet = wb["Sheet"] sheet.title = "学生表" print(wb.sheetnames) # ['学生表'] -
工作表的修改
- 创建工作表
wb.create_sheet() wb.create_sheet() print(wb.sheetnames) # ['学生表', 'Sheet', 'Sheet1']- 复制表
sheet2 = wb["学生表"] wb.copy_worksheet(sheet2) print(wb.sheetnames) # ['学生表', 'Sheet', 'Sheet1', '学生表 Copy']- 删除表
sheet23 = wb["Sheet"] wb.remove(sheet23) print(wb.sheetnames) # ['学生表', 'Sheet1', '学生表 Copy'] -
单元格的修改
- 以学生表为例
sheet3 = wb["学生表"]-
给单元格添加数据
- 方式一:索引的方式
sheet3["A1"] = "姓名" sheet3["B1"] = "性别" sheet3["C1"] = "成绩"- 方式二:sheet.cell(row,col,value)方法
sheet3.cell(1, 4, "爱好") -
追加一行数据
sheet3.append(["张三", "male", 100, "唱歌"])- 追加多行
studentslist = [ ['张三', 'male', 100, '唱歌'], ['小李', 'male', 75, '跳舞'], ['张三1', 'female', 88, '弹琴'], ['小明', 'female', 99, '打球'], ['小花', 'male', 60, '跳绳'], ['张三2', 'female', 66, '唱歌'] ] for stu in studentslist: sheet.append(stu) -
保存工作簿
wb.save(r"data/test01.xlsx")
3.4 练习
3.4.1 练习一
获取student-score.xlsx中"成绩表"中有哪些小学,总共有几个小学
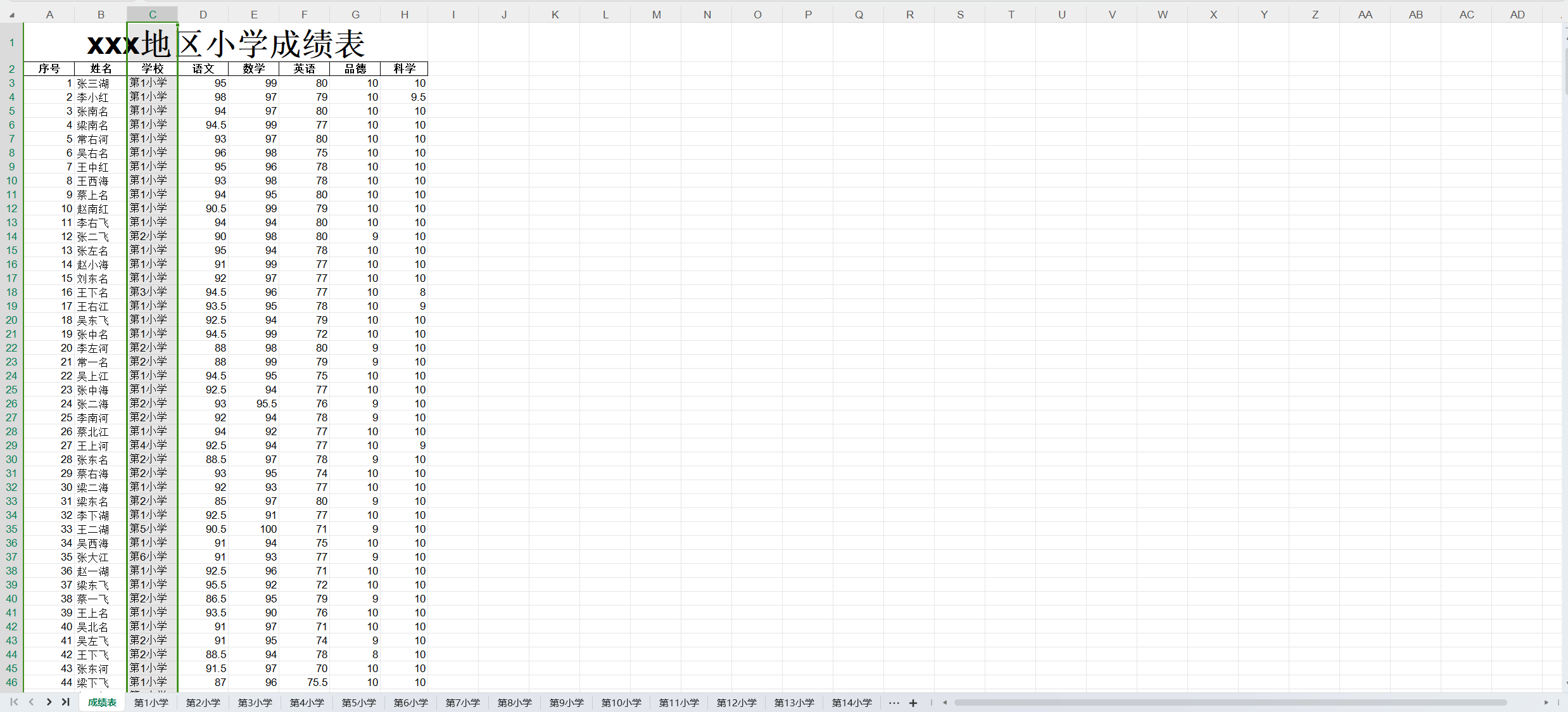
# 导入包
import openpyxl
wb = openpyxl.load_workbook(r"data/student-score.xlsx")
sheet = wb["成绩表"]
c_col = sheet["C"][2:]
print(c_col)
school_name = set([cell.value for cell in c_col])
print(sorted(school_name))
print(len(school_name))
分析:导入包,调用load_workbook方法打开文件,然后通过wb["成绩表"]获取工作表,通过sheet["C"]获取单元格对象,因为实际数据从第三行开始,所以使用切片,选取第三列及几下的数据。因获取的元素为单元格对象,所以通过列表推导式,获取单元格中的元素,在利用元组中元素不允许相同的特性,进行筛选,最后打印输出
3.4.2 练习二
有一个文件练习数据.xlsx,其中的数据如下
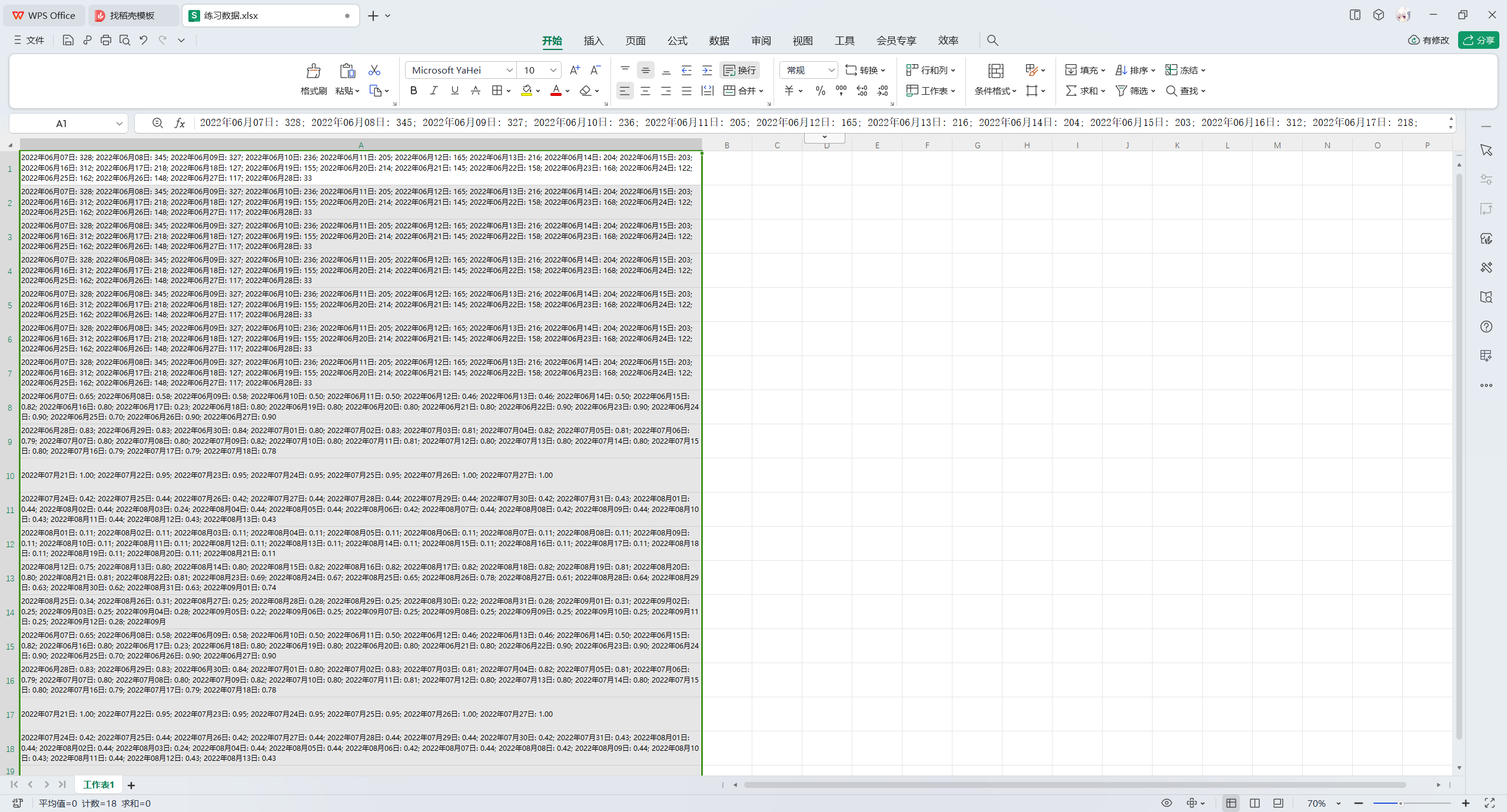
现在需要将其单元格中的数据进行拆分,拆分后的结果如下:
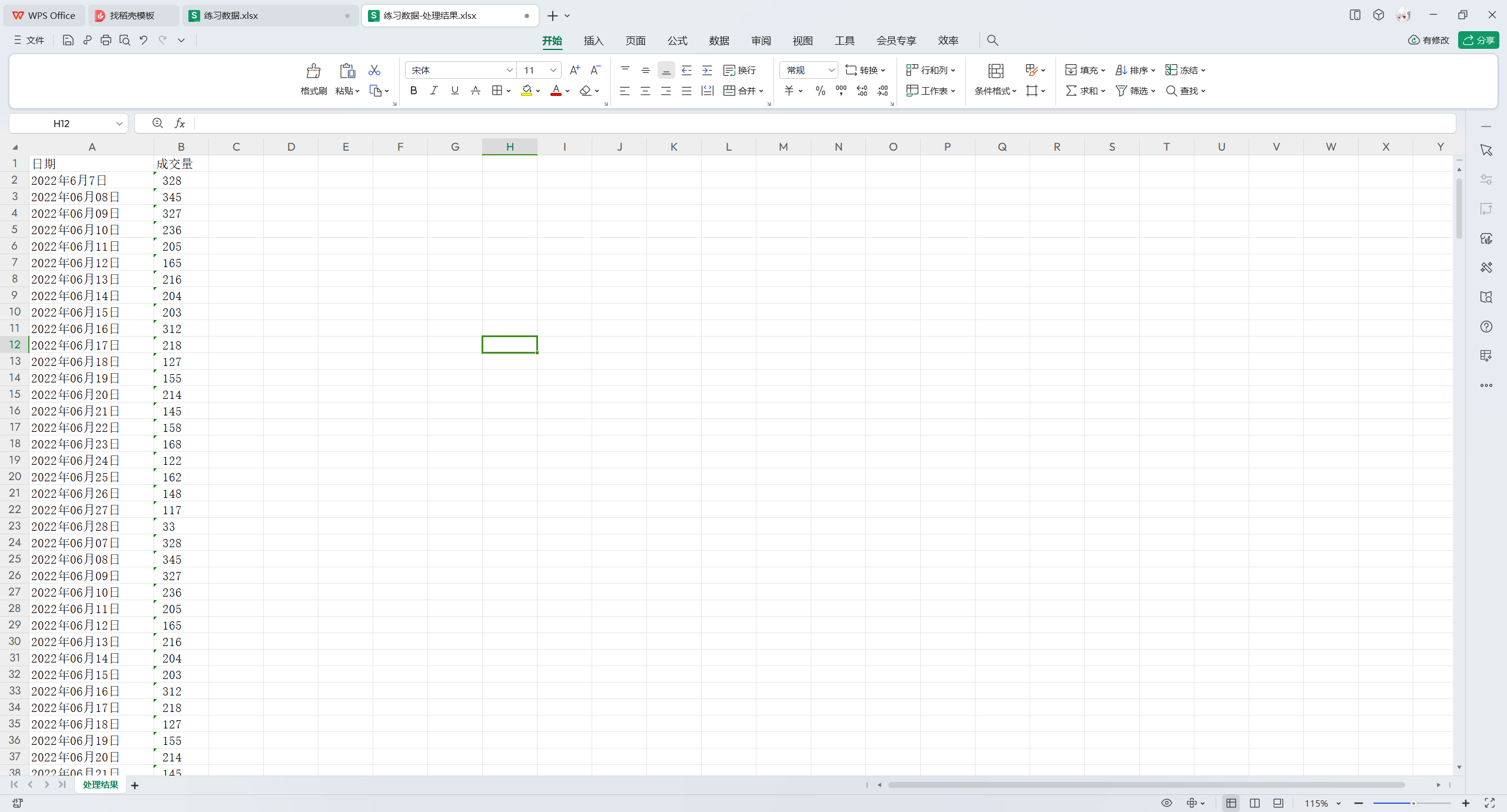
# 导入包
import openpyxl
# 打开文件并处理
wb = openpyxl.load_workbook(r"data/练习数据.xlsx")
# 选择工作表
sheet = wb.active
col = sheet["A"]
# print(col)
data_list = []
for item in col:
# print(item.value)
list1 = item.value.split(";")
for i in list1:
data = i.strip().split(":")
data_list.append(data)
# 写入到一个新的工作簿中
wb2 = openpyxl.Workbook()
sheet2 = wb2.active
sheet2.title = "处理结果"
sheet2.append(["时间", "成交量"])
for item in data_list:
sheet2.append(item)
wb2.save(r"data/练习数据-处理结果.xlsx")
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024.1.23(347.前k个高频元素)
- 新手搭建知识付费平台必备攻略:如何以低成本实现高转化?
- 34_输入设备键盘鼠标你得会
- Centos7笔记09之nginx反向代理grafana
- 毕业设计|基于SpringBoot+Vue的图书个性化推荐系统
- java: -source 7 中不支持 lambda 表达式 (请使用 -source 8 或更高版本以启用 lambda 表达式)
- WebGL开发智慧能源项目
- Windows安装和使用kafka
- 2024年【广东省安全员B证第四批(项目负责人)】考试题及广东省安全员B证第四批(项目负责人)考试资料
- 数组名作函数的实参形参之二:排序